Привет, c вами Cloud4Y!
Есть замечательная статья 'Experimenting On My Hearing Loss' by paddlesteamer, которая сама по себе достойна перевода. Но инженер компании Дмитрий Михайлов вместе с Андреем Огурчиковым пошли дальше, испытав методику на себе. Материала получилось много, с обилием кода и аудиограмм. Поэтому мы разбили его на две части. В первой расскажем, зачем нам понадобилось "играться" со звуком и опубликуем перевод статьи, ставшей основной для последующей доработки напильником. Вторая часть будет посвящена нашему решению. Если у вас есть сотрудники с нарушениями слуха, рекомендуем к прочтению.
Почему мы этим занялись
Во время пандемии мы развивались и расширяли штат, нанимая сотрудников удалённо, без личных встреч и обязательного сидения в офисе. Тем более что «сидение» в офисе у нас совсем не обязательное. Нашли много интересных ребят, но особенно интересной вышла история с сотрудником, который оказался… глухим. Мы узнали об этом через три месяца после начала работы, причём случайно. Далее расскажем, как так вышло, кем работает этот человек, и что мы сделали, чтобы ему помочь.
Осенью 2020 года HR-отдел представил компании нового сотрудника в отдел разработки. Большой опыт, а также лёгкий характер позволили ему легко влиться в коллектив. Задачи решались быстро, в помощи коллегам он не отказывал, свободно общался на любые темы. Обычный человек со своими интересами, который хорошо справляется с задачами. А что разговаривали с ним редко и лишь по видеосвязи, так это нормально для удалёнщиков.
Тайное стало явным, когда он не смог выполнить одну из задач, в которой нужно было прослушать плохого качества аудиозапись. Разработчик честно предупредил руководителя, что эта задача может затянуться из-за того, что он не слышит половины того, что есть в записи. Именно по причине глухоты.
Выяснилось, что у него с рождения двусторонняя нейросенсорная тугоухость второй степени. Чтобы было понятно, это как если плотно заткнуть уши комочками ваты, а затем пойти на многолюдную площадь. Вы будете слышать монотонный гул, но различать слова не сможете, даже если специально напрягаться, пытаясь выделить чей-то голос. Кстати, откуда идёт звук, определить тоже сложно. Вообще, такая потеря слуха, — не самое страшное, что может случиться с человеком. Но ему приходится использовать слуховые аппараты в повседневной жизни. И выкручивать на максимум громкость при общении по зуму или телефону, а ещё настраивать уровень звука через инженерное меню. Штатного диапазона громкости не хватает.
Задачу перевели на другого сотрудника. Но нашего руководителя задела проблема подопечного. И он обсудил с инженерами возможность помочь человеку, создав для него более комфортные условия. Хотелось, чтобы он мог нормально слышать через наушники любые звуки без покупки какого-то супернавороченного слухового аппарата. ИТ-отдел стал копать в этом направлении и наткнулся на интересную статью, на основании которой мы и написали своё решение. Так человек получил возможность полноценно слышать коллег, а компания — довольного сотрудника.
На чём именно базировалось наше решение? На идее из поста в блоге paddlesteamer. С этого всё и пошло. Ниже начинается перевод его исследования.

