
Идеальных сервисов не бывает — иногда у пользователя возникают вопросы к техподдержке. Трудно сказать, что в таких случаях неприятнее — попытки сложить из шаблонных реплик бота комбинацию, способную решить проблему, или ожидание ответа специалиста, который уже полдня как вот-вот с вами свяжется.
В Яндекс.Такси из двух вариантов выбрали третий — с помощью машинного интеллекта создать техподдержку с человеческим лицом. Меня зовут Татьяна Савельева, моя группа занимается машинным обучением на неструктурированных данных. Под катом — делюсь пользовательскими инсайтами, рассказываю как автоматизировать сложный процесс, организовать работу совершенно разных команд и, конечно же, применить на практике Deep learning и технические хаки (куда без них).

Казалось бы, зачем изобретать многоступенчатую структуру поддержки — наймите побольше людей. Возможно это сработает, если в поддержку приходит около 10 запросов в день. Но когда число пользовательских обращений стремится к миллиону (что для Яндекс Такси малый процент от поездок, однако абсолют впечатляет), приходится задуматься о более надёжной тактике: найти и обучить достаточное количество операторов, способных справляться с нетипичными проблемами в таких объёмах, как минимум, сложнее.
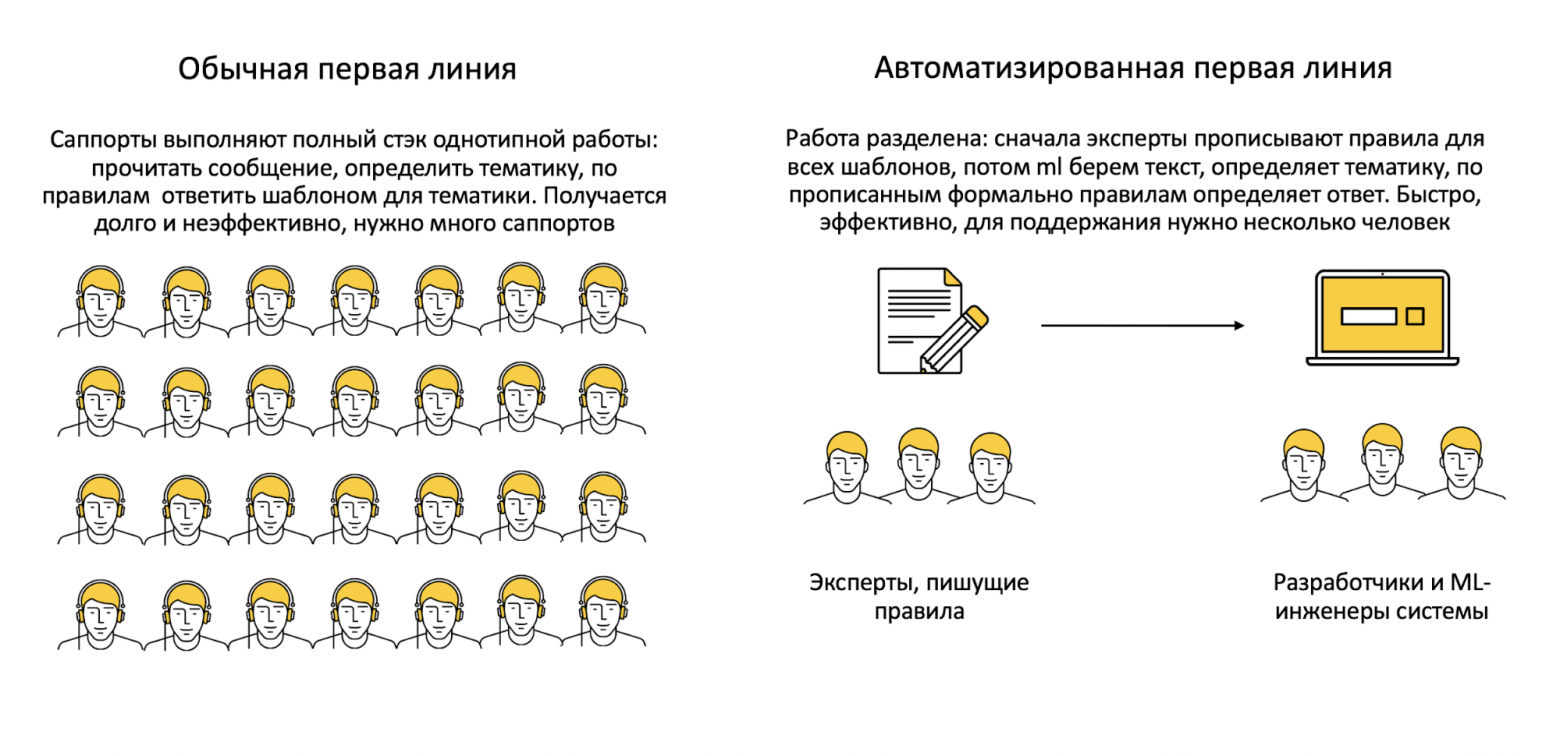
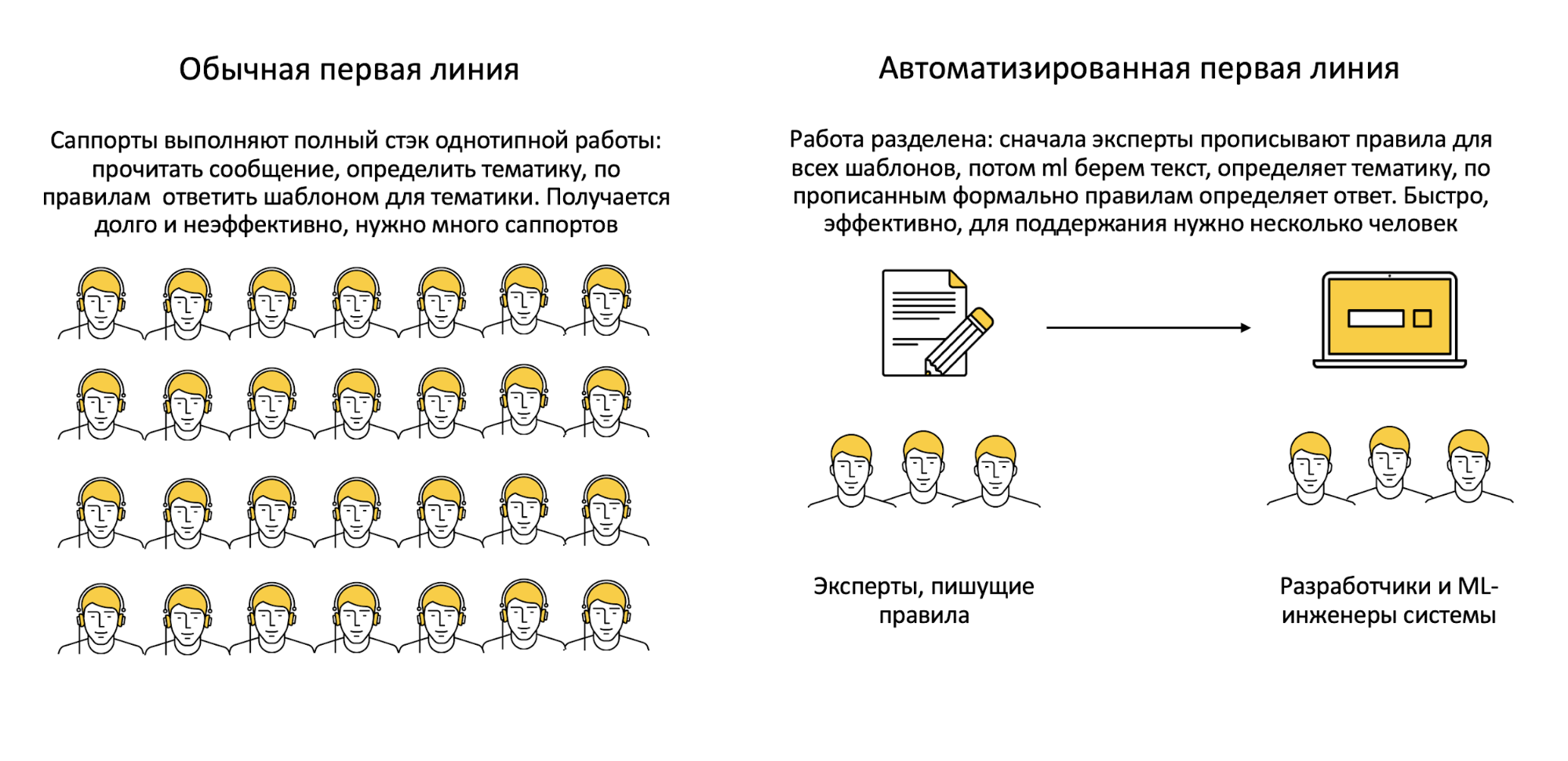
Какое-то время назад в индустрии было принято решать эту задачу с помощью нескольких уровней поддержки. На первом отфильтровывались самые простые, предсказуемые вопросы: если готовый ответ не подходил, проблема классифицировалась и передавалась более квалифицированному эксперту. Элегантно, но есть нюанс.
Растет число обращений — требуется больше времени на их обработку. Пропускная способность операторов, человеческий фактор — мало ли причин, тормозящих систему, где счёт идет на минуты? Многие из этих ограничений можно обойти с помощью машины: она не ошибется, если устанет, да и решения принимает быстрее.
Примерно год назад мы начали применять машинное обучение для того, чтобы сразу подсказывать оператору возможные сценарии взаимодействия. Теперь клиенты получают ответы быстрее. Но нет предела совершенству!
Предположим, вам не повезло: водитель не приехал и не выходит на связь. Что произойдёт с вашим обращением в службу поддержки Яндекс.Такси?

Что можно оптимизировать, чтобы проблемы решались ещё быстрее? Начнём с первого этапа, где тикет направляется на одну из двух линий. Изначально выбор зависел от ключевых слов в запросе — работало, но точность определения была довольно низкой. Исправить это помог классификатор на основе классической нейросетевой модели-энкодера BERT.
