
Привет, Хабр. Меня зовут Сергей Вертепов, я senior backend инженер. Это небольшая обзорная статья о том, как мы тестировали монолитное приложение Авито, и что изменилось с переходом на микросервисную архитектуру.

Тестирование в домикросервисную эпоху
Изначально приложение Авито было монолитным. Справедливости ради, монолит у нас и сейчас довольно большой, но микросервисов становится всё больше и больше.
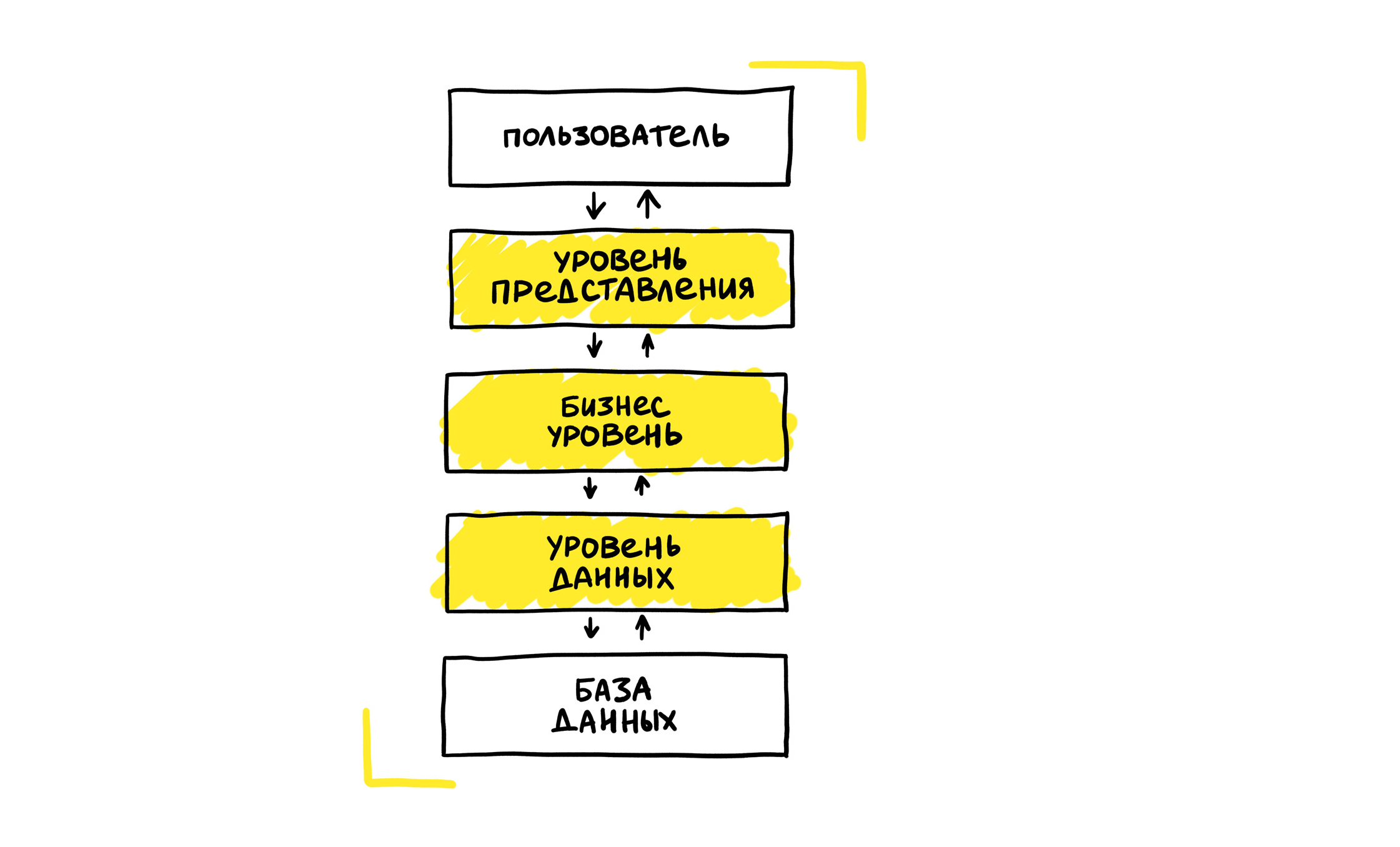
Выше — схема того, как выглядит монолитное приложение. У нас есть пользователь, есть уровень представления, бизнес-уровень, уровень данных и база данных, из которой мы их получаем. Когда у нас был большой-большой монолит, то объектом тестирования было приложение с бэкендом на PHP, фронтендом на Twig, и совсем немножко — на React.
