Отлаживая экземпляр сервера первой ревизии, мы частично протестировали скорость работы подсистемы ввода-вывода. Кроме цифр с результатами тестов, в статье я постарался отразить наблюдения, которые могут быть полезны инженерам при проектировании и настройке ввода-вывода приложений.

Начну издалека. В наш сервер можно поставить до 4 процессоров (соответственно до 48 ядер POWER8) и очень много памяти (до 8 ТБ). Это открывает много возможностей для приложений, но большой объем данных в оперативной памяти влечёт за собой необходимость где-то их хранить. Данные надо быстро достать с дисков и также быстро обратно запихнуть. В недалёком будущем нас ждёт прекрасный мир дезагрегированной энергонезависимой и разделяемой памяти. В этом прекрасном будущем, может быть, вообще не будет нужды в backing store. Процессор будет копировать байты напрямую из внутренних регистров в энергонезависимую память с временем доступа, как у DRAM (десятки нс) и иерархия памяти сократится на один этаж. Это всё потом, сейчас же все данные принято хранить на блочной дисковой подсистеме.
Определимся с начальными условиями для тестирования:
Сервер имеет относительно большое число вычислительных ядер. Это удобно использовать для параллельной обработки большого объёма данных. То есть один из приоритетов — это большая пропускная способность подсистемы ввода-вывода при большом числе параллельных процессов. Как следствие, логично использовать микробенчмарк и настроить достаточно много параллельных потоков.
Кроме того, подсистема ввода вывода построена на NVMe дисках, которые могут обрабатывать много запросов параллельно. Соответственно, мы можем ожидать прироста производительности от асинхронного ввода-вывода. Иначе говоря, интересна большая пропускная способность при параллельной обработке. Это больше соответствует назначению сервера. Производительность на однопоточных приложениях, и достижение минимального времени отклика, хоть и является одной из целей будущей настройки, но в данном тесте не рассматривается.
Бенчмарков отдельных NVMe дисков полно в сети, плодить лишние не стоит. В данной статье я рассматриваю дисковую подсистему как целое, поэтому диски нагружать будем в основном группами. В качестве нагрузки будем использовать 100% случайное чтение и запись с блоком разного размера.
На маленьком блоке 4КБ смотреть будем на IOPS (число операций в секунду) и во вторую очередь latency (время отклика). C одной стороны, фокус на IOPS — это наследие от жёстких дисков, где случайный доступ маленьким блоком приносил наибольшие задержки. В современном мире, all-flash системы способны выдавать миллионы IOPS, часто больше чем софт способен употребить. Сейчас «IOPS-интенсивные нагрузки» ценны тем, что показывают сбалансированность системы по вычислительным ресурсам и узкие места в программном стеке.
С другой стороны, для части задач важно не количество операций в секунду, а максимальная пропускная способность на большом блоке ≥64КБ. Например, при сливе данных из памяти в диски (снэпшот базы данных) или загрузке базы в память для in-memory вычислений, прогреве кеша. Для сервера с 8 терабайтами памяти пропускная способность дисковой подсистемы имеет особенное значение. На большом блоке будем смотреть пропускную способность, то есть мегабайты в секунду.
Дисковая подсистема сервера может включать до 24 дисков стандарта NVMe. Диски равномерно распределены по четырём процессорам с помощью двух PCI Express свитчей PMC 8535. Каждый свитч логически разделен на три виртуальных свитча: один x16 и два x8. Таким образом, на каждый процессор доступно PCIe x16, или до 16 ГБ/с. К каждому процессору подключено по 6 NVMe дисков. Суммарно, мы ожидаем пропускную способность до 60 ГБ/с со всех дисков.

Для тестов мне доступен экземпляр сервера с 4 процессорами (8 ядер на процессор, максимально бывает 12 ядер). Диски подключены к двум сокетам из четырёх. То есть это половина от максимальной конфигурации дисковой подсистемы. На объединительной плате с PCI Express свитчами первой ревизии оказались неисправны два разъёма Oculink, и поэтому доступна только половина дисков. Во второй ревизии это уже исправили, но тут я смог поставить только половину дисков, а именно получилась следующая конфигурация:
Разнообразие дисков вызвано тем, что мы попутно тестируем и их для формирования номенклатуры стандартных компонентов (диски, память, и т.д.) от 2-3 производителей.
Для начала выполним простой тест в минимальной конфигурации — один диск (Micron MTFDHAL2T4MCF-1AN1ZABYY), один процессор POWER8 и один поток fio с очередью = 16.
Получилось вот так:
Что мы тут видим? Получили 133K IOPS с временем отклика 119 мкс. Обратим внимание, что загрузка процессора составляет 73%. Это много. Чем занят процессор?
Мы используем асинхронный ввод-вывод, и это упрощает анализ результатов. fio отдельно считает slat (submission latency) и clat (completion latency). Первое включает в себя время выполнения системного вызова чтения до возвращения в user space. То есть все накладные расходы ядра до ухода запроса в железо показаны отдельно.
В нашем случае slat равен всего 2.8 мкс на один запрос, но с учетом повторения этого 133 000 раз в секунду получается много: 2.8 мкс * 133,000 =372 мс. То есть 37.2% времени процессор тратит только на IO submission. А есть еще код самого fio, прерывания, работа драйвера асинхронного ввода вывода.
Общая нагрузка процессора 73%. Похоже, еще одного fio ядро не потянет, но попробуем:
С двумя потоками скорость подросла со 133k до 180k, но ядро перегружено. По top утилизация процессора 100% и clat вырос. То есть 188k — это предел для одного ядра на этой нагрузке. При этом легко видим, что рост clat вызван именно процессором, а не диском. Посмотрим ‘biotop’ ():
Из-за включенной трассировки скорость несколько просела, но время отклика от дисков ~109 мкс, такое же, как и в предыдущем тесте. Измерения другим способом (sar -d) показывают те же цифры.
Ради любопытства, интересно посмотреть, чем занят процессор:
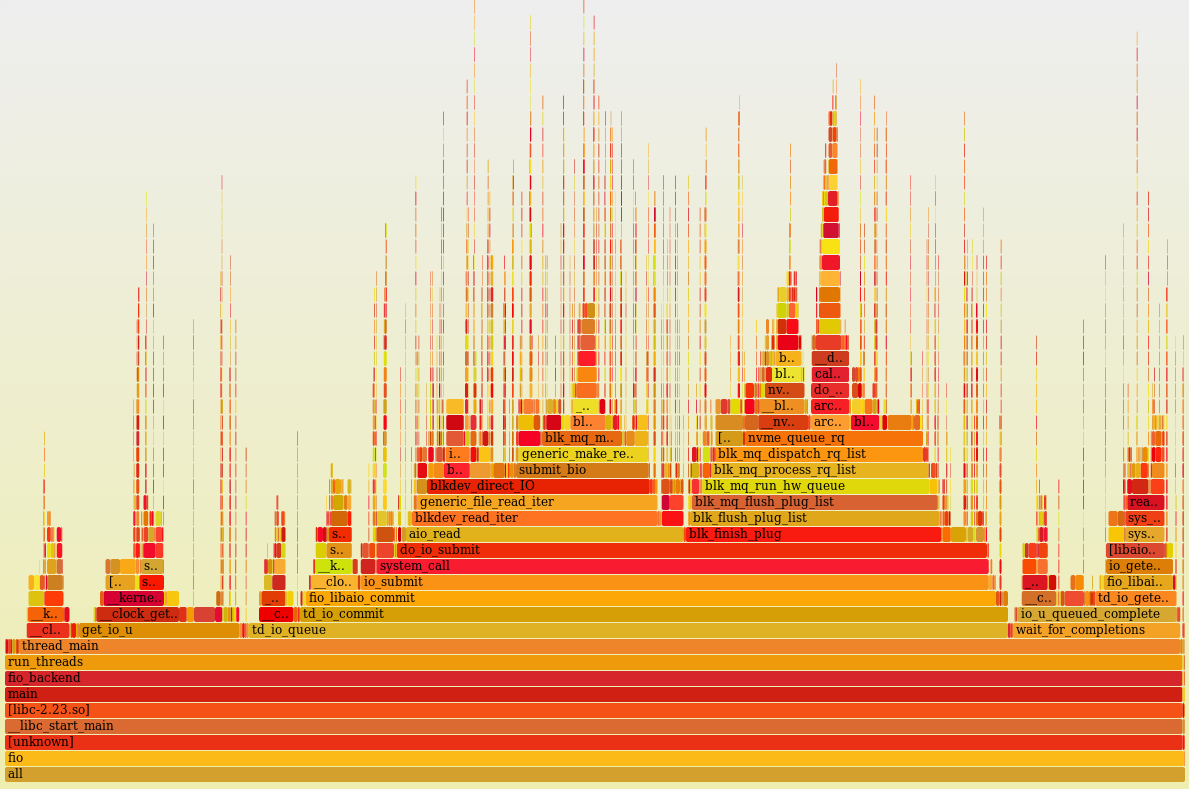
Профиль нагрузки одного ядра (perf + flame graph) с отключённой многопоточностью и работающими двумя процессами fio. Как видно, он 100% времени что-то делает (idle =0%).
Визуально, процессорное время более-менее равномерно распределено между большим количеством пользовательских (код самого fio) и ядерных функций (асинхронный ввод-вывод, блочный уровень, драйвер, много маленьких пиков – это прерывания). Не видно какой-то одной функции, где бы расходовалось аномально большое количество процессорного времени. Выглядит неплохо и, при просмотре стеков в голову не приходит идей, что тут можно было бы покрутить.