В последнее время я думал о том, чтобы изменить аудиовыход моего компьютера в соответствии с моей аудиограммой. Аудиограмма — это, по сути, график пороговых значений частоты в дБ. Вот моя аудиограмма:
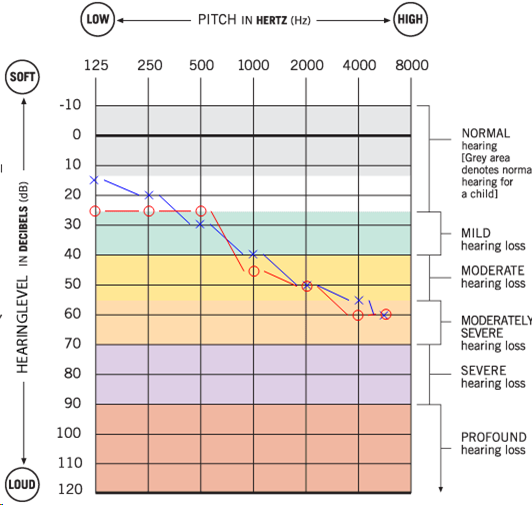
Аудиограмму легко читать. 0 дБ означает самый тихий звук, который может слышать нормальный молодой человек. Красная линия показывает пороговые значения моего правого уха, а синяя линия принадлежит моему левому уху. Пойдём по красной линии. Согласно моей аудиограмме, на частоте 250 Гц самый низкий уровень, который я слышу, — это звуки на уровне 25 дБ. На частоте 6000 Гц я не слышу звука ниже 60 дБ. Аудиограммы обычно показывают пороговые значения в дБ от 125 Гц до 8000 Гц, потому что это частотный диапазон человеческого голоса.
Я решил добавить динамическое усиление к выходному звуку в зависимости от его частотного диапазона, чтобы иметь возможность пользоваться компьютером без слуховых аппаратов. Для этого я планировал написать плагин LADSPA и использовать его с Pulseaudio. Вот мой предыдущий пост о том, как его написать. В этом посте я не буду углубляться в LADSPA, а просто расскажу о своих исследованиях.
Чтобы лучше понимать суть написанного, рекомендую почитать о дискретизации и преобразовании Фурье. Лучшее объяснение преобразования Фурье можно найти здесь (ооочень увлекательное чтение — прим. переводчика).
Итак, начнём. Давайте сгенерируем звук из синусоидальных волн с частотами от 440 Гц до 8000 Гц и частотой дискретизации 44100 Гц:
Генерируем звук
from scipy.io import wavfile
import numpy as np
def generateSamples(sampleRate):
startFreq = 440 # Hz
endFreq = 8000 # Hz
freqInc = 20 # Hz
incPeriod = 0.05 # seconds
incSampleCount = int(sampleRate*incPeriod)
samples = np.array([])
freq = startFreq
t = 0.0
while freq < endFreq:
tarray = np.linspace(t, t + incPeriod, incSampleCount, endpoint=False)
newSamples = np.sin(2 * np.pi * freq * tarray)
newSamples *= 0.05 # choose a low sound
samples = np.append(samples, newSamples)
freq += freqInc
t += incPeriod
return samples
if __name__ == "__main__":
sampleRate = 44100
samples = generateSamples(sampleRate)
wavfile.write("generated.wav", sampleRate, samples)
Далее возьмём часть сгенерированных сэмплов. Это будет наше окно. Сделаем преобразование Фурье в этом окне, чтобы попасть в частотную область. Затем найдём частоту с самым высоким дБ, которая будет нашей доминирующей частотой. Определим, какой коэффициент усиления необходим на этой частоте в соответствии с аудиограммой, и применим его к окну. Повторим для всех окон. Кстати, я буду использовать Python для всего этого.
Работаем с аудиограммой
from scipy.io import wavfile
import numpy as np
import sys
audiogram = [ # rows [ Hz, dB ]
[125.0, 25.0],
[250.0, 25.0],
[500.0, 25.0],
[1000.0, 45.0],
[2000.0, 50.0],
[4000.0, 60.0],
[6000.0, 60.0]
]
# we're going to calculate the necessary gain according to below value
# 25 dB is in the normal hearing area. see audiogram
basedB = 25.0 # dBВот функция, которая вычислит доминирующую частоту. Она выполняет преобразование Фурье к заданному окну, находит индекс наибольшей амплитуды и, наконец, возвращает соответствующее значение частоты.
