В прошлой статье было рассказано об основных принципах мироксервисной архитектуры. Теперь настал момент поговорить о переходе на неё из монолитных систем. И первым звеном в преобразовании, как правило, выступают системные аналитики.
Основная роль системных аналитиков при проектировании микросервисной архитектуры — способствование четкому, компактному и формализованному определению зоны ответственности микросервиса вокруг существующей или выявленной бизнес-потребности.

В современных корпорациях существуют десятки, иногда сотни микросервисов и их интеграций, разные технологии и архитектурные подходы. Процессы, которые действуют по-разному и имеют разные цели, но пересекаются с друг другом. В такой ситуации командам очень сложно разобраться, что, куда и зачем передается, как проходит процесс полностью, что на него может повлиять, на что он сам может повлиять. Как правило эти вопросы сваливаются на плечи системных аналитиков, именно эти герои помогают:
приводить хаос в порядок;
выявлять требования;
проектировать интеграцию;
понимать ключевые и потенциально опасные части процессов;
контролировать знания команды о системе;
доносить до бизнеса возможности и ограничения продукта.
Почему выгодны микросервисы для системных аналитиков
Во-первых, это интересно. Это как большой конструктор, из которого можно собирать разные процессы. Если нравятся интеграции и копаться в технических аспектах — то вы по адресу.
Во-вторых, простота добавления новых продуктов и функций. Для этого пишут новые микросервисы и не нужно беспокоиться о том, что новый код как-то сломает работающие процессы. При этом отследить зависимости и влияние проще, чем в монолите.
В-третьих, простота процесса, скорее всего быстро сможете определить, в каком микросервисе у вас сбоит при ошибке. И так как микросервисы относительно простые — то исправить тоже будет несложно. И при обновлении можно выкатить только свой микросервис, не беспокоя соседей.
В-четверых, будете работать с профессионалами, так как все члены команды должны обладать определенным опытом и навыками для нормальной реализации этого подхода.
Правда стоит отметить что все эти преимущества и преимущество MSA в целом смогут раскрыться только в случае проведения огромнейшей, даже сказал титанической работы, которая и позволяет эффективно управлять в современных реалиях огромными каскадами микросервисов состоящих иногда из сотен микросервисов.
Основные вызовы в работе системного аналитика
Как правило перед системными аналитиками при переходе на микросервисную архитектуру часто возникает еще целый ряд блоков-вызовов для проведения анализа и обоснования того или иного пути, от которого будет зависеть эффективность системы.

Остановимся на каждом из них более подробно.
Дробление монолита
Дробление монолита на микросервисы или рефакторинг не всегда целесообразен и, как правило, вызывает целых ворох проблем. При переводе Legacy-приложений на микросервисы рефакторинг некоторых подсистем вообще может оказаться очень долгим, либо вовсе невозможным. Но взаимодействовать с устаревшими подсистемами все равно нужно, несмотря на то, что в них, возможно, используются не самые современные технологии в части построения API, схем данных и так далее. И это как правило это та еще проблема. Как минимум трансформация SOAP и REST взаимодействия.

