
В этой статье мы поговорим об ошибках, совершаемых программистами на Bash. Во всех приведённых примерах есть какие-то изъяны. Вам удастся избежать многих из нижеописанных ошибок, если вы всегда будете использовать кавычки и никогда не будете использовать разбиение на слова (wordsplitting)! Разбиение на слова — это ущербная легаси-практика, унаследованная из оболочки Bourne. Она применяется по умолчанию, если вы не заключаете подстановки (expansions) в кавычки. В общем, подавляющее большинство подводных камней так или иначе связаны с подстановкой без кавычек, что приводит к разбиению на слова и глоббингу (globbing) получившегося результата.
Содержание
- for i in $(ls *.mp3)
- cp $file $target
- Имена файлов с предшествующими дефисами
- [ $foo = «bar» ]
- cd $(dirname "$f")
- [ "$foo" = bar && "$bar" = foo ]
- [[ $foo > 7 ]]
- grep foo bar | while read -r; do ((count++)); done
- if [grep foo myfile]
- if [bar="$foo"]; then ...
- if [ [ a = b ] && [ c = d ] ]; then ...
- read $foo
- cat file | sed s/foo/bar/ > file
- echo $foo
- $foo=bar
- foo = bar
- echo <<EOF
- su -c 'some command'
- cd /foo; bar
- [ bar == "$foo" ]
- for i in {1..10}; do ./something &; done
- cmd1 && cmd2 || cmd3
- echo «Hello World!»
- for arg in $*
- function foo()
- echo "~"
- local varname=$(command)
- export foo=~/bar
- sed 's/$foo/good bye/'
- tr [A-Z] [a-z]
- ps ax | grep gedit
- printf "$foo"
- for i in {1..$n}
- if [[ $foo = $bar ]] (в зависимости от цели)
- if [[ $foo =~ 'some RE' ]]
- [ -n $foo ] or [ -z $foo ]
- [[ -e "$broken_symlink" ]] возвращает 1, несмотря на существование $broken_symlink
- Сбой ed file <<<«g/d\{0,3\}/s//e/g»
- Сбой подцепочки (sub-string) expr для «match»
- Про UTF-8 и отметках последовательности байтов (Byte-Order Marks, BOM)
- content=$(<file)
- for file in ./*; do if [[ $file != *.* ]]
- somecmd 2>&1 >>logfile
- cmd; ((! $? )) || die
- y=$(( array[$x] ))
- read num; echo $((num+1))
- IFS=, read -ra fields <<< "$csv_line"
- export CDPATH=.:~/myProject
1. for i in $(ls *.mp3)
Одна из самых распространённых ошибок, совершаемых BASH-программистами. Выражается она в написании подобных циклов:
for i in $(ls *.mp3); do # Неправильно!
some command $i # Неправильно!
done
for i in $(ls) # Неправильно!
for i in `ls` # Неправильно!
for i in $(find . -type f) # Неправильно!
for i in `find . -type f` # Неправильно!
files=($(find . -type f)) # Неправильно!
for i in ${files[@]} # Неправильно!
Да, было бы замечательно, если бы вы могли обрабатывать выходные данные
ls или find в виде списка имён файлов и итерировать его. Но вы не можете. Этот подход целиком ошибочен, и этого никак не исправить. Нужно подходить к этому совершенно иначе.Тут есть как минимум пять проблем:
- Если имя файла содержит пробелы, то оно подвергается WordSplitting. Допустим, в текущей папке у нас есть файл с именем
01 - Don't Eat the Yellow Snow.mp3. Циклforитерирует каждое слово и выдаст результат: 01, -, Don't, Eat, etc.
- Если имя файла содержит символы glob, то оно подвергается глоббингу ("globbing"). Если выходные данные
lsсодержат символ *, то слово, в которое он входит, будет расценено как шаблон и заменено списком всех имён файлов, которые ему соответствуют. Путь к файлу может содержать любые символы, за исключением NUL. Да, в том числе и символы перевода строки.
- Утилита
lsможет искромсать имена файлов. В зависимости от платформы, на которой выработаете, от используемых вами аргументов (или не используемых), а также в зависимости от того, указывают ли на терминал стандартные выходные данные,lsможет внезапно заменить какие-то символы в имени файла на "?". Или вообще их не выводить. Никогда не пытайтесь парсить выходные данные ls.
- CommandSubstitution обрезает из выходных данных все конечные символы переноса строки. На первый взгляд, это хорошо, потому что
lsдобавляет новую строку. Но если последнее имя файла в списке заканчивается новой строкой, то `...` или$()уберут и его в придачу.
Также нельзя заключать подстановку в двойные кавычки:
for i in "$(ls *.mp3)"; do # Неправильно!
Это приведёт к тому, что выходные данные
ls целиком будут считаться одним словом. Вместо итерирования каждого имени файла, цикл будет выполнен один раз, присвоив i строковое значение из объединённых имён файлов. И вы не можете просто изменить IFS на новую строку. Имена файлов тоже могут содержать новые строки. Другая вариация на эту тему заключается в злоупотреблении разбиением на слова и циклами for для (неправильного) чтения строк файла. Например:
IFS=$'\n'
for line in $(cat file); do ... # Неправильно!
Это не работает! Особенно если строки являются именами файлов. Bash (как и любая другая оболочка семейства Bourne) просто не работает таким образом. В добавление ко всему сказанном, совершенно не нужно использовать саму
ls. Это внешняя команда, выходные данные которой специально предназначены для чтения человеком, а не для парсинга скриптом.Так как же делать правильно?
Используете
find, например, в совокупности с -exec:find . -type f -exec some command {} \;
Вместо
ls можно рассмотреть такой вариант: for i in *.mp3; do # Уже лучше! и...
some command "$i" # ...всегда заключайте в двойные кавычки!
