
Привет! Сейчас будет дежавю.
Мы снова выложили на GitHub наш PHP-компилятор — KPHP. Он проделал большой путь, и чтобы рассказать о нём, сначала телепортируемся на шесть лет назад.
Поясню для тех, кто не в теме: платформа ВКонтакте изначально была написана на PHP. Со временем нас перестала устраивать производительность, и мы решили ускорить VK. Сделали компилятор — KPHP, который поддерживал узкое подмножество PHP. Это было давно, и с тех пор мы о нём не рассказывали, так как KPHP почти не развивался до 2018-го года.
Но два года назад мы взялись за него, чтобы вдохнуть в эту разработку новую жизнь. Что сделали и какой получили результат — расскажу в этой статье. Она будет не о громком релизе, который можно прямо сейчас внедрять в свои проекты, а о внутренней разработке ВКонтакте, которую мы показываем сообществу и продолжаем развивать. Представлюсь: меня зовут Александр Кирсанов, я руковожу командой Backend-оптимизаций.
А теперь — телепортация.

Идёт 2014 год, и ВКонтакте опенсорсит репозиторий kphp-kdb. Наверняка многие из вас помнят этот момент.
Там было много движков от VK, а также первая версия KPHP. Тогда многие заинтересовались и пошли смотреть, но… Но. На тот момент там не было подробной инструкции по сборке, а также документации и сравнения с аналогами. Не было канала связи с разработчиками и поддержкой. Дальнейших апдейтов на GitHub также не случилось. И всё равно некоторые энтузиасты пробовали пользоваться этими инструментами — возможно, кому-то даже удалось, но доподлинно не известно.
Что касается KPHP — на тот момент он поддерживал версию PHP… даже не знаю. Что-то среднее между 4 и 5. Были функции, примитивы, строки и массивы. Но не было классов и ООП, не было современных (на момент 2014-го) паттернов разработки. И весь бэкенд-код ВКонтакте был написан в процедурном стиле, на ассоциативных массивах.
В общем, инфоповод был интересным, но во что-то большее не развился.
Сейчас, в конце 2020 года, весь бэкенд-код ВКонтакте по-прежнему на PHP. Пара сотен разработчиков, миллионы строк.
Но наш нынешний PHP-код мало чем отличается от актуального в индустрии. Мы пишем на современном PHP: у нас есть классы, интерфейсы и наследование; есть лямбды, трейты и Composer; а ещё строгая типизация, анализ PHPDoc и интеграция с IDE. И KPHP делает всё это быстрым.
В 2014 году в техническую команду пришли новые люди, которые начали заниматься движками. (Да, ВКонтакте до сих пор десятки собственных закрытых движков, хотя точечно мы используем ClickHouse и другие известные.) Но KPHP долго никто не трогал. До 2018-го бэкенд-код действительно был на уровне PHP 4.5, а IDE плохо понимала код и почти не подсказывала при рефакторинге.
В середине 2018 года мы возродили работу над KPHP — и за пару сумасшедших лет не только подтянули его к современным стандартам, но и добавили фичи, которых нет и не может быть в PHP. Благодаря этому провели ряд ключевых оптимизаций бэкенда, и это позволило продуктовым командам интенсивно наращивать функциональность. Да, тем самым снова замедляя бэкенд.
И сейчас мы решились на второй дубль: готовы поделиться инструментами, которые помогают нам в работе. Какими именно и что о них стоит знать — расскажу далее.
KPHP берёт PHP-код и превращает его в С++, а уже этот С++ потом компилирует.
Эта часть — техническая, она большая. Мы заглянем внутрь и увидим, что происходит с PHP-кодом: как из него получается С++ и что следует за этим. Не слишком кратко, чтобы обозначить базовые вещи, но и не чересчур детально — в дебри не полезем.
В PHP любая переменная — это
Если бы KPHP пошёл по такому пути, он бы не смог стать быстрым. Залог скорости — прежде всего в типизации. KPHP заставляет думать о типах, даже когда вы их явно не указываете.
В PHP мы не пишем типы переменных (за исключением редких type hint для аргументов) — поэтому KPHP сам выводит типы. То есть придумывает, как бы объявить переменную в C++, чтобы это было лучше.
Давайте посмотрим сниппеты на примерах.
Пример:
Тут KPHP понял, что
Ещё пример:
Казалось бы, просто изменили умножение на деление — но уже другое. Деление в PHP работает не так, как в C++.
Следующий пример:
KPHP проанализировал все вызовы функции
Дальше:
Здесь KPHP понял, что
Ещё пример:
В этом массиве (в хеш-таблице) мы смешиваем числа и строки. В KPHP есть специальный тип
Например,
И последний пример:
А здесь мы получим Compilation error. Потому что нельзя вызывать функции по имени — нельзя и всё. Нельзя обращаться по имени к переменным, к свойствам класса — KPHP напишет ошибку, несмотря на то что это работает в PHP.
Выше мы видели: когда разработчик типы не пишет, они выводятся автоматом.
Но их можно писать — с помощью PHPDoc
Пример:
Ещё пример:
Ручной контроль позволяет избегать непреднамеренных ухудшений типов. Без
Если в обычном PHP классы — это более-менее те же хеш-таблицы, то в KPHP не так. На выходе получаются обычные плюсовые структуры, которые ведут себя ссылочно, как и в PHP (очень похоже на
Каждое поле получается своего типа. Обращение к полю — это обращение к типизированному свойству с известным на момент компиляции смещением в памяти. Это в десятки раз эффективнее, чем хеш-таблицы, — как по скорости, так и по памяти.
