
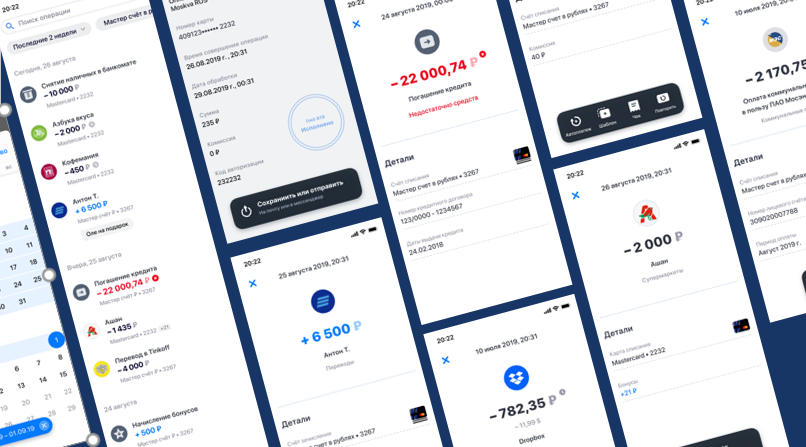
Привет, Хабр! Меня зовут Дима Бочкарёв, я IT-лидер стрима «Сквозные бизнес-компоненты ВТБ Онлайн». В этом посте я расскажу, зачем и как мы меняли архитектуру приложения в части истории операций клиентов, с какими проблемами столкнулись и как достигали цели «сделать всё хорошо». Подробности ниже.
Текущая архитектура и что мы хотели доработать
Для начала немного о том, как мы жили до изменений. Исторически у ВТБ уникальный IT-ландшафт: он связан с объединениями банков и крупными слияниями.
При этом раньше в ВТБ на протяжении многих лет разработкой занимались различные вендоры. Они внедряли те или иные фичи в рамках своей зоны ответственности — системы, которые дорабатывали только они, что приводило к нагромождениям кода. Например, типичная ситуация: «Нужно добавить иконку на операцию? Напишем if <название операции>. Ещё иконку нужно? Добавим ещё один if. Некорректная текстовка на фронте? Ну, добавим очередной if, нам не жалко».
Сейчас в банке происходит большая трансформация, направленная на унификацию (единая история операций, кастомизация отдельных операций и пр.) ландшафта банка и устранение технического долга, накопившегося за много лет. Но и сам функционал мы тоже меняем в лучшую сторону. Для истории операций мы сформулировали следующие дополнительные требования:
единая история операций по всем продуктам;
поддержка большего потока клиентов;
кастомизация отдельных операций;
постоянный мониторинг функционала «глазами клиента»;
время отклика до одной секунды.
Новая история операций
Изучив фронт работ, мы пришли к выводу, что стоит разбираться с каждым требованием по очереди. Для этого мы функционально разделили часть архитектуры приложения, отвечающую за историю операций, на четыре блока, о каждом из которых я расскажу детальнее.
1. Streaming операций клиентов от поставщиков данных
Реализовать streaming данных из АБС — серьёзная задача, и нужно было решать её в двух аспектах:
снижение нагрузки на АБС (особенно это важно в часы пиковой активности);
увеличение скорости выдачи истории операций для большинства пользователей.
Процесс сбора и обработки данных по операциям клиента мы реализовали в виде конвейера. На входе стоит REST-сервис, который принимает данные от сервисов-поставщиков для удобства большинства интеграций и отправляет их в Kafka для дальнейшей обработки. Кроме того, поставщик также может записать их в Kafka напрямую.
Следующий шаг — обогащение операций. Здесь мы фильтруем операции, определяем их принадлежность к магазину, формируем «правильное» описание операции, присваиваем категорию и т. д.
Наконец, происходят преобразование транзакции в модель хранения и сохранение операций в универсальном хранилище данных (УХД).