Классическая пирамида тестирования для монолитного приложения выглядит так:
- Много юнит-тестов.
- Чуть меньше интеграционных тестов.
- Ещё меньше сквозных тестов.
- Поверх всего — непонятное количество мануальных тестов.

Расскажу, как мы пытались прийти к такой пирамиде, и что у нас было из инфраструктуры.
У нас был собственный тестовый framework на PHP с PHPUnit под капотом. Система генерации тестовых данных у нас тоже своя. Это ресурс-менеджер, который позволяет создать любой необходимый запрашиваемый ресурс для тестирования. Например, пользователя с деньгами, с объявлениями в определённой категории на Авито, пользователя с определённым статусом.
Система просмотра отчётов — тоже самописная. Кроме неё мы написали собственный jsonwire-grid. Grid — это система оркестрации селениумными нодами, она позволяет по требованию поднять селениумную ноду. Узнать подробности про Grid, как мы его разрабатывали и какие технологии использовали, можно из доклада моего коллеги Михаила Подцерковского c Heisenbug 2018 года.
Также у нас есть собственный selenium-maper. Мы написали собственную библиотечку, которая позволяет выполнять запросы по jsonwire-протоколу.
Наш CI-pipeline выглядел следующим образом: происходил какой-то CI Event, пусть для примера это будет пуш в репозиторий. В CI собирался артефакт для запуска тестов. Самописная система параллельного запуска тестов парсила артефакт и начинала запускать тесты на куче разных нод.

В качестве тестового приложения мы использовали РНР-имплементацию Selenide, полный порт с Java. Но в процессе мы от него отказались, потому что Selenide было тяжело поддерживать, сам он уже не развивался. Мы написали свой, более легковесный, PowerUI, вокруг которого построили и архитектуру тестовых приложений с кастомными матчерами, селекторами и так далее. Этот продукт сильно упростил для нас тестирование и построение отчётов. Соответственно, дальше PowerUI через jsonwire-grid входил в селениумную ноду и выполнял необходимые действия.
Само тестовое приложение у нас дополнительно ходило в ресурс-менеджер для генерации тестовых данных, и потом уже отправляло данные в нашу систему просмотра отчётов — Test Report System.
В целом, в такой парадигме мы прекрасно жили. Вначале релизы большого монолитного PHP-приложения были раз в день, потом их количество выросло до трёх, а впоследствии и вовсе до шести. У нас было несколько тысяч Е2Е-тестов с большим покрытием, и они были довольно легковесными. В среднем они выполнялись порядка минуты, за редким исключением. Тест, который проверял огромный кусок бизнес-логики мог занимать две-три минуты. У нас был минимум ручного регресса и минимум багов в продакшене.
Тестирование в микросервисной архитектуре
Со временем мы стали переходить на микросервисную архитектуру. Основные её плюсы — это масштабирование, быстрота доставки фич и отказоустойчивость.
С монолитом пирамида тестирования у нас не получилась. Вместо неё была «мороженка» тестирования. С чем это было связано? Е2Е-тесты благодаря разработанной инфраструктуре были довольно быстры и не причиняли особой боли. Поэтому мы делали основной упор на них. Мы даже могли пренебрегать юнит-тестами.
