
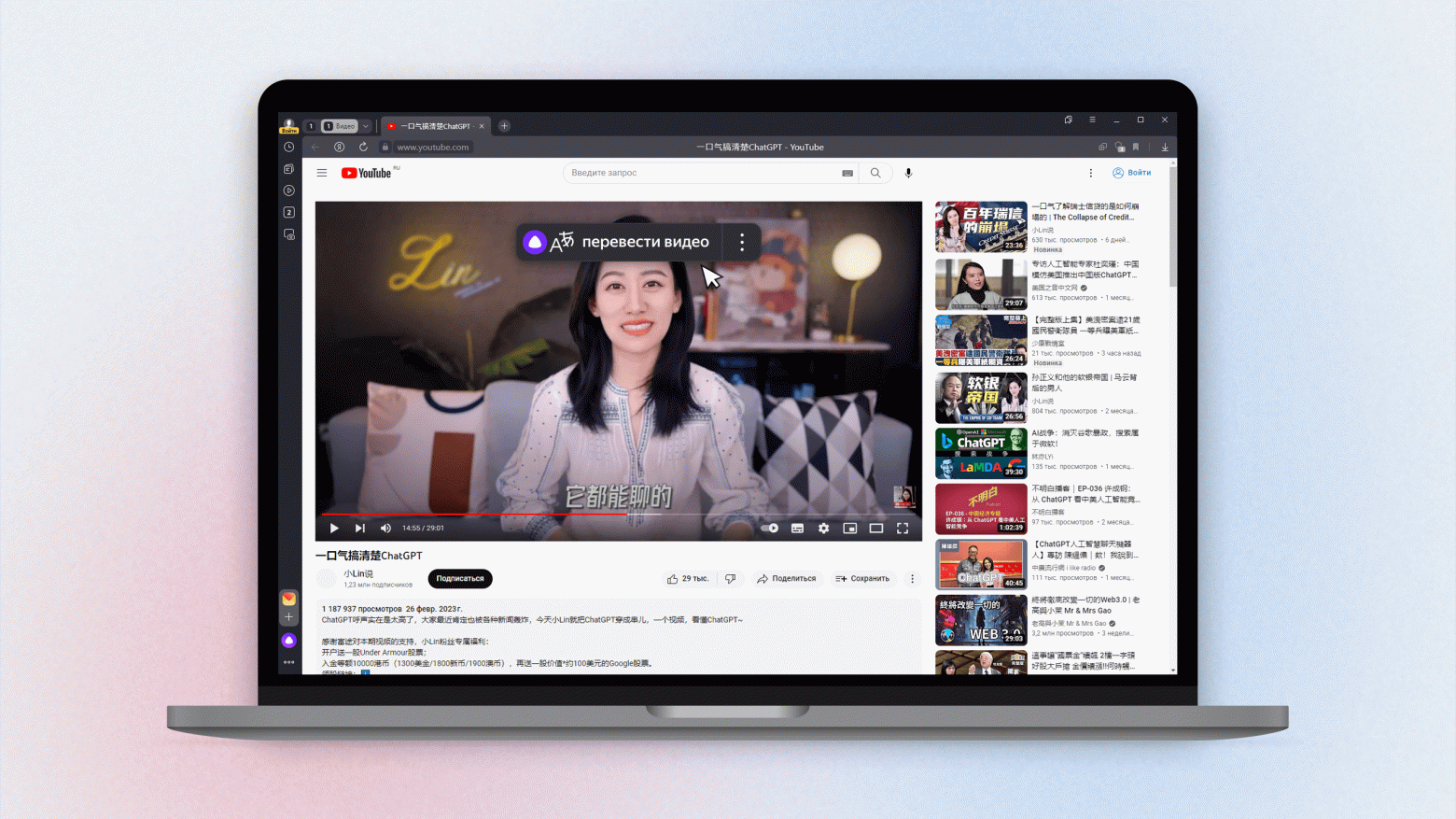
Привет, меня зовут Артур Яковлев, я делаю голосовой перевод видео в Яндекс Браузере. Примерно с лета я работаю над тем, чтобы научить Браузер переводить с китайского на русский. Почему мы посчитали это важной и интересной задачей? Дело в том, что китайская часть интернета содержит значительное количество видеоконтента, который за пределами страны почти не смотрят.
