
Совсем недавно мы опубликовали статью с описанием проблем одной из самых популярных технологий, используемых в IT, и на наше удивление она вызвала достаточно живой интерес (во всяком случае для технической статьи). Поэтому мы решили на этом не останавливаться, и сегодня мы «идем в гости» к одному из самых популярных продуктов на российском рынке разработки бизнес-приложений — платформе 1С.
Так сложилось, что на хабре многие 1С не любят, но порой складывается впечатление, что немногие из этих людей хорошо понимают, за что они его не любят. Этой статьей мы восполним этот пробел и убьем сразу двух зайцев: с одной стороны, расскажем, как в 1С все устроено изнутри, а с другой стороны — почему это все работает не так как нужно / хотелось бы. Надо сказать, что 1С многими своими решениями смог реально нас удивить, впрочем, не будем забегать вперед.
Статей с критикой 1С на Хабре достаточно (например, один, два, три), но, на мой взгляд, они либо слишком много внимания уделяют всяким мелочам, вроде неправильной организации меню, либо рассуждают о слишком абстрактных вещах, в которых 1С, возможно, и не виноват. В этой же статье, как и в статье про SQL, речь пойдет исключительно о фундаментальных (и вполне осязаемых) проблемах, которые касаются всех и каждого, кто разрабатывает / дорабатывает решения на 1С, и приводят либо к существенному росту порога вхождения, либо к серьезному падению производительности, либо к значительным трудозатратам со стороны разработчика.
Итак, поехали. Проблем в 1С достаточно много, поэтому, чтобы в них удобнее было ориентироваться, начнем с оглавления (со списком всех этих проблем):
- Объекты: Справочники, Документы и т.д.
- Таблицы / Представления: Регистры
- Запросы
- Формы
- Избыточные уровни абстракций
- Закрытая физическая модель
- Отсутствие наследования и полиморфизма
- Отсутствие явной типизации в коде
- Отсутствие модульности
- Ставка на визуальное программирование
- Фатальный недостаток
- Неуважительные по отношению к разработчикам лицензирование и брендирование
Разделы я постарался выстроить в порядке от базовых понятий / проблем к более сложным, хотя по факту в большинстве своем они никак не связаны друг с другом. Поэтому, если кому-то лень читать всю статью целиком, можете просто прочитать отдельные заинтересовавшие его разделы из оглавления, сквозного сюжета там практически нет.
Объекты: Справочники, Документы и т.д.
Как обычно устроены ORM фреймворки / платформы? В языке разработки ORM фреймворка в том или ином виде поддерживаются классы объектов. Для каждого из этих классов разработчик может задать его отображение на некоторую таблицу. Как правило, один класс соответствует одной таблице, единственный ключ которой, в свою очередь, соответствует идентификатору объекта этого класса. Тут, конечно, возникает вопрос, что делать с таблицами у которых несколько ключей. Для них тоже создаются соответствующие классы, благо большинство ORM поддерживают в качестве идентификаторов несколько полей одного класса. Порой, конечно, при таком отображении получаются достаточно дырявые абстракции вроде ТоварНаСкладе, но зато работа с данными в большинстве случаев идет в одной парадигме (ООП).
В 1С решили пойти другим путем и поддержать сразу обе парадигмы, у них одновременно есть и объекты, и записи. Логику записей используют регистры и запросы (о них в следующих разделах), логика объектов напоминает обычный ORM, правда, со своими особенностями:
- Отображением на таблицы разработчик никак не управляет, и вообще оно скрыто от него (хотя ничего особенного в нем нет)
- Никаких one-to-many, many-to-many отображений нет, их функцию выполняют так называемые табличные части — коллекции внутренних объектов, фактически агрегированных в основной объект.
Неэффективное получение данных объектов
Так как несвоевременное или избыточное чтение данных с сервера БД и передача их на сервер приложений может приводить к существенному падению производительности, обычно ORM-фреймворки предоставляют разработчику целый набор инструментов по управлению получаемыми ими данными. Но не 1С. В 1С объект читается всегда целиком, в том числе с табличными частями, но не более того (без каких либо связанных данных). Как следствие, данных читается:
- либо слишком много — если надо получить только одно поле (реквизит)
- либо слишком мало — если в цикле надо обращаться к другим объектам по ссылке, мы получаем классическую проблему N+1 (один запрос для получения N объектов и по одному запросу для каждой ссылки).
Такая убогость механизма ORM в 1С на самом деле обусловлена тем, что в 1С в какой-то момент попросту решили отказаться от ORM и сделать ставку на голый SQL (то есть регистры и запросы). Правда, немного забегая вперед, с учетом отсутствия расширенных возможностей SQL и DML в 1С периодически все-таки возвращаются к ORM, но это скорее вынужденная необходимость. А в целом типичный код типовых решений на 1С выглядит приблизительно так:
Пример кода
Процедура ИнициализироватьДанныеДокумента(ДокументСсылка, ДополнительныеСвойства, Регистры = Неопределено) Экспорт
////////////////////////////////////////////////////////////////////////////
// Создадим запрос инициализации движений
Запрос = Новый Запрос;
ЗаполнитьПараметрыИнициализации(Запрос, ДокументСсылка);
////////////////////////////////////////////////////////////////////////////
// Сформируем текст запроса
ТекстыЗапроса = Новый СписокЗначений;
ТекстЗапросаТаблицаЗаказыКлиентов(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаСвободныеОстатки(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаОбеспечениеЗаказов(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаТоварыКОтгрузке(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаТоварыНаСкладах(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаДвиженияСерийТоваров(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаПереданнаяВозвратнаяТара(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаТоварыОрганизаций(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаТоварыПереданныеНаКомиссию(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаДатыПередачиТоваровНаКомиссию(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаТоварыОрганизацийКПередаче(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаТоварыКОформлениюОтчетовКомитенту(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаСебестоимостьТоваров(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаВыручкаИСебестоимостьПродаж(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаРасчетыСКлиентами(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаСуммыДокументовВВалютеРегл(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаНДССостояниеРеализации0(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаНДСЗаписиКнигиПродаж(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаМатериалыИРаботыВПроизводстве(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаДвиженияНоменклатураНоменклатура(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаУслугиКОформлениюОтчетовПринципалу(Запрос, ТекстыЗапроса, Регистры);
ТекстЗапросаТаблицаРеестрДокументов(Запрос, ТекстыЗапроса, Регистры);
ПроведениеСерверУТ.ИницализироватьТаблицыДляДвижений(Запрос, ТекстыЗапроса, ДополнительныеСвойства.ТаблицыДляДвижений, Истина);
КонецПроцедуры
Функция ТекстЗапросаТаблицаЗаказыКлиентов(Запрос, ТекстыЗапроса, Регистры)
ИмяРегистра = "ЗаказыКлиентов";
Если НЕ ПроведениеСерверУТ.ТребуетсяТаблицаДляДвижений(ИмяРегистра, Регистры) Тогда
Возврат "";
КонецЕсли;
ТекстЗапроса =
"ВЫБРАТЬ
| ЗНАЧЕНИЕ(ВидДвиженияНакопления.Расход) КАК ВидДвижения,
| &ДатаРаспоряжения КАК Период,
| ТаблицаТовары.ЗаказКлиента КАК ЗаказКлиента,
| ТаблицаТовары.Номенклатура КАК Номенклатура,
| ТаблицаТовары.Характеристика КАК Характеристика,
| ВЫБОР
| КОГДА ТаблицаТовары.СтатусУказанияСерий В (10, 14)
| ТОГДА ТаблицаТовары.Серия
| ИНАЧЕ ЗНАЧЕНИЕ(Справочник.СерииНоменклатуры.ПустаяСсылка)
| КОНЕЦ КАК Серия,
| ТаблицаТовары.КодСтроки КАК КодСтроки,
| ВЫБОР
| КОГДА ТаблицаТовары.Номенклатура.ТипНоменклатуры В (ЗНАЧЕНИЕ(Перечисление.ТипыНоменклатуры.Товар), ЗНАЧЕНИЕ(Перечисление.ТипыНоменклатуры.МногооборотнаяТара))
| ТОГДА ТаблицаТовары.Склад
| ИНАЧЕ ЗНАЧЕНИЕ(Справочник.Склады.ПустаяСсылка)
| КОНЕЦ КАК Склад,
| 0 КАК Заказано,
| ТаблицаТовары.Количество КАК КОформлению,
| ТаблицаТовары.СуммаВзаиморасчетов КАК Сумма
|ИЗ
| Документ.РеализацияТоваровУслуг.Товары КАК ТаблицаТовары
|ГДЕ
| ТаблицаТовары.Ссылка = &Ссылка
| И ТаблицаТовары.КодСтроки <> 0
| И &Статус <> ЗНАЧЕНИЕ(Перечисление.СтатусыРеализацийТоваровУслуг.Отгружено)
| И &РеализацияПоЗаказу
| И &ИспользоватьРасширенныеВозможностиЗаказаКлиента
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| ЗНАЧЕНИЕ(ВидДвиженияНакопления.Расход),
| &ДатаРаспоряжения,
| ТаблицаТовары.ЗаказКлиента,
| ТаблицаТовары.Номенклатура,
| ТаблицаТовары.Характеристика,
| ВЫБОР
| КОГДА ТаблицаТовары.СтатусУказанияСерий В (10, 14)
| ТОГДА ТаблицаТовары.Серия
| ИНАЧЕ ЗНАЧЕНИЕ(Справочник.СерииНоменклатуры.ПустаяСсылка)
| КОНЕЦ,
| ТаблицаТовары.КодСтроки,
| ВЫБОР
| КОГДА ТаблицаТовары.Номенклатура.ТипНоменклатуры В (ЗНАЧЕНИЕ(Перечисление.ТипыНоменклатуры.Товар), ЗНАЧЕНИЕ(Перечисление.ТипыНоменклатуры.МногооборотнаяТара))
| ТОГДА ТаблицаТовары.Склад
| ИНАЧЕ ЗНАЧЕНИЕ(Справочник.Склады.ПустаяСсылка)
| КОНЕЦ,
| ТаблицаТовары.Количество,
| ТаблицаТовары.Количество,
| ТаблицаТовары.СуммаВзаиморасчетов
|ИЗ
| Документ.РеализацияТоваровУслуг.Товары КАК ТаблицаТовары
|ГДЕ
| ТаблицаТовары.Ссылка = &Ссылка
| И ТаблицаТовары.КодСтроки <> 0
| И &Статус = ЗНАЧЕНИЕ(Перечисление.СтатусыРеализацийТоваровУслуг.Отгружено)
| И &РеализацияПоЗаказу
| И &ИспользоватьРасширенныеВозможностиЗаказаКлиента
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход),
| &ДатаРаспоряжения,
| ТаблицаТовары.ЗаказКлиента,
| ТаблицаТовары.Номенклатура,
| ТаблицаТовары.Характеристика,
| ВЫБОР
| КОГДА ТаблицаТовары.СтатусУказанияСерий В (10, 14)
| ТОГДА ТаблицаТовары.Серия
| ИНАЧЕ ЗНАЧЕНИЕ(Справочник.СерииНоменклатуры.ПустаяСсылка)
| КОНЕЦ,
| ТаблицаТовары.КодСтроки,
| ВЫБОР
| КОГДА ТаблицаТовары.Номенклатура.ТипНоменклатуры В (ЗНАЧЕНИЕ(Перечисление.ТипыНоменклатуры.Товар), ЗНАЧЕНИЕ(Перечисление.ТипыНоменклатуры.МногооборотнаяТара))
| ТОГДА ТаблицаТовары.Склад
| ИНАЧЕ ЗНАЧЕНИЕ(Справочник.Склады.ПустаяСсылка)
| КОНЕЦ,
| 0,
| ТаблицаТовары.Количество,
| ТаблицаТовары.СуммаВзаиморасчетов
|ИЗ
| Документ.РеализацияТоваровУслуг.Товары КАК ТаблицаТовары
|ГДЕ
| ТаблицаТовары.Ссылка = &Ссылка
| И ТаблицаТовары.КодСтроки = 0
| И &РеализацияПоЗаказу
| И &ИспользоватьРасширенныеВозможностиЗаказаКлиента
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| ЗНАЧЕНИЕ(ВидДвиженияНакопления.Расход),
| &ДатаРаспоряжения,
| ТаблицаТовары.ЗаказКлиента,
| ТаблицаТовары.Номенклатура,
| ТаблицаТовары.Характеристика,
| ВЫБОР
| КОГДА ТаблицаТовары.СтатусУказанияСерий В (10, 14)
| ТОГДА ТаблицаТовары.Серия
| ИНАЧЕ ЗНАЧЕНИЕ(Справочник.СерииНоменклатуры.ПустаяСсылка)
| КОНЕЦ,
| ТаблицаТовары.КодСтроки,
| ВЫБОР
| КОГДА ТаблицаТовары.Номенклатура.ТипНоменклатуры В (ЗНАЧЕНИЕ(Перечисление.ТипыНоменклатуры.Товар), ЗНАЧЕНИЕ(Перечисление.ТипыНоменклатуры.МногооборотнаяТара))
| ТОГДА ТаблицаТовары.Склад
| ИНАЧЕ ЗНАЧЕНИЕ(Справочник.Склады.ПустаяСсылка)
| КОНЕЦ,
| 0,
| ТаблицаТовары.Количество,
| ТаблицаТовары.СуммаВзаиморасчетов
|ИЗ
| Документ.РеализацияТоваровУслуг.Товары КАК ТаблицаТовары
|ГДЕ
| ТаблицаТовары.Ссылка = &Ссылка
| И ТаблицаТовары.КодСтроки = 0
| И &РеализацияПоЗаказу
| И &ИспользоватьРасширенныеВозможностиЗаказаКлиента";
ТекстыЗапроса.Добавить(ТекстЗапроса, ИмяРегистра);
Возврат ТекстЗапроса;
КонецФункции
Таблицы / Представления: Регистры
Регистры в 1С это большой комбайн, который выполняет сразу несколько функций:
- Таблицы (с инфраструктурой группового замещения данных)
- Представления (в том числе материализованные)
- Работа с моментами / периодами времени (как в таблицах, так и в представлениях)
С функцией таблиц все более-менее понятно. Так таблицы регистров — это и есть обычные таблицы с ключами, а менеджеры регистров — интерфейс по замещению строк, удовлетворяющих заданному условию (отбору) другими строками (ну или просто добавлению строк)
Функционал работы со временем — это особенность ERP-платформ и 1С в частности. Так, с точки зрения SQL (да и других ЯП), например, дата — это один из примитивных типов, не сильно отличающийся от строки или числа. В 1С же работа со временем поддерживается в большом количестве различных абстракций, например, в документах, таблицах периодических регистров и регистров накоплений. Но во всех этих абстракциях поддержка времени — не более чем дополнительные поля. Существенно интереснее поддержка времени в представлениях (которые в 1С называются виртуальными таблицами).