Такой подход позволил нам организовать работу как в push-, так и put-режимах работы с АБС, а заодно подключить различные источники данных для обогащения транзакций.
2. Высокопроизводительное хранилище данных
Мы долго думали над выбором хранилища для истории операций. Много копий было сломано в ходе дискуссий, но в конечном итоге мы решили сделать всё сами — создать комбинацию из набора проверенных решений
Это key-value-хранилище, обеспечивающее целостность данных через Kafka, которая отправляет данные в PostgreSQL и Redis. Kafka у нас растянута на три ЦОДа, но данные мы храним только в двух из них, а третий ЦОД у нас кворумный. С точки зрения хранения такое решение включает шардирование и имеет несколько режимов чтения, с поддержкой консистентности данных и без неё. При этом УХД само выбирает (исходя из конфигурации), откуда произвести чтение — из Redis или/и из Postgres, и учитывает скорости записи в конкретную БД. Для нашей задачи мы используем неконсистентную выдачу, но проблему консистентности решаем на уровне приложения (об этом я ещё расскажу позднее).
Дополнительно таблицы Postgres партиционированы по идентификатору клиента.
У нас сейчас четыре шарда, каждый шард состоит из двух экземпляров Postgres и одного Redis в ЦОДе. И хранилище теперь выглядит следующим образом:

Помимо всего прочего, это решение поддерживает лёгкую замену БД или добавление, например, elastic search в виде хранилища.
Данные по каждой операции мы храним избыточно в разрезе источника данных и уникального тела операции. При чтении мы вычитываем всю цепочку записей по операции и, в зависимости от приоритетов поля и источника данных, склеиваем их в одну запись, после чего отдаём её потребителю. В упрощённом виде это выглядит вот так:

Это позволяет гибко управлять алгоритмом склеивания записей и менять его в случае необходимости.
3. Выдача списка операций клиентов в ВТБ Онлайн и другим системам-потребителям
Здесь нам нужно было обеспечить консистентность данных, а также поддержание push- и put-режима работы. Для этого мы прибегли к паттерну pub-sub для информирования об изменениях в хранилище.

Реализует этот паттерн в ВТБ Онлайн push-сервис, который позволяет бэку информировать фронт об изменениях. Вкратце расскажу, как это работает. Клиентские приложения или системы-потребители подписываются на изменения в истории операций и запрашивают историю операций (всю или по конкретному продукту). В ответ возвращаются данные, которые у нас есть в хранилище, и признак актуальности данных. Для неактуальных данных мы запрашиваем обновление у АБС и, по мере получения данных, информируем потребителя об изменениях.
Также мы кратковременно кэшируем ответы клиенту.
4. Концепция «шаблонов» в отображении операций клиентов
Проблему фронта с кучей if при кастомизации операций мы стали решать в двух местах:
Со стороны бэка мы добавили в операцию признак шаблона списка и шаблона деталей, а также справочник «ключ-значение». На этапе обогащения данных мы записываем шаблоны и добавляем дополнительную информацию об операции в справочник. Также различные источники могут обогатить своими данными операцию и назначить на неё свой шаблон.
На фронте на основании шаблона списка и шаблона деталей мы используем фабричный метод и создаём требуемое представление. Если представления нет или по каким-то причинам не получается его создать, используем шаблон по умолчанию, который отображает базовую функциональность.

