

В этой статье представлены три небольшие истории, которые произошли в нашей практике: в разное время и в разных проектах. Объединяет их то, что они связаны с сетевой подсистемой Linux (Reverse Path Filter, TIME_WAIT, multicast) и иллюстрируют, как глубоко зачастую приходится анализировать инцидент, с которым сталкиваешься впервые, чтобы решить возникшую проблему… и, конечно, какую радость можно испытать в результате полученного решения.
История первая: о Reverse Path Filter
Клиент с большой корпоративной сетью решил пропускать часть своего интернет-трафика через единый корпоративный файрвол, расположенный за маршрутизатором центрального подразделения. С помощью iproute2 трафик, уходящий в интернет, был направлен в центральное подразделение, где уже было настроено несколько таблиц маршрутизации. Добавив дополнительную таблицу маршрутизации и настроив в ней маршруты перенаправления на файрвол, мы включили перенаправление трафика из других филиалов и… трафик не пошел.
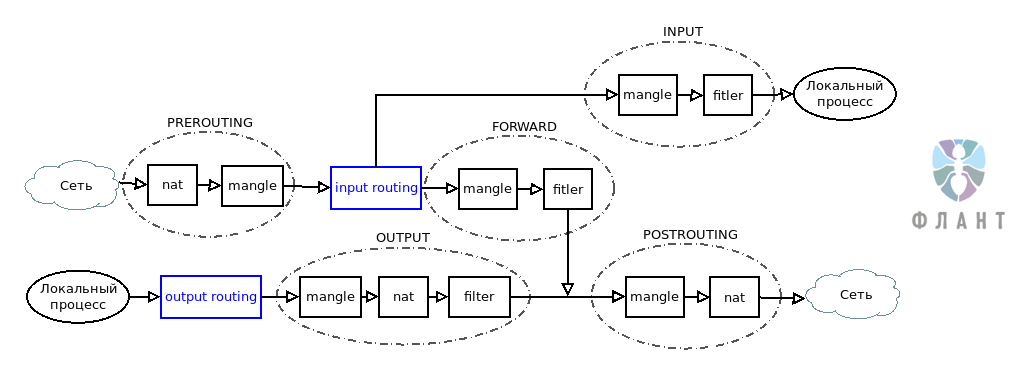
Схема прохождения трафика через таблицы и цепочки Netfilter
Начали выяснять, почему не работает настроенная маршрутизация. На входящем туннельном интерфейсе маршрутизатора трафик обнаруживался:
$ sudo tcpdump -ni tap0 -p icmp and host 192.168.7.3
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes
22:41:27.088531 IP 192.168.7.3 > 8.8.8.8: ICMP echo request, id 46899, seq 40, length 64
22:41:28.088853 IP 192.168.7.3 > 8.8.8.8: ICMP echo request, id 46899, seq 41, length 64
22:41:29.091044 IP 192.168.7.3 > 8.8.8.8: ICMP echo request, id 46899, seq 42, length 64Однако на исходящем интерфейсе пакетов не было. Стало ясно, что фильтруются они на маршрутизаторе, однако явно установленных правил отбрасывания пакетов в iptables не было. Поэтому мы начали последовательно, по мере прохождения трафика, устанавливать правила, отбрасывающие наши пакеты и после установки смотреть счетчики:
$ sudo iptables -A PREROUTING -t nat -s 192.168.7.3 -d 8.8.8.8 -j DROP
$ sudo sudo iptables -vL -t nat | grep 192.168.7.3
45 2744 DROP all -- any any 192.168.7.3 8.8.8.8 Проверили последовательно nat PREROUTING, mangle PREROUTING. В mangle FORWARD счетчик не увеличивался, а значит — пакеты теряются на этапе маршрутизации. Проверив снова маршруты и правила, начали изучать, что именно происходит на этом этапе.