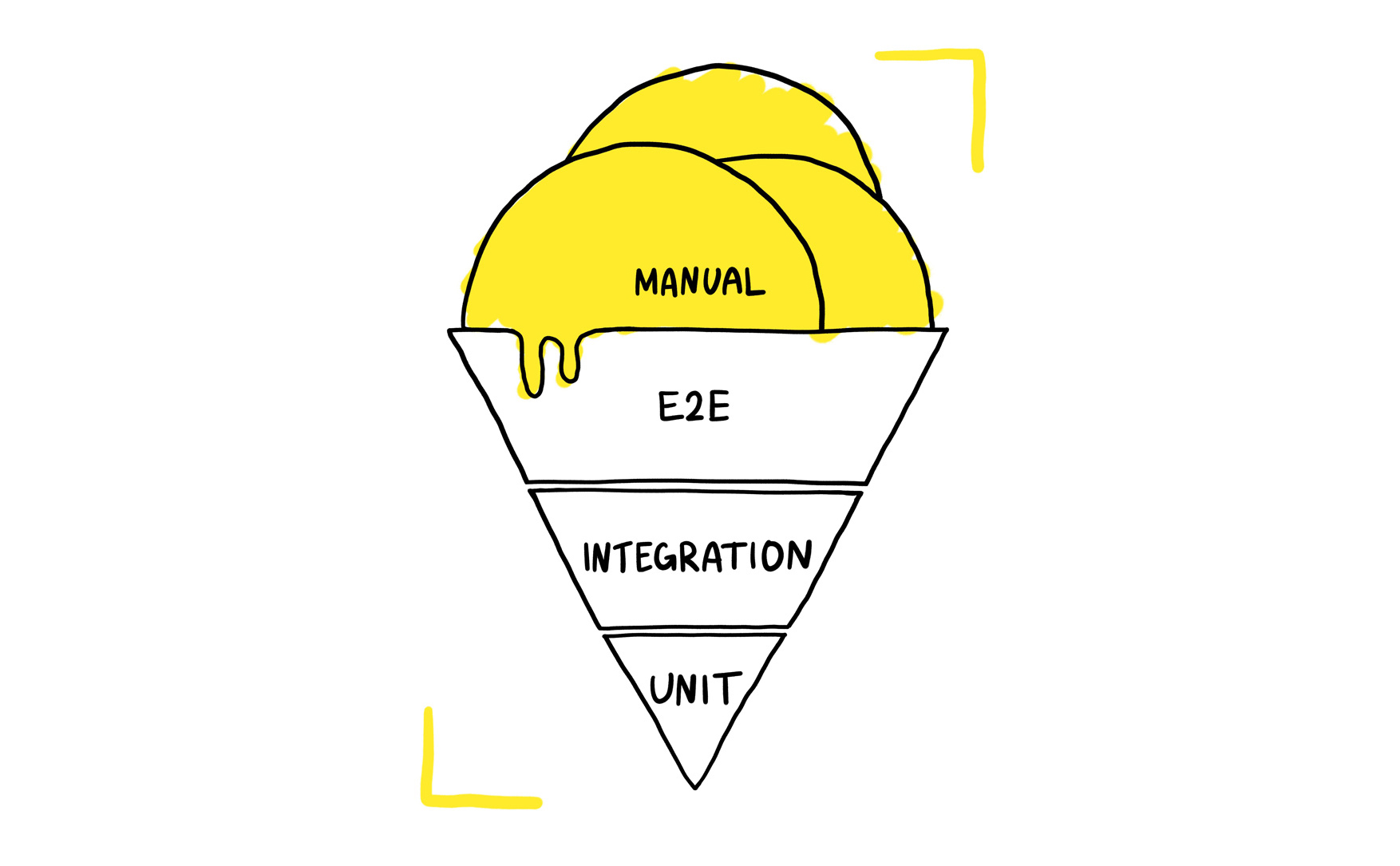
С приходом микросервисной архитектуры такой подход перестал работать. Огромная часть бизнес-логики уехала в отдельные сервисы, их становилось всё больше. На 2020 год у нас порядка 2,5 тысяч разных репозиториев. В таком случае, когда мы запускали Е2Е-тесты какой-то сервис мог, например, резко перестать отвечать. Если он отвалился, все тесты, которые ходили в этот сервис и были блокирующими для мержа, тоже начинали падать. Соответственно, у нас просто падал time to market, так как люди не могли мержиться из-за падающих тестов. Мы были вынуждены сидеть и ждать, пока придёт оунер конкретного сервиса, разберётся, что происходит, перевыкатит его или разберется с проблемами.
