

Команда VK Cloud перевела статью о том, как на контейнерной платформе Netflix увязали ошибку Kernel Panic ядра Linux с подами Kubernetes.
Введение
Недавно я решил упростить для клиентов (разработчиков, а не конечных пользователей) работу с нашей контейнерной платформой Titus. В связи с этим я занялся изучением «потерянных» подов. Бывает, что поды не завершают выполняемую задачу и в конечном счёте отправляются «в мусорную корзину», так и не добившись удовлетворительного результата. Наших владельцев заданий Service (то бишь ReplicatSet) это не слишком заботит, а вот для пользователей Batch это действительно важно. Как без кода возврата понять, безопасно ли повторять попытки?
Для пользователей эти потерянные поды — серьёзная проблема, даже если они составляют небольшую долю от общего количества подов в системе. Куда они, строго говоря, направляются? Почему исчезли?
В этой статье рассказываем о взаимосвязи между наиболее пессимистичным сценарием (Kernel Panic), Kubernetes и в конечном счёте нами, операторами — ведь нам нужно отслеживать, как и почему пропадают ноды Kubernetes.
Откуда берутся потерянные поды
Поды теряются, потому что пропадает исходный объект node в Kubernetes. В этом случае процесс GC удаляет под. У нас в Titus работает пользовательский контроллер, который хранит историю объектов Pod и Node, таким образом мы сохраняем нужные объяснения и можем предъявить их пользователям. Вот как в нашем пользовательском интерфейсе выглядит этот тип отказа:
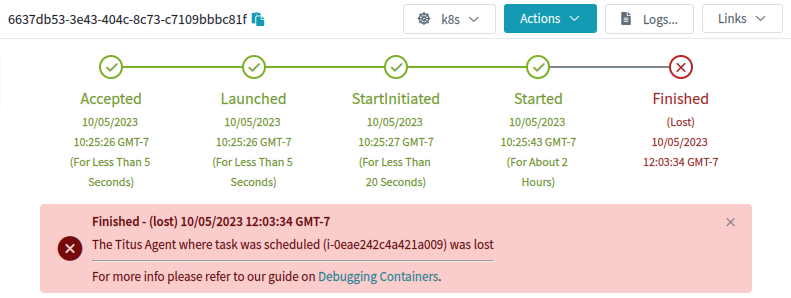
Что видят наши пользователи, когда нода Kubernetes и её поды исчезают
Да, это в каком-то смысле объяснение, но меня и наших пользователей оно не очень устраивало. Почему агент потерялся?
Откуда берутся потерянные ноды
Ноды могут исчезнуть по разным причинам, особенно в облаке. Когда такое случается, облачный контроллер Kubernetes, предоставляемый поставщиком облачных сервисов, обнаруживает, что куда-то делся сервер (в нашем случае инстанс EC2), и удаляет объект node в Kubernetes. Но это не даёт нам ответ на вопрос, почему так происходит.
Откуда нам знать, что каждый инстанс теряется не без причины, исчезает именно по этой причине и что эта причина затрагивает и под? Всё начинается с аннотации:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"annotations": {
"pod.titus.netflix.com/pod-termination-reason": "Something really bad happened!",
...
Выбрать место, где будут указываться эти данные, уже отличное начало. Теперь нам остаётся рассказать об этой аннотации GC-контроллерам, а потом добавить её в любой процесс, в котором под или нода могут неожиданно исчезнуть. При добавлении аннотации остальная часть пода остаётся как есть и в таком виде сохраняется в истории. В этом отличие от исправления статуса. Ещё мы добавляем аннотации о том, какой компонент завершил процесс, и короткий код
reason-code для расстановки тегов.Аннотация
pod-termination-reason помогает формулировать популярные удобочитаемые сообщения для пользователей, например:- «Этот под зарезервирован заданием с более высоким приоритетом ($id)»;
- «Этот под остановлен из-за сбоя аппаратного обеспечения, на котором он работает ($failuretype)»;
- «Этот под пришлось остановить, потому что $user выполнил на ноде команду sudo halt»;
- «Этот под неожиданно уничтожен из-за ошибки ноды Kernel Panic!».
