

Приятно иметь в поездке надежный и быстрый интернет, особенно когда ехать придется не один час! Если путь пролегает в густонаселенном районе — на любом современном телефоне с поддержкой сетей 4G, обычно всё просто работает, мы продолжаем пользоваться интернетом, как привыкли. Естественно, всё меняется, когда выезжаешь за пределы населенных пунктов.
В движущийся транспорт интернет можно подать только двумя путями:
- «С неба». Спутник, стратостаты и прочие технологии, которые ретранслируют канал передачи данных «сверху».
- С помощью наземной инфраструктуры. Любые способы передачи радиосигнала через базовые станции, установленные на земле. Это может быть инфраструктура сотовых операторов, Wi-Fi-инфраструктура, дедушка радио Ethernet и т. д.
Бюджета на создания своей инфраструктуры для передачи данных никто в здравом уме, конечно же, не выделит, поэтому в распоряжении есть только спутниковый канал и инфраструктура «сотовиков». Выбор еще раз упростился, когда финмодель заказчика не выдержала реализации через спутниковый канал. Поэтому дальше речь пойдет о том, как подать в движущийся транспорт максимально устойчивый канал через операторов сотовой связи.
Суть агрегации каналов передачи данных можно выразить коротко: суммировать емкость, предоставленную разными физическими линиями. Условно, если у нас есть четыре канала емкостью 1 Мбит/с каждый, на выходе мы должны получить один канал емкостью 4 Мбит/с. В нашем случае есть четыре оператора сотовой связи, через каждый из них в пределе можно выжать до 70 Мбит/с, а в сумме, если звезды сойдутся правильно, — 280 Мбит/с.
Кто-то скажет, что 280 Мбит/с никак не хватит на всех пассажиров поезда, коих в среднем 700 человек, и что получить такую скорость за пределами населенных пунктов нельзя. Более того, там, где связи нет совсем, никакой магии не произойдет: в транспорте также связи не будет. Конечно, этот кто-то совершенно прав. Поэтому мы решаем задачу не комфортного канала для всех, а хоть какого-то — там, где обычные смартфоны физически не в состоянии установить связь.
Этот пост о том, как нам пришлось с нуля изобрести велосипед, чтобы добыть интернет в автомобильном и железнодорожном транспорте для одного индийского оператора железнодорожных путей, как мы фиксировали перемещения этого транспорта и качество канала передачи данных в каждой точке пути с последующим хранением в кластере Tarantool.
Суть проекта
Агрегация решает задачу отказоустойчивости и/или суммирования емкости каналов передачи данных, участвующих в агрегации. В зависимости от типа агрегации, топологии сети и оборудования реализация может кардинально отличаться.
Каждый тип агрегации достоин отдельной статьи, но у нас конкретная задача: насколько возможно, обеспечить надежным и максимально «широким» каналом ПД транспортные средства.
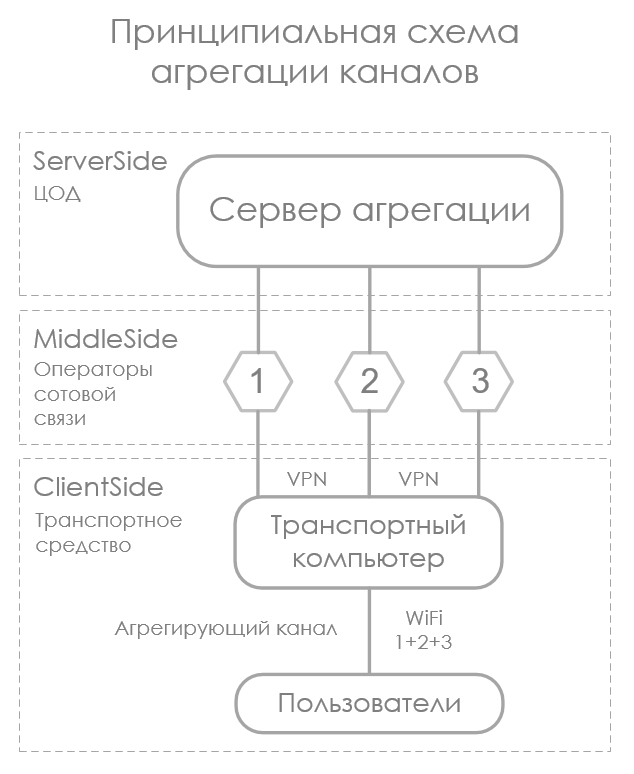
Инфраструктура операторов сотовой связи дает основу для задачи:
- Конвергентная среда. Передача данных происходит через открытый интернет и разных операторов связи. Это значит, что EtherChannel и другие аппаратно поддерживаемые протоколы работать, естественно, не будут.