done
Оболочки POSIX, как и Bash, специально для этого имеют свойство globbing — это позволяет им применять шаблоны к списку сопоставляемых имён файлов. Не нужно интерпретировать результаты работы внешней утилиты. Поскольку globbing — последний этап процедуры подстановки, то шаблон
*.mp3 корректно применяется к отдельным словам, на которые не оказывает эффекта подстановка без кавычек. Если вам нужно рекурсивно обработать файлы, то воспользуйтесь UsingFind или присмотритесь к shopt -s globstar в Bash 4 и выше.Вопрос: Что случится, если в текущей папке нет файлов, удовлетворяющих шаблону *.mp3? Цикл
for будет выполнен один раз с i="*.mp3", что не является ожидаемым поведением! В качестве решения этой проблемы можно применять проверку на наличие подходящего файла:# POSIX
for i in *.mp3; do
[ -e "$i" ] || continue
some command "$i"
done
Другое решение — использовать свойство Bash'а
shopt -s nullglob. Хотя так можно делать только после прочтения документации и внимательной оценки эффекта этой настройки на все остальные glob’ы в этом скрипте. Обратите внимание на кавычки вокруг $i в теле цикла. Это приводит нас ко второй проблеме:.2. cp $file $target
Что плохого в этой команде? В принципе, ничего, если вы заранее знаете, что
$file и $target не содержат пробелов или подстановочных символов (wildcards). Однако результаты подстановки всё равно подвергаются WordSplitting и подстановке пути к файлу. Поэтому всегда заключайте параметрические подстановки (parameter expansions) в двойные кавычки. cp -- "$file" "$target"
В противном случае вы получите такую команду
cp 01 - Don't Eat the Yellow Snow.mp3 /mnt/usb, что приведёт к ошибкам наподобие cp: cannot stat `01': No such file or directory. Если $file содержит символы подстановки (* или ? или [), то они будут разложены, только если есть удовлетворяющие условиям файлы. С двойными кавычками всё будет хорошо, пока в начале "$file" не окажется символа "-". В этом случае cp решит, что вы пытаетесь скормить ему опции командной строки (см. следующую главу).Даже в несколько необычных обстоятельствах, когда вы можете гарантировать содержимое переменной, заключать в кавычки подстановки параметров — это хорошая и общепринятая практика, особенно если в них содержатся имена файлов. Опытные авторы скриптов всегда будут использовать кавычки, за исключением редких случаев, когда из контекста кода абсолютно очевидно, что параметр содержит гарантированно безопасное значение. Эксперты наверняка решат, что использование в заголовке команды
cp является ошибкой. Вам тоже следует так считать.3. Имена файлов с предшествующими дефисами
Имена файлов с предшествующими дефисами могут доставить немало проблем. Glob’ы наподобие
*.mp3 отсортированы в расширенный список (expanded list) (согласно вашей текущей локали), а в большинстве локалей сначала сортируется дефис, а потом буквы. Затем список передаётся какой-то команде, которая может некорректно интерпретировать -filename в качестве опции. У этой ситуации есть два основных решения.Первое — вставить два дефиса (
--) между командой (например cp) и её аргументами. Это будет сигналом прекращения поиска опций, и всё будет хорошо: cp -- "$file" "$target"
Но у этого подхода есть свои проблемы. Вы должны быть уверены, что вставляете
-- при каждом использовании параметра в контексте, когда он может быть интерпретирован в качестве опции. А это подразумевает большую избыточность, и можно легко что-то упустить.Большинство из хорошо написанных библиотек для парсинга опций это понимают, и корректно использующие их программы должны бесплатно наследовать эту особенность. Однако имейте в виду, что ответственность за распознавание окончаний опций лежит исключительно на приложении. Некоторые программы, которые парсят опции вручную, или делают это некорректно, или используют сторонние библиотеки могут окончания не распознавать. Стандартные утилиты должны это делать, не считая нескольких исключений, описанных в POSIX. Например,
echo.Другой вариант — удостовериться, что ваши имена файлов всегда начинаются с папки. Для этого используются относительные или абсолютные пути к файлам.
for i in ./*.mp3; do
cp "$i" /target
...
done
В таком случае, даже если у нас есть файл, имя которого начинается с дефиса, благодаря glob мы можем быть уверены, что переменная всегда содержит что-то вроде
./-foo.mp3. А это совершенно безопасно, если говорить о cp.Наконец, если вы можете гарантировать, что все результаты будут иметь одинаковый префикс, и переменная используется в теле цикла только несколько раз, то можете просто конкатенировать префикс при подстановке. Теоретически, сэкономит нам генерирование и хранение нескольких дополнительных символов для каждого слова.
for i in *.mp3; do
cp "./$i" /target
...
done
4. [ $foo = «bar» ]
Эта ситуация очень похожа на проблему, описанную во второй главе. Но всё же я повторю её, поскольку она очень важна. В приведённой в заголовке строке кавычки находятся не там, где нужно. В Bash вам не нужно заключать в кавычки строковые литералы (если они не содержат метасимволы или символы шаблонов). Но вы должны заключать в кавычки свои переменные, если они могут содержать пробелы или символы подстановки.
Приведённый пример может сломаться по нескольким причинам:
- Если переменная, на которую ссылаются в
[, не существует или пуста, тогда команда[в конечном итоге будет выглядеть так:
[ = "bar" ] # Неправильно!
… и выкинет ошибку:unary operator expected.(Оператор=является двоичным, а не унарным, поэтому команда[будет шокирована от встречи с ним).
- Если переменная содержит внутренние пробелы, то она будет разделена на слова до того, как её увидит команда
[. Следовательно, получим:
[ multiple words here = "bar" ]
Возможно, вы не видите проблем, но благодаря использованию[тут присутствует синтаксическая ошибка. Правильный способ написания:
# POSIX [ "$foo" = bar ] # Правильно!
Это будет прекрасно работать в совместимых с POSIX реализациях, даже если перед$fooбудет идти дефис, потому что в POSIX-команда[определяет свои действия в зависимости от количества переданных ей аргументов. Только совсем древние оболочки будут испытывать с этим проблемы, можете о них не переживать при написании кода (см. далее уловку с x"$foo").
В Bash и многих других ksh-подобных оболочках есть превосходная альтернатива, использующая ключевое слово [[.
# Bash / Ksh
[[ $foo == bar ]] # Правильно!
Вам не нужно брать в кавычки ссылки на переменные, расположенные слева от
= внутри [[ ]], потому что они не подвергаются разделению на слова или глоббингу. И даже пустые переменные будут корректно обработаны. С другой стороны, использование кавычек никак не повредит. В отличие от [ и test, вы также можете использовать ==. Только обратите внимание, что при сравнениях с использованием [[ поиск по шаблону выполняется для строк в правой части, а не простое сравнение строк. Чтобы сделать правую строку литералом, вы должны поместить её в кавычки, при использовании любых символов, имеющих особое значение в контексте поиска по шаблону.# Bash / Ksh
match=b*r
[[ $foo == "$match" ]] # Хорошо! Если кавычек не будет, то также будет сопоставлено по шаблону b*r.
Вероятно, вы видели подобный код:
# POSIX / Bourne
[ x"$foo" = xbar ] # Можно, но обычно не нужно.
Для кода, работающего на совсем древних оболочках, потребует хак x"
$foo". Здесь вместо [[ используется более примитивное [. Если $foo начинается с дефиса, то возникает путаница. На старых системах [ не заботится о том, начинается ли с дефиса токен справа от =. Она использует его буквально. Так что нужно быть более внимательными с левой частью.Обратите внимание, что оболочки, для которых нужен такой обходной путь, не совместимы с POSIX. Даже Heirloom Bourne этого не требует (вероятно, это неPOSIX клон Bourne-оболочки, который до сих пор является одной из самых распространённых системных оболочек). Такая экстремальная портируемость востребована редко, она делает ваш код менее читабельным и красивым.
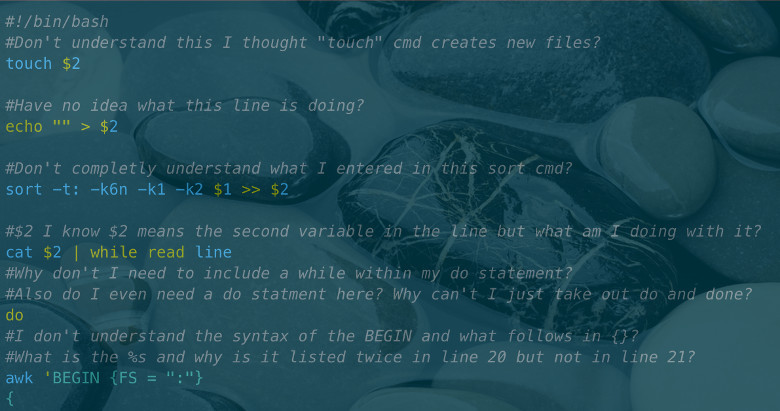
5. cd $(dirname "$f")
Ещё одна ошибка, связанная с кавычками. Как и в случае с подстановкой переменной (variable expansion), результат подстановки команды подвергается разбиению на слова и подстановке пути к файлу. Поэтому заключайте в кавычки:
cd -P -- "$(dirname -- "$f")"
Здесь не совсем очевидна логика вложенности кавычек. Программист на С будет ожидать, что первые и вторые двойные кавычки будут сгруппированы вместе, а затем будут идти третьи и четвёртые. Но в Bash всё иначе. Bash обрабатывает двойные кавычки внутри подстановки команды как одну пару, а двойные кавычки снаружи подстановки — как другую пару.