В ядре Linux для каждого интерфейса по умолчанию включен параметр Reverse Path Filtering (
rp_filter). В случае, когда вы используете сложную, асимметричную маршрутизацию и пакет с ответом будет возвращаться в источник не тем маршрутом, которым пришел пакет-запрос, Linux будет отфильтровывать такой трафик. Для решения этой задачи необходимо отключить Reverse Path Filtering для всех ваших сетевых устройств, принимающих участие в маршрутизации. Чуть ниже простой и быстрый способ сделать это для всех имеющихся у вас сетевых устройств:#!/bin/bash
for DEV in /proc/sys/net/ipv4/conf/*/rp_filter
do
echo 0 > $DEV
doneВозвращаясь к кейсу, мы решили проблему, отключив Reverse Path Filter для интерфейса tap0 и теперь хорошим тоном на маршрутизаторах считаем отключение
rp_filter для всех устройств, принимающих участие в асимметричном роутинге.История вторая: о TIME_WAIT
В обслуживаемом нами высоконагруженном веб-проекте возникла необычная проблема: от 1 до 3 процентов пользователей не могли получить доступ к сайту. При изучении проблемы мы выяснили, что недоступность никак не коррелировала с загрузкой любых системных ресурсов (диск, память, сеть и т.д.), не зависела от местоположения пользователя или его оператора связи. Единственное, что объединяло всех пользователей, которые испытывали проблемы, — они выходили в интернет через NAT.
Состояние
TIME_WAIT в протоколе TCP позволяет системе убедиться в том, что в данном TCP-соединении действительно прекращена передача данных и никакие данные не были потеряны. Но возможное количество одновременно открытых сокетов — величина конечная, а значит — это ресурс, который тратится в том числе и на состояние TIME_WAIT, в котором не выполняется обслуживание клиента. 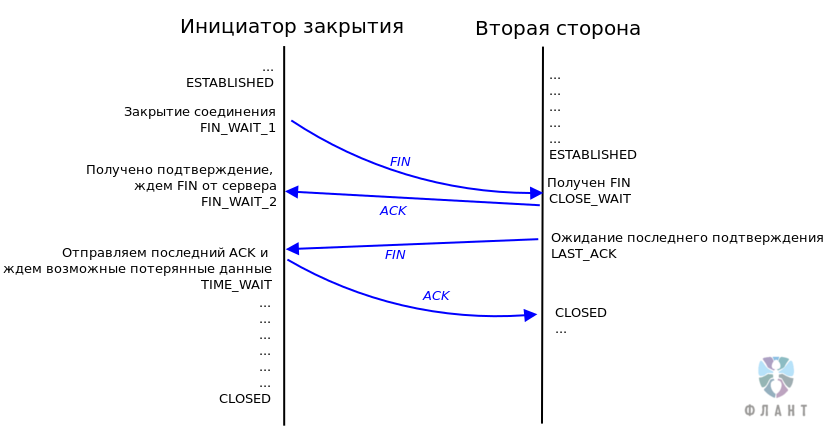
Механизм закрытия TCP-соединения
Разгадка, как и ожидалось, нашлась в документации ядра. Естественное желание администратора highload-системы — уменьшить «холостое» потребление ресурсов. Беглое гугление покажет нам множество советов, которые призывают включить опции ядра Linux
tcp_tw_reuse и tcp_tw_recycle. Но с tcp_tw_recycle не всё так просто, как могло показаться.Разберемся с этими параметрами подробнее:
- Параметр
tcp_tw_reuseполезно включить в борьбе за ресурсы, занимаемыеTIME_WAIT. TCP-соединение идентифицируется по набору параметровIP1_Port1_IP2_Port2. Когда сокет переходит в состояниеTIME_WAIT, при отключенномtcp_tw_reuseустановка нового исходящего соединения будет происходить с выбором нового локальногоIP1_Port1. Старые значения могут быть использованы только тогда, когда TCP-соединение окажется в состоянииCLOSED. Если ваш сервер создает множество исходящих соединений, установитеtcp_tw_reuse = 1и ваша система сможет использовать портыTIME_WAITв случае исчерпания свободных. Для установки впишите в/etc/sysctl.conf:
net.ipv4.tcp_tw_reuse = 1
И выполните команду:
sudo sysctl -p - Параметр