Одновременно с созданием регистра в 1С неявно создаются различные представления в зависимости от типа регистра:
- СрезПоследних (для периодических регистров сведений) — получает последнее значения на дату (в том числе текущую)
- Остатки, Обороты, ОстаткиИОбороты (для регистров накопления) — получают различные суммы на дату (в том числе текущую)
Являясь по сути не более чем представлениями в SQL, усовершенствованными для работы со временем, представления в 1С наследуют (а иногда даже и усугубляют) все проблемы представлений в SQL.
Регистры поддерживаются в очень частных случаях
Фактически, регистры в 1С поддерживают всего две операции: сумма и последнее по дате, сгруппированные по ключам таблицы. Это на порядок меньше, чем даже индексированные представления в том же MS SQL, не говоря уже про Oracle. Соответственно, шаг влево, шаг вправо — и разработчику необходимо самому создавать таблицу (непериодический регистр сведений / справочник) или поле (реквизит) и вручную поддерживать актуальность данных в них.
Если же говорить про представления вообще (а не только материализованные), то при сравнении с SQL все еще хуже: аналога этого механизма в 1С нет в принципе, соответственно, для повторного использования / декомпозиции нужно либо создавать процедуры, возвращающие / заполняющие временные таблицы, либо производить различные манипуляции с текстами запросов (вроде склейки или замены).
Отсутствие ограничений и событий для значений регистров
Но даже если для расчета некоторого показателя вам удастся обойтись существующими в 1С регистрами, у вас в дальнейшем скорее всего возникнет вопрос, как создать ограничения или события на этот рассчитанный показатель. Например, запретить ситуацию, когда количество к отгрузке становится меньше 0, или послать какое-нибудь уведомление в этом случае. И если в SQL это можно декларативно сделать хотя бы для материализованных представлений, то в 1С даже такой возможности нет. Как это обходится? Разработчики типовых, например, используют такой трюк:
В триггере ПередЗаписью (в SQL соответствует per-statement trigger on before) запоминают во временную таблицу старые записи регистра для сгенерировавшего его документа:
Код
// Текущее состояние набора помещается во временную таблицу,
// чтобы при записи получить изменение нового набора относительно текущего.
Запрос = Новый Запрос;
Запрос.УстановитьПараметр("Регистратор", Отбор.Регистратор.Значение);
Запрос.МенеджерВременныхТаблиц = ДополнительныеСвойства.ДляПроведения.СтруктураВременныеТаблицы.МенеджерВременныхТаблиц;
Запрос.Текст =
"ВЫБРАТЬ
| Таблица.ВидДвижения КАК ВидДвижения,
| Таблица.ДокументОтгрузки КАК ДокументОтгрузки,
| Таблица.Номенклатура КАК Номенклатура,
| Таблица.Характеристика КАК Характеристика,
| Таблица.Назначение КАК Назначение,
| Таблица.Серия КАК Серия,
| Таблица.Склад КАК Склад,
| Таблица.Получатель КАК Получатель,
| ВЫБОР
| КОГДА Таблица.ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
| ТОГДА Таблица.ВРезерве + Таблица.КОтгрузке
| ИНАЧЕ -Таблица.ВРезерве - Таблица.КОтгрузке
| КОНЕЦ КАК ВРезервеКОтгрузкеПередЗаписью,
| ВЫБОР
| КОГДА Таблица.ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
| ТОГДА Таблица.КОтгрузке
| ИНАЧЕ -Таблица.КОтгрузке
| КОНЕЦ КАК КОтгрузкеПередЗаписью,
| ВЫБОР
| КОГДА Таблица.ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
| ТОГДА -Таблица.Собирается
| ИНАЧЕ Таблица.Собирается
| КОНЕЦ КАК СобираетсяПередЗаписью,
| ВЫБОР
| КОГДА Таблица.ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
| ТОГДА -Таблица.Собрано
| ИНАЧЕ Таблица.Собрано
| КОНЕЦ КАК СобраноПередЗаписью
|ПОМЕСТИТЬ ДвиженияТоварыКОтгрузкеПередЗаписью
|ИЗ
| РегистрНакопления.ТоварыКОтгрузке КАК Таблица
|ГДЕ
| Таблица.Регистратор = &Регистратор";
Запрос.Выполнить();
В триггере ПослеЗаписи (on after) запоминают во временную таблицу новые + старые записи:
Код
СтруктураВременныеТаблицы = ДополнительныеСвойства.ДляПроведения.СтруктураВременныеТаблицы;
Запрос = Новый Запрос;
ОформлятьСначалаНакладные = Константы.ПорядокОформленияНакладныхРасходныхОрдеров.Получить() = Перечисления.ПорядокОформленияНакладныхРасходныхОрдеров.СначалаНакладные;
Запрос.УстановитьПараметр("ОформлятьСначалаНакладные", ОформлятьСначалаНакладные);
Запрос.УстановитьПараметр("Регистратор", Отбор.Регистратор.Значение);
Запрос.МенеджерВременныхТаблиц = СтруктураВременныеТаблицы.МенеджерВременныхТаблиц;
// Рассчитывается изменение нового набора относительно текущего с учетом накопленных изменений
// и помещается во временную таблицу.