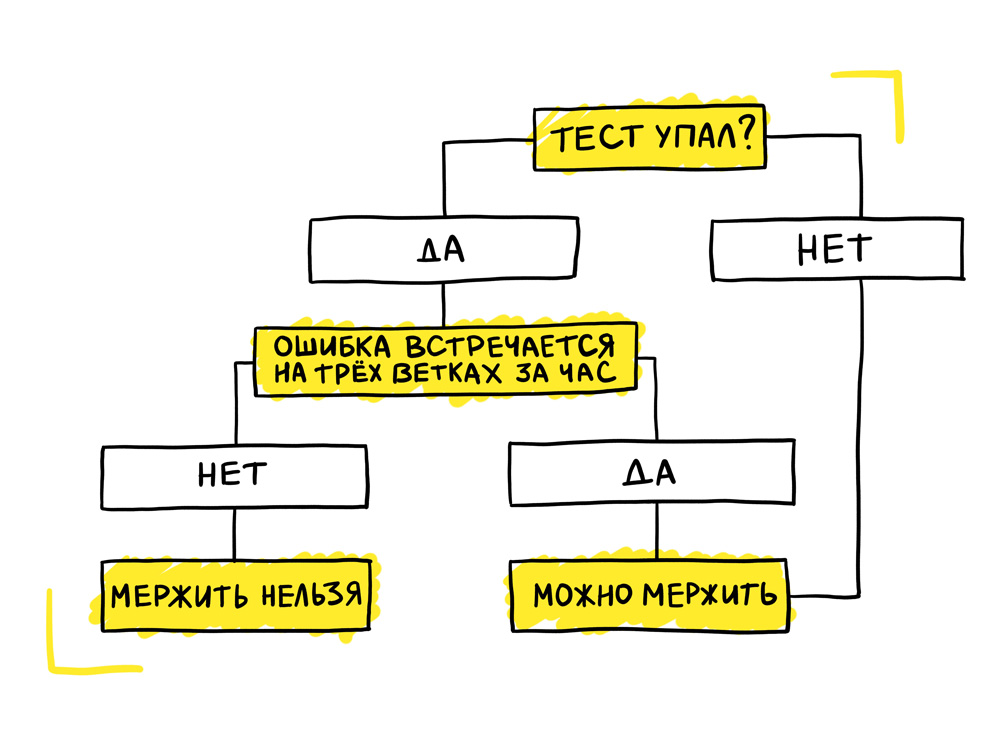
После этого мы внедрили карму тестов. Это очень простой механизм. Он работает на основе самописной системы отчётов, которая имеет всю необходимую историчность данных. Карма проверяет, что тест упал, и дальше идёт смотреть, встречается ли подобная ошибка при запуске тестов в других ветках. Ошибка — это хэш трейса. Мы берём полный трейс, хэшируем его и сохраняем. Если мы видим, что ошибка с таким хэшем встречается ещё на трёх ветках, мы понимаем, что проблема не в ветке, на которой запущены тесты, а что она носит общий характер. Если ошибка общая и не имеет отношения к конкретной ветке, то мы позволяем вмержить эту ветку.
Да, таким образом мы маскируем проблемы, но, тем не менее, это решение сильно упростило жизнь разработчиков. В случае, если разработчик пропустил какой-то баг, у нас остаётся процесс деплоя. В деплое никакая карма уже не работает, всё на ручном апруве тестировщиков и разработчиков, то есть мы прямо смотрим, что и как у нас происходило. Если находим проблемы, выкатка блокируется до тех пор, пока проблемы не решат и не сделают хотфикс.
