

Мне давно было интересно, как сжимаются данные, в том числе в Zip-файлах. Однажды я решил удовлетворить своё любопытство: узнать, как работает сжатие, и написать собственную Zip-программу. Реализация превратилась в захватывающее упражнение в программировании. Получаешь огромное удовольствие от создания отлаженной машины, которая берёт данные, перекладывает их биты в более эффективное представление, а затем собирает обратно. Надеюсь, вам тоже будет интересно об этом читать.
В статье очень подробно объясняется, как работают Zip-файлы и схема сжатия: LZ77-сжатие, алгоритм Хаффмана, алгоритм Deflate и прочее. Вы узнаете историю развития технологии и посмотрите довольно эффективные примеры реализации, написанные с нуля на С. Исходный код лежит тут: hwzip-1.0.zip.
Я очень благодарен Ange Albertini, Gynvael Coldwind, Fabian Giesen, Jonas Skeppstedt (web), Primiano Tucci и Nico Weber, которые дали ценные отзывы на черновики этой статьи.
Содержание
- История
- Сжатие Lempel-Ziv (LZ77)
- Код Хаффмана
- Deflate
- Формат Zip-файлов
- HWZip
- Заключение
- Упражнения
- Полезные материалы
История
PKZip
В восьмидесятых и начале девяностых, до широкого распространения интернета, энтузиасты-компьютерщики использовали dial-up-модемы для подключения через телефонную сеть к сети Bulletin Board Systems (BBS). BBS представляла собой интерактивную компьютерную систему, которая позволяла пользователям отправлять сообщения, играть в игры и делиться файлам. Для выхода в онлайн достаточно было компьютера, модема и телефонного номера хорошей BBS. Номера публиковались в компьютерных журналах и на других BBS.
Важным инструментом, облегчающим распространение файлов, был архиватор. Он позволяет сохранять один или несколько файлов в едином файле-архиве, чтобы удобнее хранить или передавать информацию. А в идеале архив ещё и сжимал файлы для экономии места и времени на передачу по сети. Во времена BBS был популярен архиватор Arc, написанный Томом Хендерсоном из System Enhancement Associates (SEA), маленькой компании, которую он основал со своим шурином.
В конце 1980-х программист Фил Катц выпустил собственную версию Arc — PKArc. Она была совместима с SEA Arc, но работала быстрее благодаря подпрограммам, написанным на ассемблере, и использовала новый метод сжатия. Программа стала популярной, Катц ушёл с работы и создал компанию PKWare, чтобы сосредоточиться на дальнейшей разработке. Согласно легенде, большая часть работы проходила на кухне его матери в Глендейле, штат Висконсин.

Фотография Фила Катца из статьи в Milwaukee Sentinel, 19 сентября 1994.
Однако SEA не устраивала инициатива Катца. Компания обвинила его в нарушении товарного знака и авторских прав. Разбирательства и споры в сети BBS и мире ПК стали известны как Arc-войны. В конце концов, спор был урегулирован в пользу SEA.
Отказавшись от Arc, Катц в 1989 создал новый формат архивирования, который он назвал Zip и передал в общественное пользование:
Формат файлов, создаваемых этими программами, является оригинальным с первого релиза этого программного обеспечения, и настоящим передаётся в общественное пользование. Кроме того, расширение ".ZIP", впервые использованное в контексте ПО для сжатия данных в первом релизе этого ПО, также настоящим передаётся в общественное пользование, с горячей и искренней надеждой, что никто не попытается присвоить формат для своего исключительного использования, а, скорее, что он будет использоваться в связи с ПО для сжатия данных и создания библиотек таких классов или типов, которые создают файлы в формате, в целом совместимом с данным ПО.
Программа Катца для создания таких файлов получила название PKZip и скоро распространилась в мире BBS и ПК.
Одним из аспектов, который с наибольшей вероятностью поспособствовал успеху Zip-формата, является то, что с PKZip шла документация, Application Note, в которой подробно объяснялось, как работает формат. Это позволило другим изучить формат и создать программы, которые генерируют, извлекают или как-то иначе взаимодействуют с Zip-файлами.
Zip — это формат сжатия без потерь: после распаковки данные будут такими же, как перед сжатием. Алгоритм ищет избыточности в исходных данных и эффективнее представляет информацию. Этот подход отличается от сжатия с потерями, который используется в таких форматах, как JPEG и MP3: при сжатии выбрасывается часть информации, которая менее заметна для человеческого глаза или уха.
PKZip распространялась как Shareware: её можно было свободно использовать и копировать, но автор предлагал пользователям «зарегистрировать» программу. За $47 можно было получить распечатанную инструкцию, премиальную поддержку и расширенную версию приложения.

Одной из ключевых версий PKZip стала 2.04c, вышедшая 28 декабря 1992 (вскоре после неё вышла версия 2.04g). В ней по умолчанию использовался алгоритм сжатия Deflate. Версия определила дальнейший путь развития сжатия в Zip-файлах (статья, посвящённая релизу).

С тех пор Zip-формат используется во многих других форматах файлов. Например, Java-архивы (.jar), Android Application Packages (.apk) и .docx-файлы Microsoft Office используют Zip-формат. Во многих форматах и протоколах применяется тот же алгоритм сжатия, Deflate. Скажем, веб-страницы наверняка передаются в ваш браузер в виде gzip-файла, формат которого использует Deflate-сжатие.
Фил Катц умер в 2000-м. PKWare всё ещё существует и поддерживает Zip-формат, хотя компания сосредоточена в основном на ПО для защиты данных.
Info-ZIP и zlib
Вскоре после выхода PKZip в 1989-м начали появляться другие программы для распаковки Zip-файлов. Например, программа unzip, которая могла распаковывать на Unix-системах. В марте 1990-го был создан список рассылки под названием Info-ZIP.
Группа Info-ZIP выпустила бесплатные программы с открытым исходным кодом unzip и zip, которые использовались для распаковки и создания Zip-файлов. Код портировали во многие системы, и он до сих пор является стандартом для Zip-программ под Unix-системы. Позднее это помогло росту популярности Zip-файлов.
Однажды код Info-ZIP, который выполнял Deflate-сжатие и распаковку, был вынесен в отдельную библиотеку zlib, которую написали Jean-loup Gailly (сжатие) и Mark Adler (распаковка).

Jean-loup Gailly (слева) и Mark Adler (справа) на вручении им премии USENIX STUG Award в 2009-м.
Одна из причин создания библиотеки заключалась в том, что это обеспечивало удобство использования Deflate-сжатия в других приложениях и форматах, например, в новых gzip и PNG. Эти новые форматы были призваны заменить Compress и GIF, в которых применялся защищённый патентом алгоритм LZW.
В рамках создания этих форматов Питер Дойч написал спецификацию Deflate и опубликовал под названием Internet RFC 1951 в мае 1996-го. Это оказалось более доступное описание по сравнению с исходным PKZip Application Note.
Сегодня zlib используется повсеместно. Возможно, он сейчас отвечает за сжатие этой страницы на веб-сервере и её распаковки в вашем браузере. Сегодня сжатие и распаковка большинства Zip-файлов выполняется с помощью zlib.
WinZip
Многие из тех, кто не застал PKZip, пользовались WinZip. Пользователи ПК перешли как с DOS на Windows, так и с PKZip на WinZip.
Всё началось с проекта программиста Нико Мака, который создавал ПО для OS/2 в компании Mansfield Software Group в городе Сторрс-Мансфилд, штат Коннектикут. Нико использовал Presentation Manager, это графический пользовательский интерфейс в OS/2, и его расстраивало, что приходится переходить от файлового менеджера к DOS-командам каждый раз, когда он хотел создать Zip-файлы.
Мак написал простую программу с графическим интерфейсом, которая работала с Zip-файлами прямо в Presentation Manager, назвал её PMZip и выпустил в качестве shareware в 1990-м.
OS/2 так и не добилась успеха, а мир ПК захватывала Microsoft Windows. В 1991-м Мак решил научиться писать Windows-программы, и его первым проектом стало портирование своего Zip-приложения под новую ОС. В апреле 1991-го вышла WinZip 1.00. Она распространялась в качестве shareware с 21-дневным пробным периодом и стоимостью регистрации $29. Выглядела она так:
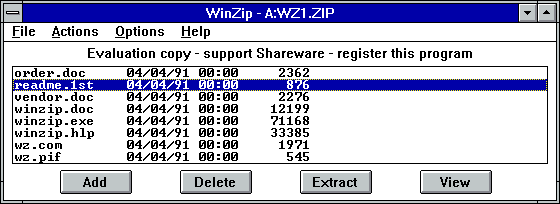
В первых версиях WinZip под капотом использовалась PKZip. Но с версии 5.0 в 1993-м для прямой обработки Zip-файлов стал использоваться код из Info-ZIP. Пользовательский интерфейс тоже постепенно эволюционировал.

WinZip 6.3 под Windows 3.11 for Workgroups.
WinZip была одной из самых популярных shareware-программ в 1990-е. Но в конце концов она потеряла актуальность из-за встраивания поддержки Zip-файлов в операционные системы. Windows работает с ними как со «сжатыми папками» начиная с 2001-го (Windows XP), для этого используется библиотека DynaZip.
Изначально компания Мака называлась Nico Mak Computing. В 2000-м её переименовали в WinZip Computing, и примерно в те годы Мак её покинул. В 2005-м компанию продали Vector Capital, и в конце концов ею стала владеть Corel, которая до сих пор выпускает WinZip в качестве продукта.
Сжатие Lempel-Ziv (LZ77)
Zip-сжатие состоит из двух основных ингредиентов: сжатия Lempel-Ziv и кода Хаффмана.
Один из способов сжатия текста заключается в создании списка частых слов или фраз с заменой разновидностей этих слов в рамках текста ссылками на словарь. Например, длинное слово «compression» в исходном тексте можно представить как #1234, где 1234 ссылается на позицию слова в списке. Это называется сжатием с использованием словаря.
Но с точки зрения сжатия универсального назначения у такого метода есть несколько недостатков. Во-первых, что именно должно попасть в словарь? Исходные данные могут быть на разных языках, это может быть даже не человеко читаемый текст. И если заранее не согласовать словарь между сжатием и распаковкой, то его придётся хранить и передавать вместе со сжатыми данными, что снижает выгоду от сжатия.
Элегантным решением этой проблемы является использование в качестве словаря самих исходных данных. В работе "A Universal Algorithm for Sequential Data Compression" 1977 года Якоб Зив и Абрахам Лемпел (работавшие в компании Technion), предложили схему сжатия, при которой исходные данные представляются в виде последовательности триплетов:
(указатель, длина, следующий)
где
указатель и длина формируют обратную ссылку на последовательность символов, которую нужно скопировать из предыдущей позиции в оригинальном тексте, а следующий — это следующий символ в генерируемых данных.