Функция
# find dominant frequency in the window
def getDominantFreq(sampleRate, window):
# get frequency domain of the window
yf = np.fft.fft(window)
yf = np.abs(2*yf/len(window))
windowSize = len(window)
maxAmp = 0.0
maxAmpIdx = 0
for i in range(int(windowSize/2)):
if yf[i] <= maxAmp:
continue
maxAmp = yf[i]
maxAmpIdx = i
# find frequency from index
freq = (sampleRate/2)*maxAmpIdx/(windowSize/2)
return freq
getGain находит пороговое значение по аудиограмме и возвращает его отличие от basedB значения. Это усиление, которое мы хотим применить к нашему окну.
Усиление
# how much gain should we apply?
def getGain(freq):
threshold = 0.0
if freq < audiogram[0][0]:
threshold = audiogram[0][1]
else:
found = False
for i in range(len(audiogram)-1):
if freq >= audiogram[i+1][0]:
continue
threshold = (audiogram[i+1][1] - audiogram[i][1]) * (freq - audiogram[i][0]) \
/ (audiogram[i+1][0] - audiogram[i][0]) + audiogram[i][1]
found = True
break
if not found:
threshold = audiogram[-1][1]
return threshold - basedB
Простая функция для преобразования дБ в амплитуду.
# converts dB to amplitude
def dBToAmplitude(dB):
return np.power(10.0, dB / 20.0)А теперь основная часть. Cначала wav-файл загружается в память, далее разбивается на части — сэмплы — в соответствии с размером окна, затем каждый сэмпл обрабатывается функциями getDominantFreq, которая определяет главную частоту сэмпла, и getGain — проверяет частоту по аудиограмме и, при необходимости, увеличивает амплитуду главной частоты. В конце все сэмплы записываются в новый файл processed.wav.
Вот так это выглядит
if __name__ == "__main__":
# load samples
sampleRate, samples = wavfile.read(sys.argv[1], mmap=True)
# output samples
outSamples = np.array([])
windowSize = 1024
sampleIdx = 0
while sampleIdx < len(samples):
window = samples[sampleIdx:sampleIdx+windowSize]
freq = getDominantFreq(sampleRate, window)
gain = getGain(freq)
amp = dBToAmplitude(gain)
amplified = window * amp
outSamples = np.append(outSamples, amplified)
sampleIdx += windowSize
wavfile.write("processed.wav", sampleRate, outSamples)
Теперь давайте запустим наш код на сгенерированных синусоидальных волнах:
$ python3 version1.py generated.wav
Мы видим, что более высокое усиление применяется к более высоким частотам, чего мы и хотим. Давайте попробуем это на реальном примере. Взгляните на небольшую часть одной из моих любимых книг:

Скачать аудиофайл (Страсти по Лейбовицу)
Давайте запустим наш код с этой записью:
$ python3 version1.py canticle_for_liebowitz.wav
Проклятье! У меня болят уши. Проблема в том, что мы применяем усиление, даже если оно находится в моём диапазоне слышимости. Не стоит добавлять усиление к звуку 65 дБ на любой частоте. Кроме того, даже если он находится за пределами моего диапазона слышимости, не следует его слишком сильно усиливать. Скажем, если у нас есть звук с 55 дБ при 4000 Гц, его не надо усиливать до 85 дБ, это слишком много. Все, что требуется, это переместить его в мой слуховой диапазон.
Но что такое 55 дБ? Например, когда у нас есть амплитуда 0,1, мы можем рассчитать эквивалент в дБ как 20 * log(0.1) = -20 дБ. Или мы знаем, что 0 дБ - это полное усиление громкости на 10^(0/20) = 1.0. Так что же, чёрт возьми, означает 55 дБ на «языке аудиограмм»?
Ответ лежит в дБ HL и дБ SPL. HL означает уровень слуха, а SPL означает уровень звукового давления. дБ SPL - это в основном измерение звукового давления. Таким образом, звук без давления составляет 0 дБ, а другие - выше 0 дБ. Уровни слуха - это уровни звукового давления в дБ, адаптированные для аудиограммы. Вы помните, что на аудиограммах диапазон слышимости людей начинается от 0 дБ? Хорошо, что 0 дБ HL выше 0 дБ по шкале SPL и отличается на каждой частоте из-за того, что слышит человеческое ухо. Вот хороший материал об этом.