Можно написать и по-другому: парсер обрабатывает подстановку команды как «уровень вложенности», и кавычки внутри идут отдельно от кавычек снаружи.
6. [ "$foo" = bar && "$bar" = foo ]
Нельзя использовать
&& внутри старой команды test (или [). Парсер Bash видит && снаружи [[ ]] или (( )), и в результате разбивает вашу команду на две команды — до и после &&. Вместо этого используйте один из двух вариантов:[ bar = "$foo" ] && [ foo = "$bar" ] # Правильно! (POSIX)
[[ $foo = bar && $bar = foo ]] # Тоже правильно! (Bash / Ksh)
(Обратите внимание, что по причине легаси, упомянутого в главе 4, мы поменяли местами константу и переменную внутри
[. Можно было бы поменять и [[, но для предотвращения интерпретирования в качестве шаблона пришлось бы брать подстановки в кавычки). То же самое относится и к
||. Вместо них используйте [[ или две команды [. Избегайте такого:
[ bar = "$foo" -a foo = "$bar" ] # Не портируемо.
Двоичные операторы
-a, -o и ( / ) (группирование) — это XSI-расширения стандарта POSIX. В POSIX-2008 все они помечены как устаревшие. Использовать их в новом коде не стоит. Одной из практических проблем, связанных с [ A = B -a C = D ] (или -o), является то, что POSIX не определяет результаты команд test или [ с более чем четырьмя аргументами. Вероятно, в большинстве оболочек это будет работать, но рассчитывать на это нельзя. Если вам нужно писать для POSIX-оболочки, то используйте две команды test или [, разделённые оператором &&.7. [[ $foo > 7 ]]
Здесь есть несколько моментов. Во-первых, команду
[[ не следует использовать исключительно для вычисления арифметических выражений. Её нужно применять для test-выражений, включающих один из поддерживаемых test-операторов. Хотя технически вы можете выполнять вычисления с помощью операторов [[, но делать это имеет смысл только в сочетании с одним из нематематических test-операторов, который присутствует где-то в выражении. Если вы хотите всего лишь сравнить числовые данные (или выполнить любое другое арифметическое действие), то гораздо лучше применить (( )):# Bash / Ksh
((foo > 7)) # Правильно!
[[ foo -gt 7 ]] # Работает, но бессмысленно. Многие сочтут ошибкой. Лучше используйте ((...)) или let.
Если внутри
[[ ]] вы используете оператор >, то система обработает это как сравнение строковых данных (проверка порядка сортировки по локали), а не числовых. Иногда это может сработать, но подведёт вас именно тогда, когда вы этого меньше всего ожидаете. Ещё хуже использовать > внутри [ ]: это перенаправление вывода. В вашей папке появится файл с названием 7, и тест будет успешно выполняться до тех пор, пока в $foo что-то есть.Если требуется строгая совместимость с POSIX и не доступна команда
((, тогда правильной альтернативой будет использование старомодной [:# POSIX
[ "$foo" -gt 7 ] # Тоже правильно!
[ $((foo > 7)) -ne 0 ] # Совместимый с POSIX эквивалент (( для более общих математических операций.
Обратите внимание, что если
$foo не является целочисленным, то команда test ... -gt завершится неудачно. Поэтому заключать в кавычки имеет смысл только ради производительности и разделения аргументов на одиночные слова, чтобы снизить вероятность возникновения побочных эффектов в некоторых оболочках.Если вы не можете гарантировать входные данные для любого арифметического контекста (включая
(( или let), либо тестового выражения [, подразумевающего числовые сравнения, тогда вы должны всегда валидировать входные данные, прежде чем выполнять вычисление.# POSIX
case $foo in
*[![:digit:]]*)
printf '$foo expanded to a non-digit: %s\n' "$foo" >&2
exit 1
;;
*)
[ $foo -gt 7 ]
esac
8. grep foo bar | while read -r; do ((count++)); done
Этот код выглядит нормально? Конечно, это всего лишь посредственная реализация
grep -c, но так сделано для простоты примера. Изменения в count не будут распространяться за границы цикла while, потому что каждая команда конвейера исполняется в отдельной подоболочке (SubShell). В какой-то момент это удивляет любого новичка в Bash.POSIX не определяет, должен ли вычисляться в подоболочке последний элемент конвейера. Одни оболочки, вроде ksh93 и Bash >= 4.2 с включённым
shopt -s lastpipe, запустят приведённый в примере цикл while в исходном shell-процессе, что может привести к любым побочным эффектам. Следовательно, портируемые скрипты должны писаться так, чтобы не зависеть от подобного поведения.Способы решения этой и подобных проблем вы можете почерпнуть из Bash FAQ #24. Здесь их слишком долго описывать.
9. if [grep foo myfile]
У многих новичков возникает ошибочное представление о выражениях
if, обусловленное тем, что очень часто за этим ключевым словом сразу идёт [ или [[. Люди считают, что [ каким-то образом является частью синтаксиса выражения if, как и простые скобки, используемые в выражении if в языке С. Это не так! if получает команду. Ею является [, это не синтаксический маркер для if. Эта команда эквивалентна test, за исключением того, что последним аргументом должен быть ]. Например:# POSIX
if [ false ]; then echo "HELP"; fi
if test false; then echo "HELP"; fi
Эти строки эквивалентны: обе проверяют, чтобы аргумент «false» не был пустым. В обоих случаях будет выводиться HELP, к удивлению программистов, пришедших из других языков и пытающихся разобраться с синтаксисом оболочки.
У выражения
if такой синтаксис:if COMMANDS
then <COMMANDS>
elif <COMMANDS> # optional
then <COMMANDS>
else <COMMANDS> # optional
fi # required
Ещё раз —
[ является командой. Она получает аргументы, как и любая другая обычная команда. if — это составная команда, содержащая другие команды. И в её синтаксисе нет [! Хотя в Bash есть встроенная команда
[, и таким образом он знает о [, в ] нет ничего особенного. Bash всего лишь передаёт ] в качестве аргумента команде [, которой нужно, чтобы именно ] был последним аргументом, иначе скрипт будет выглядеть некрасиво.Там может быть ноль и более опциональных секций
elif, а также одна опциональная секция else.Составная команда
if содержит две и более секций, в которых находятся списки команд. Каждая секция начинается с ключевого слова then, elif или else, а заканчивается ключевым словом fi. Код завершения последней команды первой секции и каждая последующая секция elif определяют вычисление каждой соответствующей секции then. Другая секция elif вычисляется до того, как будет выполнена одна из then. Если не вычислено ни одной секции then, то происходит переключение на ветку else. Если нет else, то блок if завершается, а результирующая команда if возвращает 0 (true).Если вы хотите принять решение в зависимости от выходных данных команды
grep, то не нужно заключать её в круглые или квадратные скобки, backticks или любой другой синтаксис! Просто используйте grep как команду после if:if grep -q fooregex myfile; then
...
fi
Если
grep находит совпадение в строке из myfile, тогда код завершения будет 0 (true), и выполнится часть then. Если совпадений найдено не будет, grep вернёт значение, отличное от 0, а результирующая команда if будет нулём. Читайте также:
10. if [bar="$foo"]; then ...
