
В прошлой статье я рассказал краткую историю развития внутренних и внешних продуктов компании ДубльГИС. Сегодня погрузимся в детали развития одного из продуктов, а именно экспорта данных. Я расскажу об архитектуре проекта и отдельных технических решениях, которые позволили нам постепенно развивать проект и адаптировать его под меняющиеся с течением времени требования.
Краткое резюме прошлой статьи
Есть несколько внутренних продуктов, которые собирают большие объемы данных карты, справочника организаций, рекламы, пользовательского фидбека, отзывов, фоточек, различной аналитики. Эти продукты обмениваются между собой данными через шину данных или по Rest Api. И есть отдельный процесс экспорта, который собирает все эти данные в кучку, обрабатывает и раскладывает их в нужном формате, упаковывает и формирует готовый «бандл» для доставки его конечным продуктам. Доставка происходит либо через сервера обновлений для ПК и мобильных версий, либо во внутренний бэкенд онлайна для, собственно, онлайн-версии 2ГИС.
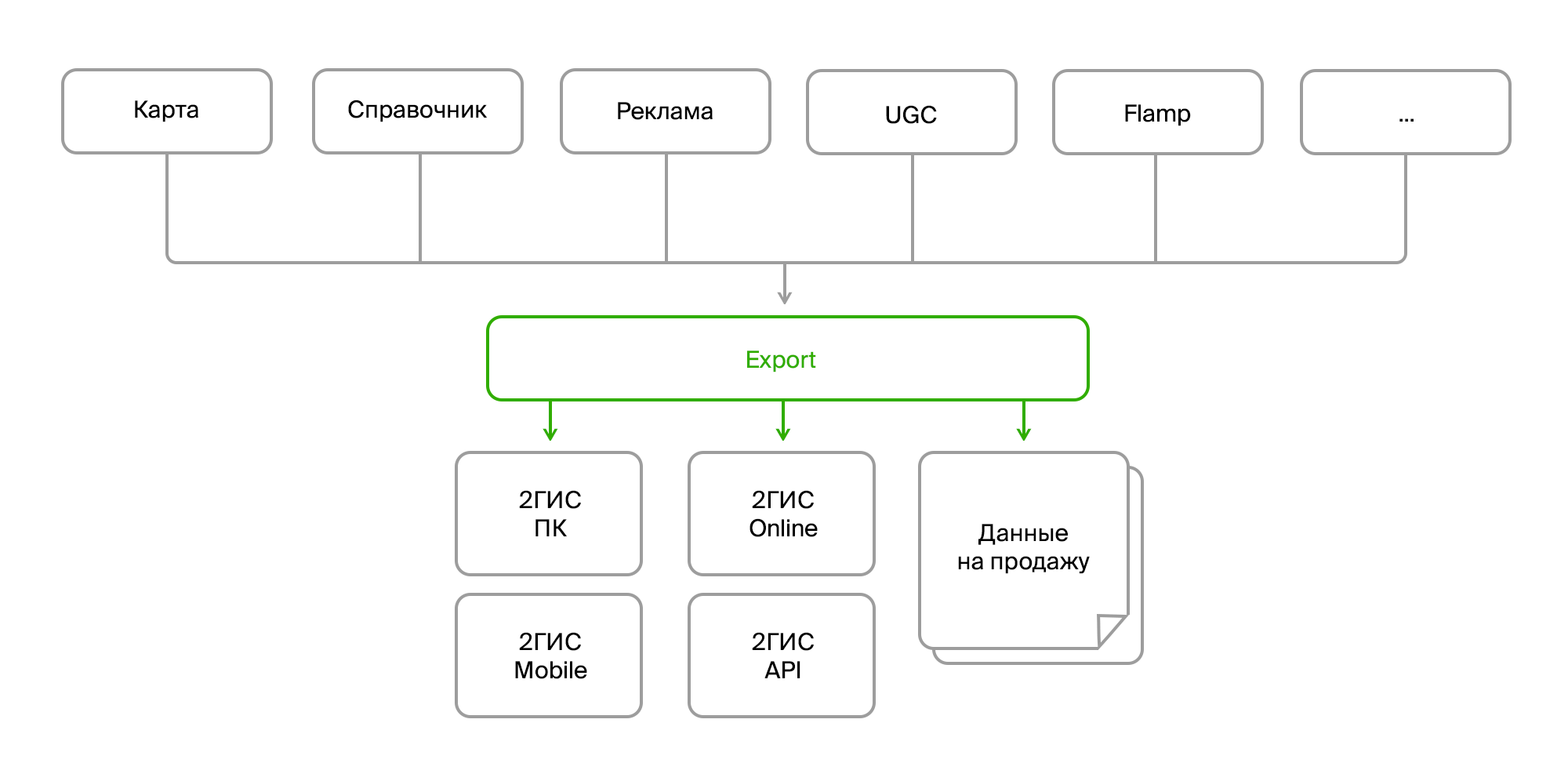
Исходные данные
Итак, на входе мы имеем:
- несколько источников однотипных данных;
- разные способы доставки (Firebird, шина, FTP, RestAPI);
- разная структура одних и тех же объектов;
- постоянные изменения структуры данных;
- разные форматы (сырые данные в БД, XML, JSON).
С точки зрения потребителя:
- опять же, разные форматы (свои форматы данных для разных версий продукта, отдельные форматы на продажу);
- постоянные изменения формата;
- агрегированные данные (нужно объединять разные объекты в один, собирать данные по фирме из всех филиалов, дополнять их ссылками на фото, отзывы, ближайшие остановки и т. д.);
- сложная пред- и пост-обработка (актуализация одних данных на основе других, преобразование данных, генерация недостающих данных, например, расстановка рекламных мини-логотипов на зданиях, удаление или исправление ошибочных данных);
- требования на консистентность и валидность данных;
- нужны ВСЕ данные.
Тут стоит заострить внимание на последнем пункте. Как вы знаете, основная фишка 2ГИС — работа в офлайне. То есть большая часть данных, которые вы видите в нашей ПК и мобильных версиях, лежит у вас на устройстве. А ведь это огромный массив: сотни тысяч геообъектов (моря, леса, реки, дороги, здания, входы, подъезды, подписи, поэтажные планы, 3D-модели), десятки и сотни тысяч фирм и их филиалов с контактами, временем работы, дополнительными атрибутами типа среднего чека и наличия Wi-Fi. Ну и, конечно же, рекламные тексты и картиночки.
