

Sherlock by ThatsWhatSheSayd
Чтобы стать великим сыщиком, Шерлоку Холмсу было достаточно замечать то, чего не видели остальные, в вещах, которые находились у всех на виду. Мне кажется, что этим качеством должен обладать и каждый специалист по машинному обучению. Но тема Feature Engineering’а зачастую изучается в курсах по машинному обучению и анализу данных вскользь. В этом материале я хочу поделиться своим опытом обработки признаков с начинающими датасаентистами. Надеюсь, это поможет им быстрее достичь успеха в решении первых задач. Оговорюсь сразу, что в рамках этой части будут рассмотрены концептуальные методы обработки. Практическую часть по этому материалу совсем скоро опубликует моя коллега Osina_Anya.
Один из популярных источников данных для машинного обучения — логи. Практически в любой строчке лога есть время, а если это web-сервис, то там будут IP и UserAgent. Рассмотрим, какие признаки можно извлечь из этих данных.
Время
UnixTimestamp
UnixTimestamp — это количество секунд, прошедшее с 1970-01-01 00:00:00.000, популярное представление времени, натуральное число. Можно в модель добавить время в этом формате, но такой подход чаще работает в задачах регрессии. В задачах классификации он работает редко, так как в UnixTimestamp-формате сохраняется только информация о последовательности событий, а о днях недели, месяцах, часах и т. д. модель ничего знать не будет.
Год, месяц, день, часы, минуты, секунды, день недели
Часто время добавляют в модель в виде набора натуральных чисел: отдельно год, отдельно номер месяца и т. д. до нужной детализации. Например, 2017-09-08 12:07:12.997 можно преобразовать в пять признаков: 2017, 09, 08, 12, 07. Ещё можно добавить бинарный признак: выходной день или нет, время года, рабочее время или нет — и т. д., и т. п. Удачный набор таких признаков чаще всего позволяет решить задачу c высоким качеством. Иногда работает метод Создание OneHotEncoding признаков на месяцы/годы, но это скорее экзотика, нежели практика.
Отображение на круг
Представления времени в качестве набора отдельных компонентов часто достаточно, но оно имеет одну слабую сторону и может требовать добавления дополнительных признаков.
Допустим, у нас есть задача: по текущему времени определить, зачем человек взял в руки мобильный телефон — отключить звук или поставить будильник. При этом мы видим по историческим данным, что человек ставит будильник с 23.00 до 01.00, а выключает звук с 07.00 до 21.00. Если мы станем решать задачу логистической регрессией, то ей надо будет построить разделяющую плоскость для следующей картинки:

Очевидно, что она не сможет этого сделать: такое представление времени теряет информацию о том, что 23.00 и 01.00 — это очень близкие события. В данном случае можно добавить квадратичные признаки, но у меня есть способ получше! Для решения таких проблем пригодится следующий приём: берём признак, о котором мы знаем, что он меняется по циклу. Например, «час» — он меняется от 0 до 23. И превращаем его в два признака: cos(«час» 2 pi / 24 ), sin(«час» 2 pi / 24 ), т. е. мы равномерно распределили все элементы цикла по единичной окружности с центром в 0 и диаметром 1.
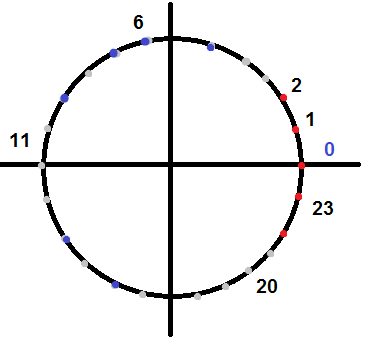
Для такого множества точек логистическая регрессия с лёгкостью найдёт разделяющую плоскость и поможет человеку поставить будильник. Аналогично можно поступать с днями недели, месяца, циклами работы поршня и т. д. Теоретически этот метод можно проинтерполировать и на более сложные периодические функции с помощью разложения в ряд Фурье, но я с такими случаями не сталкивался.
IP-адрес
Немного слов об IP
На первый взгляд IP-адрес — важный признак, но что с ним делать — совершенно непонятно. Наиболее распространённый сейчас вариант — это IPV4, т. е. последовательность из 4 байтов, традиционно записываемых в виде «255.0.0.1». Работать с этими числами или со всем IP как с числовыми признаками абсолютно некорректно. Если у вас есть два IP-адреса — 123.123.123.123 и 124.123.123.123, — то близость этих чисел совершенно ничего не значит (первый — это China Unicom Beijing province network, второй — Beam Telecom Pvt Ltd). Корректно было бы рассматривать IP как категориальный с выделением подсетей, но у больших сервисов таких категорий очень много. Например, если рассматривать категории по подсетям третьего уровня, то их получается 2^24 — ~10^16. Чтобы обучить модель более чем с 16 миллионами признаков, нужно действительно много данных, и, скорее всего, они создадут ненужный шум.

Геолокация
На самом деле из IP достаётся гораздо больше информации, чем просто разбиение по сетям. Так, из IP-адреса с хорошей точностью извлекается страна, регион, а иногда даже город, в котором находился пользователь сервиса. Для этого можно использовать:
- Открытые GeoIP-базы, которых сейчас в избытке, многие из них предоставляют бесплатное API. Главное — не слишком их нагружать (не более 100—1000 запросов в минуту). Если вам нужны большие объёмы данных, то можно купить регулярно обновляемые базы у таких компаний, как MindMax.
- Сервис WhoIs, где опубликована публичная информация о владельцах многих IP-адресов (в случае обычных пользователей — об их провайдерах). Для получения этих данных можно воспользоваться одним из WhoIs-сервисов, например https://www.nic.ru/whois/, или Python-пакетом. Например, сейчас у моего мобильного телефона IP-адрес 176.59.41.95. Сервис WhoIs показывает, что IP принадлежит российскому Tele2. Можно проделать такую же операцию с любым IP и узнать его страну, но количество информации, предоставляемой о владельце IP-адреса, отличается от случая к случаю. Кроме того, не стоит забывать, что есть особые IP-адреса, о них можно почитать тут.
Внимательно обходитесь с данными, полученными об IP из подобных сервисов. Данные иногда устаревают, иногда бывают ошибочны, а IP-адреса мобильных операторов связи — вообще большая проблема, так как нередко вы можете через одного оператора с одним и тем же IP выйти как из Москвы, так и из Владивостока. Поэтому я рекомендую формировать эти дополнительные поля к логу в момент его получения, а не позже, в момент сбора признаков, так как у вас уже может не быть версии базы на тот момент, как случилось описанное в логе событие. Плюс подхода: вы сможете отследить тот факт, что какой-то IP, встречавшийся в России, перешёл в Европу, или наоборот. Но даже с этими оговорками данная функция очень полезна для анализа данных и способна значительно повысить качество модели.
Постскриптум для этого пункта
Если ваш сервис достаточно большой, то вы можете сами собирать GeoIP-базы. Если пользователь предоставит вашему сайту/приложению доступ к своей геолокации, то вы автоматически получите информацию о расположении конкретных IP-адресов. Только вам придётся придумать, как быть с некорректными геолокациями и IP-адресами, которые имеют широкую географию. Кроме того, пользуясь этим приёмом, можно предполагать, откуда заходил пользователь: из дома, с работы, находясь в дороге.
Чистота IP-адреса
Для анализа данных иногда стоит отфильтровывать действия настоящих пользователей от действий ботов, поисковых роботов и подобной «нечисти». В исходной формулировке эта задача очень сложная, используемая во многих областях, например антиспаме и антифроде. Но для задачи фильтрации данных иногда хватает и более простых методов — фильтрации по IP. Так, в интернете можно найти открытые списки IP-адресов, с которых часто проводятся фрод- и ддос-атаки, IP-адреса tor-exitnode (боты часто используют их для обхода блокировки IP за частые запросы к сервису) и IP-адреса открытых прокси-серверов (иногда применяются для тех же целей). Так, можно добавить в вектор признаков флаг «наличие IP-адреса в этих базах». Кроме того, по историческим данным вы можете считать вероятность встретить такого же провайдера, что и у IP-адреса в данной строке лога. Эта вероятность тоже может быть признаком, только у него есть гиперпараметр: как далеко смотреть историю, чтобы считать вероятность. Это важно, так как распределение пользователей и, как следствие, распределение провайдеров пользователей на сервисе меняется.
Возвращаясь к вопросу фильтрации «плохих» пользователей, отмечу: стандартная практика — фильтрация логов с IP-адресов, фигурировавших в доверенных чёрных списках. При этом пользователи, их инициировавшие, не принадлежат к списку пользователей, недавно совершавших доверенные действия. Оба этих условия одинаково важны, так как даже хорошие пользователи иногда обращаются к Tor’у и прокси-серверам, но аккаунт хорошего пользователя может быть взломан. Поэтому действие, характеризующее его как настоящего человека, должно произойти недавно.
UserAgent
Немного о UserAgent
Если мы говорим об HTTP-протоколе, то программное обеспечение, которое отправляет запрос на ваш сервер, в заголовке запроса передаёт поле User-Agent, в котором содержится информация о версии программного обеспечения и операционной системы. С помощью этого поля заголовка часто происходит перенаправление на мобильную версию сайта или на версию сайта без использования JS. Кроме версии браузера и операционной системы, в UserAgent может содержаться и другая полезная информация, но её иногда непросто достать. Дело в том, что единого утверждённого формата для строки User-Agent’а нет, и каждый пишет туда информацию так, как захочет. Есть много различных библиотек, позволяющих извлечь из строки UserAgent браузер и операционную систему, и их можно выбирать на свой вкус. Лично мне нравится https://github.com/ua-parser.
ОС, ПО, что сложного?
Браузер и операционную систему можно добавить как категориальный признак, воспользовавшись OneHotEncoding, даже тип устройства достаётся. Только для этого нужно аккуратно смотреть и на браузер, и на операционную систему. Но в UserAgent ещё можно опознать поисковых ботов, скрипты на Python, программы и кастомные сборки браузеров, использующие WebKit. Только с этим многообразием возможностей приходит и многообразие проблем. Записать в UserAgent-строку можно всё что угодно, и этим пользуются разработчики вредоносного ПО: для вашего сервера всё будет выглядеть так, будто к вам пришёл обычный пользователь с браузером Chrome и Windows 10 на компьютере. Поэтому надо относиться очень аккуратно к данным из UserAgent и следить за аномалиями в статистике версий браузеров. В ней вы можете заметить, что очень старая версия хрома гораздо популярней последней, или увидеть «вспышки» из старых андроидов. Кроме того, поможет частотный анализ, как и в случае с IP. Чаще всего разработчики роботов не знают распределения браузеров у вашей целевой аудитории и берут UserAgent из своих баз данных о распределении UserAgent среди пользователей интернета, а базы могут устаревать, не соответствовать географии, целевой аудитории вашего сервиса и т. д. Но все эти трудности — не повод не пользоваться этими данными. Это повод посмотреть на них внимательнее и извлечь ещё больше полезной информации.
Заключение
Подготовка признаков — важный этап в анализе данных. Часто начинающие датасаентисты начинают перебирать сложные модели, строить многослойные нейронные сети, делать ансамбли различных алгоритмов в тех случаях, когда можно решить задачу, аккуратно добавив хорошие признаки в логистическую регрессию. Я рассказал о кое-каких данных, которые редко рассматриваются в учебных курсах, но часто встречаются в реальной работе. Надеюсь, что информация была вам полезной.
Спасибо за внимание — и удачи!