Для таких случаев можно использовать подход Anti-Corruption Layer. Он предназначен для изолирования различных подсистем путем размещения между ними дополнительного уровня, который может быть реализован как компонент приложения или независимая служба. Этот уровень связывает две подсистемы, позволяя им оставаться максимально независимыми друг от друга. Он содержит всю логику, необходимую для передачи данных в обе стороны: при взаимодействии с каждой из подсистем используется именно ее модель данных. Таким способом можно как бы по немного отщипывать от большого монолита функциональность и переводить ее на микросервисы, при этом сохраняя взаимодействие с монолитом.
Создание системы управления данными
Основная рекомендация при переходе на микросервисы — предоставить каждому сервису собственное хранилище данных, чтобы не было сильных зависимостей на уровне данных. Иначе это ведет к целой череде проблем и делает микросервис зависимым, что, по сути, противоречит самому принципу построения микросервисов.
При этом имеется в виду именно логическое разделение данных, то есть микросервисы могут совместно использовать одну и ту же физическую базу данных, но в ней они должны взаимодействовать с отдельной схемой, коллекцией или таблицей.
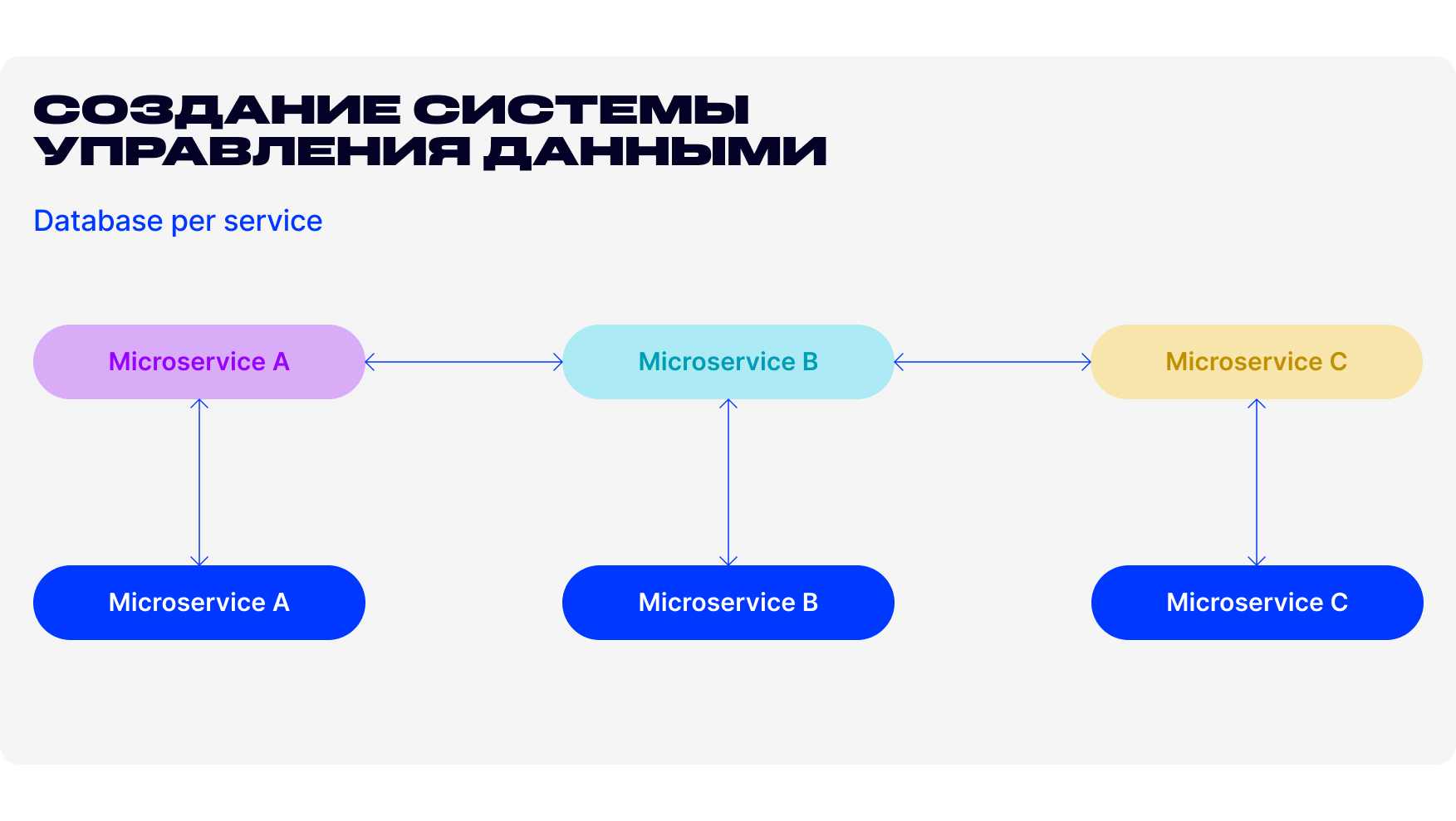
Основанный на этих принципах подход Database Per Service повышает автономность микросервисов и уменьшает связь между командами, разрабатывающими отдельные сервисы.
У подхода есть и недостатки: усложняется обмен данными между сервисами и предоставление транзакционных гарантий ACID (Atomicity — Атомарность, Consistency — Согласованность, Isolation — Изолированность, Durability — Прочность). Подход не стоит применять в небольших приложениях — он предназначен для крупномасштабных проектов с большим числом микросервисов, где каждой команде требуется полное владение ресурсами для повышения скорости разработки и лучшего масштабирования и независимого деплоя.
В крупных проектах, когда речь идет об управлении данными огромного каскада микросервисов, для управления распределенными транзакциями используется подход Сага, который обычно применяется к финансовым службам. Он обеспечивает согласованность данных финансовых транзакций клиентам, что в финансовой сфере критично и системным аналитикам необходимо учитывать этот момент.
Кстати, для банковского сектора традиционный подход к свойствам атомарности, согласованности, изоляции и устойчивости (ACID) больше не подходит. Это обусловлено тем, что данные операций размещаются в изолированных базах данных. Использование подхода Saga решает эту проблему путем координирования рабочего процесса посредством управляемой сообщениями последовательности локальных транзакций для обеспечения согласованности данных.

