Статья про данные для ML и FeatureStore

Это материал из цикла статей о ModelOps от команды Advanced Analytics GlowByte. В предыдущих статьях мы уже рассказывали про:
Как контейнеризировать среды ML разработки и не посадить на мель процессы MLOps
Как и зачем управлять ML-моделями?
Валидация моделей машинного обучения
Сегодня поговорим о не менее важном процессе, чем создание ML-моделей, - о подготовке и управлении данными для моделирования.
Что обсудим:
Как выглядит стандартный процесс подготовки данных для ML
Что с ним не так
Feature Store - что это и из чего состоит
Как Feature Store решает проблемы стандартного подхода
Какие решения есть на рынке
В последние несколько лет активно развиваются и набирают популярность “магазины фичей” - Feature Store. Что это и как помогает улучшить процесс управления данными расскажем далее в этой статье.
Но для начала нужно разобраться почему обычный процесс подготовки данных уже не работает.
Как выглядит стандартный процесс подготовки данных
Кто участники?
Data Scientist (DS). Занимается созданием ML-модели и интерпретацией результатов её работы. DS продумывает какие данные могут быть полезны в его расчетах, формирует список фичей - переменных, передающихся на вход ML-модели.
Data Engineer (DE). Разбирается в структуре источников данных. Получает от DS список необходимых фичей, продумывают как оптимальнее собрать их над данными из источников.
Стоит оговориться, что такое четкое разделение не всегда присутствует. Часто DS сам выполняет роль DE.
Что происходит?
DS составляет требования к датасету - набору целевых фичей для модели - после чего или передает их DE, или готовит алгоритм сбора данных самостоятельно.
Собираться датасет может как из уже готовых фичей, так и из новых, которые рассчитываются специально под проектируемую ML-модель.
Весь процесс обучения и подготовки модели к промышленному использованию итеративный, каждая итерация называется экспериментом.

Как реализовано?
Типичная архитектура выглядит следующим образом: на основе данных источников создаются широкие витрины целевых фичей. Эти фичи в разном составе используются в ML-моделях, или могут дополняться фичами из “песочницы” для проведения экспериментов.

