

Недавно мы писали о забавных, хитрых и странных примерах на JavaScript. Теперь пришла очередь Python. У Python, высокоуровневого и интерпретируемого языка, много удобных свойств. Но иногда результат работы некоторых кусков кода на первый взгляд выглядит неочевидным.
Ниже — забавный проект, в котором собраны примеры неожиданного поведения в Python с обсуждением того, что происходит под капотом. Часть примеров не относятся к категории настоящих WTF?!, но зато они демонстрируют интересные особенности языка, которых вы можете захотеть избегать. Я думаю, это хороший способ изучить внутреннюю работу Python, и надеюсь, вам будет интересно.
Если вы уже опытный программист на Python, то многие примеры могут быть вам знакомы и даже вызовут ностальгию по тем случаям, когда вы ломали над ними голову :)
Содержание
- Структура примеров
- Использование
- Примеры
- Пропуск строк?
- Ну, как-то сомнительно...
- Время для хеш-пирожных!
- Несоответствие времени обработки
- Преобразование словаря во время его итерирования
- Удаление элемента списка во время его итерирования
- Обратные слеши в конце строки
- Давайте сделаем гигантскую строку!
- Оптимизации интерпретатора конкатенации строк
- Да, оно существует!
isне то, что оно естьis not ...отличается отis (not ...)- Функция внутри цикла выдаёт один и тот же результат
- Утечка переменных цикла из локальной области видимости
- Крестики-нолики, где Х побеждает с первой попытки
- Опасайтесь изменяемых аргументов по умолчанию
- Те же операнды, но другая история
- Изменение неизменяемого
- Использование переменной, не определённой в области видимости
- Исчезновение переменной из внешней области видимости
Returnвозвращает везде- Когда True на самом деле False
- Будьте осторожны с цепочками операций
- Разрешение имён (name resolution) игнорирует область видимости класса
- От заполненности до None в одной инструкции
- Явное приведение типов в строковых значениях
- Атрибуты классов и экземпляров
- Ловля исключений
- Полночь не существует?
- Что не так с булевыми значениями?
- Игла в стоге сена
- For что?
- Узел not
- А вы могли такое предположить?
- Мелкие примеры
- Внести свой вклад
- Полезные ссылки
Структура примеров
Примечание: Все приведённые примеры протестированы на интерактивном интерпретаторе Python 3.5.2 и должны работать во всех версиях языка, если иное явно не указано в описании.
Структура примеров:
Какой-нибудь дурацкий заголовок
# Код.
# Подготовка к магии...Результат (версия Python):
>>> инициирующее_выражение
Вероятно, неожиданный результат(Опционально): Однострочное описание неожиданного результата.
Объяснение:
Краткое объяснение того, что произошло и почему.
Поясняющие примеры (если необходимо)
Результат:
>>> инициирование # какого-то примера, срывающего покровы с магии # объясняющий результат
Использование
Мне кажется, что лучший способ извлечь максимальную пользу из этих примеров — это читать их в хронологическом порядке:
Внимательно изучать начальный код. Если вы опытный Python-программист, то чаще всего будете успешно предсказывать, что произойдёт.
Изучать результаты и:
- Проверять, совпали ли они с вашими ожиданиями.
- Убеждаться, что вы понимаете, почему получен именно такой результат.
- Если не понимаете, то читайте объяснение (если всё равно не понимаете, то заорите и напишите здесь).
- Если понимаете, то погладьте себя по головке и переходите к следующему примеру.
P. S. Также можете читать эти примеры в командной строке. Только сначала установите npm-пакет wtfpython,
$ npm install -g wtfpythonТеперь запустите wtfpython в командной строке, и в результате эта коллекция откроется в вашем $PAGER.
#TODO: Добавьте пакет pypi для чтения в командной строке.
Примеры
Пропуск строк?
Результат:
>>> value = 11
>>> valuе = 32
>>> value
11Wat?
Примечание: проще всего воспроизвести этот пример с помощью копирования и вставки в ваш файл/оболочку.
Объяснение
Некоторые Unicode-символы выглядят так же, как и ASCII, но различаются интерпретатором.
>>> value = 42 #ascii e
>>> valuе = 23 #cyrillic e, Python 2.x interpreter would raise a `SyntaxError` here
>>> value
42Ну, как-то сомнительно...
def square(x):
"""
Простая функция для вычисления квадрата числа путём сложения.
"""
sum_so_far = 0
for counter in range(x):
sum_so_far = sum_so_far + x
return sum_so_farРезультат (Python 2.x):
>>> square(10)
10Разве должно было получиться не 100?
Примечание: если не можете воспроизвести результат, попробуйте запустить в оболочке файл mixed_tabs_and_spaces.py.
Объяснение
- Не смешивайте табуляцию и пробелы! Символ, предшествующий return, это табуляция, он распознаётся как четыре пробела.
- Вот как Python обрабатывает табуляции:
Сначала они заменяются (слева направо) пробелами, от одного до восьми, так что общее количество заменяемых символов может быть в восемь раз больше... - Поэтому табуляция в последней строке функции
squareзаменяется восемью пробелами и попадает в цикл. - Python 3 в таких случаях умеет автоматически кидать ошибку.
Результат (Python 3.x):
TabError: inconsistent use of tabs and spaces in indentationВремя для хеш-пирожных!