Итак, мы выяснили, что при активной нагрузке по IO, процессор легко перегрузить. Цифра утилизации процессора показывает, что он занят для операционной системы, но ничего не говорит о загрузке узлов процессора. В том числе, процессор может казаться загруженным во время ожидания внешних компонентов, например, памяти. Здесь у нас нет цели выяснять эффективность использования процессора, но чтобы понять потенциал тюнинга, интересно взглянуть на “CPU counters”, частично доступные через ‘perf’.
В выводе выше видно, IPC (insn per cycle) 0.73 – не так плохо, но теоретически на Power8 он может быть до 8. Кроме того, 50% “backend cycles idle” (метрика PM_CMPLU_STALL) может значить ожидание памяти. То есть процессор занят для планировщика Linux, но ресурсы самого процессора не особо загружены. Вполне можно ожидать прироста производительности от включения многопоточности (SMT), при увеличении числа потоков. Результат того, что случилось при включении SMT показан на графиках. Я получил ощутимый прирост скорости от дополнительных процессов fio, работающих на других потоках одного и того же процессора. Для сравнения приведён случай, когда все потоки работают на разных ядрах (diff cores).
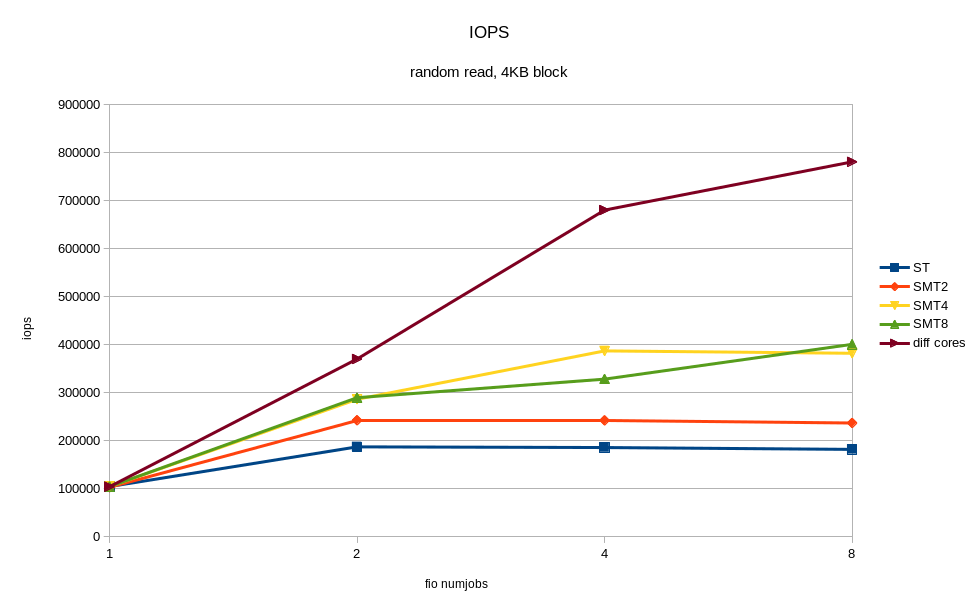
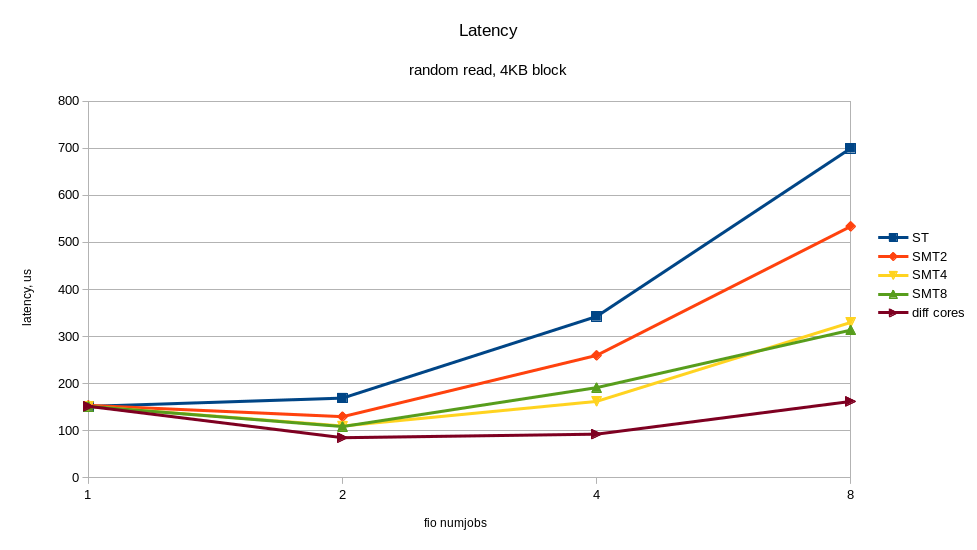
По графикам видно, что включение SMT8 даёт почти двукратный рост скорости и снижение времени отклика. Вполне неплохо и с одного ядра мы снимаем > 400K IOPS! Попутно видим, что одного ядра, даже с включённым SMT8 мало, чтобы полностью нагрузить NVMe диск. Раскидав потоки fio по разным ядрам, мы получаем почти вдвое лучшую производительность диска – это то, что может современный NVMe.
Таким образом, если архитектура приложения позволяет регулировать количество пишущих/читающих процессов, то лучше подстраивать их число под количество физических/логических ядер, во избежание замедлений от перегруженных процессоров. Один NVMe диск может легко перегрузить процессорное ядро. Включение SMT4 и SMT8 даёт кратный прирост производительности и может быть полезно для нагрузок с интенсивным по вводом-выводом.
Для балансировки нагрузки 24 внутренних NVMe диска сервера равномерно подключены к четырём процессорным сокетам. Соответственно, для каждого диска есть «родной» сокет (NUMA локальность) и «удалённый». Если приложение обращается к дискам с «удалённого» сокета, то возможны накладные расходы от влияния межпроцессорной шины. Мы решили посмотреть, как доступ с удалённого сокета влияет на итоговую производительность дисков. Для теста снова запускаем fio и с помощью numactl привязываем процессы fio к одному сокету. Сначала к «родному» сокету, потом к «удалённому». Цель теста — понять, стоит ли тратить силы на настройку NUMA, и какого эффекта можно ожидать? На графике я привёл в сравнение только один удалённый сокет из трёх из-за отсутствия между ними разницы.
Конфигурация fio:
Изменяя очередь, я смотрел пропускную способность и время отклика, запуская нагрузку в локальном сокете, удалённом, и без привязки к сокету вообще.

Как видно на графиках, разница между локальным и удалённым сокетом есть и весьма ощутима на большой нагрузке. Накладные расходы проявляются при очереди 16 (iodepth =16) >2M IOPS с блоком 4КБ (> 8 ГБ/с, проще говоря). Можно было бы сделать вывод, что уделять внимание NUMA стоит только на задачах, где нужна большая пропускная способность по вводу-выводу. Но не все так однозначно, в реальном приложении кроме ввода-вывода будет траффик по межпроцессорной шине при доступе к памяти в удалённой NUMA локальности. Как следствие, замедление может наступать и при меньшем трафике по вводу-выводу.