Запрос.Текст =
"ВЫБРАТЬ
| ТаблицаИзменений.ДокументОтгрузки КАК ДокументОтгрузки,
| ТаблицаИзменений.Номенклатура КАК Номенклатура,
| ТаблицаИзменений.Характеристика КАК Характеристика,
| ТаблицаИзменений.Назначение КАК Назначение,
| ТаблицаИзменений.Серия КАК Серия,
| ТаблицаИзменений.Склад КАК Склад,
| ТаблицаИзменений.Получатель КАК Получатель,
| СУММА(ТаблицаИзменений.КОтгрузкеИзменение) КАК КОтгрузкеИзменение,
| СУММА(ТаблицаИзменений.СобираетсяИзменение) КАК СобираетсяИзменение,
| СУММА(ТаблицаИзменений.СобираетсяИзменение) КАК СобраноИзменение
|ПОМЕСТИТЬ ДвиженияТоварыКОтгрузкеИзменение
|ИЗ
| (ВЫБРАТЬ
| Таблица.ВидДвижения КАК ВидДвижения,
| Таблица.ДокументОтгрузки КАК ДокументОтгрузки,
| Таблица.Номенклатура КАК Номенклатура,
| Таблица.Характеристика КАК Характеристика,
| Таблица.Назначение КАК Назначение,
| Таблица.Серия КАК Серия,
| Таблица.Склад КАК Склад,
| Таблица.Получатель КАК Получатель,
| Таблица.КОтгрузкеПередЗаписью КАК КОтгрузкеИзменение,
| Таблица.СобираетсяПередЗаписью КАК СобираетсяИзменение,
| Таблица.СобраноПередЗаписью КАК СобраноИзменение
| ИЗ
| ДвиженияТоварыКОтгрузкеПередЗаписью КАК Таблица
|
| ОБЪЕДИНИТЬ ВСЕ
|
| ВЫБРАТЬ
| Таблица.ВидДвижения,
| Таблица.ДокументОтгрузки,
| Таблица.Номенклатура,
| Таблица.Характеристика,
| Таблица.Назначение,
| Таблица.Серия,
| Таблица.Склад,
| Таблица.Получатель,
| ВЫБОР
| КОГДА Таблица.ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
| ТОГДА -Таблица.КОтгрузке
| ИНАЧЕ Таблица.КОтгрузке
| КОНЕЦ,
| ВЫБОР
| КОГДА Таблица.ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
| ТОГДА Таблица.Собирается
| ИНАЧЕ -Таблица.Собирается
| КОНЕЦ,
| ВЫБОР
| КОГДА Таблица.ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
| ТОГДА Таблица.Собрано
| ИНАЧЕ -Таблица.Собрано
| КОНЕЦ
| ИЗ
| РегистрНакопления.ТоварыКОтгрузке КАК Таблица
| ГДЕ
| Таблица.Регистратор = &Регистратор) КАК ТаблицаИзменений
|
|СГРУППИРОВАТЬ ПО
| ТаблицаИзменений.ВидДвижения,
| ТаблицаИзменений.ДокументОтгрузки,
| ТаблицаИзменений.Номенклатура,
| ТаблицаИзменений.Характеристика,
| ТаблицаИзменений.Назначение,
| ТаблицаИзменений.Серия,
| ТаблицаИзменений.Склад,
| ТаблицаИзменений.Получатель
|
|ИМЕЮЩИЕ
| (СУММА(ТаблицаИзменений.КОтгрузкеИзменение) > 0
| ИЛИ СУММА(ТаблицаИзменений.СобираетсяИзменение) > 0
| ИЛИ СУММА(ТаблицаИзменений.СобраноИзменение) > 0)
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| Т.Номенклатура КАК Номенклатура,
| Т.Характеристика КАК Характеристика,
| Т.Назначение КАК Назначение,
| Т.Серия КАК Серия,
| Т.Склад КАК Склад,
| Т.Склад КАК Получатель,
| СУММА(Т.УвеличениеПрихода) КАК УвеличениеПрихода
|ПОМЕСТИТЬ ДвиженияТоварыКОтгрузкеИзменениеСводно
|ИЗ
| (ВЫБРАТЬ
| Таблица.ВидДвижения КАК ВидДвижения,
| Таблица.Номенклатура КАК Номенклатура,
| Таблица.Характеристика КАК Характеристика,
| Таблица.Назначение КАК Назначение,
| Таблица.Серия КАК Серия,
| Таблица.Склад КАК Склад,
| Таблица.Склад КАК Получатель,
| -Таблица.ВРезервеКОтгрузкеПередЗаписью КАК УвеличениеПрихода
| ИЗ
| ДвиженияТоварыКОтгрузкеПередЗаписью КАК Таблица
|ГДЕ
| Таблица.Серия <> ЗНАЧЕНИЕ(Справочник.СерииНоменклатуры.ПустаяСсылка)
| И Таблица.Склад.КонтролироватьОперативныеОстатки
|
| ОБЪЕДИНИТЬ ВСЕ
|
| ВЫБРАТЬ
| Таблица.ВидДвижения,
| Таблица.Номенклатура,
| Таблица.Характеристика,
| Таблица.Назначение,
| Таблица.Серия,
| Таблица.Склад,
| Таблица.Получатель,
| ВЫБОР
| КОГДА Таблица.ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
| ТОГДА Таблица.ВРезерве + Таблица.КОтгрузке
| ИНАЧЕ -Таблица.ВРезерве - Таблица.КОтгрузке
| КОНЕЦ
| ИЗ
| РегистрНакопления.ТоварыКОтгрузке КАК Таблица
| ГДЕ
| Таблица.Регистратор = &Регистратор) КАК Т
|ГДЕ
| Т.Серия <> ЗНАЧЕНИЕ(Справочник.СерииНоменклатуры.ПустаяСсылка)
| И Т.Склад.КонтролироватьОперативныеОстатки
|
|СГРУППИРОВАТЬ ПО
| Т.ВидДвижения,
| Т.Номенклатура,
| Т.Склад,
| Т.Получатель,
| Т.Характеристика,
| Т.Назначение,
| Т.Серия
|
|ИМЕЮЩИЕ
| СУММА(Т.УвеличениеПрихода) > 0
|;
|
|////////////////////////////////////////////////////////////////////////////////
|УНИЧТОЖИТЬ ДвиженияТоварыКОтгрузкеПередЗаписью";
ЗапросПакет = Запрос.ВыполнитьПакет();
Выборка = ЗапросПакет[0].Выбрать();
Выборка.Следующий();
// Новые изменения были помещены во временную таблицу.
// Добавляется информация о ее существовании и наличии в ней записей об изменении.
СтруктураВременныеТаблицы.Вставить("ДвиженияТоварыКОтгрузкеИзменение", Выборка.Количество > 0);
Выборка = ЗапросПакет[1].Выбрать();
Выборка.Следующий();
СтруктураВременныеТаблицы.Вставить("ДвиженияТоварыКОтгрузкеИзменениеСводно", Выборка.Количество > 0);
В КонтролеПроведения (единой точке входа записи всех документов) читают текущие значения регистра для измененных ключей и проверяют на то, что они должно быть больше 0.
Код
Если ЕстьИзмененияВТаблице(ДанныеТаблиц,"ДвиженияТоварыКОтгрузкеИзменениеСводно") Тогда
МассивКонтролей.Добавить(Врег("ДвиженияТоварыКОтгрузкеСводно"));
ТекстЗапроса = ТекстЗапроса +
"
|ВЫБРАТЬ
| Остатки.Номенклатура КАК Номенклатура,
| Остатки.Номенклатура.ЕдиницаИзмерения КАК ЕдиницаИзмерения,
| Остатки.Характеристика КАК Характеристика,
| Остатки.Назначение КАК Назначение,
| Остатки.Склад КАК Склад,
| Остатки.Серия КАК Серия,
| СУММА(Остатки.Количество) КАК Количество
|
|ИЗ
|(ВЫБРАТЬ
| Т.Номенклатура КАК Номенклатура,
| Т.Характеристика КАК Характеристика,
| Т.Назначение КАК Назначение,
| Т.Склад КАК Склад,
| Т.Серия КАК Серия,
| -Т.ВРезервеОстаток - Т.КОтгрузкеОстаток КАК Количество
|ИЗ
| РегистрНакопления.ТоварыКОтгрузке.Остатки(
| ,
| (Номенклатура, Характеристика, Назначение, Склад, Серия) В
| (ВЫБРАТЬ
| Т.Номенклатура,
| Т.Характеристика,
| Т.Назначение,
| Т.Склад,
| Т.Серия
| ИЗ
| ДвиженияТоварыКОтгрузкеИзменениеСводно КАК Т)) КАК Т
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| Т.Номенклатура КАК Номенклатура,
| Т.Характеристика КАК Характеристика,
| Т.Назначение КАК Назначение,
| Т.Склад КАК Склад,
| Т.Серия КАК Серия,
| Т.ВНаличииОстаток КАК Количество
|ИЗ
| РегистрНакопления.ТоварыНаСкладах.Остатки(
| ,
| (Номенклатура, Характеристика, Назначение, Склад, Серия) В
| (ВЫБРАТЬ
| Т.Номенклатура,
| Т.Характеристика,
| Т.Назначение,
| Т.Склад,
| Т.Серия
| ИЗ
| ДвиженияТоварыКОтгрузкеИзменениеСводно КАК Т)) КАК Т
|) КАК Остатки
|
|СГРУППИРОВАТЬ ПО
| Остатки.Номенклатура,
| Остатки.Характеристика,
| Остатки.Назначение,
| Остатки.Склад,
| Остатки.Серия
|
|ИМЕЮЩИЕ
| СУММА(Остатки.Количество) < 0
|;
|///////////////////////////////////////////////////////////////////
|";
КонецЕсли;
PS: Проверено, эти временные таблицы нигде больше не используются, только для проверки одного простого ограничения.
Описанный выше способ вряд ли можно охарактеризовать как универсальный (ну и выглядит он диковато), с другой стороны лучшего способа сделать это в 1С я не нашел (как и похоже разработчики типовых). Хотя сделай 1С все по человечески, весь приведенный код можно было бы заменить на ровно одну строку.
В параметрах виртуальных таблиц можно использовать только константы
Также как и в параметризованных представлениях в SQL в параметрах виртуальных таблиц можно использовать только константы. То есть, если вы попробуете выполнить запрос:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Товар.МояДата КАК МояДата,
| Товар.Цена КАК Цена,
| ДвиженияОстатков.ЧислоОстаток КАК Число
|ИЗ
| Справочник.Товар КАК Тов
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.ДвиженияОстатков.Остатки(Товар.МояДата, Товар = Тов.Ссылка) КАК ДвиженияОстатков
| ПО ДвиженияОстатков.Товар = Тов.Ссылка
| ГДЕ Товар.Наименование = &Имя "
;
РезультатЗапроса = Запрос.Выполнить();
То получите сразу 2 ошибки: “Неверные параметры” и “Таблица Тов не найдена”. И если со второй ошибкой еще как-то можно справиться при помощи конструкции IN (В) и подзапроса (это тоже одна из проблем 1С, но о ней позже), то что делать, когда дата не является константой, а лежит, например, в поле другой таблицы, — непонятно. В SQL для хотя бы частичного решения этой проблемы есть специальный вид JOIN — LATERAL JOIN или APPLY, в 1С же даже этого нет. И, соответственно, нужно самому находить все возможные разновидности дат, хранящихся в заданном поле, после чего для каждой даты выполнять отдельный запрос. Ну или находить минимум / максимум дат и высчитывать остатки и обороты. В любом случае оба этих способа как неудобны, так и не производительны одновременно.
Справедливости ради, ограничение, что параметром момента времени должна быть константа, 1С умеет достаточно эффективно использовать, если в регистре материализованы итоги для промежуточных дат. В этом случае 1С в подзапросе виртуальной таблицы может бежать по записям регистра, начиная не от текущей даты, а от ближайшей даты, для которой материализованы итоги. С другой стороны, учитывая что в оперативной базе (OLTP) древность данных обычно обратно пропорциональна вероятности их использования, а на поддержание промежуточных итогов нужны дополнительные ресурсы (в частности место на диске), практическая польза от такой оптимизации весьма сомнительна (если, конечно, оперативную базу одновременно активно не используют как аналитическую, но об этом позже).
Запросы
Запросы в 1С пишутся на своем внутреннем диалекте SQL, который по большому счету мало чем отличается от самого SQL. Правда, в отличие от последнего и других платформ, использующих SQL, работа с запросами в 1С осталась на очень примитивном уровне, и соответственно имеет ряд недостатков.
Запросы в строках
Запросы по старинке пишутся в строках (смотри примеры выше). Это создает как минимум две проблемы:
- Со стороны IDE непонятно, как поддерживать автоподстановку, подсветку ошибок, синтаксиса, поиск использований и т.п.
- Ошибки в запросах обнаруживаются только при выполнении, а не сохранении, запуске или компиляции.
Впрочем, стоит отметить, в 1С есть возможность конструирования запросов программно (CхемаЗапроса, СКД), но с верхними двумя проблемами это не сильно поможет (в упомянутых механизмах все равно в конечном итоге используется очень много строк). Единственное с чем это теоретически может помочь, так это с отсутствием в 1С механизма представлений. Но из-за громоздкости этих механизмов, а также невозможности использования визуального программирования, для декомпозиции запросов на практике схемы запросов и СКД используются очень редко.
Отсутствие оптимизатора запросов
Существующий механизм запросов в 1С — это не более чем транслятор SQL-диалекта 1С в синтаксис РСУБД, используемой системой в качестве хранилища данных. И вот тут есть тонкий момент. Дело в том, что кроме больших коммерческих СУБД с кучей оптимизаторов (MS SQL, Oracle), 1С также поддерживает свою файловую СУБД и PostgreSQL, которые работают по принципу «что вижу, то и выполняю». В частности, как было отмечено в предыдущей статье, PostgreSQL не поддерживает Join Predicate Push Down (возможность проталкивания условия запроса внутрь подзапроса). Соответственно у 1С разработчика при написании любого запроса возникает дилемма, можно ли полагаться на оптимизаторы СУБД или нет.
Общая рекомендация самой 1С — нет (и это понятно, так как в противном случае потребовалась бы установка дорогостоящих и громоздких СУБД). И во всяком случае во всех типовых они следуют этим рекомендациям. Более того, судя по этому разделу:
В частности, виртуальная таблица по-разному формирует запросы к базе данных в зависимости от того, какой режим работы у регистра (включено ли хранение актуальных итогов, рассчитаны ли итоги и на какой последний период). Она может как использовать временные таблицы базы данных, так и сформировать подзапрос.