- Высокая энтропия каналов ПД при движении транспорта. Емкость и задержка в каждом канале непредсказуемо и быстро изменяется, поскольку сильно зависит от расстояния до БС оператора, ее загрузки, помех и т. д.
Технически агрегация очень проста и многократно описана, вы без труда сможете найти информацию любой глубины изложения. Вкратце суть такая.
Со стороны клиентского оборудования:
- Настройка сети. Через независимые каналы передачи данных устанавливаются L3-тоннели до единой точки агрегации (любой внешний сервер с настроенным NAT). Один канал — один тоннель. Поднимается интерфейс, который будет шлюзом по умолчанию для всей сети.
- Специальное ПО. Делает всего две вещи: мониторит целевые метрики качества каналов и тоннелей, потом на основе метрик распределяет NAT-трафик по тоннелям.
Необходимость самостоятельно анализировать каналы через разных операторов сотовой связи с мониторингом уровня сигнала оператора, типа связи, информации о загрузке базовой станции, ошибок в сети передачи данных оператора (не путать с L3-тоннелем) и на основе этих метрик распределять поток данных разрешает Google сообщить нам, что придется писать решение самостоятельно.
К слову, есть решения разного уровня приемлемости, в которых агрегация работает. Например, стандартный bonding интерфейсов в Linux. Поднимаем L3-тоннель через любой доступный инструментарий, хоть через VPN-сервер или SSH-тоннель, настраиваем вручную маршрутизацию и добавляем в бондинг виртуальные интерфейсы тоннелей. Всё будет нормально, пока емкость тоннелей в каждый момент времени одинакова. Дело в том, что при такой топологии сети работает только режим агрегации balance-rr, т. е. в каждый тоннель попадает равное количество байтов по очереди. Это значит, что если у нас будет три канала емкостью (Мбит/с) 100, 100 и 1, то результирующая емкость окажется 3 Мбит/с. То есть минимальная ширина канала умножается на количество каналов. Если емкость — 100, 100, 100, то результирующая будет 300.
Есть другое решение: прекрасный opensource-проект Vtrunkd, который после долгого забвения был реанимирован в 2016 году. Там уже есть почти всё, что нужно. Мы честно написали создателям, что готовы заплатить за доработку решения в части мониторинга метрик качества связи сотовых операторов и включить эти метрики в механизм распределения трафика, но ответа, к сожалению, так и не получили, поэтому решили написать свой вариант с нуля.
Qedr Summa
Начали с мониторинга метрик операторов сотовой связи (уровень сигнала, тип сети, ошибки сети и т. д.) Нужно отметить, что модемы выбирались как раз исходя из того, как хорошо они могут отдавать метрики операторов. Мы выбрали модем SIM7100 производства компании Simcom. Все интересующие нас метрики отдаются через обращение в последовательный порт. Этот же модем также отдает GPS/ГЛОНАСС-координаты с хорошей точностью. Также необходимо отслеживать статус метрик компьютера (температуру CPU, SSD, свободное количество оперативной памяти и дискового пространства, S.M.A.R.T. показатели SSD). Отдельно модуль мониторит статистику сетевых интерфейсов (наличие ошибок на прием и отправку, длина очереди на отправку, количество переданных байтов). Поскольку производительность устройства крайне ограничена и пакет передаваемых данных должен быть минимален, а также учитывая простоту мониторинга этих метрик под Linux через /proc/sys, вся подсистема мониторинга также была разработана с нуля.