И теперь, самое интересное. Нагрузим все имеющиеся 12 дисков одновременно. Причём, с учётом предыдущих экспериментов, сделаем это двумя способами:
Смотрим, что получилось:
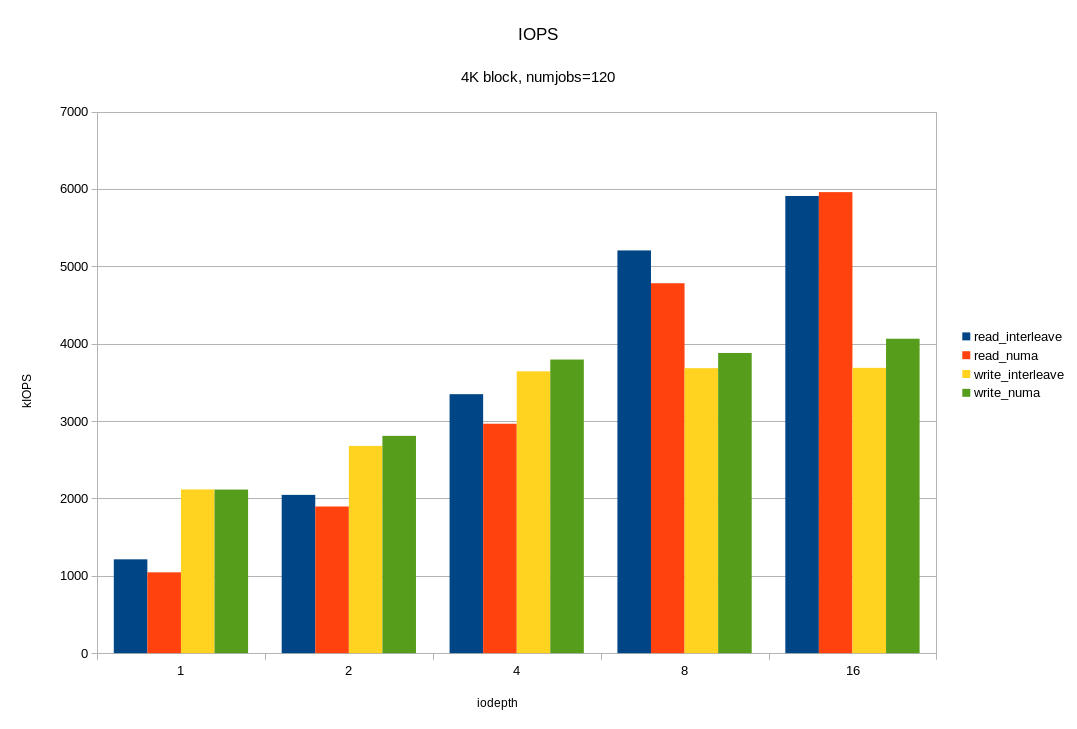
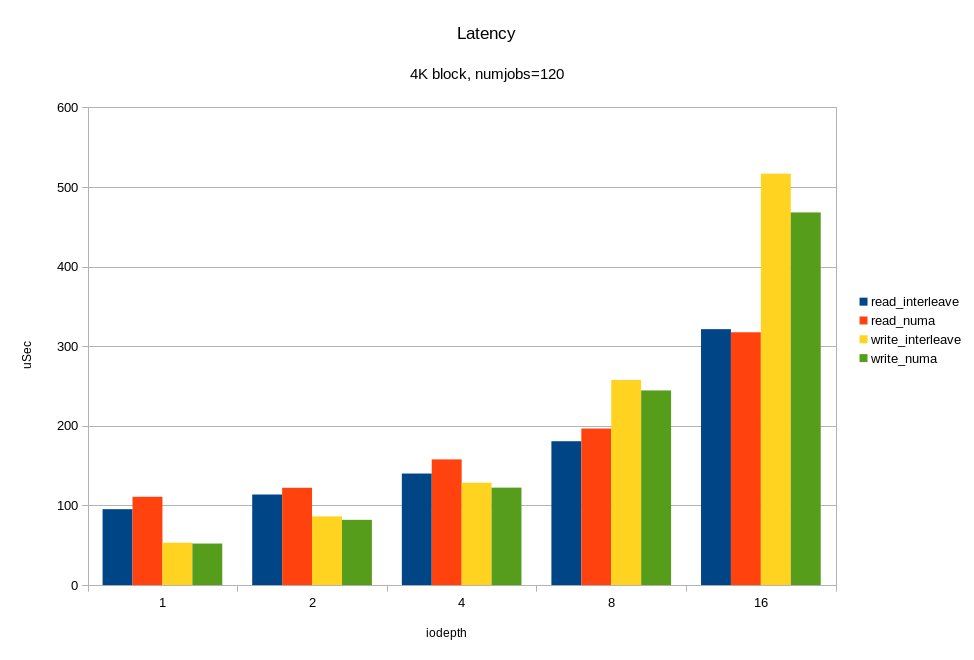
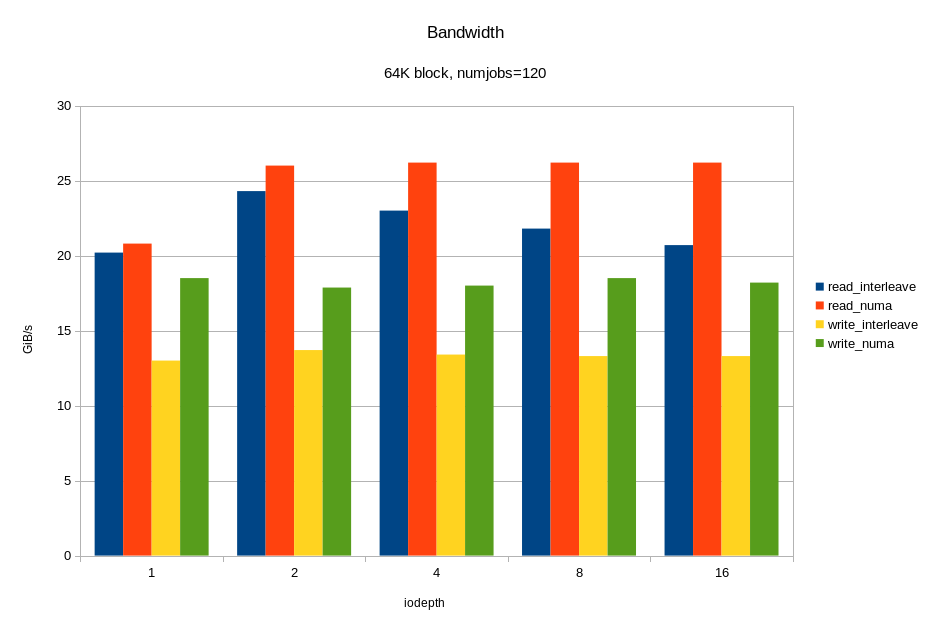
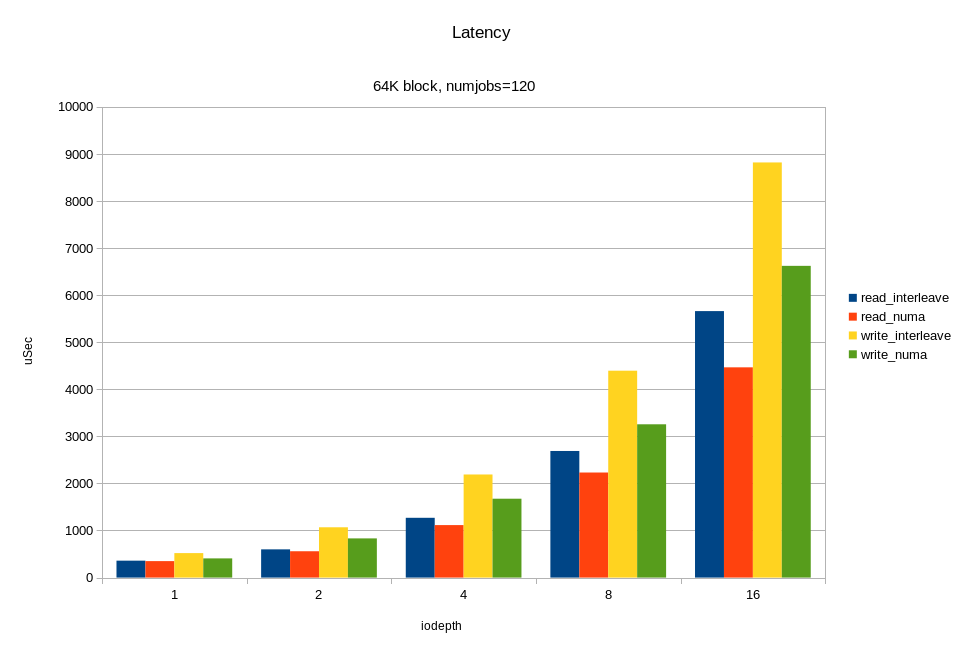
Для операций случайного чтения с блоком 4KB, мы получили ~6M IOPS при времени отклика < 330 мкс. Для блока 64KB мы получили 26.2 ГБ/с. Вероятно, мы упираемся в шину x16 между процессором и PCIe свитчем. Напомню, это половина аппаратной конфигурации! Опять же, видим, что на большой нагрузке привязка ввода-вывода к «домашней» локальности дает хороший эффект.
Отдавать диски приложению целиком, как правило, неудобно. Приложению может оказаться либо слишком мало одного диска, либо слишком много. Часто хочется изолировать компоненты приложения друг от друга через разные файловые системы. С другой стороны, хочется равномерно сбалансировать нагрузку между каналами ввода-вывода. На помощь приходит LVM. Диски объединяют в дисковые группы и распределяют пространство между приложениями через логические тома. В случае с обычными шпинделями, или даже с дисковыми массивами, накладные расходы LVM относительно малы в сравнении с задержками от дисков. В случае с NVMe, время отклика от дисков и оверхед программного стека – цифры одного порядка. интересно посмотреть их отдельно.
Я создал LVM-группу с теми же дисками, что и в предыдущем тесте, и нагрузил LVM-том тем же числом читающих потоков. В результате, получил только 1M IOPS и 100% загрузку процессоров. С помощью perf, я сделал профилирование процессоров, и вот что получилось:

В Linux LVM использует Device Mapper, и очевидно система проводит очень много времени при подсчёте и обновлении статистики по дискам в функции generic_start_io_acct(). Как отключить сбор статистики в Device Mapper я не нашёл, (в dm_make_request() ). Вероятно, тут есть потенциал для оптимизации. В целом, на данный момент, применение Device Mapper может плохо влиять на производительность при большой нагрузке по IOPS.
Поллинг – новый механизм работы работы драйверов ввода вывода Linux для очень быстрых устройств. Это новая фича, и упомяну ее только для того, чтобы сказать почему в данном обзоре она не протестирована. Новизна фичи в том, что процесс не снимается с выполнения во время ожидания ответа от дисковой подсистемы. Переключение контекста обычно выполняется во время ожидания ввода-вывода и затратно само по себе. Накладные расходы на переключение контекста оцениваются в единицы микросекунд (ядру Linux надо снять с выполнения один процесс, вычислить самого достойного кандидата для выполнения и т.д. и т.п.) Прерывания при поллинге могут сохраняться (убирается только переключение контекста) или полностью исключаться. Этот метод оправдан для ряда условий:
Обратная сторона поллинга — это повышение нагрузки на процессор.
В актуальном ядре Linux (для меня сейчас 4.10) поллинг по умолчанию включён для всех NVMe устройств, но работает только для случаев, когда приложение специально просит его использовать для отдельных «особо важных» запросов ввода-вывода. Приложение должно поставить флаг RWF_HIPRI в системных вызовах preadv2()/pwritev2().
Так как однопоточные приложения не относятся к основной теме статьи, поллинг откладывается на следующий раз.
Хотя у нас тестовый образец с половиной конфигурации дисковой подсистемы, результаты впечатляют: почти 6M IOPS блоком 4KB и > 26 ГБ/с для 64KB. Для встроенной дисковой подсистемы сервера это выглядит более чем убедительно. Система выглядит сбалансированной по числу ядер, количеству NVMe дисков на ядро и ширине шины PCIe. Даже с терабайтами памяти, весь объем можно прочитать с дисков за считанные минуты.
