
В прошлой статье мы определили понятия профилирования и оптимизации, познакомились с различными подходами к профилированию и видами инструментов. Немного коснулись истории профайлеров.
Сегодня я предлагаю перейти к практике и покажу на примерах способы ручного профилирования (и даже «метод пристального взгляда». Будут так же рассмотрены инструменты для статистического профилирования.
Какая может быть практика без примеров и тренировок? Я долго думал, какой же проект стоит взять в качестве учебного пособия, чтобы он был одновременно показательным и не очень сложным. На мой взгляд таковым является Project Euler — сборник математических и компьютерных головоломок, поскольку для решения предложенных задач приходится применять числодробительные алгоритмы и без оптимизации поиск ответа может продолжаться годами.
Вообще, очень советую порешать головоломки из «Проекта Эйлера». Помогает отвлечься, помедитировать и расслабиться, и в то же время держать свой мозг в тонусе.
В качестве примера для статьи возьмём задачу 3:
Пишем простое решение «в лоб»:
Внимательный или опытный читатель, возможно, сходу обзовёт меня нубом, назовёт несколько проблем этой программы и выдаст несколько рецептов по её оптимизации, но мы специально взяли простой пример и сделаем вид, что считаем этот код хорошим, оптимизируя его по ходу действия.
Для проверки запускаем программу c числом, делители которого нам известны:
Ответ 29, выданный программой правильный (его можно найти в условии задачи). Ура! Теперь запускаем программу с интересующим нас числом 600851475143:
И… ничего не происходит. Загрузка процессора 100%, выполнение программы не завершилось даже после нескольких часов работы. Начинаем разбираться. Вспоминаем, что оптимизировать можно только тот код, который работает корректно, но мы проверили работу программы на небольшом числе и ответ был правильный. Очевидно, что проблема в производительности и нам нужно приступать к оптимизации.
В реальной жизни я бы профилировал программу с аргументом 13195 (когда время её работы адекватно). Но поскольку мы тут тренируемся и вообще, just for jun, воспользуемся «методом пристального взгляда».
Открываем код и внимательно на него смотрим. Понимаем (если повезёт, то понимаем быстро), что для поиска делителей числа N нам нет смысла перебирать числа из интервала sqrt(N)+1…N-1, т.к. все делители из этого диапазона мы уже нашли при переборе чисел из интервала 2…sqrt(N). Слегка модифицируем код (см. строки 9 и 18):
Для проверки ещё раз запускаем программу с числом, делители которого нам известны:
Cубъективно программа отработала гораздо быстрее, значит снова запускаем её с интересующим нас числом 600851475143:
Проверяем ответ на сайте, он оказывается верным, задача решена, мы чувствуем моральное удовлетворение.
Программа выполнилась за приемлимое время (меньше минуты), ответ получен верный, смысла в дальнешей оптимизации в данном конкретном случае нет, т.к. поставленную задачу мы решили. Как мы помним, самое важное в оптимизации — уметь вовремя остановиться.
Да, я в курсе, что ребята из «Project Euler» просят не выкладывать ответы и решения в общий доступ. Но ответ к задаче 3 гуглится (например, по условию «project euler problem 3 answer» на раз, поэтому я считаю, что ничего страшного в том, что я написал ответ нет.
Один из самых распространённых способов быстро прикинуть «что к чему». В самом элементарном случае, если мы используем unix-утилиту «time» это выглядит так (до оптимизации):
И так (после оптимизации):
Ускорение почти в 65 раз (с ~3,87 секунд до ~61 милисекунд)!
Так же ручное профилирование может выглядеть так:
Результат:
Либо с использованием специального модуля «timeit», который предназначен для измерения быстродействия небольших программ. Пример применения:
Когда же можно применять ручное профилирование? Во-первых, это отличный способ для проведения различного рода соревнований между разработчиками («Мой код теперь работает быстрее твоего, значит я более лучший программист!»), и это хорошо. Во-вторых, когда требуется «на глазок» определить быстродействие программы (20 секунд? долго!) или получить результаты достигнутых улучшений (ускорил код в 100 раз!).
Но самое важное применение — это сбор статистики времени выполнения кода практически в реальном времени прямо на продакшене. Для этого измеренное время отправляем в любую систему сбора метрик и отрисовки графиков (я очень люблю использовать Graphite и StatsD в качестве аггрегатора для графита).