Так, минуточку, а как аннотировать под для ноды, у которой случилась ошибка Kernel Panic?
Фиксируем данные по Kernel Panic
С ошибкой Kernel Panic в Linux особо ничего не сделаешь. Но что, если можно было бы выслать UDP-пакет вроде: «С последним вздохом проклинаю Kubernetes!»? Можно вдохновиться статьёй про Google Spanner, в которой ноды Spanner отправляют «предсмертный» UDP-пакет, чтобы снять блокировки и высвободить арендованные ресурсы. В настройках своих серверов вы можете задать выполнение таких же действий после Kernel Panic с использованием модуля Linux netconsole.
Настраиваем netconsole
Само по себе поразительно, что ядро Linux может высылать UDP-пакеты со строкой «Kernel Panic» прямо во время паники. Это работает, если заранее настроить netconsole, указав почти весь заголовок IP-пакета. Да-да, именно так. Нужно точно указать Linux исходный MAC, IP и UDP, а также MAC назначения, IP и UDP. Вы практически собираете UDP-пакет для ядра. И если выполнить эту предварительную работу, в момент сбоя ядро сможет сконструировать пакет и вывести его через заранее настроенный сетевой интерфейс. К счастью, с командой
netconsole-setup настроить достаточно просто. Кроме того, все параметры конфигурации можно задавать в динамическом режиме, так что в случае изменения конечной точки можно указать новый IP-адрес.Когда вы закончите настройку, сообщения ядра начнут поступать сразу после команды
modprobe. Представьте, что всё работает, как dmesg | netcat -u $destination 6666, но в пространстве ядра.«Предсмертные» пакеты netconsole
С настройкой netconsole последний вздох умирающего ядра выглядит как вполне ожидаемый набор UDP-пакетов, содержимое которых — это просто текст сообщения ядра. Вот примерно как это выглядит в случае Kernel Panic (по одному UDP-пакету на строку):
Kernel Panic - not syncing: buffer overrun at 0x4ba4c73e73acce54
[ 8374.456345] CPU: 1 PID: 139616 Comm: insmod Kdump: loaded Tainted: G OE
[ 8374.458506] Hardware name: Amazon EC2 r5.2xlarge/, BIOS 1.0 10/16/2017
[ 8374.555629] Call Trace:
[ 8374.556147] <TASK>
[ 8374.556601] dump_stack_lvl+0x45/0x5b
[ 8374.557361] panic+0x103/0x2db
[ 8374.558166] ? __cond_resched+0x15/0x20
[ 8374.559019] ? do_init_module+0x22/0x20a
[ 8374.655123] ? 0xffffffffc0f56000
[ 8374.655810] init_module+0x11/0x1000 [kpanic]
[ 8374.656939] do_one_initcall+0x41/0x1e0
[ 8374.657724] ? __cond_resched+0x15/0x20
[ 8374.658505] ? kmem_cache_alloc_trace+0x3d/0x3c0
[ 8374.754906] do_init_module+0x4b/0x20a
[ 8374.755703] load_module+0x2a7a/0x3030
[ 8374.756557] ? __do_sys_finit_module+0xaa/0x110
[ 8374.757480] __do_sys_finit_module+0xaa/0x110
[ 8374.758537] do_syscall_64+0x3a/0xc0
[ 8374.759331] entry_SYSCALL_64_after_hwframe+0x62/0xcc
[ 8374.855671] RIP: 0033:0x7f2869e8ee69
...
Подключение к Kubernetes
Последняя задача — подключиться к Kubernetes. Необходимый для нас порядок действий контроллера Kubernetes:
- Послушать UDP-пакеты netconsole на порте 6666, отслеживая, нет ли признаков Kernel Panics на нодах.
- В случае Kernel Panic найти объект Kubernetes «node», связанный с IP-адресом входящего пакета netconsole.
- Найти для этой ноды Kubernetes все связанные с ней поды, аннотировать их, а потом удалить (им крышка!).
- Аннотировать эту ноду Kubernetes и потом удалить и её (ей тоже крышка!).