Технически это реализовывается в виде широких таблиц в БД, а сбоку могут прикручиваться различные полезные штуки вроде библиотеки Python - Pandas. Данные она не хранит, зато может быстро обработать большой объем; а на сдачу ещё и красивые графики нарисует. Другой хороший инструмент - DVC. Это система контроля версий моделей и датасетов, полезна при большом количестве экспериментов.
Что не так со стандартным процессом
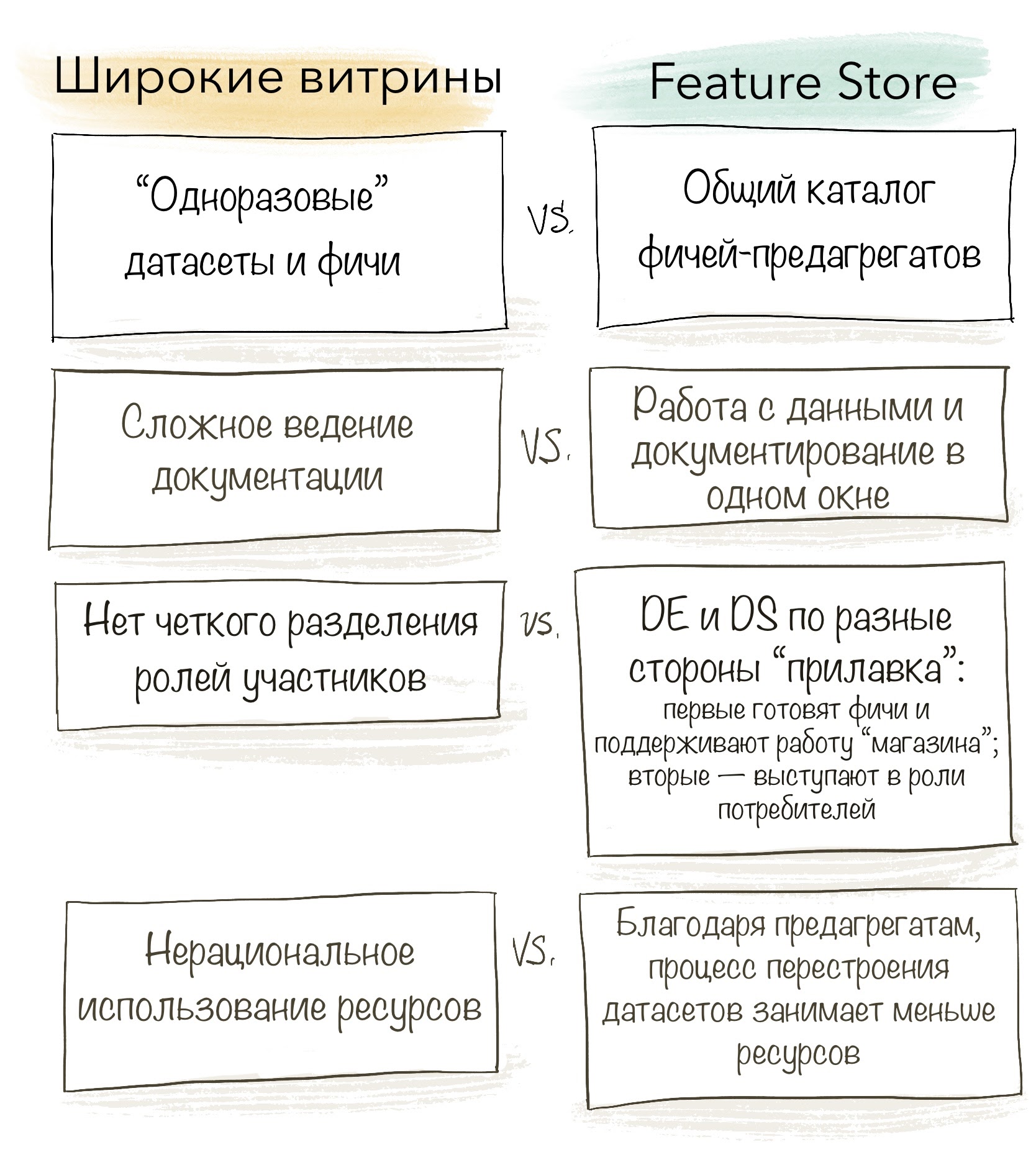
Для маленьких команд с небольшим количеством моделей описанный подход вполне рабочий. Но при увеличении количества сотрудников, экспериментов и моделей - всё болезненней ощущаются недостатки подхода с широкими витринами. Какие основные недостатки можно выделить:
“Одноразовые” датасеты
Датасеты подготавливаются для конкретного эксперимента, который может оказаться неудачным и весь процесс придется начинать с начала.
Фичи рассчитаны и хранятся в целевом виде: за определенные временные промежутки, использованы конкретные агрегирующие функции и фильтры. Практически нет возможностей сделать с ними что-то ещё, можно использовать только как есть. Это сокращает возможности переиспользования уже посчитанных фичей.
Появление новых требований так же обычно ведет к пересчету всего датасета.
Нельзя переиспользовать фичи
Переиспользование уже посчитанных данных - это хорошо. Это экономит и технические ресурсы, и время специалистов. Но без должного подхода к документированию появляется много вопросов без ответов: когда и кем собирались эти фичи? По какому алгоритму? Ведь нельзя обучить модель на чьих-то посчитанных данных, а для применения попытаться собрать что-то похожее самостоятельно. Нельзя, при условии, что мы хотим получить качественную модель.
Хаос в документации
Проблема вытекает из предыдущего пункта. Стандартный подход не предлагает отдельных инструментов для ведения документации (разве что в DVC об этом позаботились) и держится только на договоренностях и сознательности участников процесса.
Отсутствие четкого разделения ролей участников
DS тратят время на подготовку данных, вместо разработки новых моделей. DE решают частные запросы DS, вместо построения и отлаживания потоков данных.
Нерациональное использование ресурсов
Процесс повторного построения данных для фичей требует много технических ресурсов - пересчет широких витрин может быть довольно продолжительным по времени и занимать большой объем памяти. Особенно неприятно, если это разовая экспериментальная загрузка.
А главное, датасеты подготавливаются для конкретного эксперимента, который может оказаться неудачным и весь процесс придется начинать сначала.

