
Автор: Денис Цыплаков, Solution Architect, DataArt
За годы работы я обнаружил, что программисты из раза в раз повторяют одни и те же ошибки. К сожалению, книги, посвященные теоретическим аспектам разработки, избежать их не помогают: в книгах обычно нет конкретных, практических советов. И я даже догадываюсь, почему…
Первая рекомендация, которая приходит в голову, когда речь заходит, например, о логировании или дизайне классов, очень простая: «Не делать откровенной ерунды». Но опыт показывает, что ее определенно недостаточно. Как раз дизайн классов в этом случае хороший пример — вечная головная боль, возникающая из-за того, что каждый смотрит на этот вопрос по-своему. Поэтому я и решил собрать в одной статье базовые советы, следуя которым, вы избежите ряда типичных проблем, а главное, избавите от них коллег. Если некоторые принципы покажутся вам банальными (потому что они действительно банальны!) — хорошо, значит, они уже засели у вас в подкорке, и вашу команду можно поздравить.
Оговорюсь, на самом деле, мы сосредоточимся на классах исключительно для простоты. Почти то же самое можно сказать о функциях или любых других строительных блоках приложения.
Если приложение работает и выполняет задачу, значит, его дизайн хорош. Или нет? Зависит от целевой функции приложения; то, что вполне годится для мобильного приложения, которое надо один раз показать на выставке, может совершенно не подойти для трейдинговой платформы, которую какой-нибудь банк развивает годами. В какой-то мере, ответом на поставленный вопрос можно назвать принцип SOLID, но он слишком общий — хочется каких-то более конкретных инструкций, на которые можно ссылаться в разговоре с коллегами.
Целевое приложение
Поскольку универсального ответа быть не может, предлагаю сузить область. Давайте считать, что мы пишем стандартное бизнес-приложение, которое принимает запросы через HTTP или другой интерфейс, реализует какую-то логику над ними и далее либо делает запрос в следующий по цепочке сервис, либо где-то сохраняет полученные данные. Для простоты давайте считать, что мы используем Spring IoC Framework, благо он сейчас достаточно распространен и остальные фреймворки на него изрядно похожи. Что мы можем сказать о таком приложении?
- Время, которое процессор тратит на обработку одного запроса, важно, но не критично — прибавка в 0,1 % погоды не сделает.
- В нашем распоряжении нет терабайтов памяти, но если приложение займет лишние 50–100 Кбайт, катастрофой это не станет.
- Конечно, чем короче время старта, тем лучше. Но принципиальной разницы между 6 сек и 5.9 сек тоже нет.
Критерии оптимизации
Что важно для нас в этом случае?
Код проекта, скорее всего, будет использоваться бизнесом несколько, а может, и более десяти лет.
Код в разное время будут модифицировать несколько незнакомых друг с другом разработчиков.
Вполне возможно, через несколько лет разработчики захотят использовать новую библиотеку LibXYZ или фреймворк FrABC.
В какой-то момент часть кода или весь проект могут быть слиты с кодовой базой другого проекта.
В среде менеджеров принято считать, что такого рода вопросы решаются с помощью документации. Документация, безусловно, хороша и полезна, ведь так здорово, когда вы начинаете работу над проектом, на вас висит пять открытых тикетов, проджект-менеджер спрашивает, как там у вас с прогрессом, а вам надо прочитать (и запомнить) каких-то 150 страниц текста, написанных далеко не гениальными литераторами. У вас, конечно, было несколько дней или даже пара недель на вливание в проект, но, если использовать простую арифметику, — с одной стороны 5,000,000 байт кода, с другой, скажем, 50 рабочих часов. Получается, что в среднем надо было вливать в себя 100 Кбайт кода в час. И тут все очень сильно зависит от качества кода. Если он чистый: легко собирается, хорошо структурирован и предсказуем, то вливание в проект кажется заметно менее болезненным процессом. Не последнюю роль в этом играет дизайн классов. Далеко не последнюю.