1.
some_dict = {}
some_dict[5.5] = "Ruby"
some_dict[5.0] = "JavaScript"
some_dict[5] = "Python"Результат:
>>> some_dict[5.5]
"Ruby"
>>> some_dict[5.0]
"Python"
>>> some_dict[5]
"Python"Python уничтожил существование JavaScript?
Объяснение
Словари в Python проверяют эквивалентность и сравнивают значение хешей, чтобы определить, одинаковы ли два ключа.
Неизменяемые объекты с одинаковыми значениями в Python всегда получают одинаковые хеши.
>>> 5 == 5.0 True >>> hash(5) == hash(5.0) True
Примечание: объекты с разными значениями тоже могут получить одинаковые хеши (такая ситуация называется хеш-коллизией).
При выполнении выражения
some_dict[5] = "Python"существующее выражение «JavaScript» переписывается на «Python», потому что Python распознаёт5и5.0как одинаковые ключи словаряsome_dict.
На StackOverflow прекрасно объясняется причина такого поведения.
Несоответствие времени обработки
array = [1, 8, 15]
g = (x for x in array if array.count(x) > 0)
array = [2, 8, 22]Результат:
>>> print(list(g))
[8]Объяснение
- В выражении генератора клауза
inобрабатывается во время объявления, а условная клауза — во время run time. - Поэтому перед run time выполняется переприсваивание
arrayк списку[2, 8, 22], а поскольку из1,8и15только значение счётчика8больше0, то генератор выдаёт только8.
Преобразование словаря во время его итерирования
x = {0: None}
for i in x:
del x[i]
x[i+1] = None
print(i)Результат:
0
1
2
3
4
5
6
7Да, выполняется ровно восемь раз и останавливается.
Объяснение:
- В языке не поддерживается возможность итерирования словаря, который вы редактируете.
- Выполняется восемь раз потому, что в этом месте словарь увеличивается, чтобы вмещать больше ключей (у нас восемь записей удаления, так что нужно менять размер словаря). Это особенности реализации.
- Аналогичный пример разбирается на StackOverflow.
Удаление элемента списка во время его итерирования
list_1 = [1, 2, 3, 4]
list_2 = [1, 2, 3, 4]
list_3 = [1, 2, 3, 4]
list_4 = [1, 2, 3, 4]
for idx, item in enumerate(list_1):
del item
for idx, item in enumerate(list_2):
list_2.remove(item)
for idx, item in enumerate(list_3[:]):
list_3.remove(item)
for idx, item in enumerate(list_4):
list_4.pop(idx)Результат:
>>> list_1
[1, 2, 3, 4]
>>> list_2
[2, 4]
>>> list_3
[]
>>> list_4
[2, 4]Знаете, почему получился результат [2, 4]?
Объяснение:
Менять объект во время его итерирования — всегда плохая идея. Лучше тогда итерировать копию объекта, что и делает
list_3[:].
>>> some_list = [1, 2, 3, 4] >>> id(some_list) 139798789457608 >>> id(some_list[:]) # Notice that python creates new object for sliced list. 139798779601192
Разница между
del,removeиpop:
del var_nameпросто убирает привязкуvar_nameлокального или глобального пространства имён (поэтомуlist_1остаётся незатронутым).
removeубирает первое совпадающее значение, а не конкретный индекс, вызываяValueErrorпри отсутствии значения.
popубирает элемент с конкретным индексом и возвращает его, вызываяIndexError, если задан неверный индекс.
Почему получилось [2, 4]?
- Список итерируется индекс за индексом, и когда мы убираем
1изlist_2илиlist_4, то содержимым списков становится[2, 3, 4]. Оставшиеся сдвигаются вниз, то есть2оказывается на индексе 0,3— на индексе 1. Поскольку следующая итерация будет выполняться применительно к индексу 1 (где у нас3),2окажется пропущена. То же самое произойдёт с каждым вторым элементом в списке. Похожий пример, связанный со словарями в Python, прекрасно объяснён на StackOverflow.
Обратные слеши в конце строки
Результат:
>>> print("\\ some string \\")
>>> print(r"\ some string")
>>> print(r"\ some string \")
File "<stdin>", line 1
print(r"\ some string \")
^
SyntaxError: EOL while scanning string literalОбъяснение
- В необработанном строковом литерале (raw string literal), на что указывает префикс
r, обратный слеш не имеет особого значения. - Но интерпретатор меняет поведение обратных слешей, в результате они и последующий символ просто пропускаются. Поэтому обратные слеши в конце необработанных строк не действуют.
Давайте сделаем гигантскую строку!
Это вовсе не WTF, а лишь некоторые прикольные вещи, и их нужно опасаться :)
def add_string_with_plus(iters):
s = ""
for i in range(iters):
s += "xyz"
assert len(s) == 3*iters
def add_string_with_format(iters):
fs = "{}"*iters
s = fs.format(*(["xyz"]*iters))
assert len(s) == 3*iters
def add_string_with_join(iters):
l = []
for i in range(iters):
l.append("xyz")
s = "".join(l)
assert len(s) == 3*iters
def convert_list_to_string(l, iters):
s = "".join(l)
assert len(s) == 3*itersРезультат:
>>> timeit(add_string_with_plus(10000))
100 loops, best of 3: 9.73 ms per loop
>>> timeit(add_string_with_format(10000))
100 loops, best of 3: 5.47 ms per loop
>>> timeit(add_string_with_join(10000))
100 loops, best of 3: 10.1 ms per loop
>>> l = ["xyz"]*10000
>>> timeit(convert_list_to_string(l, 10000))
10000 loops, best of 3: 75.3 µs per loopОбъяснение
- Можете подробнее почитать про timeit. Обычно с её помощью измеряют, как долго выполняются фрагменты кода.