Feature Store входит в чат
Feature Store (FS) - это API, который позволяет абстрагировать инжиниринг данных от рабочего ML-процесса. Хранение и преобразование фичей, подготовка датасетов и документирование реализовано в “одном окне”.
Можно выделить 5 основных принципов Feature Store, которые закрывают слабые места стандартного подхода с широкими витринами. Также решаются дополнительные вопросы, как то мониторинг качества данных или переносимость датасетов между системами обучения и применения.
Похожие принципы Tecton описали в своей недавней статье “What is a Feature Store?”. Глобально мы согласны с их видением необходимых элементов FS, но можем расходится в нюансах.
Каталогизация
Архитектурно Feature Store отходит от стандартного хранения фичей в разных таблицах, по крайней мере на логическом уровне. Пользователю (DS) доступны для просмотра все* имеющиеся фичи “в одном окне”. Это дает возможность легко находить нужные переменные, и снижает вероятность создания одних и тех же переменных.
Дополнительно в каталогах можно хранить и информацию обо всем связанном с подготовкой данных для ML: например как часто рассчитываются фичи или какие есть датасеты и из каких переменных они состоят.
*Нужным дополнением к каталогам может быть система ролевого доступа - разграничение прав пользователей на просмотр фичей на уровне каталогов, и на уровне самих данных.

Конструктор фичей
Частая ситуация, когда при построении витрины для моделирования на вход берутся сотни уникальных по смыслу переменных и преобразовываются в тысячи целевых фичей. В ход идут фильтрации по различным категориям, агрегации разными функциями за разные временные периоды. Поверх всего этого могут использоваться скалярные выражения с несколькими фичами.
Полезно иметь инструмент, который позволяет достаточно легко настроить нужные параметры фичи для получения множества её вариаций. Плюс к этому, можно не писать вручную тысячи строк однообразного кода - Feature Store сгенерирует его самостоятельно.
Для использования подобного функционала необходимо реализовывать хранение данных в FS в виде таблиц-предагрегатов. Фичи в данном случае:
По возможности хранятся в максимально атомарном виде. Например “доли” хранятся в виде числителя и знаменателя в разных атрибутах, так мы можем и отношение рассчитать, и использовать сами числитель и знаменатель как отдельные фичи.
Сгруппированы с некоторой минимально-необходимой гранулярностью: данные агрегируются за день/неделю/месяц. Гранулярность подбирается исходя из технических возможностей (чем мельче “гранулы”, тем больше памяти потребуется для хранения) и из потребностей моделирования (для ежемесячных моделей может хватить месячных предагрегатов).

Управление хранением данных
Ключевой момент именно в том, что мы не просто храним данные, а имеем возможность достаточно гибко управлять этим процессом.
Важная фишка FS - версионирование на уровне индивидуальных фичей, а не только датасетов. Благодаря этому, при изменении алгоритма расчета фичи, не приходится переобучать сразу все связанные модели, можно делать это постепенно, храня обе версии расчета фичи.
Другая особенность - хранение и накапливание истории по фичам. Это позволяет:
быстрее собирать данные для обучения моделей (когда нужно за раз дать на вход много датасетов за разные периоды);
восстановить датасет, который ранее использовался для применения модели (например актуально для онлайн-моделей, которые используют стриминговые источники данных)

Поставка фичей (Serving)
Важный момент при подготовке данных для ML-моделирования: данные на которых обучалась модель должны соответствовать тому, что будет передаваться ей на вход во время применения. Структура данных, алгоритмы расчета должны совпадать. Особенно это становится критичным, когда обучение и применение проходят в разных системах (пример: онлайн модели, которые обучаются на данных из Хранилищ, но применяются на стриминговых источниках).
Feature Store помогает абстрагировать расчет переменных от источников. Этого можно достигнуть за счет хранения алгоритмов преобразования переменных и сбора датасетов. Делая их переносимыми (например в нотации json), есть возможность разворачивать расчет датасетов непосредственно в отдельно стоящих системах применения.