И всё постоянно меняется, добавляется, удаляется.
И дабы не захлебнуться в этом бесконечном потоке изменений, при разработке архитектуры экспорта пришлось сосредоточиться на нескольких основных областях:
- источники данных;
- способы их доставки;
- алгоритмы обработки;
- форматы данных для потребителей.
Абстрагируемся от разных источников и форматов данных
Разные источники вносят следующие сложности:
- они отдают одни и те же данные в разных форматах;
- обладают разным набором сущностей или атрибутов, которые нужно свести в единый доменный объект.
Это довольно стандартная проблема, и решается она так же стандартно. Нам необходимо просто создать интерфейс для получения данных, а конкретная реализация уже сходит куда нужно и добудет данные в требуемом для нас виде.

Пример интерфейса:
public interface ISource : IDisposable
{
ISourceReader GetDeletedRows();
ISourceReader GetInsertedOrUpdatedRows();
byte[] GetDataVersion();
}
public interface ISourceReader : IDisposable
{
bool Read();
object this[string columnName] { get; }
}
Пример реализации получения фирм:
internal class FirmSetSource : ISource
{
public ISourceReader GetDeletedRows()
{
if(_lastDataVersion == null) return null;
var query = DataContext.ExecuteObject<EsbFirmDeleted>(_lastDataVersion);
return new DeletedIdsSourceReader<long>(
query.Select(x => x.Id).GetEnumerator());
}
public ISourceReader GetInsertedOrUpdatedRows()
{
return new EnumeratorSourceReader(typeof(FirmSet),
GetNewOrChangedRows().GetEnumerator());
}
public virtual byte[] GetDataVersion()
{
return DataContext.ExecuteObject<EsbFirm>().Max(x => x.RowVersion);
}
}
Эта абстракция отчасти позволяет решить вопрос с различиями в доменной модели, но не полностью. Существенное ограничение накладывать необходимость получать данные инкрементно, то есть получать только их обновления, а не засасывать каждый раз всё целиком. В этом случае довольно неудобно отслеживать взаимосвязи между данными, чтобы собирать какие то агрегаты. И относительно сложно сделать всё без ошибок. Поэтому мы решили, что на данном этапе добывать данные из источников будем один к одному, а вопрос с доменной моделью решим на другом уровне.