При использовании этого подхода каждая локальная транзакция обновляет данные в хранилище в рамках одного микросервиса и публикует событие или сообщение, которые, в свою очередь, запускают следующую локальную транзакцию и так далее. Если локальная транзакция завершается с ошибкой, выполняется серия компенсирующих транзакций, отменяющая изменения предыдущих транзакций.
Для координации транзакций существует два основных способа:
Хореография. Децентрализованная координация, при которой каждый микросервис прослушивает события/сообщения другого микросервиса и решает, следует предпринять действие или нет.
Оркестровка. Централизованная координация, при которой отдельный компонент (оркестратор) сообщает микросервисам, какое действие необходимо выполнить далее.
Использование данного подхода решает проблему согласованности транзакций в слабосвязанных распределенных системах, однако увеличивает сложность отладки. Saga отлично подходит для систем, управляемых событиями и/или использующих базы данных NoSQL, но не рекомендуется при использовании баз данных SQL и в системах с циклическими зависимостями между сервисами.
Обеспечение процесса централизации коммуникации
Немаловажно затронуть и вызов направленный на обеспечение процесса централизации коммуникации между каскадом микросервисов, с которым неизбежно придется столкнуться в работе.
Почему это важно так важно? Все просто: MSA — это тот еще Вавилон, где интегрируются все со всеми любыми мыслимыми способами.
Помимо своей базы данных у каждого микросервиса еще и свой API, любого протокола и вероисповедания. Нет каких-то правил или ограничений для формата интеграций между микросервисами. В рамках одной системы используют разные протоколы и подходы, синхронное и асинхронное. И вот чтобы это все связать в единое целое и появились проверенные страданиями лучшие подходы.
Наиболее очевидный способ обращения к микросервисам — прямое обращение от клиента к сервису. И его вполне можно применять в небольших проектах. Однако в приложениях корпоративного масштаба с большим числом микросервисов рекомендуется использовать подход API Gateway.

Этот подход основан на применении шлюза, который находится между клиентским приложением и микросервисами, обеспечивая единую точку входа для клиента.
В зависимости от конкретной цели использования подхода иногда выделяют следующие его разновидности:
Gateway Routing. Шлюз используется как обратный Proxy, перенаправляющий запросы клиента на соответствующий сервис.
Gateway Aggregation. Шлюз используется для разветвления клиентского запроса на несколько микросервисов и возвращения агрегированных ответов клиенту.
Gateway Offloading. Шлюз решает сквозные задачи, которые являются общими для сервисов: аутентификация, авторизация, SSL, ведение журналов и так далее.
Применение данного подхода:
во-первых, сокращает число вызовов;
во-вторых, обеспечивает независимость клиента от протоколов, используемых в сервисах: REST обеспечивает централизованное управление сквозной функциональностью.
Однако шлюз может стать единой точкой отказа, требует тщательного мониторинга и при отсутствии масштабирования бывает узким местом системы.
В крупных корпорациях присутствуют и внешние партнеры, чтобы обеспечить их эффективную коммуникацию используется подход подход Double API Gateway или Mirror API Gateway. В противном случае без единой и простой точки входа партнеры бы просто утонули в разнообразии сервисов, различных способов авторизаций, сертификатами доступа и интеграций с ними, а задача наоборот упростить им доступ. Такая простота в разы ускоряет наращивание партнеров.

С помощью подхода можно добавить API, адаптированные к потребностям каждого партнера, избавившись от хранения большого количества ненужных настроек в одном месте, а также упростить возможности связанные с обеспечением должного уровня защиты и предотвращения атак извне.
Развертывание
Немаловажно уделить внимание и процессу развертывания микросервисов. При этом как правило существует серьезная проблема выкатывания новых версий незаметно для пользователей и минимизация времени простоя.
Подход Blue-Green Deployment как раз позволяет выполнить развертывание новых версий сервисов максимально незаметно для пользователей, сократив время простоя до минимума. Это достигается за счет запуска двух идентичных производственных сред — условно синего и зеленого цвета. Предположим, что синий — это существующий активный экземпляр, а зеленый — это новая версия приложения, развернутая параллельно с ним.