Наследование — плюсовое (за исключением late static binding, но оно разруливается на этапе компиляции). Интерфейсы — это тоже плюсовое множественное наследование, там главное — refcount запрятать куда нужно. Правда, методы классов — это отдельные функции, принимающие
Это же значит, что у KPHP-классов много ограничений. Например, нельзя обращаться к полям по имени или вызывать так методы. Нет и не может быть магических методов. Классы совсем никак не стыкуются с
В общем, когда разработчики пишут код, они всегда думают о типах и об их сходимости. Глупо ожидать, что напишешь фигню, а она заработает. Если ты следуешь ограничениям, получаешь скорость — иначе не бывает.
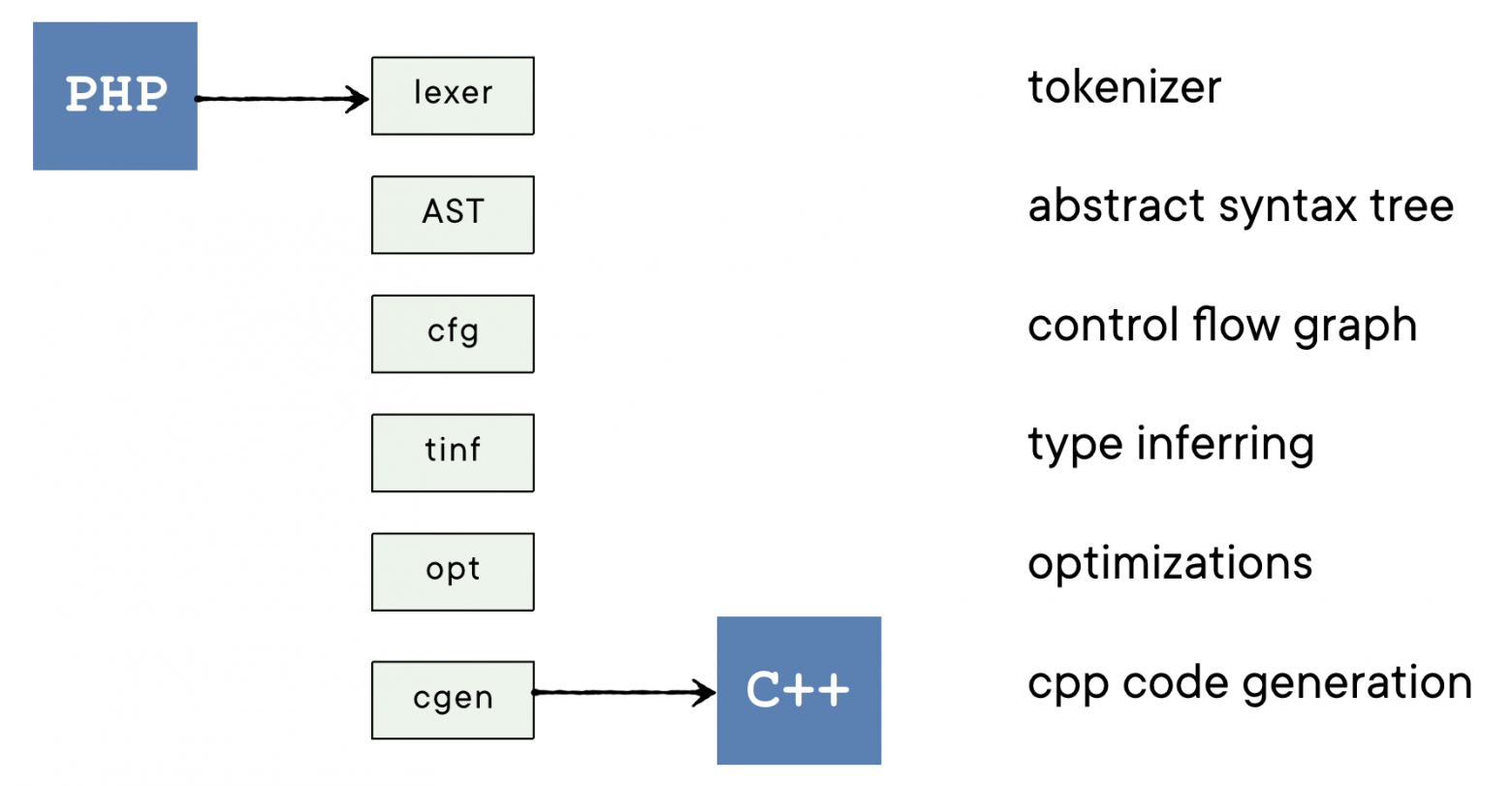
Многие знакомы с этой терминологией — те, кто занимался языками, или компиляторами, или статическим анализом.
Сначала PHP-файл превращается в линейный список токенов. Это такие минимальные неразрывные лексемы языка.
Потом линейный набор токенов превращается в синтаксическое дерево (abstract syntax tree). Оно согласовано с приоритетами операций и соответствует семантике языка. После этого этапа есть AST для всех достижимых функций.
Далее выстраивается control flow graph — это связывание функций и получение высокоуровневой информации о том, откуда и куда может доходить управление. Например, try/catch и if/else синтаксически похожи, но изнутри try можно добраться до внутренностей catch, а из if до тела else — нет. На выходе получается информация о соответствии вершин и переменных, какие из них используются на чтение, а какие на запись, и тому подобное.
Потом происходит type inferring. Это тот магический вывод типов, который ставит в соответствие всем PHP-переменным — переменные С++ с явно проставленными типами, а также определяет возвращаемые значения функций, поля классов и другое. Этот этап согласуется с тем, как код впоследствии будет исполняться на С++, какие там есть функции-хелперы, их перегрузки и прочее.
