Практически любой бизнес сталкивается с плавающей нагрузкой: то тишина, то шквал. За примерами далеко ходить не надо:
- посещаемость интернет-магазина может значительно колебаться в зависимости от времени суток или сезона;
- внутренние сервисы компаний могут «пустовать» неделями, а накануне сдачи квартального отчета их посещаемость резко подскочит.
Под катом поговорим о том, как мы помогли клиентам решить эту проблему, внедрив новый уровень хранения с настраиваемыми показателями IOPS.
Пара слов о дисках
Все наши клиенты хотят плюс-минус одного — получить надежную, соответствующую требованиям бизнес-процессов инфраструктуру по хорошей цене. Соответственно, перед нами как перед облачным провайдером стоит задача построить услуги и сервисы таким образом, чтобы для каждого клиента мы могли без труда подобрать оптимальное решение.
Ранее у нас было два уровня хранения данных: st2 и gp2. Цифра «2» в нашей внутренней терминологии означает более новую, улучшенную версию.
st2: Standard (HDD) — неторопливые и недорогие носители на SAS HDD. Отлично подходят для сервисов, где IOPS не имеют решающего значения, но важна пропускная способность.
Параметры у них следующие: время отклика — не более 10 мс, производительность дисков размером до 2000 ГБ — 500 IOPS, от 2000 ГБ — 1000 IOPS, а пропускная способность растет с каждым гигабайтом и доходит до 500 МБ/с на тех же 2000 ГБ.
gp2: Universal (SSD) — более дорогие и быстрые накопители на SAS SSD. Подходят заказчикам, чьи приложения более требовательны к количеству операций ввода-вывода в секунду. Например — базы данных интернет-магазинов.
Параметры gp2 указаны в SLA. Производительность в IOPS рассчитывается по объему — на 1 ГБ приходится 10 IOPS. Верхняя планка — 10000 IOPS. А время отклика таких дисков уже не более 2 мс. Это довольно высокая производительность, способная закрыть 97% бизнес-задач.
За годы работы мы накопили достаточно много статистики и экспертизы в отношении заказчиков и заметили, что некоторым из них не совсем комфортно выбирать из двух вариантов дисков. Например, кому-то требуется производительность повыше, чем 10 IOPS на гигабайт объема. Или плавающая нагрузка не дает возможность остановиться на одном из типов, а платить за готовые к часу пик, но периодически простаивающие мощности — тоже не вариант.
Можно смоделировать простой злободневный кейс. В период пандемии одной компании потребовалось оформить пропуска для сотрудников. Чтобы они спокойно по Москве ездили. Штат большой, две тысячи человек. Вышел приказ срочно обновить личные данные в корпоративной CRM-системе. Сказано — сделано. Больше тысячи человек одновременно бросились актуализировать информацию. Но CRM-кой занимались экономные люди. Мощностей выделили мало. Никто же не ожидал, что в нее больше десяти человек одновременно полезет! Все упало и еще сутки не могло подняться. Бизнес-процессы нарушились, люди сидят по домам и боятся штрафов. А если бы существовала возможность гибко «подкрутить» производительность дисков в облаке — подняли бы IOPS ненадолго, а потом вернули, как было, исключив или значительно сократив время простоя CRM.
С одной стороны, ситуация гротескная, процент заказчиков с такими потребностями не очень велик. Маленький провайдер и вовсе принял бы их существование за статистическую аномалию и не предпринимал бы никаких действий. С другой — организация нового уровня хранения позволит нам повысить гибкость услуг для всех клиентов. Значит, делать надо.
Если вы давно следите за нашим блогом, то наверняка помните статью, в которой мы рассказывали о череде экспериментов над Dell EMC ScaleIO (ныне PowerFlex OS) и его внедрении в Облако КРОК. Как бы то ни было, рекомендуем вам ознакомиться с ней для общего понимания.
В общих чертах скажем: ScaleIO (DellEMC переименовал ScaleIO сначала в VxFlex OS, а c 25 июня 2020 года в PowerFlex OS) — супер универсальный и надежный Software-Defined Storage, SDS. У нас надежность — это требование №0. Поэтому каждый узел, составляющий часть Storage Pool’а установлен в отдельную стойку, что исключает возможность потери данных при частичной потере электропитания в ЦОД или локально в стойке.