Доменная модель
Чтобы не зависеть от изменения набора данных и их структуры в источниках данных, в экспорте была сделана своя база с относительно стабильным перечнем таблиц, которая в итоге ложилась на наш домен. Если в источнике 1 не хватало каких-то атрибутов для сущности А (Data Object на след. картинке), то они либо получали дефолтное значение, либо были опциональны. А если сущность Б представляла собой какой-то агрегат данных источника или даже разных источников, то каждую часть можно было получить отдельно и потом собрать целиком на следующем этапе.

Абстрагируемся от способа доставки данных
На самом деле, наличие своей БД в экспорте и появление интерфейса ISourceReader уже решают эту задачу. Но есть один нерешенный момент: несколько отличающиеся модели получения данных. В одном случае мы делаем pull и получаем слепок на текущий момент, в другом — дельты изменений по шине, в третьем — также актуальное на момент запроса состояние, но с информацией об удалённых объектах с момента предыдущего запроса.
Чтобы привнести единообразия в этот зоопарк, добавим еще одну базу, в которую будем сливать все данные от всех источников.
Получится вот такая картина.
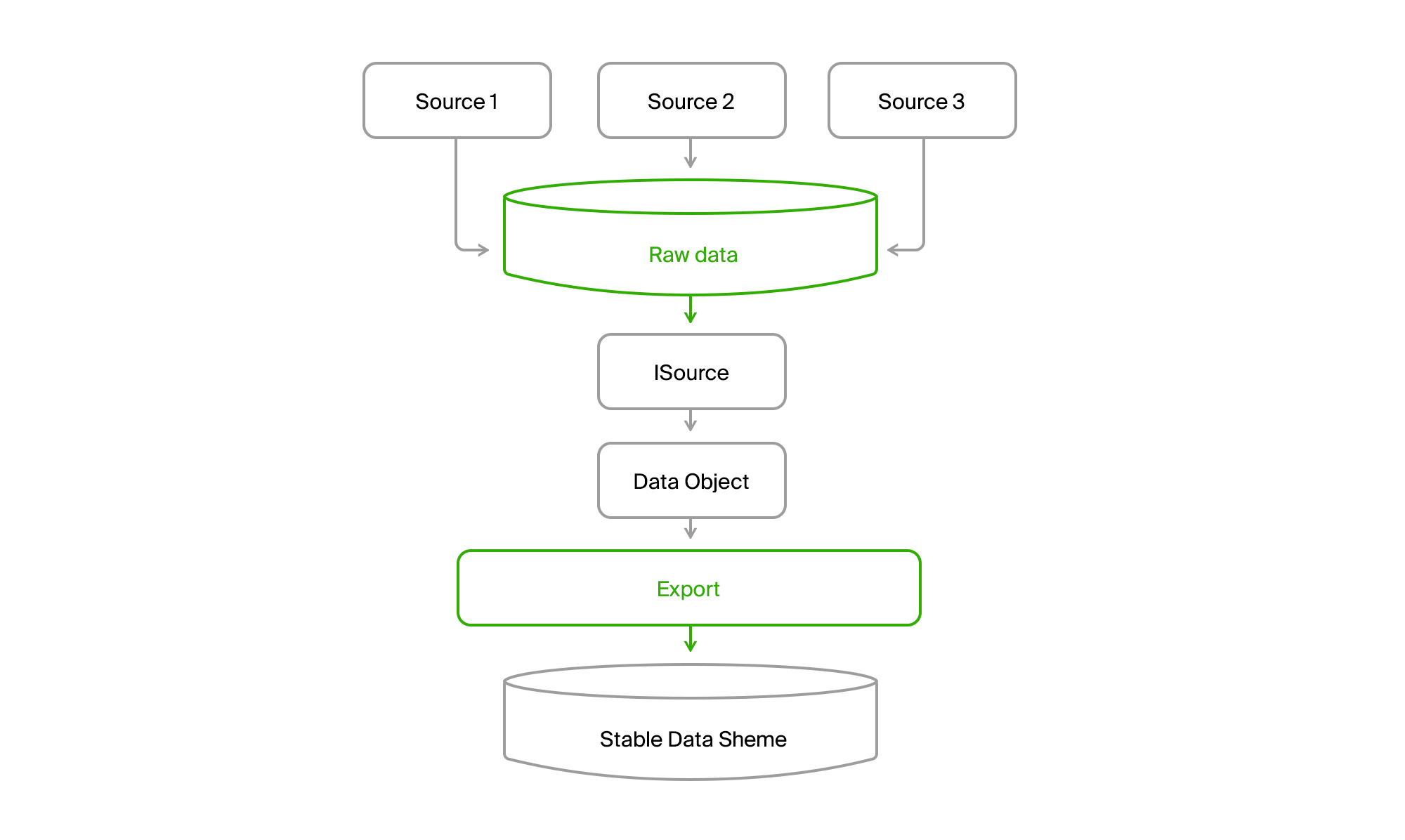
В итоге, мы читаем все данные из любого канала по всем городам в центральную БД. Почти всегда доставка происходит инкрементно, то есть приходят только изменения. Старый DGPP, пока был жив, оставался альтернативным источником. Смыла выкачивать данные из одной СУБД в другую никакого не было.
Далее, экспорт через ISource вытаскивал данные города из DGPP или EMDB в свою стабильную синхробазу и преобразовывал их в свою доменную модель.
Далее остаётся только обработать их и выгрузить в форматах потребителей.