Чего мы хотим от дизайна классов
Из всего перечисленного можно сделать много интересных выводов про общую архитектуру, стек технологий, процесс разработки и т. д. Но мы с самого начала решили поговорить о дизайне классов, давайте разберемся, что полезного мы можем извлечь из сказанного ранее применительно к нему.
- Хочется, чтобы разработчик, досконально не знакомый с кодом приложения, мог, глядя на класс, понять, что этот класс делает. И наоборот — глядя на функциональное или нефункциональное требование, мог бы быстро догадаться, в каком месте приложения находятся классы, за него отвечающие. Ну и желательно, чтобы реализация требований не была «размазана» по всему приложению, а была сосредоточена в одном классе или компактной группе классов. Объясню на примере, что за именно антипаттерн я имею ввиду. Предположим, нам надо проверять, что 10 запросов определенного типа могут исполняться только пользователями, у которых на счету больше 20 очков (неважно, что бы это ни значило). Плохой путь реализации такого требования — в начале каждого запроса вставить проверку. Тогда логика будет размазана на 10 методов, в разных контроллерах. Хороший способ — создать фильтр или WebRequestInterceptor и проверять все в одном месте.
- Хочется, чтобы изменения в одном классе, не затрагивающие контракт класса, не затрагивали, ну или (будем реалистами!) хотя бы не очень сильно затрагивали и другие классы. Иначе говоря, хочется инкапсуляции реализации контракта класса.
- Хочется, чтобы при изменении контракта класса можно было, пройдя по цепочке вызовов и сделав find usages, найти классы, которые это изменение затрагивает. Т. е. хочется, чтобы у классов не было косвенных зависимостей.
- По возможности хочется, чтобы процессы обработки запросов, состоящие из нескольких одноуровневых шагов не размазывались по коду нескольких классов, а были описаны на одном уровне. Совсем хорошо, если код, описывающий такой процесс обработки, умещается на одном экране внутри одного метода с понятным названием. Например нам надо в строке найти все слова, для каждого слова сделать вызов в сторонний сервис, получить описание слова, применить к описанию форматирование и сохранить результаты в БД. Это одна последовательность действий из 4-х шагов. Очень удобно разбираться в коде и менять его логику, когда есть метод, где эти шаги идут один за другим.
- Очень хочется, чтобы одинаковые вещи в коде были реализованы одинаковым образом. Например, если мы обращаемся в БД сразу из контроллера, лучше так делать везде (хотя хорошей практикой такой дизайн я бы не назвал). А если мы уже ввели уровни сервисов и репозиториев, то лучше напрямую из контроллера в БД не обращаться.
- Хочется, чтобы количество классов/интерфейсов, не отвечающих непосредственно за функциональные и нефункциональные требования, было не очень большим. Работать с проектом, в котором на каждый класс с логикой есть два интерфейса, сложная иерархия наследования из пяти классов, фабрика класса и абстрактная фабрика классов, довольно тяжело.
Практические рекомендации
Сформулировав пожелания, мы можем наметить конкретные шаги, которые позволят нам достичь поставленных целей.
Статичные методы
В качестве разминки начну с относительно простого правила. Не стоит создавать статичных методов за исключением случаев, когда они нужны для работы одной из используемых библиотек (например, вам нужно сделать сериализатор для типа данных).
В принципе, ничего плохого в использовании статических методов нет. Если поведение метода полностью зависит от его параметров, почему бы действительно не сделать его статическим. Но нужно учесть тот факт, что мы используем Spring IoC, который служит для связывания компонентов нашего приложения. Spring IoC оперирует понятиями бинов (Beans) и их областей применимости (Scope). Этот подход можно смешивать со статическими методами, сгруппированными в классы, но разбираться в таком приложении и тем более что-то в нем менять (если, например, понадобится передать в метод или класс какой-то глобальный параметр) может быть весьма затруднительно.