В этой задаче фиксируется полнота для экспертных линий: случаи, требующие разбирательства, не должны проходить мимо них. Но не забываем о борьбе за повышение точности: на экспертную линию должно попадать как можно меньше простых обращений, чтобы время отклика на действительно критичные случаи не выходило за пределы терпения пользователя. Точность классификации методами машинного обучения оказалась в 2 раза эффективнее анализа ключевых слов. Скорость реакции на экстренные ситуации повысилась в 1,5 раза.
Пытаться автоматизировать работу экспертной линии в рамках существующих сегодня технологий чревато: логика происходящего плохо поддается систематизации, а любая ошибка будет стоить очень дорого. Вернёмся к типичным, хорошо изученным запросам первой линии — может, доверить их обработку алгоритмам? Так рутинные задачи будут решаться ещё быстрее, а сотрудники смогут больше внимания уделять спорным случаям, выходящим за рамки шаблонов.
Чтобы проверить эту идею, был разработан саджест — система подсказок, предлагающая сотрудникам поддержки 3 наиболее предпочтительных вариантов ответа на текущий запрос:
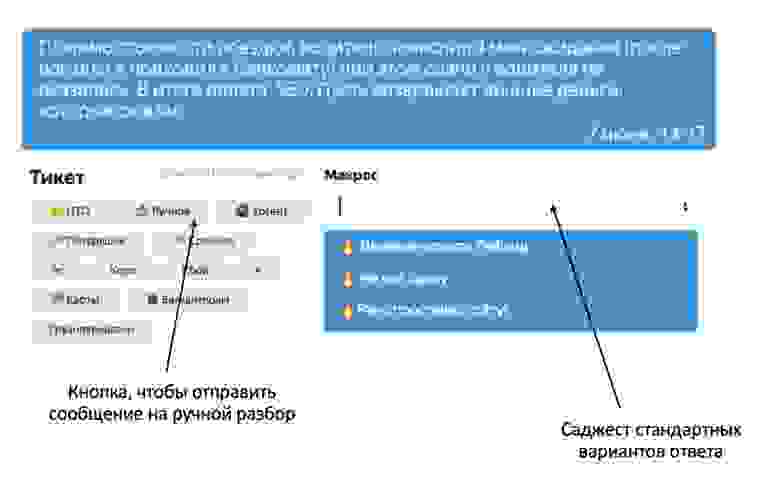
Эксперимент удался: в 70% случаев операторы выбирали одно из предложенных сообщений, что позволило уменьшить время отклика на 10%. Кажется, пора полностью автоматизировать первую линию.
Нужен план. Что делает сотрудник первой линии?
Пример, чтобы проникнуться. Дано: текстовый запрос огорченного пользователя, некоторая информация о поездке, заботливый сотрудник поддержки.

Первым делом сотрудник определит тематику обращения: «Двойное списание с карты». Далее проверит способ оплаты, статус и сумму списания. Деньги списаны один раз: в чём может быть причина? Ага, вот оно: два уведомления подряд.
Что должна делать система автоответов?
Всё то же самое. Даже ключевые требования к ответам не изменятся:
Качество
Если пользователь жалуется на приложение, не нужно обещать попросить водителя помыть машину. Недостаточно понять, в чём именно проблема, надо подробно описать, как её решить.
Скорость
Особенно если ситуация критическая и ответ важен прямо сейчас.
Гибкость и масштабируемость
Задача со звездочкой: хотя началось создание системы поддержки с Такси, полезно перенести результат и на другие сервисы: Яндекс.Еду или Яндекс.Лавку, например. То есть при изменении логики поддержки — шаблонов ответа, тематик обращений и др. — хочется перенастраивать систему за дни, а не месяцы.
Этап 1. Определяем тематику текста с помощью ML
Сначала мы составили дерево тематик обращений и натренировали классификатор ориентироваться в них. Возможных проблем набралось около 200: с поездкой (водитель не приехал), с приложением (не получается привязать карту), с автомобилем (грязная машина) и др.
Как упоминалось выше, мы воспользовались предобученной моделью на основе BERT. То есть для классификации текста запроса нужно представить его в виде векторов так, чтобы похожие по смыслу предложения лежали рядом в получившемся пространстве.
BERT предобучается на двух задачах с неразмеченными текстами. В первой 15% токенов случайным образом заменяются на [MASK], а сеть на основании контекста предсказывает исходные токены — это обеспечивает модели естественную «двунаправленность». Вторая задача учит определять связь между предложениями: два поданных на вход располагались подряд или были разбросаны по тексту?
Дообучив архитектуру BERT на выборке запросов в техподдержку Яндекс.Такси, мы получили сеть, способную предсказывать тематику сообщения с поправкой на специфику нашего сервиса. Однако частота тематик и сами тематики меняются: чтобы сеть обновлялась вместе с ними, отдельно дообучаем только нижние слои модели на самых свежих данных — за последние несколько недель. Так знание особенностей текстов поддержки сохраняется, а вероятности для возможных классов оказываются распределены адекватно текущему дню.