Абстрагируемся от алгоритмов подготовки данных
И тут возникает еще одна сложность. Во-первых, разные потребители хотят данные в своих форматах. Более того, они хотят разные наборы данных. И в довесок данные для офлайна должны быть максимально компактны и структурированы так, чтоб их можно было быстро читать. В итоге мы получаем бинарные форматы, которые разрабатывают команды конечных продуктов. А это ребята, которые работают на совершенно другом стеке технологий. У нас привычный и любимый для разработки бэкенда .NET и иногда Java, у них — в основном C++ да питон.
В общем, зоопарк технологий.
На заре бурного развития, когда у нас был только DGPP (см. прошлую статью) и ПК версия 2ГИС, формат финальных данных представлял из себя бинарь, который готовился специальной библиотекой, написанной на C++ и обёрнутой в COM-объект. Казалось бы, чем не интеграция гетерогенного кода. Подключаем референс, генерится .NET-интерфейс — и погнали. И первое время мы так и делали.
Но, как обычно, появилась пара проблем.
- Наши данные стали активно расти. Появлялись новые типы данных, новые большие города вроде Москвы.
- Стали активно распространяться x64-битные ОС.
- Проблемы в COM нужно было как то отлаживать.
Пройдёмся по пунктам.
Рост данных, которые целиком нужны нашим продуктам, привел к тому, что их процессинг стал отжирать большое количество оперативной памяти. А подключив к своему .NET процессу x86 COM-библиотеку, мы автоматом получили x86 процесс, то есть максимум 3Gb оперативы с увеличенным адресным пространством. Делать поддержку библиотеки для x64 ресурсов у команд не было, но в самой библиотеке была возможность использовать диск вместо памяти, что несколько сглаживало проблему.
