
Прошло уже больше года после публикации статей, посвященных нагрузочному тестированию Skyforge — новой MMORPG от студии Allods Team. С тех пор изменилось многое: дизайн Хабра, Ubuntu обновилась до 14.04.1 LTS, вышла Java 8, а главное — изменилась стадия развития проекта. Состоялось первое закрытое тестирование на внешних пользователях, а скоро будет и стресс-тест – приглашение максимально возможного числа «живых пользователей» на сервера в рамках ЗБТ или ОБТ. Но не буду отнимать работу у нашей команды маркетинга, расскажу лучше о том, что у нас нового в нагрузочном тестировании, что мы переосмыслили, и что из этого может быть полезно широкой общественности.

Данные тесты показали себя очень хорошо именно как нагрузочные, большего от них и не ждали. Они не способны найти ошибки, лежащие дальше простого «не работает». Зато отличаются очень хорошей повторяемостью результата, намного дешевле в разработке и, как следствие, поддержке. Если говорить об экономии еще и в железках, то выходит как-то так:
Вызвано это в первую очередь тем, что чем дальше мы от боевой конфигурации, тем больше мы можем себе позволить. Например, в тесте системы статистики нет в принципе ни одной запчасти, связанной с самой игрой, только сами приложения, обрабатывающие данные. В тестах чатика или базы данных мы сознательно не нагружаем игровую механику, держа игровой реалм в минимальной запускаемой конфигурации, и только объект нагрузки — в полностью боевом режиме. Также стоит отметить, что чем меньше подсистем участвует в тесте, тем выше стабильность теста.
Также оптимизации самого клиента игры не прошли стороной и наших ботов, так у них значительно снизилось потребление памяти. И теперь мы можем с одной физической машины запускать в два раза больше ботов — 2к вместо 1к.
Клиентские тесты мы сейчас проводим по следующей схеме: все проходят старт игры (самый важный момент для нас с точки зрения нагрузки), все как-то играют (профиль игроков, участвующих в разных активностях взят из головы), все играют на определенной карте. Это позволяет нам находить плохие, с точки зрения нагрузки, карты и оперативно вмешиваться в процесс их создания. Смотреть, какой профиль нагрузки у нас в спокойное время, и быть уверенными, что у нас всё хорошо со стартом игры.

Подробнее можно почитать на сайте Oracle.
Далее этот дамп можно открыть с помощью JMC. В дампе будет представлена вся нужная информация: статистика аллокаций, кто кушал процессорное время, вклад процесса в общий cpu load сервера и многое другое. JMC — это хорошо, но так как на боевых серверах мы его позволить себе не можем, то используем дедовский метод — логи GC, из которых вытаскиваем следующую информацию: сколько времени мы провели за минуту в gc, суммарный application stop time за этот же период, какие объекты были до FullGC, какие — после:
Пример графика:

Пример статистик до — после:

Еще на всякий случай все сервера мы запускаем с опцией удаленной отладки. Это очень экономит время, когда что-то идет не так, а из логов точная причина неполадок неясна:

Похожую статистику мы ведем и для операций с базой данных, мы знаем не только какие операции были выполнены:
Но и время их исполнения:

Для того чтобы оптимизировать трафик, также приходится делать собственные решения. Поэтому мы замеряем, какие именно сообщения были отправлены, учитывая как их количество, так и объем.

Также выделение отдельного сервиса для построения отчетов способствовало появлению единой точки входа для просмотра данных с нагрузочных тестов, боевых серверов или других тестовых стендов.
Во-вторых, если у вас большая и сложная распределенная система, то, кроме интеграционных нагрузочных тестов, может быть целесообразно также проводить нагрузочные тесты на отдельные компоненты. Это, как правило, дешевле, и такие тесты можно делать более гибкими.
И, в-третьих, нагрузочные тесты полезны еще и тем, что значительная часть обвязки, созданной для их проведения, может очень даже хорошо работать и в боевых условиях.
На этом всё. Как всегда, с радостью отвечу на возникшие вопросы в комментариях.

Краткое содержание предыдущих частей
- Skyforge — это MMORPG, действие которого происходит в мире sci-fantasy. Мир в игре будет единым для всех территорий. То есть все игроки России и других стран бывшего СССР смогут вместе выполнять задания, спасать мир и становиться богами. Не будет никакого деления по серверам.
- Сервер Skyforge написан на Java, архитектура очень подробно описана в соответствующем посте randll.
- Базы данных — PostgreSQL + распределенные транзакции.
- Бот — программа, написанная на C++ и имитирующая действия реального игрока. Боты работают по тому же протоколу, что и честный игровой клиент, используют тот же набор команд, и, в целом, с точки зрения сервера слабо отличаются от обычного клиента.
- Нагрузочное тестирование — совокупность мероприятий, направленных на получение информации о том, способен ли сервер держать положенную нагрузку. Нагрузочные тесты разного характера мы запускаем несколько раз в день. Средний тест идет 40 минут, при этом чистое время теста находится в интервале от 60 до 80 минут.
Больше нагрузочных тестов
Достаточно продолжительное время «клиентские» нагрузочные тесты оставались единственными нагрузочными тестами, которые мы проводили. Но шло время, росли амбиции, менялись потребности и появились задачи требовавшие протестировать нагрузку бóльшую, чем мы могли дать с использованием клиентских ботов. Ограничение было вызвано в первую очередь тем, что клиентские боты занимались очень большим количеством «сторонних» вещей — принимали решения, честно проверяли какие-то условия, играли, в конце концов. Так начали появляться серверные боты, написанные на Java, лишенные всякой логики и просто дающие жару. Сейчас у нас есть три типа таких «ботов»:- датабазные — посылают вслепую датабазные операции, используя в качестве исходного профиля профиль реальных игроков с закрытых тестов, и случайные данные;
- боты для чата — делают то же самое, что и датабазные, только для сервисов чата;
- генераторы статистики — идея ровно такая же, что и в двух предыдущих случаях, но для подсистемы статистики.
Данные тесты показали себя очень хорошо именно как нагрузочные, большего от них и не ждали. Они не способны найти ошибки, лежащие дальше простого «не работает». Зато отличаются очень хорошей повторяемостью результата, намного дешевле в разработке и, как следствие, поддержке. Если говорить об экономии еще и в железках, то выходит как-то так:
- для тестирования 10к CCU клиентскими ботами нам в сумме нужно 7 (объекты нагрузки) + 10 (боты) = 17 серверов;
- для тестирования базы данных 50к CCU серверными: 4 + 2 = 6 серверов;
- 100к CCU чатика: 4 + 2 = 6 серверов;
- 100к CCU системы статистики: 2 + 1 = 3 сервера.
Вызвано это в первую очередь тем, что чем дальше мы от боевой конфигурации, тем больше мы можем себе позволить. Например, в тесте системы статистики нет в принципе ни одной запчасти, связанной с самой игрой, только сами приложения, обрабатывающие данные. В тестах чатика или базы данных мы сознательно не нагружаем игровую механику, держа игровой реалм в минимальной запускаемой конфигурации, и только объект нагрузки — в полностью боевом режиме. Также стоит отметить, что чем меньше подсистем участвует в тесте, тем выше стабильность теста.
Клиентские боты
Но как бы прекрасны ни были боты серверные, от клиентских ботов отказываться мы не намерены. Потому что пользы от них существенно больше, а профиль нагрузки максимально приближен к реальному. Поэтому за минувший год они также были значительно улучшены. Теперь они почти абсолютно честно могут проходить значительную часть контента игры. При этом поддержка требуется в минимальном количестве. Выглядит это как-то так: бот появляется на карте, смотрит в свой квест-трекер, видит там указание бежать в точку А и бежит. Благодаря тому, что бот обучен взаимодействовать с окружающим миром, в точке А он последовательно попробует поговорить с кем-нибудь, повзаимодействовать с чем-нибудь или убить всех агрессоров. Почти как в той байке: может ли оно меня съесть? А я его? А могу ли с этим совокупиться? А оно со мной? :)Также оптимизации самого клиента игры не прошли стороной и наших ботов, так у них значительно снизилось потребление памяти. И теперь мы можем с одной физической машины запускать в два раза больше ботов — 2к вместо 1к.
Клиентские тесты мы сейчас проводим по следующей схеме: все проходят старт игры (самый важный момент для нас с точки зрения нагрузки), все как-то играют (профиль игроков, участвующих в разных активностях взят из головы), все играют на определенной карте. Это позволяет нам находить плохие, с точки зрения нагрузки, карты и оперативно вмешиваться в процесс их создания. Смотреть, какой профиль нагрузки у нас в спокойное время, и быть уверенными, что у нас всё хорошо со стартом игры.

Без этих инструментов нагрузочные тесты были бы в 10 раз более унылые
Пожалуй, это самая полезная часть статьи. При проведении нагрузочных тестов мало знать, держит сервер нагрузку или нет. Самое важное — это возможность быстро понять, что именно идет не так. Здесь неоценимый вклад вносит Java Mission Control и его фича — Flight Recorder. К сожалению, эта опция на боевых серверах достаточно дорогая ($), поэтому мы пользуемся ей только в тестах. Выглядит это как-то так:-XX:+UnlockCommercialFeatures # Включение поддержки JMC
-XX:+FlightRecorder # Включение режима отложенной записи профиля
-XX:StartFlightRecording=name=skyforge,filename=skyforge.jfr,delay=40m,duration=10m,settings=jmc.jfcПодробнее можно почитать на сайте Oracle.
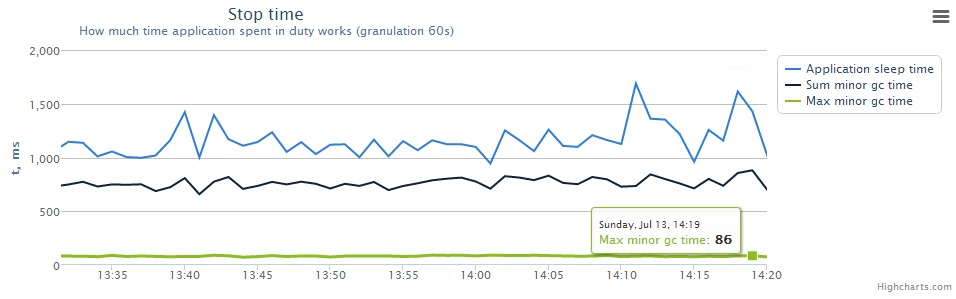
Далее этот дамп можно открыть с помощью JMC. В дампе будет представлена вся нужная информация: статистика аллокаций, кто кушал процессорное время, вклад процесса в общий cpu load сервера и многое другое. JMC — это хорошо, но так как на боевых серверах мы его позволить себе не можем, то используем дедовский метод — логи GC, из которых вытаскиваем следующую информацию: сколько времени мы провели за минуту в gc, суммарный application stop time за этот же период, какие объекты были до FullGC, какие — после:
-XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintClassHistogramBeforeFullGC -XX:+PrintClassHistogramAfterFullGC -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime -XX:+PrintPromotionFailure -Xloggc:memory/gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=memory/heap.dumpПример графика:
Пример статистик до — после:

Еще на всякий случай все сервера мы запускаем с опцией удаленной отладки. Это очень экономит время, когда что-то идет не так, а из логов точная причина неполадок неясна:
-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=51003Собственная статистика
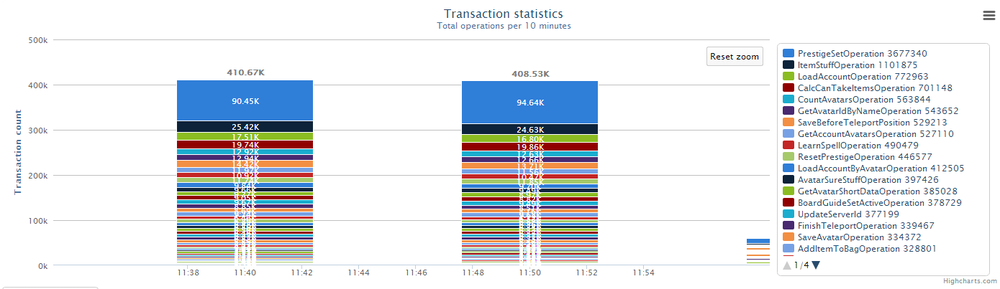
Кроме использования уже готовых средств профилирования, мы активно разрабатывали собственные. Так, например, мы логируем каждый спелл, который колдует игрок, замеряя, сколько процессорного времени было на него потрачено. Это позволяет принимать решения о том, какие именно абилки и механики нужно оптимизировать в первую очередь.
Похожую статистику мы ведем и для операций с базой данных, мы знаем не только какие операции были выполнены:

Но и время их исполнения:

Для того чтобы оптимизировать трафик, также приходится делать собственные решения. Поэтому мы замеряем, какие именно сообщения были отправлены, учитывая как их количество, так и объем.

Оптимизации при построении отчетов о тестах
С ростом числа тестов и числа графиков, стало понятно, что заниматься подготовкой теста, его проведением и анализом в одном процессе непозволительная роскошь. В связи с этим, непосредственно анализ результатов теста и построение отчета были вынесены в отдельный сервис, никак не связанный с системой CI. Это позволило освободить время для прогона дополнительных тестов.Также выделение отдельного сервиса для построения отчетов способствовало появлению единой точки входа для просмотра данных с нагрузочных тестов, боевых серверов или других тестовых стендов.
Наши грабли
Во время тестов очень важно контролировать инфраструктуру, на которой эти самые тесты проводятся. Я уже упоминал в предыдущих статьях, что у нас были проблемы с CPU Frequency Governors, когда искусственно занижалась тактовая частота процесса в целях сбережения электроэнергии. Так вот, мы опять попались на этом. Теперь думаем, как встроить проверку этих флажков в сервер. А в датабазные сервисы, например, мы добавили проверку, что на базах данных настроена синхронная реплика. Потому что её внезапное «отключение» даёт заметный прирост производительности. В общем, советую добавлять проверки окружения непосредственно в сами сервисы. Это дает гарантии того, что ваши серверы оперируются и тестируются именно в том окружении, на которое они рассчитаны.Выводы
В первую очередь хочется заметить, что нагрузочное тестирование, как и любое другое средство улучшения качества ПО, приносит максимальную пользу только тогда, когда используется постоянно. Да, поддержка тестов требует усилий, но оно того стоит. Лучше потратить эти усилия в спокойной обстановке, чем в пожарном режиме.Во-вторых, если у вас большая и сложная распределенная система, то, кроме интеграционных нагрузочных тестов, может быть целесообразно также проводить нагрузочные тесты на отдельные компоненты. Это, как правило, дешевле, и такие тесты можно делать более гибкими.
И, в-третьих, нагрузочные тесты полезны еще и тем, что значительная часть обвязки, созданной для их проведения, может очень даже хорошо работать и в боевых условиях.
На этом всё. Как всегда, с радостью отвечу на возникшие вопросы в комментариях.