Количество микросервисов растёт, а количество тестировщиков — не очень. Как правило, у нас на юнит один ручной тестировщик. Понятное дело, что в одиночку довольно-таки тяжело полностью покрывать нужды всех разработчиков из команды. В среднем это несколько фронтендеров, несколько бэкендеров, ещё автоматизаторы и так далее.
Чтобы решить эту проблему, мы стали внедрять методологию Agile Testing. Суть этой методологии состоит в том, что мы предотвращаем баги, а не ищем их. Тестирование мы обсуждаем на Product Backlog Refinements. Мы сразу определяем, как будем тестировать какую-то фичу: достаточно ли покрыть её юнит-тестом и если юнит-теста достаточно, какой это должен быть юнит-тест. Обсуждение происходит вместе с тестировщиком, который определяет, нужно ли будет дополнительно провести ручное тестирование. Как правило, юнит-теста бывает достаточно. Плюс тестировщик может подсказать ещё какие-то кейсы, а также может предоставить чеклист, на основе которого мы напишем нужные юнит- или функциональные тесты.
Разработка у нас идёт от приёмочных тестов, то есть мы всегда определяем тесты, которые будут приняты при разработке. Подробнее про переход на Agile Testing уже рассказывала моя коллега Алёна из соседнего юнита. В статье она пишет о внедрении методологии на примере своей команды, но это справедливо для всего Авито.
Но Agile Testing невозможен без Shift-left тестов. Основная суть подхода Shift-left testing — находить дефекты на ранних этапах, чтобы разработчик мог запустить необходимый тест в любой момент, когда пишет код. Также он обеспечивает непрерывное тестирование в CI, и возможность автоматизации чего угодно.
Во время Shift-left тестов мы разбиваем большие, тяжёлые тесты на кучу маленьких, чтобы они запускались и выполнялись быстрее. Мы декомпозировали наши огромные Е2Е-тесты на компонентно-интерфейсные тесты, на юнит-, интеграционные тесты, функциональные тесты, то есть начали распределять Е2Е по пирамиде. Раньше запуск тестов мог занять 20—30 минут и требовал танцев с бубном. Сейчас в любом микросервисе тесты прогоняются за 5-10 минут, и разработчик сразу знает, сломал он что-либо или нет.
Также мы внедрили методологию контрактных тестов. Сокращение CDC-тесты значит Consumer-Driven Contract тесты. Когда мы пушим изменение кода в репозитории, специально написанный брокер собирает всю необходимую информацию по тому, какие написанные CDC-тесты есть, и дальше понимает, к какому сервису они имеют отношение.
Сами CDC-тесты пишутся на стороне консьюмера сервиса. При выкатке продюсера мы прогоняем все написанные тесты, то есть проверяем, что продюсер никак не нарушает контракт. Подробнее про это рассказывал в своём докладе Фрол Крючков, который как раз драйвил эту идею.
Помогли ли нам CDC-тесты? Нет, потому что появилась проблема с тем, что сами консьюмеры не поддерживают свои тесты. Как результат — тесты нестабильны, из-за этого получалось, что наши продюсеры не могли вовремя выкатиться. Приходилось идти и фиксить тесты со стороны консьюмеров. Плюс тесты все писали по-разному, на одну ручку мог быть десяток различных тестов, которые проверяют одно и то же. Это неудобно и долго. Поэтому от идеи CDC-тестов мы отказались.
Недавно мы внедрили PaaS. Наша архитектурная команда разработала очень удобный инструмент, благодаря которому можно быстро развернуть на бойлерплейтах сервис и сразу начать его разрабатывать. При этом не надо думать ни о базах, ни о миграторах и прочих инфраструктурных штуках. Можно сразу начать писать код и катить миграции.