1С и в самой платформе следует принципу «не полагаться на оптимизаторы СУБД», поэтому у разработчика и выбора то особо не остается. А значит ему приходится ориентироваться на «самое слабое звено» и все оптимизации запросов делать вручную. В частности проталкивать условия запроса внутрь подзапросов. И если с подзапросами это еще как-то можно сделать, то с виртуальными таблицами все не так просто. В них хоть немного сложные условия внешних запросов необходимо преобразовывать в конструкции вида В (Подзапрос). Например:
ВЫБРАТЬ
РасходнаяНакладнаяСостав.Номенклатура,
УчетНоменклатурыОстатки.КоличествоОстаток
ИЗ
Документ.РасходнаяНакладная.Состав КАК РасходнаяНакладнаяСостав
ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.УчетНоменклатуры.Остатки(,
Номенклатура В (
ВЫБРАТЬ Номенклатура
ИЗ Документ.РасходнаяНакладная.Состав
ГДЕ Ссылка = &Документ)) КАК УчетНоменклатурыОстатки
ПО УчетНоменклатурыОстатки.Номенклатура = РасходнаяНакладнаяСостав.Номенклатура
ГДЕ
РасходнаяНакладнаяСостав.Ссылка = &Документ И
(УчетНоменклатурыОстатки.КоличествоОстаток < РасходнаяНакладнаяСостав.Количество ИЛИ
УчетНоменклатурыОстатки.КоличествоОстаток ЕСТЬ NULL)
Также, судя по тому, что 1С не рекомендует создавать сложные условия в виртуальных таблицах, самым «слабым звеном» в линейке РСУБД, похоже, является не PostgreSQL, а файловая СУБД (потому как во всяком случае с оптимизацией IN / EXISTS даже PostgreSQL успешно справляется). Как следствие, для нормальной работы, в том числе с файловой СУБД, все запросы надо декомпозировать вплоть до самых примитивных (что в типовых и делают).
Отсутствие расширенных SQL возможностей
Как и с оптимизатором запросов, с расширенными SQL возможностями 1С также, похоже, попали в ловушку поддержки различных СУБД, а точнее своей файловой СУБД. Так, для того чтобы поддержать такие уже де-факто стандартные вещи, как оконные функции и рекурсивные CTE, 1С пришлось бы поддержать их и в своей файловой СУБД, что является не такой уж тривиальной задачей. Как следствие, либо по причине сложности реализации, либо все же решив, что эти механизмы слишком сложны для разработчика, в 1С решили этого не делать, и сейчас SQL-диалект 1С соответствует стандарту SQL года так 92. А значит для решения таких простых задач, как расчет нарастающего итога, придется либо серьезно попотеть (чтобы добиться нормальной производительности), либо вернуться в ORM, который, как мы выяснили выше, в 1С тоже не фонтан.
Отсутствие запросов на изменение
Активное повсеместное использование запросов позволяет решить проблемы, связанные с чтением большого количества данных. Но так как, в отличии от SQL, в запросах 1С отсутствует механизм изменения данных (так называемый DML), использование запросов никак не может помочь в вопросах записи большого количества данных. То есть, если вам понадобится создать сто тысяч дисконтных карт, вам придется вернуться назад в ORM (то есть к объектам) и генерировать эти объекты по одному с соответствующей не самой высокой производительностью.
Отказ от автоматических блокировок
Одной из главных функций SQL серверов является обеспечение целостности данных (буковки CI в ACID). Самым простым способом ее обеспечения является блокировка всех читаемых данных (с защитой их от изменения). Проблема такого подхода в том, что при его использовании очень сильно страдает масштабируемость, в частности, из-за того, что читатель блокирует писателя. То есть грубо говоря, один сложный отчет, читающий большое количество данных, может ввести в ступор всю базу.
Для борьбы с этим явлением в свое время появились так называемые версионные СУБД. Основная идея этих СУБД состоит в том, чтобы для каждой записи хранить не одну, а несколько версий. Соответственно при начале любой транзакции СУБД запоминает версию базы на момент начала этой транзакции, после чего внутри транзакции читает не текущую запись в таблице, а запись именно на эту «запомненную» версию. Реализуется поддержка различных версий записей (MVCC) в Oracle и PostgreSQL по-разному, но с точки зрения логики обеспечения целостности это не так важно, поэтому останавливаться на этом здесь подробно не имеет особого смысла.
Такой подход действительно значительно повышает масштабируемость СУБД, но на самом деле это улучшение масштабируемости является следствием частичного отказа от целостности. Так, например, если вы будете проверять, что сумма значений полей из двух разных таблиц должна быть больше некоторого значения, то при одновременном редактировании значений этих полей в обеих таблицах в блокировочнике все будет хорошо (точнее возникнет дедлок, в результате которого одна из транзакций откатится), версионник же благополучно запишет оба этих изменения в базу, нарушив тем самым ваше ограничение. Что же тогда поддерживает версионник в плане целостности? На самом деле фактически он поддерживает только целостность данных, которые физически хранятся в таблицах (для них работает механизм конфликтов записи). Соответственно, чтобы сделать «версионную» базу целостной, существует два очевидных варианта:
- Материализовать данные, для которых важна целостность. Для этого, конечно, очень желательно иметь механизм прозрачной материализации этих данных, а его, как мы видели, ни в SQL (материализация представлений), ни тем более в 1С, нет.
- При чтении данных, для которых важна целостность, переводить версионную базу в «блокировочный» режим, то есть читать данные с опцией FOR UPDATE (ДЛЯ ИЗМЕНЕНИЯ).
Тут важно понимать, что целостность, как правило, важна только для ограничений (и других декларативных правил), тогда как в остальных случаях порядок транзакций все равно не гарантирован и важно лишь то, чтобы зафиксированные транзакции считывались целиком (а это версионники как раз обеспечивают).
Но вернемся к 1С. Как же они решили бороться с проблемой масштабируемости автоматических блокировок? Барабанная дробь. Они просто решили переложить эту проблему на разработчика. Одну из самых сложных задач в программировании (организацию многопоточного доступа). Самую неочевидную задачу с точки зрения человеческого мозга. Задачу, которую максимально тяжело тестировать и отлаживать. На разработчика, которым когда-то планировалось должен был быть бухгалтер. Решать императивно — ручной установкой и снятием блокировок.
Но самое интересное, что большинство разработчиков эту «манипуляцию» со стороны 1С особо и не заметили. Видимо, потому что описанная проблема весьма неочевидна, проявляется только при высококонкурентном доступе и в случае чего списывается на сбой оборудования / плохую погоду, после чего запускается пересчет, перепроверка, данные исправляются и все благополучно забывают про эту проблему до следующего инцидента.
Формы
Одной из особенностей ERP и других высокоуровневых платформ является то, что логика представлений у них, как правило, идет в комплекте. В частности в 1С за интерактивные представления отвечают так называемые формы. Изначально в 1С этот механизм был относительно простым и понятным и не сильно отличался от условного Access, но по мере роста требований к масштабируемости все изменилось.
Отказ от единого потока выполнения: разделение логики на сервер и клиент
Первым пал единый поток выполнения. Выполнять бизнес-логику на клиенте, как это делается в двухзвенной архитектуре, неэффективно как с точки зрения масштабируемости (обращений к СУБД по сети, невозможности перераспределения вычислительных мощностей), так и с точки зрения безопасности. Самое очевидное решение этой проблемы — перенести всю логику (как бизнес-логику, так и логику формы) на сервер, а реактивное обновление формы на клиенте и синхронизацию клиентского и серверного потоков выполнения реализовать автоматически средствами платформы. То есть весь поток выполнения хранить и выполнять на сервере (который многопоточен по своей природе), а клиенту оставить чисто техническую функцию — обновлять свое состояние по требованию сервера.
Что же сделал 1С? Как уже, наверное, многие догадались — переложили все на разработчика. Основной поток выполнения остался на клиенте, разработчику дали возможность создавать серверный поток выполнения, но при этом в клиентском потоке выполнения запретили обращаться к данным, а в серверном потоке выполнения — к пользователю, то есть открывать формы, диалоги и т.п. (реактивное обновление формы на клиенте они все же реализовали, то есть обращаться на сервере к данным формы можно). Как следствие простой случай общения с пользователем:
f() <- someData(); // читаем данные из базы необходимые для myForm |
превращается в кашу из пяти различных процедур с надуманными именами. Если при этом еще надо передать данные между myForm и otherForm, то придется использовать так называемые временные хранилища (что тоже было бы не нужно, если бы поток выполнения был на сервере) в результате чего код усложняется еще больше.
Возможно, причина того, почему 1С реализовали трехзвенную архитектуру именно таким образом, заключается в том, что для обеспечения более высокой отказоустойчивости и масштабируемости они не хотели хранить данные формы на сервере приложений. То есть чтобы при падении / очень большой загрузке сервера приложений можно было легко переключить пользователя на другой сервер без потери данных. Но у такой теории есть ряд белых пятен:
- Достаточно большой оверхед при передаче данных формы на сервер при каждом серверном вызове (особенно если в форме много данных). И судя по наличию оптимизационной опции &НаСервереБезКонтекста в 1С это понимают. Конечно, можно было бы хранить данные формы на сервере и слать их изменение в обе стороны (а не только в одну), но тогда возникает другой вопрос.
- Почему не реализовать «зеркалирование» данных формы и состояния серверного потока выполнения на другие сервера приложений (как это например делает Java EE) или на сам клиент. Это решило бы проблему масштабируемости и отказоустойчивости, не напрягая при этом разработчика.
- Вероятность падения клиента (по причине пропажи электричества, вируса, обновления windows и сотни других причин) куда выше, чем вероятность падения сервера приложений при его грамотном администрировании. И реально критично только для очень крупных компаний (а так страдают все)
Отказ от синхронности
Если вы думаете, что на этом ваши проблемы с потоками выполнения закончились, вы ошибаетесь. В результате того, что 1С оставил основной поток выполнения на клиенте, появилась еще одна проблема. Для того, чтобы остановить поток выполнения на клиенте и вызвать другой поток выполнения (например, открыть новую форму), на клиенте должна в принципе поддерживаться возможность создания нескольких потоков выполнения (то есть многопоточность). И если в десктоп-клиентах многопоточность с определенными оговорками еще как-то поддерживается, то в браузерах с этим все существенно сложнее. Вся их архитектура построена на однопоточности и одном цикле обработки событий. Поэтому, чтобы, например, показать диалог, 1С приходилось создавать новое окно (вкладку) браузера, что, в свою очередь:
- браузерам не очень нравится (так как они считают это спамом и по умолчанию блокируют)
- создает отдельный процесс в ОС, что не очень хорошо с точки зрения производительности
- блокирует старое окно целиком
В мобильных же браузерах ситуация с новыми вкладками в качестве диалогов еще хуже и это, похоже, стало последней каплей, которая заставила 1С что-то делать по этому поводу.
Что же они сделали? Думаете, попытались сохранить состояние потока выполнения, передать выполнение новому потоку, а по его завершению автоматически восстановить старое состояние? Как бы не так, делать что-то автоматически это, похоже, не их стиль. В 1С опять-таки решили все переложить на разработчика. Причем с весьма издевательским комментарием по этому поводу:
Следует отметить, что поначалу асинхронная модель может показаться сложнее привычной синхронной. На самом деле, понимая основные различия этих моделей, разработка асинхронных приложений становится не многим труднее.
Это подтверждается тем фактом, что все современные веб-приложения построены именно с использованием асинхронной модели и их количество постоянно растет.