Для этого можно воспользоваться простым менеджером контекстов:
Пример его использования:
Или простым декоратором:
Пример использования декоратора:
На выходе получаем график времени выполнения интересующего нас участка кода, например, вот такой:
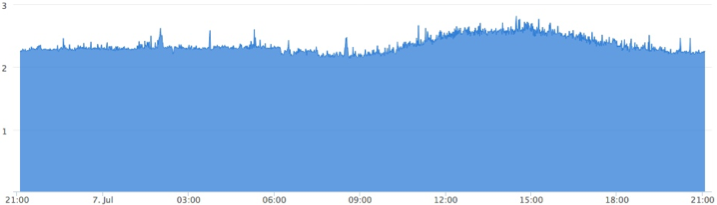
по которому всегда видно, как себя чувствует код на живых серверах, и не пора ли его оптимизировать. Видно, как код себя чувствует после очередного релиза. Если проводился рефакторинг или оптимизация, график позволяет своевременно оценить результаты и понять, улучшилась или ухудшилась ситуация в целом.
У метода есть и недостатки, и самый главный из них заключается в отсутствии зависимости от входных данных. Так, для функции определения простого числа «is_prime» время выполнения будет сильно зависеть от величины этого числа, и если эта функция в проекте вызывается очень часто график окажется совершенно бессмысленным. Важно чётко понимать где какой подход можно использовать и что мы имеем на выходе.
Конечно, можно назвать метод профилирования через сбор метрик в графит «статистическим», ведь мы собираем статистику работы программы. Но я предлагаю придерживаться принятой нами в первой части терминологии и под «статистическим» профилированием понимать именно сбор информации (семплирование) через определённые промежутки времени.
В случае использования графита и аггрегирующего сервера (StatsD) для него мы для одной метрики получаем сразу несколько графиков: минимальное и максимальное время выполнения кода, а так же медиану и количество записанных показаний (вызовов функции) в единицу времени, что очень удобно. Давайте посмотрим как просто подключить StatsD к Django.
Ставим модуль:
Добавляем настройки в settings.py: приложение и middleware:
И всё! На выходе получаем вот такие вот графики:
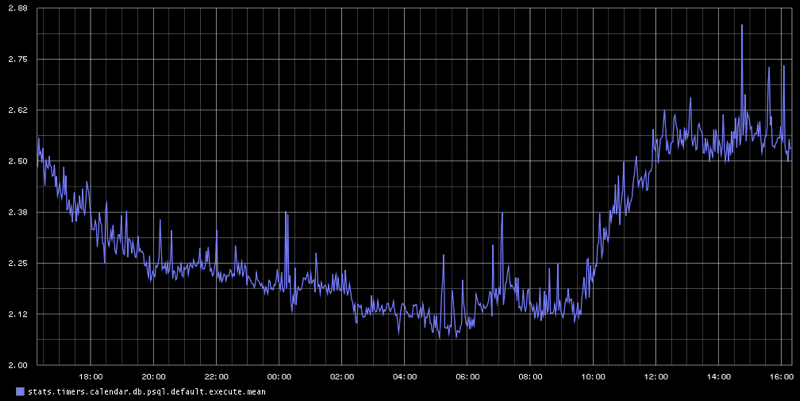
Плюсы и минусы StatsD:
+ прост в установке и использовании
+ годен для продакшена (must-have, в общем-то)
– мало информации (количество/время)
– Нужен graphite и statsd (тоже must-have)
В отличие от событийных профайлеров, инструментов для статистического профилирования немного. Я расскажу о трёх:
Пожалуй, самый известный статистический профайлер под питон — statprof. Ставим:
Используем, например. так:
Или как менеджер контекста (нет в версии 0.1.2 из pypi, есть только в версии из репозитория):
Попробуем отпрофилировать наш код:
Видим два «хотспота» в нашей программе. Первый: строки 12 и 11 функции «is_prime» (что логично), их выполнение занимает около 82% времени работы программы, и второй: строка 21 функции «find_prime_factors» (около 17% времени):
Именно из этой строки вызывается самая «горячая» функция программы «is_prime». Просто поменяв местами операнды в условии мы значительно ускорим программу, т.к. операция получения остатка от деления (num % i) выполняется быстрее функции «is_prime», и в то же время достаточно часто остаток от деления одного числа на другое не равен нулю, и «not num % i» вернёт False. Таким образом, мы кардинально уменьшим количество вызовов функции «is_prime»:
Запускаем профилирование:
Самое горячее место в нашей программе теперь строка 21 функции «find_prime_factors», то есть операция получения остатка от деления («num % i»). Функция «is_prime» теперь вызывается гораздо реже и выполняется всего 5% времени работы программы. Время работы программы значительно уменьшилось и наибольший простой делитель числа 600851475143 теперь находится всего за 0,25 секунд (ускорили программу почти в 80 раз).
Обратим внимание на то, как сильно упала точность работы профайлера: вместо 3575 семплов (в примере до оптимизации) было сделано всего 40 измерений и получена информация всего о пяти строках. Конечно, этого недостаточно. Собственно, в этом и заключается особенность статистических профайлеров: чем больше времени мы собираем данные, тем точнее анализ. Если бы мы, например, запустили программу десять или сто раз, мы бы получили гораздо более точные результаты.
