
Фото из открытых источников
Массовые скопления людей создают проблемы в самых разных областях (ритейл, госслужбы, банки, застройщики). Заказчикам необходимо объединять и мониторить информацию о количестве людей во множестве мест: в офисах обслуживания, административных помещениях, на строительных площадках и т. д.
Задачи подсчета людей имеют готовые решения, например применение камер со встроенной аналитикой. Однако во многих случаях важно использовать большое количество камер, ранее уже установленных в разных отделениях. Кроме того, решение, учитывающее специфику конкретного заказчика, окажется для него более качественным.
Нас зовут Татьяна Воронова и Эльвира Дяминова, мы занимаемся анализом данных в компании Center 2M. Хотя тема кажется наиболее простой из того, что сейчас рассматривается в задачах компьютерного зрения, даже в этой задаче, когда дело доходит до практики (внедрения), приходится решать много сложных и нетривиальных подзадач. Цель нашей статьи – показать сложности и основные подходы к задачам компьютерного зрения на примере решения одной из базовых задач. Для последующих материалов мы хотим привлечь коллег: девопса, инженера, руководителей проектов по видеоаналитике, чтобы они рассказали про задействованные вычислительные ресурсы, замеры скорости, нюансы общения с заказчиками и проектные истории внедрения. Мы же остановимся на некоторых использовавшихся методах анализа данных.
Начнем со следующей постановки: необходимо выводить количество людей в очереди в офисе обслуживания. Если очередь, согласно внутренним правилам компании-заказчика, будет сочтена критичной, начнет отрабатываться внутренний сценарий:
- уведомление о необходимости открытия дополнительного входа/кассы;
- вызов менеджера;
- информирование о необходимости перенаправления потоков людей на другие (более свободные) кассы.
Таким образом, наша работа сохранит клиентам немало нервов.
Машинное обучение, используемые модели
Детектирование силуэтов людей
Первоначально мы решили использовать уже обученную модель для детектирования людей (силуэтов), так как подобные задачи имеют достаточно хорошие решения, например определение силуэтов.
Так, в библиотеке TensorFlow есть большое количество уже предобученных моделей.
После проведения тестов мы остановились сначала на двух архитектурах: Faster R-CNN и YOLO v2. Позже, после появления новой версии, мы добавили YOLO v3.
Описание моделей.
Пример результата распознавания для YOLO v2 (здесь и далее изображения берутся из свободных источников – мы не можем публиковать кадры с камер заказчиков):

Пример результата распознавания для Faster R-CNN:

Преимущество YOLO в том, что модель отвечает быстрее, а в некоторых задачах это важно. Однако на практике мы выяснили, что если нет возможности использовать предобученный вариант модели, а требуется дообучение на своем специализированном обучающем множестве, правильнее использовать Faster R-CNN. Если камера была установлена достаточно далеко от людей (высота силуэта меньше 100 пикселей для разрешения 1920 на 1080) или требовалось дополнительно распознавать средства индивидуальной защиты на человеке: каски, крепления, элементы защитной одежды, в таких ситуациях качество результата обучения на собственном датасете (до 10 тыс. различных объектов) для YOLO v2 нас не устроило.
YOLO v3 показала приемлемые результаты, однако тесты на скорость не дали значительного преимущества для YOLO v3 по сравнению с Faster R-CNN. Кроме того, мы нашли способ увеличить скорость распознавания с помощью использования batch (групповой обработки изображений), выборочного анализа снимков (об этом подробнее ниже).
Для всех типов моделей мы улучшали точность с помощью пост-обработки результатов: убирали выбросы в значениях, брали наиболее часто встречающиеся значения для набора подряд идущих кадров. Одной секунде с одной камеры обычно соответствуют 25–50 кадров. Конечно, для улучшения быстродействия (при возрастающем количестве камер) мы анализируем не каждый кадр, но нередко есть возможность давать итоговый ответ по интервалу в несколько секунд, то есть использовать несколько кадров. Это решение можно принимать динамически, учитывая общее количество камер (видеопотоков для обработки) и доступные вычислительные мощности.
Пример использования модели Faster R-CNN, дообученной на собственном датасете:

Сейчас мы проводим тесты с моделью SSD-300. Надеемся, она даст нам прирост в производительности при сохранении приемлемого качества распознавания.
Формирование собственного обучающего датасета
В случаях, когда требуется создавать свое обучающее множество, мы выработали для себя следующий порядок действий:
- собираем видеофрагменты с требуемыми объектами: видео заказчиков, видео в открытом доступе (выложенные ролики, камеры наблюдения);
- видеофрагменты нарезаем и фильтруем для того, чтобы получаемый датасет был сбалансированным по различным объектам распознавания;
- кадры распределяем между разметчиками для выделения необходимых объектов. Пример инструмента разметки;
- выборочно проверяем результаты работы разметчиков;
- при необходимости осуществляем аугментацию: обычно добавляем повороты, отражение, меняем резкость (формируем расширенный размеченный датасет).
Использование зон детектирования
Одной из проблем с подсчетом людей в очереди является пересечение областей видимости нескольких камер. В помещении может быть установлено более одной камеры, поэтому важно сохранять зону перекрытия изображений, и при попадании человека в область видимости нескольких камер он должен учитываться в расчете один раз.
В отдельных ситуациях нужно детектировать людей лишь в некоторой зоне помещения (около окон обслуживания) или площадки (около оборудования).
По понятным причинам неправильно проверять, что граница-прямоугольник (box/рамка), ограничивающий человека целиком, попадает в зону (полигон). В этой ситуации нижняя (треть/половина) прямоугольника делится на точки – узлы (берется сетка 10 на 10 узлов) и проверяется попадание в зону отдельных выделенных узлов. «Знаковые» узлы выделяются администратором системы исходя из геометрии помещения (также подобраны значения «по умолчанию» – если настройка для конкретного помещения не введена).

Кроме того, тестируется применение архитектуры Mask R-CNN под наши задачи. Метод позволяет определять контур силуэта – это даст возможность уйти от использования границы-прямоугольника при анализе пересечения с зоной.

Другой подход: детектирование голов (обучение модели)
Не всегда качество достигается выбором модели, увеличением/изменением обучающей выборки и прочими, чисто ML-ными методами. Иногда решающее улучшение можно получить только сменой всей постановки задачи (например, в нашей задаче). В настоящих очередях люди толпятся и потому перекрывают друг друга, поэтому качество распознавания является часто недостаточным для использования только этого метода в реальных условиях.
Возьмем изображение ниже. Закроем глаза на то, что снимок сделан на телефон, и угол его наклона не соответствует углу наклона камер видеонаблюдения. На кадре присутствуют 18 человек, а модель по детектированию силуэтов выделила 11 персон:

Для улучшения результатов мы перешли от определения силуэтов к определению голов. Для этого была обучена модель Faster R-CNN на датасете, взятом по ссылке (в датасет входят кадры с разным количеством людей, в том числе большие скопления, среди которых есть люди разных рас и возрастов).
Плюс мы примерно на треть обогатили датасет кадрами из материала (с видеокамер) заказчика (в основном, из-за того, что в исходном датасете было мало голов в головных уборах). Для самостоятельного обучения модели был полезен туториал.
Основные проблемы, с которыми мы столкнулись, – это качество изображений и масштаб объектов. Головы имеют разные размеры (как видно из изображения выше), а кадры с камер заказчика имели разрешение 640х480, из-за этого у нас в качестве голов иногда детектируются интересные объекты (капюшоны, елочные шарики, спинки стульев).
Например, в обучающем датасете у нас есть размеченные головы:
 – это головы в датасете;
– это головы в датасете; – а это спинка стула, но модели хочется верить, что это голова.
– а это спинка стула, но модели хочется верить, что это голова.Однако в целом данная модель достаточно хорошо справляется в случаях, когда наблюдается массовое скопление людей. Так, на кадре выше наша модель определила 15 человек:
Таким образом, на данном изображении модель не смогла найти только три головы, которые были значительно перекрыты посторонними предметами.
Для улучшения качества модели можно заменять текущие камеры на камеры с более высоким разрешением и дополнительно собирать и размечать обучающий датасет.
Тем не менее стоит учитывать, что при малом количестве людей больше подходит способ детектирования по силуэтам, чем по головам, так как силуэт сложнее полностью перекрыть или спутать с посторонними предметами. Однако при наличии толпы нет выхода, поэтому для подсчета людей в очереди было решено использовать две модели параллельно – по головам и силуэтам – и комбинировать ответ.
Силуэты и головы, пример результата распознавания:

Оценка точности
При тестировании модели выбирались кадры, не участвовавшие в обучении (датасет с различным количеством людей на кадре, в разных ракурсах и различного размера), для оценки качества модели мы использовали recall и precision.
Recall – полнота показывает, какую долю объектов, реально относящихся к положительному классу, мы предсказали верно.
Precision – точность показывает, какую долю объектов, распознанных как объекты положительного класса, мы предсказали верно.
На кадрах с камер на тестовых площадках (в датасете присутствовали изображения в этих помещениях) метрики:

На кадрах с новых камер (в датасете не были представлены эти помещения):

Когда заказчику была необходима одна цифра, комбинация точности и полноты, мы предоставляли гармоническое среднее, или F-меру:
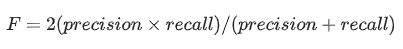
Отчетность
Важная часть сервиса – статистика. Вместе с отдельными кадрами (и выделенными, посчитанными людьми на них) заказчики хотят видеть результаты в виде готовых отчетов (дашбордов) со средней/максимальной заполненностью для различных временных интервалов. Результат часто интересен в виде графиков и диаграмм, характеризующих распределение количества людей по времени.
Например, в нашем решении для кадра подсчитывается количество людей для обеих моделей (силуэты и головы) и выбирается максимальное. Если в помещении есть несколько камер, сохраняется зона перекрытия изображений (заранее установленная через интерфейс), и при попадании человека в область видимости нескольких камер он учитывается в расчете один раз.
Далее формируется значение количества человек в очереди для нескольких идущих подряд кадров – за интервал ∆t. В течение часа для каждого помещения выгружаются значения для нескольких таких интервалов.
Размер временного интервала и количество интервалов определяются исходя из количества помещений и используемых вычислительных мощностей. Для каждого интервала формируется массив значений с количеством людей в помещении.
Выбирается наиболее часто встречающееся значение (мода). Если встречается несколько значений с одинаковой частотой, выбирается максимальное.
Получившееся значение – это количество людей в очереди, относящееся к моменту времени t, следующему непосредственно за рассматриваемым интервалом. Всего за час получается набор значений для различных интервалов – то есть значения к моментам времени t_1, t_2 …. t_n.
Далее для t_1, t_2 …. t_n вычисляются максимальное и среднее значения количества людей – эти значения отображаются в отчете в качестве пиковой и средней нагрузки для заданного часа.
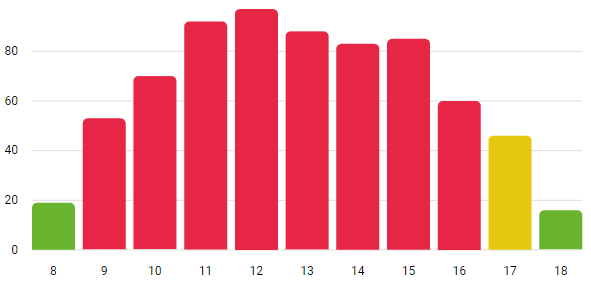
Диаграмма распределения людей по времени для максимальной загрузки (простой пример):

Диаграмма распределения людей по времени для средней загрузки (простой пример):
Толпы
В заключение для полноты освещаемой темы хотелось бы упомянуть о случаях очень больших скоплений людей, например толпах на стадионах, в местах интенсивного людского трафика.
В этих задачах речь идет об оценке размера толпы: если это толпа в 300 человек, ответ 312 или 270 считается приемлемым.
На практике нам не приходилось решать такие задачи с помощью видеоаналитики (если это организованное мероприятие, то проще каждому человеку выдать метку). Однако тестирования мы проводили. Для подобных задач используются отдельные методы, обзор методов.
Был воспроизведен результат работы модели из обзора (модель, предобученная на CSRNet):
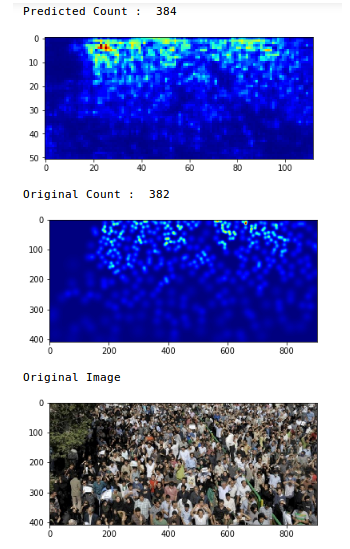
Для настроек данной модели важен ракурс, то есть если место съемки зафиксировано, результат будет лучше, чем при применении на разноплановых снимках. Вообще говоря, есть возможность дообучать эту модель – качество можно улучшать в процессе работы модели, когда идет реальное видео с установленных камер.
Авторы статьи: Татьяна Воронова (tvoronova), Эльвира Дяминова(elviraa)