После того как модуль мониторинга метрик был готов, приступили к сетевой части: программной агрегации каналов. К сожалению, детальный алгоритм — коммерческая тайна, опубликовать его я не могу. Всё же опишу в общих чертах, как работает модуль агрегации, установленный в транспорте:
- При запуске читает конфиг в формате JSON, в котором описаны настройки виртуальных интерфейсов. Адреса серверов агрегации подтягиваются из центральной системы динамически. Это обеспечивает балансинг нагрузки на серверную часть и условно бесшовный хендовер при сбое любого сервера агрегации.
- На основе прочитанных данных создает L3-тоннели до серверов агрегации. Настраивает маршрутизацию. Тоннель опционально может иметь сжатие данных и шифрование.
- На основе данных от модуля мониторинга присваивает каждому тоннелю свой «вес». Чем больше вес, тем больше трафика пойдет именно через этот тоннель. Вес каждого тоннеля актуализируется каждую секунду
- Статистика работы устройства, геопозиция и метрики бизнес-логики накапливаются в течение 10 минут, формируется транзакция. Транзакции хранятся в локальной базе Tarantool и отправляются в «голову» нативным механизмом репликации данных СУБД «Тarantool», за что отдельное спасибо разработчикам и активному комьюнити этой СУБД.
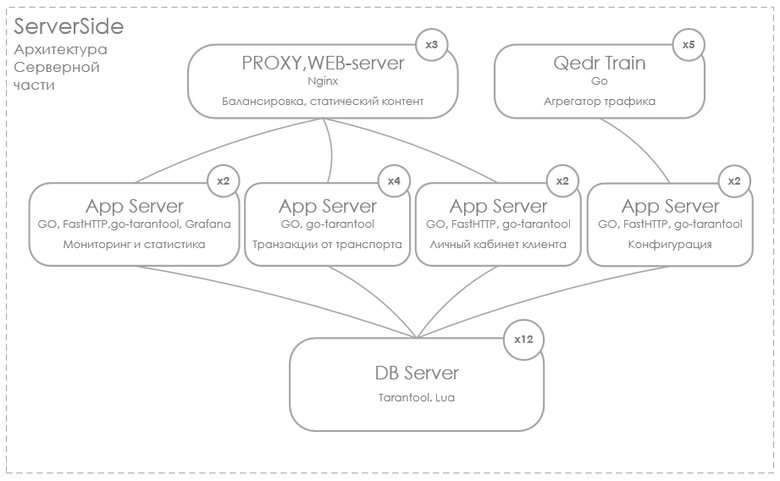
Серверная часть агрегации работает радикально проще. При старте модуль агрегации обращается к серверу настроек, получает конфигурацию в JSON-формате и на ее основе запускает L3-интерфейсы. В целом всё тривиально.
Отдельно стоит описать систему сбора и визуализации всех метрик проекта. Она поделена на две большие части. Первая часть — мониторинг систем жизнеобеспечения клиентского и серверного оборудования. Вторая — мониторинг бизнес-метрик работы проекта.
Стек технологий проекта стандартный. Визуализация: Grafana, OpenStreetMap, сервер приложений на клиентской и серверной стороне: Go, СУБД Tarantool.
Tarantool
История эволюции СУБД в наших проектах начинается с PostgreSQL в 2009 году. Мы успешно хранили в нем геоданные от бортовых устройств, установленных на спецтранспорте. Модуль PostGIS вполне справлялся с задачами. Со временем очень сильно стало не хватать производительности в обработке данных без схемы хранения. Экспериментировали с MongoDB c версии 2.4 до версии 3.2. Пару раз не смогли восстановить данные после аварийного отключения (полностью дублировать данные не позволял бюджет). Далее обратили внимание на ArangoDB. Если учесть, что бэкенд в то время мы писали на JavaScript, стек технологий выглядел очень приятно. Однако и эта базейка, побыв с нами добрые два года, ушла в прошлое: мы не смогли контролировать потребление оперативной памяти на больших объемах данных. В этом проекте обратили внимание на Tarantool. Ключевым для нас было следующее:
- Встроенный механизм транзакций.