- Не используйте
+для генерирования длинных строк: в Pythonstr— неизменяемая, поэтому для каждой пары конкатенаций левая и правая строки должны быть скопированы в новую строку. Если вы конкатенируете четыре строки длиной по 10 символов, то копируйте (10 + 10) + ((10 + 10) + 10) + (((10 + 10) +10) +10) = 90 символов вместо 40. По мере увеличения количества и размера строк ситуация вчетверо ухудшается. - Поэтому рекомендуется использовать синтаксис
.format.или%(но на коротких строках это работает чуть медленнее, чем +). - А если ваш контент уже доступен в виде итерируемого объекта, то лучше выбирать гораздо более быстрое
''.join(iterable_object).
Оптимизации интерпретатора конкатенации строк
>>> a = "some_string"
>>> id(a)
140420665652016
>>> id("some" + "_" + "string") # Notice that both the ids are same.
140420665652016
# using "+", three strings:
>>> timeit.timeit("s1 = s1 + s2 + s3", setup="s1 = ' ' * 100000; s2 = ' ' * 100000; s3 = ' ' * 100000", number=100)
0.25748300552368164
# using "+=", three strings:
>>> timeit.timeit("s1 += s2 + s3", setup="s1 = ' ' * 100000; s2 = ' ' * 100000; s3 = ' ' * 100000", number=100)
0.012188911437988281Объяснение:
+=быстрее+более чем двух строк, потому что первая строка (например,s1дляs1 += s2 + s3) не уничтожается, пока строка не будет обработана целиком.- Обе строки ссылаются на один объект, потому что оптимизация CPython в некоторых случаях старается использовать существующие неизменяемые объекты (особенность реализации), а не создавать каждый раз новые. Почитать подробнее.
Да, оно существует!
Клауза else для циклов. Типичный пример:
def does_exists_num(l, to_find):
for num in l:
if num == to_find:
print("Exists!")
break
else:
print("Does not exist")Результат:
>>> some_list = [1, 2, 3, 4, 5]
>>> does_exists_num(some_list, 4)Существует!
>>> does_exists_num(some_list, -1)Не существует.
Клауза else в обработке исключений. Пример:
try:
pass
except:
print("Exception occurred!!!")
else:
print("Try block executed successfully...")Результат:
Try block executed successfully...Объяснение:
- Клауза
elseисполняется после цикла только тогда, когда после всех итераций нет явногоbreak. - Клауза
elseпосле блокаtryтакже называется клаузой завершения (completion clause), поскольку доступностьelseв выраженииtryозначает, что блокtryуспешно завершён.
is не то, что оно есть
Этот пример очень широко известен.
>>> a = 256
>>> b = 256
>>> a is b
True
>>> a = 257
>>> b = 257
>>> a is b
False
>>> a = 257; b = 257
>>> a is b
TrueОбъяснение:
Разница между is и ==
- Оператор
isпроверяет, чтобы оба операнда ссылались на один объект (т. е. проверяет, идентичны ли они друг другу). - Оператор
==сравнивает значения операндов и проверяет на идентичность. - Так что
isиспользуется для эквивалентности ссылок, а==— для эквивалентности значений. Поясняющий пример:
>>> [] == []
True
>>> [] is [] # These are two empty lists at two different memory locations.
False256 — существующий объект, а 257 — нет
При запуске Python в памяти размещаются числа от -5 до 256. Они используются часто, так что целесообразно держать их наготове.
Цитата из https://docs.python.org/3/c-api/long.html
В текущей реализации поддерживается массив целочисленных объектов для всех чисел с –5 по 256, так что когда вы создаёте int из этого диапазона, то получаете ссылку на существующий объект. Поэтому должна быть возможность изменить значение на 1. Но подозреваю, что в этом случае поведение Python будет непредсказуемым. :-)
>>> id(256)
10922528
>>> a = 256
>>> b = 256
>>> id(a)
10922528
>>> id(b)
10922528
>>> id(257)
140084850247312
>>> x = 257
>>> y = 257
>>> id(x)
140084850247440
>>> id(y)
140084850247344Интерпретатор оказался не так умён, и во время исполнения y = 257 не понял, что мы уже создали целое число со значением 257, поэтому создаёт в памяти другой объект.
a и b ссылаются на один объект при инициализации с одинаковым значением в одной строке.
>>> a, b = 257, 257
>>> id(a)
140640774013296
>>> id(b)
140640774013296
>>> a = 257
>>> b = 257
>>> id(a)
140640774013392
>>> id(b)
140640774013488- Когда в одной строке
aиbприсваивается значение257, интерпретатор Python создаёт новый объект, в то же время делая на него ссылку из второй переменной. Если же присвоить значения в разных строках, то интерпретатор не будет «знать», что у нас уже есть257в виде объекта. - Это оптимизация компилятора, специфически применяемая к интерактивному окружению. Когда вы вводите в работающий интерпретатор две строки, они компилируются, а значит, и оптимизируются раздельно. Если попробуете прогнать этот пример в файле
.py, то не увидите такого поведения, потому что файл компилируется за раз.
is not ... отличается от is (not ...)