Достоинства и недостатки statprof:
+ минимальный оверхед
+ простое использование
– реализация достаточно сырая и экспериментальная
– для адекватного результата нужен длительный анализ
– мало данных на выходе
Отдельным пунктом стоит отметить django-live-profiler — профайлер приложений Django, использующий statprof. Для его работы необходимо сначала установить zeromq:
Ставим сам модуль:
И запускаем аггрегатор:
Дальше добавляем профайлер в settings.py:
И в urls.py:
Запускаем сервер:
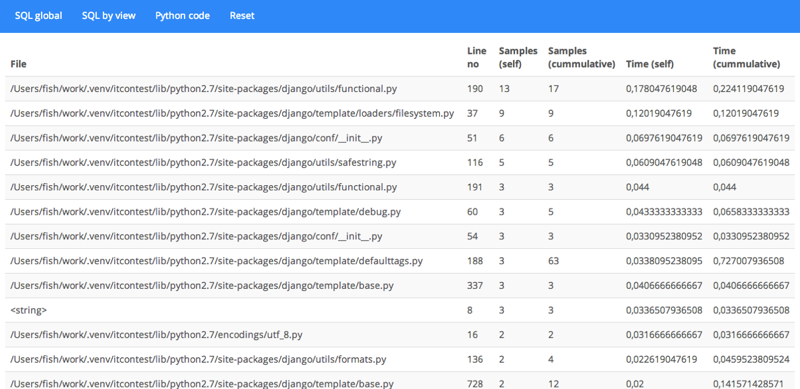
Открываем в браузере профайлер: 127.0.0.1:8000/profiler/ и радуемся жизни, наблюдая за результатами профилирования живого проекта в реальном времени:
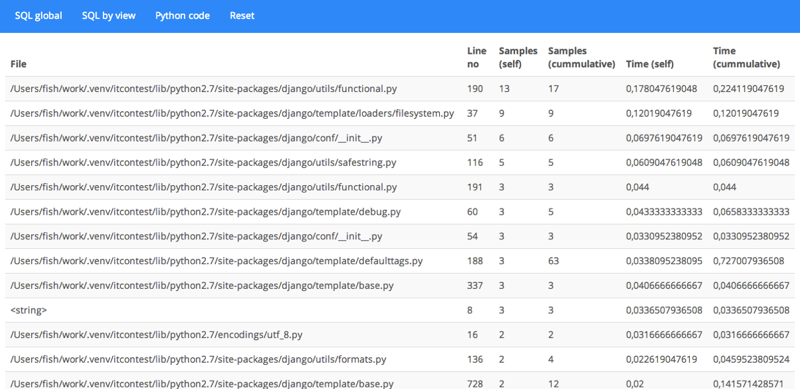
А ещё django-live-profiler умеет показывать SQL-запросы:

Достоинства и недостатки django-live-profiler:
+ небольшой оверхед
+ можно пускать в продакшн (очень осторожно)
+ профилирование SQL-запросов
– сложная установка, зависимости
– мало данных на выходе
Ещё один статистический профайлер называется plop (Python Low-Overhead Profiler). Автор сразу предупреждает, что реализация сырая и проект находится в стадии активной разработки. Установка тривиальна:
Запускаем профилирование:
Запускаем сервер для просмотра результатов:
Открываем в баузере страницу http://localhost:8888/ и любуемся результатами:

Plop можно использовать для профилирования Django-приложений. Для этого нужно установить пакет django-plop:
Добавить в settings.py middleware и параметр, указывающий профайлеру, куда складывать результаты:
В большом проекте граф будет выглядеть более внушительно:

Картина достаточно психоделична, серьёзным инструментом для профилирование это назвать сложно, но тем не менее граф вызовов у нас есть, самые горячие участки кода видно, оверхед минимальный (по утверждениям авторов всего 2%), и в некоторых случаях этого инструмента оказывается достаточно для обнаружения участков кода, нуждающихся в профилировании. Сервис Dropbox использует plop прямо в продакшене, а это о многом говорит.
Достоинства и недостатки plop:
+ минимальный оверхед
+ можно пускать в продакшн
– сложная установка, зависимости
– очень мало данных на выходе
Говоря о статистических профайлерах нельзя не сказать о сервисе New Relic, который предназначен не только для профилирования, но так же для мониторинга серверов и веб-приложений (а так же мобильных версий). Желающие могут посмотреть всю информацию на сайте компании, а так же попробовать сервис совершенно бесплатно. Я же не буду рассказывать о нём потому, что лично не пробовал работать с New Relic, а я привык говорить только о тех вещах, которые пробовал сам. Посмотреть скриншоты можно на странице, посвящённой профайлеру.