Стек NVMe в Linux легковесный, процессор оказывается перегружен только при большой нагрузке fio >400K IOPS, (4KB, read, SMT8).
NVMe диск быстрый сам по себе, и довести его до насыщения приложением достаточно сложно. Больше нет проблемы с медленными дисками, но возможна проблема с ограничениями шины PCIe и программного стека ввода-вывода, а иногда и ресурсами ядра. Во время теста мы именно в диски практически не упирались. Интенсивный ввод-вывод сильно нагружает все подсистемы сервера (память и процессор). Таким образом, для приложений, интенсивных по вводу-выводу, нужна настройка всех подсистем сервера: процессоров (SMT), памяти (интерливинга, к примеру), приложения (количество пишущих/читающих процессов, очередь, привязка к дискам).
Если планируемая нагрузка не требует больших вычислений, но интенсивна по вводу-выводу с маленьким блоком, все равно лучше брать процессоры POWER8 с наибольшим числом ядер из доступной линейки, то есть 12.
Включение в стек ввода-вывода на NVMe дополнительных программных слоев (типа Device Mapper) может ощутимо снижать пиковую производительность.
На большом блоке (>=64KB), привязка IO нагрузки к NUMA локальностям (процессорам), к которым подключены диски, дает снижение времени отклика от дисков и ускоряет ввод-вывод. Причина в том, что на такой нагрузке важна ширина шины от процессора до дисков.
На маленьком блоке (~4KB) все менее однозначно. При привязке нагрузки к локальности есть риск неравномерной загрузки процессоров. То есть можно просто перегрузить сокет, к которому подключены диски и привязана нагрузка.
В любом случае, при организации ввода-вывода, особенно асинхронного, лучше разносить нагрузку по разным ядрам с помощью NUMA-утилит в Linux.
Использование SMT8 сильно повышает производительность при большом числе пишущих/читающих процессов.
Исторически, подсистема ввода-вывода медленная. С появлением флеша она стала быстрой, а с появлением NVMe совсем быстрой. В традиционных дисках есть механика. Она делает шпиндель самым медленным элементом вычислительного комплекса. Что из этого следует?

Методика теста и нагрузка
Начну издалека. В наш сервер можно поставить до 4 процессоров (соответственно до 48 ядер POWER8) и очень много памяти (до 8 ТБ). Это открывает много возможностей для приложений, но большой объем данных в оперативной памяти влечёт за собой необходимость где-то их хранить. Данные надо быстро достать с дисков и также быстро обратно запихнуть. В недалёком будущем нас ждёт прекрасный мир дезагрегированной энергонезависимой и разделяемой памяти. В этом прекрасном будущем, может быть, вообще не будет нужды в backing store. Процессор будет копировать байты напрямую из внутренних регистров в энергонезависимую память с временем доступа, как у DRAM (десятки нс) и иерархия памяти сократится на один этаж. Это всё потом, сейчас же все данные принято хранить на блочной дисковой подсистеме.
Определимся с начальными условиями для тестирования:
Сервер имеет относительно большое число вычислительных ядер. Это удобно использовать для параллельной обработки большого объёма данных. То есть один из приоритетов — это большая пропускная способность подсистемы ввода-вывода при большом числе параллельных процессов. Как следствие, логично использовать микробенчмарк и настроить достаточно много параллельных потоков.
Кроме того, подсистема ввода вывода построена на NVMe дисках, которые могут обрабатывать много запросов параллельно. Соответственно, мы можем ожидать прироста производительности от асинхронного ввода-вывода. Иначе говоря, интересна большая пропускная способность при параллельной обработке. Это больше соответствует назначению сервера. Производительность на однопоточных приложениях, и достижение минимального времени отклика, хоть и является одной из целей будущей настройки, но в данном тесте не рассматривается.
Бенчмарков отдельных NVMe дисков полно в сети, плодить лишние не стоит. В данной статье я рассматриваю дисковую подсистему как целое, поэтому диски нагружать будем в основном группами. В качестве нагрузки будем использовать 100% случайное чтение и запись с блоком разного размера.
Какие метрики смотреть?
На маленьком блоке 4КБ смотреть будем на IOPS (число операций в секунду) и во вторую очередь latency (время отклика). C одной стороны, фокус на IOPS — это наследие от жёстких дисков, где случайный доступ маленьким блоком приносил наибольшие задержки. В современном мире, all-flash системы способны выдавать миллионы IOPS, часто больше чем софт способен употребить. Сейчас «IOPS-интенсивные нагрузки» ценны тем, что показывают сбалансированность системы по вычислительным ресурсам и узкие места в программном стеке.
С другой стороны, для части задач важно не количество операций в секунду, а максимальная пропускная способность на большом блоке ≥64КБ. Например, при сливе данных из памяти в диски (снэпшот базы данных) или загрузке базы в память для in-memory вычислений, прогреве кеша. Для сервера с 8 терабайтами памяти пропускная способность дисковой подсистемы имеет особенное значение. На большом блоке будем смотреть пропускную способность, то есть мегабайты в секунду.
Встроенная дисковая подсистема
Дисковая подсистема сервера может включать до 24 дисков стандарта NVMe. Диски равномерно распределены по четырём процессорам с помощью двух PCI Express свитчей PMC 8535. Каждый свитч логически разделен на три виртуальных свитча: один x16 и два x8. Таким образом, на каждый процессор доступно PCIe x16, или до 16 ГБ/с. К каждому процессору подключено по 6 NVMe дисков. Суммарно, мы ожидаем пропускную способность до 60 ГБ/с со всех дисков.

Для тестов мне доступен экземпляр сервера с 4 процессорами (8 ядер на процессор, максимально бывает 12 ядер). Диски подключены к двум сокетам из четырёх. То есть это половина от максимальной конфигурации дисковой подсистемы. На объединительной плате с PCI Express свитчами первой ревизии оказались неисправны два разъёма Oculink, и поэтому доступна только половина дисков. Во второй ревизии это уже исправили, но тут я смог поставить только половину дисков, а именно получилась следующая конфигурация:
- 4 × Toshiba PX04PMB160
- 4 × Micron MTFDHAL2T4MCF-1AN1ZABYY
- 3 × INTEL SSDPE2MD800G4
- 1 × SAMSUNG MZQLW960HMJP-00003
Разнообразие дисков вызвано тем, что мы попутно тестируем и их для формирования номенклатуры стандартных компонентов (диски, память, и т.д.) от 2-3 производителей.
Нагрузка минимальной конфигурации
Для начала выполним простой тест в минимальной конфигурации — один диск (Micron MTFDHAL2T4MCF-1AN1ZABYY), один процессор POWER8 и один поток fio с очередью = 16.
[global]
ioengine=libaio
direct=1
group_reporting=1
bs=4k
iodepth=16
rw=randread
[ /dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY]
stonewall
numjobs=1
filename=/dev/nvme1n1
Получилось вот так:
# numactl --physcpubind=0 ../fio/fio workload.fio
/dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=16
fio-2.21-89-gb034
time 3233 cycles_start=1115105806326
Starting 1 process
Jobs: 1 (f=1): [r(1)][13.7%][r=519MiB/s,w=0KiB/s][r=133k,w=0 IOPS][eta 08m:38s]
fio: terminating on signal 2
Jobs: 1 (f=0): [f(1)][100.0%][r=513MiB/s,w=0KiB/s][r=131k,w=0 IOPS][eta 00m:00s]
/dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY: (groupid=0, jobs=1): err= 0: pid=3235: Fri Jul 7 13:36:21 2017
read: IOPS=133k, BW=519MiB/s (544MB/s)(41.9GiB/82708msec)
slat (nsec): min=2070, max=124385, avg=2801.77, stdev=916.90
clat (usec): min=9, max=921, avg=116.28, stdev=15.85
lat (usec): min=13, max=924, avg=119.38, stdev=15.85
………...
cpu : usr=20.92%, sys=52.63%, ctx=2979188, majf=0, minf=14
Что мы тут видим? Получили 133K IOPS с временем отклика 119 мкс. Обратим внимание, что загрузка процессора составляет 73%. Это много. Чем занят процессор?
Мы используем асинхронный ввод-вывод, и это упрощает анализ результатов. fio отдельно считает slat (submission latency) и clat (completion latency). Первое включает в себя время выполнения системного вызова чтения до возвращения в user space. То есть все накладные расходы ядра до ухода запроса в железо показаны отдельно.
В нашем случае slat равен всего 2.8 мкс на один запрос, но с учетом повторения этого 133 000 раз в секунду получается много: 2.8 мкс * 133,000 =372 мс. То есть 37.2% времени процессор тратит только на IO submission. А есть еще код самого fio, прерывания, работа драйвера асинхронного ввода вывода.