Если из строя выйдет диск, сервер или целая стойка, у нас будет достаточно времени, чтобы отреплицировать данные на другие хосты и в последствии заменить сбойный элемент. Если умрут сразу две стойки, все равно ничего не потеряется. В этой ситуации кластер перейдет в аварийный режим, запись и чтение данных с дисков будет ограничено, но после восстановления связности с «упавшей» стойкой PowerFlex OS сам займется процессом Rebuild’а данных и восстановления работы кластера. Такой процесс, кстати, чаще всего занимает не более пары минут.
Это, безусловно, аварийная ситуация — приложения, которые не смогут писать и читать, тут же «отвалятся», но потеря даже такой большой части инфраструктуры не уничтожит данные. Пусть вероятность отказа двух стоек в разных частях машинного зала крайне мала — это не значит, что ее не нужно брать в расчет.
С точки зрения универсальности PowerFlex OS (бывш. ScaleIO) также идеально подходит под наши требования. Фактически это конструктор, готовый к приему любых нагрузок и способный «принимать» и медленные SATA/SAS HDD диски, и быстрые SSD, и ультра-скоростные NVME накопители. И это действительно правда – проверено на многочисленных stage- и testing-стендах команд разработки и эксплуатации, собрать кластер можно практически из
Музыка с пяти до шести
Давайте рассмотрим один из сценариев, в которых заказчику может потребоваться гибкая производительность, на реальном примере. Среди наших клиентов есть сеть магазинов музыкальных инструментов. Технические специалисты компании отслеживают, сколько посетителей посещают их сайт в каждый день и час. Это отражено даже в нашем SLA: с 17:00 до 18:00 магазин получает максимальное количество покупателей, поэтому никаких технических работ или простоев быть не должно.
Стандартная практика расчетов — когда 100% нагрузки делятся 24 часа. Выходит примерно 4% на каждый час. У сети музыкальных магазинов этот конкретный час «весит» не 4, а 10% — это десятки тысяч посетителей и покупателей.