При этом статические методы по сравнению с IoC-бинами дают очень незначительное преимущество в скорости вызова метода. Причем на этом, пожалуй, преимущества и заканчиваются.
Если вы не строите бизнес-функцию, требующую большого числа сверхбыстрых вызовов между разным классами, лучше статические методы не использовать.
Тут читатель может спросить: «А как же классы StringUtils и IOUtils?» Действительно, в Java-мире сложилась традиция — вспомогательные функции работы со строками и потоками ввода-вывода выносить в статичные методы и собирать под зонтиком SomethingUtils-классов. Но мне такая традиция кажется достаточно замшелой. Если вы будете следовать ей, большого вреда, конечно, не ожидается — все Java-программисты к этому привыкли. Но и смысла в таком ритуальном действии нет. С одной стороны, почему бы не сделать бин StringUtils, с другой, если не делать бин и все вспомогательные методы сделать статичными, давайте уже делать статичные зонтичные классы StockTradingUtils и BlockChainUtils. Начав выносить логику в статичные методы, провести границу и остановиться сложно. Я советую не начинать.
Наконец, не стоит забывать, что к Java 11 многие вспомогательные методы, десятилетиями кочевавшие за разработчиками из проекта в проект, либо стали частью стандартной библиотеки, либо объединились в библиотеки, например, в Google Guava.
Атомарный, компактный контракт класса
Есть простое правило, применимое к разработке любой программной системы. Глядя на любой класс, вы должны быть способны быстро и компактно, не прибегая к долгим раскопкам, объяснить, что этот класс делает. Если уместить объяснение в один пункт (необязательно, впрочем, выраженный одним предложением) не получается, возможно, стоит подумать и разбить этот класс на несколько атомарных классов. Например, класс «Ищет текстовые файлы на диске и считает количество букв Z в каждом из них» — хороший кандидат на декомпозицию “ищет на диске” + “считает количество букв”.
С другой стороны, не стоит делать слишком мелких классов, каждый из которых рассчитан на одно действие. Но какого же размера тогда должен быть класс? Базовые правила таковы:
- Идеально, когда контракт класса совпадает с описанием бизнес-функции (или подфункции, смотря как у нас устроены требования). Это не всегда возможно: если попытка соблюсти это правило ведет к созданию громоздкого, неочевидного кода, класс лучше разбить на более мелкие части.
- Хорошая метрика для оценки качества контракта класса — отношение его внутренней сложности к сложности контракта. Например очень хороший (пусть и фантастический) контракт класса может выглядеть так: «Класс имеет один метод, который получает на входе строку с описанием тематики на русском языке и в качестве результата сочиняет качественный рассказ или даже повесть на заданную тему». Здесь контракт прост и в целом понятен. Его реализация крайне сложна, но сложность скрыта внутри класса.
Почему это правило важно?
- Во-первых, умение внятно объяснить самому себе, что делает каждый из классов, всегда полезно. К сожалению, далеко не в каждом проекте разработчики могут такое проделать. Часто можно услышать, что вроде: «Ну, это такая обертка над классом Path, которую мы зачем-то сделали и иногда используем вместо Path. Она еще имеет метод, который умеет удваивать в пути все File.separator — нам этот метод нужен при сохранении отчетов в облако, и он почему-то оказался в классе Path».
- Человеческий мозг способен единовременно оперировать не более чем пятью–десятью объектами. У большинства людей — не больше семи. Соответственно, если для решения задачи разработчику нужно оперировать более чем семью объектами, он либо что-то упустит, либо будет вынужден упаковать несколько объектов под один логический «зонтик». И если упаковывать все равно придется, почему бы не сделать это сразу, осознанно, и не дать этому зонтику осмысленное название и четкий контракт.