Абрахам Лемпел и Якоб Зив.
Рассмотрим такие строки:
It was the best of times,
it was the worst of times,
Во второй строке последовательность «t was the w» можно представить как (26, 10, w), поскольку она воссоздаётся копированием 10 символов с позиции в 26 символов назад и до буквы «w». Для символов, которые до этого ещё не появлялись, используются обратные ссылки нулевой длины. Например, начальная «I» может быть представлена как (0, 0, I).
Эта схема получила название сжатие Lempel-Ziv, или сжатие LZ77. Однако в практических реализациях алгоритма обычно не используется часть триплета
следующий. Вместо этого символы генерируются по-одиночке, а для обратных ссылок используются пары (расстояние, длина) (этот вариант называется сжатием LZSS). Как кодируются литералы и обратные ссылки — это отдельный вопрос, мы рассмотрим его ниже, когда будем разбирать алгоритм Deflate.Этот текст:
It was the best of times,
it was the worst of times,
it was the age of wisdom,
it was the age of foolishness,
it was the epoch of belief,
it was the epoch of incredulity,
it was the season of Light,
it was the season of Darkness,
it was the spring of hope,
it was the winter of despair,
we had everything before us,
we had nothing before us,
we were all going direct to Heaven,
we were all going direct the other way
Можно сжать в такой:
It was the best of times,
i(26,10)wor(27,24)age(25,4)wisdom(26,20)
foolishnes(57,14)epoch(33,4)belief(28,22)incredulity
(33,13)season(34,4)Light(28,23)Dark(120,17)
spring(31,4)hope(231,14)inter(27,4)despair,
we had everyth(57,4)before us(29,9)no(26,20)
we(12,3)all go(29,4)direct to Heaven
(36,28)(139,3)(83,3)(138,3)way
Одним из важных свойств обратных ссылок является то, что они могут перекрывать друг друга. Такое случается тогда, когда длина больше расстояния. Например:
Fa-la-la-la-la
Можно сжать в:
Fa-la(3,9)
Вам это может показаться странным, но метод работает: после того, как скопированы байты первых трёх «-la», копирование продолжается уже с использованием недавно сгенерированных байтов.
По сути, это разновидность кодирования длин серий, при котором часть данных многократно копируется для получения нужной длины.
Интерактивный пример использования сжатия Lempel-Ziv для текстов песен показан в статье Колина Морриса Are Pop Lyrics Getting More Repetitive?.
Ниже приведён пример копирования обратных ссылок на языке С. Обратите внимание, что из-за возможного перекрытия мы не можем использовать
memcpy или memmove./* Output the (dist,len) backref at dst_pos in dst. */
static inline void lz77_output_backref(uint8_t *dst, size_t dst_pos,
size_t dist, size_t len)
{
size_t i;
assert(dist <= dst_pos && "cannot reference before beginning of dst");
for (i = 0; i < len; i++) {
dst[dst_pos] = dst[dst_pos - dist];
dst_pos++;
}
}
Генерировать литералы легко, но для полноты воспользуемся вспомогательной функцией:
/* Output lit at dst_pos in dst. */
static inline void lz77_output_lit(uint8_t *dst, size_t dst_pos, uint8_t lit)
{
dst[dst_pos] = lit;
}
Обратите внимание, что вызывающий эту функцию должен удостовериться, что в
dst достаточно места для генерируемых данных и что обратная ссылка не обращается к позиции до начала буфера.Сложно не генерировать данные с помощью обратных ссылок в ходе распаковки, а создавать их первым делом при сжатии исходных данных. Это можно сделать по-разному, но мы воспользуемся методикой на основе хэш-таблиц из zlib, который предлагается в RFC 1951.
Будем применять хэш-таблицу с позициями трёхсимвольных префиксов, которые ранее встречались в строке (более короткие обратные ссылки пользы не приносят). В Deflate допускаются обратные ссылки в рамках предыдущих 32 768 символов — это называется окном. Это обеспечивает потоковое сжатие: входные данные подвергаются небольшой обработке за раз, при условии, что окно с последними байтами хранится в памяти. Однако наша реализация предполагает, что нам доступны все входные данные и мы можем обработать их целиком за раз. Это позволяет сосредоточиться на сжатии, а не на учёте, который необходим для потоковой обработки.
Воспользуемся двумя массивами: в
head содержится хэш-значение трёхсимвольного префикса для позиции во входных данных, а в prev содержится позиция предыдущей позиции с этим хэш-значением. По сути, head[h] — это заголовок связного списка позиций префиксов с хэшем h, а prev[x] получает элемент, предшествующий x в списке.#define LZ_WND_SIZE 32768
#define LZ_MAX_LEN 258
#define HASH_SIZE 15
#define NO_POS SIZE_MAX
/* Perform LZ77 compression on the len bytes in src. Returns false as soon as
either of the callback functions returns false, otherwise returns true when
all bytes have been processed. */
bool lz77_compress(const uint8_t *src, size_t len,
bool (*lit_callback)(uint8_t lit, void *aux),
bool (*backref_callback)(size_t dist, size_t len, void *aux),
void *aux)
{
size_t head[1U << HASH_SIZE];
size_t prev[LZ_WND_SIZE];
uint16_t h;
size_t i, j, dist;
size_t match_len, match_pos;
size_t prev_match_len, prev_match_pos;
/* Initialize the hash table. */
for (i = 0; i < sizeof(head) / sizeof(head[0]); i++) {
head[i] = NO_POS;
}
Для вставки в хэш-таблицу новой строковой позиции
prev обновляется, чтобы указывать на предыдущую head, а затем обновляется сама head:static void insert_hash(uint16_t hash, size_t pos, size_t *head, size_t *prev)
{
prev[pos % LZ_WND_SIZE] = head[hash];
head[hash] = pos;
}
Обратите внимание на операцию по модулю при индексировании в
prev: нас интересуют только те позиции, которые попадают в текущее окно.Вместо того, чтобы с нуля вычислять хэш-значение для каждого трёхсимвольного префикса, мы воспользуемся кольцевым хэшем и будем постоянно обновлять его, чтобы в его значении отражались только три последних символа:
static uint16_t update_hash(uint16_t hash, uint8_t c)
{
hash <<= 5; /* Shift out old bits. */
hash ^= c; /* Include new bits. */
hash &= (1U << HASH_SIZE) - 1; /* Mask off excess bits. */
return hash;
}
Хэш-карту потом можно использовать для эффективного поиска предыдущих совпадений с последовательностью, как показано ниже. Поиск совпадений — самая ресурсозатратная операция сжатия, поэтому мы ограничим глубину поиска по списку.
Изменение различных параметров, вроде глубины поиска по списку префиксов и выполнения ленивого сравнения, как будет описано ниже, — это способ повышения скорости за счёт снижения степени сжатия. Настройки в нашем коде выбраны так, чтобы соответствовать максимальному уровню сжатия в zlib.
/* Find the longest most recent string which matches the string starting
* at src[pos]. The match must be strictly longer than prev_match_len and
* shorter or equal to max_match_len. Returns the length of the match if found
* and stores the match position in *match_pos, otherwise returns zero. */
static size_t find_match(const uint8_t *src, size_t pos, uint16_t hash,
size_t prev_match_len, size_t max_match_len,
const size_t *head, const size_t *prev,
size_t *match_pos)
{
size_t max_match_steps = 4096;
size_t i, l;
bool found;
if (prev_match_len == 0) {
/* We want backrefs of length 3 or longer. */
prev_match_len = 2;
}
if (prev_match_len >= max_match_len) {
/* A longer match would be too long. */
return 0;
}
if (prev_match_len >= 32) {
/* Do not try too hard if there is already a good match. */
max_match_steps /= 4;
}
found = false;
i = head[hash];
while (max_match_steps != 0) {
if (i == NO_POS) {
/* No match. */
break;
}
assert(i < pos && "Matches should precede pos.");
if (pos - i > LZ_WND_SIZE) {
/* The match is outside the window. */
break;
}
l = cmp(src, i, pos, prev_match_len, max_match_len);
if (l != 0) {
assert(l > prev_match_len);
assert(l <= max_match_len);
found = true;
*match_pos = i;
prev_match_len = l;
if (l == max_match_len) {
/* A longer match is not possible. */
return l;
}
}
/* Look further back in the prefix list. */
i = prev[i % LZ_WND_SIZE];
max_match_steps--;
}
if (!found) {
return 0;
}
return prev_match_len;
}
/* Compare the substrings starting at src[i] and src[j], and return the length
* of the common prefix. The match must be strictly longer than prev_match_len
* and shorter or equal to max_match_len. */
static size_t cmp(const uint8_t *src, size_t i, size_t j,
size_t prev_match_len, size_t max_match_len)
{
size_t l;
assert(prev_match_len < max_match_len);
/* Check whether the first prev_match_len + 1 characters match. Do this
* backwards for a higher chance of finding a mismatch quickly. */
for (l = 0; l < prev_match_len + 1; l++) {
if (src[i + prev_match_len - l] !=
src[j + prev_match_len - l]) {
return 0;
}
}
assert(l == prev_match_len + 1);
/* Now check how long the full match is. */
for (; l < max_match_len; l++) {
if (src[i + l] != src[j + l]) {
break;
}
}
assert(l > prev_match_len);
assert(l <= max_match_len);
assert(memcmp(&src[i], &src[j], l) == 0);
return l;
}
Можно завершить функцию
lz77_compress этим кодом для поиска предыдущих совпадений: /* h is the hash of the three-byte prefix starting at position i. */
h = 0;
if (len >= 2) {
h = update_hash(h, src[0]);
h = update_hash(h, src[1]);
}
prev_match_len = 0;
prev_match_pos = 0;
for (i = 0; i + 2 < len; i++) {
h = update_hash(h, src[i + 2]);
/* Search for a match using the hash table. */
match_len = find_match(src, i, h, prev_match_len,
min(LZ_MAX_LEN, len - i), head, prev,
&match_pos);
/* Insert the current hash for future searches. */
insert_hash(h, i, head, prev);
/* If the previous match is at least as good as the current. */
if (prev_match_len != 0 && prev_match_len >= match_len) {
/* Output the previous match. */
dist = (i - 1) - prev_match_pos;
if (!backref_callback(dist, prev_match_len, aux)) {
return false;
}
/* Move past the match. */
for (j = i + 1; j < min((i - 1) + prev_match_len,
len - 2); j++) {
h = update_hash(h, src[j + 2]);
insert_hash(h, j, head, prev);
}
i = (i - 1) + prev_match_len - 1;
prev_match_len = 0;
continue;
}
/* If no match (and no previous match), output literal. */
if (match_len == 0) {
assert(prev_match_len == 0);
if (!lit_callback(src[i], aux)) {
return false;
}
continue;
}
/* Otherwise the current match is better than the previous. */
if (prev_match_len != 0) {
/* Output a literal instead of the previous match. */
if (!lit_callback(src[i - 1], aux)) {
return false;
}
}
/* Defer this match and see if the next is even better. */
prev_match_len = match_len;
prev_match_pos = match_pos;
}
/* Output any previous match. */
if (prev_match_len != 0) {
dist = (i - 1) - prev_match_pos;
if (!backref_callback(dist, prev_match_len, aux)) {
return false;
}
i = (i - 1) + prev_match_len;
}
/* Output any remaining literals. */
for (; i < len; i++) {
if (!lit_callback(src[i], aux)) {
return false;
}
}
return true;
}
Этот код ищет самую длинную обратную ссылку, которая может быть сгенерирована на текущей позиции. Но прежде чем её выдать, программа решает, можно ли на следующей позиции найти ещё более длинное совпадение. В zlib это называется оценкой с помощью ленивого сравнения. Это всё ещё жадный алгоритм: он выбирает самое длинное совпадение, даже если текущее более короткое позволяет позднее получить совпадение ещё длиннее и достичь более сильного сжатия.
Сжатие Lempel-Ziv может работать как быстро, так и медленно. Zopfli потратил много времени на поиски оптимальных обратных ссылок, чтобы выжать дополнительные проценты сжатия. Это полезно для данных, которые сжимаются один раз и потом многократно используются, например, для статичной информации на веб-сервере. На другой стороне шкалы находятся такие компрессоры, как Snappy и LZ4, которые сравнивают только с последним 4-байтным префиксом и работают очень быстро. Такой тип сжатия полезен в базах данных и RPC-системах, в которых время, потраченное на сжатие, окупается экономией времени при отправке данных по сети или на диск.
Идея использовать исходные данные в качестве словаря очень элегантна, но и от статичного словаря можно получить пользу. Brotli — алгоритм на основе LZ77, но он также использует большой статичный словарь из строковых, которые часто встречаются в сети.
Код LZ77 можно посмотреть в lz77.h и lz77.c.
Код Хаффмана
Вторым алгоритмом Zip-сжатия является код Хаффмана.
Термин код в данном контексте является отсылкой к системе представления данных в какой-то другой форме. В данном случае нас интересует код, с помощью которого можно эффективно представлять литералы и обратные ссылки, сгенерированные алгоритмом Lempel-Ziv.
Традиционно англоязычный текст представляют с помощью American Standard Code for Information Interchange (ASCII). Эта система присваивает каждому символу число, которые обычно хранятся в 8-битном представлении. Вот ASCII-коды для прописных букв английского алфавита:
| A | 01000001 | N | 01001110 |
| B | 01000010 | O | 01001111 |
| C | 01000011 | P | 01010000 |
| D | 01000100 | Q | 01010001 |
| E | 01000101 | R | 01010010 |
| F | 01000110 | S | 01010011 |
| G | 01000111 | T | 01010100 |
| H | 01001000 | U | 01010101 |
| I | 01001001 | V | 01010110 |
| J | 01001010 | W | 01010111 |
| K | 01001011 | X | 01011000 |
| L | 01001100 | Y | 01011001 |
| M | 01001101 | Z | 01011010 |
Один байт на символ — это удобный способ хранения текста. Он позволяет легко обращаться к частям текста или изменять их, и всегда понятно, сколько байтов требуется для хранения N символов, или сколько символов хранится в N байтов. Однако это не самый эффективный способ с точки зрения занимаемого объёма. Например, в английском языке буква E используется чаще всего, а Z — реже всего. Поэтому с точки зрения объёма эффективнее использовать более короткое битовое представление для E и более длинное для Z, а не присваивать каждому символу одинаковое количество битов.
Код, который разным исходным символам задаёт кодировки разной длины, называется кодом переменной длины. Самый известный пример — азбука Морзе, в которой каждый символ кодируется точками и тире, изначально передававшимися по телеграфу короткими и длинными импульсами:
| A | • − | N | − • |
| B | − • • • | O | − − − |
| C | − • − • | P | • − − • |
| D | − • • | Q | − − • − |
| E | • | R | • − • |
| F | • • − • | S | • • • |
| G | − − • | T | − |
| H | • • • • | U | • • − |
| I | • • | V | • • • − |
| J | • − − − | W | • − − |
| K | − • − | X | − • • − |
| L | • − • • | Y | − • − − |
| M | − − | Z | − − • • |
Одним из недостатков азбуки Морзе является то, что одно кодовое слово может быть префиксом другого. Например, • • − • не имеет уникального декодирования: это может быть F или ER. Это решается с помощью пауз (длиной в три точки) между буквами в ходе передачи. Однако было бы лучше, если бы кодовые слова не могли являться префиксами других слов. Такой код называется беспрефиксным. ASCII-код фиксированной длины является беспрефиксным, потому что кодовые слова всегда одной длины. Но коды переменной длины тоже могут быть беспрефиксными. Телефонные номера чаще всего беспрефиксные. Прежде чем в Швеции ввели телефон экстренной помощи 112, пришлось поменять все номера, начинавшиеся со 112. А в США нет ни одного телефонного номера, начинающегося с 911.
Для минимизации размера закодированного сообщения лучше использовать беспрефиксный код, в котором часто встречающиеся символы имеют более короткие кодовые слова. Оптимальным кодом будет такой, который генерирует самый короткий возможный результат — сумма длин кодовых слов, умноженная на их частоту появления, будет минимально возможной. Это называется беспрефиксным кодом с минимальной избыточностью, или кодом Хаффмана, в честь изобретателя эффективного алгоритма для генерирования таких кодов.
Алгоритм Хаффмана
Изучая материалы для написания своей докторской диссертации по электронной инженерии в MIT, Дэвид Хаффман прослушал курс по теории информации, который читал Роберт Фано. Согласно легенде, Фано позволил своим слушателям выбирать: писать финальный экзамен или курсовую. Хаффман выбрал последнее, и ему дали тему поиска беcпрефиксных кодов с минимальной избыточностью. Предполагается, что он не знал о том, что над этой задачей в то время работал сам Фано (самым известный методом в те годы был алгоритм Шеннона-Фано). Работа Хаффмана была опубликована в 1952-м под названием A Method for the Construction of Minimum-Redundancy Codes in 1952. И с тех пор его алгоритм получил широкое распространение.

Дэвид Хаффман пресс-релиз UC Santa Cruz.
Алгоритм Хаффмана создаёт беспрефиксный код с минимальной избыточностью для набора символов и их частоты использования. Алгоритм многократно выбирает два символа, которые реже всего встречаются в исходных данных, — допустим, Х и Y — и заменяет их на составной символ, означающий «X или Y». Частотой появления составного символа является сумма частот двух исходных символов. Кодовые слова для X и Y могут быть любыми кодовыми словами, которые присвоены составному символу «X или Y», за которым идёт 0 или 1, чтобы отличать друг от друга исходные символы. Когда входные данные уменьшаются до одного символа, алгоритм прекращает работу (видеообъяснение).
Вот пример работы алгоритма на маленьком наборе символов:
| Символ | Частота |
| A | 6 |
| B | 4 |
| C | 2 |
| D | 3 |
Первая итерация обработки:
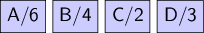
Два самых редких символа, C и D, убираются из набора и заменяются составным символом, частота которого является суммой частот C и D:

Теперь самыми редкими символами стали B и составной символ с частотой 5. Они убираются из набора и заменяются составным символом с частотой 9:

Наконец, A и составной символ с частотой 9 объединяются в новый символ с частотой 15:

Весь набор свёлся к одному символу, обработка завершена.
Алгоритм создал структуру, которая называется деревом Хаффмана. Входные символы — это листья, а чем больше частота у символа, тем выше он расположен. Начиная от корня дерева можно сгенерировать кодовые слова для символов, добавляя 0 или 1, когда переходим влево или вправо соответственно. Получится так:
| Символ | Кодовое слово |
| A | 0 |
| B | 10 |
| C | 110 |
| D | 111 |
Ни одно кодовое слово не является префиксом для какого-то другого. Чем чаще встречается символ, тем короче его кодовое слово.
Дерево можно использовать и для декодирования: начинаем с корня и идём направо или налево для значение с 0 или 1 перед символом. Например, строка 010100 декодируется в ABBA.
Обратите внимание, что длина каждого кодового слова эквивалентна глубине соответствующего узла дерева. Как мы увидим в следующей части, нам не нужно настоящее дерево для присвоения кодовых слов. Достаточно знать длину самих слов. Таким образом, результатом работы нашей реализации алгоритма Хаффмана будут длины кодовых слов.
Для хранения набора символов и эффективного нахождения наименьших частот мы воспользуемся структурой данных двоичная куча. В частности, нас интересует min-куча, поскольку минимальное значение должно быть наверху.
/* Swap the 32-bit values pointed to by a and b. */
static void swap32(uint32_t *a, uint32_t *b)
{
uint32_t tmp;
tmp = *a;
*a = *b;
*b = tmp;
}
/* Move element i in the n-element heap down to restore the minheap property. */
static void minheap_down(uint32_t *heap, size_t n, size_t i)
{
size_t left, right, min;
assert(i >= 1 && i <= n && "i must be inside the heap");
/* While the ith element has at least one child. */
while (i * 2 <= n) {
left = i * 2;
right = i * 2 + 1;
/* Find the child with lowest value. */
min = left;
if (right <= n && heap[right] < heap[left]) {
min = right;
}
/* Move i down if it is larger. */
if (heap[min] < heap[i]) {
swap32(&heap[min], &heap[i]);
i = min;
} else {
break;
}
}
}
/* Establish minheap property for heap[1..n]. */
static void minheap_heapify(uint32_t *heap, size_t n)
{
size_t i;
/* Floyd's algorithm. */
for (i = n / 2; i >= 1; i--) {
minheap_down(heap, n, i);
}
}
Чтобы отслеживать частоту
n символов, будем использовать кучу из n элементов. Также при каждом создании составного символа мы хотим «связывать» с ним оба исходных символа. Поэтому каждый символ будет иметь «элемент связи».Для хранения
n-элементной кучи и n элементов связи будем использовать массив из n * 2 + 1 элементов. Когда два символа в куче заменяются одним, мы будем использовать второй элемент для сохранения ссылки на новый символ. Этот подход основан на реализации Managing Gigabytes Уиттена, Моффата и Белла.В каждом узле куче мы будем использовать 16 старших битов для хранения частоты символа, а 16 младших — для хранения индекса элемента связи символа. За счёт использования старших битов разница частот будет определяться результатом 32-битного сравнения между двумя элементами кучи.
Из-за такого представления нам нужно удостовериться, что частота символов всегда укладывается в 16 битов. После завершения работы алгоритма финальный составной символ будет иметь частоту всех объединённых символов, то есть эта сумма должна помещаться в 16 битов. Наша реализация Deflate будет проверять это с помощью одновременной обработки до 64 535 символов.
Символы с нулевой частотой будут получать кодовые слова нулевой длины и не станут участвовать в составлении кодировки.
Если кодовое слово достигнет заданной максимальной глубины, мы «сгладим» распределение частот, наложив частотное ограничение, и попробуем опять (да, с помощью
goto). Есть и более сложные способы выполнения ограниченного по глубине кодирования Хаффмана, но этот прост и эффективен.#define MAX_HUFFMAN_SYMBOLS 288 /* Deflate uses max 288 symbols. */
/* Construct a Huffman code for n symbols with the frequencies in freq, and
* codeword length limited to max_len. The sum of the frequencies must be <=
* UINT16_MAX. max_len must be large enough that a code is always possible,
* i.e. 2 ** max_len >= n. Symbols with zero frequency are not part of the code
* and get length zero. Outputs the codeword lengths in lengths[0..n-1]. */
static void compute_huffman_lengths(const uint16_t *freqs, size_t n,
uint8_t max_len, uint8_t *lengths)
{
uint32_t nodes[MAX_HUFFMAN_SYMBOLS * 2 + 1], p, q;
uint16_t freq;
size_t i, h, l;
uint16_t freq_cap = UINT16_MAX;
#ifndef NDEBUG
uint32_t freq_sum = 0;
for (i = 0; i < n; i++) {
freq_sum += freqs[i];
}
assert(freq_sum <= UINT16_MAX && "Frequency sum too large!");
#endif
assert(n <= MAX_HUFFMAN_SYMBOLS);
assert((1U << max_len) >= n && "max_len must be large enough");
try_again:
/* Initialize the heap. h is the heap size. */
h = 0;
for (i = 0; i < n; i++) {
freq = freqs[i];
if (freq == 0) {
continue; /* Ignore zero-frequency symbols. */
}
if (freq > freq_cap) {
freq = freq_cap; /* Enforce the frequency cap. */
}
/* High 16 bits: Symbol frequency.
Low 16 bits: Symbol link element index. */
h++;
nodes[h] = ((uint32_t)freq << 16) | (uint32_t)(n + h);
}
minheap_heapify(nodes, h);
/* Special case for less than two non-zero symbols. */
if (h < 2) {
for (i = 0; i < n; i++) {
lengths[i] = (freqs[i] == 0) ? 0 : 1;
}
return;
}
/* Build the Huffman tree. */
while (h > 1) {
/* Remove the lowest frequency node p from the heap. */
p = nodes[1];
nodes[1] = nodes[h--];
minheap_down(nodes, h, 1);
/* Get q, the next lowest frequency node. */
q = nodes[1];
/* Replace q with a new symbol with the combined frequencies of
p and q, and with the no longer used h+1'th node as the
link element. */
nodes[1] = ((p & 0xffff0000) + (q & 0xffff0000))
| (uint32_t)(h + 1);
/* Set the links of p and q to point to the link element of
the new node. */
nodes[p & 0xffff] = nodes[q & 0xffff] = (uint32_t)(h + 1);
/* Move the new symbol down to restore heap property. */
minheap_down(nodes, h, 1);
}
/* Compute the codeword length for each symbol. */
h = 0;
for (i = 0; i < n; i++) {
if (freqs[i] == 0) {
lengths[i] = 0;
continue;
}
h++;
/* Link element for the i'th symbol. */
p = nodes[n + h];
/* Follow the links until we hit the root (link index 2). */
l = 1;
while (p != 2) {
l++;
p = nodes[p];
}
if (l > max_len) {
/* Lower freq_cap to flatten the distribution. */
assert(freq_cap != 1 && "Cannot lower freq_cap!");
freq_cap /= 2;
goto try_again;
}
assert(l <= UINT8_MAX);
lengths[i] = (uint8_t)l;
}
}
Элегантной альтернативой варианту с двоичной кучей является сохранение символов в двух очередях. Первая содержит исходные символы, отсортированные по частоте. Когда создаётся составной символ, он добавляется во вторую очередь. Таким образом символ с наименьшей частотой всегда будет на первой позиции одной из очередей. Этот подход описан Jan van Leeuwen в On the Construction of Huffman Trees (1976).
Кодирование Хаффмана оптимально для беспрефиксных кодов, но в других случаях есть более эффективные способы: арифметическое кодирование и асимметричные системы счисления.
Канонические коды Хаффмана
В примере выше мы построили дерево Хаффмана:
Если идти от корня и использовать 0 для левой ветки и 1 для правой, то мы получим такие коды:
| Символ | Кодовое слово |
| A | 0 |
| B | 10 |
| C | 110 |
| D | 111 |
Решение об использовании 0 для левой ветки и 1 для правой выглядит произвольным. Если сделать наоборот, то получим:
| Символ | Кодовое слово |
| A | 1 |
| B | 01 |
| C | 001 |
| D | 000 |
Мы можем произвольно помечать две ветки, исходящие из ноды, нулём и единицей (главное, чтобы метки были разными), и всё равно получим эквивалентный код:
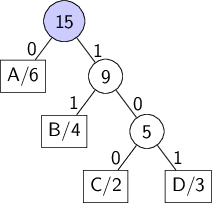
| Символ | Кодовое слово |
| A | 0 |
| B | 11 |
| C | 100 |
| D | 101 |
Хотя алгоритм Хаффмана дает требуемые длины кодовых слов для беспрефиксного кода с минимальной избыточностью, есть множество способов присвоения отдельных кодовых слов.
Учитывая длину кодового слова, вычисляемую по алгоритму Хаффмана, канонический код Хаффмана присваивает символам кодовые слова определённым образом. Это полезно, поскольку позволяет хранить и передавать длины кодовых слов со сжатыми данными: декодер сможет восстановить кодовые слова на основе их длин. Конечно, можно хранить и передавать частоты символов и запускать в декодере алгоритм Хаффмана, но это потребует от декодера больше работы и больше места для хранения. Другим очень важным свойством является то, что структура канонических кодов использует эффективное декодирование.
Идея заключается в том, чтобы присваивать символам кодовые слова последовательно, под одному за раз. Первым кодовым словом является 0. Следующим будет слово длиной предыдущее слово + 1. Первое слово длиной N составляется из последнего слова длиной N-1, добавления единицы (чтобы получилось новое кодовое слово) и смещения на один шаг влево (для увеличения длины).
В терминологии дерева Хоффмана кодовые слова последовательно присваиваются листьям в порядке слева-направо, по одному уровню за раз, смещаясь влево при переходе на следующий уровень.
В нашем примере A-B-C-D алгоритм Хаффмана присвоил кодовые слова с длинами 1, 2, 3 и 3. Первым словом является 0. Это также последнее слово длиной 1. Для длины 2 мы берём 0 и добавляем 1 для получения следующего кода, который станет префиксом двухбитных кодов, смещаемся влево и получаем 10. Это теперь последнее слово длиной 2. Для получения длины 3 мы добавляем 1 и смещаемся: 110. Для получения следующего слова длиной 3 мы добавляем 1: 111.
| Символ | Кодовое слово |
| A | 0 |
| B | 10 |
| C | 110 |
| D | 111 |
Ниже показана реализация генератора канонических кодов. Обратите внимание, что алгоритм Deflate ожидает, что кодовые слова будут генерироваться по принципу LSB-first (сначала младшим значащим битом). То есть первый бит кодового слова должен храниться в наименьшем значащем бите. Это означает, что нам нужно поменять порядок битов, например, с помощью поисковой таблицы.
#define MAX_HUFFMAN_BITS 15 /* Deflate uses max 15-bit codewords. */
static void compute_canonical_code(uint16_t *codewords, const uint8_t *lengths,
size_t n)
{
size_t i;
uint16_t count[MAX_HUFFMAN_BITS + 1] = {0};
uint16_t code[MAX_HUFFMAN_BITS + 1];
int l;
/* Count the number of codewords of each length. */
for (i = 0; i < n; i++) {
count[lengths[i]]++;
}
count[0] = 0; /* Ignore zero-length codes. */
/* Compute the first codeword for each length. */
code[0] = 0;
for (l = 1; l <= MAX_HUFFMAN_BITS; l++) {
code[l] = (uint16_t)((code[l - 1] + count[l - 1]) << 1);
}
/* Assign a codeword for each symbol. */
for (i = 0; i < n; i++) {
l = lengths[i];
if (l == 0) {
continue;
}
codewords[i] = reverse16(code[l]++, l); /* Make it LSB-first. */
}
}
/* Reverse the n least significant bits of x.
The (16 - n) most significant bits of the result will be zero. */
static inline uint16_t reverse16(uint16_t x, int n)
{
uint16_t lo, hi;
uint16_t reversed;
assert(n > 0);
assert(n <= 16);
lo = x & 0xff;
hi = x >> 8;
reversed = (uint16_t)((reverse8_tbl[lo] << 8) | reverse8_tbl[hi]);
return reversed >> (16 - n);
}
Теперь соберём всё вместе и напишем код инициализации кодировщика:
typedef struct huffman_encoder_t huffman_encoder_t;
struct huffman_encoder_t {
uint16_t codewords[MAX_HUFFMAN_SYMBOLS]; /* LSB-first codewords. */
uint8_t lengths[MAX_HUFFMAN_SYMBOLS]; /* Codeword lengths. */
};
/* Initialize a Huffman encoder based on the n symbol frequencies. */
void huffman_encoder_init(huffman_encoder_t *e, const uint16_t *freqs, size_t n,
uint8_t max_codeword_len)
{
assert(n <= MAX_HUFFMAN_SYMBOLS);
assert(max_codeword_len <= MAX_HUFFMAN_BITS);
compute_huffman_lengths(freqs, n, max_codeword_len, e->lengths);
compute_canonical_code(e->codewords, e->lengths, n);
}
Также сделаем функцию для настройки кодировщика с помощью уже вычисленных длин кодов:
/* Initialize a Huffman encoder based on the n codeword lengths. */
void huffman_encoder_init2(huffman_encoder_t *e, const uint8_t *lengths,
size_t n)
{
size_t i;
for (i = 0; i < n; i++) {
e->lengths[i] = lengths[i];
}
compute_canonical_code(e->codewords, e->lengths, n);
}
Эффективное декодирование Хаффмана
Самый простой способ декодирования Хаффмана заключается в обходе дерева начиная с корня, считывая по одному биту входных данных за раз и решая, какую ветку брать следующей, левую или правую. Когда достигается листовой узел, это декодированный символ.
Этому методу часто учат в университетах и книгах. Он прост и элегантен, но обрабатывать по одному биту за раз слишком медленно. Гораздо быстрее декодировать с помощью поисковой таблицы. Для вышеприведённого примера, в котором максимальная длина кодового слова равна трём битам, можно использовать такую таблицу:
| Биты | Символ | Длина кодового слова |
| 000 | A | 1 |
| 001 | A | 1 |
| 010 | A | 1 |
| 011 | A | 1 |
| 100 | B | 2 |
| 101 | B | 2 |
| 110 | C | 3 |
| 111 | D | 3 |
Хотя символов всего четыре, нам нужна таблица с восемью записями, чтобы охватить все возможные трёхбитные комбинации. Символы с кодовыми словами короче трёх битов имеют в таблице по несколько записей. Например, слово 10 было «дополнено» 100 и 101, чтобы охватить все трёхбитные комбинации, начинающиеся с 10.
Чтобы декодировать таким образом, нужно проиндексировать в таблице с помощью следующих трёх входных битов и немедленно найти соответствующий символ и длину его кодового слова. Длина важна, потому что несмотря на то, что мы смотрели на следующие три бита, нам нужно получить такое же количество входных битов, какова длина кодового слова.
Метод на основе поисковой таблицы работает очень быстро, но у него есть недостаток: размер таблицы удваивается при каждом дополнительном бите в длине кодового слова. То есть построение таблицы замедляется экспоненциально, и если она перестаёт помещаться в кэш процессора, то метод начинает работать медленно.
Из-за этого таблицу поиска обычно используют только для кодовых слов не больше определённой длины. А для более длинных слов применяют другой подход. Как при кодировании Хаффмана более частым символами присваиваются более короткие кодовые слова, так и использование поисковой таблицы для коротких кодовых слов является во многих случаях прекрасной оптимизацией.
В zlib используется несколько уровней поисковых таблиц. Если кодовое слово слишком длинное для первой таблицы, то поиск перейдёт во вторичную таблицу, чтобы проиндексировать оставшиеся биты.
Но есть и другой, очень элегантный метод, основанный на свойствах канонических кодов Хаффмана. Он описывается в статье On the Implementation of Minimum Redundancy Prefix Codes (Моффат и Турпин, 1997-й), а также объясняется в статье The Lost Huffman Paper Чарльза Блума.
Возьмём кодовые слова из канонической версии: 0, 10, 110, 111. Будем отслеживать первые кодовые слова каждой из длин, а также номер каждого кодового слова в общей последовательности — «символьный индекс».
| Длина кодового слова | Первое кодовое слово | Первый символьный индекс |
| 1 | 0 | 1 (A) |
| 2 | 10 | 2 (B) |
| 3 | 110 | 3 (С) |
Поскольку кодовые слова присваиваются последовательно, то если нам известно количество битов, мы можем в вышеприведённой таблице найти символ, который представляют эти биты. Например, для трёхбитного 111 мы видим, что это смещение на единицу от первого кодового слова этой длины (110). Первым символьным индексом такой длины является 3, а смещение на единицу даёт нам индекс 4. Другая таблица сопоставляет символьный индекс с символом:
sym_idx = d->first_symbol[len] + (bits - d->first_code[len]);
sym = d->syms[sym_idx];
Маленька оптимизация: вместо раздельного хранения первого символьного индекса и первого кодового слова мы можем хранить в таблице первый индекс минус первое кодовое слово:
sym_idx = d->offset_first_sym_idx[len] + bits;
sym = d->syms[sym_idx];
Чтобы понять, сколько битов нужно оценить, мы снова воспользуемся свойством последовательности кода. В нашем примере все валидные однобитные кодовые слова строго меньше 1, двухбитные — строго меньше 11, трёхбитные — меньше 1000 (по сути, верно для всех трёхбитных значений). Иными словами, валидное N-битное кодовое слово должно быть строго меньше первого N-битного кодового слова плюс количество N-битных кодовых слов. Более того, мы можем смещать влево эти границы, чтобы все они были трёхбитной ширины. Давайте назовём это ограничительными битами для каждой из длин кодовых слов:
| Длина кодового слова | Ограничительные биты |
| 1 | 100 |
| 2 | 110 |
| 3 | 1000 |
Ограничитель для длины 3 переполнился до 4 битов, но это лишь означает, что подойдёт любое трёхбитное слово.
Мы можем искать среди трёхбитных входных данных и сравнивать с ограничительными битами, чтобы понять, какой длины наше кодовое слово. После завершения мы смещаем входные биты, только чтобы вычислить их правильное количество, а затем находим символьный индекс:
for (len = 1; len <= 3; len++) {
if (bits < d->sentinel_bits[len]) {
bits >>= 3 - len; /* Get the len most significant bits. */
sym_idx = d->offset_first_sym_idx[len] + bits;
}
}
Временная сложность процесса линейная относительно количества битов в кодовых словах, но зато место расходуется эффективно, на каждом шаге требуется только загрузка и сравнение, а поскольку более короткие кодовые слова встречаются чаще, метод позволяет оптимизировать сжатие во многих ситуациях.
Полный код декодера:
#define HUFFMAN_LOOKUP_TABLE_BITS 8 /* Seems a good trade-off. */
typedef struct huffman_decoder_t huffman_decoder_t;
struct huffman_decoder_t {
/* Lookup table for fast decoding of short codewords. */
struct {
uint16_t sym : 9; /* Wide enough to fit the max symbol nbr. */
uint16_t len : 7; /* 0 means no symbol. */
} table[1U << HUFFMAN_LOOKUP_TABLE_BITS];
/* "Sentinel bits" value for each codeword length. */
uint16_t sentinel_bits[MAX_HUFFMAN_BITS + 1];
/* First symbol index minus first codeword mod 2**16 for each length. */
uint16_t offset_first_sym_idx[MAX_HUFFMAN_BITS + 1];
/* Map from symbol index to symbol. */
uint16_t syms[MAX_HUFFMAN_SYMBOLS];
#ifndef NDEBUG
size_t num_syms;
#endif
};
/* Get the n least significant bits of x. */
static inline uint64_t lsb(uint64_t x, int n)
{
assert(n >= 0 && n <= 63);
return x & (((uint64_t)1 << n) - 1);
}
/* Use the decoder d to decode a symbol from the LSB-first zero-padded bits.
* Returns the decoded symbol number or -1 if no symbol could be decoded.
* *num_used_bits will be set to the number of bits used to decode the symbol,
* or zero if no symbol could be decoded. */
static inline int huffman_decode(const huffman_decoder_t *d, uint16_t bits,
size_t *num_used_bits)
{
uint64_t lookup_bits;
size_t l;
size_t sym_idx;
/* First try the lookup table. */
lookup_bits = lsb(bits, HUFFMAN_LOOKUP_TABLE_BITS);
assert(lookup_bits < sizeof(d->table) / sizeof(d->table[0]));
if (d->table[lookup_bits].len != 0) {
assert(d->table[lookup_bits].len <= HUFFMAN_LOOKUP_TABLE_BITS);
assert(d->table[lookup_bits].sym < d->num_syms);
*num_used_bits = d->table[lookup_bits].len;
return d->table[lookup_bits].sym;
}
/* Then do canonical decoding with the bits in MSB-first order. */
bits = reverse16(bits, MAX_HUFFMAN_BITS);
for (l = HUFFMAN_LOOKUP_TABLE_BITS + 1; l <= MAX_HUFFMAN_BITS; l++) {
if (bits < d->sentinel_bits[l]) {
bits >>= MAX_HUFFMAN_BITS - l;
sym_idx = (uint16_t)(d->offset_first_sym_idx[l] + bits);
assert(sym_idx < d->num_syms);
*num_used_bits = l;
return d->syms[sym_idx];
}
}
*num_used_bits = 0;
return -1;
}
Для настройки декодера мы заранее вычислим канонические коды, как для huffman_encoder_init, и заполним разные таблицы:
/* Initialize huffman decoder d for a code defined by the n codeword lengths.
Returns false if the codeword lengths do not correspond to a valid prefix
code. */
bool huffman_decoder_init(huffman_decoder_t *d, const uint8_t *lengths,
size_t n)
{
size_t i;
uint16_t count[MAX_HUFFMAN_BITS + 1] = {0};
uint16_t code[MAX_HUFFMAN_BITS + 1];
uint32_t s;
uint16_t sym_idx[MAX_HUFFMAN_BITS + 1];
int l;
#ifndef NDEBUG
assert(n <= MAX_HUFFMAN_SYMBOLS);
d->num_syms = n;
#endif
/* Zero-initialize the lookup table. */
for (i = 0; i < sizeof(d->table) / sizeof(d->table[0]); i++) {
d->table[i].len = 0;
}
/* Count the number of codewords of each length. */
for (i = 0; i < n; i++) {
assert(lengths[i] <= MAX_HUFFMAN_BITS);
count[lengths[i]]++;
}
count[0] = 0; /* Ignore zero-length codewords. */
/* Compute sentinel_bits and offset_first_sym_idx for each length. */
code[0] = 0;
sym_idx[0] = 0;
for (l = 1; l <= MAX_HUFFMAN_BITS; l++) {
/* First canonical codeword of this length. */
code[l] = (uint16_t)((code[l - 1] + count[l - 1]) << 1);
if (count[l] != 0 && code[l] + count[l] - 1 > (1U << l) - 1) {
/* The last codeword is longer than l bits. */
return false;
}
s = (uint32_t)((code[l] + count[l]) << (MAX_HUFFMAN_BITS - l));
d->sentinel_bits[l] = (uint16_t)s;
assert(d->sentinel_bits[l] == s && "No overflow.");
sym_idx[l] = sym_idx[l - 1] + count[l - 1];
d->offset_first_sym_idx[l] = sym_idx[l] - code[l];
}
/* Build mapping from index to symbol and populate the lookup table. */
for (i = 0; i < n; i++) {
l = lengths[i];
if (l == 0) {
continue;
}
d->syms[sym_idx[l]] = (uint16_t)i;
sym_idx[l]++;
if (l <= HUFFMAN_LOOKUP_TABLE_BITS) {
table_insert(d, i, l, code[l]);
code[l]++;
}
}
return true;
}
static void table_insert(huffman_decoder_t *d, size_t sym, int len,
uint16_t codeword)
{
int pad_len;
uint16_t padding, index;
assert(len <= HUFFMAN_LOOKUP_TABLE_BITS);
codeword = reverse16(codeword, len); /* Make it LSB-first. */
pad_len = HUFFMAN_LOOKUP_TABLE_BITS - len;
/* Pad the pad_len upper bits with all bit combinations. */
for (padding = 0; padding < (1U << pad_len); padding++) {
index = (uint16_t)(codeword | (padding << len));
d->table[index].sym = (uint16_t)sym;
d->table[index].len = (uint16_t)len;
assert(d->table[index].sym == sym && "Fits in bitfield.");
assert(d->table[index].len == len && "Fits in bitfield.");
}
}
Deflate
Алгоритм Deflate, представленный в PKZip 2.04c в 1993-м, это стандартный метод сжатия в современных Zip-файлах. Он также применяется в gzip, PNG и многих других форматах. В нём используется сочетание сжатия LZ77 и кодирования Хаффмана, которое мы рассмотрим и реализуем в этом разделе.
До Deflate в PKZip использовались методы сжатия Shrink, Reduce и Implode. Сегодня они встречаются редко, хотя после появления Deflate ещё какое-то время были в ходу, потому что потребляли меньше памяти. Но мы их рассматривать не будем.
Битовые потоки
Deflate сохраняет кодовые слова Хаффмана в битовом потоке по принципу LSB-first. Это означает, что первый бит потока сохраняется в наименее младшем значащем бите первого байта.
Рассмотрим битовый поток (читается слева направо) 1-0-0-1-1. Когда он сохраняется по принципу LSB-first, то значение байта становится 0b00011001 (двоичное) или 0x19 (шестнадцатеричное). Может показаться, что поток просто представлен задом наперёд (в некотором смысле так и есть), но преимущество заключается в том, что так нам проще получить первые N битов из компьютерного слова: просто скрываем N младших битов.
Эти процедуры взяты из bitstream.h:
/* Input bitstream. */
typedef struct istream_t istream_t;
struct istream_t {
const uint8_t *src; /* Source bytes. */
const uint8_t *end; /* Past-the-end byte of src. */
size_t bitpos; /* Position of the next bit to read. */
size_t bitpos_end; /* Position of past-the-end bit. */
};
/* Initialize an input stream to present the n bytes from src as an LSB-first
* bitstream. */
static inline void istream_init(istream_t *is, const uint8_t *src, size_t n)
{
is->src = src;
is->end = src + n;
is->bitpos = 0;
is->bitpos_end = n * 8;
}
Нашему декодеру Хаффмана нужно смотреть на следующие биты в потоке (достаточно битов для самого длинного возможного кодового слова), а затем продолжать поток на количество битов, использованных декодированным символом:
#define ISTREAM_MIN_BITS (64 - 7)
/* Get the next bits from the input stream. The number of bits returned is
* between ISTREAM_MIN_BITS and 64, depending on the position in the stream, or
* fewer if the end of stream is reached. The upper bits are zero-padded. */
static inline uint64_t istream_bits(const istream_t *is)
{
const uint8_t *next;
uint64_t bits;
int i;
next = is->src + (is->bitpos / 8);
assert(next <= is->end && "Cannot read past end of stream.");
if (is->end - next >= 8) {
/* Common case: read 8 bytes in one go. */
bits = read64le(next);
} else {
/* Read the available bytes and zero-pad. */
bits = 0;
for (i = 0; i < is->end - next; i++) {
bits |= (uint64_t)next[i] << (i * 8);
}
}
return bits >> (is->bitpos % 8);
}
/* Advance n bits in the bitstream if possible. Returns false if that many bits
* are not available in the stream. */
static inline bool istream_advance(istream_t *is, size_t n) {
if (is->bitpos + n > is->bitpos_end) {
return false;
}
is->bitpos += n;
return true;
}
Суть в том, что на 64-битных машинах
istream_bits обычно можно исполнять как инструкцию одиночной загрузки и каких-то арифметических действий, учитывая, что элементы структуры istream_t находятся в регистрах. read64le реализован в bits.h (современные компиляторы преобразуют его в одиночную 64-битную загрузку по принципу little-endian):/* Read a 64-bit value from p in little-endian byte order. */
static inline uint64_t read64le(const uint8_t *p)
{
/* The one true way, see
* https://commandcenter.blogspot.com/2012/04/byte-order-fallacy.html */
return ((uint64_t)p[0] << 0) |
((uint64_t)p[1] << 8) |
((uint64_t)p[2] << 16) |
((uint64_t)p[3] << 24) |
((uint64_t)p[4] << 32) |
((uint64_t)p[5] << 40) |
((uint64_t)p[6] << 48) |
((uint64_t)p[7] << 56);
}
Также нам нужна функция для продолжения битового потока к границе следующего байта:
/* Round x up to the next multiple of m, which must be a power of 2. */
static inline size_t round_up(size_t x, size_t m)
{
assert((m & (m - 1)) == 0 && "m must be a power of two");
return (x + m - 1) & (size_t)(-m); /* Hacker's Delight (2nd), 3-1. */
}
/* Align the input stream to the next 8-bit boundary and return a pointer to
* that byte, which may be the past-the-end-of-stream byte. */
static inline const uint8_t *istream_byte_align(istream_t *is)
{
const uint8_t *byte;
assert(is->bitpos <= is->bitpos_end && "Not past end of stream.");
is->bitpos = round_up(is->bitpos, 8);
byte = is->src + is->bitpos / 8;
assert(byte <= is->end);
return byte;
}
Для исходящего битового потока мы пишем биты с помощью последовательности операций чтение-модификация-запись. В быстром случае записать бит можно с помощью 64-битного чтения, какой-то битовой операции и 64-битной записи.
/* Output bitstream. */
typedef struct ostream_t ostream_t;
struct ostream_t {
uint8_t *dst;
uint8_t *end;
size_t bitpos;
size_t bitpos_end;
};
/* Initialize an output stream to write LSB-first bits into dst[0..n-1]. */
static inline void ostream_init(ostream_t *os, uint8_t *dst, size_t n)
{
os->dst = dst;
os->end = dst + n;
os->bitpos = 0;
os->bitpos_end = n * 8;
}
/* Get the current bit position in the stream. */
static inline size_t ostream_bit_pos(const ostream_t *os)
{
return os->bitpos;
}
/* Return the number of bytes written to the output buffer. */
static inline size_t ostream_bytes_written(ostream_t *os)
{
return round_up(os->bitpos, 8) / 8;
}
/* Write n bits to the output stream. Returns false if there is not enough room
* at the destination. */
static inline bool ostream_write(ostream_t *os, uint64_t bits, size_t n)
{
uint8_t *p;
uint64_t x;
int shift, i;
assert(n <= 57);
assert(bits <= ((uint64_t)1 << n) - 1 && "Must fit in n bits.");
if (os->bitpos_end - os->bitpos < n) {
/* Not enough room. */
return false;
}
p = &os->dst[os->bitpos / 8];
shift = os->bitpos % 8;
if (os->end - p >= 8) {
/* Common case: read and write 8 bytes in one go. */
x = read64le(p);
x = lsb(x, shift);
x |= bits << shift;
write64le(p, x);
} else {
/* Slow case: read/write as many bytes as are available. */
x = 0;
for (i = 0; i < os->end - p; i++) {
x |= (uint64_t)p[i] << (i * 8);
}
x = lsb(x, shift);
x |= bits << shift;
for (i = 0; i < os->end - p; i++) {
p[i] = (uint8_t)(x >> (i * 8));
}
}
os->bitpos += n;
return true;
}
/* Write a 64-bit value x to dst in little-endian byte order. */
static inline void write64le(uint8_t *dst, uint64_t x)
{
dst[0] = (uint8_t)(x >> 0);
dst[1] = (uint8_t)(x >> 8);
dst[2] = (uint8_t)(x >> 16);
dst[3] = (uint8_t)(x >> 24);
dst[4] = (uint8_t)(x >> 32);
dst[5] = (uint8_t)(x >> 40);
dst[6] = (uint8_t)(x >> 48);
dst[7] = (uint8_t)(x >> 56);
}
Также нам нужно эффективно записывать в поток байты. Конечно, можно многократно выполнять 8-битные записи, но гораздо быстрее будет использовать
memcpy:/* Align the bitstream to the next byte boundary, then write the n bytes from
src to it. Returns false if there is not enough room in the stream. */
static inline bool ostream_write_bytes_aligned(ostream_t *os,
const uint8_t *src,
size_t n)
{
if (os->bitpos_end - round_up(os->bitpos, 8) < n * 8) {
return false;
}
os->bitpos = round_up(os->bitpos, 8);
memcpy(&os->dst[os->bitpos / 8], src, n);
os->bitpos += n * 8;
return true;
}
Распаковка (Inflation)
Поскольку алгоритм сжатия называется Deflate — сдувание, извлечение воздуха из чего-либо, — то процесс распаковки иногда называют Inflation (накачивание). Если первым делом изучить этот процесс, то мы поймём, как работает формат. Код можно посмотреть в первой части deflate.h и deflate.c, bits.h, tables.h и tables.c (сгенерирован с помощью generate_tables.c).
Данные, сжатые с помощью Deflate, хранятся в виде серии блоков. Каждый блок начинается с 3-битного заголовка, в котором первый (младший значимый) бит задаётся в том случае, если это финальный блок серии, а остальные два бита обозначают его тип.