В любой момент времени только одна из сред является активной, и именно она обслуживает весь производственный трафик. После успешного развертывания новой версии — с прохождением всех тестов и так далее — трафик переключается на нее. В случае ошибок всегда можно вернуться к предыдущей версии.
С использованием данного подхода пользователь почти не испытывает дискомфорта, связанного с апдейтом системы, а системные аналитики могут спокойно без седьмого пекла выкатывать новые релизы.
Тестирование микросервисов
Отдельным особняком выступает вопрос тестирования микросерисов. Проблематика состоит в том, что юнит-тестов нужно много, они должны иметь техническую, а не бизнес направленность. Для каждого сервиса нужно писать тесты его поведения, их нужно меньше, они должны быть ориентированными на бизнес-требования. E2e тесты очень важны, но они сложные и дорогие. Как же можно выкрутиться из такой непростой ситуации?
В этом может помочь подход «Тестирование контрактов, ориентированных на потребителя», который рекомендуются использовать в крупномасштабных проектах, где несколько команд работают над различными сервисами. Суть подхода в том, что набор автоматизированных тестов для каждого сервиса (Provider Microservice) пишется разработчиками других сервисов (Consumer Microservice), вызывающих проверяемый сервис. Каждый такой набор тестов является контрактом, проверяющим, соответствует ли сервис провайдера ожиданиям потребителя. Сами тесты включают в себя запрос и ожидаемый ответ.

Подход Consumer-Driven Contract Testing увеличивает автономность команд и позволяет своевременно обнаруживать изменения в сервисах, написанных другими командами. Но его применение может потребовать дополнительной работы по интеграции тестов, так как команды могут пользоваться различными инструментами тестирования.
Мониторинг
Эффективной мониторинг каскада микросервисов является одним из острых камней и от его качества как ранее затрагивалось зависит очень многое.
Хорошей практикой при разработке микросервисов считается ведение логов каждым экземпляром сервиса. Логи могут содержать ошибки, предупреждения, информационные и отладочные сообщения. Но с увеличением числа сервисов анализ логов, разнесенных по различным хостам, становится затруднительным. В обилии разрозненных логов очень сложно разобраться, иногда невозможно.

Подход Log Aggregation предлагает использовать централизованную службу ведения логов, которая будет собирать логи от каждого экземпляра сервиса. Это предоставит пользователям единую точку для поиска, анализа логов и настройки предупреждений, которые будут запускаться при появлении в них определенных сообщений, что существенно упрощает работу с мониторингом.
В целом, микросервисам в рамках одной платформы или корпорации часто требуются общие функции, относящиеся к мониторингу, ведению журналов, настройкам безопасности, сетевым службам и так далее. Однако это осложняется тем, что в MSA отдельные сервисы могут быть построены с помощью различных языков и технологий — следовательно, они могут иметь свои зависимости и требовать определенных языковых библиотек, что может вызвать ряд сложностей при обеспечении таких интеграций.
Подход Ambassador предлагает помещать клиентские фреймворки и библиотеки для решения периферийных задач внутрь вспомогательного сервиса, выступающего в роли Proxy между клиентским приложением или основным сервисом и прочими частями системы.

Применение подхода Ambassador позволяет:
Унифицировать обращение клиентских приложений к общим задачам независимо от используемого языка и фреймворка. Обеспечивая простоту интеграций.
Решать периферийные задачи, не затрагивая основную функциональность, в том числе за счет передачи разработки отдельным специализированным командам. Это полезно, например, при необходимости централизованного управления сетевыми вызовами и функциями безопасности — во избежание дублирования сложного кода на каждом компоненте отдельно.
Добавлять новую функциональность в Legacy-приложения, которые тяжело поддаются рефакторингу.
Так как добавление Proxy пусть и незначительно, но увеличивает сетевые задержки, шаблон Ambassador не рекомендуется использовать, когда время задержки критично. Также подход лучше не применять в случаях, когда можно обойтись стандартной клиентской библиотекой — например, если используется всего один язык или нет возможности выделить общие периферийные задачи.
Управление настройками
Практически все приложения во время работы используют разнообразные конфигурационные параметры: адреса служб, строки подключения к базам данных, учетные данные, пути к сертификатам и так далее. При этом параметры будут отличаться в зависимости от среды выполнения: Dev, Prod и так далее. Хранить конфигурации локально — в файлах, развертываемых вместе с приложением, — считается очень плохой практикой, особенно при переходе на микросервисы. Это приводит к серьезным рискам безопасности и требует повторного развертывания при каждом изменении конфигурационных параметров, что очень трудозатратно.
Поэтому в приложениях корпоративного уровня рекомендуется использовать подход External Configuration, предлагающий хранить все конфигурации во внешнем хранилище. В качестве такого хранилища может выступать облачная служба хранения, база данных или другая система.

В результате применения этого подхода процесс сборки будет отделен от среды выполнения, а риски безопасности будут сведены к минимуму, так как конфигурации для производственной среды перестанут являться частью кодовой базы.
За MSA будущее?
Микросервисная архитектура действительно помогает ускорить внедрение и совершенствование сервисов. А именно скорость появление новой функциональности для конечных пользователей становится одной из причин выбора продукта. Поэтому изучение и внедрение MSA сегодня — это дополнительный буст для успеха проекта в будущем.