Ещё немного об адекватности: для всех наших сервисов — в том числе Такси — была разработана целая библиотека модулей архитектур моделей и способов валидации порогов вероятностей. Она позволяет:
Этап 2. Работаем с информацией о поездке: прописываем бизнес-правила для каждого шаблона
Сотрудникам поддержки был предложен интерфейс, где для каждого шаблона ответа требуется прописать некоторое обязательное правило. Как это выглядит, например, для случая с двойной оплатой:
Шаблон: «Здравствуйте! Я всё проверил: поездка оплачена один раз. Деньги сперва „замораживаются” на вашей карте и только потом списываются, из-за этого банк может дважды оповестить об одной операции. Пожалуйста, проверьте выписку с банковского счёта, чтобы во всём убедиться. Если увидите там две списанные суммы, пришлите, пожалуйста, скан или фото выписки»
Правило: payment_type is “card” and transaction_status is “clear_success” and transaction_sum == order_cost
Только для шаблонов клиентской поддержки наши эксперты заполнили уже более 1,5 тысяч правил.
Этап 3. Выбираем ответ: соединяем соответствующие тематики текста и бизнес-правила для шаблонов
Каждой тематике ставим в соответствие подходящие шаблоны ответов: тематика определяется методами ML, а откликающиеся на нее шаблоны проверяются на истинность правилом из предыдущего пункта. Пользователь получит ответ, проверка которого выдала значение “True”. Если таких вариантов несколько, будет выбран самый популярный у сотрудников поддержки.
Кстати, процессы взаимодействия с водителями в Яндекс.Такси при этом никак не меняются: модель только выбирает за оператора нужный шаблон и самостоятельно отвечает пользователю.
Ура! Система спроектирована, запуск состоялся, оптимизация показывает прекрасные результаты, но расслабляться еще рано. Автоответы должны стабильно функционировать без постоянного вмешательства и легко масштабироваться — самостоятельно или в полуручном режиме. Этого мы добились благодаря трёхчастной структуре системы:

И снова к примерам. Топ самых популярных хотелок заказчиков (и как мы справляемся с ними без написания кода):
У Такси классные автоответы: хочу такие же в Яндекс.Еде
Чтобы подключить любую поддержку к нашей системе, потребуются четыре простых шага:
Если все это есть, мы зададим путь до новой выгрузки, модель доучится на полученных данных и подтянется в наш микросервис вместе со всеми заданными правилами (интегрируются с определенной ML тематикой). Обратите внимание: никакой новой логики не пишется, все в рамках существующего процесса!
Логика поддержки поменялась, хотим новые правила
Пожалуйста — заполните новые правила в нашей админке. Система проанализирует, как изменения повлияют на процент автоответов*, учитывая, насколько востребовано было правило. Если все прошло успешно, заполненные правила превращаются в конфиг и подгружаются в ML-сервис. Ура! Прошло меньше часа, а бизнес-правила обновлены в production, не написано ни единой строчки кода, программисты не потревожены.
*кажется, это не очень очевидно, поэтому добавим пример в пример. Допустим, эксперты ввели правило: использование некоторого шаблона ответа возможно только для заказов стоимостью выше 200 рублей. Если это ограничение заработает, тикеты для поездок на меньшую сумму останутся незакрытыми, доля автоматических подобранных ответов сократится, КПД всей системы снизится. Чтобы такого не случилось, важно вовремя перехватить неудачные правила и отправить на доработку.
Добавили новую тематику, хотим поменять модель, нужно чтобы завтра все работало.
Часто специалисты по контенту хотят добавить новую тематику, разделить на несколько уже существующую или удалить неактуальную. Без проблем — потребуется изменить в админке соответствие тематик и шаблонов ответов.
Если новые или измененные тематики уже появлялись в ответах сотрудников поддержки первой линии, то модель при регулярном переобучении, автоматически подтянет эти данные и рассчитает для них пороги (на данных за последнюю неделю, за исключением отложенного на тест множества).
На тестовой выборке старая и новая модель сравниваются по специальным метрикам — точность, доля автореплая. Если изменения положительные, в production выкатывается новая модель.
Ориентироваться будем на два критерия — среднюю оценку автоответа пользователем и возникновение дополнительных вопросов. Изменения мониторились в аб-эксперименте, статистически значимой просадки метрик не наблюдалось, более того, зачастую пользователи высоко оценивали результаты работы модели из-за скорости ответа.
Однако как бы мы не старались, методы машинного обучения иногда выдают абсурдные реакции. После очередного обновления модели, мы отловили такой случай:
Пользователь: Спасибо водителю, машина приехала вовремя, водитель молодец, все прошло прекрасно!
Саппорт: Водителя накажем, такого больше не повторится.
Запуск, к счастью, был тестовый. А проблема была в следующем: модель училась отвечать на отзывы с рейтингом меньше 4, а мы иногда по ошибке показывали ей отзывы с 4 и 5 звёздами. Разумеется, из-за ограничений при обучении, ничего более умного нейронка ответить и не могла. При внедрении такие случаи редки (0.1% от общего количества) — отслеживаем их и принимаем соответствующие меры: на повторное сообщение пользователя ответит уже не нейросеть.
После подключения системы автоматических ответов мы стали значительно быстрее реагировать на обращения пользователей и уделять максимум внимания действительно сложным случаям, требующим детального разбирательства. Надеемся, что это поможет нам улучшить качество Яндекс.Такси и минимизировать количество неприятных инцидентов.