Имея типы, можно провести ряд оптимизаций времени компиляции. Например, заранее вынести константы, безопасно заинлайнить простые функции, а нетривиальные аргументы только для чтения передавать по const-ссылке, чтобы не вызывать конструктор копирования и не флапать рефкаунтер лишний раз.
И наконец, кодогенерация: все PHP-функции превращаются в С++ функции, а PHP-классы — в С++ структуры. Изменённые файлы и их зависимости перезаписываются, и код проекта на С++ готов.
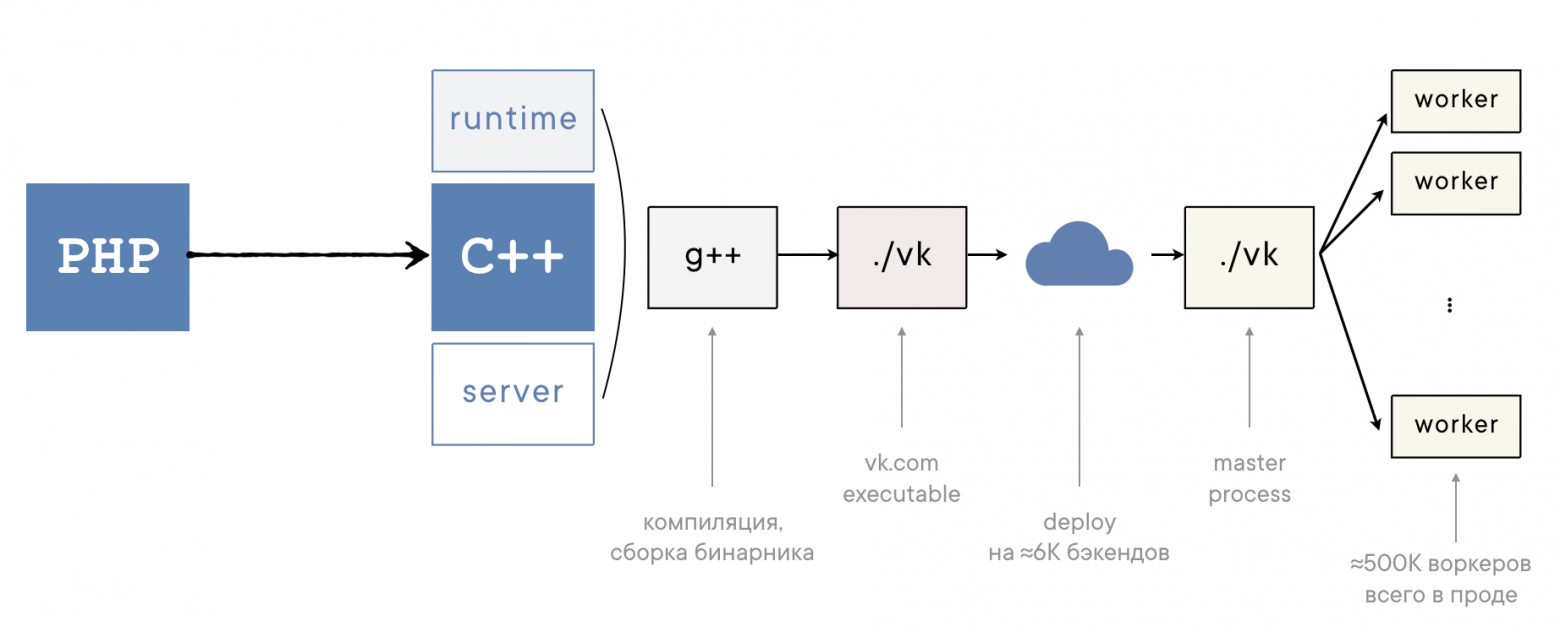
Сгенерировать С++ из PHP — этого мало. Собственно говоря, это самое простое.
Во-первых, в PHP мы используем кучу функций стандартной библиотеки:
Во-вторых, PHP-сайт — это веб-сервер. Следовательно, и в KPHP должна быть вся серверная часть, чтобы можно было в том же nginx подменить PHP-шный upstream на KPHP-шный — и всё продолжало работать так же. KPHP поднимает свой веб-сервер, оркестрирует процессы, заполняет суперглобалы и переинициализирует состояние, как и PHP… Это тоже хардкорная часть — называется server, квадратик снизу.
И только имея результирующий код C++, написанные runtime и server, всё это можно объединить и отдать на откуп плюсовым компиляторам. Мы используем g++ — там в диаграмме есть квадратик
Многие технические проблемы остаются за кадром — их не опишешь в статье на Хабре. Чего стоит один только сбор трейсов при ошибках: ведь в С++ не получить человекочитаемый стек, а хочется разработчику вообще его на PHP-код намаппить. Гигантское количество внутренних нюансов, множество подпорок и легаси — но в итоге продукт хорошо работает и развивается.
По итогам предыдущей части статьи должно было сложиться чёткое понимание: KPHP не может взять любой PHP-код и ускорить его. Так не работает.
В скорости. Если использовать KPHP грамотно, то код будет работать значительно быстрее, чем на PHP 7.4. А некоторых вещей нет в PHP — и чтобы при разработке он не падал с ошибками, там просто заглушки.
Итак, в чём наш профит:
Отдельно чуть-чуть расскажу про асинхронность. Это чем-то похоже на async/await в других языках, а чем-то — на горутины. KPHP-воркеры однопоточные, но умеют свитчиться между ветками исполнения: когда одна ветка ждёт ответ от движка, вторая выполняет свою работу, и когда первая дождалась — управление снова переключается туда.