Но с отладкой-то было по прежнему очень тяжело. Нужно было запустить экспорт, дождаться, когда он подготовит данные, начнёт складывать эти данные в библиотеку. И после появления ошибки нужно понять по логам, что же пошло не так и повторить процесс снова. Нехорошо, очень нехорошо.
Решение как обычно на поверхности. Достаточно вынести весь чужеродный код в отдельный процесс, а коммуникацию наладить через промежуточные файлы в простом бинарном или текстовом формате.
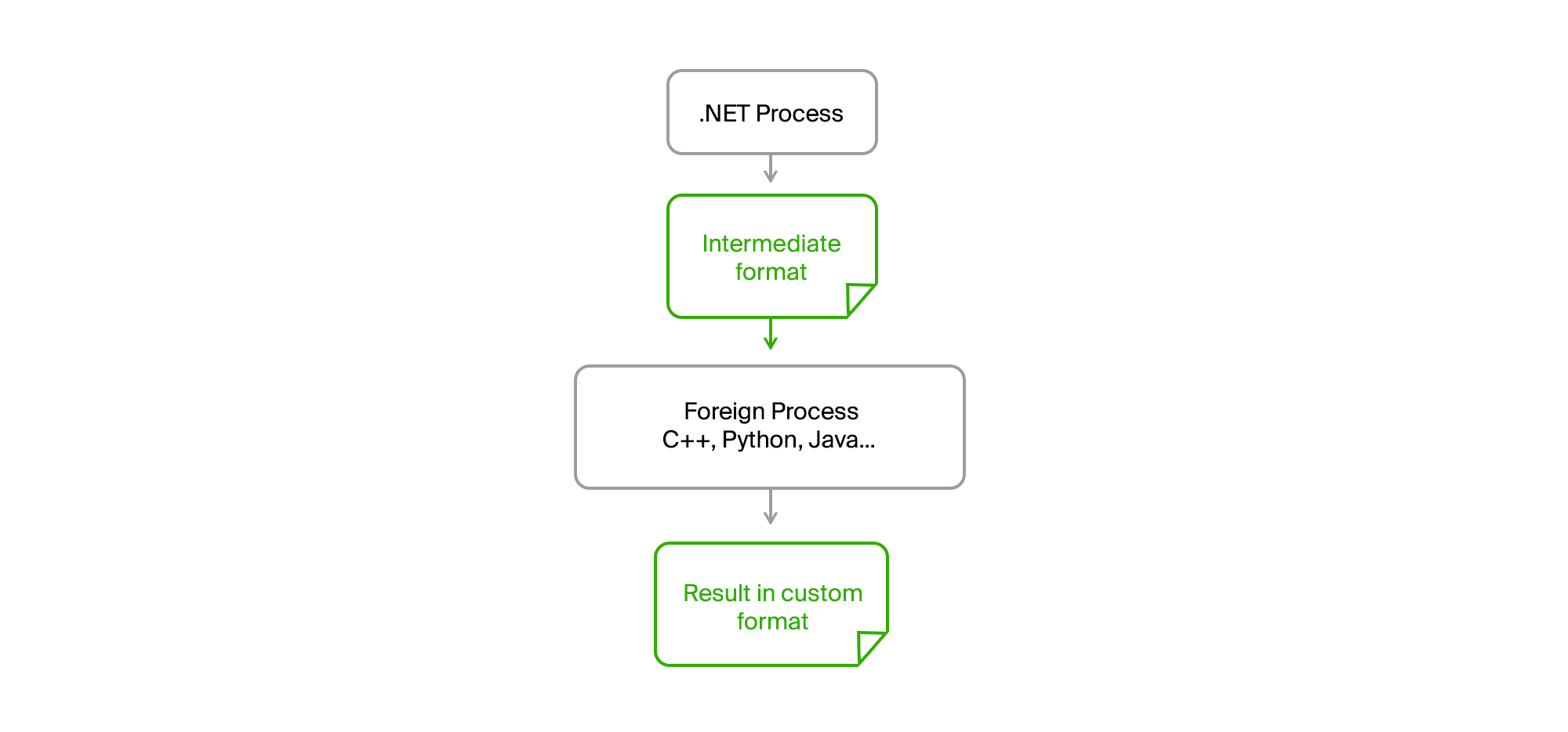
В итоге наш исходный .NET-процесс стал полностью any cpu. Никакие утечки памяти или критические ошибки в стороннем коде на него больше не влияли. Экспорт готовил данные, выгружал их в промежуточный файл, скармливал его утилите и получал от неё результат также в виде файла. Ребята из сторонних команд писали свои алгоритмы на своих языках (С++ или Python) и могли их отладить на реальных данных в случае возникновения ошибок на своей машине без необходимости запуска экспорта.