Существует множество диаграмм преобразования дБ HL в дБ SPL. Эти преобразования различаются между аудиометрами и наушниками, используемыми на этих аудиометрах.

Проблема здесь в том, что я не знаю стандарта калибровки моей аудиограммы и не знаю, с какими наушниками меня проверяли. Так что придётся собирать собственные данные. Давайте проведём собственный тест слуха! Не будем использовать дБ SPL, а просто измерим обычные значения дБ с моего компьютера. Результат будет зависеть от моего компьютера, но это нормально. По крайней мере, это надёжно.
Создадим синусоидальные волны на частотах 125 Гц, 250 Гц, 500 Гц, 1000 Гц, 2000 Гц, 4000 Гц и 6000 Гц с уменьшающейся громкостью. Затем я прослушаю аудиофайлы и отмечу моменты, когда я что-то слышу.
Генерируем частоты
import numpy as np
from scipy.io import wavfile
if __name__ == "__main__":
sampleRate = 44100
duration = 0.05
sampleCount = sampleRate * duration
for freq in [125, 250, 500, 1000, 2000, 4000, 6000]:
samples = np.array([])
amp = 0.01
t = 0.0
while True:
ta = np.linspace(t, t+duration, sampleCount)
startTime = np.round(t, 2)
endTime = np.round(t+0.05, 2)
dB = np.round(20 * np.log10(amp), 2)
print(f"{startTime}-{endTime}s: {dB} dB")
namples = np.sin(2 * np.pi * freq * ta)
namples *= amp
t += duration
amp -= 0.0001
samples = np.append(samples, namples)
if amp <= 0.0:
break
wavfile.write(f"sine_{freq}.wav", sampleRate, samples)
Хорошо, результаты есть. Посмотрите на ту классную аудиограмму, которую я создал на Canva:

Ха-ха. Теперь отредактируем наш код. Удалим переменную basedB и добавим в код нашу новую аудиограмму:
Аудиограмма
audiogram = [ # rows [ Hz, dB ]
[125.0, -66.02],
[250.0, -66.02],
[500.0, -67.96],
[1000.0, -60.0],
[2000.0, -47.96],
[4000.0, -44.88],
[6000.0, -44.44]
]Немного отредактируем getDominantFreq, чтобы вернуть дБ доминирующей частоты:
Редактируем
# converts amplitude to dB
def amplitudeTodB(amp):
return 20 * np.log10(amp)
# find dominant frequency in the window
# returns dominant frequency and the dB
def getDominantFreq(sampleRate, window):
# get frequency domain of the window
yf = np.fft.fft(window)
yf = np.abs(2*yf/len(window))
windowSize = len(window)
maxAmp = 0.0
maxAmpIdx = 0
for i in range(int(windowSize/2)):
if yf[i] <= maxAmp:
continue
maxAmp = yf[i]
maxAmpIdx = i
# find frequency from index
freq = (sampleRate/2)*maxAmpIdx/(windowSize/2)
return freq, amplitudeTodB(maxAmp)Теперь getGain(). Изменим return часть:
Меняем
# how much gain should we apply?
def getGain(freq, dB):
threshold = 0.0
if freq < audiogram[0][0]:
threshold = audiogram[0][1]
else:
found = False
for i in range(len(audiogram)-1):
if freq >= audiogram[i+1][0]:
continue
threshold = (audiogram[i+1][1] - audiogram[i][1]) * (freq - audiogram[i][0]) \
/ (audiogram[i+1][0] - audiogram[i][0]) + audiogram[i][1]
found = True
break
if not found:
threshold = audiogram[-1][1]
# I can already hear it, no need to apply gain
if threshold <= dB:
return 0.0
# move the samples slightly in my hearing range
return threshold - dB + 3Теперь проверяем, попадают ли образцы в мой слуховой диапазон. Если я что-то слышу, нет необходимости применять усиление. Если звук выходит за пределы моего диапазона слышимости, перемещаем его в мой диапазон слышимости. Но не усиливаем его слишком сильно, потому что это исказит звук.