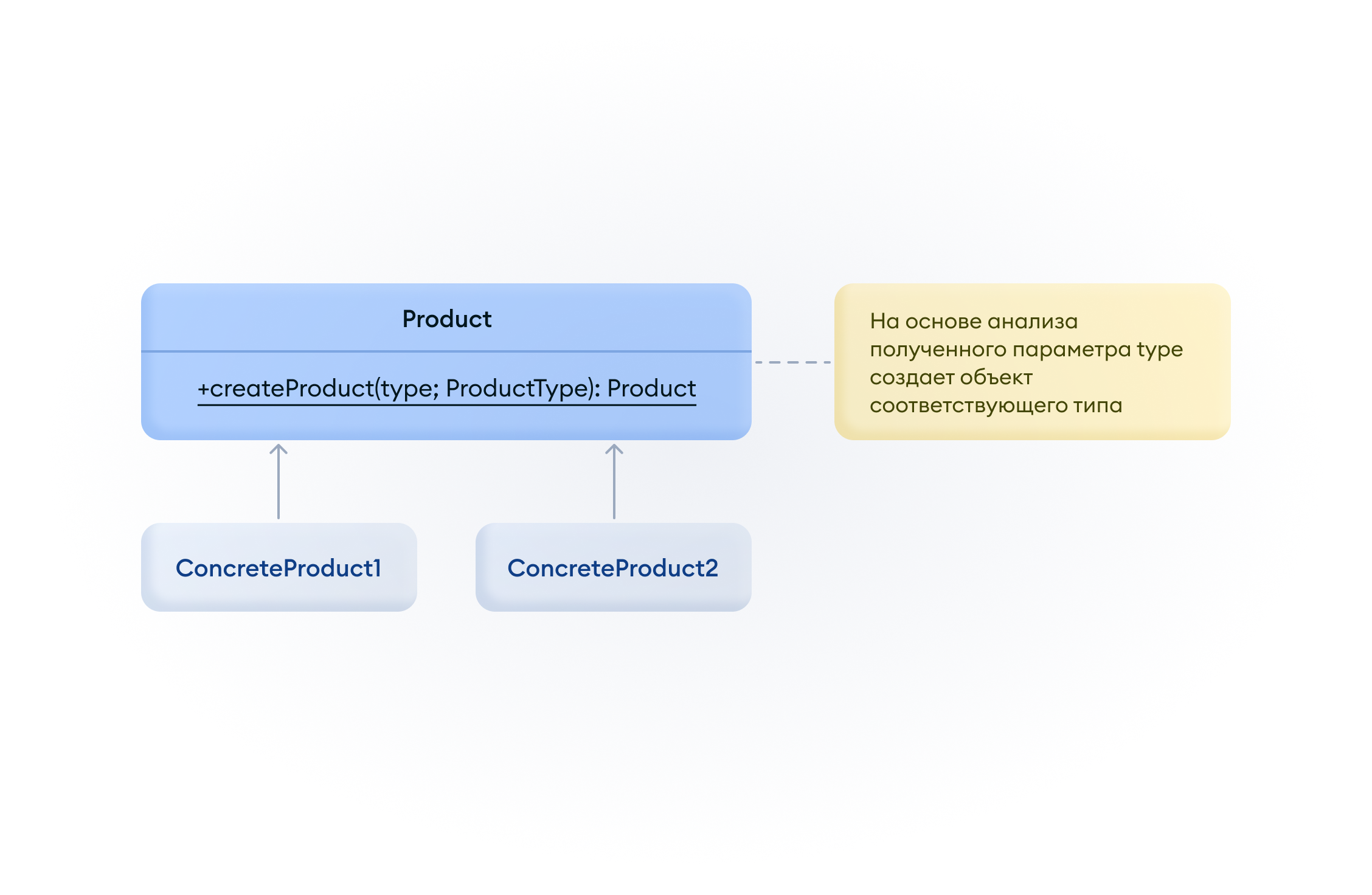
Данное решение дало больше свободы другим командам в части создания дополнительной функциональности в истории операций: они теперь могут не бояться, что из-за их деятельности сломается соседний функционал.
Планы развития
Одной из приоритетных задач для ВТБ на 2021 год стала миграция в целевые АБС, поэтому организация обратного потока данных для 100% источников перекочевала в планы на 2022 год, но для ряда операций и продуктов это уже работает. Сейчас функционал единой истории операций доступен для всех пользователей интернет-банка, а также для всех сотрудников в мобильном приложении. До конца года мы полностью перейдём на новый сервис истории операций в мобильном банке.