>>> 'something' is not None
True
>>> 'something' is (not None)
FalseОбъяснение
is not— это одиночный бинарный оператор, поведение которого отличается от ситуации, когда по отдельности используютсяisиnot.is notвыдаётFalse, если переменные с обеих сторон оператора указывают на один объект. В противном случае выдаётсяTrue.
Функция внутри цикла выдает один и тот же результат
funcs = []
results = []
for x in range(7):
def some_func():
return x
funcs.append(some_func)
results.append(some_func())
funcs_results = [func() for func in funcs]Результат:
>>> results
[0, 1, 2, 3, 4, 5, 6]
>>> funcs_results
[6, 6, 6, 6, 6, 6, 6]Если до добавления some_func в funcs значения x в каждой итерации были разными, все функции возвращали 6.
//OR
>>> powers_of_x = [lambda x: x**i for i in range(10)]
>>> [f(2) for f in powers_of_x]
[512, 512, 512, 512, 512, 512, 512, 512, 512, 512]Объяснение
- При определении функции в цикле, в теле которого используется переменная цикла, замыкание функции цикла привязано к переменной, а не к её значению. Так что все функции для вычисления используют последнее значение, присвоенное переменной.
- Чтобы получить желаемое поведение, вы можете передавать в функцию переменную цикла в качестве именованной переменной. Почему это работает? Потому что таким образом переменная снова будет определена в области видимости функции.
funcs = []
for x in range(7):
def some_func(x=x):
return x
funcs.append(some_func)Результат:
>>> funcs_results = [func() for func in funcs]
>>> funcs_results
[0, 1, 2, 3, 4, 5, 6]Утечка переменных цикла из локальной области видимости
1.
for x in range(7):
if x == 6:
print(x, ': for x inside loop')
print(x, ': x in global')Результат:
6 : for x inside loop
6 : x in globalНо x не был определён для цикла вне области видимости.
2.
# This time let's initialize x first
x = -1
for x in range(7):
if x == 6:
print(x, ': for x inside loop')
print(x, ': x in global')Результат:
6 : for x inside loop
6 : x in global3.
x = 1
print([x for x in range(5)])
print(x, ': x in global')Результат (on Python 2.x):
[0, 1, 2, 3, 4]
(4, ': x in global')Результат (on Python 3.x):
[0, 1, 2, 3, 4]
1 : x in globalОбъяснение
- В Python циклы for используют то пространство видимости, в котором они существуют, не заботясь о своих определённых переменных цикла. Это относится и к ситуации, если мы до этого явно определили переменную цикла for в глобальном пространстве имён. Тогда она будет перепривязана к существующей переменной.
- Разница в результатах работы интерпретаторов Python 2.x и Python 3.x применительно к примеру с генерированием списков (list comprehension) может быть объяснена с помощью изменения, описанного в документации What’s New In Python 3.0:
«Для генерирования списков больше не поддерживается синтаксическая форма
[... for var in item1, item2, ...]. Используйте вместо неё[... for var in (item1, item2, ...)]. Также обратите внимание, что генерирования списков имеют разные семантики: они ближе к синтаксическому сахару применительно к генерирующему выражению внутри конструктораlist(), и, в частности, переменные управления циклом больше не утекают в окружающую область видимости».
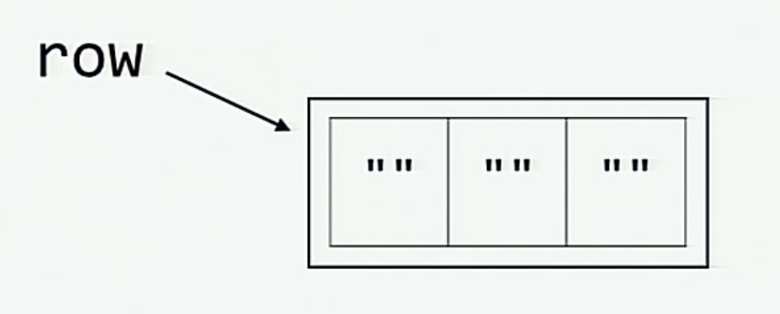
Крестики-нолики, где Х побеждает с первой попытки
# Let's initialize a row
row = [""]*3 #row i['', '', '']
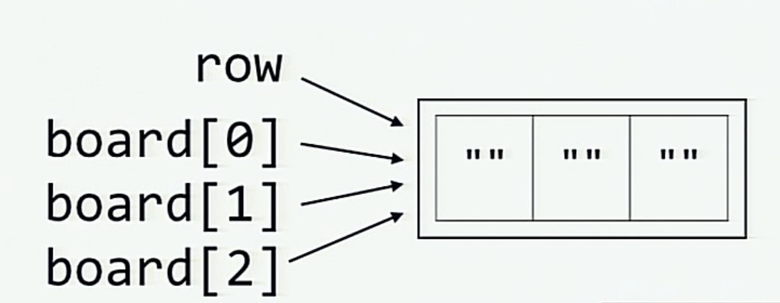
# Let's make a board
board = [row]*3Результат:
>>> board
[['', '', ''], ['', '', ''], ['', '', '']]
>>> board[0]
['', '', '']
>>> board[0][0]
''
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['X', '', ''], ['X', '', '']]Но мы же не присваивали три X, верно?