Например, нам нужно загрузить пользователя и одновременно посчитать какую-то подпись запроса (CPU-работа — допустим, это долго). В обычном (синхронном) варианте это выглядит так:
Но эти действия независимы — пока грузится пользователь, можно считать хеш, а потом дождаться загрузки. В асинхронном варианте это происходит так:
То есть отличие от паттерна async/await в том, что мы никак не меняем сигнатуру функции
В итоге: с одной стороны, мы следим за типами. С другой, можем делать запросы к движкам параллельно. С третьей, zero-cost abstractions (плохой термин, но пусть) — константы напрямую инлайнятся, всякие простые геттеры и сеттеры тоже, и оверхед от абстракций в разы меньше, чем в PHP.
Если говорить про бенчмарки, то на средних VK-страничках у нас профит от 3 до 10 раз. А на конкретных участках, где мы прицельно выжимали максимум, — до 20–50 раз.
Это не значит, что можно просто взять PHP-код и он будет работать в 10 раз быстрее. Нет: рандомный сниппет, даже будучи скомпилированным, может и не впечатлить, потому что чаще всего там навыводится
Это значит, что PHP-код можно превратить в быстрый, если думать о типах и использовать built-in KPHP-функции.
Система типов в KPHP значительно шире и строже, чем в PHP. Мы уже говорили, что нельзя смешивать в массиве числа и объекты — потому что какой тогда тип элементов этого массива?
Нельзя! А как можно? Например, сделать отдельный класс с двумя полями и вернуть его. Или вернуть кортеж (tuple) — специальный KPHP-тип.
К функции можно даже PHPDoc написать, KPHP его прочитает и после стрелочки (->) поймёт:
Но вот проблема: KPHP-то понимает, а вот IDE нет. Ведь
Не так давно у нас появился KPHPStorm — плагин для PhpStorm, который расширяет подсказки, оставляя рабочим рефакторинг. А ещё сам трекает сходимость типов значительно строже нативного.
Если вы интересуетесь разработкой плагинов для IDEA — загляните, все исходники открыты. KPHPStorm глубоко внедряется во внутренности IDE (через кучу недокументированного API). Многое пришлось пройти, чтобы всё заработало. Спасибо ребятам из JetBrains за помощь.
Мы усовершенствовали KPHP и показываем его вам: можно посмотреть, покомпилировать что-то простое — теперь есть все инструкции и даже Docker-образ. Но будем честны: KPHP пока остаётся инструментом, заточенным под задачи VK, и для более широкого применения в реальных сторонних проектах он ещё не адаптирован.
Почему так? Мы всегда поддерживали в первую очередь собственные движки ВКонтакте. KPHP не умеет в Redis, MongoDB и другое. Даже Memcache у нас свой, который по RPC работает. Даже перед ClickHouse, который у нас развёрнут, стоит собственная proxy, куда мы тоже ходим по TL/RPC.
Мы никогда не поддерживали стандартные базы, потому что это не было нужно. Но знаете, в чём прикол? Если мы не выйдем в Open Source, этого никогда и не произойдёт — потому что это так и не потребуется. За последние два года KPHP прошёл огромный путь, возродился. Мы можем ещё пару лет продержать его у себя. Можем покрыть возможности PHP 8, сделать ещё ряд оптимизаций, освоить микросервисы и интеграцию с Kubernetes — но нам не будут нужны стандартные базы. И через два года будет то же самое.
Только открытость и внешняя заинтересованность помогут выделить дополнительные ресурсы, чтобы пилить фичи не только для нас, но и наружу. Может, уже среди читателей этой статьи найдутся те, кому интересно с нами развивать это направление? Почему нет — у нас очень маленькая команда, и мы занимаемся интересными, глубокими и совершенно не продуктовыми вещами.
Теперь вся разработка KPHP будет вестись на GitHub. Правда, CI пока останется в приватной инфраструктуре. Движки по-прежнему будут закрыты — но когда-нибудь команда движков, надеемся, тоже решится вынести в сообщество хотя бы часть кода.
У вас может возникнуть вопрос: а сложно ли добавить поддержку протоколов MySQL, Redis и других? И да и нет. Если пробовать интегрировать готовые модули — скорее всего, будет фейл. Особенно если они порождают дополнительные потоки, ведь воркеры принципиально однопоточные. К тому же, просто поддержать протокол, может, и не проблема — но сложно сделать его «прерываемым», чтобы это стыковалось с корутинами. А вот к этому сейчас код совершенно не готов: там корутины тесно переплетены с сетью и TL. Непростая история, в общем :) Но выполнимая, и над этим надо работать.
GitHub
Документация
FAQ
Мы рассчитываем, что в дальнейшем нашей команде — возможно, при помощи сообщества — удастся развить KPHP так, чтобы он стал полезным инструментом и вне ВКонтакте. Не так важно, как быстро это произойдёт. В любом случае, это тот ориентир, который теперь стоит перед проектом.
Мы снова выложили на GitHub наш PHP-компилятор — KPHP. Он проделал большой путь, и чтобы рассказать о нём, сначала телепортируемся на шесть лет назад.
Поясню для тех, кто не в теме: платформа ВКонтакте изначально была написана на PHP. Со временем нас перестала устраивать производительность, и мы решили ускорить VK. Сделали компилятор — KPHP, который поддерживал узкое подмножество PHP. Это было давно, и с тех пор мы о нём не рассказывали, так как KPHP почти не развивался до 2018-го года.