[bar="$foo"] # Неправильно!
[ bar="$foo" ] # Все еще неправильно!
Как объяснялось в предыдущей главе,
[ — это команда (это можно доказать с помощью type -t [ или whence -v [). Как и в случае с любой другой простой командой, Bash ожидает, что после неё будет идти пробел, затем первый аргумент, снова пробел, и так далее. Вы просто не можете пренебрегать пробелами! Вот правильное написание:if [ bar = "$foo" ]; then ...
Каждый из компонентов —
bar, =, подстановка "$foo" и ] — являются отдельными аргументами команды [. Каждая пара аргументов должна быть разделена пробелом, чтобы оболочка знала, где начинается и кончается каждый из них. 11. if [ [ a = b ] && [ c = d ] ]; then ...
Повторюсь в который раз.
[ является командой. Это не синтаксический маркер, расположенный между if и каким-нибудь «состоянием», наподобие как в С. Не используется [ и для группирования. Вы не можете взять С-команды if и транслировать их в Bash-команды, просто заменив круглые скобки на квадратные! Если вы хотите выразить составные условные конструкции, делайте так:
if [ a = b ] && [ c = d ]; then ...
Обратите внимание, что здесь у нас две команды после
if, объединённые оператором && (логическое AND, сокращённое вычисление). Это то же самое, что и:if test a = b && test c = d; then ...
Если первая команда
test возвращает false, то вход в тело выражения if не выполняется. Если возвращает true, тогда запускается вторая команда test; если и она возвращает true, тогда выполняется вход в тело выражения if. (C-программисты уже знакомы с &&. Bash использует такое же упрощённое вычисление. Подобно тому, как || выполняет упрощённое вычисление для операции OR.)Ключевое слово
[[ разрешает использование &&, так что можно написать и так: if [[ a = b && c = d ]]; then ...
В главе 6 описана проблема, связанная с комбинированием
test с условными операторами.12. read $foo
Не используйте
$ перед именем переменной в команде read. Если вы хотите поместить данные в переменную с именем foo, делайте так: read foo
Или ещё безопаснее:
IFS= read -r foo
read $foo считает строку входных данных и поместит её в переменную/ые с именем $foo. Это может быть полезным, если вы действительно хотели сделать foo ссылкой на другую переменную; но в большинстве случаев это баг. 13. cat file | sed s/foo/bar/ > file
Вы не можете читать из файла и писать в него в рамках одного конвейера. В зависимости от того, что делает ваш конвейер, файл:
- может оказаться затёрт (clobbered) (до 0 байт, или до размера, эквивалентного размеру буфера конвейера вашей ОС),
- может разрастись и заполнить всё доступное дисковое пространство,
- может достичь предельного размера, заданного ОС или вами, и так далее.
Если вы хотите безопасно изменить файл, не просто добавляя информацию в конец, то воспользуйтесь текстовых редактором.
printf %s\\n ',s/foo/bar/g' w q | ed -s file
Если он не может помочь вам в решении вашей задачи, то в определённый момент(*) необходимо создавать временный файл.
Этот пример можно портировать без ограничений:
sed 's/foo/bar/g' file > tmpfile && mv tmpfile file
Этот пример будет работать только под GNU sed 4.x:
sed -i 's/foo/bar/g' file(s)
Обратите внимание, что здесь создаётся временный файл и применяется такой же трюк с переименованием — обработка выполняется прозрачно.
А следующая команда-аналог требует наличия Perl 5.x (который, вероятно, более распространён, чем GNU sed 4.x):
perl -pi -e 's/foo/bar/g' file(s)
За подробностями о замене контента файлов обратитесь к Bash FAQ #21.
(*) в мануале к
sponge из moreutils приводится такой пример: sed '...' file | grep '...' | sponge file
Вместо использования временного файла и атомарного
mv, эта версия «впитывает» (цитата из мануала!) все данные, прежде чем открыть и записать в file. Правда, если программа или система рухнет в ходе операции, данные будут потеряны, потому что в этот момент на диске нет копии исходной информации.Использование временного файла
+ mv всё ещё подвергает нас небольшому риску потери данных при падении системы / отключении питания. Чтобы старый или новый файл сохранился, нужно перед mv использовать sync.14. echo $foo
Эта относительно безобидно выглядящая команда вносит сильную путаницу. Поскольку
$foo не взята в кавычки, она не только подвергнется разбиению на слова, но и глоббингу. Из-за этого Bash-программисты думают, что их переменные содержат неправильные значения, хотя на самом деле с ними всё в порядке. Смуту вносит разбиение на слова или подстановка пути к файлу.msg="Пожалуйста, введите название формы *.zip"
echo $msg
Это сообщение разбито на слова, а все глобы (glob) (вроде *.zip) разложены. Что подумают пользователи, когда увидят сообщение:
Пожалуйста, введите название формы freenfss.zip lw35nfss.zip. Иллюстрация: var="*.zip" # var содержит звёздочку, точку и слово "zip"
echo "$var" # пишет *.zip
echo $var # пишет список файлов, заканчивающихся на .zip
По сути, здесь команда
echo не может быть использована безопасно. Если переменная содержит, например, -n, то echo решит, что это опция, а не данные для вывода на экран. Единственный гарантированный способ вывода значения переменной — использование printf:printf "%s\n" "$foo"
15. $foo=bar
Нет, помещая
$ перед именем переменной, вы не присваиваете ей значение. Это не Perl. 16. foo = bar
Нет, вы не можете вставить пробелы вокруг
=, когда присваиваете переменной значение. Это не С. Когда вы пишете foo = bar, оболочка разбивает это на три слова. Первое — foo — берётся в качестве имени команды. Второе и третье — в качестве аргументов команды.foo= bar # Неправильно!foo =bar # Неправильно!$foo = bar; # СОВСЕМ НЕПРАВИЛЬНО!foo=bar # Правильно.foo="bar" # Ещё правильнее.
17. echo <<EOF
Here-док — это полезный инструмент для встраивания в скрипт больших блоков текстовых данных. Это приводит к перенаправлению строк текста в скрипте на стандартный ввод команды. К сожалению, команда
echo не читает из stdin.# Это неправильно:
echo <<EOF
Hello world
How's it going?
EOF
# Вот что вы пытались сделать:
cat <<EOF
Hello world
How's it going?
EOF
# Либо используйте кавычки, которые могут объединять несколько строк (эффективно, echo встроена):
echo "Hello world
How's it going?"
При использовании кавычек это будет прекрасно работать во всех оболочках. Но вы не сможете просто закинуть в скрипт пачку строк. Первая и последняя строки должны иметь синтаксическую разметку. Если вы хотите, чтобы строки не содержали синтаксиса оболочки, и не хотите множить команду
cat, то воспользуйтесь альтернативой:# Или примените printf (тоже эффективно, printf встроена):
printf %s "\
Hello world
How's it going?