Верхом садизма при этом является отсутствие в 1С замыканий и передачи функций в качестве параметров. То есть переменные контекста нужно самому сохранять, например, в какую-нибудь структуру, после чего передавать эту структуру параметром явно созданной и именованной процедуре обработке результата. В итоге получается что-то зубодробительное вроде:
&НаКлиенте
Процедура ВыполнитьОперацию(Команда)
Оп = Новый ОписаниеОповещения("ВыполнитьОперациюЗавершение", ЭтотОбъект);
ПолучитьТекстВыбора(Оп);
КонецПроцедуры
&НаКлиенте
Процедура ВыполнитьОперациюЗавершение(Результат, Параметры) Экспорт
Сообщить(Результат);
КонецПроцедуры
&НаКлиенте
Процедура ПолучитьТекстВыбора(ОбработкаОповещения)
Контекст = Новый Структура("СледующееОповещение", ОбработкаОповещения);
Оп = Новый ОписаниеОповещения("ПолучитьТекстВыбораЗавершение", ЭтотОбъект, Контекст);
ПоказатьВопрос(Оп, "Продолжить операцию?", РежимДиалогаВопрос.ДаНет);
КонецПроцедуры
&НаКлиенте
Процедура ПолучитьТекстВыбораЗавершение(Результат, Контекст) Экспорт
Стр = ?(Результат = КодВозвратаДиалога.Да,
"Продолжаем выполнять операцию...",
"Операция прервана!");
Если Контекст <> Неопределено И Контекст.СледующееОповещение <> Неопределено Тогда
ВыполнитьОбработкуОповещения(Контекст.СледующееОповещение, Стр);
КонецЕсли;
КонецПроцедуры
Отказ от WYSIWYG: разделение интерфейса на запись и чтение
Следующей жертвой гонки за производительностью / масштабируемостью стал WYSIWYG. Здесь, конечно, не совсем правильно говорить о жертве, потому как в ранних версиях 1С его тоже не было, поэтому будем считать WYSIWYG жертвой по сравнению с тем, как в 1С могли бы реализовать свои интерфейсы.
В ранних версиях 1С было всего несколько вариантов работы с данными в списках. К списку можно было привязать:
- Первичные данные: объекты (справочники, документы), их агрегированные объекты (табличные части) и т.д.
- Программно создаваемую таблицу: таблицу значений, читать данные в которую и записывать данные из которой разработчик должен вручную.
Естественно, с таким набором возможностей даже для такой простой задачи, как выдать на форме список товаров с их ценами и остатками, нужно было основательно потрудиться (и это даже без требований нормальной производительности). Поэтому разработчики 1С в последние версии платформы добавили так называемые динамические списки — списки, у которых в качестве источника данных могут быть любые запросы. Вроде бы все красиво, но дьявол, как известно, кроется в деталях:
- С учетом отсутствия оптимизатора запросов, в этих запросах фактически нельзя использовать подзапросы / виртуальные таблицы на дату и / или с условием на источник данных. Дело в том, что в динамическом списке предполагается считывание только видимой части записей (например первых 50), а учитывая, что, как уже отмечалось выше, автоматическое проталкивание условий верхнего запроса внутрь подзапроса 1C не поддерживает, а как протолкнуть эти условия вручную (к чему обратиться для получения видимой части в запросе) — непонятно. То есть, если в качестве запроса динамического списка написать запрос:
ВЫБРАТЬ Товар.МояДата КАК МояДата, Товар.Цена КАК Цена, ДвиженияОстатков.ЧислоОстаток КАК Число ИЗ Справочник.Товар КАК Тов ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.ДвиженияОстатков.Остатки(&Дата, ) КАК ДвиженияОстатков ПО ДвиженияОстатков.Товар = Тов.Ссылка"
то при каждом открытии формы с этим динамическим списком будут рассчитываться остатки на заданную дату для всех (а не только видимых) товаров.
- Но самый главный вопрос — с редактированием динамических списков. В ранних версиях 1С была такая возможность, как редактирование данных в списке, что в общем-то понятно, так как все данные были первичными. С динамическими списками все усложнилось, так как в этом случае, надо из запроса выяснять, какие колонки первичные, а какие — нет. Плюс при выполнении запроса надо автоматически обновлять его результаты с учетом сделанных пользователем изменений.
Что сделали в 1С? Ну вы поняли. Просто запретили (а точнее, не поддержали) редактирование динамических списков. Причем, так как механизм динамических списков стал основным механизмом работы со списками, заодно запретили редактирование и списков с первичными данными (справочниками и документами, то есть то, что работало в предыдущих версиях). Ну и объяснили это в стиле «просто не держите его так». А если очень хочется, то используйте таблицы значений. Правда, чтобы с использованием таблиц значений реализовать функционал динамического списка (с чтением только видимых записей), нужно, мягко говоря, серьезно повозиться.
Как следствие, на практике в 1С есть строгое разделение интерфейса на списки, где идет чтение данных, и на списки, где идет ввод данных (такой анти-WYSIWYG). Особенно наглядно эта разница видна на примере подбора товаров в типовых конфигурациях, где пользователь в одном списке выбирает товары, а во втором вводит количество этих товаров. Впрочем, про это была отдельная статья, поэтому подробно на этой теме останавливаться не будем.
Невозможность обращаться в списках к реквизитам форм / текущим значениям других списков
Эта проблема может показаться менее существенной по сравнению с описанными выше, но, на мой взгляд, ее также не стоит недооценивать. Фактически эта проблема означает, что все списки / объекты на форме в 1С сами по себе, а связывать их друг с другом разработчику необходимо самостоятельно императивным кодом в подписках на различные события.
Так, например, если мы хотим в форме документа показать список договоров поставщика этого документа, нам надо:
- В запрос списка договоров добавить параметр &Поставщик и использовать его для отбора нужных договоров
- Обновлять этот параметр при:
- Открытии формы
- Изменении поставщика в документе пользователем
- Выборе другого документа (например, если на форме отображается список документов)
- При обновлении данных формы (так как поставщик мог быть изменен другим пользователем, а пользователь нажал обновить)
- Открытии формы
И это в самом простом случае. Если условие «соединения данных» на форме сделать еще более сложным, событий и кода их обработки понадобится еще больше.
Соответственно, почему возможность обращаться к другим реквизитам формы (и автоматически обновлять динамические списки при их изменении) не поддержали непосредственно на уровне платформы — еще одна из загадок 1С (хотя, возможно, я просто не нашел такую возможность).
Собственно, исходя из всего вышесказанного, неудивительно почему большинство форм в 1С достаточно примитивны и состоят в лучшем случае из одного списка, причем зачастую только с первичными данными. Конечно, в типовых решениях с их неограниченными бюджетами на разработку все немного получше, но в отраслевых и решениях, разработанных с нуля, пользователей, как правило, не сильно балуют множеством информации на форме и удобством работы с ней.
Избыточные уровни абстракций
Когда я начинал изучать 1С, я все не мог избавиться от мысли, что в 1С есть отдельная система поощрения для тех, кто придумает какое-то новое понятие. Там, где вроде можно было немного отрефакторить и обойтись меньшим числом абстракций, в 1С создают все новые и новые уровни, как будто специально усложняя разработку. И когда видишь вот такую картинку:
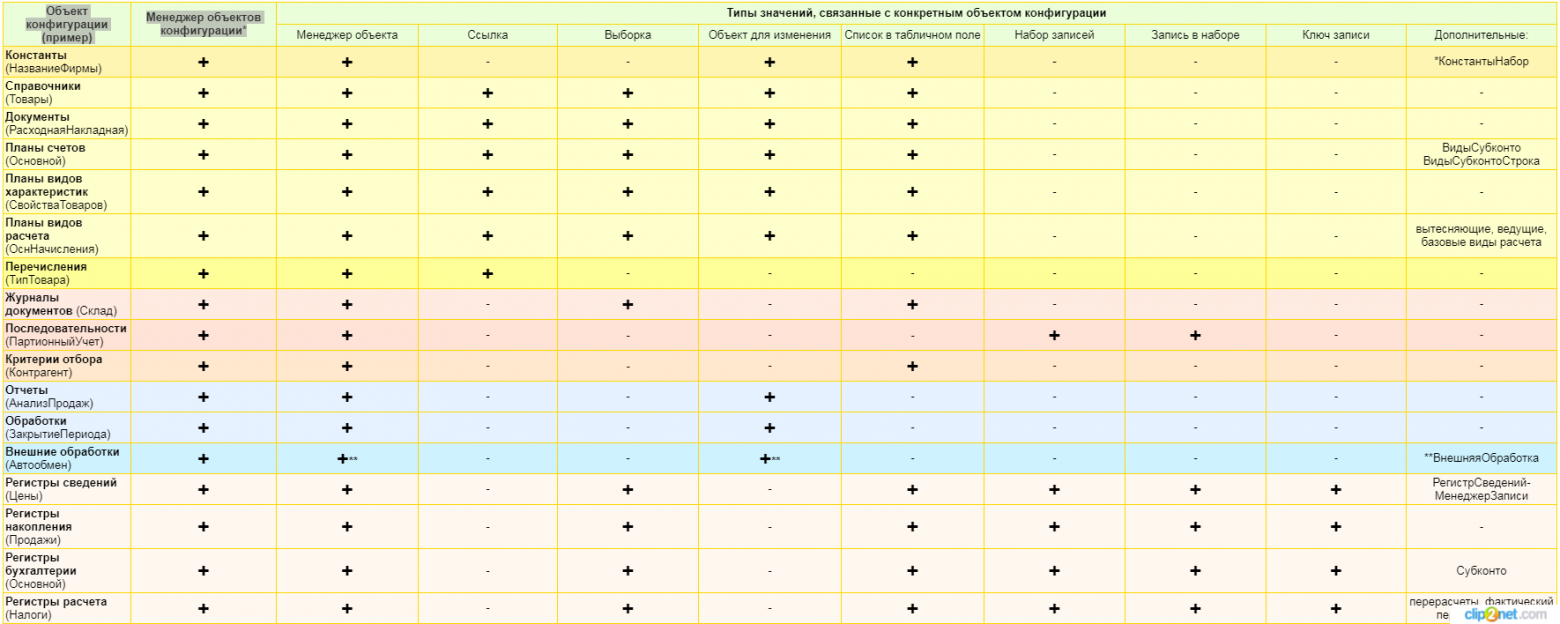
Первая мысль: кто все эти люди? Впоследствии, конечно, когда со всеми этими понятиями познакомишься немного поближе, эта картинка уже не выглядит настолько пугающе, но все равно не покидает ощущение, что многие вещи в 1С, на мой взгляд, явно лишние.
- Объекты / записи
Это разделение уже упоминалось в разделе про ORM. Причем тут вопрос не к понятию объект, как таковому (это понятие есть везде), а в том, что в 1С объекты, как и записи (регистры), также отвечают за хранение данных. Собственно, верхняя картинка и получается настолько большой и сложной по причине того, что 1С пытается усидеть сразу на двух стульях.
- Объекты / ссылки на объекты
Очень странное разделение, которое поначалу сильно сбивает с толку. Я сначала думал, что это своего рода аналог ссылок / объектов в C#, C++. Но это не так. Фактически ключевое отличие этих двух понятий заключается в том, что объекты используются для записи и чтения, а ссылки — только для чтения. Конечно физически там больше нюансов — при обращении по ссылке объект читается неявно и сохраняется в кэше на какое-то время (разработчик этим никак не управляет), а чтением объекта (и остальным циклом его жизни) управляет разработчик. Но логически разницы никакой, и ни в какой другой технологии (что ORM, что не ORM) такого разделения нет.