tcp_tw_recycleпризван сократить время нахождения сокета в состоянииTIME_WAIT. По умолчанию это время равно 2*MSL (Maximum Segment Lifetime), а MSL, согласно RFC 793, рекомендуется устанавливать в 2 минуты. Включивtcp_tw_recycle, вы говорите ядру Linux, чтобы оно использовало в качестве MSL не константу, а рассчитало его на основе особенностей именно вашей сети. Как правило (если у вас не dial-up), включениеtcp_tw_recycleзначительно сокращает время нахождения соединения в состоянииTIME_WAIT. Но здесь есть подводный камень: перейдя в состояниеTIME_WAIT, ваш сетевой стек при включенномtcp_tw_recycleбудет отвергать все пакеты с IP второй стороны, участвовавшей в соединении. Это может вызывать ряд проблем с доступностью при работе из-за NAT, с чем мы и столкнулись в приведенном выше кейсе. Проблема крайне сложно диагностируется и не имеет простой процедуры воспроизведения/повторяемости, поэтому мы рекомендуем проявлять крайнюю осторожность при использованииtcp_tw_recycle. Если же вы решили ее включить, внесите в/etc/sysctl.confодну строку и (не забудьте выполнитьsysctl -p):
net.ipv4.tcp_tw_recycle = 1
История третья: об OSPF и мультикастовом трафике
Обслуживаемая корпоративная сеть была построена на базе tinc VPN и прилегающими к ней лучами IPSec и OVPN-соединений. Для маршрутизации всего этого адресного пространства L3 мы использовали OSPF. На одном из узлов, куда агрегировалось большое количество каналов, мы обнаружили, что небольшая часть сетей, несмотря на верную конфигурацию OSPF, периодически пропадает из таблицы маршрутов на этом узле.

Упрощенное устройство VPN-сети, используемой в описываемом проекте
В первую очередь проверили связь с маршрутизаторами проблемных сетей. Связь была стабильной:
Router 40 $ sudo ping 172.24.0.1 -c 1000 -f
PING 172.24.0.1 (172.24.0.1) 56(84) bytes of data.
--- 172.24.0.1 ping statistics ---
1000 packets transmitted, 1000 received, 0% packet loss, time 3755ms
rtt min/avg/max/mdev = 2.443/3.723/15.396/1.470 ms, pipe 2, ipg/ewma 3.758/3.488 msПродиагностировав OSPF, мы удивились еще больше. На узле, где наблюдались проблемы, маршрутизаторы проблемных сетей отсутствовали в списке соседей. На другой стороне проблемный маршрутизатор в списке соседей присутствовал:
Router 40 # vtysh -c 'show ip ospf neighbor' | grep 172.24.0.1Router 1 # vtysh -c 'show ip ospf neighbor' | grep 172.24.0.40
255.0.77.148 10 Init 14.285s 172.24.0.40 tap0:172.24.0.1 0 0 0Следующим этапом исключили возможные проблемы с доставкой ospf hello от 172.24.0.1. Запросы от него приходили, а вот ответы — не уходили:
Router 40 $ sudo tcpdump -ni tap0 proto ospf
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes
09:34:28.004159 IP 172.24.0.1 > 224.0.0.5: OSPFv2, Hello, length 132
09:34:48.446522 IP 172.24.0.1 > 224.0.0.5: OSPFv2, Hello, length 132Никаких ограничений в iptables не было установлено — выяснили, что пакет отбрасывается уже после прохождения всех таблиц в Netfilter. Снова углубились в чтение документации, где и был обнаружен параметр ядра
igmp_max_memberships, который ограничивает количество multicast-соединений для одного сокета. По умолчанию это количество равно 20. Мы, для круглого числа, увеличили его до 42 — работа OSPF нормализовалась:Router 40 # echo 'net.ipv4.igmp_max_memberships=42' >> /etc/sysctl.conf
Router 40 # sysctl -p
Router 40 # vtysh -c 'show ip ospf neighbor' | grep 172.24.0.1
255.0.77.1 0 Full/DROther 1.719s 172.24.0.1 tap0:172.24.0.40 0 0 0Заключение
Какой бы сложной ни была проблема, она всегда решаема и зачастую — с помощью изучения документации. Буду рад увидеть в комментариях описание вашего опыта поиска решения сложных и необычных проблем.
P.S.
Читайте также в нашем блоге:
