

Be my friend by oosDesign
Перед крупными интернет-компаниями часто встают такие сложные задачи, как обработка больших данных и анализ графов социальных сетей. Помогают в их решении фреймворки, но сперва необходимо проанализировать возможные варианты и выбрать подходящий. В лаборатории при Техносфере Mail.Ru мы изучаем эти вопросы на реальных примерах из проектов Mail.Ru Group (myTarget, Поиск Mail.Ru, Антиспам). Задачи могут быть как сугубо практические, так и с исследовательской составляющей. По мотивам одной из таких задач и появилась эта статья.
Во время сборки и запуска своего первого проекта на Giraph сотрудники лаборатории анализа данных Техносферы Mail.Ru столкнулись с рядом проблем, в связи с чем родилась идея написать краткий туториал, как же собрать и запустить свой первый Giraph-проект.
В этой статье мы расскажем, как создавать свои приложения под фреймворк Giraph, который является надстройкой над популярной системой обработки данных Hadoop.
0. Что такое Giraph
Giraph — это фреймворк для итеративной обработки больших графов, который работает поверх весьма популярной системы распределенной обработки данных Hadoop. Подобно тому как толчком для появления Hadoop и HDFS послужила статья Google о концепции MapReduce и GFS (Google File System), Giraph появился как open source версия гугловой Pregel, статья о которой была опубликована в 2010 году. Giraph используется такими крупными корпорациями, как Facebook, для обработки графов.
В чем заключается особенность Giraph? Основная его «фишка» — так называемая vertex-centric-модель. Как написано в Practical Graph Analytics with Apache Giraph:
Эта модель требует от разработчика, чтобы он побывал в шкуре вершины, которая может обмениваться сообщениями с другими вершинами между итерациями. Во время разработки вам не придется задумываться о проблемах параллелизации и масштабирования — этим занимается сам Giraph.
Обработка графа в Giraph выглядит следующим образом: процесс разбит на итерации, которые называются суперстепами (supersteps). На каждом суперстепе вершина выполняет необходимую программу и, если надо, может разослать сообщения другим вершинам. На следующей итерации вершина получает сообщения, выполняет программу, рассылает сообщения и т. д. После завершения всех суперстепов вы получите результирующий граф.
Giraph поддерживает большое количество возможностей взаимодействия с графом, в том числе создание/удаление вершин, создание/удаление ребер, возможность переопределения формата, в котором задан граф или выбор из существующих, управление загрузкой с диска и выгрузкой частей графа на диск во время работы с ним и многое другое. С подробностями можно ознакомиться в книге Practical Graph Analytics with Apache Giraph.
1. Необходимое ПО
Для начала вам понадобится сам Hadoop. Если у вас нет доступа к кластеру с Hadoop, можно развернуть его single-node-версию. Она не очень требовательна к ресурсам, на ноутбуке заработает спокойно. Для этого, например, можно использовать дистрибутив Hadoop под названием Cloudera. Мануал по установке Cloudera вы можете найти здесь. При разработке и тестировании в этой статье был использован Cloudera 5.5 (Hadoop 2.6.0).
Giraph реализован на Java. При сборке проектов используется билд-менеджер Maven. Исходный код Giraph можно скачать с официального сайта. Инструкция по компиляции самого Giraph и примеров, которые поставляются с ним, находится тут и в Quick Start Guide.
Любая IDE, такая как Eclipse или IntelliJ IDEA, умеет работать с Maven в проектах, что очень удобно при разработке. Мы в своих экспериментах использовали IntelliJ IDEA.
2. Компиляция Giraph
Давайте для начала скомпилируем содержимое исходников Giraph и попробуем что-нибудь запустить. Как было сказано в инструкции, в папке с проектом Giraph выполняем команду:
mvn -Phadoop_2 -fae -DskipTests clean install
И ждем какое-то время, пока все собирается… В папочке giraph-examples/target появятся собранные jar-файлы, нам понадобится giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar.
Давайте запустим, например, SimpleShortestPathsComputation. Для начала нам нужен файл с входными данными. Возьмем пример из Quick Start Guide:
[0,0,[[1,1],[3,3]]]
[1,0,[[0,1],[2,2],[3,1]]]
[2,0,[[1,2],[4,4]]]
[3,0,[[0,3],[1,1],[4,4]]]
[4,0,[[3,4],[2,4]]]
Сохраним это в файл tiny_graph.txt и положим в HDFS в нашу локальную папку:
hdfs dfs -put ./tiny_graph.txt ./
При такой команде файл попадет в вашу локальную директорию. Проверить это можно, выведя на экран содержимое файла:
hdfs dfs -text tiny_graph.txt
Ок, все круто, а теперь запустимся:
hadoop jar \
giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar \
org.apache.giraph.GiraphRunner \
org.apache.giraph.examples.SimpleShortestPathsComputation \
-vif org.apache.giraph.io.formats.JsonLongDoubleFloatDoubleVertexInputFormat \
-vip tiny_graph.txt \
-vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat \
-op shortestpaths \
-w 1
Давайте разберемся, что тут написано:
hadoop jar giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar— эта часть команды говорит Хадупу запустить jar-файл;org.apache.giraph.GiraphRunner— имя ранера. Тут используется дефолтный. Ранер можно переопределить. Чтобы он, например, при старте удалял старые данные или совершал еще какие-то подготовительные действия. Подробней об этом можно прочитать в книжке Practical Graph Analytics with Apache Giraph;org.apache.giraph.examples.SimpleShortestPathsComputation— класс, содержащий compute-метод, который будет исполнен;-vifопределяет класс, который будет читать входной файл с вершинами. Этот класс выбирается в зависимости от формата входного файла и может быть разным, при необходимости его даже можно переопределить (см. в Practical Graph Analytics with Apache Giraph). Описание стандартных классов можно посмотреть тут;-vip— путь до входного файла, который содержит описания вершин;-vof— в каком формате будет сохранен результат работы. При желании переопределяется, описания стандартных классов смотри тут;-op— куда сохранить;-w— количество воркеров (процессов, которые обрабатывают повершинно граф).