Есть три типа блоков: несжатый (0), сжатый с помощью фиксированных кодов Хаффмана (1) и сжатый с помощью «динамических» кодов Хаффмана (2).
Этот код выполняет распаковку с использованием вспомогательных функций для разных типов блоков, которые мы реализуем позднее:
typedef enum {
HWINF_OK, /* Inflation was successful. */
HWINF_FULL, /* Not enough room in the output buffer. */
HWINF_ERR /* Error in the input data. */
} inf_stat_t;
/* Decompress (inflate) the Deflate stream in src. The number of input bytes
used, at most src_len, is stored in *src_used on success. Output is written
to dst. The number of bytes written, at most dst_cap, is stored in *dst_used
on success. src[0..src_len-1] and dst[0..dst_cap-1] must not overlap.
Returns a status value as defined above. */
inf_stat_t hwinflate(const uint8_t *src, size_t src_len, size_t *src_used,
uint8_t *dst, size_t dst_cap, size_t *dst_used)
{
istream_t is;
size_t dst_pos;
uint64_t bits;
bool bfinal;
inf_stat_t s;
istream_init(&is, src, src_len);
dst_pos = 0;
do {
/* Read the 3-bit block header. */
bits = istream_bits(&is);
if (!istream_advance(&is, 3)) {
return HWINF_ERR;
}
bfinal = bits & 1;
bits >>= 1;
switch (lsb(bits, 2)) {
case 0: /* 00: No compression. */
s = inf_noncomp_block(&is, dst, dst_cap, &dst_pos);
break;
case 1: /* 01: Compressed with fixed Huffman codes. */
s = inf_fixed_block(&is, dst, dst_cap, &dst_pos);
break;
case 2: /* 10: Compressed with "dynamic" Huffman codes. */
s = inf_dyn_block(&is, dst, dst_cap, &dst_pos);
break;
default: /* Invalid block type. */
return HWINF_ERR;
}
if (s != HWINF_OK) {
return s;
}
} while (!bfinal);
*src_used = (size_t)(istream_byte_align(&is) - src);
assert(dst_pos <= dst_cap);
*dst_used = dst_pos;
return HWINF_OK;
}
Несжатые Deflate-блоки
Это «хранимые» блоки, простейший тип. Он начинается со следующей 8-битной границы битового потока с 16 битного слова (len), обозначающего длину блока. За ним идёт другое 16-битное слово (nlen), которое дополняет (порядок битов инвертирован) слов len. Предполагается, что nlen действует как простая контрольная сумма len: если файл повреждён, то, вероятно, значения уже не будут взаимодополняющими и программа сможет обнаружить ошибку.

После len и nlen идут несжатые данные. Поскольку длина блока представляет собой 16-битное значение, размер данных ограничен 65 535 байтами.
static inf_stat_t inf_noncomp_block(istream_t *is, uint8_t *dst,
size_t dst_cap, size_t *dst_pos)
{
const uint8_t *p;
uint16_t len, nlen;
p = istream_byte_align(is);
/* Read len and nlen (2 x 16 bits). */
if (!istream_advance(is, 32)) {
return HWINF_ERR; /* Not enough input. */
}
len = read16le(p);
nlen = read16le(p + 2);
p += 4;
if (nlen != (uint16_t)~len) {
return HWINF_ERR;
}
if (!istream_advance(is, len * 8)) {
return HWINF_ERR; /* Not enough input. */
}
if (dst_cap - *dst_pos < len) {
return HWINF_FULL; /* Not enough room to output. */
}
memcpy(&dst[*dst_pos], p, len);
*dst_pos += len;
return HWINF_OK;
}
Deflate-блоки с применением фиксированных кодов Хаффмана
Сжатые Deflate-блоки используют код Хаффмана для представления последовательности LZ77-литералов. Обратные ссылки прерываются с помощью маркеров конца блока. Для литералов, длин обратных ссылок и маркеров используется код Хаффмана litlen. А для расстояний обратных ссылок используется код dist.