Достоинства и недостатки:
+ предназначен для продакшена
+ много разного функционала (не только профилирование)
– платный (есть бесплатная версия)
– данные отправляются на чужие серверы
В следующей статье мы перейдём к изучению событийных профайлеров — основными инструментами при профилировании Python. Оставайтесь на связи!
Сегодня я предлагаю перейти к практике и покажу на примерах способы ручного профилирования (и даже «метод пристального взгляда». Будут так же рассмотрены инструменты для статистического профилирования.
- Введение и теория — зачем вообще нужно профилирование, различные подходы, инструменты и отличия между ними
- Ручное и статистическое профилирование — переходим к практике
- Событийное профилирование — инструменты и их применение
- Отладка — что делать, когда ничего не работает
Тренируемся
Какая может быть практика без примеров и тренировок? Я долго думал, какой же проект стоит взять в качестве учебного пособия, чтобы он был одновременно показательным и не очень сложным. На мой взгляд таковым является Project Euler — сборник математических и компьютерных головоломок, поскольку для решения предложенных задач приходится применять числодробительные алгоритмы и без оптимизации поиск ответа может продолжаться годами.
Вообще, очень советую порешать головоломки из «Проекта Эйлера». Помогает отвлечься, помедитировать и расслабиться, и в то же время держать свой мозг в тонусе.
В качестве примера для статьи возьмём задачу 3:
Простые делители числа 13195 — это 5, 7, 13 и 29.
Какой самый большой делитель числа 600851475143, являющийся простым числом?
Пишем простое решение «в лоб»:
"""Project Euler problem 3 solve"""
from __future__ import print_function
import sys
def is_prime(num):
"""Checks if num is prime number"""
for i in range(2, num):
if not num % i:
return False
return True
def find_prime_factors(num):
"""Find prime factors of num"""
result = []
for i in range(2, num):
if is_prime(i) and not num % i:
result.append(i)
return result
if __name__ == '__main__':
try:
num = int(sys.argv[1])
except (TypeError, ValueError, IndexError):
sys.exit("Usage: euler_3.py number")
if num < 1:
sys.exit("Error: number must be greater than zero")
prime_factors = find_prime_factors(num)
if len(prime_factors) == 0:
print("Can't find prime factors of %d" % num)
else:
print("Answer: %d" % prime_factors[-1])Внимательный или опытный читатель, возможно, сходу обзовёт меня нубом, назовёт несколько проблем этой программы и выдаст несколько рецептов по её оптимизации, но мы специально взяли простой пример и сделаем вид, что считаем этот код хорошим, оптимизируя его по ходу действия.
Для проверки запускаем программу c числом, делители которого нам известны:
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ python euler_3.py 13195
Answer: 29
Ответ 29, выданный программой правильный (его можно найти в условии задачи). Ура! Теперь запускаем программу с интересующим нас числом 600851475143:
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ python euler_3.py 600851475143
И… ничего не происходит. Загрузка процессора 100%, выполнение программы не завершилось даже после нескольких часов работы. Начинаем разбираться. Вспоминаем, что оптимизировать можно только тот код, который работает корректно, но мы проверили работу программы на небольшом числе и ответ был правильный. Очевидно, что проблема в производительности и нам нужно приступать к оптимизации.
Метод пристального взгляда
В реальной жизни я бы профилировал программу с аргументом 13195 (когда время её работы адекватно). Но поскольку мы тут тренируемся и вообще, just for jun, воспользуемся «методом пристального взгляда».
Открываем код и внимательно на него смотрим. Понимаем (если повезёт, то понимаем быстро), что для поиска делителей числа N нам нет смысла перебирать числа из интервала sqrt(N)+1…N-1, т.к. все делители из этого диапазона мы уже нашли при переборе чисел из интервала 2…sqrt(N). Слегка модифицируем код (см. строки 9 и 18):
"""Project Euler problem 3 solve"""
from __future__ import print_function
import math
import sys
def is_prime(num):
"""Checks if num is prime number"""
for i in range(2, int(math.sqrt(num)) + 1):
if not num % i:
return False
return True
def find_prime_factors(num):
"""Find prime factors of num"""
result = []
for i in range(1, int(math.sqrt(num)) + 1):
if is_prime(i) and not num % i:
result.append(i)
if is_prime(num):
result.append(i)
return result
if __name__ == '__main__':
try:
num = int(sys.argv[1])
except (TypeError, ValueError, IndexError):
sys.exit("Usage: euler_3.py number")
if num < 1:
sys.exit("Error: number must be greater than zero")
prime_factors = find_prime_factors(num)
if len(prime_factors) == 0:
print("Can't find prime factors of %d" % num)
else:
print("Answer: %d" % prime_factors[-1])Для проверки ещё раз запускаем программу с числом, делители которого нам известны:
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ python euler_3.py 13195
Answer: 29
Cубъективно программа отработала гораздо быстрее, значит снова запускаем её с интересующим нас числом 600851475143:
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ python euler_3.py 600851475143
Answer: 6857
Проверяем ответ на сайте, он оказывается верным, задача решена, мы чувствуем моральное удовлетворение.