Действия № 1 и 2 могут выглядеть следующим образом:
for {
n, addr, err := serverConn.ReadFromUDP(buf)
if err != nil {
klog.Errorf("Error ReadFromUDP: %s", err)
} else {
line := santizeNetConsoleBuffer(buf[0:n])
if isKernelPanic(line) {
panicCounter = 20
go handleKernelPanicOnNode(ctx, addr, nodeInformer, podInformer, kubeClient, line)
}
}
if panicCounter > 0 {
klog.Infof("KernelPanic context from %s: %s", addr.IP, line)
panicCounter++
}
}
А вот как могут выглядеть действия № 3 и 4:
func handleKernelPanicOnNode(ctx context.Context, addr *net.UDPAddr, nodeInformer cache.SharedIndexInformer, podInformer cache.SharedIndexInformer, kubeClient kubernetes.Interface, line string) {
node := getNodeFromAddr(addr.IP.String(), nodeInformer)
if node == nil {
klog.Errorf("Got a Kernel Panic from %s, but couldn't find a k8s node object for it?", addr.IP.String())
} else {
pods := getPodsFromNode(node, podInformer)
klog.Infof("Got a Kernel Panic from node %s, annotating and deleting all %d pods and that node.", node.Name, len(pods))
annotateAndDeletePodsWithReason(ctx, kubeClient, pods, line)
err := deleteNode(ctx, kubeClient, node.Name)
if err != nil {
klog.Errorf("Error deleting node %s: %s", node.Name, err)
} else {
klog.Infof("Deleted panicked node %s", node.Name)
}
}
}
Если у вас есть этот код, то в случае обнаружения Kernel Panic поды и ноды немедленно исчезают. Не нужно ждать процесса GC. Аннотации помогают задокументировать, что случилось с нодой и подом:
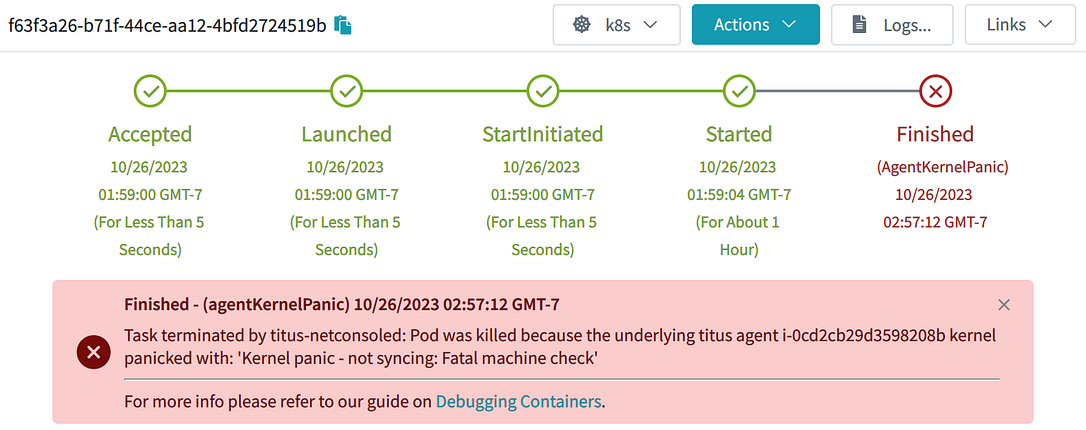
Пример из жизни: под, потерянный на ноде Kubernetes, с которой произошла ошибка Kernel Panic!
Заключение
Возможно, весточка, что задание закончилось с ошибкой из-за Kernel Panic, не слишком обрадует наших заказчиков. Но порадует понимание, что теперь у нас есть необходимые инструменты наблюдаемости, позволяющие устранить Kernel Panic!
Вы прямо сейчас можете воспользоваться Kubernetes от VK Cloud. Для тестирования мы начисляем новым пользователям 3000 бонусных рублей и будем рады вашей обратной связи.
Stay tuned.
Присоединяйтесь к телеграм-каналу «Вокруг Kubernetes», чтобы быть в курсе новостей из мира K8s: регулярные дайджесты, полезные статьи, а также анонсы конференций и вебинаров.