Множество диалектов, влияющие на смысл тоны и грамматические нюансы — ряд особенностей китайского усложняют разработку распознавания речи. Сейчас я коротко расскажу читателям Хабра о трудностях языка и объясню, как мы их преодолели.
С чего мы начинали
Есть множество региональных языков и групп диалектов: кантонский, хакка, минь и другие. Они сильно отличаются, и их носители даже не всегда понимают друг друга. Самый распространенный вариант — севернокитайский язык. На Западе он известен как мандаринский. Им владеет почти миллиард человек, и это больше 70% населения Китая. Поэтому для перевода видео наша команда выбрала именно его. В нём примерно 400 основных слогов — и это без учёта тонов. Кстати, слоги не равны иероглифам, но об этом чуть позже.
Что мы сделали: пайплайн обучения мы отработали на множестве языков. Он отлажен для случаев, когда есть готовый качественный датасет. Для китайского готового датасета не было, так что пришлось собирать его.
Самый сложный этап — найти много размеченных данных с текстами и привести их в нужный вид. В случае китайского было важно разделять диалекты и проверять валидность данных. Вот как мы построили работу:
- Поскольку мы хотим переводить видео, то и учиться распознавать речь нужно на видео. Поэтому взяли несколько тысяч часов видео, для которых есть китайские субтитры.
- Отфильтровали по языку. Часто китайские субтитры можно встретить для роликов на английском языке. Используем классификатор, который знает несколько китайских диалектов.
- Достали из видео все куски с голосом на основе субтитров в VTT-формате, который содержит фразы со временем их начала и конца. Текст в субтитрах сам по себе довольно шумный – там могут быть цифры, даты, символы процентов и так далее. Данные нужно нормализовывать. Для этого использовали готовую библиотеку.
- Нарезали видео на чанки в соответствии с субтитрами.
- Отфильтровали видео по субтитрам. Проблема в том, что в субтитрах не всегда написана правда. Если субтитры отмечены как китайские, это не значит, что они действительно на китайском. Кроме того, в них бывают сдвинуты тайминги, они могут описывать происходящее на экране и т.д. Справиться с этим помогла модель с Hugging Face, обученная на мандаринском диалекте. С её помощью мы оценили субтитры и отобрали подходящие для обучения нашей модели.
- В результате получили набор видео с хорошими субтитрами, валидными для обучения акустической модели.
Иероглифическая, а не алфавитная письменность
Чтобы перевести видео, сначала нужно распознать речь и превратить её в текст — поэтому важно разбираться в письменности исходного языка. В китайском она совершенно не похожа на привычный русский или английский языки, ведь в нём нет алфавита.
Вместо него есть десятки тысяч иероглифов, из которых можно составлять слова и фразы — как из конструктора. Например, слово «компьютер» записывается двумя иероглифами: «электронный» и «мозг». Довольно логично! Каждый иероглиф читается как слог, при этом многие иероглифы произносятся одинаково, поэтому их число намного больше слогов (это называется омофонией и представляет отдельную особенность; дальше расскажу о ней подробнее). Впрочем, все 20 тысяч иероглифов мало кто знает наизусть — для нормального общения людям хватает и пары тысяч.
А ещё в китайском языке нет привычного для европейской письменности разделения на слова, а текст выглядит как сплошная последовательность иероглифов.
Что мы сделали: парадоксально, но система китайской письменности, которая порой ставит в тупик иностранцев, вообще не стала проблемой для обучения модели. Она использует словарь токенов — по сути, слогов. Если все европейские языки помещаются в 5000 токенов, то наш словарь для китайского — это 10 000 токенов. Разница только в объёме. Для токенизации используем распространённый алгоритм BPE. Размер словаря выбрали с учётом того, чтобы часто используемые комбинации иероглифов были объединены в один токен — это может помочь при декодировании и понимании контекста.
А вот отсутствие деления на слова немного усложнило нам жизнь. В одной части данных, которые мы использовали для обучения моделей, были пробелы между словами, в другой их не было. Помнив о том, что в китайской письменности нет деления на слова, мы просто выкинули везде пробелы, чтобы унифицировать датасеты. Это была ошибка, ведь наша инфраструктура опирается на пробелы, чтобы расставлять алайнменты — то есть, метки времени для фрагментов текста. В итоге ASR выдавала распознанный текст с неправильными метками. Мы решили проблему, применив на этапе предобработки данных библиотеку, которая расставила пробелы. Получилось условное разделение на «слова», которое помогло верно расставить алайнменты.