Программа выполнилась за приемлимое время (меньше минуты), ответ получен верный, смысла в дальнешей оптимизации в данном конкретном случае нет, т.к. поставленную задачу мы решили. Как мы помним, самое важное в оптимизации — уметь вовремя остановиться.
Да, я в курсе, что ребята из «Project Euler» просят не выкладывать ответы и решения в общий доступ. Но ответ к задаче 3 гуглится (например, по условию «project euler problem 3 answer» на раз, поэтому я считаю, что ничего страшного в том, что я написал ответ нет.
Ручное профилирование
Один из самых распространённых способов быстро прикинуть «что к чему». В самом элементарном случае, если мы используем unix-утилиту «time» это выглядит так (до оптимизации):
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ time python euler_3.py 13195
Answer: 29
python euler_3.py 13195 3,83s user 0,03s system 99% cpu 3,877 total
И так (после оптимизации):
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ time python euler_3.py 13195
Answer: 29
python euler_3.py 13195 0,03s user 0,02s system 90% cpu 0,061 total
Ускорение почти в 65 раз (с ~3,87 секунд до ~61 милисекунд)!
Так же ручное профилирование может выглядеть так:
import time
...
start = time.time()
prime_factors = find_prime_factors(num)
print("Time: %.03f s" % (time.time() - start))Результат:
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ python euler_3.py 600851475143
Answer: 6857
Time: 19.811 s
Либо с использованием специального модуля «timeit», который предназначен для измерения быстродействия небольших программ. Пример применения:
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ python -m timeit -n 10 -s'import euler_3' 'euler_3.find_prime_factors(600851475143)'
10 loops, best of 3: 21.3 sec per loop
Когда же можно применять ручное профилирование? Во-первых, это отличный способ для проведения различного рода соревнований между разработчиками («Мой код теперь работает быстрее твоего, значит я более лучший программист!»), и это хорошо. Во-вторых, когда требуется «на глазок» определить быстродействие программы (20 секунд? долго!) или получить результаты достигнутых улучшений (ускорил код в 100 раз!).
Но самое важное применение — это сбор статистики времени выполнения кода практически в реальном времени прямо на продакшене. Для этого измеренное время отправляем в любую систему сбора метрик и отрисовки графиков (я очень люблю использовать Graphite и StatsD в качестве аггрегатора для графита).
Для этого можно воспользоваться простым менеджером контекстов:
"""Collect profiling statistic into graphite"""
import socket
import time
CARBON_SERVER = '127.0.0.1'
CARBON_PORT = 2003
class Stats(object):
"""Context manager for send stats to graphite"""
def __init__(self, name):
self.name = name
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, *args):
duration = (time.time() - self.start) * 1000 # msec
message = '%s %d %d\n' % (self.name, duration, time.time())
sock = socket.socket()
sock.connect((CARBON_SERVER, CARBON_PORT))
sock.sendall(message)
sock.close()Пример его использования:
from python_profiling.context_managers import Stats
...
with Stats('project.application.some_action'):
do_some_action()Или простым декоратором:
"""Collect profiling statistic into graphite"""
import socket
import time
CARBON_SERVER = '127.0.0.1'
CARBON_PORT = 2003
def stats(name):
"""Decorator for send stats to graphite"""
def _timing(func):
def _wrapper(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
duration = (time.time() - start) * 1000 # msec
message = '%s %d %d\n' % (name, duration, time.time())
sock = socket.socket()
sock.connect((CARBON_SERVER, CARBON_PORT))
sock.sendall(message)
sock.close()
return result
return _wrapper
return _timingПример использования декоратора:
from python_profiling.decorators import stats
...
@stats('project.application.some_action')
def do_some_action():
"""Doing some useful action"""На выходе получаем график времени выполнения интересующего нас участка кода, например, вот такой:

по которому всегда видно, как себя чувствует код на живых серверах, и не пора ли его оптимизировать. Видно, как код себя чувствует после очередного релиза. Если проводился рефакторинг или оптимизация, график позволяет своевременно оценить результаты и понять, улучшилась или ухудшилась ситуация в целом.