- Данные формы / Данные объектов
Это разделение является следствием борьбы за масштабируемость (разделения логики на сервер и клиент) с одной стороны, и дублирования логики данных в объектах и записях с другой. То есть 1С нужно было поддержать что-то среднее, что решало бы проблемы сериализации данных на клиента и при этом подводило бы объекты (справочники, документы) и записи (регистры, запросы) под общий знаменатель. Соответственно для этого в 1С и отделили данные формы от просто данных, но при этом в попытках сделать это разделение менее явным создали ряд очень странных абстракций. Например, класс в скобочках. Который выглядит как класс, крякает как класс, но не класс (например методы этого класса вызывать нельзя). А чтобы сделать из него настоящий класс, нужно использовать специальную процедуру РеквизитФормыВЗначение (ну и соответственно ДанныеФормыВЗначение в обратную сторону).
И если с данными формы такое разделение было во многом вынужденным, то зачем понадобилось разделять команды формы и действия, я, если честно, не совсем понял. Может в комментариях кто-нибудь сможет это объяснить.
В любом случае с управляемыми формами разработчики 1С явно перемудрили, все можно было сделать гораздо проще. Правда, скорее всего избавившись от первоначальных проблем (то есть разделения логики на сервер и клиент, и на объекты и записи).
- Запросы / СКД / Аналитика (BI)
Обычно бизнес-приложения принято разделять на два контура: OLTP и OLAP. В первом люди работают по более-менее конкретным бизнес-процессам: получают и вводят одну и ту же информацию и нажимают на одни и те же кнопки в одних и тех же доступных им формах. OLAP — творческий контур, в нем пользователи обычно «играют» с информацией, получая эту информацию в различных заранее неизвестных срезах. В OLTP люди обычно принимают оперативные решения и отражают уже произошедшие события, OLAP же используется для принятия стратегических решений. Понятно, что в жизни есть полутона, когда пользователю и в OLTP нужна какая-то гибкость, но как правило она ограничивается простыми отборами, сортировками и выбором / изменением размеров колонок, так как бОльшая гибкость будет, во-первых, слишком сложна для пользователя (многим даже отборы с трудом даются), а во-вторых, необходимость этой гибкости говорит о несовершенстве бизнес-процессов и если один более продвинутый пользователь догадается это несовершенство побороть, то второй пользователь так и будет продолжать работать неэффективно. Плюс надо понимать, что при сильном изменении структуры информации формы часто требуется изменение физической модели, например, материализация промежуточной информации (как это обычно делается в OLAP), что с одной стороны позволяет не нагружать оперативную базу долгими запросами, а с другой стороны позволяет пользователю получать информацию за секунды.
Для OLAP есть большое количество уже готовых решений, которые умеют забирать данные из существующих SQL баз через веб-сервисы и многими другими способами, после чего агрегировать их и давать пользователю максимально быстрые и эргономичные интерфейсы по работе с этими данными. И самым логичным решением для любой платформы было бы максимально упростить интеграцию с такими инструментами.
Но в 1С решили сделать не как все. Они реализовали так называемую систему компоновки данных (СКД) с очень непонятной областью применения:
- Как инструмент разработки печатных форм он слишком сложный (по сравнению с классическими системами отчетности)
- Как инструмент аналитики (где пользователь сам настраивает группировки, колонки) он по эргономике и производительности значительно уступает существующим BI инструментам
- Как интерактивный интерфейс, то есть замена формам, СКД также плохо подходит, так как не умеет и половину того, что умеют формы
- Как программный инструмент доступа к данным он слишком громоздкий и тяжело читается, когда используется в коде
В общем получился какой-то франкенштейн, который при этом по функционалу пересекается с половиной других абстракций в 1С. В которые (например, формы) они еще и попытались интегрировать этот СКД. В результате понять что, где, когда и как нужно использовать — задача весьма неочевидная.
- Как инструмент разработки печатных форм он слишком сложный (по сравнению с классическими системами отчетности)
Закрытая физическая модель
В этом вопросе у 1С похоже какая-то принципиальная позиция. Что им мешает дать возможность разработчику самому задавать имена таблиц и полей, я до сих пор не понимаю. Да, местами возникнут вопросы, например, с составными типами реквизитов (где они, насколько я помню, в определенных случаях создают три колонки в базе), с тем, что имена всех метаданных на русском (хотя большинство СУБД позволяют создавать таблицы и поля на русском) и так далее, но все эти проблемы решаемы.
Открытая же физическая модель дала бы огромное количество возможностей: от простой интеграции на чтение со стороны тех же OLAP систем до возможности использования встроенных средств СУБД, таких как рекомендация построения индексов, профилировщиков и так далее (без необходимости гадания, что же это за поля и таблицы — _Fld16719 и _Document5759).
Но 1С не то что решили не открывать физическую модель, а наоборот, лицензионно запретили лезть разработчикам в базу без явного на то разрешение со стороны самой 1С.
Отсутствие наследования и полиморфизма
Тема, о которую сломано много копий. За это часто критикуют 1С, но тут надо понимать, что так как 1С в какой-то момент для производительности решил перейти на голый SQL, а даже в самом SQL наследование и полиморфизм не реализовали, требовать реализацию этих механизмов от 1С достаточно наивно.
Ну и, конечно, с аргументом «покажите, что можно реализовать с наследованием и полиморфизмом, чего нельзя реализовать с помощью if'ов» тяжело спорить. Но к чему приводит отсутствие наследования, как раз хорошо иллюстрируют типовые 1С, где для того, чтобы поддержать некую общую логику, скажем для всех строк документов:
- Делают общую процедуру ОбработатьСтрокуТЧ, которая должна вызываться для всех строк документов (кстати одно из немногих мест, где используется ORM, а не запросы)
- Внутри этой процедуры пишут реализации всех существующих классов строк документов:
Процедура ОбработатьСтрокуТЧПроцедура ОбработатьСтрокуТЧ(ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения) Экспорт Если КэшированныеЗначения = Неопределено Тогда КэшированныеЗначения = ОбработкаТабличнойЧастиКлиентСервер.ПолучитьСтруктуруКэшируемыеЗначения(); КонецЕсли; ПроверитьАссортиментСтроки( ТекущаяСтрока, СтруктураДействий); ЗаполнитьНоменклатуруПоНоменклатуреПоставщикаВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьНоменклатуруПоставщикаПоНоменклатуреВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПроверитьСопоставленнуюНоменклатуруПоставщикаВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьСлужебныеРеквизитыПоНоменклатуреВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПроверитьКорректностьЗаполнитьХарактеристикиИУпаковки( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПроверитьКорректностьЗаполнитьХарактеристикиКиЗ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоНеОтгружатьСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ЗаполнитьGTINВСтроке( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоУпаковокПоФактуВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоУпаковокСуффиксИзОтклоненияВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоЕдиницВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоЕдиницСуффиксВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоУпаковокВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоУпаковокСуффиксВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоОтклонение( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоУпаковокПоВесу( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьКоличествоУпаковокПоОбъему( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьВесОбъемВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьЦенуЗаУпаковкуВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьЦенуЗаказаЗаУпаковкуВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьВидЦеныВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ЗаполнитьЦенуПродажиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьЦенуПродажиПоАссортиментуВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьЦенуЗакупкиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьУсловияПродажВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьУсловияЗакупокВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ЗаполнитьПартиюТМЦВЭксплуатации( ТекущаяСтрока, СтруктураДействий); ЗаполнитьСтавкуНДСВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьСтавкуНДСПоНоменклатуреВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ПересчитатьЦенуСНДС( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьСтавкуНДСВозвратнойТарыВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуРучнойСкидкиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуАвтоматическойСкидкиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьПроцентРучнойСкидкиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуВСтрокеТЧРасхождения( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьЦенуСкидкуПоСуммеВПродажахВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьЦенуСкидкуПоСуммеВЗакупкахВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьЦенуПоСуммеВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПересчитатьСуммуПродажиПоСуммеСНДС( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьЦенуПродажиПоСуммеПродажиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуСУчетомАвтоматическойСкидкиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуСУчетомРучнойСкидкиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуСУчетомСкидкиБонуснымиБалламиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПересчитатьСуммуСУчетомПогрешностиОкругленияВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПересчитатьСуммуНДСВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуСНДСВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуБезНДСВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуРеглВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьНДСРеглВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуПродажиВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуПродажиНДСВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьРеквизитыПоНоменклатуреВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПроверитьСтатьюАналитикуРасходов( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ОчиститьСуммуВознагражденияВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.УстановитьАктивностьСтроки( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПроверитьЗаполнитьСкладВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПроверитьЗаполнитьОбеспечениеВСтрокеТЧДокументаПродажи( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПроверитьЗаполнитьОбеспечениеВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ПроверитьПолучитьВариантКомплектации( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьФлагиРасхождениеИИзлишекПорча( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ОчиститьСуммуВзаиморасчетовВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ОчиститьАвтоматическуюСкидкуВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий); ЗаполнитьСодержаниеУслуги( ТекущаяСтрока, СтруктураДействий); ЗаполнитьСтатьюАналитикуРасходовПоУмолчанию( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьПартнера( ТекущаяСтрока, СтруктураДействий); ЗаполнитьПомещение( ТекущаяСтрока, СтруктураДействий); ЗаполнитьПродавца( ТекущаяСтрока, СтруктураДействий); ЗаполнитьУчетноеКоличествоНоменклатуры( ТекущаяСтрока, СтруктураДействий); ЗаполнитьПризнакНаличияНоменклатурыПродаваемойСовместно( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьПризнакБезВозвратнойТары( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьПризнакОтмененоБезВозвратнойТары( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьПризнакАктивностьБезВозвратнойТары( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьДубликатыЗависимыхРеквизитов( ТекущаяСтрока, СтруктураДействий); ПроверитьСериюРассчитатьСтатус( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ПересчитатьСуммуСверхЗаказаВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); УстановитьПризнакДляЗаполненияТекстовогоОписания( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьВариантОтраженияКорректировкиРеализации( ТекущаяСтрока, СтруктураДействий); ЗаполнитьВариантОбеспеченияПоДатеОтгрузки( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.НоменклатураПриИзмененииПереопределяемый( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ХарактеристикаПриИзмененииПереопределяемый( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьПризнакПринимаетсяКНУ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьПризнакАналитикаРасходовОбязательна( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьПризнакРаспределениеНДС( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьПризнакАналитикаДоходовОбязательна( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьПризнакАналитикаАктивовПассивовНеИспользуется( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьПризнакАналитикаРасходовЗаказРеализация( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьТипСтатьи( ТекущаяСтрока, СтруктураДействий); ЗаполнитьПризнакАдресногоХранения( ТекущаяСтрока, СтруктураДействий); ЗаполнитьПризнакИспользованияПомещений( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьПризнакиКатегорииЭксплуатации( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьРасхожденияПослеОтгрузки( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьРасхожденияПослеПриемки( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьРасхождения( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьПризнакНаличияКомментарияПриемка( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьПризнакНаличияКомментарияОтгрузка( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьПризнакНаличияКомментария( ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ЗаполнитьПризнакТоварногоМестаТребуетсяОбработка( ТекущаяСтрока, СтруктураДействий); ЗаполнитьПризнакДвиженияПоСкладскимРегистрам(ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ПриИзмененииТипаНоменклатурыИлиВариантаОбеспечения(ТекущаяСтрока, СтруктураДействий); ОбработкаТабличнойЧастиКлиентСервер.ПроверитьЗаполнитьНазначениеВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ОбработкаТабличнойЧастиКлиентСервер.ПриИзмененииНазначенияВСтрокеТЧ( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); ЗаполнитьНоменклатуруЕГАИС( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); АкцизныеМаркиКлиентСервер.ЗаполнитьИндексАкцизнойМаркиДляСтрокиТабличнойЧасти( ТекущаяСтрока, СтруктураДействий); ЗаполнитьСтрануПроисхожденияДляНомераГТД( ТекущаяСтрока, СтруктураДействий); ЗаполнитьСпособОпределенияСебестоимости( ТекущаяСтрока, СтруктураДействий); ЗаполнитьСпособОпределенияСебестоимостиСтрокой( ТекущаяСтрока, СтруктураДействий); ПоместитьОбработанныеСтрокиВКэшированныеЗначения( ТекущаяСтрока, СтруктураДействий, КэшированныеЗначения); КонецПроцедуры
- Внутри каждой реализации проверка на наличие поля (которое по сути и является признаком принадлежности классу строки документа):
Процедура ЗаполнитьПризнакНаличияКомментарияПриемка(ТекущаяСтрока, СтруктураДействий) Экспорт Если НЕ СтруктураДействий.Свойство("ПризнакНаличиеКомментарияПриемка") Тогда Возврат; КонецЕсли; ТекущаяСтрока.ЕстьКомментарийПоставщика = НЕ ПустаяСтрока(ТекущаяСтрока.КомментарийПоставщика); ТекущаяСтрока.ЕстьКомментарийМенеджера = НЕ ПустаяСтрока(ТекущаяСтрока.КомментарийМенеджера); КонецПроцедуры
P.S.: Как могли бы выглядеть наследование и полиморфизм в 1С разбиралось в недавней статье, поэтому подробно на этой теме здесь также останавливаться не будем.