С помощью litlen кодируются значения в диапазоне 0-285. Значения 0-255 используются для байтов литералов, 256 — маркер конца блока, а 257-285 используются для длин обратных ссылок.
Обратные ссылки бывают длиной 3-258 байтов. Litlen-значение определяет базовую длину, к которой из потока добавляется ноль или больше дополнительных битов, чтобы получилась полная длина согласно нижеприведённой таблице. Например, litlen-значение 269 означает базовую длину 19 и два дополнительных бита. Прибавка двух битов из потока даёт финальную длину от 19 до 22.
| Litlen | Дополнительные биты | Длины |
| 257 | 0 | 3 |
| 258 | 0 | 4 |
| 259 | 0 | 5 |
| 260 | 0 | 6 |
| 261 | 0 | 7 |
| 262 | 0 | 8 |
| 263 | 0 | 9 |
| 264 | 0 | 10 |
| 265 | 1 | 11–12 |
| 266 | 1 | 13–14 |
| 267 | 1 | 15–16 |
| 268 | 1 | 17–18 |
| 269 | 2 | 19–22 |
| 270 | 2 | 23–26 |
| 271 | 2 | 27–30 |
| 272 | 2 | 31–34 |
| 273 | 3 | 35–42 |
| 274 | 3 | 43–50 |
| 275 | 3 | 51–58 |
| 276 | 3 | 59–66 |
| 277 | 4 | 67–82 |
| 278 | 4 | 83–98 |
| 279 | 4 | 99–114 |
| 280 | 4 | 115–130 |
| 281 | 5 | 131–162 |
| 282 | 5 | 163–194 |
| 283 | 5 | 195–226 |
| 284 | 5 | 227–257 |
| 285 | 0 | 258 |
Обратите внимание, что litlen-значение 284 плюс 5 дополнительных битов может представлять длины от 227 до 258, однако в спецификации указано, что длина 258 — максимальная длина обратной ссылки — должна быть представлена с помощью отдельного litlen-значения. Предполагается, что это позволяет сократить кодирование в ситуациях, когда часто встречается максимальная длина.
Декомпрессор использует использует таблицу для получения из litlen-значения (минус 257) базовой длины и дополнительных битов:
/* Table of litlen symbol values minus 257 with corresponding base length
and number of extra bits. */
struct litlen_tbl_t {
uint16_t base_len : 9;
uint16_t ebits : 7;
};
const struct litlen_tbl_t litlen_tbl[29] = {
/* 257 */ { 3, 0 },
/* 258 */ { 4, 0 },
...
/* 284 */ { 227, 5 },
/* 285 */ { 258, 0 }
};
Фиксированный litlen-код Хаффмана является каноническим и использует следующие длины кодовых слов (286–287 не являются корректными litlen-значениями, но они участвуют в генерировании кодов):
| Litlen-значения | Длина кодового слова |
| 0–143 | 8 |
| 144–255 | 9 |
| 256–279 | 7 |
| 280–287 | 8 |
Декомпрессор сохраняет эти длины в таблицу, удобную для передачи в
huffman_decoder_init:const uint8_t fixed_litlen_lengths[288] = {
/* 0 */ 8,
/* 1 */ 8,
...
/* 287 */ 8,
};
Расстояния обратных ссылок меняются от 1 до 32 768. Они кодируются с помощью схемы, которая аналогична схеме кодирования длин. Код Хаффмана dist кодирует значения от 0 до 29, каждое из которых соответствует базовой длине, к которой добавляются дополнительные биты для получения финального расстояния:
| Dist | Дополнительные биты | Расстояния |
| 0 | 0 | 1 |
| 1 | 0 | 2 |
| 2 | 0 | 3 |
| 3 | 0 | 4 |
| 4 | 1 | 5–6 |
| 5 | 1 | 7–8 |
| 6 | 2 | 9–12 |
| 7 | 2 | 13–16 |
| 8 | 3 | 17–24 |
| 9 | 3 | 25–32 |
| 10 | 4 | 33–48 |
| 11 | 4 | 49–64 |
| 12 | 5 | 65–96 |
| 13 | 5 | 97–128 |
| 14 | 6 | 129–192 |
| 15 | 6 | 193–256 |
| 16 | 7 | 257–384 |
| 17 | 7 | 385–512 |
| 18 | 8 | 513–768 |
| 19 | 8 | 769–1024 |
| 20 | 9 | 1025–1536 |
| 21 | 9 | 1537–2048 |
| 22 | 10 | 2049–3072 |
| 23 | 10 | 3073–4096 |
| 24 | 11 | 4097–6144 |
| 25 | 11 | 6145–8192 |
| 26 | 12 | 8193–12288 |
| 27 | 12 | 12289–16384 |
| 28 | 13 | 16385–24576 |
| 29 | 13 | 24577–32768 |
Фиксированный код Хаффмана dist является каноническим. Все кодовые слова длиной 5 битов. Он прост, декомпрессор хранит коды в таблице, которую можно использовать с
huffman_decoder_init (dist-значения 30–31 не являются корректными. Указано, что они участвуют в генерировании кодов Хаффмана, но на самом деле не оказывают никакого эффекта):const uint8_t fixed_dist_lengths[32] = {
/* 0 */ 5,
/* 1 */ 5,
...
/* 31 */ 5,
};
Код декомпрессии, или распаковки — Deflate-блок с использованием фиксированных кодов Хаффмана:
static inf_stat_t inf_fixed_block(istream_t *is, uint8_t *dst,
size_t dst_cap, size_t *dst_pos)
{
huffman_decoder_t litlen_dec, dist_dec;
huffman_decoder_init(&litlen_dec, fixed_litlen_lengths,
sizeof(fixed_litlen_lengths) /
sizeof(fixed_litlen_lengths[0]));
huffman_decoder_init(&dist_dec, fixed_dist_lengths,
sizeof(fixed_dist_lengths) /
sizeof(fixed_dist_lengths[0]));
return inf_block(is, dst, dst_cap, dst_pos, &litlen_dec, &dist_dec);
}
#define LITLEN_EOB 256
#define LITLEN_MAX 285
#define LITLEN_TBL_OFFSET 257
#define MIN_LEN 3
#define MAX_LEN 258
#define DISTSYM_MAX 29
#define MIN_DISTANCE 1
#define MAX_DISTANCE 32768
static inf_stat_t inf_block(istream_t *is, uint8_t *dst, size_t dst_cap,
size_t *dst_pos,
const huffman_decoder_t *litlen_dec,
const huffman_decoder_t *dist_dec)
{
uint64_t bits;
size_t used, used_tot, dist, len;
int litlen, distsym;
uint16_t ebits;
while (true) {
/* Read a litlen symbol. */
bits = istream_bits(is);
litlen = huffman_decode(litlen_dec, (uint16_t)bits, &used);
bits >>= used;
used_tot = used;
if (litlen < 0 || litlen > LITLEN_MAX) {
/* Failed to decode, or invalid symbol. */
return HWINF_ERR;
} else if (litlen <= UINT8_MAX) {
/* Literal. */
if (!istream_advance(is, used_tot)) {
return HWINF_ERR;
}
if (*dst_pos == dst_cap) {
return HWINF_FULL;
}
lz77_output_lit(dst, (*dst_pos)++, (uint8_t)litlen);
continue;
} else if (litlen == LITLEN_EOB) {
/* End of block. */
if (!istream_advance(is, used_tot)) {
return HWINF_ERR;
}
return HWINF_OK;
}
/* It is a back reference. Figure out the length. */
assert(litlen >= LITLEN_TBL_OFFSET && litlen <= LITLEN_MAX);
len = litlen_tbl[litlen - LITLEN_TBL_OFFSET].base_len;
ebits = litlen_tbl[litlen - LITLEN_TBL_OFFSET].ebits;
if (ebits != 0) {
len += lsb(bits, ebits);
bits >>= ebits;
used_tot += ebits;
}
assert(len >= MIN_LEN && len <= MAX_LEN);
/* Get the distance. */
distsym = huffman_decode(dist_dec, (uint16_t)bits, &used);
bits >>= used;
used_tot += used;
if (distsym < 0 || distsym > DISTSYM_MAX) {
/* Failed to decode, or invalid symbol. */
return HWINF_ERR;
}
dist = dist_tbl[distsym].base_dist;
ebits = dist_tbl[distsym].ebits;
if (ebits != 0) {
dist += lsb(bits, ebits);
bits >>= ebits;
used_tot += ebits;
}
assert(dist >= MIN_DISTANCE && dist <= MAX_DISTANCE);
assert(used_tot <= ISTREAM_MIN_BITS);
if (!istream_advance(is, used_tot)) {
return HWINF_ERR;
}
/* Bounds check and output the backref. */
if (dist > *dst_pos) {
return HWINF_ERR;
}
if (round_up(len, 8) <= dst_cap - *dst_pos) {
output_backref64(dst, *dst_pos, dist, len);
} else if (len <= dst_cap - *dst_pos) {
lz77_output_backref(dst, *dst_pos, dist, len);
} else {
return HWINF_FULL;
}
(*dst_pos) += len;
}
}
Обратите внимание на такую оптимизацию: когда в исходящем буфере недостаточно места, мы выдаём обратные ссылки с помощью нижеприведённой функции, которая копирует по 64 бита за раз. Это «неаккуратно» в том смысле, что при этом часто копируется несколько дополнительных байтов (до следующего значения, кратного 8). Но работает гораздо быстрее
lz77_output_backref, потому что требует меньше циклических итераций и обращений к памяти. По сути, короткие обратные ссылки теперь будут обрабатываться за одну итерацию, что очень хорошо для прогнозирования ветвления./* Output the (dist,len) backref at dst_pos in dst using 64-bit wide writes.
There must be enough room for len bytes rounded to the next multiple of 8. */
static void output_backref64(uint8_t *dst, size_t dst_pos, size_t dist,
size_t len)
{
size_t i;
uint64_t tmp;
assert(len > 0);
assert(dist <= dst_pos && "cannot reference before beginning of dst");
if (len > dist) {
/* Self-overlapping backref; fall back to byte-by-byte copy. */
lz77_output_backref(dst, dst_pos, dist, len);
return;
}
i = 0;
do {
memcpy(&tmp, &dst[dst_pos - dist + i], 8);
memcpy(&dst[dst_pos + i], &tmp, 8);
i += 8;
} while (i < len);
}
Deflate-блоки с применением динамических кодов Хаффмана
Deflate-блоки, использующие динамические коды Хаффмана, работают так же, как описано выше. Но вместо заранее определённых кодов для litlen и dist они используют коды, хранящиеся в самом Deflate-потоке, в начале блока. Название, пожалуй, неудачное, поскольку динамическими кодами Хаффмана также называют коды, которые меняются в ходе кодирования — это адаптивное кодирование Хаффмана. Описанные здесь коды не имеют к той процедуре никакого отношения. Они динамические лишь в том смысле, что разные блоки могут использовать разные коды.
Генерирование динамических litlen- и dist-кодов является самой сложной частью Deflate-формата. Но как только коды сгенерированы, декомпрессия выполняется так же, как описано в предыдущей части, с использованием
inf_block:static inf_stat_t inf_dyn_block(istream_t *is, uint8_t *dst,
size_t dst_cap, size_t *dst_pos)
{
inf_stat_t s;
huffman_decoder_t litlen_dec, dist_dec;
s = init_dyn_decoders(is, &litlen_dec, &dist_dec);
if (s != HWINF_OK) {
return s;
}
return inf_block(is, dst, dst_cap, dst_pos, &litlen_dec, &dist_dec);
}
Litlen- и dist-коды для динамических Deflate-блоков хранятся в виде серий длин кодовых слов. Сами длины закодированы с помощью третьего кода Хаффмана — codelen. Этот код определяется длиной кодовых слов (
codelen_lens), которые хранятся в блоке (я уже говорил, что это сложно?).
В начале динамического блока находятся 14 битов, которые определяют количество litlen-, dist- и codelen-длин кодовых слов, которые нужно прочитать из блока:
#define MIN_CODELEN_LENS 4
#define MAX_CODELEN_LENS 19
#define MIN_LITLEN_LENS 257
#define MAX_LITLEN_LENS 288
#define MIN_DIST_LENS 1
#define MAX_DIST_LENS 32
#define CODELEN_MAX_LIT 15
#define CODELEN_COPY 16
#define CODELEN_COPY_MIN 3
#define CODELEN_COPY_MAX 6
#define CODELEN_ZEROS 17
#define CODELEN_ZEROS_MIN 3
#define CODELEN_ZEROS_MAX 10
#define CODELEN_ZEROS2 18
#define CODELEN_ZEROS2_MIN 11
#define CODELEN_ZEROS2_MAX 138
/* RFC 1951, 3.2.7 */
static const int codelen_lengths_order[MAX_CODELEN_LENS] =
{ 16, 17, 18, 0, 8, 7, 9, 6, 10, 5, 11, 4, 12, 3, 13, 2, 14, 1, 15 };
static inf_stat_t init_dyn_decoders(istream_t *is,
huffman_decoder_t *litlen_dec,
huffman_decoder_t *dist_dec)
{
uint64_t bits;
size_t num_litlen_lens, num_dist_lens, num_codelen_lens;
uint8_t codelen_lengths[MAX_CODELEN_LENS];
uint8_t code_lengths[MAX_LITLEN_LENS + MAX_DIST_LENS];
size_t i, n, used;
int sym;
huffman_decoder_t codelen_dec;
bits = istream_bits(is);
/* Number of litlen codeword lengths (5 bits + 257). */
num_litlen_lens = lsb(bits, 5) + MIN_LITLEN_LENS;
bits >>= 5;
assert(num_litlen_lens <= MAX_LITLEN_LENS);
/* Number of dist codeword lengths (5 bits + 1). */
num_dist_lens = lsb(bits, 5) + MIN_DIST_LENS;
bits >>= 5;
assert(num_dist_lens <= MAX_DIST_LENS);
/* Number of code length lengths (4 bits + 4). */
num_codelen_lens = lsb(bits, 4) + MIN_CODELEN_LENS;
bits >>= 4;
assert(num_codelen_lens <= MAX_CODELEN_LENS);
if (!istream_advance(is, 5 + 5 + 4)) {
return HWINF_ERR;
}
Затем идут длины кодовых слов для codelen-кода. Эти длины представляют собой обычные трёхбитные значения, но записанные в особом порядке, который задан в
codelen_lengths_order. Поскольку нужно определить 19 длин, из потока будет прочитан только num_codelen_lens; всё остальное является неявно нулевым. Длины перечисляются в определённом порядке, чтобы нулевые длины с большей вероятностью попадали в конец списка и не сохранялись в блоке. /* Read the codelen codeword lengths (3 bits each)
and initialize the codelen decoder. */
for (i = 0; i < num_codelen_lens; i++) {
bits = istream_bits(is);
codelen_lengths[codelen_lengths_order[i]] =
(uint8_t)lsb(bits, 3);
if (!istream_advance(is, 3)) {
return HWINF_ERR;
}
}
for (; i < MAX_CODELEN_LENS; i++) {
codelen_lengths[codelen_lengths_order[i]] = 0;
}
if (!huffman_decoder_init(&codelen_dec, codelen_lengths,
MAX_CODELEN_LENS)) {
return HWINF_ERR;
}
С помощью настройки codelen-декодера мы можем считывать из потока длины кодовых слов litlen и dist.
/* Read the litlen and dist codeword lengths. */
i = 0;
while (i < num_litlen_lens + num_dist_lens) {
bits = istream_bits(is);
sym = huffman_decode(&codelen_dec, (uint16_t)bits, &used);
bits >>= used;
if (!istream_advance(is, used)) {
return HWINF_ERR;
}
if (sym >= 0 && sym <= CODELEN_MAX_LIT) {
/* A literal codeword length. */
code_lengths[i++] = (uint8_t)sym;
}
16, 17 и 18 не являются настоящими длинами, это индикаторы того, что предыдущую длину нужно повторить какое-то количество раз, или что нужно повторить нулевую длину:
else if (sym == CODELEN_COPY) {
/* Copy the previous codeword length 3--6 times. */
if (i < 1) {
return HWINF_ERR; /* No previous length. */
}
n = lsb(bits, 2) + CODELEN_COPY_MIN; /* 2 bits + 3 */
if (!istream_advance(is, 2)) {
return HWINF_ERR;
}
assert(n >= CODELEN_COPY_MIN && n <= CODELEN_COPY_MAX);
if (i + n > num_litlen_lens + num_dist_lens) {
return HWINF_ERR;
}
while (n--) {
code_lengths[i] = code_lengths[i - 1];
i++;
}
} else if (sym == CODELEN_ZEROS) {
/* 3--10 zeros. */
n = lsb(bits, 3) + CODELEN_ZEROS_MIN; /* 3 bits + 3 */
if (!istream_advance(is, 3)) {
return HWINF_ERR;
}
assert(n >= CODELEN_ZEROS_MIN &&
n <= CODELEN_ZEROS_MAX);
if (i + n > num_litlen_lens + num_dist_lens) {
return HWINF_ERR;
}
while (n--) {
code_lengths[i++] = 0;
}
} else if (sym == CODELEN_ZEROS2) {
/* 11--138 zeros. */
n = lsb(bits, 7) + CODELEN_ZEROS2_MIN; /* 7 bits +138 */
if (!istream_advance(is, 7)) {
return HWINF_ERR;
}
assert(n >= CODELEN_ZEROS2_MIN &&
n <= CODELEN_ZEROS2_MAX);
if (i + n > num_litlen_lens + num_dist_lens) {
return HWINF_ERR;
}
while (n--) {
code_lengths[i++] = 0;
}
} else {
/* Invalid symbol. */
return HWINF_ERR;
}
}
Обратите внимание, что litlen- и dist-длины считываются одна за другой в массив
code_lengths. Они не могут считываться отдельно, потому что прогоны длин кода могут переноситься с последних litlen-длин на первые dist-длины.Подготовив длины кодовых слов, мы можем настроить декодеры Хаффмана и вернуться к задаче декодирования литералов и обратных ссылок:
if (!huffman_decoder_init(litlen_dec, &code_lengths[0],
num_litlen_lens)) {
return HWINF_ERR;
}
if (!huffman_decoder_init(dist_dec, &code_lengths[num_litlen_lens],
num_dist_lens)) {
return HWINF_ERR;
}
return HWINF_OK;
}
Сжатие (Deflation)
В предыдущих частях мы создали все инструменты, необходимые для Deflate-сжатия: Lempel-Ziv, кодирование Хаффмана, битовые потоки и описание трёх типов Deflate-блоков. А в этой части мы соберём всё вместе, чтобы получилось Deflate-сжатие.
Сжатие Lempel-Ziv парсит исходные данные в последовательность обратных ссылок и литералов. Эту последовательность нужно разделить и закодировать в Deflate-блоки, как описано в предыдущей части. Выбор способа разделения часто называют разбиением на блоки. С одной стороны, каждый новый блок означает какие-то накладные расходы, объём которых зависит от типа блока и его содержимого. Меньше блоков — меньше накладных расходов. С другой стороны, эти расходы на создание нового блока могут окупаться. Например, если характеристики данных позволяют эффективнее выполнять кодирование Хаффмана и уменьшать общий объём генерируемых данных.
Разбиение на блоки — сложная задача по оптимизации. Некоторые компрессоры (например, Zopfli) стараются лучше других, но большинство просто используют жадный подход: выдают блоки, как только те достигают определённого размера.
У разных типов блоков свои ограничения размеров:
- Несжатые блоки могут содержать не больше 65 535 байтов.
- Фиксированные коды Хаффмана не имеют максимального размера.
- Динамические коды Хаффмана в целом не имеют максимального размера, но поскольку наша реализация алгоритма Хаффмана используется 16-битные последовательности символов, мы ограничены 65 535 символами.
Чтобы свободно использовать блоки любого типа, ограничим их размер 65 534 байтами:
/* The largest number of bytes that will fit in any kind of block is 65,534.
It will fit in an uncompressed block (max 65,535 bytes) and a Huffman
block with only literals (65,535 symbols including end-of-block marker). */
#define MAX_BLOCK_LEN_BYTES 65534
Для отслеживания исходящего битового потока и содержимого текущего блока в ходе сжатия будем использовать структуру:
typedef struct deflate_state_t deflate_state_t;
struct deflate_state_t {
ostream_t os;
const uint8_t *block_src; /* First src byte in the block. */
size_t block_len; /* Number of symbols in the current block. */
size_t block_len_bytes; /* Number of src bytes in the block. */
/* Symbol frequencies for the current block. */
uint16_t litlen_freqs[LITLEN_MAX + 1];
uint16_t dist_freqs[DISTSYM_MAX + 1];
struct {
uint16_t distance; /* Backref distance. */
union {
uint16_t lit; /* Literal byte or end-of-block. */