Объяснение
Эта визуализация объясняет, что происходит в памяти при инициализации переменной row:
А когда посредством умножения row инициализируется board, то в памяти происходит вот что (каждый из элементов board[0], board[1] и board[2] является ссылкой на один и тот же список, указанный в row):
Опасайтесь изменяемых аргументов по умолчанию
def some_func(default_arg=[]):
default_arg.append("some_string")
return default_argРезультат:
>>> some_func()
['some_string']
>>> some_func()
['some_string', 'some_string']
>>> some_func([])
['some_string']
>>> some_func()
['some_string', 'some_string', 'some_string']Объяснение
- В Python изменяемые аргументы по умолчанию на самом деле не инициализируются при каждом вызове функции. Вместо этого в качестве значения по умолчанию берётся недавно присвоенное значение. Когда мы явным образом передали
[]в качестве аргумента вsome_func, то для переменнойdefault_argне было использовано значение по умолчанию, поэтому функция вернула то, что ожидалось.
def some_func(default_arg=[]):
default_arg.append("some_string")
return default_argРезультат:
>>> some_func.__defaults__ #This will show the default argument values for the function
([],)
>>> some_func()
>>> some_func.__defaults__
(['some_string'],)
>>> some_func()
>>> some_func.__defaults__
(['some_string', 'some_string'],)
>>> some_func([])
>>> some_func.__defaults__
(['some_string', 'some_string'],)- Стандартный способ избежать багов из-за изменяемых аргументов — присваивание
Noneв качестве значения по умолчанию с последующей проверкой, передано ли какое-то значение в функцию, соответствующую этому аргументу. Пример:
def some_func(default_arg=None): if not default_arg: default_arg = [] default_arg.append("some_string") return default_arg
Те же операнды, но другая история
1.
a = [1, 2, 3, 4] b = a a = a + [5, 6, 7, 8]
Результат:
>>> a [1, 2, 3, 4, 5, 6, 7, 8] >>> b [1, 2, 3, 4]
2.
a = [1, 2, 3, 4] b = a a += [5, 6, 7, 8]
Результат:
>>> a [1, 2, 3, 4, 5, 6, 7, 8] >>> b [1, 2, 3, 4, 5, 6, 7, 8]
Объяснение
- Выражение
a += bведёт себя не так же, какa = a + b - Выражение
a = a + [5,6,7,8]генерирует новый объект и присваивает a ссылку на него, оставляяbбез изменений. - Выражение
a + =[5,6,7,8]фактически преобразуется (mapped to) в функцию extend, которая работает с объектом таким образом, чтоaиbвсё ещё указывают на один и тот же объект, который был изменён на месте.
Изменение неизменяемого
some_tuple = ("A", "tuple", "with", "values") another_tuple = ([1, 2], [3, 4], [5, 6])
Результат:
>>> some_tuple[2] = "change this" TypeError: 'tuple' object does not support item assignment >>> another_tuple[2].append(1000) #This throws no error >>> another_tuple ([1, 2], [3, 4], [5, 6, 1000]) >>> another_tuple[2] += [99, 999] TypeError: 'tuple' object does not support item assignment >>> another_tuple ([1, 2], [3, 4], [5, 6, 1000, 99, 999])
Но ведь кортежи неизменяемы, разве нет...
Объяснение
- Цитата из https://docs.python.org/2/reference/datamodel.html
Объект неизменяемого типа последовательности (immutable sequence type) не может измениться после своего создания. Если объект содержит ссылки на другие объекты, то эти объекты могут быть изменяемыми и могут быть изменены. Однако коллекцию объектов, на которую прямо ссылается неизменяемый объект, изменить нельзя.
- Оператор
+=изменяет список на месте. Присвоение элемента (item assignment) не работает, но, когда возникает исключение, элемент уже был изменён на месте.
Использование переменной, не определeнной в области видимости
a = 1 def some_func(): return a def another_func(): a += 1 return a
Результат:
>>> some_func() 1 >>> another_func() UnboundLocalError: local variable 'a' referenced before assignment
Объяснение
- Когда вы присваиваете переменную в области видимости, она становится локальной для этой области. То есть a становится локальной переменной области видимости
another_func, но она не была ранее инициализирована в той же области, которая кидает ошибку. - Почитайте это короткое замечательное руководство, чтобы больше узнать о том, как в Python работают пространства имён и разрешение области видимости (scope resolution).
- Используйте ключевое слово
globalдля модифицирования переменной внешней области видимостиaвanother_func.
def another_func() global a a += 1 return a
Результат:
>>> another_func() 2
Исчезновение переменной из внешней области видимости
e = 7 try: raise Exception() except Exception as e: pass
Результат (Python 2.x):
>>> print(e) # prints nothing
Результат (Python 3.x):
>>> print(e) NameError: name 'e' is not defined
Объяснение
Источник.
Если назначает исключение с целевымas, оно очищается в конце клаузыexcept. Как если бы
except E as N: foo
было преобразовано в
except E as N: try: foo finally: del N
Это означает, что исключение нужно назначать на другое имя, чтобы можно было ссылаться на него после клаузы
except. Исключения очищаются потому, что к ним прикрепляется обратная трассировка (traceback), в результате во фрейме стека формируется ссылочный цикл (reference cycle), поддерживающий все локалы в этом фрейме живыми, пока не пройдёт следующая итерация сборки мусора.
В Python клаузы не входят в область видимости. В этом примере всё представлено в одной области видимости, и переменная e убирается из-за исполнения клаузы
except. Но это не относится к функциям, имеющим отдельные внутренние области видимости. Иллюстрация:
def f(x): del(x) print(x)
x = 5
y = [5, 4, 3]
**Результат:**
f(x)
UnboundLocalError: local variable 'x' referenced before assignment
f(y)
UnboundLocalError: local variable 'x' referenced before assignment
x
5
y
[5, 4, 3]
- В Python 2.x имя переменной e присвоено экземпляру `Exception()`, так что при попытке вывода на экран вы ничего не увидите.