Отсутствие явной типизации в коде
С явной типизацией в 1С все не так однозначно. Частично она есть — при создании любого реквизита можно и нужно указать его тип (класс). Конечно, тут возникает вопрос, что делать если значение реквизита может быть не одного типа (а наследование, как мы помним, в 1С отсутствует). Для таких случаев в 1С поддерживаются так называемые составные типы, когда в качестве типа можно указать не один, а сразу несколько типов. Эффективность реализации этих составных типов, конечно, оставляет желать лучшего:
Рекомендации по использованию составных типов
- Используйте поля составных типов только тогда, когда это является оправданным с точки зрения логики функционирования конфигурации.
- Не используйте составные типы, кроме ссылочных, для полей, по которым связываются таблицы. Например, если в документах «ПриходнаяНакладная» и «РасходнаяНакладная» есть реквизит «Контракт» составного типа, то исполнение следующего запроса может быть неэффективным:
ВЫБРАТЬ ПриходнаяНакладная.Контракт ИЗ Документ.ПриходнаяНакладная КАК ПриходнаяНакладная ЛЕВОЕ СОЕДИНЕНИЕ Документ.РасходнаяНакладная КАК РасходнаяНакладная ПО ПриходнаяНакладная.Контракт = РасходнаяНакладная.Контракт
- Избегайте выполнения операций поиска и отбора по значениям полей составных типов, кроме ссылочных.
- Не определяйте полей составных типов, кроме ссылочных, в таблицах с потенциально очень большим количеством записей.
- Избегайте использования в регистрах измерений составных типов, кроме ссылочных.
- Используйте индексирование по полям составных типов только после тщательного анализа этого решения с точки зрения необходимости и потерь производительности.
Другими словами, не рекомендуется использовать никогда (ключевой момент тут на самом деле в неэффективном сравнении полей с разным количеством типов). Но как говорится: «На безрыбье и рак — рыба».
В любом случае это все касается только реквизитов (а также ресурсов, измерений и т.п.). С кодом же ситуация куда печальнее. Типов переменных нет, и какие у данной переменной есть поля и методы, можно только гадать. И если внутри одной процедуры IDE (Конфигуратор) еще как-то может вывести тип переменной, то как только эта переменная передается в другую процедуру, вся информация о ней теряется, а с ней теряется и подсветка ошибок, автоподстановка и прочие радости жизни разработчика.
Конечно, существует значительное количество языков, которые также как и 1С обходятся без явной типизации. Но на больших проектах со сложной логикой, которыми являются современные бизнес-приложения, разобраться, для чего нужен данный кусок кода и что именно в нем происходит, когда у каждой переменной не известен ее класс, на порядок сложнее.
Отсутствие модульности
Как по идее должно выглядеть идеальное бизнес-решение в идеальном мире. Есть большой набор (а точнее граф) готовых модулей с различным функционалом, из которых заказчик может, как из кубиков, собрать решение, которое надо именно ему (с учетом специфики его бизнеса), а если каких-то кубиков не хватает, разработать их уже лично для себя. Возможность такой декомпозиции информационной системы обычно принято называть модульностью.
Частично решить проблему модульности в 1С попытались при помощи так называемого механизма расширений. Но, во-первых, сам этот механизм, больше адаптирован под кастомизацию, а не под модульную разработку. Так, если модулей будет достаточно много (несколько сотен), работать с ними в текущих интерфейсах 1С будет крайне неудобно. Собственно, в самом 1С это понимают:
Есть соблазн использовать расширения для создания тиражных прикладных решений, однако делать этого не стоит. Во-первых, потому, что расширения не проектировались под такие задачи. А во-вторых, потому, что другие механизмы платформы, например механизмы поставки и поддержки, ничего не знают о расширениях.
…
Мы анализировали все эти задачи и пришли к выводу, что наиболее приоритетной на данный момент является адаптация конфигураций к пожеланиям пользователей во время внедрений.
Во-вторых, одних только расширений для обеспечения модульности недостаточно — нужны еще:
- расширения запросов, которые, как мы помним, в 1С как правило задаются обычными строками (а при помощи запросов реализуется бОльшая часть бизнес-логики)
- события изменения данных, которые формально существуют, но в них либо возникает проблема N+1, либо логика в них также описывается запросами, а значит смотри предыдущий пункт. Плюс в 1С есть только события изменения первичных данных, события изменения вычисляемых данных (например, регистров), как мы видели выше, в 1С не поддерживаются.
- наследование и полиморфизм, которых, как мы уже выяснили, в 1С также нет
- агрегации, которые нужны, когда наследования недостаточно
Но в целом инициатива с расширениями, конечно, правильная, хотя на текущем этапе до реальной модульности 1С еще ой как далеко. И последние версии типовых решений — это по прежнему один большой монолит. Причем по мере роста сложности этих решений возникает следующая парадоксальная ситуация:
- Чем сложнее решение, тем сложнее его дорабатывать (особенно с учетом плохой модульности, а значит сильной связности кода)
- Чем сложнее решение, тем с меньшей вероятностью оно подойдет под существующие на предприятии бизнес-процессы (а значит это решение придется дорабатывать)
Как следствие, в последних версиях 1С постепенно приобретает «болезнь SAP» — на любое пожелание заказчика, ему говорится: «вы просто неправильно работаете, есть best practice, вы тоже должны работать именно так». И не важно, что бизнес по торговле автомобильными запчастями отличается от бизнеса по торговле нефтью чуть менее, чем полностью (если конечно речь не идет об автоматизации уровня «пришло-ушло-осталось»). А именно максимальная гибкость и свои ноу-хау позволяет малому и среднему бизнесу противостоять крупным корпорациям в борьбе за рынок. Нет — все должны работать одинаково. Да, конечно, в монолите часто делают миллионы настроек, но:
- гибкость таких настроек по определению сильно ограничена (обычно это не более, чем просто включение / выключение различных сценариев)
- они сильно перегружают интерфейс (когда пользователю приходится работать по инструкции: зайдите на третью вкладку, включите пятую галочку, заполните десятое поле)
- они не в состоянии полностью исключить избыточное потребление ресурсов. То есть настройка может быть выключена, но поля в таблицах в базе все равно будут (а значит будут потреблять лишнее место, попадать в кэши СУБД), часть общего кода все равно будет выполняться и так далее.
Ставка на визуальное программирование
Тема с визуальным программированием, а точнее low-code / no-code платформами то и дело всплывает то тут, то там с завидной регулярностью. Позиционируют себя эти платформы, как средства ускоряющие / упрощающие разработку. При этом почему программирование мышкой по их мнению должно быть априори эффективнее программирования клавиатурой — непонятно. Разработку действительно можно ускорить / упростить повышением уровня абстракций, но никак не способом ввода этих абстракций в систему. Одна строка кода в этом смысле лучше, чем пять кликов / перетаскиваний мышкой, не говоря уже о том, что скорость работы с клавиатурой у опытного разработчика как правило выше, чем скорость работы с мышкой. Поэтому утверждения «ну раз код писать не надо, то и разработчик не нужен» не более, чем маркетинговая уловка.
Но попробуем взвесить все за и против обоих подходов (Все-в-виде-кода vs Визуальное программирование). Итак, преимущества всего в виде кода:
- Система контроля версий — поддержка gitflow из коробки (например возможность выполнения операций слияния веток и разрешения конфликтов при этом слиянии)
- Метапрограммирование / кодогенерация — возможность использовать макросы и / или механизмы шаблонов в IDE
- Копирование — можно взять любой кусок кода, клонировать его, а затем, если нужно «тоже самое, но с перламутровыми пуговицами» групповым изменением, например, поменять в клонированном коде одно слово на другое
- Редактирование — код можно просмотреть в любом текстовом редакторе, переслать через мессенджер, разместить на форуме и т.п.
- Унифицированность — для кода есть готовая инфраструктура и стандарты работы с ним в IDE (например стандартные действия по переходу к объявлению, поиск использований, установка брейкпоинтов и т.п.). То есть разработчик работая с любым языком по умолчанию знает все интерфейсы работы с любым элементом этого языка.
- Отладка — любой элемент можно легко идентифицировать по файлу и номеру строки в коде
- Лаконичность — в коде видно только то, что было изменено / реально используется, в отличие от визуального программирования, где разработчику информация вываливается вся сразу:
Пример визуальной настройки
- Ниже порог вхождения. Но это не точно.
- Удобнее задавать пользовательские интерфейсы с абсолютным позиционированием. Актуально только для печатных форм, так как в вебе, который сейчас практически везде, такое позиционирование не используется.
Конечно противопоставлять эти два подхода тоже не всегда правильно. Так визуальное программирование можно использовать для генерации кода, то есть в режиме конструктора. Но в таком режиме предполагается, что код первичен и разработчик должен уметь одинаково хорошо пользоваться как «текстовым», так и «графическим» интерфейсом разработки. А в таких случаях, как показывает мировой опыт, он просто отказывается от «графического» интерфейса, так как «текстовым» интерфейсом разработчику все равно придется пользоваться гораздо чаще, а зачем ему два механизма? Поэтому в современных технологиях использование конструкторов, как правило, сведено к минимуму.
Но вернемся к 1С. Судя по тому, что основную ставку 1С решили сделать на EDT, там все вышесказанное тоже отлично понимают и поэтому старательно пытаются исправить «ошибки прошлого». Но так как платформа у них принципиально не language-based, в 1С решили сделать это, преобразовав все свои прикладные абстракции не в свой язык, а в XML. Выглядит это конечно на любителя. Мало того что язык XML сам по себе достаточно громоздкий, так они еще:
- выгружают туда значения всех свойств (в том числе тех, которые не изменялись). В результате структура примитивного документа (без кода вообще) занимает 1336 строк.
- часто используют сгенерированные id, которые, конечно, с одной стороны помогают решить проблемы с миграцией, но с другой стороны требуют при написании кода дополнительные инструменты для их генерации.