Соответственно, заказчику было бы очень удобно, если бы в этот «золотой» час их диски как по волшебству становились быстрее,
Теперь у нас появилась возможность в самые нагруженные часы выдавать клиентам хоть 30, хоть 50 тысяч IOPS, а в остальное время держать производительность на обычном уровне. Такой тип хранения мы назвали io2: Ultimate (SSD). Время отклика дисков на основе этого типа хранения уже не более 1 мс!
И снова о надежности: st2, gp2 и новый io2 — это самостоятельные, независимые друг от друга Storage Pool’ы в кластере PowerFlex.
Если раньше клиент выбирал диск и получал фиксированную производительность, то теперь он может ее, производительность, выбирать и настраивать. Вне зависимости от объема. Философия здесь следующая: получить огромный и быстрый диск можно у большого количества провайдеров, но готовы ли вы платить за него 100% времени?
Как управлять
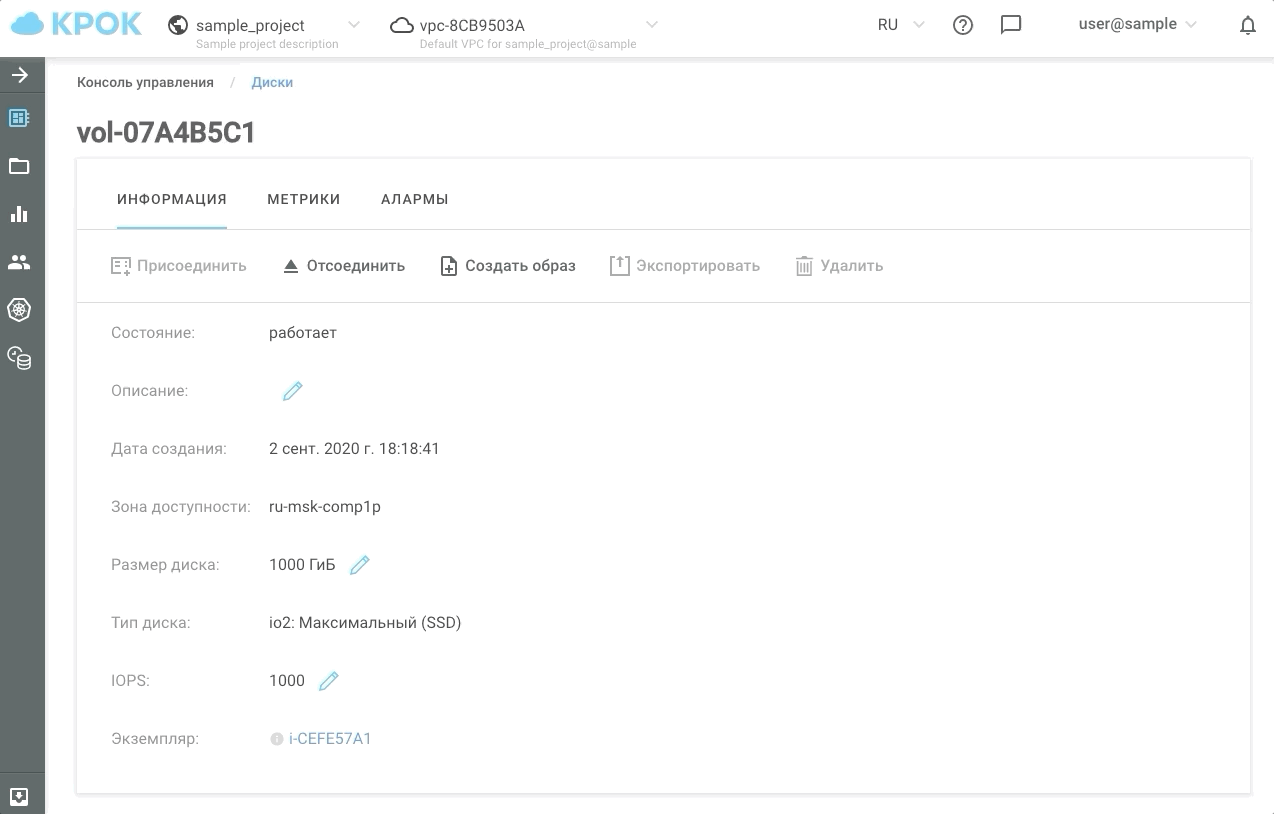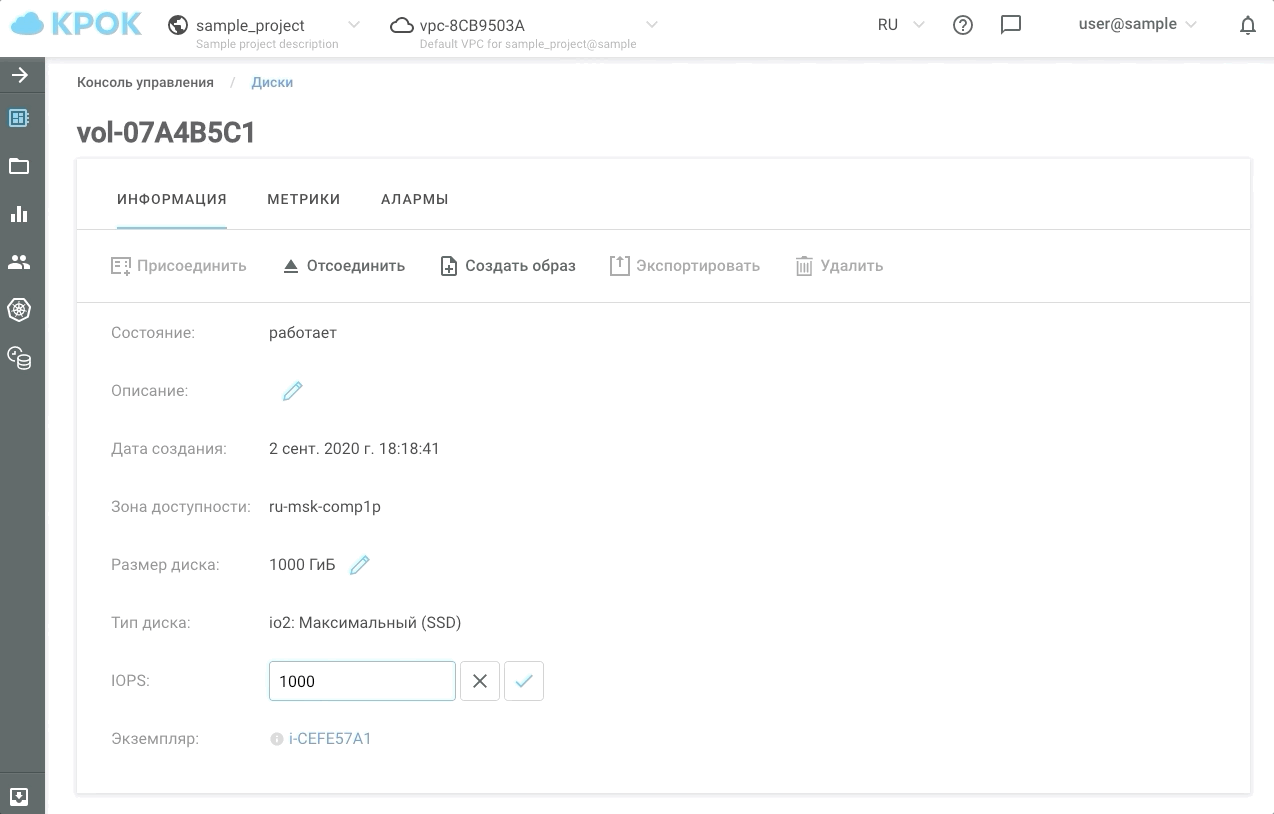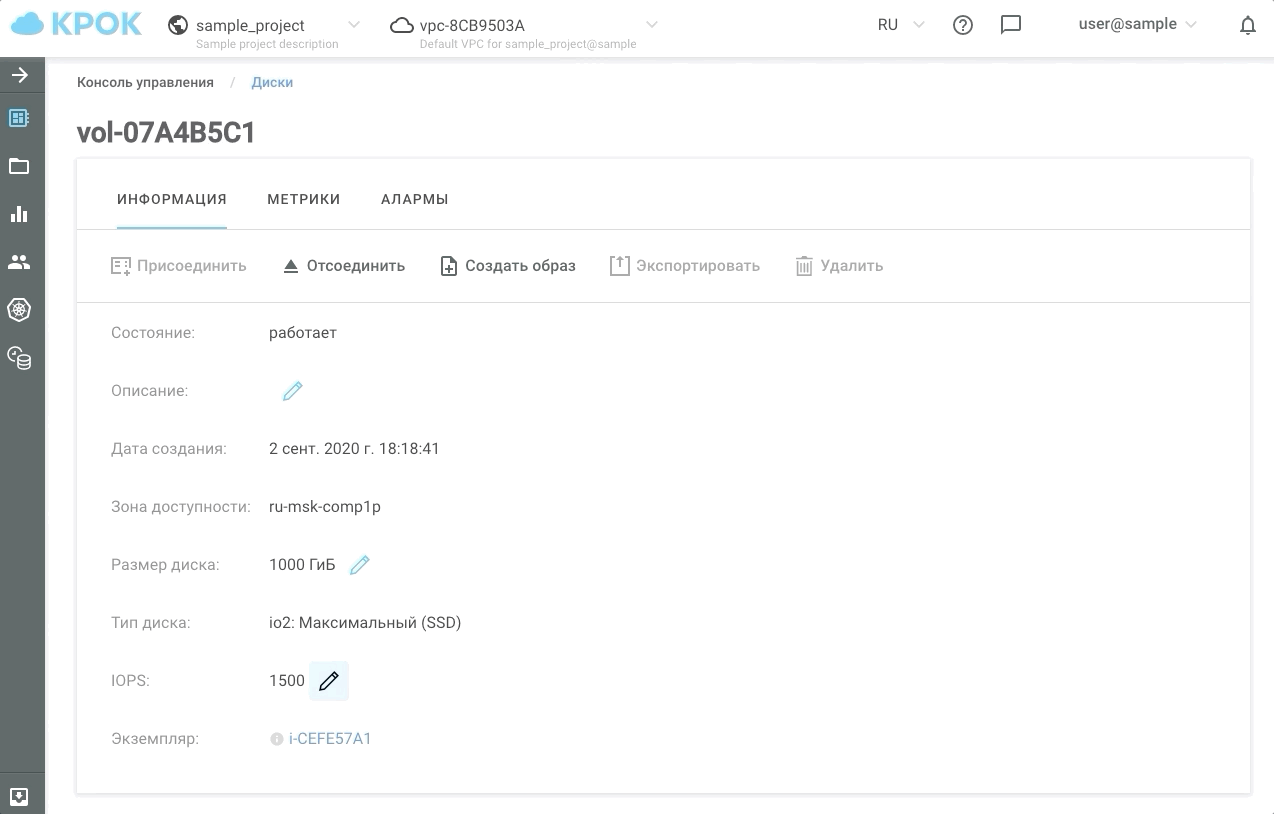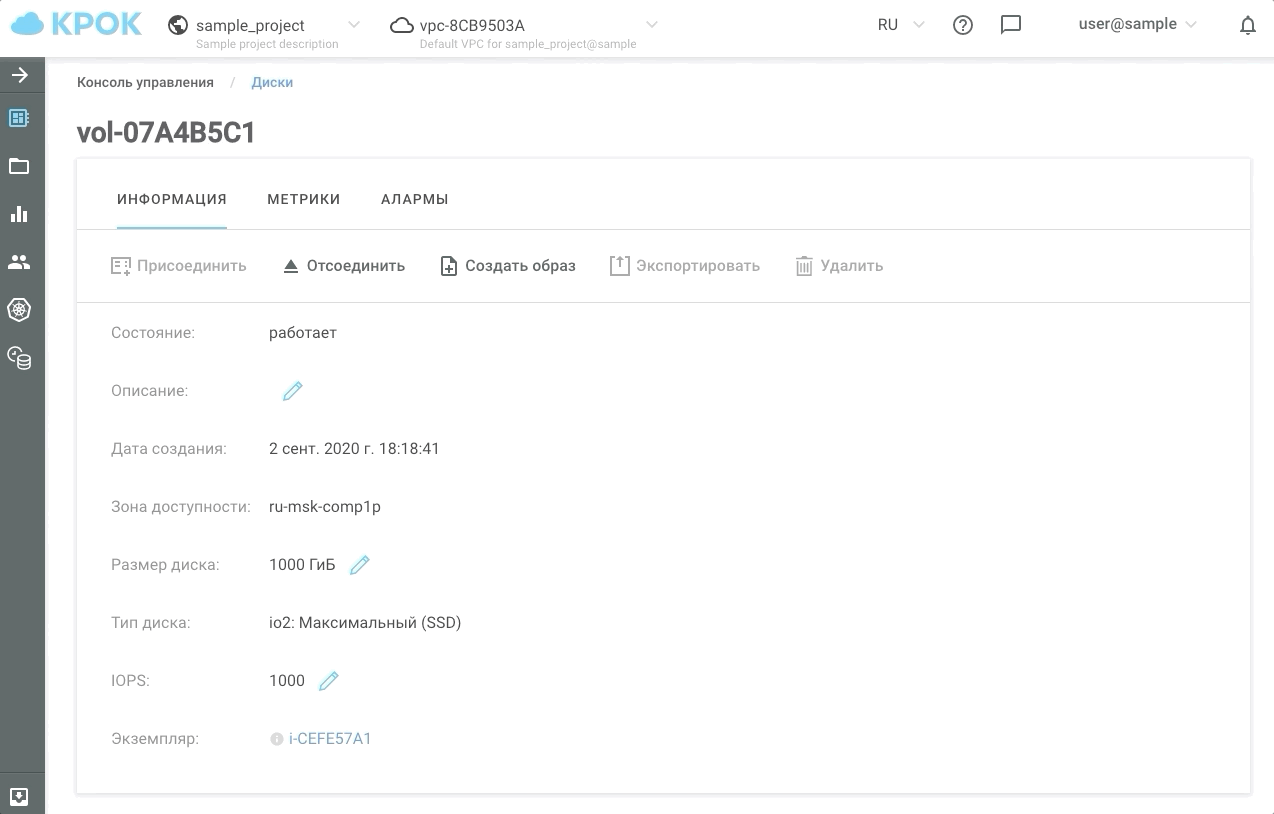
Управлять производительностью можно двумя способами: по старинке, через веб-интерфейс, и с помощью API. Это дает возможность написать простые скрипты, которые по расписанию будут «ускорять» или «замедлять» диски и, соответственно, экономить ваши деньги.
Если раньше мы могли принять любую нагрузку, требующуюся клиенту, теперь мы можем сделать это по оптимальной цене.
Вот, как это выглядит на практике
Повышение адаптивности облачной инфраструктуры — это актуальный и очень правильный тренд. Нельзя говорить заказчику: «бери, что дают, а то и этого не будет!». Он должен иметь возможность решать, какие ресурсы, когда и в каком объеме ему требуются. Именно за такими гибкими и надежными решениями — будущее.
За свои сервисы мы ручаемся: все параметры прописаны в SLA, и вы можете рассчитывать на то, что «бумажные» цифры с реальными не разойдутся.
А как проверить своего облачного провайдера, мы уже писали в предыдущей статье.