uint16_t len; /* Backref length (distance != 0). */
} u;
} block[MAX_BLOCK_LEN_BYTES + 1];
};
static void reset_block(deflate_state_t *s)
{
s->block_len = 0;
s->block_len_bytes = 0;
memset(s->litlen_freqs, 0, sizeof(s->litlen_freqs));
memset(s->dist_freqs, 0, sizeof(s->dist_freqs));
}
Чтобы добавлять в блок результаты работы
lz77_compress будем использовать функции обратного вызова, и по достижении максимального размера запишем блок в битовый поток:static bool lit_callback(uint8_t lit, void *aux)
{
deflate_state_t *s = aux;
if (s->block_len_bytes + 1 > MAX_BLOCK_LEN_BYTES) {
if (!write_block(s, false)) {
return false;
}
s->block_src += s->block_len_bytes;
reset_block(s);
}
assert(s->block_len < sizeof(s->block) / sizeof(s->block[0]));
s->block[s->block_len ].distance = 0;
s->block[s->block_len++].u.lit = lit;
s->block_len_bytes++;
s->litlen_freqs[lit]++;
return true;
}
static bool backref_callback(size_t dist, size_t len, void *aux)
{
deflate_state_t *s = aux;
if (s->block_len_bytes + len > MAX_BLOCK_LEN_BYTES) {
if (!write_block(s, false)) {
return false;
}
s->block_src += s->block_len_bytes;
reset_block(s);
}
assert(s->block_len < sizeof(s->block) / sizeof(s->block[0]));
s->block[s->block_len ].distance = (uint16_t)dist;
s->block[s->block_len++].u.len = (uint16_t)len;
s->block_len_bytes += len;
assert(len >= MIN_LEN && len <= MAX_LEN);
assert(dist >= MIN_DISTANCE && dist <= MAX_DISTANCE);
s->litlen_freqs[len2litlen[len]]++;
s->dist_freqs[distance2dist[dist]]++;
return true;
}
Самое интересное — запись блоков. Если блок не сжат, то всё просто:
static bool write_uncomp_block(deflate_state_t *s, bool final)
{
uint8_t len_nlen[4];
/* Write the block header. */
if (!ostream_write(&s->os, (0x0 << 1) | final, 3)) {
return false;
}
len_nlen[0] = (uint8_t)(s->block_len_bytes >> 0);
len_nlen[1] = (uint8_t)(s->block_len_bytes >> 8);
len_nlen[2] = ~len_nlen[0];
len_nlen[3] = ~len_nlen[1];
if (!ostream_write_bytes_aligned(&s->os, len_nlen, sizeof(len_nlen))) {
return false;
}
if (!ostream_write_bytes_aligned(&s->os, s->block_src,
s->block_len_bytes)) {
return false;
}
return true;
}
Для записи статичного блока Хаффмана мы сначала сгенерируем канонические коды на основе фиксированных длин кодовых слов для litlen- и dist-кодов. Затем итерируем блок, записывая символы, которые используют эти коды:
static bool write_static_block(deflate_state_t *s, bool final)
{
huffman_encoder_t litlen_enc, dist_enc;
/* Write the block header. */
if (!ostream_write(&s->os, (0x1 << 1) | final, 3)) {
return false;
}
huffman_encoder_init2(&litlen_enc, fixed_litlen_lengths,
sizeof(fixed_litlen_lengths) /
sizeof(fixed_litlen_lengths[0]));
huffman_encoder_init2(&dist_enc, fixed_dist_lengths,
sizeof(fixed_dist_lengths) /
sizeof(fixed_dist_lengths[0]));
return write_huffman_block(s, &litlen_enc, &dist_enc);
}
static bool write_huffman_block(deflate_state_t *s,
const huffman_encoder_t *litlen_enc,
const huffman_encoder_t *dist_enc)
{
size_t i, nbits;
uint64_t distance, dist, len, litlen, bits, ebits;
for (i = 0; i < s->block_len; i++) {
if (s->block[i].distance == 0) {
/* Literal or EOB. */
litlen = s->block[i].u.lit;
assert(litlen <= LITLEN_EOB);
if (!ostream_write(&s->os,
litlen_enc->codewords[litlen],
litlen_enc->lengths[litlen])) {
return false;
}
continue;
}
/* Back reference length. */
len = s->block[i].u.len;
litlen = len2litlen[len];
/* litlen bits */
bits = litlen_enc->codewords[litlen];
nbits = litlen_enc->lengths[litlen];
/* ebits */
ebits = len - litlen_tbl[litlen - LITLEN_TBL_OFFSET].base_len;
bits |= ebits << nbits;
nbits += litlen_tbl[litlen - LITLEN_TBL_OFFSET].ebits;
/* Back reference distance. */
distance = s->block[i].distance;
dist = distance2dist[distance];
/* dist bits */
bits |= (uint64_t)dist_enc->codewords[dist] << nbits;
nbits += dist_enc->lengths[dist];
/* ebits */
ebits = distance - dist_tbl[dist].base_dist;
bits |= ebits << nbits;
nbits += dist_tbl[dist].ebits;
if (!ostream_write(&s->os, bits, nbits)) {
return false;
}
}
return true;
}
Конечно, записывать динамические блоки Хаффмана сложнее, потому что они содержат хитрое кодирование litlen- и dist-кодов. Для представления этого кодирования воспользуемся такой структурой:
typedef struct codelen_sym_t codelen_sym_t;
struct codelen_sym_t {
uint8_t sym;
uint8_t count; /* For symbols 16, 17, 18. */
};
Сначала мы отбрасываем хвост их нулевых длин кодовых слов litlen и dist, а потом копируем их в обычный массив для последующего кодирования. Мы не можем отбросить все нули: невозможно закодировать Deflate-блок, если в нём ни одного dist-кода. Также невозможно иметь меньше 257 litlen-кодов, но поскольку у нас всегда есть маркер окончания байта, то всегда будут ненулевая длина кода для символа 256.
/* Encode litlen_lens and dist_lens into encoded. *num_litlen_lens and
*num_dist_lens will be set to the number of encoded litlen and dist lens,
respectively. Returns the number of elements in encoded. */
static size_t encode_dist_litlen_lens(const uint8_t *litlen_lens,
const uint8_t *dist_lens,
codelen_sym_t *encoded,
size_t *num_litlen_lens,
size_t *num_dist_lens)
{
size_t i, n;
uint8_t lens[LITLEN_MAX + 1 + DISTSYM_MAX + 1];
*num_litlen_lens = LITLEN_MAX + 1;
*num_dist_lens = DISTSYM_MAX + 1;
/* Drop trailing zero litlen lengths. */
assert(litlen_lens[LITLEN_EOB] != 0 && "EOB len should be non-zero.");
while (litlen_lens[*num_litlen_lens - 1] == 0) {
(*num_litlen_lens)--;
}
assert(*num_litlen_lens >= MIN_LITLEN_LENS);
/* Drop trailing zero dist lengths, keeping at least one. */
while (dist_lens[*num_dist_lens - 1] == 0 && *num_dist_lens > 1) {
(*num_dist_lens)--;
}
assert(*num_dist_lens >= MIN_DIST_LENS);
/* Copy the lengths into a unified array. */
n = 0;
for (i = 0; i < *num_litlen_lens; i++) {
lens[n++] = litlen_lens[i];
}
for (i = 0; i < *num_dist_lens; i++) {
lens[n++] = dist_lens[i];
}
return encode_lens(lens, n, encoded);
}
Сложив длины кодов в один массив, мы выполняем кодирование, применяя специальные символы для прогона одинаковых длин кодов.
/* Encode the n code lengths in lens into encoded, returning the number of
elements in encoded. */
static size_t encode_lens(const uint8_t *lens, size_t n, codelen_sym_t *encoded)
{
size_t i, j, num_encoded;
uint8_t count;
i = 0;
num_encoded = 0;
while (i < n) {
if (lens[i] == 0) {
/* Scan past the end of this zero run (max 138). */
for (j = i; j < min(n, i + CODELEN_ZEROS2_MAX) &&
lens[j] == 0; j++);
count = (uint8_t)(j - i);
if (count < CODELEN_ZEROS_MIN) {
/* Output a single zero. */
encoded[num_encoded++].sym = 0;
i++;
continue;
}
/* Output a repeated zero. */
if (count <= CODELEN_ZEROS_MAX) {
/* Repeated zero 3--10 times. */
assert(count >= CODELEN_ZEROS_MIN &&
count <= CODELEN_ZEROS_MAX);
encoded[num_encoded].sym = CODELEN_ZEROS;
encoded[num_encoded++].count = count;
} else {
/* Repeated zero 11--138 times. */
assert(count >= CODELEN_ZEROS2_MIN &&
count <= CODELEN_ZEROS2_MAX);
encoded[num_encoded].sym = CODELEN_ZEROS2;
encoded[num_encoded++].count = count;
}
i = j;
continue;
}
/* Output len. */
encoded[num_encoded++].sym = lens[i++];
/* Scan past the end of the run of this len (max 6). */
for (j = i; j < min(n, i + CODELEN_COPY_MAX) &&
lens[j] == lens[i - 1]; j++);
count = (uint8_t)(j - i);
if (count >= CODELEN_COPY_MIN) {
/* Repeat last len 3--6 times. */
assert(count >= CODELEN_COPY_MIN &&
count <= CODELEN_COPY_MAX);
encoded[num_encoded].sym = CODELEN_COPY;
encoded[num_encoded++].count = count;
i = j;
continue;
}
}
return num_encoded;
}
Использованные для кодирования символы будут записаны с помощью кода Хаффмана — codelen. Длины кодовых слов из кода codelen записываются в блок в определённом порядке, чтобы нулевые длины с большей вероятностью оказывались в конце. Вот функция, подсчитывающая, сколько длин нужно записать:
static const int codelen_lengths_order[19] =
{ 16, 17, 18, 0, 8, 7, 9, 6, 10, 5, 11, 4, 12, 3, 13, 2, 14, 1, 15 };
/* Count the number of significant (not trailing zeros) codelen lengths. */
size_t count_codelen_lens(const uint8_t *codelen_lens)
{
size_t n = MAX_CODELEN_LENS;
/* Drop trailing zero lengths. */
while (codelen_lens[codelen_lengths_order[n - 1]] == 0) {
n--;
}
/* The first 4 lengths in the order (16, 17, 18, 0) cannot be used to
encode any non-zero lengths. Since there will always be at least
one non-zero codeword length (for EOB), n will be >= 4. */
assert(n >= MIN_CODELEN_LENS && n <= MAX_CODELEN_LENS);
return n;
}
Допустим, мы уже задали litlen- и dist-коды, настроили кодирование длин их кодовых слов и код для этих длин. Теперь можем записать динамический блок Хаффмана:
static bool write_dynamic_block(deflate_state_t *s, bool final,
size_t num_litlen_lens, size_t num_dist_lens,
size_t num_codelen_lens,
const huffman_encoder_t *codelen_enc,
const codelen_sym_t *encoded_lens,
size_t num_encoded_lens,
const huffman_encoder_t *litlen_enc,
const huffman_encoder_t *dist_enc)
{
size_t i;
uint8_t codelen, sym;
size_t nbits;
uint64_t bits, hlit, hdist, hclen, count;
/* Block header. */
bits = (0x2 << 1) | final;
nbits = 3;
/* hlit (5 bits) */
hlit = num_litlen_lens - MIN_LITLEN_LENS;
bits |= hlit << nbits;
nbits += 5;
/* hdist (5 bits) */
hdist = num_dist_lens - MIN_DIST_LENS;
bits |= hdist << nbits;
nbits += 5;
/* hclen (4 bits) */
hclen = num_codelen_lens - MIN_CODELEN_LENS;
bits |= hclen << nbits;
nbits += 4;
if (!ostream_write(&s->os, bits, nbits)) {
return false;
}
/* Codelen lengths. */
for (i = 0; i < num_codelen_lens; i++) {
codelen = codelen_enc->lengths[codelen_lengths_order[i]];
if (!ostream_write(&s->os, codelen, 3)) {
return false;
}
}
/* Litlen and dist code lengths. */
for (i = 0; i < num_encoded_lens; i++) {
sym = encoded_lens[i].sym;
bits = codelen_enc->codewords[sym];
nbits = codelen_enc->lengths[sym];
count = encoded_lens[i].count;
if (sym == CODELEN_COPY) { /* 2 ebits */
bits |= (count - CODELEN_COPY_MIN) << nbits;
nbits += 2;
} else if (sym == CODELEN_ZEROS) { /* 3 ebits */
bits |= (count - CODELEN_ZEROS_MIN) << nbits;
nbits += 3;
} else if (sym == CODELEN_ZEROS2) { /* 7 ebits */
bits |= (count - CODELEN_ZEROS2_MIN) << nbits;
nbits += 7;
}
if (!ostream_write(&s->os, bits, nbits)) {
return false;
}
}
return write_huffman_block(s, litlen_enc, dist_enc);
}
Для каждого блока мы хотим использовать тот тип, которому требуется наименьшее количество битов. Длину несжатого блока можно вычислить быстро:
/* Calculate the number of bits for an uncompressed block, including header. */
static size_t uncomp_block_len(const deflate_state_t *s)
{
size_t bit_pos, padding;
/* Bit position after writing the block header. */
bit_pos = ostream_bit_pos(&s->os) + 3;
padding = round_up(bit_pos, 8) - bit_pos;
/* Header + padding + len/nlen + block contents. */
return 3 + padding + 2 * 16 + s->block_len_bytes * 8;
}
Для блоков, закодированных по Хаффману, можно вычислить длину тела с помощью litlen- и dist-частот символов и длин кодовых слов:
/* Calculate the number of bits for a Huffman encoded block body. */
static size_t huffman_block_body_len(const deflate_state_t *s,
const uint8_t *litlen_lens,
const uint8_t *dist_lens)
{
size_t i, freq, len;
len = 0;
for (i = 0; i <= LITLEN_MAX; i++) {
freq = s->litlen_freqs[i];
len += litlen_lens[i] * freq;
if (i >= LITLEN_TBL_OFFSET) {
len += litlen_tbl[i - LITLEN_TBL_OFFSET].ebits * freq;
}
}
for (i = 0; i <= DISTSYM_MAX; i++) {
freq = s->dist_freqs[i];
len += dist_lens[i] * freq;
len += dist_tbl[i].ebits * freq;
}
return len;
}
Общая длина статичного блока равна 3 битам заголовка плюс длина тела. Вычисление размера заголовка динамического блока требует гораздо больше работы:
/* Calculate the number of bits for a dynamic Huffman block. */
static size_t dyn_block_len(const deflate_state_t *s, size_t num_codelen_lens,
const uint16_t *codelen_freqs,
const huffman_encoder_t *codelen_enc,
const huffman_encoder_t *litlen_enc,
const huffman_encoder_t *dist_enc)
{
size_t len, i, freq;
/* Block header. */
len = 3;
/* Nbr of litlen, dist, and codelen lengths. */
len += 5 + 5 + 4;
/* Codelen lengths. */
len += 3 * num_codelen_lens;
/* Codelen encoding. */
for (i = 0; i < MAX_CODELEN_LENS; i++) {
freq = codelen_freqs[i];
len += codelen_enc->lengths[i] * freq;
/* Extra bits. */
if (i == CODELEN_COPY) {
len += 2 * freq;
} else if (i == CODELEN_ZEROS) {
len += 3 * freq;
} else if (i == CODELEN_ZEROS2) {
len += 7 * freq;
}
}
return len + huffman_block_body_len(s, litlen_enc->lengths,
dist_enc->lengths);
}
Теперь соберём всё воедино и создадим главную функцию записи блоков:
/* Write the current deflate block, marking it final if that parameter is true,
returning false if there is not enough room in the output stream. */
static bool write_block(deflate_state_t *s, bool final)
{
size_t old_bit_pos, uncomp_len, static_len, dynamic_len;
huffman_encoder_t dyn_litlen_enc, dyn_dist_enc, codelen_enc;
size_t num_encoded_lens, num_litlen_lens, num_dist_lens;
codelen_sym_t encoded_lens[LITLEN_MAX + 1 + DISTSYM_MAX + 1];
uint16_t codelen_freqs[MAX_CODELEN_LENS] = {0};
size_t num_codelen_lens;
size_t i;
old_bit_pos = ostream_bit_pos(&s->os);
/* Add the end-of-block marker in case we write a Huffman block. */
assert(s->block_len < sizeof(s->block) / sizeof(s->block[0]));
assert(s->litlen_freqs[LITLEN_EOB] == 0);
s->block[s->block_len ].distance = 0;
s->block[s->block_len++].u.lit = LITLEN_EOB;
s->litlen_freqs[LITLEN_EOB] = 1;
uncomp_len = uncomp_block_len(s);
static_len = 3 + huffman_block_body_len(s, fixed_litlen_lengths,
fixed_dist_lengths);
/* Compute "dynamic" Huffman codes. */
huffman_encoder_init(&dyn_litlen_enc, s->litlen_freqs,
LITLEN_MAX + 1, 15);
huffman_encoder_init(&dyn_dist_enc, s->dist_freqs, DISTSYM_MAX + 1, 15);
/* Encode the litlen and dist code lengths. */
num_encoded_lens = encode_dist_litlen_lens(dyn_litlen_enc.lengths,
dyn_dist_enc.lengths,
encoded_lens,
&num_litlen_lens,
&num_dist_lens);
/* Compute the codelen code. */
for (i = 0; i < num_encoded_lens; i++) {
codelen_freqs[encoded_lens[i].sym]++;
}
huffman_encoder_init(&codelen_enc, codelen_freqs, MAX_CODELEN_LENS, 7);
num_codelen_lens = count_codelen_lens(codelen_enc.lengths);
dynamic_len = dyn_block_len(s, num_codelen_lens, codelen_freqs,
&codelen_enc, &dyn_litlen_enc,
&dyn_dist_enc);
if (uncomp_len <= dynamic_len && uncomp_len <= static_len) {
if (!write_uncomp_block(s, final)) {
return false;
}
assert(ostream_bit_pos(&s->os) - old_bit_pos == uncomp_len);
} else if (static_len <= dynamic_len) {
if (!write_static_block(s, final)) {
return false;
}
assert(ostream_bit_pos(&s->os) - old_bit_pos == static_len);
} else {
if (!write_dynamic_block(s, final, num_litlen_lens,
num_dist_lens, num_codelen_lens,
&codelen_enc, encoded_lens,
num_encoded_lens, &dyn_litlen_enc,
&dyn_dist_enc)) {
return false;
}
assert(ostream_bit_pos(&s->os) - old_bit_pos == dynamic_len);
}
return true;
}
Наконец, инициатор всего процесса сжатия должен задать начальное состояние, запустить сжатие Lempel-Ziv и записать получившийся блок:
/* Compress (deflate) the data in src into dst. The number of bytes output, at
most dst_cap, is stored in *dst_used. Returns false if there is not enough
room in dst. src and dst must not overlap. */
bool hwdeflate(const uint8_t *src, size_t src_len, uint8_t *dst,
size_t dst_cap, size_t *dst_used)
{
deflate_state_t s;
ostream_init(&s.os, dst, dst_cap);
reset_block(&s);
s.block_src = src;
if (!lz77_compress(src, src_len, &lit_callback,
&backref_callback, &s)) {
return false;
}
if (!write_block(&s, true)) {
return false;
}
/* The end of the final block should match the end of src. */
assert(s.block_src + s.block_len_bytes == src + src_len);
*dst_used = ostream_bytes_written(&s.os);
return true;
}
Формат Zip-файлов
Выше мы рассмотрели, как работает Deflate-сжатие, используемое в Zip-файлах. А что насчёт самого формата файлов? В этой части мы подробно рассмотрим его устройство и реализацию. Код доступен в zip.h и zip.c.
Обзор
Формат файлов описан в PKZip Application Note:
- Каждый файл, или элемента архива, в Zip-файле имеет локальный заголовок файла с метаданными об элементе.
- Центральный каталог служит индексом архива. Он содержит центральный заголовок файла для каждого элемента архива, копию метаданных из локального заголовка файла, а также дополнительную информацию, такую как смещение элемента в Zip-файле.
- В конце файла, сразу после центрального каталога конец записи центрального каталога. Она содержит размер и позицию центрального каталога, а также может содержать комментарии обо всём архиве. Это начальная точка чтения Zip-файла.