"
В примере с
printf, знак \ в первой строке предотвращает появление дополнительной новой строки в начале текстового блока. Новая строка есть в конце блока (потому что последняя кавычка находится в новой строке). Отсутствие \n в аргументе printf предотвращает добавление в конце новой строки. Только трюк с \ не сработает при использовании одинарных кавычек. Если вы хотите включить в них блок текста, то у вас есть два варианта, и оба они подразумевают «загрязнение» ваших данных синтаксисом оболочки:printf %s \
'Hello world
'
printf %s 'Hello world
'
18. su -c 'some command'
Этот синтаксис почти корректен. Проблема в том, что на многих платформах
su берёт аргумент -c, но не тот, который вам нужен. Вот пример с OpenBSD: $ su -c 'echo hello'
su: only the superuser may specify a login class
Вы хотите передать оболочке
-c 'some command', то есть перед -c вам нужно имя пользователя.su root -c 'some command' # Now it's right.
su подразумевает имя root-пользователя, когда вы его опускаете. Но он сталкивается с этим, когда вы позднее пытаетесь передать команду оболочке. Так что в этом случае вы должны явно указать имя пользователя. 19. cd /foo; bar
Если вы не проверяете на наличие ошибок после команды
cd, то можете выполнить bar в неверном месте. А это попахивает катастрофой, если, к примеру, bar окажется rm -f *. Всегда проверяйте на наличие ошибок после команды cd. Простейший способ: cd /foo && bar
Если после
cd идёт больше одной команды, то можно сделать так: cd /foo || exit 1
bar
baz
bat ... # Lots of commands.
cd сообщит о невозможности изменения папки, выдав stderr-сообщение наподобие «bash: cd: /foo: No such file or directory». Если вы хотите добавить в stdout собственное сообщение, то можете применить группирование команд: cd /net || { echo >&2 "Can't read /net. Make sure you've logged in to the Samba network, and try again."; xit 1; }
do_stuff
more_stuff
Обратите внимание, что между
{ и echo нужен пробел. Также перед закрывающей } нужен ;. Некоторые любят включать set -e, чтобы их скрипты прерывались на любой команде, возвращающей значение, отличное от нуля. Но это не так просто использовать правильно (потому что многие обычные команды могут возвращать не нулевое значение ради предупреждения, что вы можете не считать фатальным).
Кстати, если вы много раз меняете папки в Bash-скрипте, то почитайте инструкцию по пользованию
pushd, popd и dirs. Вероятно, весь код, который вы писали для управления cd и pwd, совершенно не нужен. Сравните это: find ... -type d -print0 | while IFS= read -r -d '' subdir; do
here=$PWD
cd "$subdir" && whatever && ...
cd "$here"
done
C этим:
find ... -type d -print0 | while IFS= read -r -d '' subdir; do
(cd "$subdir" || exit; whatever; ...)
done
Принудительное использование подоболочки заставляет
cd выполняться только в ней. Для следующей итерации цикла мы возвращаемся в нормальное место, вне зависимости от того, успешно ли выполнилась cd. Нам не нужно менять папку вручную, и мы не застреваем в бесконечной строке с логикой ... && ..., предотвращающей использование других условных конструкций. Версия с подоболочкой проще и чище (хотя и немножко медленнее).20. [ bar == "$foo" ]
Оператор
== не является валидным для POSIX-команды [. Используйте = ключевое слово [[. [ bar = "$foo" ] && echo yes
[[ bar == $foo ]] && echo yes
В Bash
[ "$x" == y ] принимается как подстановка, поэтому многие программисты считают синтаксис правильным. Но это не так — это «башизм» (Bashism). Если вы собрались использовать башизмы, то можете вместо этого использовать и [[. 21. for i in {1..10}; do ./something &; done
Нельзя помещать
; сразу после &. Просто удалите лишнюю ;. for i in {1..10}; do ./something & done
Или:
for i in {1..10}; do
./something &
done
& уже работает как прерыватель команды (command terminator), как и ;. Нельзя их смешивать.В целом,
; можно заменить новой строкой, но не все новые строки можно заменить на ;. 22. cmd1 && cmd2 || cmd3
Кто-то любит использовать
&& и || в качестве сокращённого синтаксиса для if ... then ... else ... fi. Во многих случаях это безопасно: [[ -s $errorlog ]] && echo "Uh oh, there were some errors." || echo "Successful."
Однако в целом эта конструкция не полностью эквивалентна
if ... fi. Команда, идущая после &&, также генерирует код завершения. И если этот код не «true» (0), тогда будет вызвана и команда, идущая после ||. Например:i=0
true && ((i++)) || ((i--))
echo $i # Prints 0
Что здесь происходит? Похоже, что
i должно равняться 1, но получается 0. Почему? Потому что были выполнены и i++, и i--. Команда ((i++)) имеет код завершения, который унаследован от вычисления выражения внутри круглых скобок по примеру языка С. Значение выражения равно 0 (начальное значение i), а в С выражение целочисленным, равным 0, считается false. Так что команда ((i++)) (когда i равно 0) имеет код завершения 1 (false), и значит также выполняется команда ((i--)). Это не происходит, если мы используем оператор предварительного инкрементирования, поскольку код завершения
++i равен true:i=0
true && (( ++i )) || (( --i ))
echo $i # Prints 1
Но это работает благодаря случайности. Вы не можете полагаться на
x && y || z, если y имеет малейший шанс сбоя! Этот пример не будет работать, если начальное значение i будет -1 вместо 0. Если вас волнует безопасность или если вы просто не уверены, как это работает, или если вы хоть что-то недопоняли из предыдущих параграфов, пожалуйста, используйте простой синтаксис
if ... fi.i=0
if true; then
((i++))
else
((i--))
fi
echo $i # Prints 1
Эта часть также применима к оболочке Bourne:
true && { echo true; false; } || { echo false; true; }
На выходе получается две строки «true» и «false», вместо одной строки «true».
23. echo «Hello World!»
В интерактивной оболочке Bash (до версии 4.3), вы увидите ошибку:
bash: !": event not found
Дело в том, что при настройках по умолчанию для интерактивной оболочки, Bash выполняет подстановку истории (history expansion) в стиле csh, используя восклицательный знак. Это проблема не для скриптов оболочки, а только для интерактивных оболочек. К сожалению, очевидная попытка «исправления» не сработает:
$ echo "hi\!"
hi\!
Простейшее решение — вернуть в исходное состояние опцию
histexpand. Это можно сделать с помощью set +H или set +o histexpand:Вопрос: Почему лучше использовать
histexpand, чем одинарные кавычки? Я лично столкнулся с этой ситуацией, когда манипулировал файлами песен с помощью команд наподобие
mp3info -t "Don't Let It Show" ...
mp3info -t "Ah! Leah!" ...
Одинарные кавычки неудобны в использовании, потому что все песни имеют в названиях апострофы. Использование двойных кавычек привело к проблеме подстановки истории. А представьте, что у файла в названии и апостроф, и двойные кавычки. Так что от кавычек лучше отказаться. Поскольку я никогда не прибегаю к подстановке истории, то предпочитаю выключить
~/.bashrc. -- GreyCatСработает такое решение:
echo 'Hello World!'
Или
set +H
echo "Hello World!"