Как проверить, что у вас все достаточно гранулярно? Попросите коллегу уделить вам 5 (пять) минут. Возьмите часть приложения, над созданием которой вы сейчас работаете. Для каждого из классов объясните коллеге, что именно этот класс делает. Если вы не укладываетесь в 5 минут, или коллега не может понять, зачем тот или иной класс нужен — возможно, вам стоит что-то изменить. Ну или не менять и провести опыт еще раз, уже с другим коллегой.
Зависимости между классами
Предположим, нам надо для PDF-файла, упакованного в ZIP-архив, выделить связанные участки текста длиннее 100 байт и сохранить их в базу данных. Популярный антипаттерн в таких случаях выглядит так:
- Есть класс, который раскрывает ZIP-архив, ищет в нем PDF-файл и возвращает его в виде InputStream.
- Этот класс имеет ссылку на класс, который ищет в PDF абзацы текста.
- Класс, работающий с PDF, в свою очередь имеет ссылку на класс, сохраняющий данные в БД.
С одной стороны, все выглядит логично: получил данные, вызвал напрямую следующий класс в цепочке. Но при этом в контракт класса вверху цепочки примешиваются контракты и зависимости всех классов, которые идут в цепочке за ним. Гораздо правильнее сделать эти классы атомарными и не зависящими друг от друга, и создать еще один класс, который собственно реализует логику обработки, связывая эти три класса между собой.
Как делать не надо:
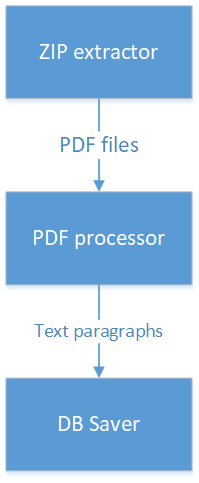
Что здесь не так? Класс, работающий с ZIP-файлами, передает данные классу, обрабатывающему PDF, а тот, в свою очередь, — классу, работающему с БД. Значит, класс, работающий с ZIP, в результате зачем-то зависит от классов, работающих с БД. Кроме того, логика обработки размазана по трем классам, и чтобы ее понять, надо по всем трем классам пробежаться. Что делать, если вам понадобится абзацы текста, полученные из PDF, передать третьестороннему сервису через REST-вызов? Вам надо будет менять класс, который работает с PDF, и втягивать в него еще и работу с REST.
Как надо делать:
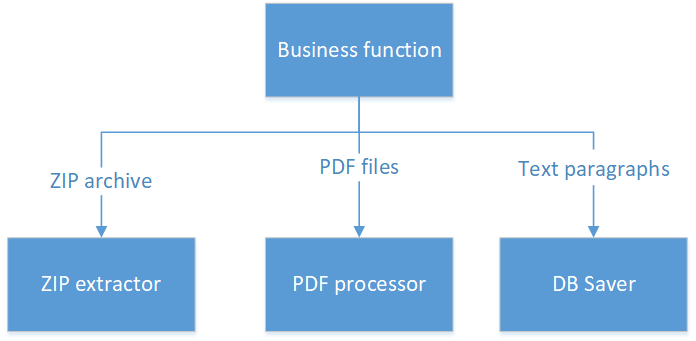
Здесь у нас есть четыре класса:
- Класс, который работает только с ZIP-архивом и возвращает список PDF-файлов (тут можно возразить — возвращать файлы плохо — они большие и сломают приложение. Но давайте в этом случае читать слово «возвращает» в широком смысле. Например, возвращает Stream из InputStream).
- Второй класс отвечает за работу с PDF.
- Третий класс ничего не знает и не умеет, кроме сохранения параграфов в БД.
- И четвертый класс, состоящий буквально из нескольких строчек кода, содержит всю бизнес-логику, которая умещается на одном экране.
Еще раз подчеркиваю, в 2019 году в Java есть как минимум два хороших (и несколько менее
хороших) способа не передавать файлы и полный список всех параграфов как объекты в памяти. Это:
- Java Stream API.