Но два года назад мы взялись за него, чтобы вдохнуть в эту разработку новую жизнь. Что сделали и какой получили результат — расскажу в этой статье. Она будет не о громком релизе, который можно прямо сейчас внедрять в свои проекты, а о внутренней разработке ВКонтакте, которую мы показываем сообществу и продолжаем развивать. Представлюсь: меня зовут Александр Кирсанов, я руковожу командой Backend-оптимизаций.
А теперь — телепортация.
Из 2020-го в 2014-й
Идёт 2014 год, и ВКонтакте опенсорсит репозиторий kphp-kdb. Наверняка многие из вас помнят этот момент.
Там было много движков от VK, а также первая версия KPHP. Тогда многие заинтересовались и пошли смотреть, но… Но. На тот момент там не было подробной инструкции по сборке, а также документации и сравнения с аналогами. Не было канала связи с разработчиками и поддержкой. Дальнейших апдейтов на GitHub также не случилось. И всё равно некоторые энтузиасты пробовали пользоваться этими инструментами — возможно, кому-то даже удалось, но доподлинно не известно.
Что касается KPHP — на тот момент он поддерживал версию PHP… даже не знаю. Что-то среднее между 4 и 5. Были функции, примитивы, строки и массивы. Но не было классов и ООП, не было современных (на момент 2014-го) паттернов разработки. И весь бэкенд-код ВКонтакте был написан в процедурном стиле, на ассоциативных массивах.
В общем, инфоповод был интересным, но во что-то большее не развился.
Из 2014-го в 2020-й
Сейчас, в конце 2020 года, весь бэкенд-код ВКонтакте по-прежнему на PHP. Пара сотен разработчиков, миллионы строк.
Но наш нынешний PHP-код мало чем отличается от актуального в индустрии. Мы пишем на современном PHP: у нас есть классы, интерфейсы и наследование; есть лямбды, трейты и Composer; а ещё строгая типизация, анализ PHPDoc и интеграция с IDE. И KPHP делает всё это быстрым.
В 2014 году в техническую команду пришли новые люди, которые начали заниматься движками. (Да, ВКонтакте до сих пор десятки собственных закрытых движков, хотя точечно мы используем ClickHouse и другие известные.) Но KPHP долго никто не трогал. До 2018-го бэкенд-код действительно был на уровне PHP 4.5, а IDE плохо понимала код и почти не подсказывала при рефакторинге.
В середине 2018 года мы возродили работу над KPHP — и за пару сумасшедших лет не только подтянули его к современным стандартам, но и добавили фичи, которых нет и не может быть в PHP. Благодаря этому провели ряд ключевых оптимизаций бэкенда, и это позволило продуктовым командам интенсивно наращивать функциональность. Да, тем самым снова замедляя бэкенд.
И сейчас мы решились на второй дубль: готовы поделиться инструментами, которые помогают нам в работе. Какими именно и что о них стоит знать — расскажу далее.
Давайте про KPHP: что это и как работает
KPHP берёт PHP-код и превращает его в С++, а уже этот С++ потом компилирует.
Эта часть — техническая, она большая. Мы заглянем внутрь и увидим, что происходит с PHP-кодом: как из него получается С++ и что следует за этим. Не слишком кратко, чтобы обозначить базовые вещи, но и не чересчур детально — в дебри не полезем.
KPHP выводит типы переменных
В PHP любая переменная — это
ZVAL, то есть «что угодно». В переменную можно записать число, объект, замыкание; в хеш-таблицу — добавить одновременно числа и объекты; а в функцию — передать любое значение, а потом это разрулить в рантайме.Если бы KPHP пошёл по такому пути, он бы не смог стать быстрым. Залог скорости — прежде всего в типизации. KPHP заставляет думать о типах, даже когда вы их явно не указываете.
В PHP мы не пишем типы переменных (за исключением редких type hint для аргументов) — поэтому KPHP сам выводит типы. То есть придумывает, как бы объявить переменную в C++, чтобы это было лучше.
Давайте посмотрим сниппеты на примерах.
Пример:
// PHP
$a = 8 * 9;
// C++
int64_t v$a = 0;
v$a = 8 * 9;
Тут KPHP понял, что
$a — это целое число, то есть int64_t в C++, и сгенерил такой код.Ещё пример:
// PHP
$a = 8 / 9;
// C++
double v$a = 0;
v$a = divide(8, 9);
Казалось бы, просто изменили умножение на деление — но уже другое. Деление в PHP работает не так, как в C++.