Результат (Python 2.x):
>>> e Exception() >>> print e # Nothing is printed!
Return возвращает везде
def some_func(): try: return 'from_try' finally: return 'from_finally'
Результат:
>>> some_func() 'from_finally'
Объяснение
- Когда в блоке
tryвыраженияtry…finallyвыполняетсяreturn,breakилиcontinue, то на выходе также исполняется клаузаfinally. - Возвращаемое функцией значение определяется последним выполненным выражением
return. Поскольку клаузаfinallyисполняется всегда, выражениеreturn, исполненное в клаузеfinally, всегда будет последним исполненным.
Когда True на самом деле False
True = False if True == False: print("I've lost faith in truth!")
Результат:
I've lost faith in truth!
Объяснение
- Изначально в Python не было типа
bool(программисты использовали 0 для false и ненулевое значение вроде 1 для true). Затем в язык добавилиTrue,Falseи типbool, но из-за обратной совместимости нельзя было сделатьTrueиFalseконстантами — они представляли собой просто встроенные переменные. - Python 3 стал обратно несовместимым, поэтому в нём наконец исправили ситуацию с булевыми значениями, так что этот пример не работает в Python 3.x!
Будьте осторожны с цепочками операций
>>> True is False == False False >>> False is False is False True >>> 1 > 0 < 1 True >>> (1 > 0) < 1 False >>> 1 > (0 < 1) False
Объяснение
Как сказано в https://docs.python.org/2/reference/expressions.html#not-in
Формально, если a, b, c, ..., y, z — выражения, а op1, op2, ..., opN —операторы сравнения, тогда a op1 b op2 c… y opN z эквивалентно op1 b и b op2 c и… y opN z, за исключением того, что каждое выражение вычисляется однократно.
Хотя такое поведение могло показаться вам глупостью, оно очень удобно в ситуациях вроде
a == b == c и 0 <= x <= 100.
False is False is Falseэквивалентно(False is False) and (False is False)True is False == FalseэквивалентноTrue is False and False == False, и поскольку первая часть выражения (True is False) вычисляется какFalse, то и всё выражение вычисляется какFalse.1 > 0 < 1эквивалентно1 > 0and0 < 1, что вычисляется какTrue.- Выражение
(1 > 0) < 1эквивалентноTrue < 1и
>>> int(True) 1 >>> True + 1 #not relevant for this example, but just for fun 2
Так что
1 < 1вычисляется какFalse
Разрешение имен игнорирует область видимости класса
1.
x = 5 class SomeClass: x = 17 y = (x for i in range(10))
Результат:
>>> list(SomeClass.y)[0] 5
2.
x = 5 class SomeClass: x = 17 y = [x for i in range(10)]
Результат (Python 2.x):
>>> SomeClass.y[0] 17
Результат (Python 3.x):
>>> SomeClass.y[0] 5
Объяснение
- Области видимости, вложенные внутрь определения класса, игнорируют имена, привязанные к уровню класса.
- Генерирующее выражение имеет собственную область видимости.
- Начиная с Python 3.X генераторы списков (list comprehensions) тоже имеют свои области видимости.
От заполненности до None в одной инструкции
some_list = [1, 2, 3] some_dict = { "key_1": 1, "key_2": 2, "key_3": 3 } some_list = some_list.append(4) some_dict = some_dict.update({"key_4": 4})
Результат:
>>> print(some_list) None >>> print(some_dict) None
Объяснение
Большинство методов, изменяющих элементы объектов последовательности/преобразования (sequence/mapping objects) вроде
list.append,dict.update,list.sortи т. д., изменяют объекты на месте и возвращаютNone. Причина — в улучшении производительности благодаря избеганию созданий копии объекта, если операцию можно выполнить на месте (взято отсюда)
Явное приведение типов в строковых значениях
Это вовсе не WTF, но у меня ушла куча времени на осознание того, что в Python существуют такие вещи. Делюсь с начинающими.
a = float('inf') b = float('nan') c = float('-iNf') #These strings are case-insensitive d = float('nan')
Результат:
>>> a inf >>> b nan >>> c -inf >>> float('some_other_string') ValueError: could not convert string to float: some_other_string >>> a == -c #inf==inf True >>> None == None # None==None True >>> b == d #but nan!=nan False >>> 50/a 0.0 >>> a/a nan >>> 23 + b nan
Объяснение
'inf'и'nan'— специальные строковые значения (чувствительные к регистру). Если явно привести их к типуfloat, то можно использовать их для представления, соответственно, математических «бесконечности» и «не числа».
Атрибуты классов и экземпляров
1.
class A: x = 1 class B(A): pass class C(A): pass
Результат:
>>> A.x, B.x, C.x (1, 1, 1) >>> B.x = 2 >>> A.x, B.x, C.x (1, 2, 1) >>> A.x = 3 >>> A.x, B.x, C.x (3, 2, 3) >>> a = A() >>> a.x, A.x (3, 3) >>> a.x += 1 >>> a.x, A.x (4, 3)
2.
class SomeClass: some_var = 15 some_list = [5] another_list = [5] def __init__(self, x): self.some_var = x + 1 self.some_list = self.some_list + [x] self.another_list += [x]
Результат:
>>> some_obj = SomeClass(420) >>> some_obj.some_list [5, 420] >>> some_obj.another_list [5, 420] >>> another_obj = SomeClass(111) >>> another_obj.some_list [5, 111] >>> another_obj.another_list [5, 420, 111] >>> another_obj.another_list is SomeClass.another_list True >>> another_obj.another_list is some_obj.another_list True
Объяснение
- Переменные классов и переменные в экземплярах классов внутренне обрабатываются как словари объектов классов. Если имя переменной не найдено в словаре текущего класса, то поиск выполняется в родительских классах.