Общая нагрузка процессора 73%. Похоже, еще одного fio ядро не потянет, но попробуем:
Starting 2 processes
Jobs: 2 (f=2): [r(2)][100.0%][r=733MiB/s,w=0KiB/s][r=188k,w=0 IOPS][eta 00m:00s]
/dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY: (g=0): rw=randread, bs=(R)
pid=3391: Sun Jul 9 13:14:02 2017
read: IOPS=188k, BW=733MiB/s (769MB/s)(430GiB/600001msec)
slat (usec): min=2, max=963, avg= 3.23, stdev= 1.82
clat (nsec): min=543, max=4446.1k, avg=165831.65, stdev=24645.35
lat (usec): min=13, max=4465, avg=169.37, stdev=24.65
…………
cpu : usr=13.71%, sys=36.23%, ctx=7072266, majf=0, minf=72
С двумя потоками скорость подросла со 133k до 180k, но ядро перегружено. По top утилизация процессора 100% и clat вырос. То есть 188k — это предел для одного ядра на этой нагрузке. При этом легко видим, что рост clat вызван именно процессором, а не диском. Посмотрим ‘biotop’ ():
PID COMM D MAJ MIN DISK I/O Kbytes AVGus
3553 fio R 259 1 nvme0n1 633385 2533540 109.25
3554 fio R 259 1 nvme0n1 630130 2520520 109.25
Из-за включенной трассировки скорость несколько просела, но время отклика от дисков ~109 мкс, такое же, как и в предыдущем тесте. Измерения другим способом (sar -d) показывают те же цифры.
Ради любопытства, интересно посмотреть, чем занят процессор:
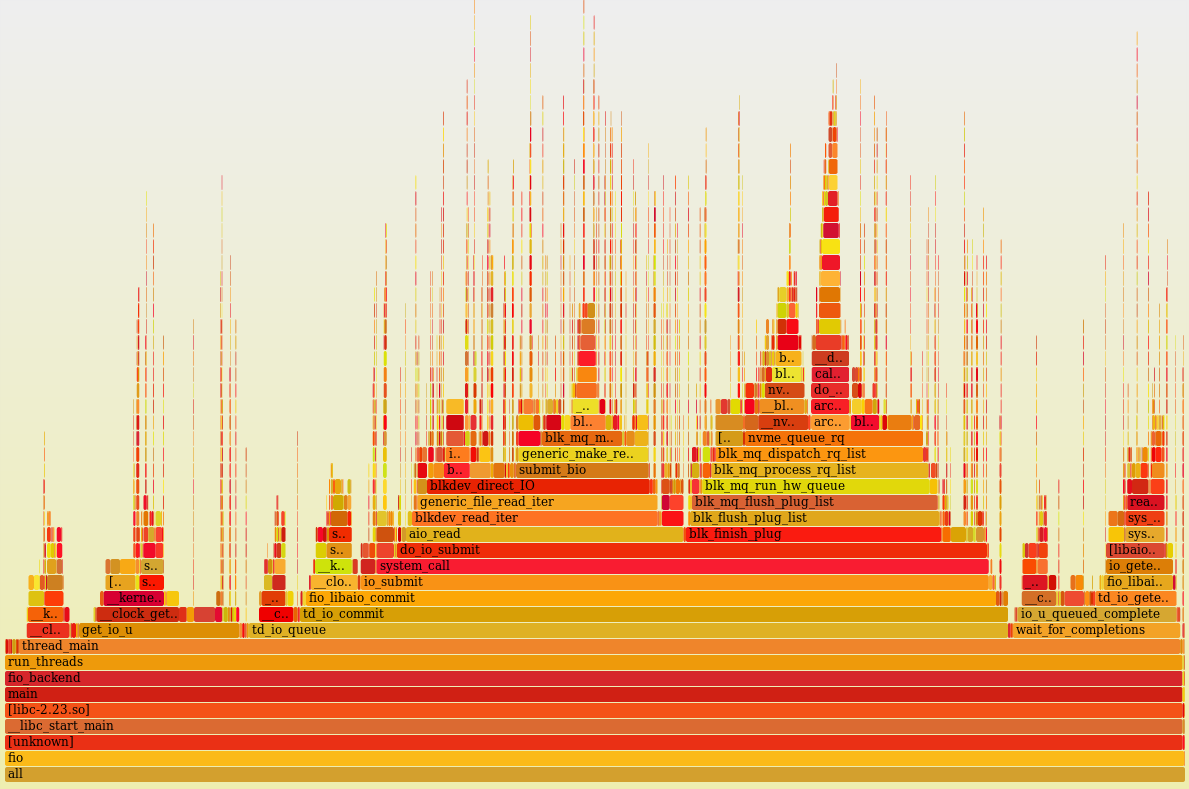
Профиль нагрузки одного ядра (perf + flame graph) с отключённой многопоточностью и работающими двумя процессами fio. Как видно, он 100% времени что-то делает (idle =0%).
Визуально, процессорное время более-менее равномерно распределено между большим количеством пользовательских (код самого fio) и ядерных функций (асинхронный ввод-вывод, блочный уровень, драйвер, много маленьких пиков – это прерывания). Не видно какой-то одной функции, где бы расходовалось аномально большое количество процессорного времени. Выглядит неплохо и, при просмотре стеков в голову не приходит идей, что тут можно было бы покрутить.
Влияние многопоточности POWER8 на скорость ввода-вывода
Итак, мы выяснили, что при активной нагрузке по IO, процессор легко перегрузить. Цифра утилизации процессора показывает, что он занят для операционной системы, но ничего не говорит о загрузке узлов процессора. В том числе, процессор может казаться загруженным во время ожидания внешних компонентов, например, памяти. Здесь у нас нет цели выяснять эффективность использования процессора, но чтобы понять потенциал тюнинга, интересно взглянуть на “CPU counters”, частично доступные через ‘perf’.
root@vesninl:~# perf stat -C 0
Performance counter stats for 'CPU(s) 0':
2393.117988 cpu-clock (msec) # 1.000 CPUs utilized
7,518 context-switches # 0.003 M/sec
0 cpu-migrations # 0.000 K/sec
0 page-faults # 0.000 K/sec
9,248,790,673 cycles # 3.865 GHz (66.57%)
401,873,580 stalled-cycles-frontend # 4.35% frontend cycles idle (49.90%)
4,639,391,312 stalled-cycles-backend # 50.16% backend cycles idle (50.07%)
6,741,772,234 instructions # 0.73 insn per cycle
# 0.69 stalled cycles per insn (66.78%)
1,242,533,904 branches # 519.211 M/sec (50.10%)
19,620,628 branch-misses # 1.58% of all branches (49.93%)
2.393230155 seconds time elapsed
В выводе выше видно, IPC (insn per cycle) 0.73 – не так плохо, но теоретически на Power8 он может быть до 8. Кроме того, 50% “backend cycles idle” (метрика PM_CMPLU_STALL) может значить ожидание памяти. То есть процессор занят для планировщика Linux, но ресурсы самого процессора не особо загружены. Вполне можно ожидать прироста производительности от включения многопоточности (SMT), при увеличении числа потоков. Результат того, что случилось при включении SMT показан на графиках. Я получил ощутимый прирост скорости от дополнительных процессов fio, работающих на других потоках одного и того же процессора. Для сравнения приведён случай, когда все потоки работают на разных ядрах (diff cores).
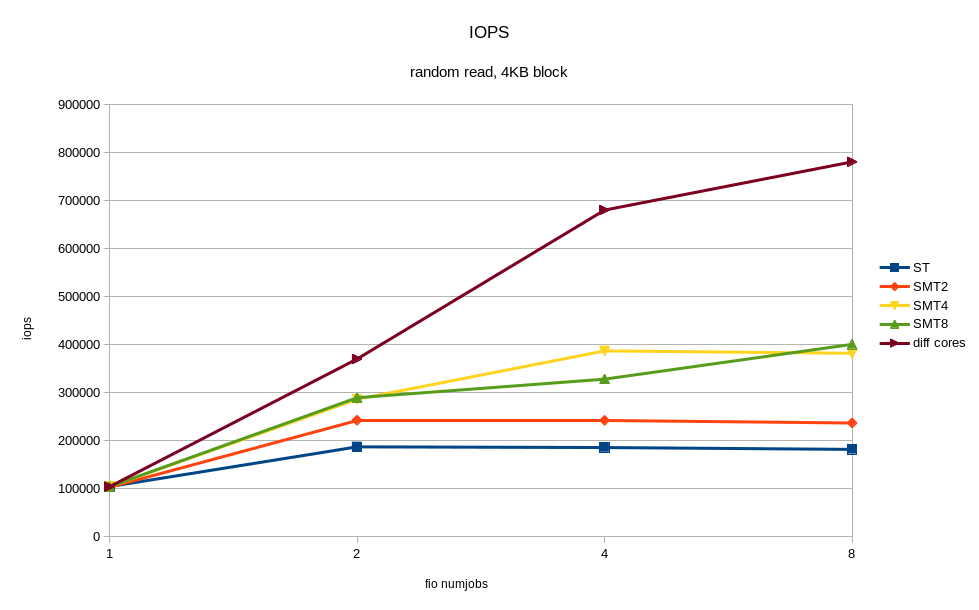
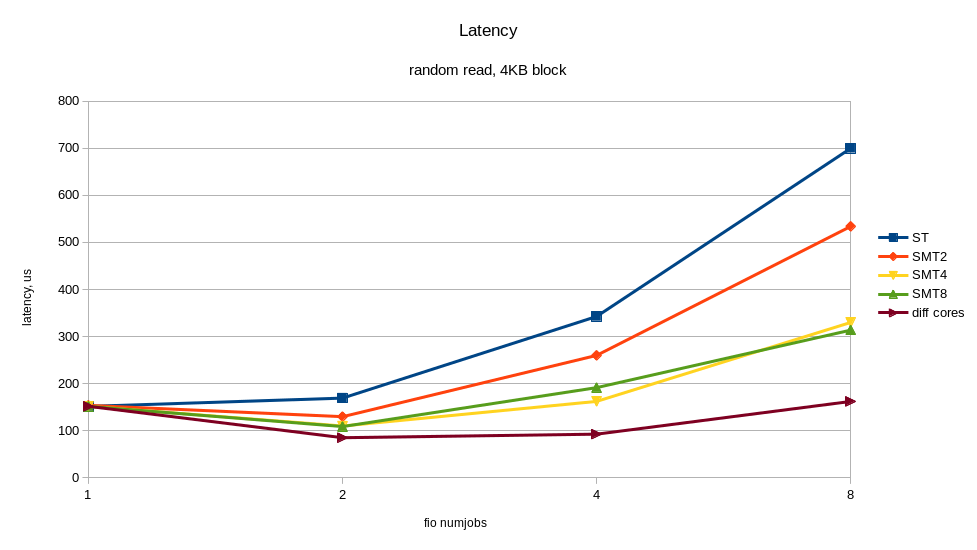
По графикам видно, что включение SMT8 даёт почти двукратный рост скорости и снижение времени отклика. Вполне неплохо и с одного ядра мы снимаем > 400K IOPS! Попутно видим, что одного ядра, даже с включённым SMT8 мало, чтобы полностью нагрузить NVMe диск. Раскидав потоки fio по разным ядрам, мы получаем почти вдвое лучшую производительность диска – это то, что может современный NVMe.