У метода есть и недостатки, и самый главный из них заключается в отсутствии зависимости от входных данных. Так, для функции определения простого числа «is_prime» время выполнения будет сильно зависеть от величины этого числа, и если эта функция в проекте вызывается очень часто график окажется совершенно бессмысленным. Важно чётко понимать где какой подход можно использовать и что мы имеем на выходе.
Конечно, можно назвать метод профилирования через сбор метрик в графит «статистическим», ведь мы собираем статистику работы программы. Но я предлагаю придерживаться принятой нами в первой части терминологии и под «статистическим» профилированием понимать именно сбор информации (семплирование) через определённые промежутки времени.
Django StatsD
В случае использования графита и аггрегирующего сервера (StatsD) для него мы для одной метрики получаем сразу несколько графиков: минимальное и максимальное время выполнения кода, а так же медиану и количество записанных показаний (вызовов функции) в единицу времени, что очень удобно. Давайте посмотрим как просто подключить StatsD к Django.
Ставим модуль:
➜ pip install django-statsd-mozilla
Добавляем настройки в settings.py: приложение и middleware:
INSTALLED_APPS += ('django_statsd',)
MIDDLEWARE_CLASSES += (
'django_statsd.middleware.GraphiteRequestTimingMiddleware',
'django_statsd.middleware.GraphiteMiddleware',
)
# send DB timings
STATSD_PATCHES = ['django_statsd.patches.db']И всё! На выходе получаем вот такие вот графики:

Плюсы и минусы StatsD:
+ прост в установке и использовании
+ годен для продакшена (must-have, в общем-то)
– мало информации (количество/время)
– Нужен graphite и statsd (тоже must-have)
Статистические профайлеры
В отличие от событийных профайлеров, инструментов для статистического профилирования немного. Я расскажу о трёх:
StatProf
Пожалуй, самый известный статистический профайлер под питон — statprof. Ставим:
➜ pip install statprof
Используем, например. так:
import statprof
...
statprof.start()
try:
do_some_action()
finally:
statprof.stop()
statprof.display()Или как менеджер контекста (нет в версии 0.1.2 из pypi, есть только в версии из репозитория):
import statprof
...
with statprof.profile():
do_some_action()Попробуем отпрофилировать наш код:
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ python euler_3.py 600851475143
% cumulative self
time seconds seconds name
44.42 8.63 8.63 euler_3.py:12:is_prime
37.12 7.21 7.21 euler_3.py:11:is_prime
16.90 19.40 3.28 euler_3.py:21:find_prime_factors
0.95 0.18 0.18 euler_3.py:9:is_prime
0.48 0.09 0.09 euler_3.py:13:is_prime
0.06 0.01 0.01 euler_3.py:14:is_prime
0.06 0.01 0.01 euler_3.py:20:find_prime_factors
0.03 0.01 0.01 euler_3.py:23:find_prime_factors
0.00 19.42 0.00 euler_3.py:37:<module>
— Sample count: 3575
Total time: 19.420000 seconds
Answer: 6857
Видим два «хотспота» в нашей программе. Первый: строки 12 и 11 функции «is_prime» (что логично), их выполнение занимает около 82% времени работы программы, и второй: строка 21 функции «find_prime_factors» (около 17% времени):
if is_prime(i) and not num % i:Именно из этой строки вызывается самая «горячая» функция программы «is_prime». Просто поменяв местами операнды в условии мы значительно ускорим программу, т.к. операция получения остатка от деления (num % i) выполняется быстрее функции «is_prime», и в то же время достаточно часто остаток от деления одного числа на другое не равен нулю, и «not num % i» вернёт False. Таким образом, мы кардинально уменьшим количество вызовов функции «is_prime»:
if not num % i and is_prime(i):Запускаем профилирование:
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ python euler_3.py 600851475143
% cumulative self
time seconds seconds name
87.50 0.22 0.22 euler_3.py:21:find_prime_factors
5.00 0.01 0.01 euler_3.py:20:find_prime_factors
5.00 0.01 0.01 euler_3.py:11:is_prime
2.50 0.01 0.01 euler_3.py:23:find_prime_factors
0.00 0.25 0.00 euler_3.py:37:<module>
— Sample count: 40
Total time: 0.250000 seconds
Answer: 6857
Самое горячее место в нашей программе теперь строка 21 функции «find_prime_factors», то есть операция получения остатка от деления («num % i»). Функция «is_prime» теперь вызывается гораздо реже и выполняется всего 5% времени работы программы. Время работы программы значительно уменьшилось и наибольший простой делитель числа 600851475143 теперь находится всего за 0,25 секунд (ускорили программу почти в 80 раз).