8/9 в С++ будет целочисленный 0, поэтому есть функция divide() с разными перегрузками. В частности, для двух интов она выполняет сначала каст к double.Следующий пример:
// PHP
function demo($val) { ... }
// в других местах кода
demo(1);
demo(10.5);
// C++
void f$demo(double v$val) { … }
KPHP проанализировал все вызовы функции
demo() и увидел, что она вызывается только с целыми и дробными числами. Значит, её аргумент — это double. Перегрузки нет в PHP, нет её и в KPHP (и не может быть, пока типы выводятся, а не указываются явно). Кстати, если внутри demo() будет вызов is_int($val), то на аргументе 1 это будет true в PHP, но false в KPHP, так как 1 скастится к 1.0. Ну и ладно, просто не надо так писать. Во многих случаях, если KPHP видит, что поведение может отличаться, выдаёт ошибку компиляции.Дальше:
// PHP
$a = [1];
$a[] = 2;
// C++
array < int64_t > v$a;
v$a = v$const_array$us82309jfd;
v$a.push_back(2);
Здесь KPHP понял, что
$a — это массив и в нём могут быть только целые числа. Значит, array<int64_t>. В данном случае array<T> — это кастомная реализация PHP-массивов, которая ведёт себя идентично. В PHP массивы могут быть и векторами, и хеш-таблицами. Они передаются по значению, но для экономии используют copy-on-write. Индексация числами и числовыми строками — это (почти) одно и то же. Всё это в KPHP реализовано похожим образом, чтобы работало одинаково.Ещё пример:
// PHP
$group = [
'id' => 5,
'name' => "Code mode"
];
// C++
array < mixed > v$group;
v$group = v$const_array$usk6r3l12e;
В этом массиве (в хеш-таблице) мы смешиваем числа и строки. В KPHP есть специальный тип
mixed, обозначающий «какой-нибудь примитив». Это напоминает ZVAL в PHP, однако mixed — это всего лишь 16 байт (enum type + char[8] storage). В mixed можно сложить числа и строки, но нельзя — объекты и более сложные типы. В общем, это не ZVAL, а что-то промежуточное. Например,
json_decode($arg, true) возвращает mixed, так как значение неизвестно на этапе компиляции. Или даже microtime() возвращает mixed, потому что microtime(true) — это float, а microtime(false) — массив (и кто это только придумал?..).И последний пример:
// PHP
$func_name = 'action_' . $_GET['act'];
call_user_func($func_name);
А здесь мы получим Compilation error. Потому что нельзя вызывать функции по имени — нельзя и всё. Нельзя обращаться по имени к переменным, к свойствам класса — KPHP напишет ошибку, несмотря на то что это работает в PHP.
KPHP хоть и выводит типы, но позволяет их контролировать
Выше мы видели: когда разработчик типы не пишет, они выводятся автоматом.
Но их можно писать — с помощью PHPDoc
@var/@param/@return или через PHP 7 type hint. Тогда KPHP сначала всё выведет, а потом проверит.Пример:
/** @param int[] $arr */
function demo(int $x, array $arr) { ... }
demo('234', []); // ошибка в 1-м аргументе
demo(234, [3.5]); // ошибка во 2-м аргументе
Ещё пример:
/** @var int[] */
$ids = [1,2,3];
/* ... */
// ошибка, если $group — это mixed[] из примера выше
$ids[] = $group['id'];
// а вот так ок
$ids[] = (int)$group['id'];
Ручной контроль позволяет избегать непреднамеренных ухудшений типов. Без
@var переменная $ids вывелась бы как mixed[], и никто бы этого не заметил. А когда разработчик пишет PHPDoc — значит, всё скомпилированное вывелось так же, как написано.KPHP превращает PHP class в C++ struct
// PHP
class Demo {
/** @var int */
public $a = 20;
/** @var string|false */
protected $name = false;
}
// C++
struct C$Demo : public refcountable_php_classes<C$Demo> {
int64_t v$a{20L};
Optional < string > v$name{false};
const char *get_class() const noexcept;
int get_hash() const noexcept;
};
Если в обычном PHP классы — это более-менее те же хеш-таблицы, то в KPHP не так. На выходе получаются обычные плюсовые структуры, которые ведут себя ссылочно, как и в PHP (очень похоже на
std::shared_ptr идеологически). Каждое поле получается своего типа. Обращение к полю — это обращение к типизированному свойству с известным на момент компиляции смещением в памяти. Это в десятки раз эффективнее, чем хеш-таблицы, — как по скорости, так и по памяти.
Наследование — плюсовое (за исключением late static binding, но оно разруливается на этапе компиляции). Интерфейсы — это тоже плюсовое множественное наследование, там главное — refcount запрятать куда нужно. Правда, методы классов — это отдельные функции, принимающие
this явно, так оно логичнее с нескольких позиций.Это же значит, что у KPHP-классов много ограничений. Например, нельзя обращаться к полям по имени или вызывать так методы. Нет и не может быть магических методов. Классы совсем никак не стыкуются с
mixed. Нельзя из функции вернуть «либо класс, либо массив» — не сойдётся по типам. Нельзя в функцию передать разные классы без общего предка (впрочем, в KPHP есть шаблонные функции, но это уже сложнее). Нельзя в хеш-таблицу сложить одновременно числа, строки и инстансы — нет, иди и делай типизированный класс или используй именованные кортежи.В общем, когда разработчики пишут код, они всегда думают о типах и об их сходимости. Глупо ожидать, что напишешь фигню, а она заработает. Если ты следуешь ограничениям, получаешь скорость — иначе не бывает.
Как конкретно происходит конвертация PHP в C++
Многие знакомы с этой терминологией — те, кто занимался языками, или компиляторами, или статическим анализом.
Сначала PHP-файл превращается в линейный список токенов. Это такие минимальные неразрывные лексемы языка.
Потом линейный набор токенов превращается в синтаксическое дерево (abstract syntax tree). Оно согласовано с приоритетами операций и соответствует семантике языка. После этого этапа есть AST для всех достижимых функций.
Далее выстраивается control flow graph — это связывание функций и получение высокоуровневой информации о том, откуда и куда может доходить управление. Например, try/catch и if/else синтаксически похожи, но изнутри try можно добраться до внутренностей catch, а из if до тела else — нет. На выходе получается информация о соответствии вершин и переменных, какие из них используются на чтение, а какие на запись, и тому подобное.
Потом происходит type inferring. Это тот магический вывод типов, который ставит в соответствие всем PHP-переменным — переменные С++ с явно проставленными типами, а также определяет возвращаемые значения функций, поля классов и другое. Этот этап согласуется с тем, как код впоследствии будет исполняться на С++, какие там есть функции-хелперы, их перегрузки и прочее.