Тоны определяют смысл
Произношение — ключевая характеристика китайской речи. Дело в том, что слова меняют смысл в зависимости от того, как их произнести. Тон — это мелодический рисунок голоса. Выделяют четыре основных тона:
Первый тон — произносится ровно и высоко:
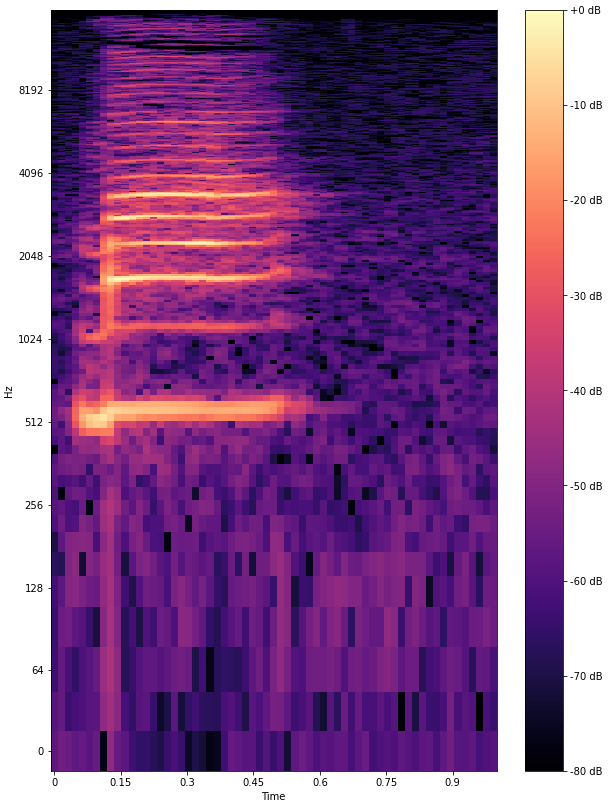
Второй тон — восходящий, со среднего до высокого регистра, голос повышается ближе к концу:
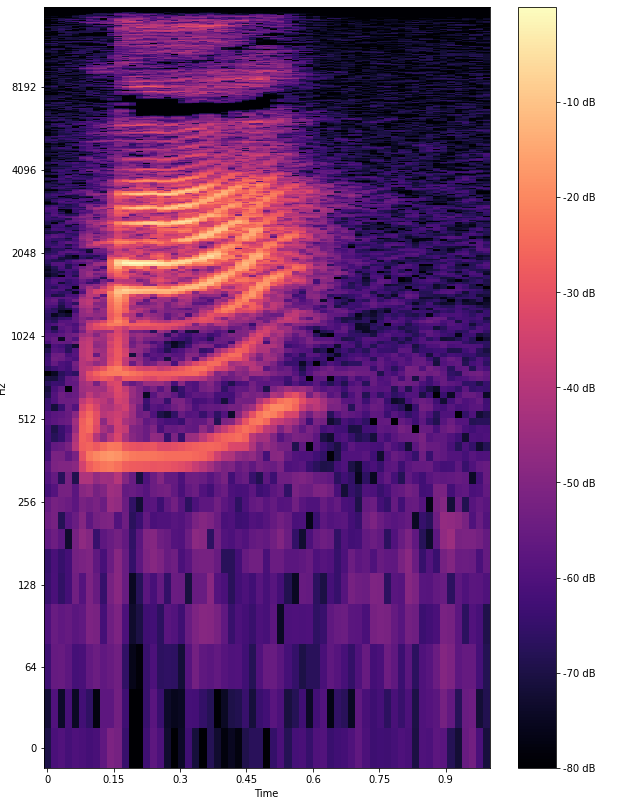
Третий тон — нисходяще-восходящий, сначала понижается с низкого регистра, затем быстро поднимается к верхнему регистру:

Четвёртый тон — нисходящий, быстро падает с высшей точки вниз.

Есть ещё нейтральный тон — точнее, отсутствие тона. Встречается в местах, где нет смыслового ударения.