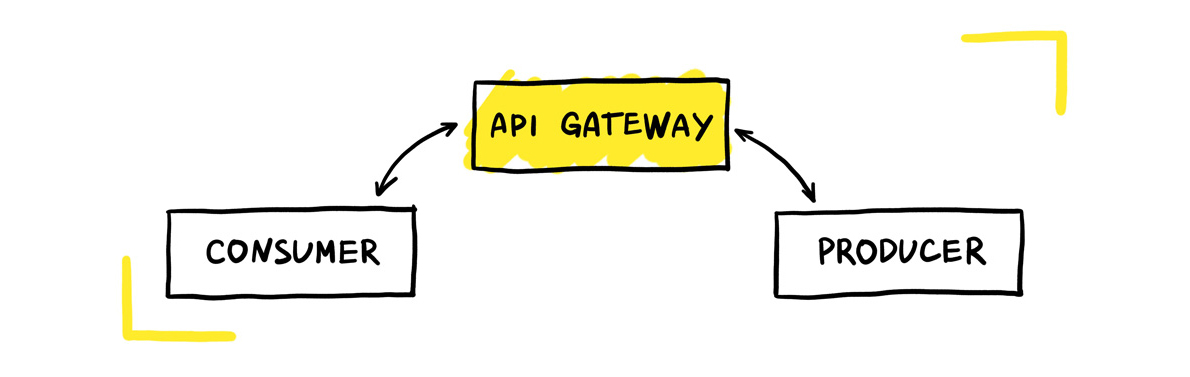
Теперь сервис-потребитель и сервис-продюсер общаются между собой через Api Gateway. На стороне Api Gateway есть валидация контрактов на основе бриф-файлов. Бриф-файл — это очень простой структурный файлик, который описывает сервисное взаимодействие. Есть бриф-файл на стороне продюсера, он описывает то, как мы должны общаться с этим сервисом. Консьюмер копипастой берёт необходимую себе ручку, необходимую структуру, затаскивает всё это в свой сервис, и генерирует на основе этого клиенты.
Соответственно, у нас идёт валидация бриф-файлов, что у нас всё в порядке, что мы не ломаем никакое сетевое взаимодействие. Сейчас уже такая валидация даже будет блокировать мерж, если у нас где-то нарушаются контракты. Мы как раз проверяем контракты на стороне инфраструктурных штук.
Ещё мы внедрили такую штуку, как service mesh. Service mesh — это когда рядом с кодом сервиса поднимается sidecar, который проксирует все необходимые запросы. Запрос идет не в сам сервис, его сначала получает sidecar, который прокидывает необходимые заголовки, проверяет, роутит маршруты, и передаёт запрос сервису. Cервис передаёт запрос обратно в sidecar, и так дальше по цепочке.
Про service mesh подробно можно узнать из доклада Саши Лукьянченко с DevOpsConf 2019 года. В нём Саша рассказывает про то, как разрабатывал решение и как мы к нему пришли.
На основе sidecar мы внедрили OpenTracing. Это технология, которая позволяет полностью отследить запросы от самого фронта до конечного сервиса и посмотреть, какие были отвалы, сколько шёл запрос.