Или
histchars=
Многие просто кладут
set +H или set +o histexpand в свои ~/.bashrc, чтобы навсегда деактивировать подстановку истории. Это дело вкуса, выбирайте, что вам больше подходит.Другое решение:
exmark='!'
echo "Hello, world$exmark"
В Bash 4.3 и ниже, двойные кавычки после
! больше не запускают подстановку истории. Но с двойными кавычками оно всё же выполняется, и хотя с echo "Hello World!" порядок, у нас ещё есть проблема:echo "Hello, World!(and the rest of the Universe)"
echo "foo!'bar'"
24. for arg in $*
Bash (как и все Bourne-оболочки) имеет специальный синтаксис для ссылания на список позиционных параметров, по одному за раз. Это
$*, а не $@. Они оба раскладываются на список слов в ваших параметрах скрипта, каждый параметр не является отдельным словом. Правильный синтаксис: for arg in "$@"
# Или проще:
for arg
Поскольку в скриптах часто прогоняют через циклы позиционные параметры,
for arg по умолчанию используется для for arg in "$@". Взятый в двойные кавычки "$@" — это особая магия, благодаря которой каждый параметр используется как отдельное слово (или отдельная итерация цикла). Так вы должны делать в 99% случаев.Пример:
# Ошибочная версия
for x in $*; do
echo "parameter: '$x'"
done
$ ./myscript 'arg 1' arg2 arg3
parameter: 'arg'
parameter: '1'
parameter: 'arg2'
parameter: 'arg3'
Надо было написать:
# Правильная версия
for x in "$@"; do
echo "parameter: '$x'"
done
# Или лучше:
for x; do
echo "parameter: '$x'"
done
$ ./myscript 'arg 1' arg2 arg3
parameter: 'arg 1'
parameter: 'arg2'
parameter: 'arg3'
25. function foo()
В некоторых оболочках это работает, но не во всех. При определении функции никогда не комбинируйте ключевое слово
function с круглыми скобками (). Bash (как минимум некоторые версии) позволяет их смешивать. Но большинство оболочек такой код не примут (например, zsh 4.x и, вероятно, выше). Некоторые оболочки примут function foo, но для максимальной совместимости лучше применять:foo() {
...
}
26. echo "~"
Подстановка с помощью тильды применяется только тогда, когда '~' не взято в кавычки. В этом примере echo пишет в stdout '~', а не путь пользовательской домашней папки. Брать в кавычки параметры, которые выражены относительно пользовательской домашней папки, нужно с помощью $HOME, а не '~'. Возьмите ситуацию, когда $HOME — это "/home/my photos".
"~/dir with spaces" # разворачивается до "~/dir with spaces"
~"/dir with spaces" # разворачивается до "~/dir with spaces"
~/"dir with spaces" # разворачивается до "/home/my photos/dir with spaces"
"$HOME/dir with spaces" # разворачивается до "/home/my photos/dir with spaces"
27. local varname=$(command)
При объявлении в функции локальной переменной,
local самостоятельно действует как команда. Иногда остальная часть строки может итерироваться странно. Например, если вы хотите получить код завершения ($?) подстановки команды, то у вас ничего не получится. Он будет скрыт кодом завершения локали. Для этого лучше разделять команды:local varname
varname=$(command)
rc=$?
Следующая проблема описывает другую особенность синтаксиса.
28. export foo=~/bar
Когда тильда находится в начале слова, — самостоятельно или через слэш — то гарантированно будет выполнена только подстановка с помощью тильды (с именем пользователя или без него). Также оно будет обязательно выполнено, когда в присваивании тильда идёт сразу после
=.Однако команды
export и local не осуществляют присваивание. Так что в некоторых оболочках (вроде Bash) export foo=~/bar подвергнется подстановке с помощью тильды, а в других (вроде dash) — нет.foo=~/bar; export foo # Правильно!
export foo="$HOME/bar" # Правильно!
29. sed 's/$foo/good bye/'
В одинарных кавычках параметры подстановки вроде
$foo не раскладываются. Это предназначение одинарных кавычек — защищать от оболочки символы наподобие $. Применяйте двойные кавычки: foo="hello"; sed "s/$foo/good bye/"
Но помните: в этом случае вам может понадобиться использовать больше escapes. За подробностями обратитесь к странице «кавычки».
30. tr [A-Z] [a-z]
Здесь как минимум три проблемы. Первая проблема:
[A-Z] и [a-z] рассматриваются оболочкой как глобы. Если у вас в текущей папке нет файлов с именами, состоящими из одного символа, то команда получается некорректной. Если есть, то всё пойдет наперекосяк. Вероятно, в 3 ночи в выходные.Вторая проблема: на самом деле это неправильная нотация для
tr. Фактически, здесь '[' переводится в '[', затем что-то из диапазона A-Z в a-z, а затем ']' в ']'. Так что вам даже не нужны эти квадратные скобки, первая проблема исчезнет сама собой.Третья проблема заключается в том, что в зависимости от локали, A-Z или a-z могут не дать вам ожидаемые 26 ASCII-символов. Фактически в некоторых локалях z находится посреди алфавита! Решение зависит от того, что вам нужно:
# Используйте, если хотите изменить 26 латинских букв
LC_COLLATE=C tr A-Z a-z
# Используйте, если вам нужно преобразование в зависимости от локаля. Это с большей вероятностью нужно пользователям
tr '[:upper:]' '[:lower:]'
Для второй команды необходимо использовать кавычки, чтобы избежать глоббинга.
31. ps ax | grep gedit
Фундаментальная проблема заключается в том, что имя исполняемого процесса по своей природе ненадёжно. Может быть несколько легитимных процессов gedit. Может быть что-то ещё, маскирующееся под gedit (можно тривиально изменить объявляемое имя исполненной команды). Чтобы разобраться подробнее, читайте об управлении процессами. При поиске PID gedit (например), многие начнут с
$ ps ax | grep gedit
10530 ? S 6:23 gedit
32118 pts/0 R+ 0:00 grep gedit
А это, в зависимости от Race Condition, часто выдаёт в качестве результата сам grep. Его можно отфильтровать:
ps ax | grep -v grep | grep gedit # сработает, но выглядит страшненько
Альтернатива:
ps ax | grep '[g]edit' # возьмите в кавычки, чтобы избежать shell GLOB
Grep будет проигнорирован в таблице процессов, потому что он
[g]edit, grep будут искать единожды выполненный gedit.В GNU/Linux параметр –C можно использовать для фильтрования по имени команды:
$ ps -C gedit
PID TTY TIME CMD
10530 ? 00:06:23 gedit
Но зачем переживать, если можно использовать
pgrep? $ pgrep gedit
10530
На втором этапе PID зачастую извлекается с помощью
awk или cut: $ ps -C gedit | awk '{print $1}' | tail -n1
Но даже это можно обработать с помощью триллионов параметров для
ps:$ ps -C gedit -opid=
10530
Если вы застряли в 1992 году и не используете
pgrep, то можете применить древний, устаревший и осуждаемый pidof (только под GNU/Linux):$ pidof gedit
10530
А если вам нужен PID, чтобы убить процесс, то вас может заинтересовать
pkill. Только обратите внимание, что, например, pgrep/pkill ssh также найдёт процессы под названием sshd, убивать которые вам не захочется.К сожалению, некоторые программы начинаются не со своего имени. Скажем, Firefox часто стартует как firefox-bin. Этот процесс тоже надо будет найти с помощью, скажем, ps ax | grep firefox. Или можно добавить несколько параметров к pgrep:
$ pgrep -fl firefox
3128 /usr/lib/firefox/firefox
7120 /usr/lib/firefox/plugin-container /usr/lib/flashplugin-installer/libflashplayer.so -greomni /usr/lib/firefox/omni.ja 3128 true plugin
Почитайте про управление процессами. Серьёзно.