- Хранение нереляционных данных.
- Система хранения данных InMemory и Vinyl (на диске).
- Механизм мастер-слейв репликации.
- Эффективная работа на мощном железе в ЦОДе и на очень ограниченном оборудовании в транспортном средстве.
На первый взгляд, всё в ней хорошо, за исключением того, что работает она только на одном ядре процессора. Ради науки провели ряд экспериментов, чтобы понять, будет ли это препятствием. После тестов на целевом железе убедились, что для этого проекта СУБД справляется с обязанностями прекрасно.
У нас всего три основных профиля данных: это финансовые операции, временные ряды (т. е. журналы работы систем) и геоданные.
Финансовые операции — это информация о движении денег по лицевому счету каждого устройства. Любое устройство имеет как минимум три SIM-карты от разных операторов связи, поэтому нужно контролировать баланс лицевого счета у каждого оператора связи и, чтобы не допустить отключения, заранее знать, когда пополнить баланс для каждого оператора каждого устройства.
Временные ряды — просто журналы мониторинга от всех подсистем, включая журнал совокупной пропускной полосы для каждого устройства в транспорте. Это дает нам возможность знать, в какой точке пути какой был канал по каждому оператору. Эти данные используются для аналитики покрытия сетью, что, в свою очередь, нужно для упреждающего переключения и развесовки каналов по операторам связи. Если мы заранее знаем, что в конкретной точке у такого-то оператора худшее качество, мы заранее отключаем этот канал из агрегации.
Геоданные — простой трек транспортного средства по пути следования. Каждую секунду мы опрашиваем GPS-датчик, встроенный в модем, и получаем координаты и высоту над уровнем моря. Трек длительностью 10 минут собирается в пакет и отправляется в ЦОД. По требованию заказчика эти данные должны храниться вечно, что при возрастающем количестве транспортных средств заставляет заранее очень серьезно планировать инфраструктуру. Однако в Tarantool шардинг сделан очень просто, и ломать голову над масштабированием хранилища под самые быстрорастущие данные никакой необходимости нет. Резервная копия данных не пишется, поскольку исторической ценности сейчас в этих данных нет.
Для всех типов данных мы использовали движок Vinyl (хранение данных на диске). Финансовых операций не так много, и нет смысла всегда хранить их в памяти, как и журналы, естественно, и геоданные, пока по ним не будет производиться аналитика. Когда аналитика потребуется, в зависимости от требований к быстродействию, возможно, будет иметь смысл подготовить уже агрегированные данные и хранить их на движке InMemory, а далее анализировать эти данные. Но всё это начнется, когда заказчик сформирует свои требования.
Важно отметить, что Tarantool прекрасно справился с нашей задачей. Он одинаково комфортно себя чувствует на ограниченном в ресурсах устройстве и в ЦОДе на десять шардов. Спецификация устройств, которые стоят в транспорте:
CPU: ARMv8, 4Core, 1.1 Ghz
RAM: 2 Gb
Storage: 32 GB SSD
Спецификация сервера ЦОДа:
СPU x64 Intel Corei7, 8Core, 3.2 Ghz
RAM: 32 Gb
Storage: 2 × 512 Gb (Soft Raid 0)
Как я уже говорил, репликация данных из транспорта в ЦОД налажена средствами самой СУБД. Шардинг данных между десятью шардами — также функционал «из коробки». Вся информация присутствует на сайте Tarantool, и описывать это тут, думаю, не нужно. В настоящий момент система обслуживает всего 866 транспортных средств. Заказчик планирует расширение до 8 тысяч.
Александр Родин, Национальные транспортные и телематические системы. Если возникнут вопросы, пишите в комменты или на a.rodin@qedr.com. Постараюсь по возможности ответить всем.