Мониторинг качества
За счет того, что Feature Store хранит все фичи, датасеты и сами данные централизованно - есть возможность собирать большое количество различных метаданных. Анализируя данные и метаданные можно собирать различные полезные статистики начиная от мониторинга перекоса входных данных для модели - data drift - “не пора ли переобучить модель?”, заканчивая анализом “популярности” конкретных переменных или их сочетаний - “с этой фичей чаще всего заказывают…”.

С учетом вышеописанных возможностей Feature Store, можно нарисовать следующую архитектуру:

Бизнес процесс при использовании FS:

Как Feature Store решает проблемы стандартного подхода
Подведем итог как ложатся описанные нами принципы Feature Store на недостатки подхода с широкими витринами.
Нужно отметить, что Feature Store всё-таки не волшебная таблетка и важным этапом оптимизации подготовки данных является отладка самого процесса. На что важно обратить внимание, чтобы применение Feature Store “выстрелило” (и желательно не в ногу):
Роли DE и DS разделены: DE - отвечает за наполнение FS данными в правильной структуре; DS - формулируют запрос на необходимые фичи, не погружаясь в логику хранения данных на уровне FS и его источников.
Фичи регистрируются в FS в максимально атомарном виде; агрегация, отбор данных за разные временные окна или расчет по формулам вычисляется на уровне сбора датасета на стороне Feature Store.
Отсутствуют повторяющиеся фичи: при появлении новых требований, DE сначала проверят есть ли нужные переменные в FS, а уже потом, при необходимости, добавляет новые.
Обучение и применение должно происходить на одних и тех же структурах данных.
Требуется контроль качества данных, который решает несколько задач:
Проверка консистентности данных перед использованием датасетов в моделях;
Сбор и сравнение метрик над данными для обучения и данными для применения, что позволит своевременно переобучать модели.
Что есть на рынке?
С ростом популярности машинного обучения и моделирования, острее стала ощущаться потребность в оптимизации процесса подготовки данных.
Некоторые компании принимают решение о разработке собственного FS (или чего-то похожего) в силу различных причин:
рыночные решения дороги или не устраивают по функционалу;
достаточно собственной экспертизы и ресурсов для проектирования решения специально под свои нужды;
нет необходимости реализовывать FS во всей красе, есть потребность только в каком-то одном модуле (например нужен только конструктор фичей).
И тем не менее, на рынке “магазины фичей” стали появляться в последние несколько лет как грибы после дождя. Решения, за которыми мы в команде GlowByte Advanced Analytics активно следим:
dotData (правда в какой-то момент они переобулись в термин AutoFE - Automated Feature Engineering)
Сравнительный анализ этих продуктов - пожалуй тема для отдельного разговора и статьи. Но если обобщить - на наш взгляд пока на рынке не появилось то решение, в котором были бы реализованы все описанные выше принципы в полном объеме. Кто-то не реализовывает переносимость алгоримов сбора датасетов. Кто-то делает очень урезанные по функционалу конструкторы, которые в общем-то умеют только в join’ы таблиц с фичами. Всегда приходится чем-то жертвовать при выборе существующих FS-решений.
Но поскольку направление ещё долго не потеряет своей актуальности, то и продуктовые реализации будут развиваться и лучше подстраиваться под нужды пользователей. Аминь.
Заключение
Управление данными - важный элемент MLOps, который не стоит оставлять без внимания, особенно при большом и постоянно растущем парке моделей. При грамотном использовании, Feature Store позволят значительно сократить количество рутинных задач и TTM моделей. И несмотря на то, что пока на рынке нет “того самого”, эталонного, "магазина фичей", реализаций достаточно много и есть возможность подобрать что-то достаточно подходящее под свои нужды.
Про Feature Store, MLOps и другие вопросы вокруг применения ML и продвинутой аналитики в реальных бизнес-задачах мы регулярно общаемся в нашем сообществе NoML:
В ближайший четверг 7 октября, проведем дискуссию на безе данной статьи в формате голосового чата. Присоединяйтесь.