Имея типы, можно провести ряд оптимизаций времени компиляции. Например, заранее вынести константы, безопасно заинлайнить простые функции, а нетривиальные аргументы только для чтения передавать по const-ссылке, чтобы не вызывать конструктор копирования и не флапать рефкаунтер лишний раз.
И наконец, кодогенерация: все PHP-функции превращаются в С++ функции, а PHP-классы — в С++ структуры. Изменённые файлы и их зависимости перезаписываются, и код проекта на С++ готов.
Что дальше происходит с С++ кодом
Сгенерировать С++ из PHP — этого мало. Собственно говоря, это самое простое.
Во-первых, в PHP мы используем кучу функций стандартной библиотеки:
header(), mb_strlen(), curl_init(), array_merge(). Их тысячи — и все должны быть реализованы внутри KPHP с учётом типизации и работать так же, как в PHP. Реализация всего PHP stdlib (а также KPHP-дополнений), всех PHP-типов с операциями и допущениями — это называется runtime, вон там квадратик сверху.Во-вторых, PHP-сайт — это веб-сервер. Следовательно, и в KPHP должна быть вся серверная часть, чтобы можно было в том же nginx подменить PHP-шный upstream на KPHP-шный — и всё продолжало работать так же. KPHP поднимает свой веб-сервер, оркестрирует процессы, заполняет суперглобалы и переинициализирует состояние, как и PHP… Это тоже хардкорная часть — называется server, квадратик снизу.
И только имея результирующий код C++, написанные runtime и server, всё это можно объединить и отдать на откуп плюсовым компиляторам. Мы используем g++ — там в диаграмме есть квадратик
g++. Но не совсем так: у vk.com настолько огромная кодовая база, что этот компилятор не справляется, и поэтому мы применяем патченный distcc для параллельной компиляции на множестве агентов. В итоге всё линкуется в один огромный бинарник (это весь vk.com), он раскидывается на кучу бэкендов и синхронно перезапускается. Каждая копия запускает мастер-процесс, который порождает группу однопоточных воркеров. Вот они на самом деле и исполняют исходный PHP-код.Многие технические проблемы остаются за кадром — их не опишешь в статье на Хабре. Чего стоит один только сбор трейсов при ошибках: ведь в С++ не получить человекочитаемый стек, а хочется разработчику вообще его на PHP-код намаппить. Гигантское количество внутренних нюансов, множество подпорок и легаси — но в итоге продукт хорошо работает и развивается.
KPHP vs PHP: что мы не поддерживаем
По итогам предыдущей части статьи должно было сложиться чёткое понимание: KPHP не может взять любой PHP-код и ускорить его. Так не работает.
Если код работает на PHP — это не значит, что он заработает на KPHP.
KPHP — это отдельный язык, со своими ограничениями и правилами.
- KPHP не компилирует то, что принципиально не компилируемо. Например, выше мы говорили про вызов функции по имени. Туда же — eval, mocks, reflection. PHP extensions тоже не поддерживаются, так как внутренности KPHP пересекаются с Zend API примерно на 0%. Так что PHPUnit запустить на KPHP не выйдет. Но и не нужно! Потому что мы пишем на PHP, мы тестируем на PHP, а KPHP — для продакшена.
- KPHP не компилирует то, что не вписывается в систему типов. Нельзя в массив сложить числа и объекты. Нельзя накидать рандомных интерфейсов с лямбдами и разгрести это в рантайме. В KPHP нет волшебного типа
any. - KPHP не поддерживает то, что нам в VK никогда не было нужно. ВКонтакте куча своих движков — и мы с ними общаемся по специальному протоколу, который описан в TL-схеме. Поэтому нам никогда не нужна была человеческая поддержка MySQL, Postgres, Redis и прочего.
- Часть PHP-синтаксиса просто ещё не покрыта. Текущий уровень поддержки находится примерно на уровне PHP 7.2. Но отдельных синтаксических вещей нет: что-то сделать очень сложно, до другого не дошли руки, а оставшееся мы считаем ненужным. Например, KPHP не поддерживает генераторы и наследование исключений — мы не любим исключения. Ссылки поддержаны только внутри foreach и в аргументах функций. Всё так, потому что мы разрабатывали KPHP как удобный инструмент для наших задач, — а компилировать сторонние библиотеки в планы не входило.
KPHP vs PHP: в чём мы превосходим
В скорости. Если использовать KPHP грамотно, то код будет работать значительно быстрее, чем на PHP 7.4. А некоторых вещей нет в PHP — и чтобы при разработке он не падал с ошибками, там просто заглушки.
Итак, в чём наш профит:
- строгая типизация, примитивы на стеке, а классы — это не хеш-таблицы;
- асинхронность (аналог корутин);
- шаренная память для всех воркеров одновременно, живущая между исполнениями скрипта;
- оптимизации времени компиляции;
- оптимизации времени рантайма, чаще всего при чистых типах.
Отдельно чуть-чуть расскажу про асинхронность. Это чем-то похоже на async/await в других языках, а чем-то — на горутины. KPHP-воркеры однопоточные, но умеют свитчиться между ветками исполнения: когда одна ветка ждёт ответ от движка, вторая выполняет свою работу, и когда первая дождалась — управление снова переключается туда.
Например, нам нужно загрузить пользователя и одновременно посчитать какую-то подпись запроса (CPU-работа — допустим, это долго). В обычном (синхронном) варианте это выглядит так:
$user = loadUser($id);
$hash = calcHash($_GET);
Но эти действия независимы — пока грузится пользователь, можно считать хеш, а потом дождаться загрузки. В асинхронном варианте это происходит так:
$user_future = fork(loadUser($id));
$hash = calcHash($_GET);
$user = wait($user_future);
То есть отличие от паттерна async/await в том, что мы никак не меняем сигнатуру функции
loadUser() и всех вложенных. Просто вызываем функцию через конструкцию fork(), и она становится прерываемой. Возвращается future<T>, и потом можно подождать результат через wait(). При этом в PHP отдельно реализованы PHP-функции fork и wait, которые почти ничего не делают.В итоге: с одной стороны, мы следим за типами. С другой, можем делать запросы к движкам параллельно. С третьей, zero-cost abstractions (плохой термин, но пусть) — константы напрямую инлайнятся, всякие простые геттеры и сеттеры тоже, и оверхед от абстракций в разы меньше, чем в PHP.
Если говорить про бенчмарки, то на средних VK-страничках у нас профит от 3 до 10 раз. А на конкретных участках, где мы прицельно выжимали максимум, — до 20–50 раз.
Это не значит, что можно просто взять PHP-код и он будет работать в 10 раз быстрее. Нет: рандомный сниппет, даже будучи скомпилированным, может и не впечатлить, потому что чаще всего там навыводится
mixed.Это значит, что PHP-код можно превратить в быстрый, если думать о типах и использовать built-in KPHP-функции.
KPHP и IDE
Система типов в KPHP значительно шире и строже, чем в PHP. Мы уже говорили, что нельзя смешивать в массиве числа и объекты — потому что какой тогда тип элементов этого массива?
function getTotalAndFirst() {
// пусть $total_count это int, $user это объект User
...
return [$total_count, $user]; // нельзя
}
Нельзя! А как можно? Например, сделать отдельный класс с двумя полями и вернуть его. Или вернуть кортеж (tuple) — специальный KPHP-тип.
function getTotalAndFirst() {
...
return tuple($total_count, $user); // ok
}
К функции можно даже PHPDoc написать, KPHP его прочитает и после стрелочки (->) поймёт:
/** @return tuple(int, User) */
function getTotalAndFirst() { ... }
[$n, $u] = getTotalAndFirst();
$u->id; // ok
Но вот проблема: KPHP-то понимает, а вот IDE нет. Ведь
tuple — это наша придумка, как и разные другие штуки внутри PHPDoc. Не так давно у нас появился KPHPStorm — плагин для PhpStorm, который расширяет подсказки, оставляя рабочим рефакторинг. А ещё сам трекает сходимость типов значительно строже нативного.
Если вы интересуетесь разработкой плагинов для IDEA — загляните, все исходники открыты. KPHPStorm глубоко внедряется во внутренности IDE (через кучу недокументированного API). Многое пришлось пройти, чтобы всё заработало. Спасибо ребятам из JetBrains за помощь.
Закругляемся: вот он Open Source, что дальше?
Мы усовершенствовали KPHP и показываем его вам: можно посмотреть, покомпилировать что-то простое — теперь есть все инструкции и даже Docker-образ. Но будем честны: KPHP пока остаётся инструментом, заточенным под задачи VK, и для более широкого применения в реальных сторонних проектах он ещё не адаптирован.
Почему так? Мы всегда поддерживали в первую очередь собственные движки ВКонтакте. KPHP не умеет в Redis, MongoDB и другое. Даже Memcache у нас свой, который по RPC работает. Даже перед ClickHouse, который у нас развёрнут, стоит собственная proxy, куда мы тоже ходим по TL/RPC.
Мы никогда не поддерживали стандартные базы, потому что это не было нужно. Но знаете, в чём прикол? Если мы не выйдем в Open Source, этого никогда и не произойдёт — потому что это так и не потребуется. За последние два года KPHP прошёл огромный путь, возродился. Мы можем ещё пару лет продержать его у себя. Можем покрыть возможности PHP 8, сделать ещё ряд оптимизаций, освоить микросервисы и интеграцию с Kubernetes — но нам не будут нужны стандартные базы. И через два года будет то же самое.
Только открытость и внешняя заинтересованность помогут выделить дополнительные ресурсы, чтобы пилить фичи не только для нас, но и наружу. Может, уже среди читателей этой статьи найдутся те, кому интересно с нами развивать это направление? Почему нет — у нас очень маленькая команда, и мы занимаемся интересными, глубокими и совершенно не продуктовыми вещами.
Теперь вся разработка KPHP будет вестись на GitHub. Правда, CI пока останется в приватной инфраструктуре. Движки по-прежнему будут закрыты — но когда-нибудь команда движков, надеемся, тоже решится вынести в сообщество хотя бы часть кода.
У вас может возникнуть вопрос: а сложно ли добавить поддержку протоколов MySQL, Redis и других? И да и нет. Если пробовать интегрировать готовые модули — скорее всего, будет фейл. Особенно если они порождают дополнительные потоки, ведь воркеры принципиально однопоточные. К тому же, просто поддержать протокол, может, и не проблема — но сложно сделать его «прерываемым», чтобы это стыковалось с корутинами. А вот к этому сейчас код совершенно не готов: там корутины тесно переплетены с сетью и TL. Непростая история, в общем :) Но выполнимая, и над этим надо работать.
Итак: где ссылки, как попробовать
GitHub
Документация
FAQ
Мы рассчитываем, что в дальнейшем нашей команде — возможно, при помощи сообщества — удастся развить KPHP так, чтобы он стал полезным инструментом и вне ВКонтакте. Не так важно, как быстро это произойдёт. В любом случае, это тот ориентир, который теперь стоит перед проектом.