- Callbacks. Т. е. класс с бизнес-функцией не передает данные напрямую, а говорит ZIP Extractor: вот тебе callback, ищи в ZIP-файле PDF-файлы, для каждого файла создавай InputStream и вызывай с ним переданный callback.
Неявное поведение
Когда мы не пытаемся решить совершенно новую, ранее никем не решенную задачу, а напротив, делаем что-то, что другие разработчики уже делали ранее несколько сотен (или сотен тысяч) раз, у всех членов команды есть некие ожидания относительно цикломатической сложности и ресурсоемкости решения. Например, если нам надо в файле найти все слова, начинающиеся с буквы z, это последовательное, однократное чтение файла блоками с диска. Т. е. если ориентироваться на https://gist.github.com/jboner/2841832 —такая операция займет несколько микросекунд на 1 Мб, ну может быть, в зависимости от среды программирования и загруженности системы несколько десятков или даже сотню микросекунд, но никак не секунду. Памяти на это потребуется несколько десятков килобайт (оставляем за скобками вопрос, что мы делаем с результатами, это забота другого класса), и код, скорее всего, займет примерно один экран. При этом мы ожидаем, что никаких других ресурсов системы использовано не будет. Т. е. код не будет создавать нити, писать данные на диск, посылать пакеты по сети и сохранять данные в БД.
Это обычные ожидание от вызова метода:
zWordFinder.findZWords(inputStream). ...Если код вашего класса не удовлетворяет этим требованиям по какой-то разумной причине, например, для классификации слова на z и не z вам надо каждый раз вызвать REST-метод (не знаю, зачем это может быть нужно, но давайте представим такое), это надо очень тщательно прописать в контракте класса, и совсем хорошо, если в имени метода будет указание на то, что метод куда-то бегает советоваться.
Если у вас нет никакой разумной причины для неявного поведения — перепишите класс.
Как понять ожидания от сложности и ресурсоемкости метода? Нужно прибегнуть к одному из этих простых способов:
- С опытом приобрести достаточно широкий кругозор.
- Спросить у коллеги — это всегда можно сделать.
- Перед стартом разработки проговорить с членами команды план реализации.
- Задать себе вопрос: «А не использую ли я в этом методе _слишком_ много избыточных ресурсов?» Обычно этого бывает достаточно.
Излишне увлекаться оптимизацией тоже не стоит — экономия 100 байтов при используемых классом 100,000 не имеет особенного смысла для большинства приложений.
Это правило открывает нам окно в богатый мир оверинжениринга, скрывающем ответы на вопросы вида «почему не стоит тратить месяц, чтобы сэкономить 10 байт памяти в приложении, которому для работы требуется 10 Гбайт». Но эту тему здесь я развивать не стану. Она достойна отдельной статьи.
Неявные имена методов
В Java-программировании на текущий момент сложилось несколько неявных соглашений по поводу имен классов и их поведения. Их не так много, но лучше их не нарушать. Попробую перечислить те из них, которые приходят мне на ум:
- Конструктор — создает экземпляр класса, может создавать какие-то достаточно разветвленные структуры данных, но при этом не работает с БД, не пишет на диск, не посылает данные по сети (оговорюсь, все это может делать встроенный логгер, но это отдельная история и в любом случае лежит она на совести конфигуратора логирования).
- Getter — getSomething() — возвращает какую-то структуру памяти из глубин объекта. Опять же не пишет на диск, не делает сложных вычислений, не посылает данных по сети, не работает с БД (за исключением случая, когда это lazy поле ORM, и это как раз одна из причин, почему lazy поля стоит использовать с большой осторожностью).
- Setter — setSomething (Something something) — устанавливает значение структуры данных, не делает сложных вычислений, не посылает данных по сети, не работает с БД. Обычно от сеттера вообще не ожидается неявного поведения или потребления сколько-нибудь значительных вычислительных ресурсов.
- equals() и hashcode() — не ожидается вообще ничего, кроме простых вычислений и сравнений в количестве, линейно зависимом от размера структуры данных. Т. е. если мы вызываем hashcode для объекта из трех примитивных полей, ожидается, что будет выполнено N*3 простых вычислительных инструкций.