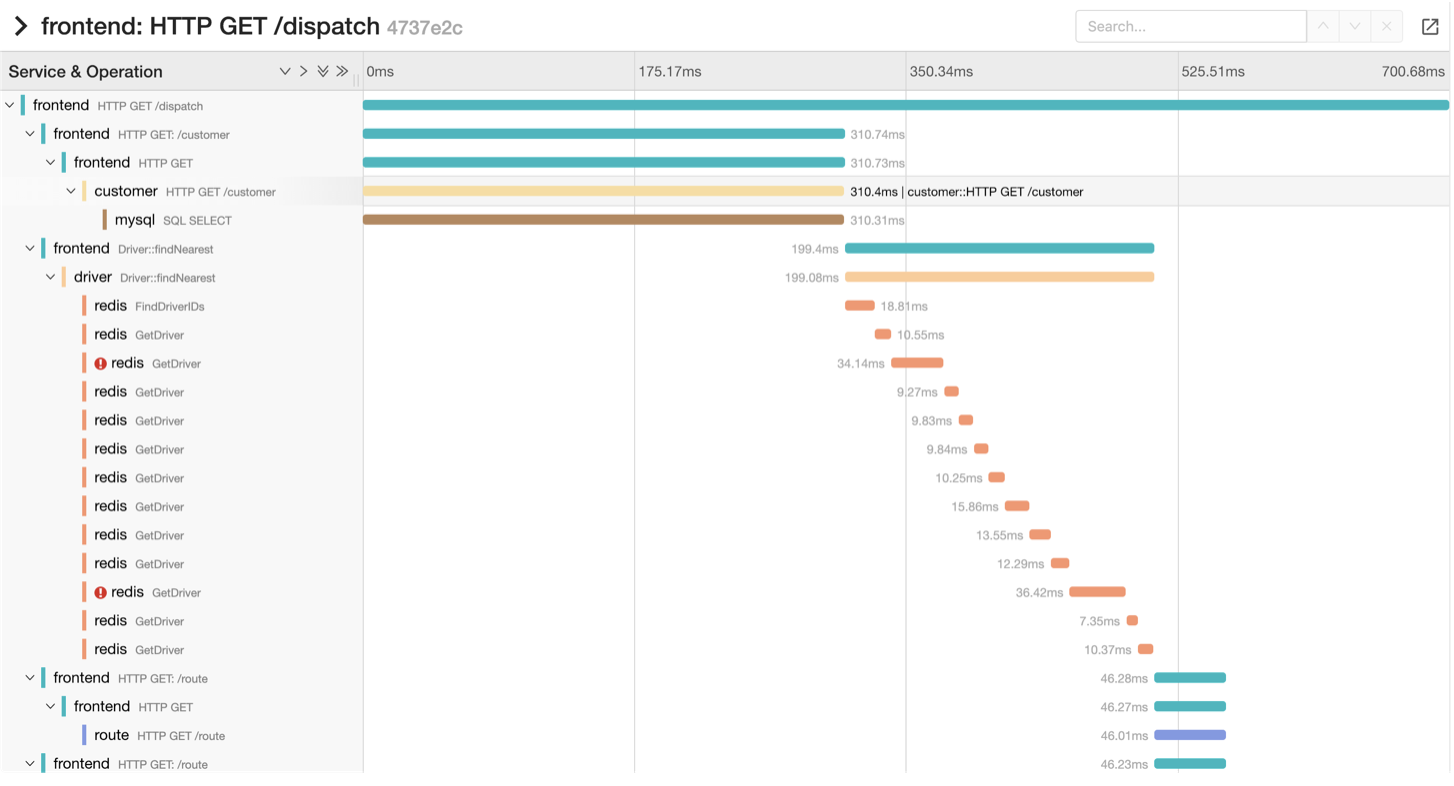
Это интерфейс Jaeger UI. На скриншоте — трейсинг запросов со временем выполнения и маршрутом
Также с помощью service mesh мы сделали Graceful Degradation тестирование. Graceful Degradation тестирование — это когда мы отключаем какой-то сервис и проверяем, как у нас будет работать приложение. Мы смотрим, выдаст ли приложение какую-то ошибку или полностью крашнется. Такого развития событий мы не хотим, но так как микросервисов становится много, количество точек отказа тоже растёт. Такой вид тестирования позволяет проверить поведение всей системы при отказе одного из сервисов.