Модель автореплая закрывает порядка 60% первой линии, не просаживая при этом среднюю оценку пользователей. Планируем и дальше развивать метод и довести процент использования автоответов на первой линии до 99.9%. Ну и, конечно же, продолжать помогать вам — поддерживать в наших приложениях и делиться опытом об этом на Хабре.
В Яндекс.Такси из двух вариантов выбрали третий — с помощью машинного интеллекта создать техподдержку с человеческим лицом. Меня зовут Татьяна Савельева, моя группа занимается машинным обучением на неструктурированных данных. Под катом — делюсь пользовательскими инсайтами, рассказываю как автоматизировать сложный процесс, организовать работу совершенно разных команд и, конечно же, применить на практике Deep learning и технические хаки (куда без них).

Зачем вообще что-то автоматизировать?
Казалось бы, зачем изобретать многоступенчатую структуру поддержки — наймите побольше людей. Возможно это сработает, если в поддержку приходит около 10 запросов в день. Но когда число пользовательских обращений стремится к миллиону (что для Яндекс Такси малый процент от поездок, однако абсолют впечатляет), приходится задуматься о более надёжной тактике: найти и обучить достаточное количество операторов, способных справляться с нетипичными проблемами в таких объёмах, как минимум, сложнее.
Какое-то время назад в индустрии было принято решать эту задачу с помощью нескольких уровней поддержки. На первом отфильтровывались самые простые, предсказуемые вопросы: если готовый ответ не подходил, проблема классифицировалась и передавалась более квалифицированному эксперту. Элегантно, но есть нюанс.
Растет число обращений — требуется больше времени на их обработку. Пропускная способность операторов, человеческий фактор — мало ли причин, тормозящих систему, где счёт идет на минуты? Многие из этих ограничений можно обойти с помощью машины: она не ошибется, если устанет, да и решения принимает быстрее.
Примерно год назад мы начали применять машинное обучение для того, чтобы сразу подсказывать оператору возможные сценарии взаимодействия. Теперь клиенты получают ответы быстрее. Но нет предела совершенству!
С чего начать?
Предположим, вам не повезло: водитель не приехал и не выходит на связь. Что произойдёт с вашим обращением в службу поддержки Яндекс.Такси?

Что можно оптимизировать, чтобы проблемы решались ещё быстрее? Начнём с первого этапа, где тикет направляется на одну из двух линий. Изначально выбор зависел от ключевых слов в запросе — работало, но точность определения была довольно низкой. Исправить это помог классификатор на основе классической нейросетевой модели-энкодера BERT.
В этой задаче фиксируется полнота для экспертных линий: случаи, требующие разбирательства, не должны проходить мимо них. Но не забываем о борьбе за повышение точности: на экспертную линию должно попадать как можно меньше простых обращений, чтобы время отклика на действительно критичные случаи не выходило за пределы терпения пользователя. Точность классификации методами машинного обучения оказалась в 2 раза эффективнее анализа ключевых слов. Скорость реакции на экстренные ситуации повысилась в 1,5 раза.
Пытаться автоматизировать работу экспертной линии в рамках существующих сегодня технологий чревато: логика происходящего плохо поддается систематизации, а любая ошибка будет стоить очень дорого. Вернёмся к типичным, хорошо изученным запросам первой линии — может, доверить их обработку алгоритмам? Так рутинные задачи будут решаться ещё быстрее, а сотрудники смогут больше внимания уделять спорным случаям, выходящим за рамки шаблонов.
Чтобы проверить эту идею, был разработан саджест — система подсказок, предлагающая сотрудникам поддержки 3 наиболее предпочтительных вариантов ответа на текущий запрос:
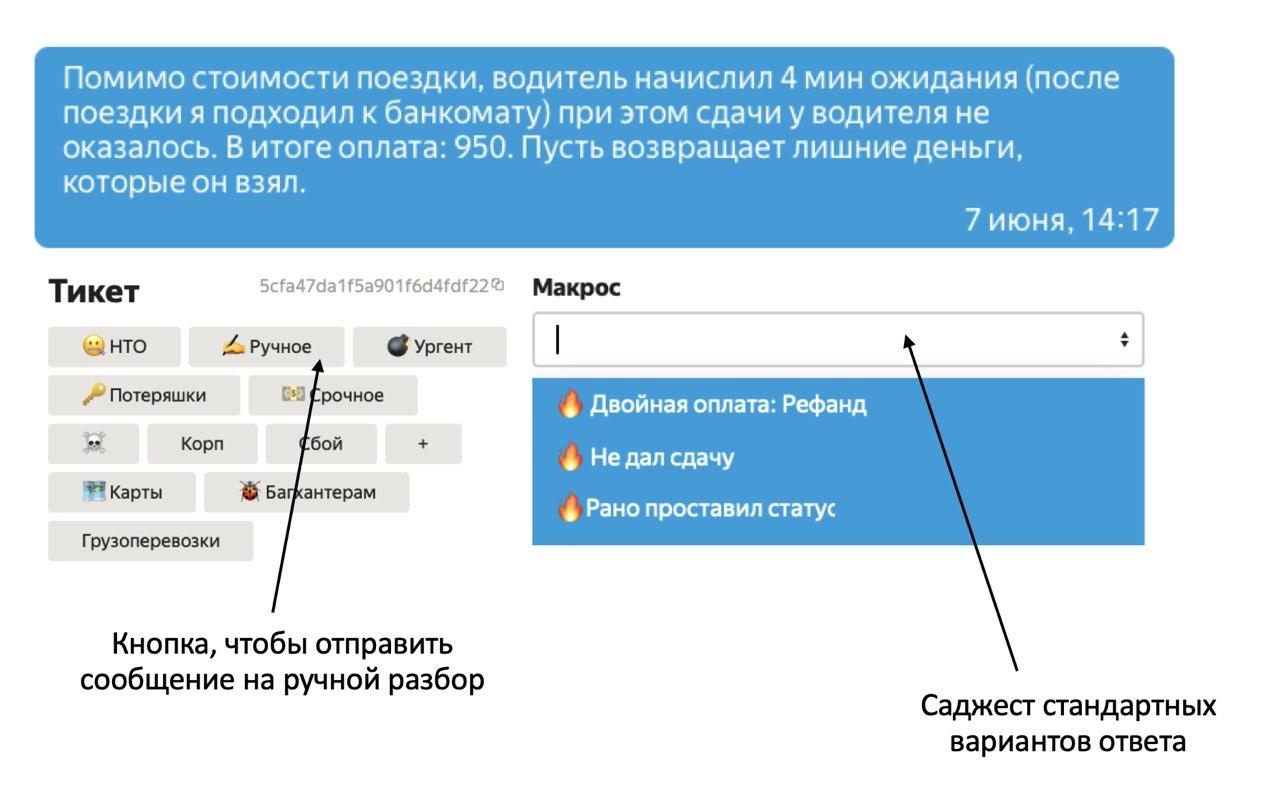
Эксперимент удался: в 70% случаев операторы выбирали одно из предложенных сообщений, что позволило уменьшить время отклика на 10%. Кажется, пора полностью автоматизировать первую линию.
Нужен план. Что делает сотрудник первой линии?
- Читает текст, определяет тематику обращения.
- Изучает информацию о поездке.
- Выбирает один из заготовленных ответов с учетом первых двух пунктов.
Пример, чтобы проникнуться. Дано: текстовый запрос огорченного пользователя, некоторая информация о поездке, заботливый сотрудник поддержки.

Первым делом сотрудник определит тематику обращения: «Двойное списание с карты». Далее проверит способ оплаты, статус и сумму списания. Деньги списаны один раз: в чём может быть причина? Ага, вот оно: два уведомления подряд.
Что должна делать система автоответов?
Всё то же самое. Даже ключевые требования к ответам не изменятся:
Качество
Если пользователь жалуется на приложение, не нужно обещать попросить водителя помыть машину. Недостаточно понять, в чём именно проблема, надо подробно описать, как её решить.
Скорость
Особенно если ситуация критическая и ответ важен прямо сейчас.
Гибкость и масштабируемость
Задача со звездочкой: хотя началось создание системы поддержки с Такси, полезно перенести результат и на другие сервисы: Яндекс.Еду или Яндекс.Лавку, например. То есть при изменении логики поддержки — шаблонов ответа, тематик обращений и др. — хочется перенастраивать систему за дни, а не месяцы.
Как это реализовано
Этап 1. Определяем тематику текста с помощью ML
Сначала мы составили дерево тематик обращений и натренировали классификатор ориентироваться в них. Возможных проблем набралось около 200: с поездкой (водитель не приехал), с приложением (не получается привязать карту), с автомобилем (грязная машина) и др.
Как упоминалось выше, мы воспользовались предобученной моделью на основе BERT. То есть для классификации текста запроса нужно представить его в виде векторов так, чтобы похожие по смыслу предложения лежали рядом в получившемся пространстве.
BERT предобучается на двух задачах с неразмеченными текстами. В первой 15% токенов случайным образом заменяются на [MASK], а сеть на основании контекста предсказывает исходные токены — это обеспечивает модели естественную «двунаправленность». Вторая задача учит определять связь между предложениями: два поданных на вход располагались подряд или были разбросаны по тексту?
Дообучив архитектуру BERT на выборке запросов в техподдержку Яндекс.Такси, мы получили сеть, способную предсказывать тематику сообщения с поправкой на специфику нашего сервиса. Однако частота тематик и сами тематики меняются: чтобы сеть обновлялась вместе с ними, отдельно дообучаем только нижние слои модели на самых свежих данных — за последние несколько недель. Так знание особенностей текстов поддержки сохраняется, а вероятности для возможных классов оказываются распределены адекватно текущему дню.
Ещё немного об адекватности: для всех наших сервисов — в том числе Такси — была разработана целая библиотека модулей архитектур моделей и способов валидации порогов вероятностей. Она позволяет:
- экспериментировать, исходя из особенностей конкретной поддержки: для иерархической структуры классов подобрать архитектуру с кастомными слоями, для входных данных разных типов — умеющую обрабатывать нетекстовую информацию;
- убедиться, что модель достаточно уверена в предсказанном классе и не ляпнет пользователю глупость. За это отвечает модуль с функциями, валидирующими пороги вероятностей. Например, исходя из ограничений точности определения класса запроса, можно задать порог, который будет соответствовать точности работы сотрудника поддержки.