32. printf "$foo"
Здесь ошибка связана не с кавычками, а с использованием строки формата. Если
$foo не находится под вашим полным контролем, тогда наличие в переменной символов \ или % может привести к нежелательному поведению. Всегда задавайте свою строку формата: printf %s "$foo"
printf '%s\n' "$foo"
33. for i in {1..$n}
Парсер Bash выполняет раскрытие скобок до всех разложений и подстановок. Так что код раскрытия видит литерал
$n, который не является числом, и поэтому не раскрывает фигурные скобки в список чисел. Так что практически невозможно использовать раскрытие скобок для создания списков, размер которых известен только в ходе runtime. Лучше делайте так: for ((i=1; i<=n; i++)); do
...
done
При простом итерировании целочисленных переменных почти всегда лучше начинать с цикла арифметических вычислений
for, а не с раскрытия скобок, потому что в последнем случае каждый аргумент предварительно раскладывается (pre-expands), что может снизить производительность и увеличить потребление памяти.34. if [[ $foo = $bar ]] (в зависимости от цели)
Если не взять в кавычки то, что расположено справа от
= внутри [[, то Bash не будет считать это строкой, а будет сопоставлять с шаблоном. Так что если в приведённом коде bar будет содержать *, то результат будет всегда true. Если вы хотите проверить строковые на эквивалентность друг другу, то возьмите правую часть в кавычки: if [[ $foo = "$bar" ]]
Если вам нужно сопоставить с шаблоном, то умнее будет выбрать иное имя переменной, обозначающее, что правая часть содержит шаблон. Или использовать комментарии.
Ещё нужно указать, что если взять в кавычки часть справа от
=~, тогда будет принудительно выполняться ещё и простое сравнение строковых, а не только сопоставление регулярных выражений. Это приводит нас к следующей проблеме.35. if [[ $foo =~ 'some RE' ]]
Кавычки вокруг правой части делают их содержимое строкой, а не регулярным выражением. Если вам нужно использовать длинное или сложное регулярное выражение, избегая многочисленных изолирований с помощью обратных слешей, то поместите данные в переменную:
re='some RE'
if [[ $foo =~ $re ]]
Также это помогает обойти различия в работе
=~ в разных версиях Bash. Благодаря переменной мы избегаем некоторых неприятных и неочевидных проблем. Та же проблема возникает при сопоставлении с шаблоном внутри
[[: [[ $foo = "*.glob" ]] # Wrong! *.glob is treated as a literal string.
[[ $foo = *.glob ]] # Correct. *.glob is treated as a glob-style pattern.
36. [ -n $foo ] or [ -z $foo ]
Используя команду
[, вы должны брать в кавычки все передаваемые ей подстановки. В противном случае $foo может разложиться на 0 слов, или 42 слова, или любое другое количество, кроме 1, что сломает синтаксис.[ -n "$foo" ]
[ -z "$foo" ]
[ -n "$(внутри какая-то команда с "$file")" ]
# [[ не выполняет разделение на слова или подстановку с помощью глобов, так что можно использовать и это:
[[ -n $foo ]]
[[ -z $foo ]]
37. [[ -e "$broken_symlink" ]] возвращает 1 несмотря на существование $broken_symlink
Test идёт после symlink’ов, следовательно, если symlink сломан, — например, указывает на файл, который не существует или находится в недоступной папке, — тогда
test –e возвращает 1, несмотря на существование symlink. Чтобы это обойти (и подготовиться к этому), используйте:# bash/ksh/zsh
[[ -e "$broken_symlink" || -L "$broken_symlink" ]]
# POSIX sh+test
[ -e "$broken_symlink" ] || [ -L "$broken_symlink" ]
38. Сбой ed file <<<«g/d\{0,3\}/s//e/g»
Проблема в том, что ed не принимает 0 для \{0,3\}. Можете проверить, что такой код работает:
ed file <<<"g/d\{1,3\}/s//e/g"
Обратите внимание, что это происходит несмотря на то что POSIX-состояния, которые BRE (особенность регулярных выражений, используемая ed), должны принимать 0 в качестве минимального количества вхождений (см. главу 5).
39. Сбой подцепочки (sub-string) expr для «match»
Это достаточно хорошо работает… чаще всего
word=abcde
expr "$word" : ".\(.*\)"
bcde
Но со словом «match» произойдёт сбой
word=match
expr "$word" : ".\(.*\)"
Дело в том, что «match» — ключевое слово. В GNU эта проблема решается с помощью префикса '+'
word=match
expr + "$word" : ".\(.*\)"
atch
Или можно просто отказаться от
expr. Всё, что она умеет делать, вы можете выполнять с помощью параметрической подстановки (Parameter Expansion). Например, нужно убрать первую букву в слове? В POSIX-оболочках это решается посредством параметрической подстановки или разложения на подцепочки (Substring Expansion):$ word=match
$ echo "${word#?}" # PE
atch
$ echo "${word:1}" # SE
atch
Серьёзно, для использования
expr у вас нет оправданий, если только вы не работаете на Solaris с его несовместимым с POSIX /bin/sh. Это внешний процесс, так что он работает куда медленнее, чем внутрипроцессная обработка строки. А поскольку никто его не использует, то никто и не понимает, что он делает, так что ваш код будет запутан и труден в сопровождении.40. Про UTF-8 и метки последовательности байтов (Byte-Order Marks, BOM)
В целом: в Unix текст в кодировке UTF-8 не использует BOM. Кодирование обычного текста определяется локалью, MIME-типами или другими метаданными. Хотя наличие BOM обычно не вредит документу в кодировке UTF-8, предназначенному только для чтения людьми, но является проблемой (зачастую из-за нелегального синтаксиса) в любых текстовых файлах, предназначенных для автоматизированных процессов в скриптах, исходном коде, конфигурационных файлах и так далее. Файлы, которые начинаются с BOM, нужно считать чужеродными, как и те, что содержат разрывы строк в стиле MS-DOS.