Эти особенности сложно передать на письме, лучше послушать примеры. Хорошая новость в том, что нейросеть распознаёт различные тоны не хуже, чем это делают люди.
Что мы сделали: здесь вообще ничего дополнительного делать не пришлось. Модель сама научилась распознавать тоны по обучающим данным. Получается, что то, на что студенты-китаисты тратят кучу времени, модель сделала сама очень быстро: после сбора данных процесс обучения занял примерно месяц — за это время модель проанализировала столько данных, сколько человек не услышит и за 15-20 лет жизни в Китае.
Нужно хорошо понимать контекст
С одной стороны, в китайском простые правила нормализации: слова, в общем, не меняются в зависимости от лица, времени, вида, рода, числа или падежа. Это упростило подготовку данных по сравнению, например, с французским языком.
С другой стороны, при распознавании китайской речи важно учитывать контекст из-за обилия омофонов в языке. Омофоны — это слова, которые звучат одинаково, но пишутся по-разному и при этом обладают разным значением. Есть даже вполне содержательная поэма, состоящая из 92 слогов «ши». Омофоны представляют интересную задачу для распознавания, потому что одного произношения недостаточно — важен контекст.
Что мы сделали: понимание контекста не стало проблемой. Наша модель давно умеет учитывать предыдущий текст при распознавании — можно сказать, что мы всегда готовились понимать китайский.
Кроме того, помогло разбиение на BPE-токены. Например, иероглиф 谓 («сказать», произносится «вей») почти всегда встречается в комбинации с другими иероглифами: 可谓 («можно сказать», «кэ-вей») и 所谓 («так называемый», «суо-вей»). Такие комбинации различать между собой проще, чем сами токены, поскольку у них уникальное произношение. Использование BPE вместе с делением на «слова» позволяет выделить подобные комбинации на стадии подготовки данных.
Как мы доработали перевод
Пара слов о том, как работает перевод с китайского. Он устроен как последовательность двух переводов: сперва с китайского на английский, потом с английского на русский.
Сначала мы использовали нашу стандартную модель перевода. Отдавали в модель предложения на китайском и получали на русском. У такого подхода было два существенных недостатка. Во-первых, в отличие от нашей англо-русской модели, она не учитывала контекст. Во-вторых, модель не была адаптирована под видео: она училась на массиве всех данных и не выделяла среди них субтитры, которые как раз важны для перевода видео.
Когда мы заметили, что эти недостатки влияют на качество, то начали исправлять их. Например, с китайского на английский переводим по предложениям, а затем подключается англо-русская модель, которая хорошо понимает контекст и учитывает его при переводе. Вторую проблему решили, дообучив модель на релевантных для перевода видео данных, что позволило повысить качество.
Также пришлось учесть различия в пунктуации китайского и русского. Одна фраза на китайском языке может содержать несколько отдельных смысловых частей, которые человек переведёт в несколько предложений. Расстановка пунктуации по настоящим правилам сильно усложняет перевод, ведь для учёта контекста придётся отдельно разбивать на предложения уже готовые переводы с китайского на английский. Поэтому удачным решением мы посчитали своего рода «гибридный» пунктуатор: он расставляет знаки препинания, принятые в китайском, но выделяет смысловые части в отдельные предложения.
Такой пунктуатор мы получили с помощью существующей модели перевода с китайского. Она умеет переводить одно китайское предложение в несколько английских, чем мы и воспользовались: взяли большое количество китайских данных, перевели их на английский, а затем нашли соответствие пунктуации перевода и оригинального текста (т.н. выравнивание). Это соответствие позволило понять, где в китайских предложениях нужно заменить запятые на точки, чтобы добиться большей гранулярности в обучающих данных пунктуатора.
И вот результат:
Технология перевода видео во многом универсальна, даже сложности китайского не потребовали перепридумывания всей архитектуры. Как можно заметить, здесь я почти не говорил про корректировки в ML-моделях, и мы считаем, что отсутствие необходимости что-то серьёзно менять от языка к языку — это важный плюс.
Перевод с китайского доступен на YouTube. Чтобы всё заработало, перезапустите Яндекс Браузер. Дальше можно, например, посмотреть обзоры на новые устройства или познакомиться с китайской кухней. Чуть позже появится поддержка популярной китайской видеоплатформы Bilibili.