Этап 2. Работаем с информацией о поездке: прописываем бизнес-правила для каждого шаблона
Сотрудникам поддержки был предложен интерфейс, где для каждого шаблона ответа требуется прописать некоторое обязательное правило. Как это выглядит, например, для случая с двойной оплатой:
Шаблон: «Здравствуйте! Я всё проверил: поездка оплачена один раз. Деньги сперва „замораживаются” на вашей карте и только потом списываются, из-за этого банк может дважды оповестить об одной операции. Пожалуйста, проверьте выписку с банковского счёта, чтобы во всём убедиться. Если увидите там две списанные суммы, пришлите, пожалуйста, скан или фото выписки»
Правило: payment_type is “card” and transaction_status is “clear_success” and transaction_sum == order_cost
Только для шаблонов клиентской поддержки наши эксперты заполнили уже более 1,5 тысяч правил.
Этап 3. Выбираем ответ: соединяем соответствующие тематики текста и бизнес-правила для шаблонов
Каждой тематике ставим в соответствие подходящие шаблоны ответов: тематика определяется методами ML, а откликающиеся на нее шаблоны проверяются на истинность правилом из предыдущего пункта. Пользователь получит ответ, проверка которого выдала значение “True”. Если таких вариантов несколько, будет выбран самый популярный у сотрудников поддержки.
Кстати, процессы взаимодействия с водителями в Яндекс.Такси при этом никак не меняются: модель только выбирает за оператора нужный шаблон и самостоятельно отвечает пользователю.
Финализируем
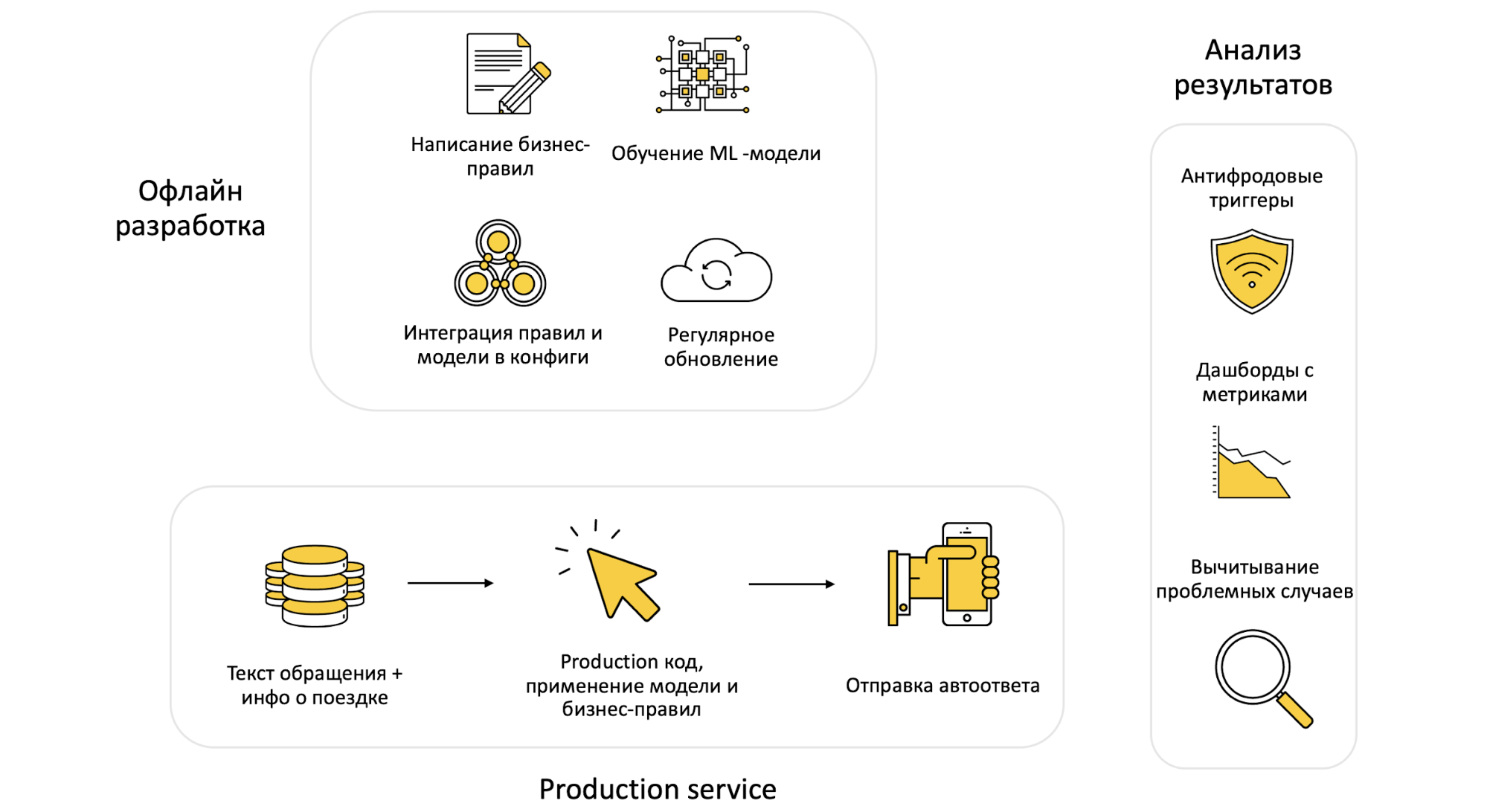
Ура! Система спроектирована, запуск состоялся, оптимизация показывает прекрасные результаты, но расслабляться еще рано. Автоответы должны стабильно функционировать без постоянного вмешательства и легко масштабироваться — самостоятельно или в полуручном режиме. Этого мы добились благодаря трёхчастной структуре системы:
- Оффлайн-разработка — на этой стадии изменяются модели, готовятся правила;
- Production service — микросервис, который подхватывает обновления, применяет их и отвечает пользователям в реальном времени;
- Последующий анализ результатов, чтобы убедиться — новая модель работает корректно, пользователи довольны автоответами.