Каждый элемент архива сжимается и хранится индивидуально. Это означает, что даже если между файлами в архиве есть совпадения, они не будут учитываться для улучшения сжатия.
Расположение центрального каталога в конце позволяет постепенно достраивать архив. По мере сжатия файлов элементов они дописываются в архив. Индекс записывается после всех сжатых размеров, что позволяет узнать смещения всех файлов. Добавлять файлы в существующий архив довольно легко, он помещается после последнего элемента, а центральный каталог перезаписывается.
Возможность постепенно создавать архивы была особенно важна для распространения информации на многочисленных дискетах или томах. По мере сжатия PKZip предлагал пользователям вставлять новые дискеты, а на последнюю (последние) записывал центральный каталог. Для распаковки многотомного архива PKZip сначала спрашивал последнюю дискету, чтобы записать прочитать центральный каталог, а затем остальные дискеты, необходимые для извлечения запрошенных файлов.
Вас это может удивить, но не существовало правила, запрещающего иметь в архиве несколько файлов с одинаковыми именами. Это могло приводить к большой путанице при распаковке: если есть несколько файлов с одинаковыми именами, то какой из них нужно распаковать? В свою очередь это могло приводить к проблемам в безопасности. Из-за бага «Master Key» в Android (CVE-2013-4787, слайды и видео с доклада на Black Hat) злоумышленник мог при установке программ обходить проверки операционной системой криптоподписей. Android-программы распространяются в APK-файлах, которые представляют собой Zip-файлы. Как выяснилось, если APK содержал несколько файлов с одинаковыми именами, код проверки подписи выбирал последний файл с таким именем, а инсталлятор выбирал первый файл, то есть проверка не выполнялась. Иными словами, это небольшое различие между двумя Zip-библиотеками позволяло обойти всю модель безопасности операционной системы.
В отличие от большинства форматов, Zip-файлы не должны начинаться с сигнатуры или магического числа. Вообще не указано, что Zip-файл должен начинаться каким-то конкретным образом, что легко позволяет создавать файлы, одновременно валидные и как Zip, и как другой формат — файлы-полиглоты. Например, самораспаковывающиеся Zip-архивы (например, pkz204g.exe) обычно одновременно и исполняемые, и Zip-файлы: первая часть является исполняемой, а за ней идёт Zip-файл (который распаковывается исполняемой частью). ОС может выполнять его как исполняемый, но Zip-программа откроет его как Zip-файл. Такая особенность могла стать причиной не требовать сигнатуру в начале файла.
Хотя такие файлы-полиглоты и умны, но они могут приводить к проблемам в безопасности, поскольку способны обмануть программы, старающиеся определить содержимое файла, а также позволяют доставлять зловредный код в месте с файлами разных типов. Например, в эксплойтах использовались GIFAR-файлы, которые одновременно являются корректными GIF-изображениями и Java-архивами (JAR, разновидность Zip-файлов). Подробнее об этой проблеме рассказывается в статье Abusing file formats (начиная со страницы 18).
Как мы увидим ниже, Zip-файлы используют для смещений и размеров 32-битные поля, чтобы ограничивать размер архива и его элементов четырьмя гигабайтами. В Application Note 4.5 PKWare добавила расширения формата, позволяющие использовать 64-битные смещения и размеры. Файлы, использующие эти расширения, относят к формату Zip64, но мы не будем их рассматривать.
Структуры данных
Конец записи центрального каталога
Конец записи центрального каталога (EOCDR) обычно используется в качестве начальной точки для чтения Zip-файла. В ней содержится расположение и размер центрального каталога, а также опциональные комментарии обо всём архиве.
В Zip-файлах, которые занимали несколько дискет — или томов, — EOCDR также содержала информацию о том, какой диск мы сейчас используем, на каком диске начинается центральный каталог и т.д. Сегодня эта функциональность используется редко, и код из этой статьи такие файлы не обрабатывает.
EOCDR определяется по сигнатуре 'P' 'K', за которой идут байты 5 и 6. За ней следует нижеприведённая структура, числа хранятся по принципу little-endian:
/* End of Central Directory Record. */
struct eocdr {
uint16_t disk_nbr; /* Number of this disk. */
uint16_t cd_start_disk; /* Nbr. of disk with start of the CD. */
uint16_t disk_cd_entries; /* Nbr. of CD entries on this disk. */
uint16_t cd_entries; /* Nbr. of Central Directory entries. */
uint32_t cd_size; /* Central Directory size in bytes. */
uint32_t cd_offset; /* Central Directory file offset. */
uint16_t comment_len; /* Archive comment length. */
const uint8_t *comment; /* Archive comment. */
};
EOCDR должна располагаться в конце файла. Но поскольку в её хвосте может быть комментарий произвольной 16-битной длины, может потребоваться находиться конкретную позицию:
/* Read 16/32 bits little-endian and bump p forward afterwards. */
#define READ16(p) ((p) += 2, read16le((p) - 2))
#define READ32(p) ((p) += 4, read32le((p) - 4))
/* Size of the End of Central Directory Record, not including comment. */
#define EOCDR_BASE_SZ 22
#define EOCDR_SIGNATURE 0x06054b50 /* "PK\5\6" little-endian. */
static bool find_eocdr(struct eocdr *r, const uint8_t *src, size_t src_len)
{
size_t comment_len;
const uint8_t *p;
uint32_t signature;
for (comment_len = 0; comment_len <= UINT16_MAX; comment_len++) {
if (src_len < EOCDR_BASE_SZ + comment_len) {
break;
}
p = &src[src_len - EOCDR_BASE_SZ - comment_len];
signature = READ32(p);
if (signature == EOCDR_SIGNATURE) {
r->disk_nbr = READ16(p);
r->cd_start_disk = READ16(p);
r->disk_cd_entries = READ16(p);
r->cd_entries = READ16(p);
r->cd_size = READ32(p);
r->cd_offset = READ32(p);
r->comment_len = READ16(p);
r->comment = p;
assert(p == &src[src_len - comment_len] &&
"All fields read.");
if (r->comment_len == comment_len) {
return true;
}
}
}
return false;
}
Записывать EOCDR несложно. Эта функция записывает и возвращает количество записанных байтов:
/* Write 16/32 bits little-endian and bump p forward afterwards. */
#define WRITE16(p, x) (write16le((p), (x)), (p) += 2)
#define WRITE32(p, x) (write32le((p), (x)), (p) += 4)
static size_t write_eocdr(uint8_t *dst, const struct eocdr *r)
{
uint8_t *p = dst;
WRITE32(p, EOCDR_SIGNATURE);
WRITE16(p, r->disk_nbr);
WRITE16(p, r->cd_start_disk);
WRITE16(p, r->disk_cd_entries);
WRITE16(p, r->cd_entries);
WRITE32(p, r->cd_size);
WRITE32(p, r->cd_offset);
WRITE16(p, r->comment_len);
assert(p - dst == EOCDR_BASE_SZ);
if (r->comment_len != 0) {
memcpy(p, r->comment, r->comment_len);
p += r->comment_len;
}
return (size_t)(p - dst);
}
Центральный заголовок файла
Центральный каталог состоит из центральных заголовков файлов, записанных друг за другом, по одному для каждого элемента архива. Каждый заголовок начинается с сигнатуры 'P', 'K', 1, 2, а потом идёт такая структура:
#define EXT_ATTR_DIR (1U << 4)
#define EXT_ATTR_ARC (1U << 5)
/* Central File Header (Central Directory Entry) */
struct cfh {
uint16_t made_by_ver; /* Version made by. */
uint16_t extract_ver; /* Version needed to extract. */
uint16_t gp_flag; /* General purpose bit flag. */
uint16_t method; /* Compression method. */
uint16_t mod_time; /* Modification time. */
uint16_t mod_date; /* Modification date. */
uint32_t crc32; /* CRC-32 checksum. */
uint32_t comp_size; /* Compressed size. */
uint32_t uncomp_size; /* Uncompressed size. */
uint16_t name_len; /* Filename length. */
uint16_t extra_len; /* Extra data length. */
uint16_t comment_len; /* Comment length. */
uint16_t disk_nbr_start; /* Disk nbr. where file begins. */
uint16_t int_attrs; /* Internal file attributes. */
uint32_t ext_attrs; /* External file attributes. */
uint32_t lfh_offset; /* Local File Header offset. */
const uint8_t *name; /* Filename. */
const uint8_t *extra; /* Extra data. */
const uint8_t *comment; /* File comment. */
};
made_by_ver и extract_ver кодируют информацию об ОС и версии программы, использованной для добавления этого элемента, а также о том, какая версия нужна для его извлечения. Самые важные восемь битов кодируют операционную систему (например, 0 означает DOS, 3 — Unix, 10 — Windows NTFS), а младшие восемь битов кодируют версию ПО. Зададим десятичное значение 20, что означает совместимость с PKZip 2.0.gp_flag содержит разные флаги. Нас интересуют:- Бит 0, обозначающий факт зашифровки элемента (мы это не будем рассматривать);
- И биты 1 и 2, кодирующие уровень Deflate-сжатия (0 — нормальное, 1 — максимальное, 2 — быстрое, 3 — очень быстрое).
method кодирует метод сжатия. 0 — данные не сжаты, 8 — применён Delate. Другие значения относятся к старым или новым алгоритмам, но почти все Zip-используют эти два значения.mod_time и mod_date содержат дату и время изменения файла, закодированные в MS-DOS-формате. С помощью этого кода мы преобразуем обычные временные метки С time_t в MS-DOS-формат и из него:/* Convert DOS date and time to time_t. */
static time_t dos2ctime(uint16_t dos_date, uint16_t dos_time)
{
struct tm tm = {0};
tm.tm_sec = (dos_time & 0x1f) * 2; /* Bits 0--4: Secs divided by 2. */
tm.tm_min = (dos_time >> 5) & 0x3f; /* Bits 5--10: Minute. */
tm.tm_hour = (dos_time >> 11); /* Bits 11-15: Hour (0--23). */
tm.tm_mday = (dos_date & 0x1f); /* Bits 0--4: Day (1--31). */
tm.tm_mon = ((dos_date >> 5) & 0xf) - 1; /* Bits 5--8: Month (1--12). */
tm.tm_year = (dos_date >> 9) + 80; /* Bits 9--15: Year-1980. */
tm.tm_isdst = -1;
return mktime(&tm);
}
/* Convert time_t to DOS date and time. */
static void ctime2dos(time_t t, uint16_t *dos_date, uint16_t *dos_time)
{
struct tm *tm = localtime(&t);
*dos_time = 0;
*dos_time |= tm->tm_sec / 2; /* Bits 0--4: Second divided by two. */
*dos_time |= tm->tm_min << 5; /* Bits 5--10: Minute. */
*dos_time |= tm->tm_hour << 11; /* Bits 11-15: Hour. */
*dos_date = 0;
*dos_date |= tm->tm_mday; /* Bits 0--4: Day (1--31). */
*dos_date |= (tm->tm_mon + 1) << 5; /* Bits 5--8: Month (1--12). */
*dos_date |= (tm->tm_year - 80) << 9; /* Bits 9--15: Year from 1980. */
}
Поле
crc32 содержит значение циклического избыточного кода несжатых данных. Он используется для проверки целостности данных после извлечения. Реализация здесь: crc32.c.comp_size и uncomp_size содержат сжатый и несжатый размер данных файла элемента. Следующие три поля содержат длины имени, комментарий и дополнительные данные, которые идут сразу после заголовка. disk_nbr_start предназначено для архивов, использующих несколько дискет.int_attrs и ext_attrs описывают внутренние и внешние атрибуты файла. Внутренние относятся к содержимому файла, например, младший бит обозначает, содержит ли файл только текст. Внешние атрибуты показывают, является ли файл скрытым, только для чтения и т.д. Содержимое этих полей зависит от ОС, в частности, от made_by_ver. В DOS младшие 8 битов содержат байт атрибутов файла, который можно получить из системного вызова Int 21/AX=4300h. К примеру, бит 4 означает, что это директория, а бит 5 — что установлен атрибут «архив» (верно для большинства файлов в DOS). Насколько я понял, ради совместимости эти биты аналогично задаются и в других ОС. В Unix старшие 16 битов этого поля содержат биты режима файла, которые возвращаются stat(2) в st_mode.lfh_offset говорит нам, где искать локальный заголовок файла. name — имя файла (C-строка), а comment — опциональный комментарий для этого элемента архива (С-строка). extra может содержать опциональные дополнительные данные вроде информации о владельце Unix-файла, более точные дату и время изменения или Zip64-поля.Эта функция используется для чтения центральных заголовков файлов:
/* Size of a Central File Header, not including name, extra, and comment. */
#define CFH_BASE_SZ 46
#define CFH_SIGNATURE 0x02014b50 /* "PK\1\2" little-endian. */
static bool read_cfh(struct cfh *cfh, const uint8_t *src, size_t src_len,
size_t offset)
{
const uint8_t *p;
uint32_t signature;
if (offset > src_len || src_len - offset < CFH_BASE_SZ) {
return false;
}
p = &src[offset];
signature = READ32(p);
if (signature != CFH_SIGNATURE) {
return false;
}
cfh->made_by_ver = READ16(p);
cfh->extract_ver = READ16(p);
cfh->gp_flag = READ16(p);
cfh->method = READ16(p);
cfh->mod_time = READ16(p);
cfh->mod_date = READ16(p);
cfh->crc32 = READ32(p);
cfh->comp_size = READ32(p);
cfh->uncomp_size = READ32(p);
cfh->name_len = READ16(p);
cfh->extra_len = READ16(p);
cfh->comment_len = READ16(p);
cfh->disk_nbr_start = READ16(p);
cfh->int_attrs = READ16(p);
cfh->ext_attrs = READ32(p);
cfh->lfh_offset = READ32(p);
cfh->name = p;
cfh->extra = cfh->name + cfh->name_len;
cfh->comment = cfh->extra + cfh->extra_len;
assert(p == &src[offset + CFH_BASE_SZ] && "All fields read.");
if (src_len - offset - CFH_BASE_SZ <
cfh->name_len + cfh->extra_len + cfh->comment_len) {
return false;
}
return true;
}
static size_t write_cfh(uint8_t *dst, const struct cfh *cfh)
{
uint8_t *p = dst;
WRITE32(p, CFH_SIGNATURE);
WRITE16(p, cfh->made_by_ver);
WRITE16(p, cfh->extract_ver);
WRITE16(p, cfh->gp_flag);
WRITE16(p, cfh->method);
WRITE16(p, cfh->mod_time);
WRITE16(p, cfh->mod_date);
WRITE32(p, cfh->crc32);
WRITE32(p, cfh->comp_size);
WRITE32(p, cfh->uncomp_size);
WRITE16(p, cfh->name_len);
WRITE16(p, cfh->extra_len);
WRITE16(p, cfh->comment_len);
WRITE16(p, cfh->disk_nbr_start);
WRITE16(p, cfh->int_attrs);
WRITE32(p, cfh->ext_attrs);
WRITE32(p, cfh->lfh_offset);
assert(p - dst == CFH_BASE_SZ);
if (cfh->name_len != 0) {
memcpy(p, cfh->name, cfh->name_len);
p += cfh->name_len;
}
if (cfh->extra_len != 0) {
memcpy(p, cfh->extra, cfh->extra_len);
p += cfh->extra_len;
}
if (cfh->comment_len != 0) {
memcpy(p, cfh->comment, cfh->comment_len);
p += cfh->comment_len;
}
return (size_t)(p - dst);
}
Локальный заголовок файла
Данные каждого элемента архива предваряются локальным заголовком файла, который повторяет большую часть информации из центрального заголовка.
Вероятно, дублирование данных в центральном и локальном заголовках было введено для того, чтобы PKZip при распаковке не держал в памяти весь центральный каталог. Вместо этого по мере извлечения каждого файла его имя и прочая информация может быть считана из локального заголовка. Кроме того, локальные заголовки полезны для восстановления файлов из Zip-архивов, в которых центральный каталог отсутствует или повреждён.
Однако эта избыточность является и главным источником неопределённости. Например, что будет, если имена файлов в центральном и локальном заголовках не совпадают? Это часто приводит к багам и проблемам в безопасности.
Дублируется не вся информация из центрального заголовка. Например, поля с атрибутами файлов. Кроме того, если задан третий младший значимый бит
gp_flags (CRC-32), то поля сжатого и несжатого размера будут обнулены, а эту информацию можно будет найти в блоке Data Descriptor после данных самого файла (рассматривать не будем). Это позволяет записывать локальный заголовок до того, как станет известен размер файла элемента или до какого размера он будет сжат.Локальный заголовок начинается с сигнатуры 'P', 'K', 3, 4, а потом идёт такая структура:
/* Local File Header. */
struct lfh {
uint16_t extract_ver;
uint16_t gp_flag;
uint16_t method;
uint16_t mod_time;
uint16_t mod_date;
uint32_t crc32;
uint32_t comp_size;
uint32_t uncomp_size;
uint16_t name_len;
uint16_t extra_len;
const uint8_t *name;
const uint8_t *extra;
};
Эти функции считывают и записывают локальные заголовки, как и другие структуры данных:
/* Size of a Local File Header, not including name and extra. */
#define LFH_BASE_SZ 30
#define LFH_SIGNATURE 0x04034b50 /* "PK\3\4" little-endian. */
static bool read_lfh(struct lfh *lfh, const uint8_t *src, size_t src_len,
size_t offset)
{
const uint8_t *p;
uint32_t signature;
if (offset > src_len || src_len - offset < LFH_BASE_SZ) {
return false;
}
p = &src[offset];
signature = READ32(p);
if (signature != LFH_SIGNATURE) {
return false;
}
lfh->extract_ver = READ16(p);
lfh->gp_flag = READ16(p);
lfh->method = READ16(p);
lfh->mod_time = READ16(p);
lfh->mod_date = READ16(p);
lfh->crc32 = READ32(p);
lfh->comp_size = READ32(p);
lfh->uncomp_size = READ32(p);
lfh->name_len = READ16(p);
lfh->extra_len = READ16(p);
lfh->name = p;
lfh->extra = lfh->name + lfh->name_len;
assert(p == &src[offset + LFH_BASE_SZ] && "All fields read.");
if (src_len - offset - LFH_BASE_SZ < lfh->name_len + lfh->extra_len) {
return false;
}
return true;
}
static size_t write_lfh(uint8_t *dst, const struct lfh *lfh)
{
uint8_t *p = dst;
WRITE32(p, LFH_SIGNATURE);
WRITE16(p, lfh->extract_ver);
WRITE16(p, lfh->gp_flag);
WRITE16(p, lfh->method);
WRITE16(p, lfh->mod_time);
WRITE16(p, lfh->mod_date);
WRITE32(p, lfh->crc32);
WRITE32(p, lfh->comp_size);
WRITE32(p, lfh->uncomp_size);
WRITE16(p, lfh->name_len);
WRITE16(p, lfh->extra_len);
assert(p - dst == LFH_BASE_SZ);
if (lfh->name_len != 0) {
memcpy(p, lfh->name, lfh->name_len);
p += lfh->name_len;
}
if (lfh->extra_len != 0) {
memcpy(p, lfh->extra, lfh->extra_len);
p += lfh->extra_len;
}
return (size_t)(p - dst);
}
Реализация Zip-считывания
С помощью вышеописанных функций мы реализуем чтение Zip-файла в память и получаем итератор для доступа к элементам архива:
typedef size_t zipiter_t; /* Zip archive member iterator. */
typedef struct zip_t zip_t;
struct zip_t {
uint16_t num_members; /* Number of members. */
const uint8_t *comment; /* Zip file comment (not terminated). */
uint16_t comment_len; /* Zip file comment length. */
zipiter_t members_begin; /* Iterator to the first member. */
zipiter_t members_end; /* Iterator to the end of members. */
const uint8_t *src;
size_t src_len;
};
/* Initialize zip based on the source data. Returns true on success, or false
if the data could not be parsed as a valid Zip file. */
bool zip_read(zip_t *zip, const uint8_t *src, size_t src_len)