Соответственно просматривать / редактировать такой код руками — так себе удовольствие. Поэтому ни о каких преимуществах подхода Все-в-виде-кода, в том виде в котором он реализован в 1С, к сожалению говорить не приходится. То есть, как говорится, хотели как лучше, а получилось как всегда.
Фатальный недостаток
Шутка про фатальный недостаток, пришедшая из Microsoft в 1С, заиграла новыми красками. Попробуем пересчитать все то, что 1С написали сами, и аналоги чего уже существуют и используются во всем мире:
- IDE — IDEA, Eclipse, Microsoft Visual Studio / VSCode используются повсеместно и имеют достаточно развитую инфраструктуру для написания сторонних плагинов. Конфигуратор по сравнению с той же IDEA играет не то что в другой лиге, а можно сказать в другой вид спорта.
- Систему контроля версий — тут git победил всех, хотя subversion и mercurial тоже местами держатся. Ну а механизму системы контроля версий в 1С до git, мягко говоря, очень далеко.
- СУБД — тут они хотели скорее всего упростить процесс развертывания среды разработки / выполнения, но реализовать СУБД даже на уровне PostgreSQL, задача не самая простая. И, как мы видели в разделе Запросы, 1С реализовал свою СУБД где-то на уровне SQL-92 и тем самым выстрелили себе в ногу, сделав невозможным использование даже базовых возможностей нормальных СУБД.
Ну и конечно своя сборка PostgreSQL, когда можно было обойтись правильным его использованием (судя по списку изменений, которые 1С там сделал), это конечно за гранью. Очень напоминает старый анекдот.
- Систему отчетности — в мире таких систем тоже огромное количество, но тут особенность в том, что они все используются только для формирования печатных форм. В 1С отчеты еще зачем-то пытаются выполнять функции обычных форм (то есть обладают интерактивностью) и BI. Так что если бы даже в 1С попытались воспользоваться готовыми системами отчетности, у них все равно не получилось бы это сделать.
- Язык — со своим языком в 1С вообще непонятно. Ладно еще то, что ключевые слова в нем могут быть на русском, есть расхожее мнение, что это понижает порог вхождения, так как много русскоязычных жителей не знают английский (хотя китайцам это не мешает почему-то). Но у них же платформа не language-based (как, например, SAP или SQL, где все их возможности в языке), а значит и смысл своего языка теряется практически полностью. То есть никаких преимущества от наличия своего языка 1С не получает, а вот все недостатки присутствуют в полном объеме. Как в той шутке: «я сегодня таксиста обманул, заплатил, а не поехал». Плюс 1С по какой-то непонятной логике держит свой язык на максимально примитивном уровне. Видимо, они считают, что явная типизация, наследование или замыкания / лямбды — это слишком сложно для разработчика, а ручные блокировки, директивы компиляции, callback'и на клиенте и тонны своих сложных дублирующих друг друга абстракций — вполне нормально.
- Системы сборки / управления зависимости — у систем сборки лидеры наверное Jenkins и TeamCity, для управлений зависимости у каждого языка свой лидер у Java — Maven, Gradle, у JavaScript — npm, у Python — pip и т.д. У всех них есть большие community, центральные репозитории библиотек, поддержка версионности из коробки, поддержка со стороны многочисленных IDE и куча чего еще. Но для экосистемы 1С это все опять-таки, видимо, слишком сложно, поэтому у них все свое, что по уровню, конечно, и близко не дотягивает до текущих лидеров на рынке.
- UI фреймворки. Тут я досконально не изучал их внутренности, но факт того, как мучительно долго они добавляли поддержку Linux, а потом MacOS (хотя при условии использования той же Java они получили бы все это практически из коробки), говорит о том, что удержаться от соблазна «изобрести свой велосипед с квадратными колесами» и в этом случае они скорее всего не смогли.
Стоит отметить, что тупиковость первых двух веток в самом 1С также отлично понимают, и поэтому уже лет пять пишут свой плагин под Eclipse. Правда, судя по отзывам, делают это они с переменным успехом, потому как обеспечить нормальную производительность на кодовой базе даже УТ (не говоря уже про ERP) не так то просто. Особенно с учетом того, что не факт, что в том же Eclipse есть инфраструктура stub индексов, ленивого парсинга (chameleon токенов), language injection и т.п., как в той же IDEA (если же в Eclipse это все есть, то непонятно, что можно разрабатывать такое количество времени и не сделать EDT основным инструментом разработки).
В любом случае, с EDT 1С кроме всего вышеперечисленного нужно поддерживать и разрабатывать еще одну IDE. Поэтому неудивительно, что в последнее время они начали действовать по принципу «нужно больше золота». Страшно представить, что будет, если Eclipse совсем умрет под натиском IDEA, и в 1С решат написать еще одну IDE.
Неуважительные по отношению к разработчикам лицензирование и брендирование
У 1С конечно очень своеобразная политика лицензирования. Например: 1С: Предприятие 8. Управление торговлей стоит 22 600 рублей. На неограниченное число пользователей (!). В чем спросите вы подвох? А он в том, что основная стоимость в платформе: 1С: Предприятие 8 ПРОФ. Клиентская лицензия на 100 рабочих мест — 360 000. 1С: Предприятие 8.3 ПРОФ. Лицензия на сервер — 86 400. И тут важны не конкретные цифры, а то, что решение стоит на порядок (!) дешевле платформы. Платформы, в которой, как мы выяснили, разработчику приходится делать практически все самому вручную. И если я вдруг решу написать свое решение и продавать его серийно, мне придется конкурировать с решением за 22 600 рублей. А это не так просто с учетом следующей проблемы.
1С не только лицензирует, но и брендирует все свои решения, как будто самое главное — это 1С как платформа, а решения (которые они брезгливо называют конфигурациями) это так — люди мышкой понатыкали. Поэтому люди, не разбирающиеся в IT, часто говорят: «мы смотрим / купили 1С». Ты у них спрашиваешь, какое именно решение, а они смотрят на тебя как на идиота с немым вопросом в глазах: что мне непонятно, я же сказал — 1С. И такой подход в брендировании — это палка о двух концах. Да, с одной стороны разработчикам так действительно проще продавать свое решение, так как уже есть готовый поток лидов, синергия с продажей других продуктов (например бухгалтерии) и так далее. Но с другой стороны:
- Если для клиента все 1С разработчики на одно лицо, возникают ситуации, когда, например, вы разработали что-то крутое для конкретной отрасли и продаете по цене в соответствии с затратами, которые вы понесли (а рынок для конкретной отрасли узкий по определению). А вам клиент при продаже говорит: «так мне ваши конкуренты за 20к рублей 1С предлагают, вы меня обмануть хотите?». И реально покупает какое-нибудь УТ, а потом мучается с ним, потому как признавать свои ошибки люди не очень любят (а за внедрение и доработки уже заплачено).
- Как мы видели выше, при разработке / доработке решений на 1С способов выстрелить себе в ногу огромное количество (указать условие не в параметрах виртуальной таблицы, а в блоке ГДЕ, использовать подзапрос в динамическом списке и т.п.). И клиенту, купившему решение на 1С, при доработке которого какой-нибудь не самый грамотный разработчик изрядно накосячил, потом очень тяжело объяснить, что это не «1С тормозит», а тормозит конкретное решение на 1С.
Понятно, что уровень IT-грамотности в бизнесе постепенно растет. Люди учатся отличать платформы от решений и уделять больше внимания компаниям, у которых они покупают решение, а не самим решениям. Но 1С своей политикой сам очень сильно препятствует этому процессу, и разработчикам на 1С это должно быть как минимум обидно. Хотя, возможно, у людей, привыкших к платной документации, пониженный болевой порог.
Заключение
Итак, подводя итог, посчитаем, от чего 1С отказались:
- ORM
- SQL:
- Расширенных возможностей
- Оптимизатора
- Блокировок
- Расширенных возможностей
- Единого control flow
- Единой логики работы с данными на форме
- Синхронности
- WYSIWYG
Полагаю, такими темпами они в следующих версиях откажутся от условных переходов и перейдут на goto. И назовут их управляемыми переходами. Кстати, с этой «управляемостью» у них весьма оригинальная манипуляция получилась. По хорошему управляемые приложение, формы и блокировки должны были бы называться ручными, но тогда это звучало бы как недостаток. А так они назвали их управляемыми и вуаля — теперь это возможность. Почему, например, производители машин с ручной коробкой передач до такого трюка до сих пор не додумались — непонятно.
Конечно, некоторые скажут, что отказ от всех вышеперечисленных вещей — это неизбежное зло, необходимое для обеспечения масштабируемости. И если бы я не знал, что это неправда, то не писал бы эту статью. Но, например, в том же lsFusion всех описанных разделений, ограничений и других проблем нет, а при этом он спокойно работает с терабайтными базами, тысячами одновременных пользователей и очень непростым функционалом. Плюс все это дело крутится на весьма бюджетных серверах и с использованием бесплатных СУБД и ОС.
Но ладно, что разработчики 1С отказываются от возможностей, свойственных высокоуровневым платформам, так они при этом и возможности языков общего назначения (такие, как явная типизация, наследование и лямбды) не добавляют. То есть берут самое худшее от обоих подходов, оставляя за бортом самое лучшее. Гениально, я считаю. И как со всем этим они собираются выходить на англоязычный рынок, где у них не будет их двух главных преимуществ: армии разработчиков и поддержки местного законодательства в типовых решениях, для меня загадка. Благо на рынке IT деньги решают далеко не все, иначе в мире (в том числе и в России) ничего кроме Oracle, SAP и Microsoft не существовало бы.
Понятно, что самому 1С на качество платформы в общем-то наплевать. У них такие бюджеты на разработку типовых решений, что они могут их хоть на ассемблере писать. Конечно, дорабатывать такие решения — занятие не самое простое и приятное, но, как говорится, «проблемы индейцев шерифа не волнуют». А вот зачем 1С в качестве платформы разработки выбирают разработчики отраслевых решений, а также ИТ-директора для создания решений внутренней автоматизации (так называемые «самописки») — это, конечно, загадка. Черт с ним с lsFusion, он только пару месяцев назад на рынок вышел, но любая из связок .Net+MSSQL или Python+PostgreSQL будет уж точно не хуже. При этом не надо будет мучаться с ключами защиты, и платить лицензии за платформу, которая местами не то что не помогает, а наоборот мешает. Все ради одной реально полезной абстракции — регистры (которая легко реализуется как средствами СУБД, так и средствами того же .Net) и сомнительной пользы визуального программирования? Причем с конечными клиентами все более-менее понятно: на постсоветском пространстве для многих из них покупка программы — это приблизительно тоже самое, что и покупка мебели в офис. Но решение о создании отраслевых решений и самописок принимают люди с большим опытом в IT. Они-то чем думают? Впрочем, как говорил Эйнштейн, есть две бесконечные вещи, и ими, видимо, все и объясняется.
В конце статьи хотелось бы обратиться к разработчикам Axapta и SAP. Дело в том, что мы сейчас готовим материалы для выхода на англоязычный рынок (где про 1С никто и не знает), поэтому нам желательно знать, как со всеми вышеперечисленными проблемами дела обстоят у местных, не скажу что лидеров, но, скажем так, самых известных продуктов на рынке. Соответственно, если кому не лень, просьба поделиться этой информацией в комментариях. Мы, конечно, изучим все эти продукты, насколько это возможно, самостоятельно, но хотелось бы узнать необходимую нам информацию, так сказать, из первых рук (а найти специалистов по Axapta и SAP на постсоветском пространстве гораздо тяжелее, чем по 1С).
UPD: Статья с описанием того, как все вышесказанные проблемы решаются в lsFusion.