- Оператор
+=модифицирует изменяемый объект на месте без создания нового объекта. Так что изменение атрибута одного экземпляра влияет также на другие экземпляры и атрибут класса.
Ловля исключений
some_list = [1, 2, 3] try: # This should raise an ``IndexError`` print(some_list[4]) except IndexError, ValueError: print("Caught!") try: # This should raise a ``ValueError`` some_list.remove(4) except IndexError, ValueError: print("Caught again!")
Результат (Python 2.x):
Caught! ValueError: list.remove(x): x not in list
Результат (Python 3.x):
File "<input>", line 3 except IndexError, ValueError: ^ SyntaxError: invalid syntax
Объяснение
- Для добавления нескольких исключений в клаузу
exceptвам нужно передавать их в первый аргумент в виде взятого в круглые скобки кортежа. Второй аргумент — опциональное имя, которое потом привязывается к экземпляру после кидаемого исключения. Пример:
some_list = [1, 2, 3] try: # This should raise a ``ValueError`` some_list.remove(4) except (IndexError, ValueError), e: print("Caught again!") print(e)
Результат (Python 2.x):
Caught again! list.remove(x): x not in list
Результат (Python 3.x):
File "<input>", line 4 except (IndexError, ValueError), e: ^ IndentationError: unindent does not match any outer indentation level
- Не рекомендуется отделять исключение от переменной с помощью запятой, это не работает в Python 3; нужно использовать
as. Пример:
some_list = [1, 2, 3] try: some_list.remove(4) except (IndexError, ValueError) as e: print("Caught again!") print(e)
Результат:
Caught again! list.remove(x): x not in list
Полночь не существует?
from datetime import datetime midnight = datetime(2018, 1, 1, 0, 0) midnight_time = midnight.time() noon = datetime(2018, 1, 1, 12, 0) noon_time = noon.time() if midnight_time: print("Time at midnight is", midnight_time) if noon_time: print("Time at noon is", noon_time)
Результат:
('Time at noon is', datetime.time(12, 0)) The midnight time is not printed.
Объяснение
До Python 3.5 булевым значением для объекта
datetime.timeбылоFalse, если требовалось представить полночь в формате UTC. Из-за этого могут возникать ошибки при использовании синтаксисаif obj: при проверке, имеет лиobjзначение null или другой эквивалент «пустоты».
Что не так с булевыми значениями?
1.
# A simple example to count the number of boolean and # integers in an iterable of mixed data types. mixed_list = [False, 1.0, "some_string", 3, True, [], False] integers_found_so_far = 0 booleans_found_so_far = 0 for item in mixed_list: if isinstance(item, int): integers_found_so_far += 1 elif isinstance(item, bool): booleans_found_so_far += 1
Результат:
>>> booleans_found_so_far 0 >>> integers_found_so_far 4
2.
another_dict = {} another_dict[True] = "JavaScript" another_dict[1] = "Ruby" another_dict[1.0] = "Python"
Результат:
>>> another_dict[True] "Python"
Объяснение
- Булевые значения — подкласс
int
>>> isinstance(True, int) True >>> isinstance(False, int) True - Целое число
Trueравно1, аFalse—0.
>>> True == 1 == 1.0 and False == 0 == 0.0 True - Причины описаны на StackOverflow.
Игла в стоге сена
Почти каждый Python-программист сталкивался с этой ситуацией.
t = ('one', 'two') for i in t: print(i) t = ('one') for i in t: print(i) t = () print(t)
Результат:
one two o n e tuple()
Объяснение
- Корректным выражением для ожидаемого поведения будет
t = ('one',)илиt = 'one', (отсутствует запятая), иначе интерпретатор решит, чтоtявляетсяstrи итерирует её символ за символом. - () — специальный токен, обозначающий пустой
tuple.
For что?
Предложено @MittalAshok.
some_string = "wtf" some_dict = {} for i, some_dict[i] in enumerate(some_string): pass
Результат:
>>> some_dict # An indexed dict is created. {0: 'w', 1: 't', 2: 'f'}
Объяснение
- Выражение
forопределено в учебнике Python как:
for_stmt: 'for' exprlist 'in' testlist ':' suite ['else' ':' suite]
Здесь
exprlist— цель присвоения. Это означает, что эквивалент{exprlist} = {next_value}исполняется для каждого элемента из итерируемых. Интересный пример предложен @tukkek:
for i in range(4): print(i) i = 10
Результат:
0 1 2 3
Вы думали, что цикл будет прогнан только один раз?