Более подробно о параметрах запуска можно узнать, набрав в консоли:
hadoop jar \
giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar \
org.apache.giraph.GiraphRunner \
org.apache.giraph.examples.SimpleShortestPathsComputation -h
После запуска мы можем прочесть результат в shortestpaths, выполнив
hdfs dfs -text shortestpaths/*
3. Создание собственного проекта
А теперь давайте напишем приложение, которое будет считать степень вершин в ненаправленном графе. Я создаю новый Maven-проект. Как это сделать, написано, например, тут. В корне проекта лежит pom.xml, заполняем его следующим образом:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>ru.simple.giraph.project.org</groupId>
<artifactId>simple-giraph-project</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>cloudera</id>
<url>
https://repository.cloudera.com/artifactory/cloudera-repos/
</url>
</repository>
</repositories>
<properties>
<org.apache.hadoop.version>2.6.0-cdh5.5.1</org.apache.hadoop.version>
</properties>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<finalName>simple-giraph-project</finalName>
<descriptor>
${project.basedir}/src/main/assembly/single-jar.xml
</descriptor>
</configuration>
<executions>
<execution>
<goals>
<goal>single</goal>
</goals>
<phase>package</phase>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${org.apache.hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${org.apache.hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.giraph</groupId>
<artifactId>giraph-core</artifactId>
<version>1.1.0-hadoop2</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
</dependencies>
</project>
О том, как создавать pom-файлы и работать с Maven, вы можете прочесть в официальном гайде тут. После этого в src я создаю новый файл ComputationDegree.java. Это будет наш класс, который будет считать степени вершин:
/**
* This is a simple implementation of vertex degree computation.
*/
package ru.simple.giraph.project.org;
import com.google.common.collect.Iterables;
import org.apache.giraph.graph.BasicComputation;
import org.apache.giraph.graph.Vertex;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class ComputeDegree extends
BasicComputation<IntWritable, IntWritable,
NullWritable, Text> {
public void compute(Vertex<IntWritable, IntWritable,
NullWritable> vertex, Iterable<Text> iterable) throws IOException {
if (getSuperstep() == 0){
sendMessageToAllEdges(vertex, new Text());
} else if (getSuperstep() == 1){
Integer degree = Iterables.size(vertex.getEdges());
vertex.setValue(new IntWritable(degree));
}else{
vertex.voteToHalt();
}
}
}
Работает это так:
- На первом шаге каждая вершина шлет своим соседям сообщения.
- Каждая вершина подсчитывает количество входящих сообщений и сохраняет их в значении вершины.
- Все вершины голосуют за остановку вычислений.
На выходе мы имеем граф, который в значении вершины хранит степень вершины. Компилируемся командой:
mvn package -fae -DskipTests clean install
Обычно после компиляции создается папочка target, в которой лежит файл giraph-test-fatjar.jar. Этот файл мы и будем запускать. Возьмем какой-нибудь очень простой граф, например вот такой:
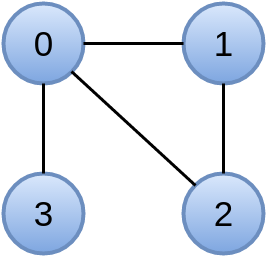
В качестве входного формата данных будем использовать org.apache.giraph.io.formats.IntIntNullTextVertexInputFormat, так что файл, описывающий наш граф, будет выглядеть вот так:
0 0 1 2 3
1 0 0 2
2 0 0 1
3 0 0
Сохраняем его в файл example_graph.txt, кладем на HDFS и запускаем нашу программу:
hadoop jar ./target/giraph-test-fatjar.jar org.apache.giraph.GiraphRunner \
ru.giraph.test.org.ComputeDegree \
-vif org.apache.giraph.io.formats.IntIntNullTextVertexInputFormat \
-vip example_graph.txt \
-vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat \
-op degrees \
-w 1
Смотрим результат:
hdfs dfs -text degrees/*
И видим примерно такой ответ:
0 3
2 2
1 2
3 1
Итак, в данной статье мы научились компилировать Giraph и написали свое маленькое приложение. А весь проект можно скачать тут.
В следующей статье поговорим о работе с Giraph на примере алгоритма обучения Restricted Boltzmann Machine. Мы попытаемся максимально ускорить алгоритм, чтобы понять тонкости настройки Giraph и оценить, насколько эта система удобна/производительна/стабильна.