{
struct eocdr eocdr;
struct cfh cfh;
struct lfh lfh;
size_t i, offset;
const uint8_t *comp_data;
zip->src = src;
zip->src_len = src_len;
if (!find_eocdr(&eocdr, src, src_len)) {
return false;
}
if (eocdr.disk_nbr != 0 || eocdr.cd_start_disk != 0 ||
eocdr.disk_cd_entries != eocdr.cd_entries) {
return false; /* Cannot handle multi-volume archives. */
}
zip->num_members = eocdr.cd_entries;
zip->comment = eocdr.comment;
zip->comment_len = eocdr.comment_len;
offset = eocdr.cd_offset;
zip->members_begin = offset;
/* Read the member info and do a few checks. */
for (i = 0; i < eocdr.cd_entries; i++) {
if (!read_cfh(&cfh, src, src_len, offset)) {
return false;
}
if (cfh.gp_flag & 1) {
return false; /* The member is encrypted. */
}
if (cfh.method != ZIP_STORED && cfh.method != ZIP_DEFLATED) {
return false; /* Unsupported compression method. */
}
if (cfh.method == ZIP_STORED &&
cfh.uncomp_size != cfh.comp_size) {
return false;
}
if (cfh.disk_nbr_start != 0) {
return false; /* Cannot handle multi-volume archives. */
}
if (memchr(cfh.name, '\0', cfh.name_len) != NULL) {
return false; /* Bad filename. */
}
if (!read_lfh(&lfh, src, src_len, cfh.lfh_offset)) {
return false;
}
comp_data = lfh.extra + lfh.extra_len;
if (cfh.comp_size > src_len - (size_t)(comp_data - src)) {
return false; /* Member data does not fit in src. */
}
offset += CFH_BASE_SZ + cfh.name_len + cfh.extra_len +
cfh.comment_len;
}
zip->members_end = offset;
return true;
}
Как я упоминал выше, итераторы элементов — это просто смещения центрального заголовка файла, через которые можно обращаться к данным элементов:
typedef enum { ZIP_STORED = 0, ZIP_DEFLATED = 8 } method_t;
typedef struct zipmemb_t zipmemb_t;
struct zipmemb_t {
const uint8_t *name; /* Member name (not null terminated). */
uint16_t name_len; /* Member name length. */
time_t mtime; /* Modification time. */
uint32_t comp_size; /* Compressed size. */
const uint8_t *comp_data; /* Compressed data. */
method_t method; /* Compression method. */
uint32_t uncomp_size; /* Uncompressed size. */
uint32_t crc32; /* CRC-32 checksum. */
const uint8_t *comment; /* Comment (not null terminated). */
uint16_t comment_len; /* Comment length. */
bool is_dir; /* Whether this is a directory. */
zipiter_t next; /* Iterator to the next member. */
};
/* Get the Zip archive member through iterator it. */
zipmemb_t zip_member(const zip_t *zip, zipiter_t it)
{
struct cfh cfh;
struct lfh lfh;
bool ok;
zipmemb_t m;
assert(it >= zip->members_begin && it < zip->members_end);
ok = read_cfh(&cfh, zip->src, zip->src_len, it);
assert(ok);
ok = read_lfh(&lfh, zip->src, zip->src_len, cfh.lfh_offset);
assert(ok);
m.name = cfh.name;
m.name_len = cfh.name_len;
m.mtime = dos2ctime(cfh.mod_date, cfh.mod_time);
m.comp_size = cfh.comp_size;
m.comp_data = lfh.extra + lfh.extra_len;
m.method = cfh.method;
m.uncomp_size = cfh.uncomp_size;
m.crc32 = cfh.crc32;
m.comment = cfh.comment;
m.comment_len = cfh.comment_len;
m.is_dir = (cfh.ext_attrs & EXT_ATTR_DIR) != 0;
m.next = it + CFH_BASE_SZ +
cfh.name_len + cfh.extra_len + cfh.comment_len;
assert(m.next <= zip->members_end);
return m;
}
Реализация Zip-записи
Чтобы записать Zip-файл в буфер памяти, сначала нужно узнать, сколько памяти под него выделить. А раз мы не знаем, сколько данных сожмём, прежде чем попытаемся записать, то вычислим верхнюю границу на основе размеров несжатых элементов:
/* Compute an upper bound on the dst size required by zip_write() for an
* archive with num_memb members with certain filenames, sizes, and archive
* comment. Returns zero on error, e.g. if a filename is longer than 2^16-1, or
* if the total file size is larger than 2^32-1. */
uint32_t zip_max_size(uint16_t num_memb, const char *const *filenames,
const uint32_t *file_sizes, const char *comment)
{
size_t comment_len, name_len;
uint64_t total;
uint16_t i;
comment_len = (comment == NULL ? 0 : strlen(comment));
if (comment_len > UINT16_MAX) {
return 0;
}
total = EOCDR_BASE_SZ + comment_len; /* EOCDR */
for (i = 0; i < num_memb; i++) {
assert(filenames[i] != NULL);
name_len = strlen(filenames[i]);
if (name_len > UINT16_MAX) {
return 0;
}
total += CFH_BASE_SZ + name_len; /* Central File Header */
total += LFH_BASE_SZ + name_len; /* Local File Header */
total += file_sizes[i]; /* Uncompressed data size. */
}
if (total > UINT32_MAX) {
return 0;
}
return (uint32_t)total;
}
Этот код записывает Zip-файл с помощью Deflate-сжатия каждого элемента, уменьшая их размер:
/* Write a Zip file containing num_memb members into dst, which must be large
enough to hold the resulting data. Returns the number of bytes written, which
is guaranteed to be less than or equal to the result of zip_max_size() when
called with the corresponding arguments. comment shall be a null-terminated
string or null. callback shall be null or point to a function which will
get called after the compression of each member. */
uint32_t zip_write(uint8_t *dst, uint16_t num_memb,
const char *const *filenames,
const uint8_t *const *file_data,
const uint32_t *file_sizes,
const time_t *mtimes,
const char *comment,
void (*callback)(const char *filename, uint32_t size,
uint32_t comp_size))
{
uint16_t i;
uint8_t *p;
struct eocdr eocdr;
struct cfh cfh;
struct lfh lfh;
bool ok;
uint16_t name_len;
uint8_t *data_dst;
size_t comp_sz;
uint32_t lfh_offset, cd_offset, eocdr_offset;
p = dst;
/* Write Local File Headers and deflated or stored data. */
for (i = 0; i < num_memb; i++) {
assert(filenames[i] != NULL);
assert(strlen(filenames[i]) <= UINT16_MAX);
name_len = (uint16_t)strlen(filenames[i]);
data_dst = p + LFH_BASE_SZ + name_len;
if (hwdeflate(file_data[i], file_sizes[i], data_dst,
file_sizes[i], &comp_sz) &&
comp_sz < file_sizes[i]) {
lfh.method = ZIP_DEFLATED;
assert(comp_sz <= UINT32_MAX);
lfh.comp_size = (uint32_t)comp_sz;
} else {
memcpy(data_dst, file_data[i], file_sizes[i]);
lfh.method = ZIP_STORED;
lfh.comp_size = file_sizes[i];
}
if (callback != NULL) {
callback(filenames[i], file_sizes[i], lfh.comp_size);
}
lfh.extract_ver = (0 << 8) | 20; /* DOS | PKZIP 2.0 */
lfh.gp_flag = (lfh.method == ZIP_DEFLATED ? (0x1 << 1) : 0x0);
ctime2dos(mtimes[i], &lfh.mod_date, &lfh.mod_time);
lfh.crc32 = crc32(file_data[i], file_sizes[i]);
lfh.uncomp_size = file_sizes[i];
lfh.name_len = name_len;
lfh.extra_len = 0;
lfh.name = (const uint8_t*)filenames[i];
p += write_lfh(p, &lfh);
p += lfh.comp_size;
}
assert(p - dst <= UINT32_MAX);
cd_offset = (uint32_t)(p - dst);
/* Write the Central Directory based on the Local File Headers. */
lfh_offset = 0;
for (i = 0; i < num_memb; i++) {
ok = read_lfh(&lfh, dst, SIZE_MAX, lfh_offset);
assert(ok);
cfh.made_by_ver = lfh.extract_ver;
cfh.extract_ver = lfh.extract_ver;
cfh.gp_flag = lfh.gp_flag;
cfh.method = lfh.method;
cfh.mod_time = lfh.mod_time;
cfh.mod_date = lfh.mod_date;
cfh.crc32 = lfh.crc32;
cfh.comp_size = lfh.comp_size;
cfh.uncomp_size = lfh.uncomp_size;
cfh.name_len = lfh.name_len;
cfh.extra_len = 0;
cfh.comment_len = 0;
cfh.disk_nbr_start = 0;
cfh.int_attrs = 0;
cfh.ext_attrs = EXT_ATTR_ARC;
cfh.lfh_offset = lfh_offset;
cfh.name = lfh.name;
p += write_cfh(p, &cfh);
lfh_offset += LFH_BASE_SZ + lfh.name_len + lfh.comp_size;
}
assert(p - dst <= UINT32_MAX);
eocdr_offset = (uint32_t)(p - dst);
/* Write the End of Central Directory Record. */
eocdr.disk_nbr = 0;
eocdr.cd_start_disk = 0;
eocdr.disk_cd_entries = num_memb;
eocdr.cd_entries = num_memb;
eocdr.cd_size = eocdr_offset - cd_offset;
eocdr.cd_offset = cd_offset;
eocdr.comment_len = (uint16_t)(comment == NULL ? 0 : strlen(comment));
eocdr.comment = (const uint8_t*)comment;
p += write_eocdr(p, &eocdr);
assert(p - dst <= zip_max_size(num_memb, filenames, file_sizes,
comment));
return (uint32_t)(p - dst);
}
HWZip
Теперь мы знаем, как читать и записывать Zip-файлы, как сжимать и распаковывать хранящиеся в них данные. Теперь напишем простую Zip-программу, содержащую все эти инструменты. Код доступен в hwzip.c.
Воспользуемся макросом для простой обработки ошибок и несколькими вспомогательными функциями для проверенного выделения памяти:
#define PERROR_IF(cond, msg) if (cond) { perror(msg); exit(1); }
static void *xmalloc(size_t size)
{
void *ptr = malloc(size);
PERROR_IF(ptr == NULL, "malloc");
return ptr;
}
static void *xrealloc(void *ptr, size_t size)
{
ptr = realloc(ptr, size);
PERROR_IF(ptr == NULL, "realloc");
return ptr;
}
Другие две функции используются для чтения и записи файлов:
static uint8_t *read_file(const char *filename, size_t *file_sz)
{
FILE *f;
uint8_t *buf;
size_t buf_cap;
f = fopen(filename, "rb");
PERROR_IF(f == NULL, "fopen");
buf_cap = 4096;
buf = xmalloc(buf_cap);
*file_sz = 0;
while (feof(f) == 0) {
if (buf_cap - *file_sz == 0) {
buf_cap *= 2;
buf = xrealloc(buf, buf_cap);
}
*file_sz += fread(&buf[*file_sz], 1, buf_cap - *file_sz, f);
PERROR_IF(ferror(f), "fread");
}
PERROR_IF(fclose(f) != 0, "fclose");
return buf;
}
static void write_file(const char *filename, const uint8_t *data, size_t n)
{
FILE *f;
f = fopen(filename, "wb");
PERROR_IF(f == NULL, "fopen");
PERROR_IF(fwrite(data, 1, n, f) != n, "fwrite");
PERROR_IF(fclose(f) != 0, "fclose");
}
Наша Zip-программ может выполнять три функции: составлять список содержимого Zip-файлов и извлекать его, а также создавать Zip-файлы. Составление списка проще некуда:
static void list_zip(const char *filename)
{
uint8_t *zip_data;
size_t zip_sz;
zip_t z;
zipiter_t it;
zipmemb_t m;
printf("Listing ZIP archive: %s\n\n", filename);
zip_data = read_file(filename, &zip_sz);
if (!zip_read(&z, zip_data, zip_sz)) {
printf("Failed to parse ZIP file!\n");
exit(1);
}
if (z.comment_len != 0) {
printf("%.*s\n\n", (int)z.comment_len, z.comment);
}
for (it = z.members_begin; it != z.members_end; it = m.next) {
m = zip_member(&z, it);
printf("%.*s\n", (int)m.name_len, m.name);
}
printf("\n");
free(zip_data);
}
Извлечение чуть сложнее. Мы будем использовать вспомогательные функции для нуль-терминирования имени файла (чтобы передавать его в
fopen) и распаковки:static char *terminate_str(const char *str, size_t n)
{
char *p = xmalloc(n + 1);
memcpy(p, str, n);
p[n] = '\0';
return p;
}
static uint8_t *inflate_member(const zipmemb_t *m)
{
uint8_t *p;
size_t src_used, dst_used;
assert(m->method == ZIP_DEFLATED);
p = xmalloc(m->uncomp_size);
if (hwinflate(m->comp_data, m->comp_size, &src_used, p, m->uncomp_size,
&dst_used) != HWINF_OK) {
free(p);
return NULL;
}
if (src_used != m->comp_size || dst_used != m->uncomp_size) {
free(p);
return NULL;
}
return p;
}
Наша программа будет пропускать любые элементы архива, которые есть директории. Это делается для того, чтобы избежать так называемых path traversal-атак: зловредный архив используется для записи файла извне директории, указанной пользователем. Подробности читайте в Info-ZIP FAQ.
static void extract_zip(const char *filename)
{
uint8_t *zip_data;
size_t zip_sz;
zip_t z;
zipiter_t it;
zipmemb_t m;
char *tname;
uint8_t *inflated;
const uint8_t *uncomp_data;
printf("Extracting ZIP archive: %s\n\n", filename);
zip_data = read_file(filename, &zip_sz);
if (!zip_read(&z, zip_data, zip_sz)) {
printf("Failed to read ZIP file!\n");
exit(1);
}
if (z.comment_len != 0) {
printf("%.*s\n\n", (int)z.comment_len, z.comment);
}
for (it = z.members_begin; it != z.members_end; it = m.next) {
m = zip_member(&z, it);
if (m.is_dir) {
printf(" (Skipping dir: %.*s)\n",
(int)m.name_len, m.name);
continue;
}
if (memchr(m.name, '/', m.name_len) != NULL ||
memchr(m.name, '\\', m.name_len) != NULL) {
printf(" (Skipping file in dir: %.*s)\n",
(int)m.name_len, m.name);
continue;
}
assert(m.method == ZIP_STORED || m.method == ZIP_DEFLATED);
printf(" %s: %.*s",
m.method == ZIP_STORED ? "Extracting" : " Inflating",
(int)m.name_len, m.name);
fflush(stdout);
if (m.method == ZIP_STORED) {
assert(m.uncomp_size == m.comp_size);
inflated = NULL;
uncomp_data = m.comp_data;
} else {
inflated = inflate_member(&m);
if (inflated == NULL) {
printf("Error: inflation failed!\n");
exit(1);
}
uncomp_data = inflated;
}
if (crc32(uncomp_data, m.uncomp_size) != m.crc32) {
printf("Error: CRC-32 mismatch!\n");
exit(1);
}
tname = terminate_str((const char*)m.name, m.name_len);
write_file(tname, uncomp_data, m.uncomp_size);
printf("\n");
free(inflated);
free(tname);
}
printf("\n");
free(zip_data);
}
Чтобы создать Zip-архив, мы прочитаем входные файлы и скормим их
zip_write. Поскольку стандартная библиотека C не позволяет получить время изменения файла, мы воспользуемся текущим временем (исправление этой особенности оставляю вам в качестве домашнего задания).void zip_callback(const char *filename, uint32_t size, uint32_t comp_size)
{
bool deflated = comp_size < size;
printf(" %s: %s", deflated ? "Deflated" : " Stored", filename);
if (deflated) {
printf(" (%u%%)", 100 - 100 * comp_size / size);
}
printf("\n");
}
static void create_zip(const char *zip_filename, const char *comment,
uint16_t n, const char *const *filenames)
{
time_t mtime;
time_t *mtimes;
uint8_t **file_data;
uint32_t *file_sizes;
size_t file_size, zip_size;
uint8_t *zip_data;
uint16_t i;
printf("Creating ZIP archive: %s\n\n", zip_filename);
if (comment != NULL) {
printf("%s\n\n", comment);
}
mtime = time(NULL);
file_data = xmalloc(sizeof(*file_data) * n);
file_sizes = xmalloc(sizeof(*file_sizes) * n);
mtimes = xmalloc(sizeof(*mtimes) * n);
for (i = 0; i < n; i++) {
file_data[i] = read_file(filenames[i], &file_size);
if (file_size >= UINT32_MAX) {
printf("%s is too large!\n", filenames[i]);
exit(1);
}
file_sizes[i] = (uint32_t)file_size;
mtimes[i] = mtime;
}
zip_size = zip_max_size(n, filenames, file_sizes, comment);
if (zip_size == 0) {
printf("zip writing not possible");
exit(1);
}
zip_data = xmalloc(zip_size);
zip_size = zip_write(zip_data, n, filenames,
(const uint8_t *const *)file_data,
file_sizes, mtimes, comment, zip_callback);
write_file(zip_filename, zip_data, zip_size);
printf("\n");
free(zip_data);
for (i = 0; i < n; i++) {
free(file_data[i]);
}
free(mtimes);
free(file_sizes);
free(file_data);
}
Наконец,
main проверяет аргументы командной строки и решает, что делать:static void print_usage(const char *argv0)
{
printf("Usage:\n\n");
printf(" %s list <zipfile>\n", argv0);
printf(" %s extract <zipfile>\n", argv0);
printf(" %s create <zipfile> [-c <comment>] <files...>\n", argv0);
printf("\n");
}
int main(int argc, char **argv) {
printf("\n");
printf("HWZIP " VERSION " -- A very simple ZIP program ");
printf("from https://www.hanshq.net/zip.html\n");
printf("\n");
if (argc == 3 && strcmp(argv[1], "list") == 0) {
list_zip(argv[2]);
} else if (argc == 3 && strcmp(argv[1], "extract") == 0) {
extract_zip(argv[2]);
} else if (argc >= 3 && strcmp(argv[1], "create") == 0) {
if (argc >= 5 && strcmp(argv[3], "-c") == 0) {
create_zip(argv[2], argv[4], (uint16_t)(argc - 5),
(const char *const *)&argv[5]);
} else {
create_zip(argv[2], NULL, (uint16_t)(argc - 3),
(const char *const *)&argv[3]);
}
} else {
print_usage(argv[0]);
return 1;
}
return 0;
}
Инструкции по сборке
Полный набор исходных файлов доступен в hwzip-1.0.zip. Как скомпилировать HWZip под Linux или Mac:
$ clang generate_tables.c && ./a.out > tables.c
$ clang -O3 -DNDEBUG -march=native -o hwzip crc32.c deflate.c huffman.c \
hwzip.c lz77.c tables.c zip.c
Под Windows, в командной строке разработчика в Visual Studio (если у вас нет Visual Studio, скачайте инструменты для сборки):
cl /TC generate_tables.c && generate_tables > tables.c
cl /O2 /DNDEBUG /MT /Fehwzip.exe /TC crc32.c deflate.c huffman.c hwzip.c
lz77.c tables.c zip.c /link setargv.obj
Setargv.obj для расширяющих wildcard-аргументов командной строки.)
Заключение
Удивительно, как одновременно быстро и медленно развивается технология. Формат Zip был создан 30 лет назад на основе технологий пятидесятых и семидесятых годов. И хотя с тех пор многое изменилось, Zip-файлы, по сути, остались теми же и сегодня более распространены, чем когда-либо. Думаю, будет полезно хорошо разбираться в том, как они работают.
Упражнения
- Сделайте так, чтобы HWZip записывал время изменения каждого файла, а не текущее время создания архива. Используйте stat(2) на Linux или Mac и GetFileTime на Windows. Или добавьте флаг командной строки, который позволяет пользователю задавать определённое время изменения файлов.
- С помощью кода сжатия и распаковки из этой статьи напишите программу создания и распаковки gzip-файлов. Этот формат — простая обёртка вокруг данных, сжатых с помощью Deflate (обычно всего один файл). Он описан в RFC 1952.
- Реализации чтения и записи Zip-файлов спроектированы для работы с отображением файлов в памяти. Измените HWZip так, чтобы вместо
read_fileиспользовать mmap(2) под Linux или Mac и CreateFileMapping под Windows. - Измените HWZip так, чтобы он поддерживал извлечение и создание архивов в формате Zip64. Подробности ищите в последнем appnote.txt.
Полезные материалы
- Подробнее о BBS-культуре рассказывается в BBS: The Documentary. Видео можно найти на YouTube. В Part 8: Compression рассказывается о противостоянии SEA и PKWare. На сайте есть архив исторических материалов.
- В статье A better Zip bomb прекрасно объясняется создание Zip-файла, который при распаковке «взрывается» в огромный объём данных.
- В статье Zip Files All The Way Down показано, как создать Zip-квайн — файл, содержащий копию самого себя.
- ascii-zip — это программа, генерирующая Deflate-поток полностью в ASCII-кодировке. Она использовалась в эксплойте Rosetta Flash.
- Ten Thousand Security Pitfalls: the Zip File Format — подробная презентация о формате с точки зрения безопасности.
- Reading bits in far too many ways part 1, part 2 и part 3 — отличный источник информации о реализации битовых потоков.
- Статья Understanding Compression является введением в тему сжатия данных.

{kind=link}