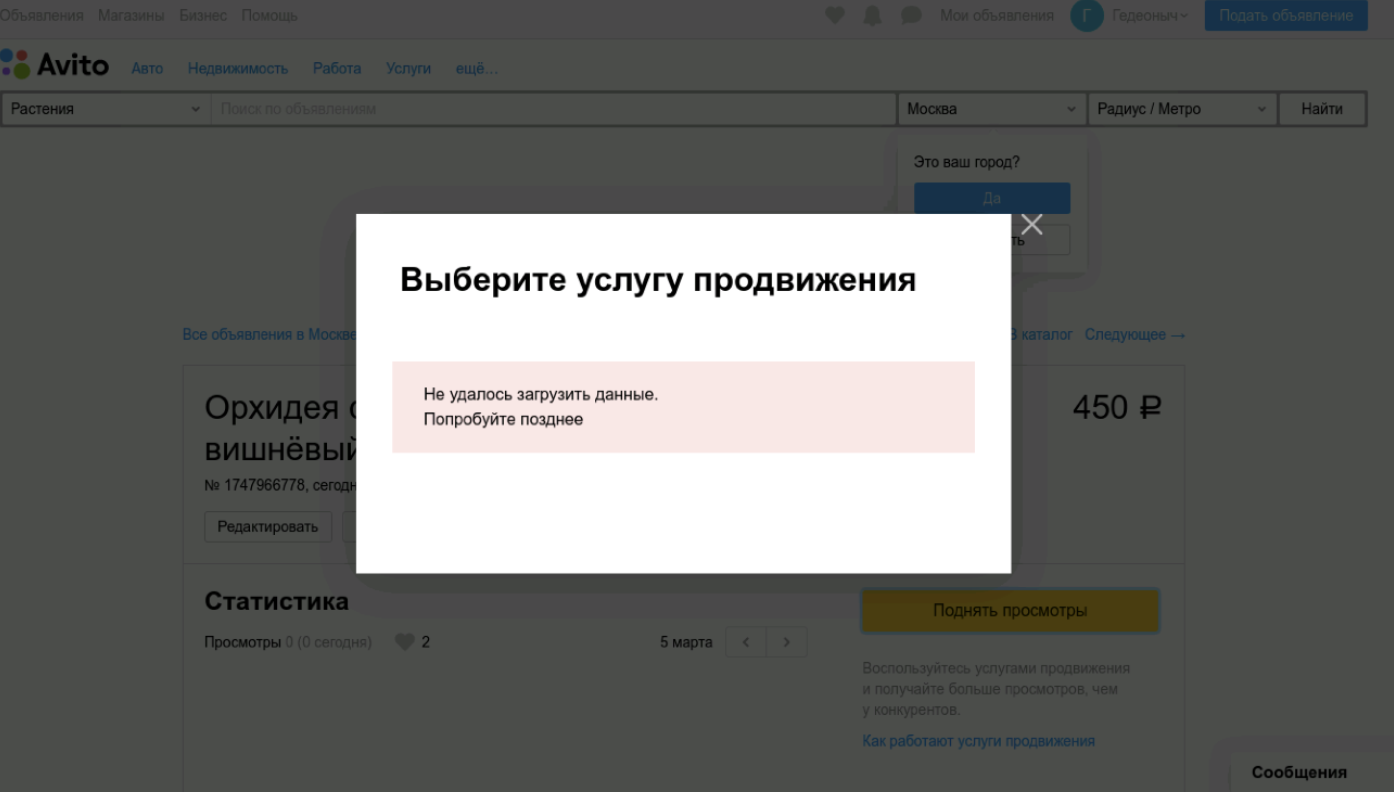
На скриншоте — боевой пример с одного из наших тестов во время прохода. Мы отключали сервис услуг и проверяли, что выдадим пользователю читаемое сообщение.
Всё это работает благодаря service mesh утилите Netramesh. Достаточно прописать заголовок X-Route, наш sidecar перехватывает запрос до сервиса и перенаправляет куда надо. В конкретном случаем мы его перенаправляли в никуда, будто бы сервис отвалился. Мы могли сказать ему, чтобы он вернул пятисотую ошибку, либо могли сделать таймаут. Netramesh всё это умеет, единственная проблема, что здесь необходимо через DevTools-протокол добавлять ко всем запросам необходимый заголовок.
В сухом остатке
Сейчас для тестирования в микросервисной архитектуре мы используем:
- Карму для E2E-тестов.
- Методологию Agile Testing.
- PaaS c Api Gateway.
- Service mesh, благодаря которому работают OpenTracing и Graceful Degradation тестирование.