Нам же оставалось лишь сформировать соглашения относительно интерфейса утилит, которые предоставлялись вместе с рантаймом, имели оговоренный перечень обязательных параметров и выводили информационные сообщения и ошибки в stdout в нужном формате.
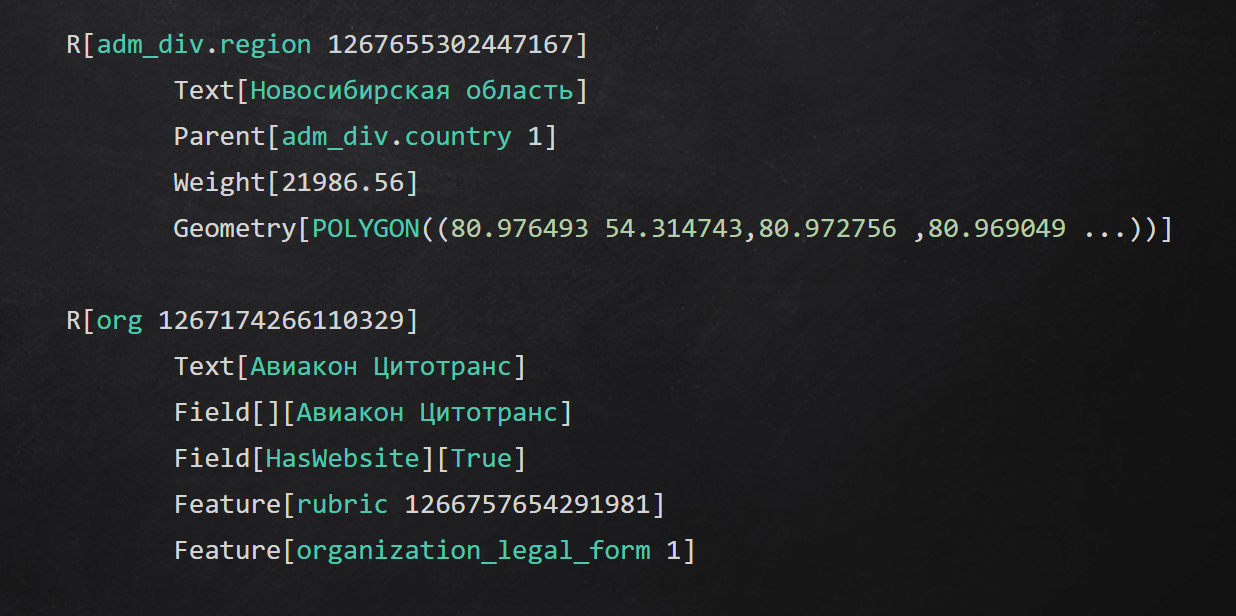
Пример промежуточного текстового формата
Итоги
В статье я рассказал о некоторых подходах, которые мы применяли на различных уровнях приложения для изоляции процесса подготовки данных:
- прятали детали доступа к источникам данных за интерфейсы;
- абстрагировались от каналов доставки данных с помощью промежуточного хранилища;
- делали свой стабильный домен и преобразовывали исходные данные в него;
- выносили отдельные этапы обработки данных в процессы и использовали код на других языках.
Спасибо, что добрались до конца. Отвечу на все вопросы в комментариях, обязательно задавайте.