Обратим внимание на то, как сильно упала точность работы профайлера: вместо 3575 семплов (в примере до оптимизации) было сделано всего 40 измерений и получена информация всего о пяти строках. Конечно, этого недостаточно. Собственно, в этом и заключается особенность статистических профайлеров: чем больше времени мы собираем данные, тем точнее анализ. Если бы мы, например, запустили программу десять или сто раз, мы бы получили гораздо более точные результаты.
Здесь я должен сделать небольшое лирическое отступление.
99% всех вспомогательных утилит, таких как профайлеры или инструменты для анализа покрытия кода тестами (code coverage), работают со строками в качестве минимальной единицы информации. Таким образом, если мы будем пытаться писать код как можно более компактно, например так:
мы не сможем в профайлере увидеть, какая из функций вызывалась, а какая нет. И в отчёте coverage мы не увидим, покрыт ли тот или иной вариант развития событий тестами. Несмотря на более привычный и, казалось бы, удобный код, в некоторых случаях всё-таки лучше писать так:
и тогда мы сразу увидим какие строки не исполняются, а какие — исполняются (и как часто). Однострочники и компактность — это, конечно, хорошо и прикольно, но иногда лучше потратить больше времени и получить код, который легче профилировать, тестировать и поддерживать.
result = foo() if bar else baz()мы не сможем в профайлере увидеть, какая из функций вызывалась, а какая нет. И в отчёте coverage мы не увидим, покрыт ли тот или иной вариант развития событий тестами. Несмотря на более привычный и, казалось бы, удобный код, в некоторых случаях всё-таки лучше писать так:
if bar:
result = foo()
else:
result = baz()и тогда мы сразу увидим какие строки не исполняются, а какие — исполняются (и как часто). Однострочники и компактность — это, конечно, хорошо и прикольно, но иногда лучше потратить больше времени и получить код, который легче профилировать, тестировать и поддерживать.
Достоинства и недостатки statprof:
+ минимальный оверхед
+ простое использование
– реализация достаточно сырая и экспериментальная
– для адекватного результата нужен длительный анализ
– мало данных на выходе
Django-live-profiler
Отдельным пунктом стоит отметить django-live-profiler — профайлер приложений Django, использующий statprof. Для его работы необходимо сначала установить zeromq:
➜ brew install zmq
Ставим сам модуль:
➜ pip install django-live-profiler
И запускаем аггрегатор:
➜ aggregated --host 127.0.0.1 --port 5556
Дальше добавляем профайлер в settings.py:
# добавляем application
INSTALLED_APPS += ('profiler',)
# добавляем middleware
MIDDLEWARE_CLASSES += (
'profiler.middleware.ProfilerMiddleware',
'profiler.middleware.StatProfMiddleware',
)И в urls.py:
url(r'^profiler/', include('profiler.urls'))Запускаем сервер:
➜ python manage.py runserver --noreload --nothreading
Открываем в браузере профайлер: 127.0.0.1:8000/profiler/ и радуемся жизни, наблюдая за результатами профилирования живого проекта в реальном времени:
А ещё django-live-profiler умеет показывать SQL-запросы:
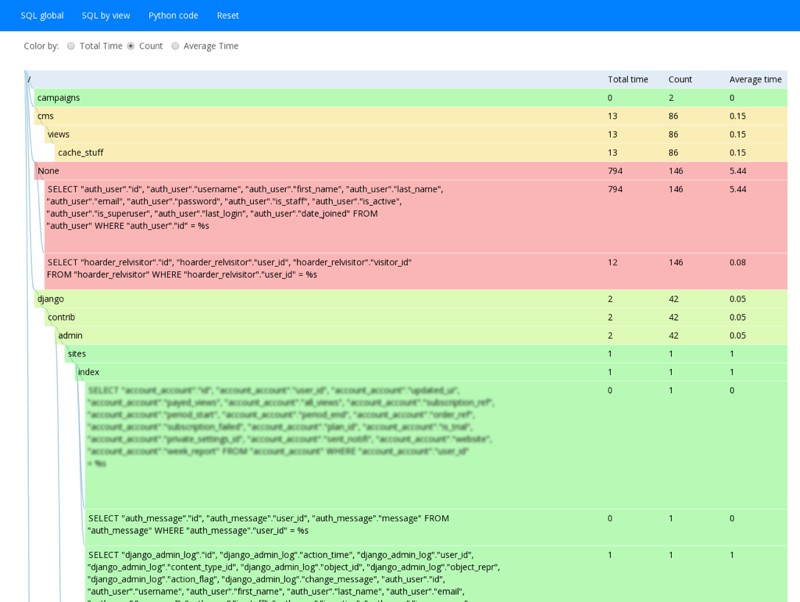
Достоинства и недостатки django-live-profiler:
+ небольшой оверхед
+ можно пускать в продакшн (очень осторожно)
+ профилирование SQL-запросов
– сложная установка, зависимости
– мало данных на выходе
Plop
Ещё один статистический профайлер называется plop (Python Low-Overhead Profiler). Автор сразу предупреждает, что реализация сырая и проект находится в стадии активной разработки. Установка тривиальна:
➜ pip install plop tornado
Запускаем профилирование:
rudnyh@work:~/work/python-profiling (venv: python-profiling)
➜ python -m plop.collector euler_3.py 600851475143
Answer: 6857
profile output saved to /tmp/plop.out
overhead was 5.89810884916e-05 per sample (0.00589810884916%)
Запускаем сервер для просмотра результатов:
➜ python -m plop.viewer --datadir=/tmp/
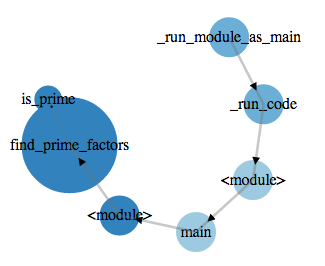
Открываем в баузере страницу http://localhost:8888/ и любуемся результатами:
Plop можно использовать для профилирования Django-приложений. Для этого нужно установить пакет django-plop:
➜ pip install django-plop
Добавить в settings.py middleware и параметр, указывающий профайлеру, куда складывать результаты:
MIDDLEWARE_CLASSES += (
'django-plop.middleware.PlopMiddleware',
)
PLOP_DIR = os.path.join(PROJECT_ROOT, 'plop')В большом проекте граф будет выглядеть более внушительно:
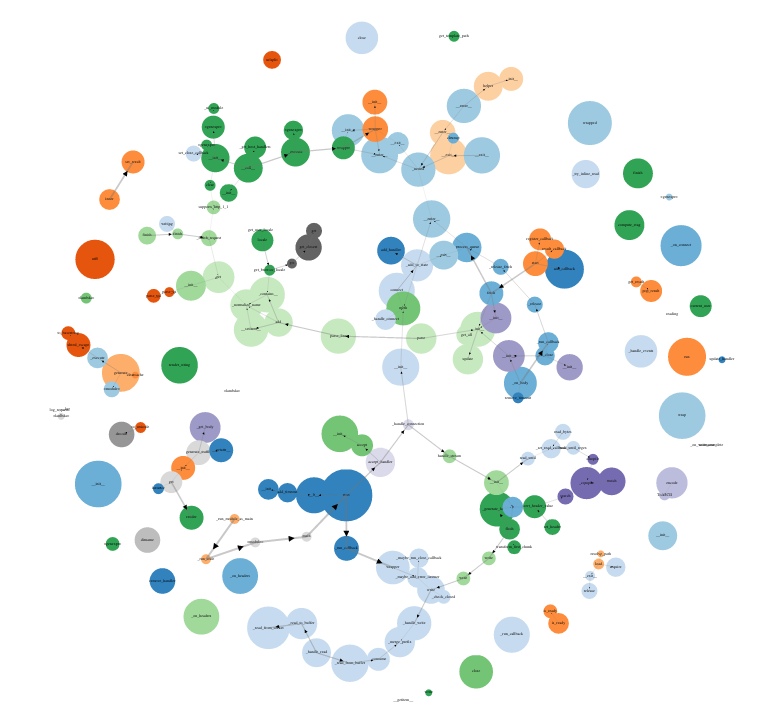
Картина достаточно психоделична, серьёзным инструментом для профилирование это назвать сложно, но тем не менее граф вызовов у нас есть, самые горячие участки кода видно, оверхед минимальный (по утверждениям авторов всего 2%), и в некоторых случаях этого инструмента оказывается достаточно для обнаружения участков кода, нуждающихся в профилировании. Сервис Dropbox использует plop прямо в продакшене, а это о многом говорит.
Достоинства и недостатки plop:
+ минимальный оверхед
+ можно пускать в продакшн
– сложная установка, зависимости
– очень мало данных на выходе
New Relic
Говоря о статистических профайлерах нельзя не сказать о сервисе New Relic, который предназначен не только для профилирования, но так же для мониторинга серверов и веб-приложений (а так же мобильных версий). Желающие могут посмотреть всю информацию на сайте компании, а так же попробовать сервис совершенно бесплатно. Я же не буду рассказывать о нём потому, что лично не пробовал работать с New Relic, а я привык говорить только о тех вещах, которые пробовал сам. Посмотреть скриншоты можно на странице, посвящённой профайлеру.
Достоинства и недостатки:
+ предназначен для продакшена
+ много разного функционала (не только профилирование)
– платный (есть бесплатная версия)
– данные отправляются на чужие серверы
В следующей статье мы перейдём к изучению событийных профайлеров — основными инструментами при профилировании Python. Оставайтесь на связи!