Таким образом, если архитектура приложения позволяет регулировать количество пишущих/читающих процессов, то лучше подстраивать их число под количество физических/логических ядер, во избежание замедлений от перегруженных процессоров. Один NVMe диск может легко перегрузить процессорное ядро. Включение SMT4 и SMT8 даёт кратный прирост производительности и может быть полезно для нагрузок с интенсивным по вводом-выводом.
Влияние NUMA архитектуры
Для балансировки нагрузки 24 внутренних NVMe диска сервера равномерно подключены к четырём процессорным сокетам. Соответственно, для каждого диска есть «родной» сокет (NUMA локальность) и «удалённый». Если приложение обращается к дискам с «удалённого» сокета, то возможны накладные расходы от влияния межпроцессорной шины. Мы решили посмотреть, как доступ с удалённого сокета влияет на итоговую производительность дисков. Для теста снова запускаем fio и с помощью numactl привязываем процессы fio к одному сокету. Сначала к «родному» сокету, потом к «удалённому». Цель теста — понять, стоит ли тратить силы на настройку NUMA, и какого эффекта можно ожидать? На графике я привёл в сравнение только один удалённый сокет из трёх из-за отсутствия между ними разницы.
Конфигурация fio:
- 60 процессов (numjobs). Число взято из аппаратной конфигурации. У нас в тестовом образце установлены процессоры с 8 ядрами и включен SMT8. C точки зрения операционной системы, могут выполняться 64 процесса на каждом сокете. То есть нагрузку я нагло подгонял под аппаратные возможности.
- размер блока — 4kb
- тип нагрузки — случайное чтение 100%
- объект нагрузки — 6 дисков, подключённых к сокету 0.
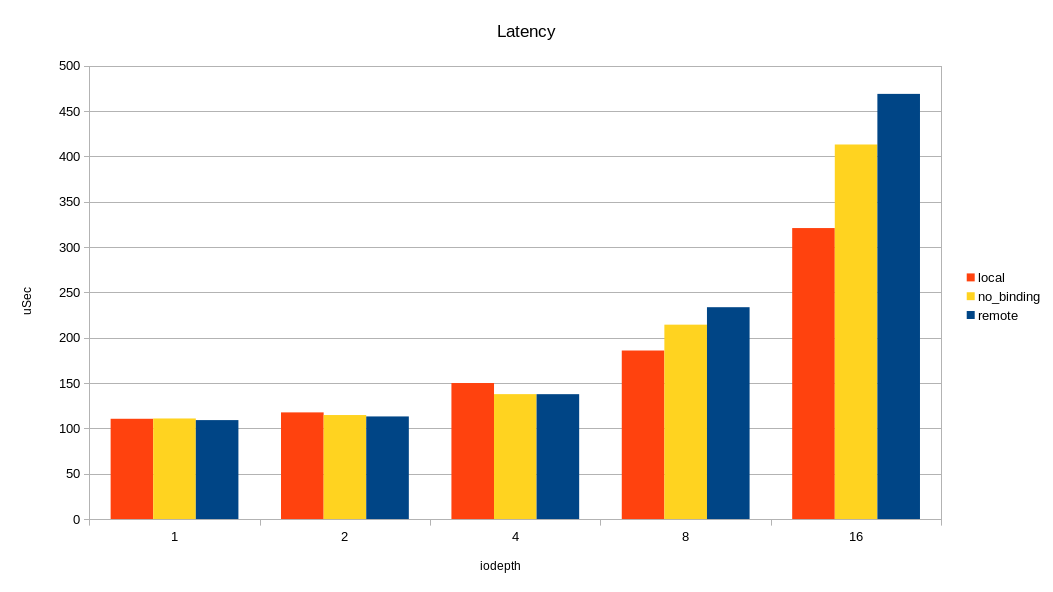
Изменяя очередь, я смотрел пропускную способность и время отклика, запуская нагрузку в локальном сокете, удалённом, и без привязки к сокету вообще.
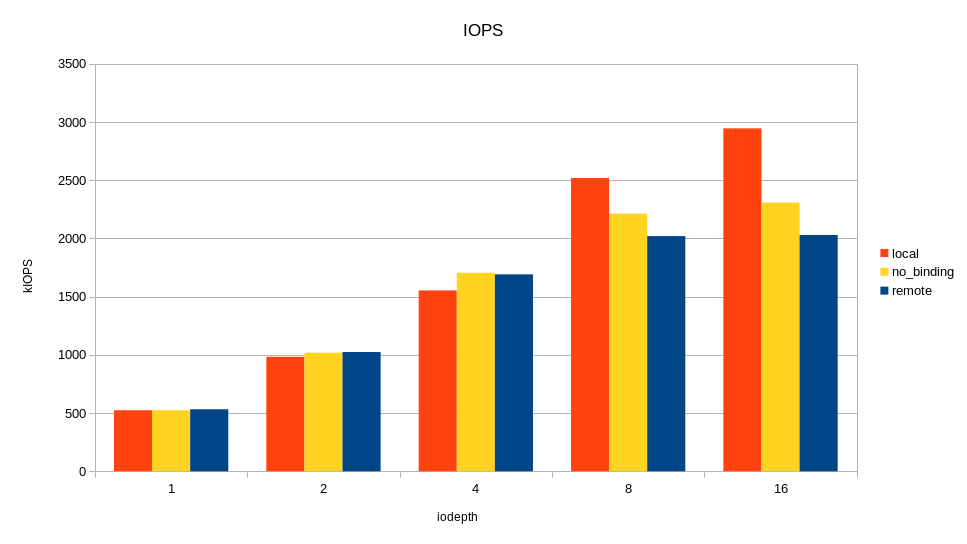
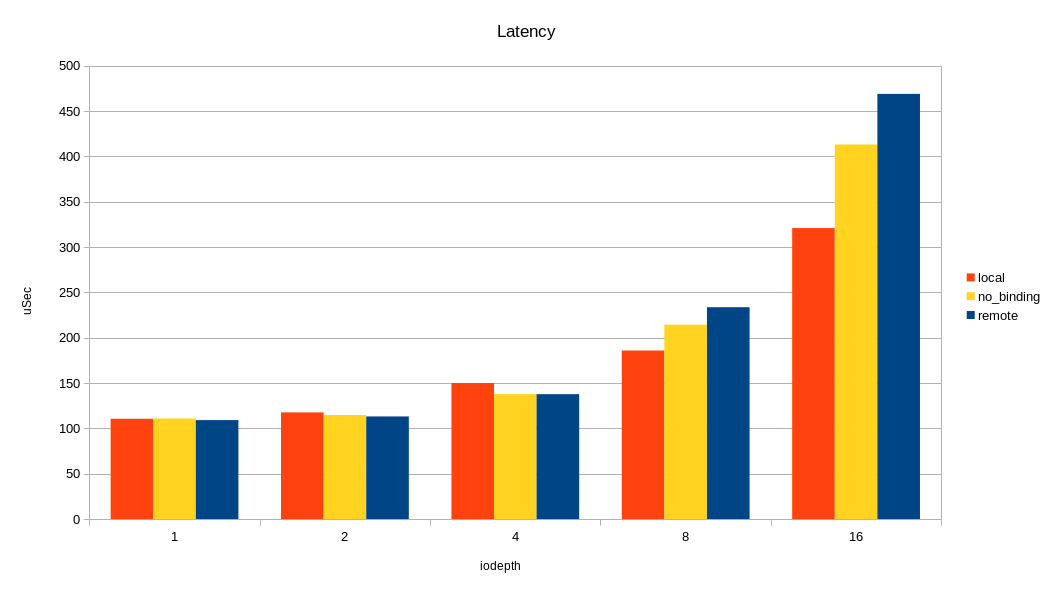
Как видно на графиках, разница между локальным и удалённым сокетом есть и весьма ощутима на большой нагрузке. Накладные расходы проявляются при очереди 16 (iodepth =16) >2M IOPS с блоком 4КБ (> 8 ГБ/с, проще говоря). Можно было бы сделать вывод, что уделять внимание NUMA стоит только на задачах, где нужна большая пропускная способность по вводу-выводу. Но не все так однозначно, в реальном приложении кроме ввода-вывода будет траффик по межпроцессорной шине при доступе к памяти в удалённой NUMA локальности. Как следствие, замедление может наступать и при меньшем трафике по вводу-выводу.
Производительность под максимальной нагрузкой
И теперь, самое интересное. Нагрузим все имеющиеся 12 дисков одновременно. Причём, с учётом предыдущих экспериментов, сделаем это двумя способами:
- ядро выбирает на каком сокете запускать fio без учёта физического подключения;
- fio работает только на том сокете, к которому подключены диски.