И снова к примерам. Топ самых популярных хотелок заказчиков (и как мы справляемся с ними без написания кода):
У Такси классные автоответы: хочу такие же в Яндекс.Еде
Чтобы подключить любую поддержку к нашей системе, потребуются четыре простых шага:
- Составить дерево тематик для текстов;
- Каждой тематике поставить в соответствие шаблоны;
- Заполнить набор правил с шаблонами в нашей админке;
- Предоставить таблицу соответствий между обращениями пользователей и ответами поддержки.
Если все это есть, мы зададим путь до новой выгрузки, модель доучится на полученных данных и подтянется в наш микросервис вместе со всеми заданными правилами (интегрируются с определенной ML тематикой). Обратите внимание: никакой новой логики не пишется, все в рамках существующего процесса!
Логика поддержки поменялась, хотим новые правила
Пожалуйста — заполните новые правила в нашей админке. Система проанализирует, как изменения повлияют на процент автоответов*, учитывая, насколько востребовано было правило. Если все прошло успешно, заполненные правила превращаются в конфиг и подгружаются в ML-сервис. Ура! Прошло меньше часа, а бизнес-правила обновлены в production, не написано ни единой строчки кода, программисты не потревожены.
*кажется, это не очень очевидно, поэтому добавим пример в пример. Допустим, эксперты ввели правило: использование некоторого шаблона ответа возможно только для заказов стоимостью выше 200 рублей. Если это ограничение заработает, тикеты для поездок на меньшую сумму останутся незакрытыми, доля автоматических подобранных ответов сократится, КПД всей системы снизится. Чтобы такого не случилось, важно вовремя перехватить неудачные правила и отправить на доработку.
Добавили новую тематику, хотим поменять модель, нужно чтобы завтра все работало.
Часто специалисты по контенту хотят добавить новую тематику, разделить на несколько уже существующую или удалить неактуальную. Без проблем — потребуется изменить в админке соответствие тематик и шаблонов ответов.
Если новые или измененные тематики уже появлялись в ответах сотрудников поддержки первой линии, то модель при регулярном переобучении, автоматически подтянет эти данные и рассчитает для них пороги (на данных за последнюю неделю, за исключением отложенного на тест множества).
На тестовой выборке старая и новая модель сравниваются по специальным метрикам — точность, доля автореплая. Если изменения положительные, в production выкатывается новая модель.
Анализируем метрики: не просадить, не сломать
Ориентироваться будем на два критерия — среднюю оценку автоответа пользователем и возникновение дополнительных вопросов. Изменения мониторились в аб-эксперименте, статистически значимой просадки метрик не наблюдалось, более того, зачастую пользователи высоко оценивали результаты работы модели из-за скорости ответа.
Однако как бы мы не старались, методы машинного обучения иногда выдают абсурдные реакции. После очередного обновления модели, мы отловили такой случай:
Пользователь: Спасибо водителю, машина приехала вовремя, водитель молодец, все прошло прекрасно!
Саппорт: Водителя накажем, такого больше не повторится.
Запуск, к счастью, был тестовый. А проблема была в следующем: модель училась отвечать на отзывы с рейтингом меньше 4, а мы иногда по ошибке показывали ей отзывы с 4 и 5 звёздами. Разумеется, из-за ограничений при обучении, ничего более умного нейронка ответить и не могла. При внедрении такие случаи редки (0.1% от общего количества) — отслеживаем их и принимаем соответствующие меры: на повторное сообщение пользователя ответит уже не нейросеть.
О выводах и планах на будущее
После подключения системы автоматических ответов мы стали значительно быстрее реагировать на обращения пользователей и уделять максимум внимания действительно сложным случаям, требующим детального разбирательства. Надеемся, что это поможет нам улучшить качество Яндекс.Такси и минимизировать количество неприятных инцидентов.
Модель автореплая закрывает порядка 60% первой линии, не просаживая при этом среднюю оценку пользователей. Планируем и дальше развивать метод и довести процент использования автоответов на первой линии до 99.9%. Ну и, конечно же, продолжать помогать вам — поддерживать в наших приложениях и делиться опытом об этом на Хабре.