- toSomething() — также ожидается, что это метод, преобразующий один тип данных в другой, и для преобразования ему требуется только количество памяти, сопоставимое с размерами структур, и процессорное время, линейно зависящее от размера структур. Тут надо заметить, что не всегда преобразование типов можно сделать линейно, скажем, преобразование пиксельной картинки в SVG-формат может быть весьма нетривиальным действием, но в таком случае лучше назвать метод по-другому. Например, название computeAndConvertToSVG() выглядит несколько неуклюжим, зато сразу наводит на мысль, что там внутри происходят какие-то значительные вычисления.
Приведу пример. Недавно я делал аудит приложения. По логике работы я знаю, что приложение где-то в коде подписывается на RabbitMQ-очередь. Иду по коду сверху вниз — не могу найти это место. Ищу непосредственно обращение к rabbit, начинаю подниматься вверх, дохожу до места в business flow, где подписка собственно происходит — начинаю ругаться. Как это выглядит в коде:
- Вызывается метод service.getQueueListener(tickerName) — возвращаемый результат игнорируется. Это могло бы насторожить, но такой фрагмент кода, где игнорируются результаты работы метода, в приложении не единственный.
- Внутри tickerName проверяется на null и вызывается другой метод getQueueListenerByName(tickerName).
- Внутри него из хэша по имени тикера берется экземпляр класса QueueListener (если его нет, он создается), и у него вызывается метод getSubscription().
- А вот уже внутри метода getSubscription() собственно и происходит подписка. Причем происходит она где-то в самой середине метода размером в три экрана.
Скажу прямо — не пробежав всей цепочки и не прочтя внимательного десяток экранов кода, догадаться, где же происходит подписка, было нереально. Если бы метод назывался subscribeToQueueByTicker(tickerName), это сэкономило бы мне немало времени.
Утилитарные классы
Есть прекрасная книга Design Patterns: Elements of Reusable Object-Oriented Software (1994), ее часто называют GOF (Gang of Four, по количеству авторов). Польза этой книги прежде всего в том, что она дала разработчикам из разных стран единый язык для описания шаблонов дизайна классов. Теперь вместо «класс гарантированно существующий только в одном экземпляре и имеющий статическую точку доступа» можно сказать «синглтон». Эта же книга нанесла заметный урон неокрепшим умам. Вред этот хорошо описывает цитата с одного из форумов «Коллеги, мне надо сделать веб-магазин, скажите, с использования каких шаблонов мне надо начать». Иначе говоря, некоторые программисты склонны злоупотреблять шаблонами проектирования, и там, где можно было обойтись одним классом, иногда создают сразу пять или шесть — на всякий случай, «для большей гибкости».
Как решить, нужна вам абстрактная фабрика классов (или другой паттерн сложнее интерфейса) или нет? Есть несколько простых соображений:
- Если вы пишете прикладное приложение на Spring, в 99 % случаев не нужна. Spring предлагает вам более высокоуровневые строительные блоки, используйте их. Максимум, что вам может пригодится, это абстрактный класс.
- Если пункт 1 все же не дал вам четкого ответа — помните, что каждый шаблон — это +1000 очков к сложности приложения. Тщательно проанализируйте, перевесит ли польза от использования шаблона вред от него же. Обращаясь к метафоре, помните, каждое лекарство не только лечит, но и немножечко вредит. Не надо пить все таблетки сразу.
Хороший пример того, как делать не надо, можете посмотреть здесь.
Заключение
Подводя итог, хочу заметить, что перечислил самые базовые рекомендации. Я бы вообще не стал оформлять их в виде статьи — настолько они очевидны. Но за прошедший год мне слишком часто попадались приложения, в которых многие из этих рекомендаций нарушались. Давайте писать простой код, который легко читать и легко поддерживать.