Смотрим, что получилось:
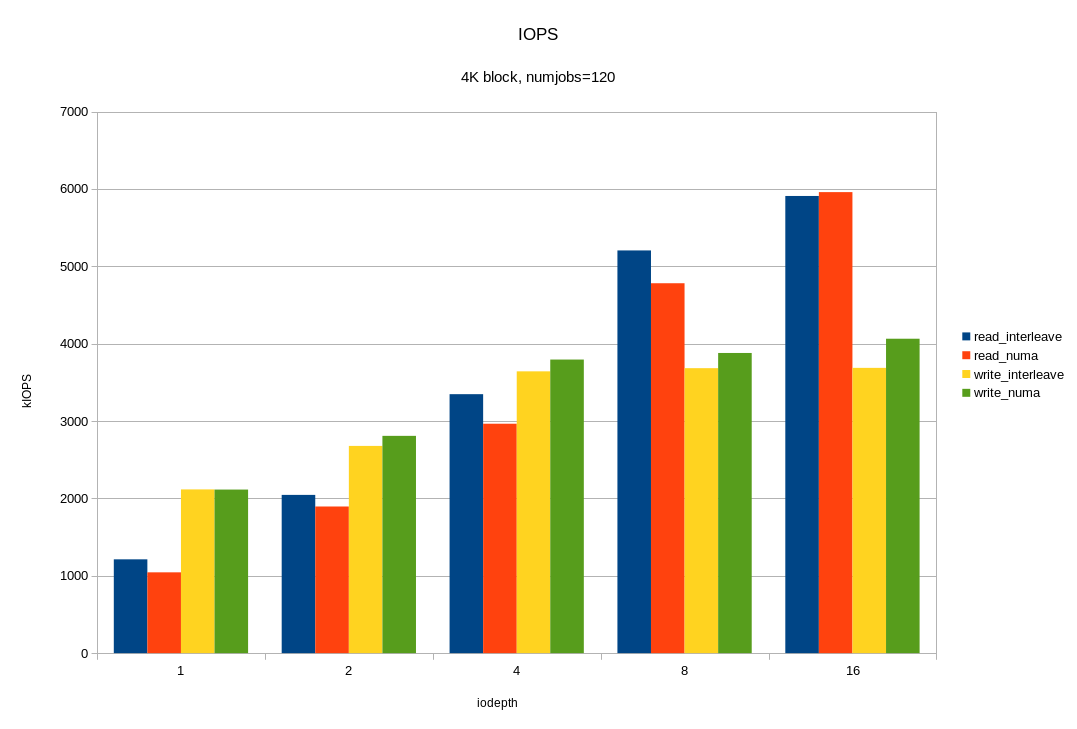
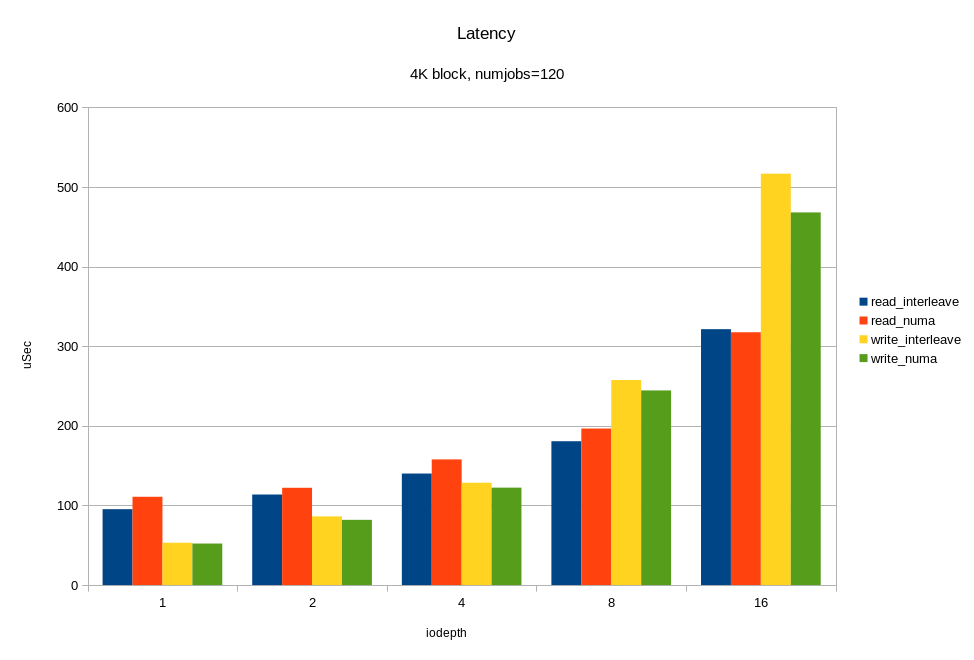
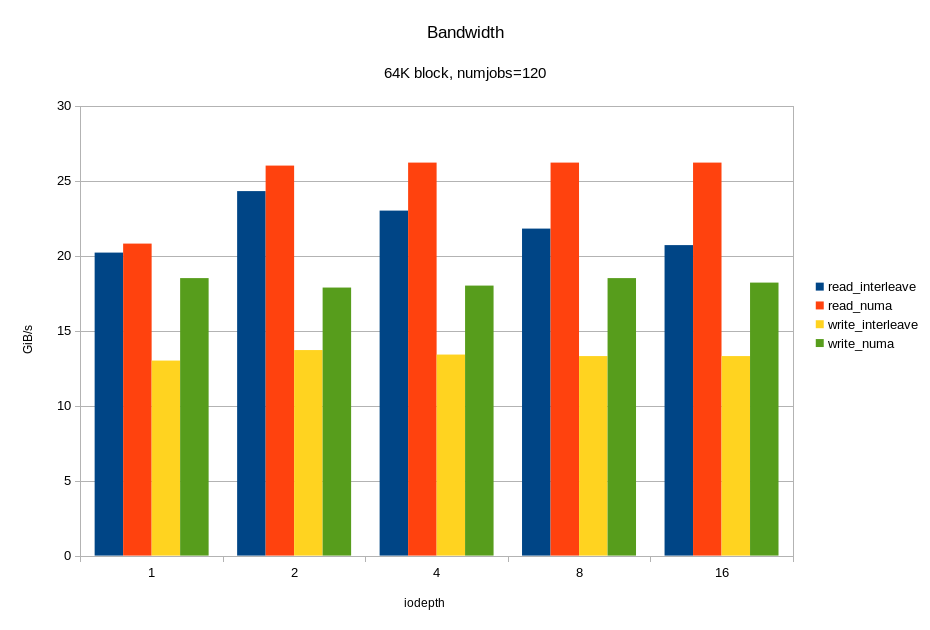
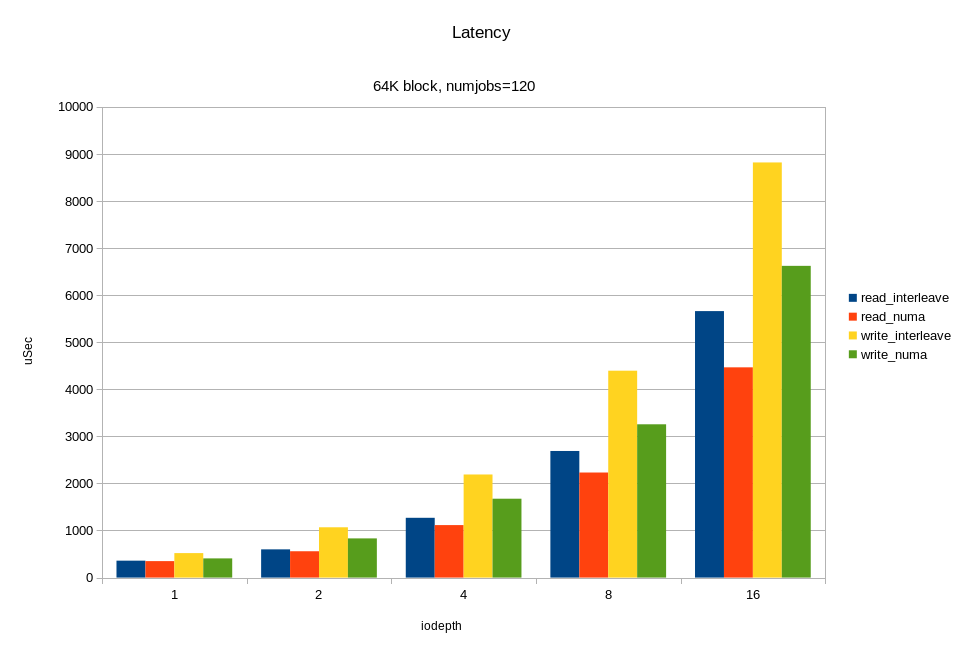
Для операций случайного чтения с блоком 4KB, мы получили ~6M IOPS при времени отклика < 330 мкс. Для блока 64KB мы получили 26.2 ГБ/с. Вероятно, мы упираемся в шину x16 между процессором и PCIe свитчем. Напомню, это половина аппаратной конфигурации! Опять же, видим, что на большой нагрузке привязка ввода-вывода к «домашней» локальности дает хороший эффект.