Не буду касаться остальной части кода. Окончательная версия приведена ниже:
Финал
from scipy.io import wavfile
import numpy as np
import sys
audiogram = [ # rows [ Hz, dB ]
[125.0, -66.02],
[250.0, -66.02],
[500.0, -67.96],
[1000.0, -60.0],
[2000.0, -47.96],
[4000.0, -44.88],
[6000.0, -44.44]
]
# find dominant frequency in the window
# returns dominant frequency and the dB
def getDominantFreq(sampleRate, window):
# get frequency domain of the window
yf = np.fft.fft(window)
yf = np.abs(2*yf/len(window))
windowSize = len(window)
maxAmp = 0.0
maxAmpIdx = 0
for i in range(int(windowSize/2)):
if yf[i] <= maxAmp:
continue
maxAmp = yf[i]
maxAmpIdx = i
# find frequency from index
freq = (sampleRate/2)*maxAmpIdx/(windowSize/2)
return freq, amplitudeTodB(maxAmp)
# how much gain should we apply?
def getGain(freq, dB):
threshold = 0.0
if freq < audiogram[0][0]:
threshold = audiogram[0][1]
else:
found = False
for i in range(len(audiogram)-1):
if freq >= audiogram[i+1][0]:
continue
threshold = (audiogram[i+1][1] - audiogram[i][1]) * (freq - audiogram[i][0]) \
/ (audiogram[i+1][0] - audiogram[i][0]) + audiogram[i][1]
found = True
break
if not found:
threshold = audiogram[-1][1]
# I can already hear it, no need to apply gain
if threshold <= dB:
return 0.0
# move the samples slightly in my hearing range
return threshold - dB + 3
# converts dB to amplitude
def dBToAmplitude(dB):
return np.power(10.0, dB / 20.0)
# converts amplitude to dB
def amplitudeTodB(amp):
return 20 * np.log10(amp)
if __name__ == "__main__":
# load samples
sampleRate, samples = wavfile.read(sys.argv[1], mmap=True)
# output samples
outSamples = np.array([])
windowSize = 1024
sampleIdx = 0
while sampleIdx < len(samples):
window = samples[sampleIdx:sampleIdx+windowSize]
freq, dB = getDominantFreq(sampleRate, window)
gain = getGain(freq, dB)
startSec = np.round(sampleIdx/ sampleRate, 2)
endSec = np.round((sampleIdx + windowSize)/ sampleRate, 2)
if gain > 0.0:
print(f"{startSec}-{endSec}s: freq: {freq} Hz, dB: {dB} dB, gain: {gain} dB")
amp = dBToAmplitude(gain)
amplified = window * amp
outSamples = np.append(outSamples, amplified)
sampleIdx += windowSize
wavfile.write("processed.wav", sampleRate, outSamples)
Что же у нас получилось?

Это очень хорошо! Вы слышите небольшие искажения между ними? Мне они не кажутся искажёнными. Конечно, они могут звучать неестественно, но зато мне легче понять, что говорит собеседник.
Я многому научился из этого процесса, особенно тому, как работает моё ухо, как работает звук. Не могу поверить, что не изучал это до сих пор. Я хочу разработать ещё несколько проектов, касающихся моего нарушения слуха, и, возможно, даже сделаю свой собственный слуховой аппарат.
Продолжение с адаптацией кода под наши нужды — во второй части статьи.
Что ещё интересного есть в блоге Cloud4Y
→ Изучаем своё железо: сброс паролей BIOS на ноутбуках
→ Частые ошибки в настройках Nginx, из-за которых веб-сервер становится уязвимым
→ Фишинг с поддельным приглашением на встречу
→ Облачная кухня: готовим данные для мониторинга с помощью vCloud API и скороварки
→ Подготовка шаблона vApp тестовой среды VMware vCenter + ESXi
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу.