Объяснение
- Выражение присваивания
i = 10никогда не влияет на итерации цикла из-за особенностей работы цикла в Python. Перед началом каждой итерации следующий элемент, предоставленный итератором (range(4)в данном случае), распаковывается и присваивается к переменной из целевого списка (iв данном случае). - Функция
enumerate(some_string)в каждой итерации извлекает новое значениеi(счётчикAувеличивается) и символ изsome_string. Затем она задаёт (просто присваивает) этому символу ключiиз словаряsome_dict. Развёртку цикла можно упростить до:
>>> i, some_dict[i] = (0, 'w') >>> i, some_dict[i] = (1, 't') >>> i, some_dict[i] = (2, 'f') >>> some_dict
Узел not
Предложено @MostAwesomeDude.
x = True y = False
Результат:
>>> not x == y True >>> x == not y File "<input>", line 1 x == not y ^ SyntaxError: invalid syntax
Объяснение
- Старшинство оператора влияет на вычисление выражения, и в Python оператор
==выше по старшинству, чем операторnot. - Поэтому
not x == yэквивалентноnot (x == y), что эквивалентно выражениюnot (True == False), которое вычисляется какTrue. - Но
x == not yвыдаётSyntaxError, потому что его можно представить как эквивалент(x == not) y, а неx == (not y), как вы могли подумать в первый момент. - Парсер ожидает, что токен
not— часть оператораnot in(потому что операторы==иnot inимеют одинаковое старшинство), но когда следом за токеномnotон не находит токенin, то выдаёт SyntaxError.
А вы могли такое предположить?
a, b = a[b] = {}, 5
Результат:
>>> a {5: ({...}, 5)}
Объяснение
- Согласно языковой справке, оператор присваивания имеет форму:
(target_list "=")+ (expression_list | yield_expression)
а также:
Оператор присваивания обрабатывает список выражений (это может быть одиночное выражение или список выражений, разделённых запятыми, во втором случае получается кортеж) и присваивает единственный результирующий объект каждому элементу из списка, слева направо.
- Выражение
+в(target_list "=")+означает, что может быть один или несколько целевых списков. В этом случае целевыми списками являютсяa,bиa[b](обратите внимание, что список выражений только один, в нашем случае{},5). - После обработки списка выражений его значение распаковывается в целевой список слева направо. В нашем случае сначала кортеж
{},5распаковывается вa,b, и теперь у насa = {}иb = 5. aтеперь присваивается{}, который является изменяемым объектом.- Второй целевой список —
a[b](вы можете подумать, что будет выдана ошибка, потому чтоaиbне были перед этим определены. Но помните, мы просто присвоилиaк{}иbк5). - Теперь задаём ключ
5из словаря кортежу({}, 5), создавая тем самым циклическую ссылку ({...}в выходных данных ссылается на тот же объект, на который теперь ссылаетсяa). Более простой пример циклической ссылки:
>>> some_list = some_list[0] = [0] >>> some_list [[...]] >>> some_list[0] [[...]] >>> some_list is some_list[0] [[...]]
Аналогично вышеприведённому примеру (
a[b][0]это тот же объект, что иa)
- То есть вы можете разбить пример на:
a, b = {}, 5 a[b] = a, b
И циклическая ссылка может быть оправдана тем, что
a[b][0]является тем же объектом, что и
a >>> a[b][0] is a True
Мелкие примеры
Join()— это строковая операция (string operation), а не операция списка (list operation). В первое время это выглядит неочевидным.
Объяснение: еслиjoin()— это метод для строки, тогда он может оперировать любыми итерируемыми (списками, кортежами, итераторами). Если бы это был метод для списка, то он реализовывался бы каждым типом отдельно. Кроме того, нет смысла помещать предназначенный для строковых значений метод в API обычного объектаlist.- Несколько странно выглядящих, но семантически корректных выражений:
[] = ()(распаковывает пустойtupleв пустойlist)'a'[0][0][0][0][0]также семантически корректно, потому что строки в Python итерируемые.3 --0-- 5 == 8 и --5 == 5семантически верны и вычисляются какTrue.
- Python использует два байта для хранения локальной переменной в функции. В теории это означает, что в функции можно определить только 65 536 переменных. Но в Python есть удобное встроенное решение, которое позволяет хранить более 2^16 имён переменных. В этом коде показано, что произойдёт в стеке, когда определено более 65 536 локальных переменных (внимание: код выводит около 2^18 строк текста!):
import dis exec(""" def f():* """ + """ """.join(["X"+str(x)+"=" + str(x) for x in range(65539)])) f() print(dis.dis(f))
- Несколько потоков выполнения Python не будут работать параллельно (да, именно так!). Если вы создадите несколько потоков и попытаетесь запустить их параллельно, то из-за Global Interpreter Lock в Python все ваши потоки будут выполняться на одном ядре шаг за шагом. Для реального распараллеливания воспользуйтесь модулем многопроцессорной обработки.
- Создание срезов списка (list slicing) с выходящими за границы индексами не приведёт к ошибкам:
>>> some_list = [1, 2, 3, 4, 5] >>> some_list[111:] []
Внести свой вклад
Все патчи приветствуются! Только перед самой публикацией прошу сначала создавать тему:) Подробности описаны в CONTRIBUTING.md.
Полезные ссылки
• https://www.youtube.com/watch?v=sH4XF6pKKmk
• https://www.reddit.com/r/Python/comments/3cu6ej/what_are_some_wtf_things_about_python
• https://sopython.com/wiki/Common_Gotchas_In_Python
• https://stackoverflow.com/questions/530530/python-2-x-gotchas-and-landmines
• https://stackoverflow.com/questions/1011431/common-pitfalls-in-python (В этой теме на StackOverflow приведены полезные рекомендации, что можно и что нельзя делать в Python.) - Выражение