Накладные расходы LVM
Отдавать диски приложению целиком, как правило, неудобно. Приложению может оказаться либо слишком мало одного диска, либо слишком много. Часто хочется изолировать компоненты приложения друг от друга через разные файловые системы. С другой стороны, хочется равномерно сбалансировать нагрузку между каналами ввода-вывода. На помощь приходит LVM. Диски объединяют в дисковые группы и распределяют пространство между приложениями через логические тома. В случае с обычными шпинделями, или даже с дисковыми массивами, накладные расходы LVM относительно малы в сравнении с задержками от дисков. В случае с NVMe, время отклика от дисков и оверхед программного стека – цифры одного порядка. интересно посмотреть их отдельно.
Я создал LVM-группу с теми же дисками, что и в предыдущем тесте, и нагрузил LVM-том тем же числом читающих потоков. В результате, получил только 1M IOPS и 100% загрузку процессоров. С помощью perf, я сделал профилирование процессоров, и вот что получилось:
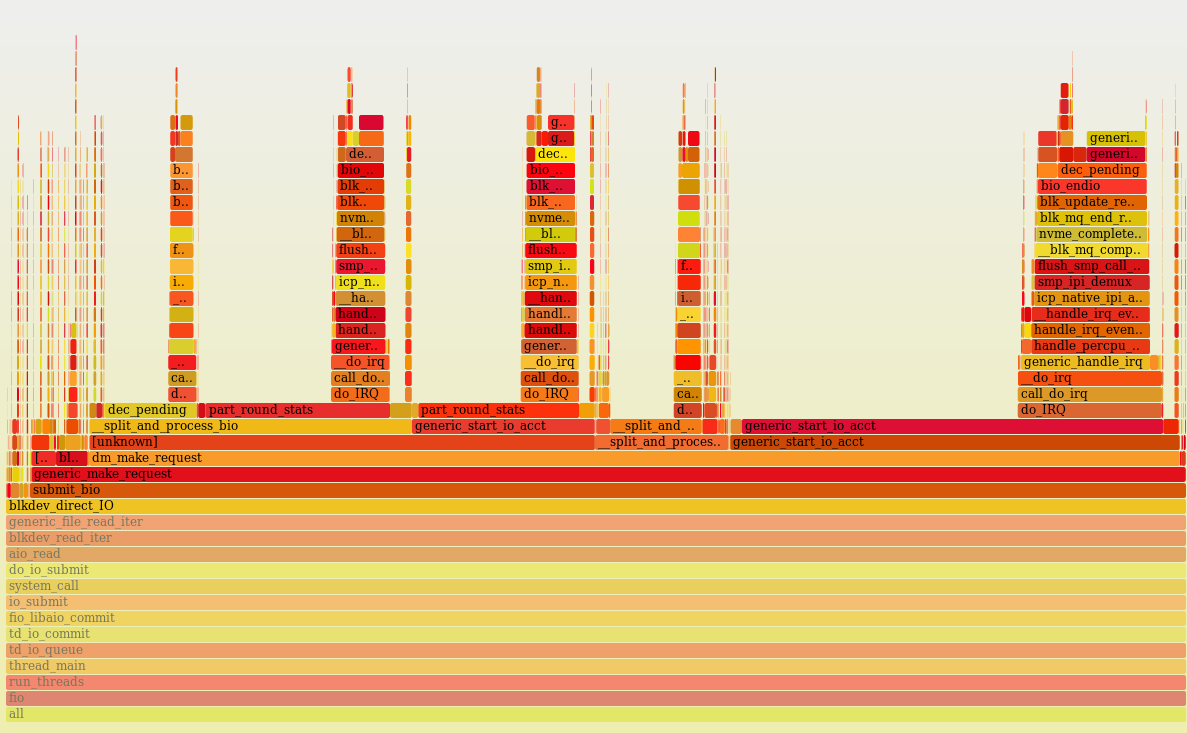
В Linux LVM использует Device Mapper, и очевидно система проводит очень много времени при подсчёте и обновлении статистики по дискам в функции generic_start_io_acct(). Как отключить сбор статистики в Device Mapper я не нашёл, (в dm_make_request() ). Вероятно, тут есть потенциал для оптимизации. В целом, на данный момент, применение Device Mapper может плохо влиять на производительность при большой нагрузке по IOPS.
Поллинг
Поллинг – новый механизм работы работы драйверов ввода вывода Linux для очень быстрых устройств. Это новая фича, и упомяну ее только для того, чтобы сказать почему в данном обзоре она не протестирована. Новизна фичи в том, что процесс не снимается с выполнения во время ожидания ответа от дисковой подсистемы. Переключение контекста обычно выполняется во время ожидания ввода-вывода и затратно само по себе. Накладные расходы на переключение контекста оцениваются в единицы микросекунд (ядру Linux надо снять с выполнения один процесс, вычислить самого достойного кандидата для выполнения и т.д. и т.п.) Прерывания при поллинге могут сохраняться (убирается только переключение контекста) или полностью исключаться. Этот метод оправдан для ряда условий:
- требуется большая производительность для однопоточной задачи;
- основной приоритет – минимальное время отклика;
- используется Direct IO (нет кеширования файловой системы);
- для приложения процессор не является бутылочным горлышком.
Обратная сторона поллинга — это повышение нагрузки на процессор.
В актуальном ядре Linux (для меня сейчас 4.10) поллинг по умолчанию включён для всех NVMe устройств, но работает только для случаев, когда приложение специально просит его использовать для отдельных «особо важных» запросов ввода-вывода. Приложение должно поставить флаг RWF_HIPRI в системных вызовах preadv2()/pwritev2().
/* flags for preadv2/pwritev2: */
#define RWF_HIPRI 0x00000001 /* high priority request, poll if possible */Так как однопоточные приложения не относятся к основной теме статьи, поллинг откладывается на следующий раз.
Заключение
Хотя у нас тестовый образец с половиной конфигурации дисковой подсистемы, результаты впечатляют: почти 6M IOPS блоком 4KB и > 26 ГБ/с для 64KB. Для встроенной дисковой подсистемы сервера это выглядит более чем убедительно. Система выглядит сбалансированной по числу ядер, количеству NVMe дисков на ядро и ширине шины PCIe. Даже с терабайтами памяти, весь объем можно прочитать с дисков за считанные минуты.
Стек NVMe в Linux легковесный, процессор оказывается перегружен только при большой нагрузке fio >400K IOPS, (4KB, read, SMT8).
NVMe диск быстрый сам по себе, и довести его до насыщения приложением достаточно сложно. Больше нет проблемы с медленными дисками, но возможна проблема с ограничениями шины PCIe и программного стека ввода-вывода, а иногда и ресурсами ядра. Во время теста мы именно в диски практически не упирались. Интенсивный ввод-вывод сильно нагружает все подсистемы сервера (память и процессор). Таким образом, для приложений, интенсивных по вводу-выводу, нужна настройка всех подсистем сервера: процессоров (SMT), памяти (интерливинга, к примеру), приложения (количество пишущих/читающих процессов, очередь, привязка к дискам).
Если планируемая нагрузка не требует больших вычислений, но интенсивна по вводу-выводу с маленьким блоком, все равно лучше брать процессоры POWER8 с наибольшим числом ядер из доступной линейки, то есть 12.
Включение в стек ввода-вывода на NVMe дополнительных программных слоев (типа Device Mapper) может ощутимо снижать пиковую производительность.
На большом блоке (>=64KB), привязка IO нагрузки к NUMA локальностям (процессорам), к которым подключены диски, дает снижение времени отклика от дисков и ускоряет ввод-вывод. Причина в том, что на такой нагрузке важна ширина шины от процессора до дисков.
На маленьком блоке (~4KB) все менее однозначно. При привязке нагрузки к локальности есть риск неравномерной загрузки процессоров. То есть можно просто перегрузить сокет, к которому подключены диски и привязана нагрузка.
В любом случае, при организации ввода-вывода, особенно асинхронного, лучше разносить нагрузку по разным ядрам с помощью NUMA-утилит в Linux.
Использование SMT8 сильно повышает производительность при большом числе пишущих/читающих процессов.
Заключительные размышления на тему.
Исторически, подсистема ввода-вывода медленная. С появлением флеша она стала быстрой, а с появлением NVMe совсем быстрой. В традиционных дисках есть механика. Она делает шпиндель самым медленным элементом вычислительного комплекса. Что из этого следует?
- Во-первых, у дисков скорость измеряется в милисекундах, и они многократно медленнее всех остальных элементов сервера. Как следствие, шанс упереться в скорость шины и дискового контроллера относительно невысок. Гораздо более вероятно, что проблема возникнет со шпинделями. Бывает, один диск нагружен больше остальных, время отклика от него чуть выше, и это тормозит всю систему. С NVMe пропускная способность дисков огромная, «бутылочное горлышко» смещается.
- Во вторых, чтобы минимизировать задержки от дисков, дисковый контроллер и операционная система используют алгоритмы оптимизации, в том числе кеширование, отложенную запись, опережающее чтение. Это потребляет вычислительные ресурсы и усложняет настройку. Когда диски сразу быстрые, необходимость в большом количестве оптимизации отпадает. Вернее, ее цели изменяются. Вместо сокращения ожиданий внутри диска, становится более важно сократить задержку до диска и как можно быстрее донести блок данных из памяти в диск. Стек NVMe в Linux не требует настройки и сразу работает быстро.
- И в третьих, забавное о работе консультантов по производительности. В прошлом, когда система тормозила, искать причину было легко и приятно. Ругайся на систему хранения и скорее всего, не ошибёшься. Консультанты по базам данных это дело любят и умеют. В системе, с традиционными дисками всегда можно найти какую-нибудь проблему с производительностью хранилища и озадачить вендора, даже если база данных тормозит из-за чего-то другого. С быстрыми дисками все чаще «бутылочные горлышки» будут смещаться на другие ресурсы, в том числе приложение. Жизнь будет интереснее.