В скриптах оболочек: там, где UTF-8 прозрачно используется в 8-битных средах, применение BOM будет мешать любому протоколу или файловому формату, который ожидает, что в начале будут идти конкретные ASCII-символы, наподобие "#!" в начале скриптов Unix-оболочки».
http://unicode.org/faq/utf_bom.html#bom5
41. content=$(<file)
С этим выражением всё в порядке, но помните, что эти подстановки команд (всех форм:
`...`, $(...), $(<file), `<file` и ${ ...; } (ksh)) удаляют все конечные новые строки. Зачастую, это неуместно или даже нежелательно, но если вам нужно сохранить выходные данные литерала, включая все возможные конечные новые строки, то это будет непросто, поскольку совершенно неизвестно, есть ли они вообще и сколько их. Есть способ решения этой проблемы, хотя и корявый: добавляем внутри подстановки команды постфикс и убираем его снаружи.absolute_dir_path_x=$(readlink -fn -- "$dir_path"; printf x)
absolute_dir_path=${absolute_dir_path_x%x}
Менее портируемое, но более приятное решение: использовать
read с пустым разделителем. # Ksh (or bash 4.2+ with lastpipe enabled)
readlink -fn -- "$dir_path" | IFS= read -rd '' absolute_dir_path
Недостатком этого способа является то, что
read всегда будет возвращать false, если команда не выдаёт NUL-байт, что приводит к чтению только части потока. Единственный способ получения кода завершения команды — через PIPESTATUS. Можно также намеренно выводить NUL-байт, чтобы заставить read вернуть true, и использовать pipefail.set -o pipefail
{ readlink -fn -- "$dir_path"; printf '\0x'; } | IFS= read -rd '' absolute_dir_path
Здесь настоящий хаос портируемости: Bash поддерживает
pipefail и PIPESTATUS, ksh93 — только pipefail, лишь последние версии mksh поддерживают pipefail, а более ранние — только PIPESTATUS. Кроме того, требуется самая свежая версия ksh93, чтобы заставить read остановиться на NUL-байте. 42. for file in ./*; do if [[ $file != *.* ]]
Одним из способов не дать программам интерпретировать передаваемые им имена файлов как опции, является использование путей к файлам (см. главу 3). В названиях файлов в текущей папке можно использовать префикс относительного пути
./.Но могут возникнуть проблемы с шаблоном
*.*, потому что он сопоставляет файлы вида ./filename. В простом случае можно просто напрямую использовать глоб для генерирования желаемых соответствий. Однако, если требуется отдельный этап сопоставления с шаблоном (например, результаты были предварительно обработаны и сохранены в массиве, и их нужно отфильтровать), то в шаблоне можно учитывать префикс: [[ $file != ./*.* ]], либо расщепить шаблон. # Bash
shopt -s nullglob
for path in ./*; do
[[ ${path##*/} != *.* ]] && rm "$path"
done
# Так ещё лучше
for file in *; do
[[ $file != *.* ]] && rm "./${file}"
done
# Всё ещё лучше
for file in *.*; do
rm "./${file}"
done
Другой способ сигнализировать о конце опций — использовать аргумент
-- (снова читайте главу 3).shopt -s nullglob
for file in *; do
[[ $file != *.* ]] && rm -- "$file"
done
43. somecmd 2>&1 >>logfile
Несомненно, это наиболее распространённая ошибка, связанная с перенаправлениями, обычно совершаемая программистами, которые хотят направить в файл или пайп stdout и stderr. Они пытаются это сделать и не понимают, почему stderr всё ещё отображается в их терминалах. Если вы тоже в недоумении по этому поводу, то вероятно не знаете, как начать работать с перенаправлениями или файловыми дескрипторами. Перенаправления выполняются слева направо, до выполнения команды. Этот семантически неправильный код означает: «сначала перенаправить стандартную ошибку туда, куда сейчас указывает стандартный вывод (tty), а затем перенаправить стандартный вывод в лог-файл». Это в обратном направлении. Стандартная ошибка уже направляется в tty. Правильно так:
somecmd >>logfile 2>&1
Читайте более подробное объяснение, объяснение про дескриптор Copy и BashGuide — redirection.
44. cmd; ((! $? )) || die
$? нужно только тогда, когда вы пытаетесь извлечь конкретный статус предыдущей команды. Если вам всего лишь нужно узнать, была ли она успешной или нет (любой не нулевой статус), то запросите команду напрямую, например:if cmd; then
...
fi
Проверку кода завершения по списку альтернатив можно делать по такому шаблону:
cmd
status=$?
case $status in
0)
echo success >&2
;;
1)
echo 'Must supply a parameter, exiting.' >&2
exit 1
;;
*)
echo "Unknown error $status, exiting." >&2
exit "$status"
esac
45. y=$(( array[$x] ))
Поскольку POSIX выражает арифметическую подстановку (arithmetic expansion) словами (разложение подстановок команд вызывается после параметрической подстановки), то подстановка индекса массива (array subscript) внутри арифметической подстановки может привести к внедрению эксплойтов. Да, получается много больших, запутанных слов.
$ x='$(date >&2)' # перенаправление только для того, чтобы видеть, что происходит
$ y=$((array[$x])) # массив даже не нужно создавать
Mon Jun 2 10:49:08 EDT 2014
Не поможет и использование кавычек:
$ y=$((array["$x"]))
Mon Jun 2 10:51:03 EDT 2014
Работают два способа:
# 1. Изолирование $x, чтобы он не был разложен раньше времени.
$ y=$((array[\$x]))
# 2. Использование полного синтаксиса ${array[$x]}.
$ y=$((${array[$x]}))
46. read num; echo $((num+1))
Всегда валидируйте входные данные (см. BashFAQ/054), прежде чем использовать num в арифметическом контексте, поскольку он позволяет выполнять внедрение чужеродного кода.
$ echo 'a[$(echo injection >&2)]' | bash -c 'read num; echo $((num+1))'
injection
1
47. IFS=, read -ra fields <<< "$csv_line"
Это может показаться невероятным, но POSIX подходит к IFS как к прерывателю поля (field terminator), а не к разделителю полей. В нашем примере это означает, что если в конце строки ввода есть пустое поле, то оно будет отброшено:
$ IFS=, read -ra fields <<< "a,b,"
$ declare -p fields
declare -a fields='([0]="a" [1]="b")'
Куда делось пустое поле? Оно пропало по историческим причинам («потому что всегда так делалось»). Такое поведение характерно не только для Bash, это делают все совместимые оболочки. Непустое поле сканируется корректно:
$ IFS=, read -ra fields <<< "a,b,c"
$ declare -p fields
declare -a fields='([0]="a" [1]="b" [2]="c")'
Что нам делать с этой ерундой? Судя по всему, добавление IFS-символа в конец входной строки заставит сканирование работать правильно. Если замыкающее поле пустое, то дополнительный IFS-символ «прерывает» его, чтобы оно было просканировано. А если замыкающее поле непустое, то IFS-символ создаёт новое, пустое поле, которое и теряется.
$ input="a,b,"
$ IFS=, read -ra fields <<< "$input,"
$ declare -p fields
declare -a fields='([0]="a" [1]="b" [2]="")'
48. export CDPATH=.:~/myProject
Не экспортируйте CDPATH. Настраивание CDPATH в .bashrc не является проблемой, но экспортирование приведёт к тому, что выполняемый Bash- или sh-скрипт, использующий
cd, может повести себя иначе. Есть две проблемы. Скрипт, делающий следующее: cd some/dir || exit
cmd to be run in some/dir
Может изменить папку с
./some/dir на ~/myProject/some/dir, в зависимости от того, какие папки существуют в данный момент. Так что cd может отправить скрипт в ошибочную папку, что может оказать негативное влияние на следующие команды, которые теперь выполняются не там, где задумано.Вторая проблема — когда
cd выполняется в контексте, где захватываются выходные данные: output=$(cd some/dir && some command)
Когда CDPATH настроен, то в качестве побочного эффекта
cd может выдать stdout нечто вроде /home/user/some/dir, чтобы показать, что папка найдена через CDPATH, который завершится в выходной переменной с ожидаемыми выходными данными some command. Скрипт может обрести иммунитет к CDPATH, унаследованному от среды, благодаря обязательному использованию
./ для относительных путей. Или можно в начале скрипта запустить unset CDPATH, но не думайте, что каждый автор скриптов учитывает этот подводный камень, так что не экспортируйте CDPATH.