

Эта статья, которая поможет разобраться в том, как устроена балансировка нагрузки в Kubernetes, что происходит при масштабировании долгоживущих соединений и почему стоит рассматривать балансировку на стороне клиента, если вы используете HTTP/2, gRPC, RSockets, AMQP или другие долгоживущие протоколы.
Немного о том, как перераспределяется трафик в Kubernetes
Kubernetes предоставляет две удобные абстракции для выкатки приложений: сервисы (Services) и развертывания (Deployments).
Развертывания описывают, каким образом и сколько копий вашего приложения должно быть запущено в любой момент времени. Каждое приложение разворачивается как под (Pod) и ему назначается IP-адрес.
Сервисы по функциям похожи на балансировщик нагрузки. Они предназначены для распределения трафика по множеству подов.
Посмотрим, как это выглядит.
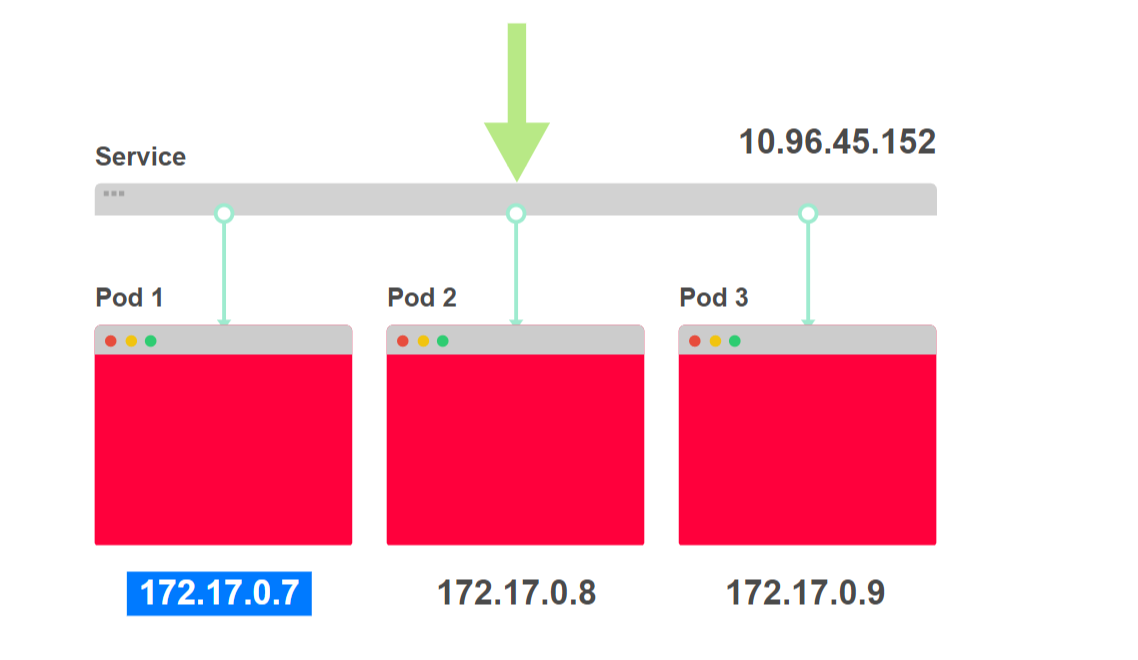
- На диаграмме ниже вы видите три экземпляра одного приложения и балансировщик нагрузки:
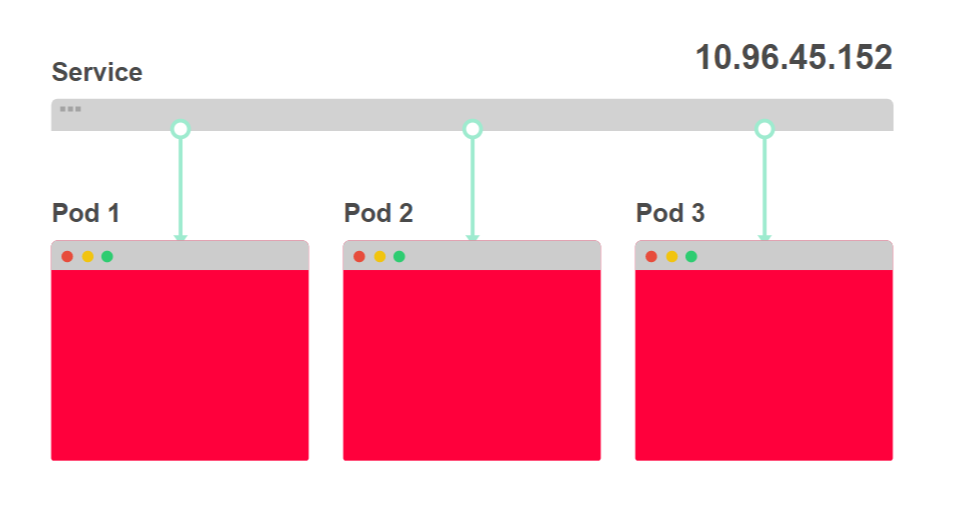
- Балансировщик нагрузки называется сервис (Service), ему присвоен IP-адрес. Любой входящий запрос перенаправляется к одному из подов:
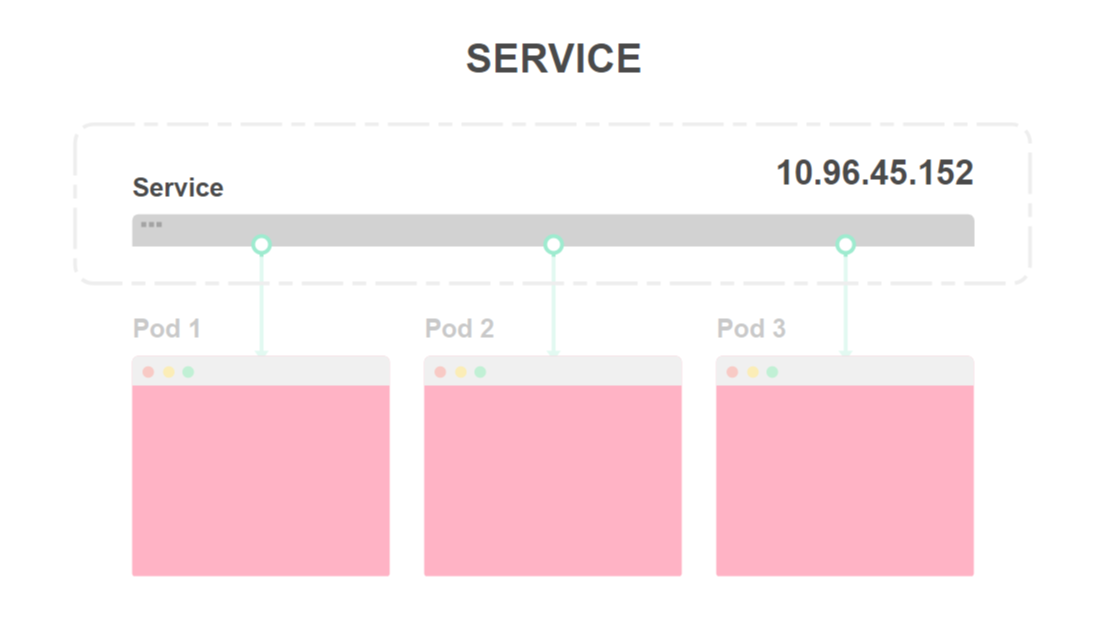
- Сценарий развертывания определяет количество экземпляров приложения. Вам практически никогда не придется разворачивать непосредственно под:

- Каждому поду присваивается свой IP-адрес:
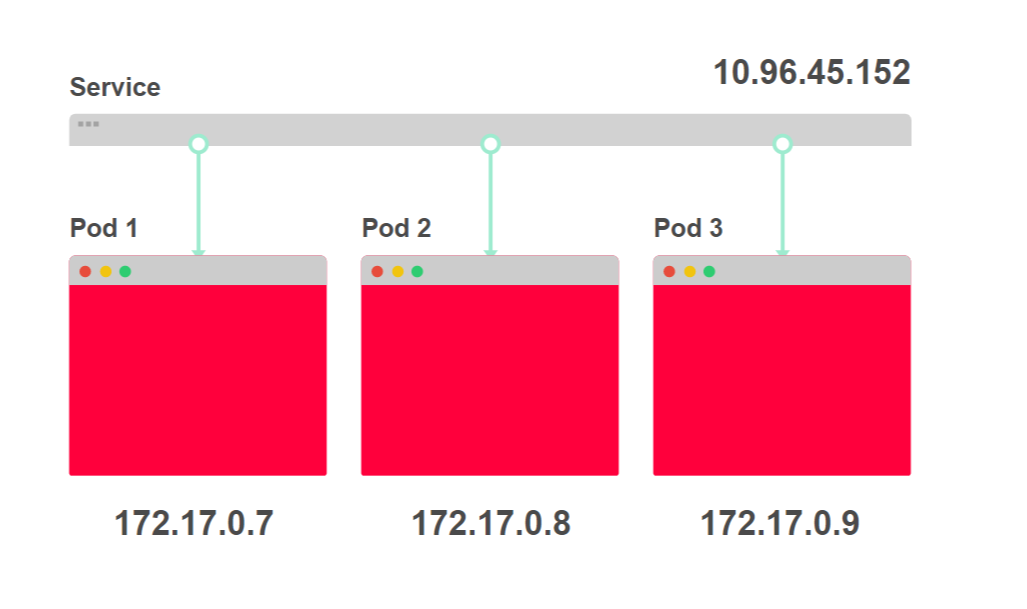




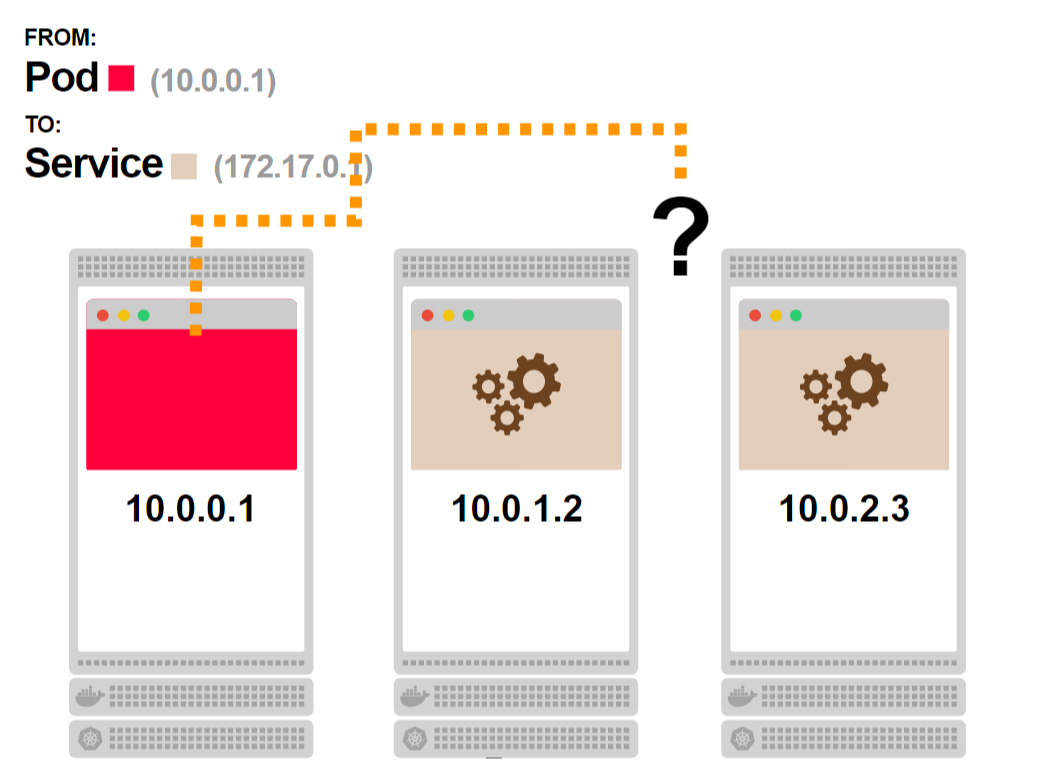
Полезно рассматривать сервисы как набор IP-адресов. Каждый раз, когда вы обращаетесь к сервису, один из IP-адресов выбирается из списка и используется как адрес назначения.
Это выглядит следующим образом.
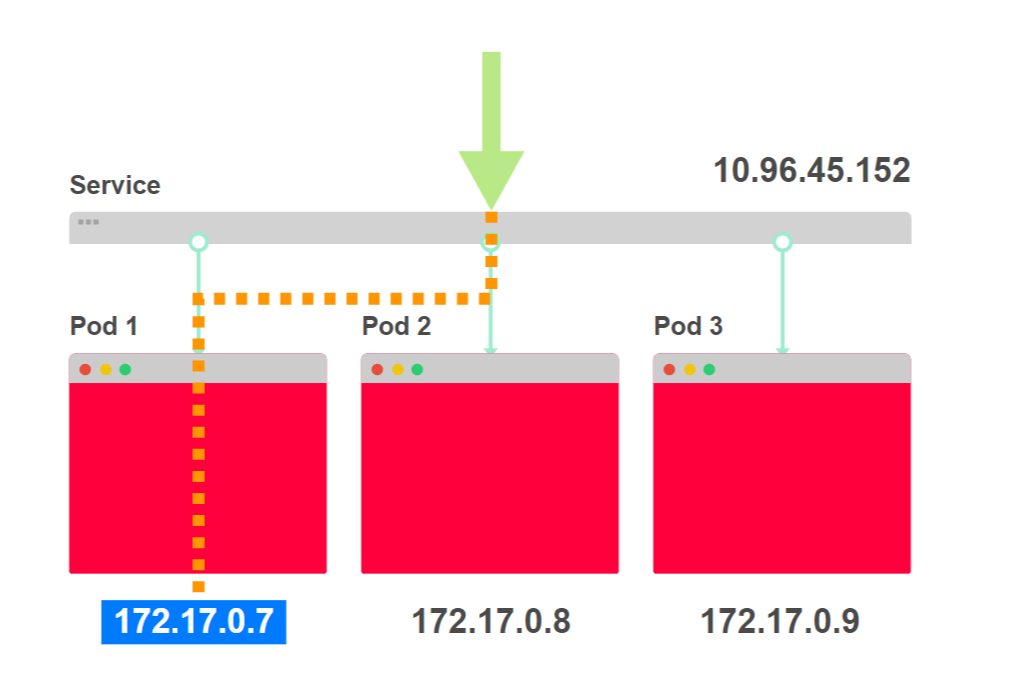
- Поступает запрос curl 10.96.45.152 к сервису:

- Сервис выбирает один из трех адресов подов в качестве пункта назначения:
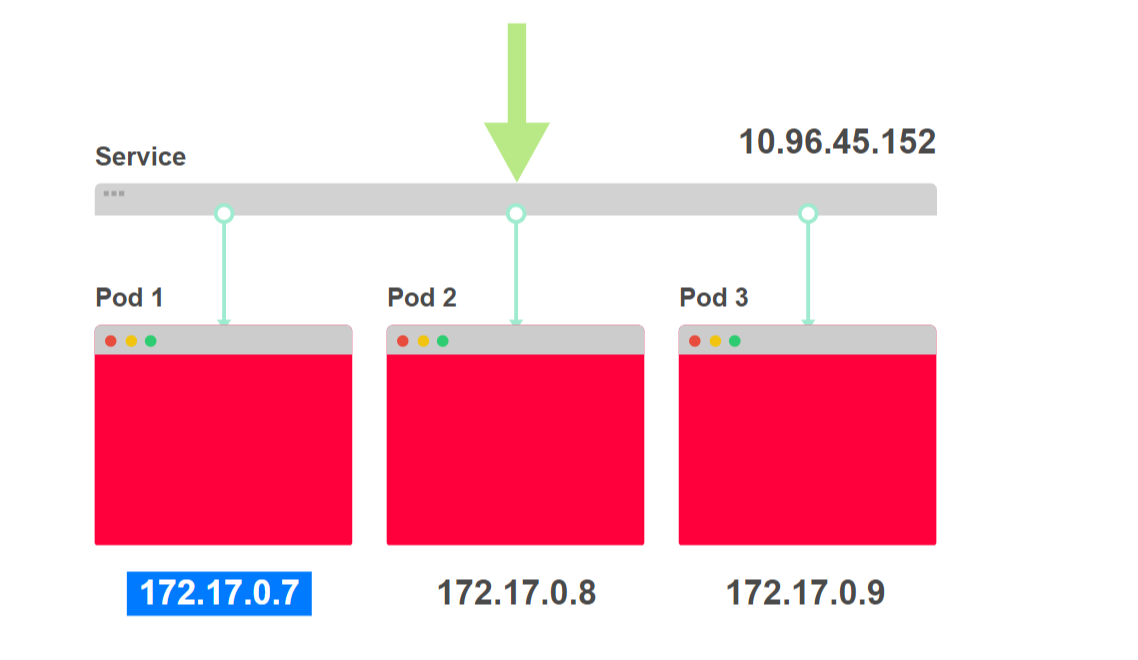
- Трафик перенаправляется к конкретному поду:


Если ваше приложение состоит из фронтенда и бэкенда, то у вас будет и сервис, и развертывание для каждого.
Когда фронтенд выполняет запрос к бэкенду, ему нет необходимости знать, сколько именно подов обслуживает бэкенд: их может быть и один, и десять, и сто.
Также фронтенд ничего не знает об адресах подов, обслуживающих бэкенд.
Когда фронтенд выполняет запрос к бэкенду, он использует IP-адрес сервиса бэкенда, который не изменяется.
Вот как это выглядит.
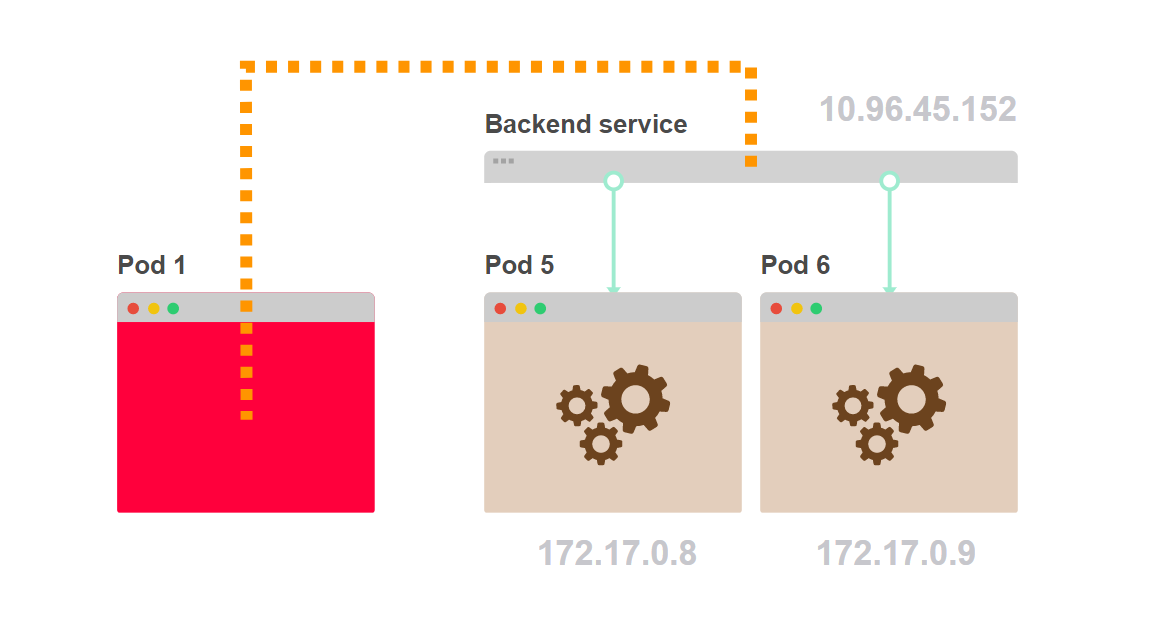
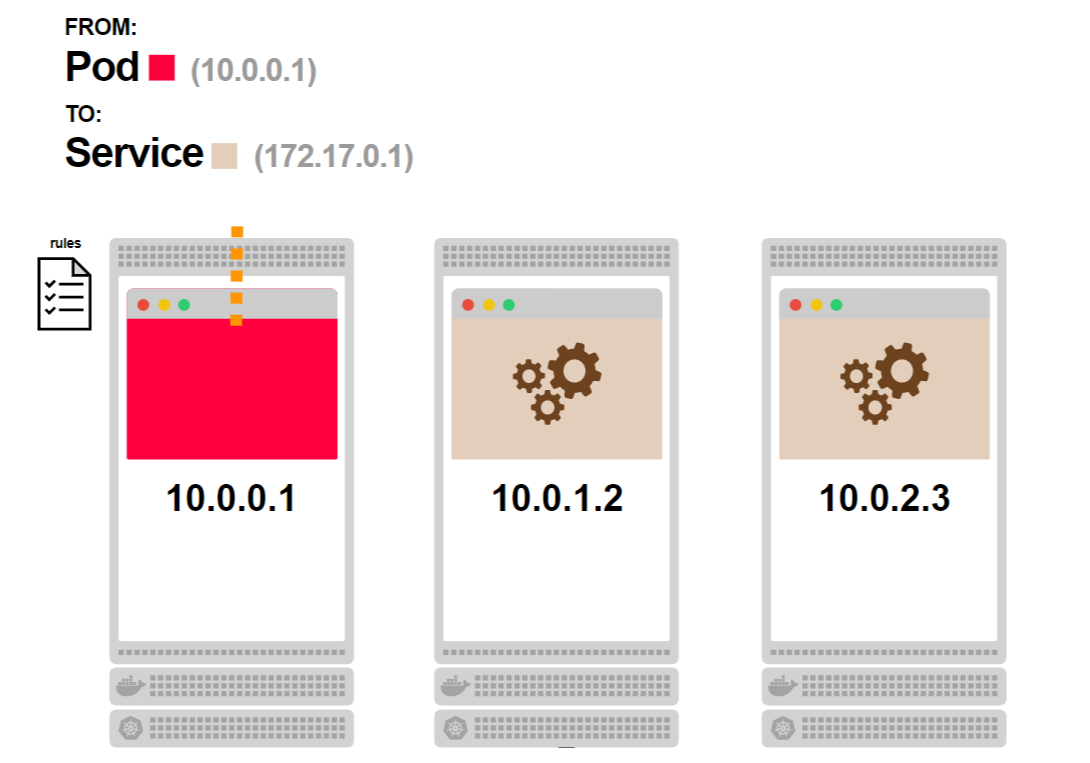
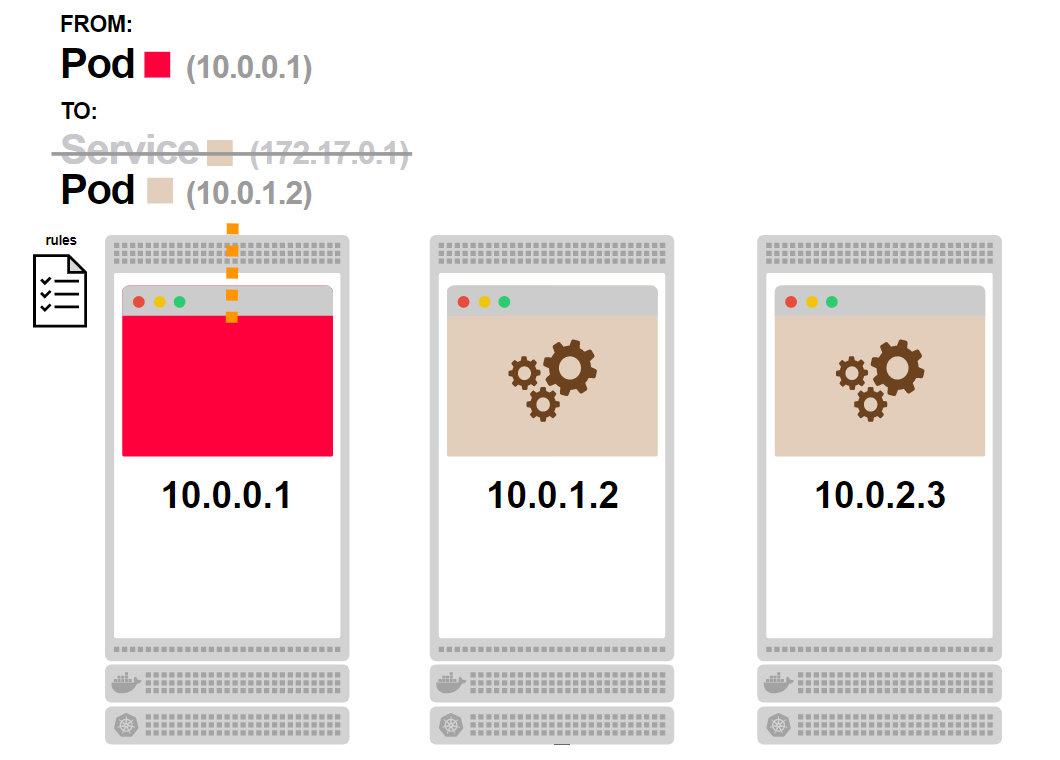
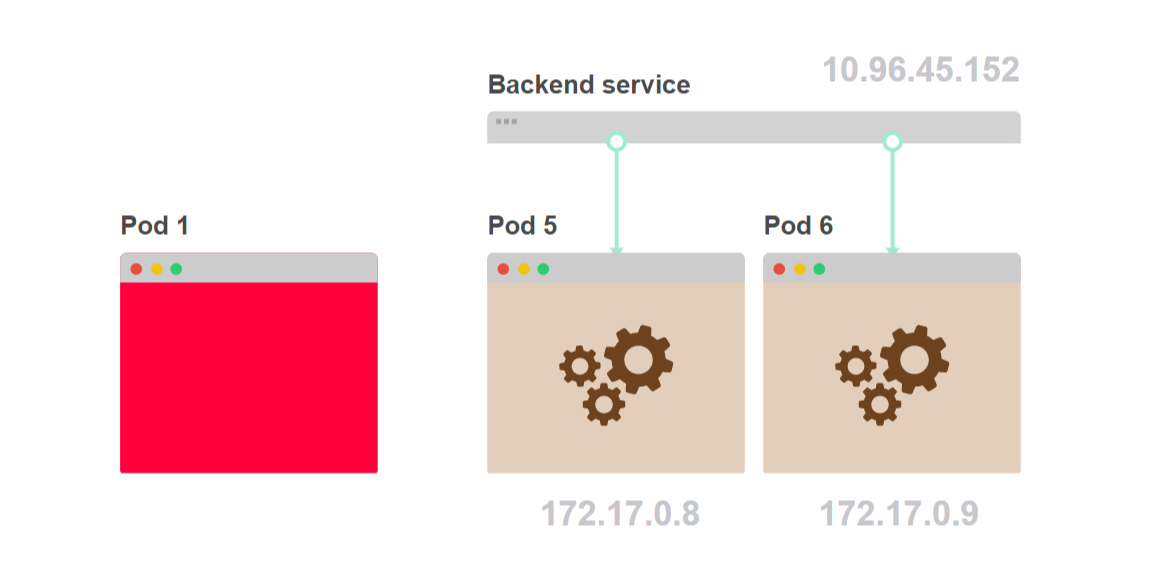
- Под 1 запрашивает внутренний компонент бэкенда. Вместо того, чтобы выбрать конкретный под бэкенда, он выполняет запрос к сервису:
- Сервис выбирает один из подов бэкенда в качестве адреса назначения:

- Трафик идет от пода 1 к поду 5, выбранному сервисом:

- Под 1 не знает, сколько именно таких подов, как под 5, спрятано за сервисом:





Но как именно сервис распределяет запросы? Вроде бы используется балансировка round-robin? Давайте разбираться.
Балансировка в сервисах Kubernetes
Сервисы Kubernetes не существуют. Для сервиса не существует процесса, которому выделен IP-адрес и порт.
Вы можете убедиться в этом, зайдя на любую ноду кластера и выполнив команду netstat -ntlp.
Вы даже не сможете найти IP-адрес, выделенный сервису.
IP-адрес сервиса размещен в слое управления, в контроллере, и записан в базу данных — etcd. Этот же адрес используется еще одним компонентом — kube-proxy.
Kube-proxy получает список IP-адресов для всех сервисов и формирует набор правил iptables на каждой ноде кластера.
Эти правила говорят: «Если мы видим IP-адрес сервиса, нужно модифицировать адрес назначения запроса и отправить его на один из подов».
IP-адрес сервиса используется только как точка входа и не обслуживается каким-либо процессом, слушающим этот ip-адрес и порт.
Посмотрим на это.
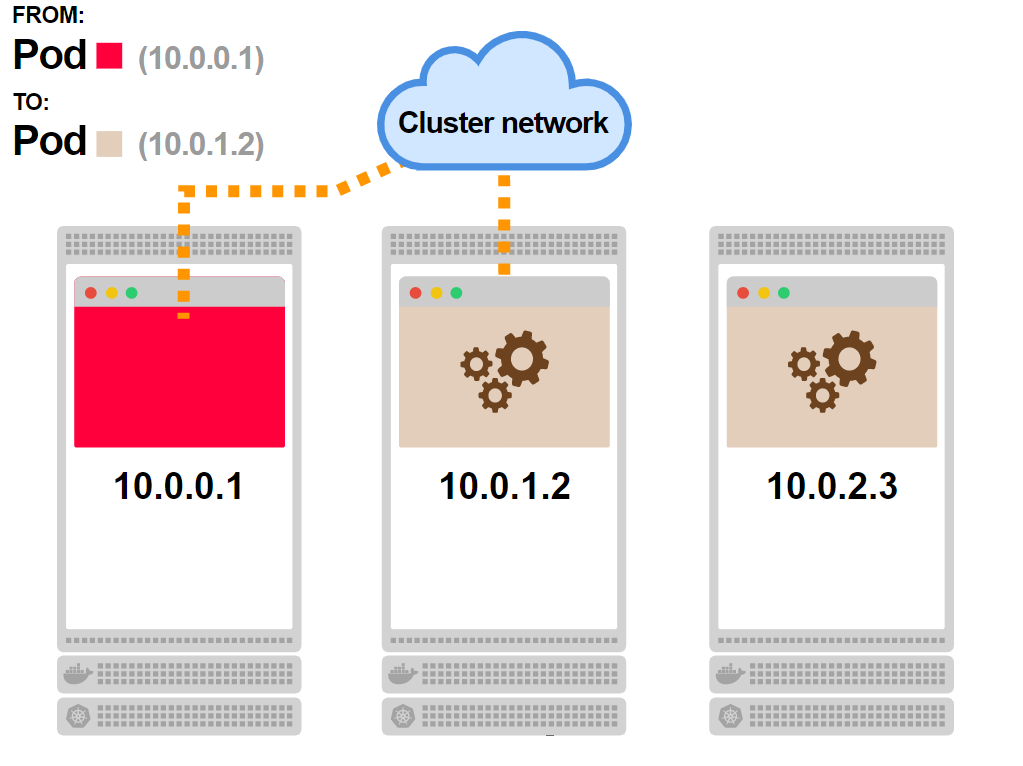
- Рассмотрим кластер из трех нод. На каждой ноде присутствуют поды:
- Связанные поды, окрашенные бежевым цветом, — это часть сервиса. Поскольку сервис не существует как процесс, он изображен серым цветом:

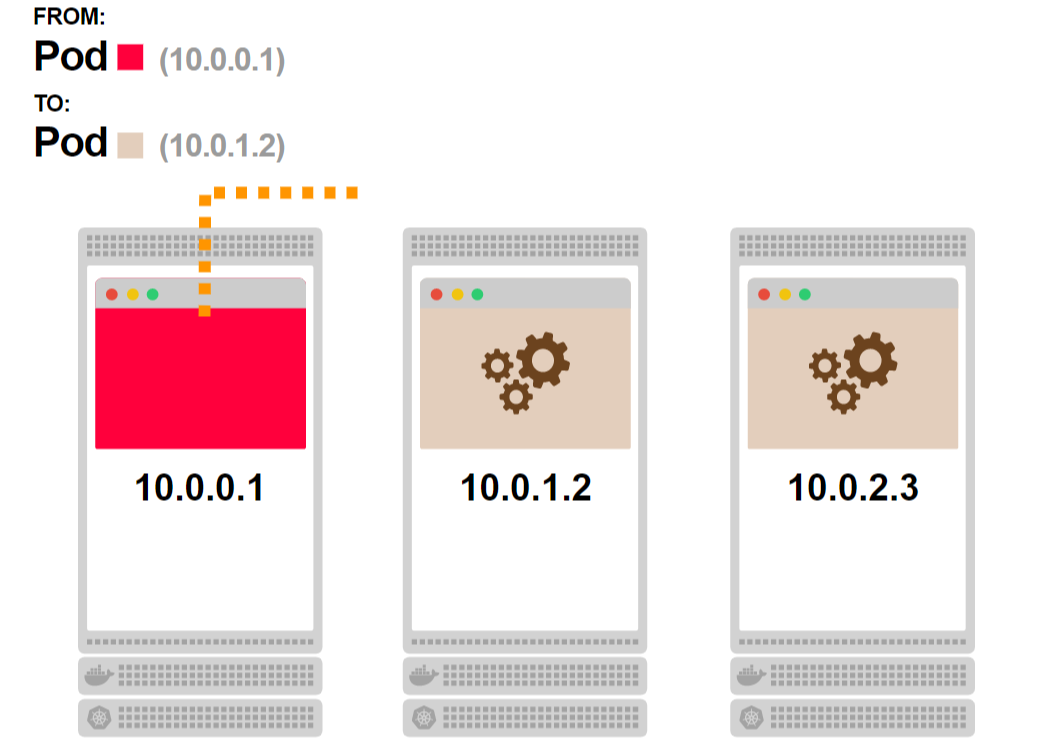
- Первый под запрашивает сервис и должен попасть на один из связанных подов:

- Но сервис не существует, процесса нет. Как же это работает?
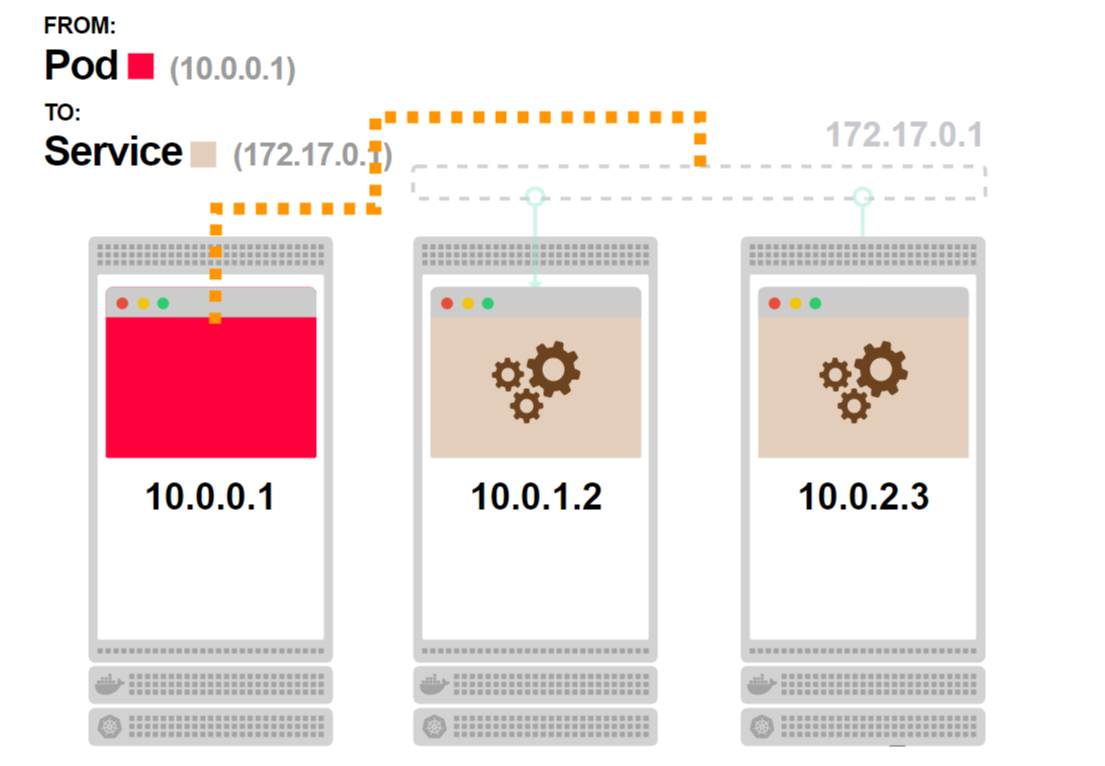
- Перед тем как запрос покинет ноду, он проходит через правила iptables:
- Правила iptables знают, что сервиса нет, и заменяют его IP-адрес одним из IP-адресов подов, связанных с этим сервисом:
- Запрос получает действующий IP-адрес в качестве адреса назначения и нормально обрабатывается:

- В зависимости от сетевой топологии, запрос в итоге достигает пода:





Умеют ли iptables балансировать нагрузку?
Нет, iptables используются для фильтрации и не проектировались для балансировки.
Однако существует возможность написать набор правил, которые работают как псевдобалансер.
И именно это реализовано в Kubernetes.
Если у вас есть три пода, kube-proxy напишет следующие правила:
- Выбрать первый под с вероятностью 33%, иначе перейти к следующему правилу.
- Выбрать второй под с вероятностью 50%, иначе перейти к следующему правилу.
- Выбрать третий под.
Такая система приводит к тому, что каждый под выбирается с вероятностью 33%.
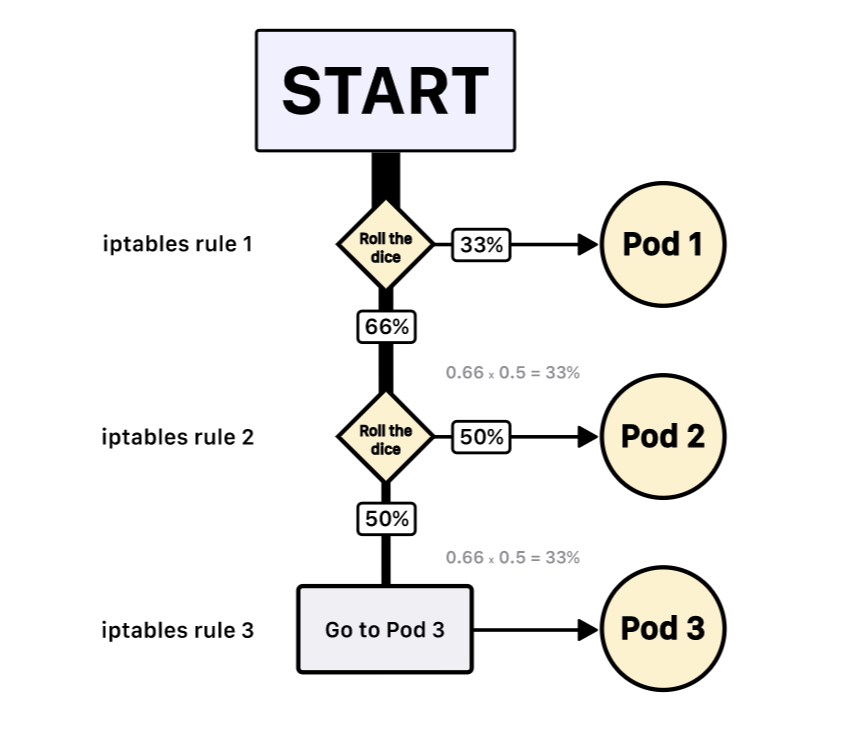
И нет никакой гарантии, что под 2 будет выбран следующим после пода 1.
Примечание: iptables использует статистический модуль со случайным распределением. Таким образом, алгоритм балансировки базируется на случайном выборе.
Теперь, когда вы понимаете, как работают сервисы, давайте посмотрим на более интересные сценарии работы.
Долгоживущие соединения в Kubernetes не масштабируются по умолчанию
Каждый HTTP-запрос от фронтенда к бэкенду обслуживается отдельным TCP-соединением, которое открывается и закрывается.
Если фронтенд отправляет 100 запросов в секунду бэкенду, то открывается и закрывается 100 разных TCP-соединений.
Можно уменьшить время обработки запроса и снизить нагрузку, если открыть одно TCP-соединение и использовать его для всех последующих HTTP-запросов.
В HTTP-протокол заложена возможность, называемая HTTP keep-alive, или повторное использование соединения. В этом случае одно TCP-соединение используется для отправки и получения множества HTTP-запросов и ответов:

Эта возможность не включена по умолчанию: и сервер, и клиент должны быть сконфигурированы соответствующим образом.
Сама по себе настройка проста и доступна для большинства языков программирования и сред.
Вот несколько ссылок на примеры на разных языках:
Что произойдет, если мы будем использовать keep-alive в сервисе Kubernetes?
Давайте будем считать, что и фронтенд, и бэкенд поддерживают keep-alive.
У нас одна копия фронтенда и три экземпляра бэкенда. Фронтенд делает первый запрос и открывает TCP-соединение к бэкенду. Запрос достигает сервиса, один из подов бэкенда выбирается как адрес назначения. Под бэкенда отправляет ответ, и фронтенд его получает.
В отличие от обычной ситуации, когда после получения ответа TCP-соединение закрывается, сейчас оно поддерживается открытым для следующих HTTP-запросов.
Что произойдет, если фронтенд отправит еще запросы на бэкенд?
Для пересылки этих запросов будет задействовано открытое TCP-соединение, все запросы попадут на тот же самый под бэкенда, куда попал первый запрос.
Разве iptables не должен перераспределить трафик?
Не в этом случае.
Когда создается TCP-соединение, оно проходит через правила iptables, которые и выбирают конкретный под бэкенда, куда попадет трафик.
Поскольку все следующие запросы идут по уже открытому TCP-соединению, правила iptables больше не вызываются.
Посмотрим, как это выглядит.
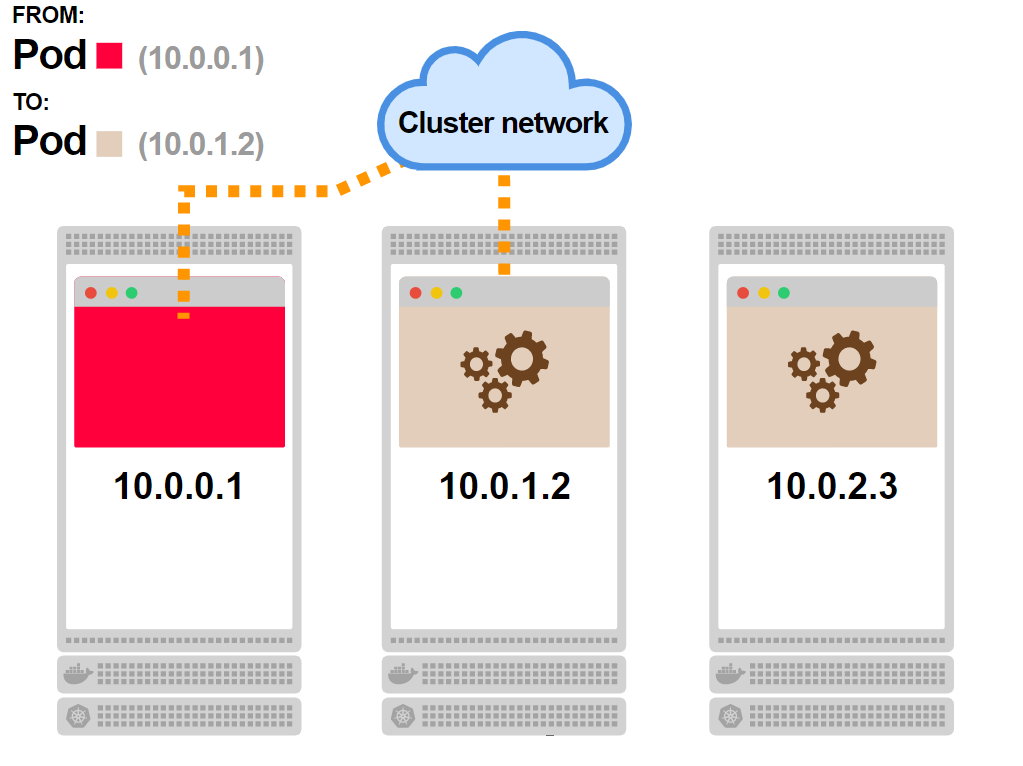
- Первый под отправляет запрос к сервису:
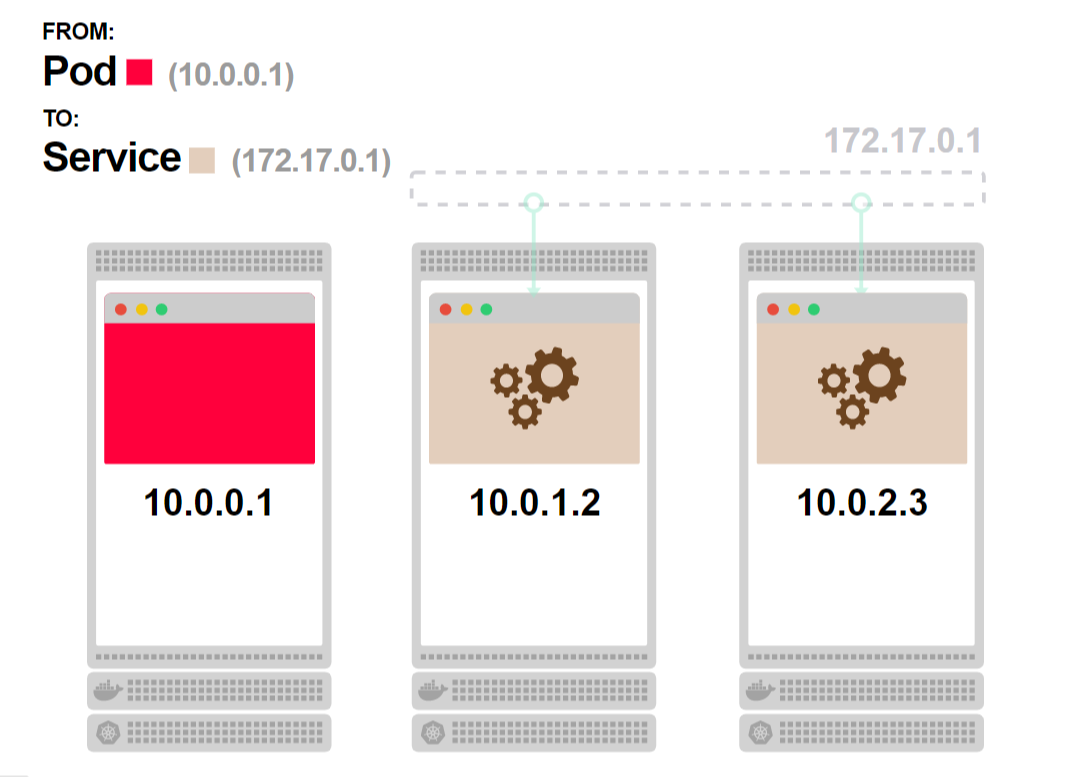
- Вы уже знаете что будет дальше. Сервиса не существует, но есть правила iptables, которые обработают запрос:
- Один из подов бэкенда будет выбран в качестве адреса назначения:

- Запрос достигает пода. В этот момент постоянное TCP-соединение между двумя подами будет установлено:

- Любой следующий запрос от первого пода будет идти по уже установленному соединению:

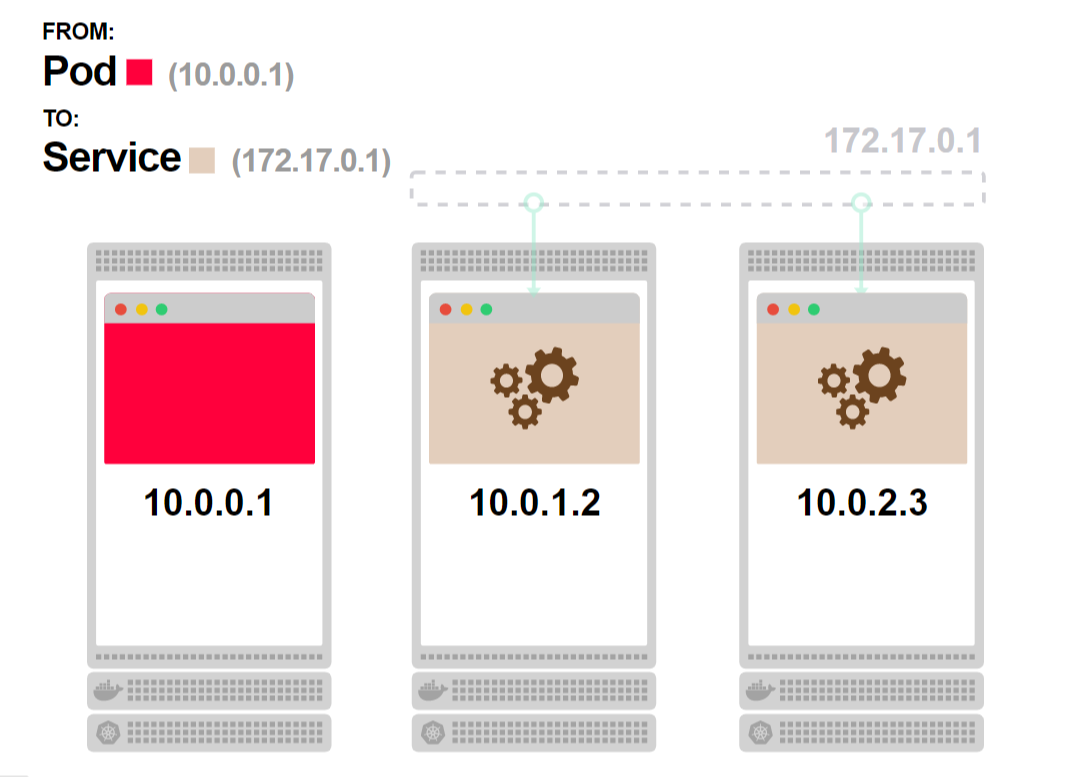

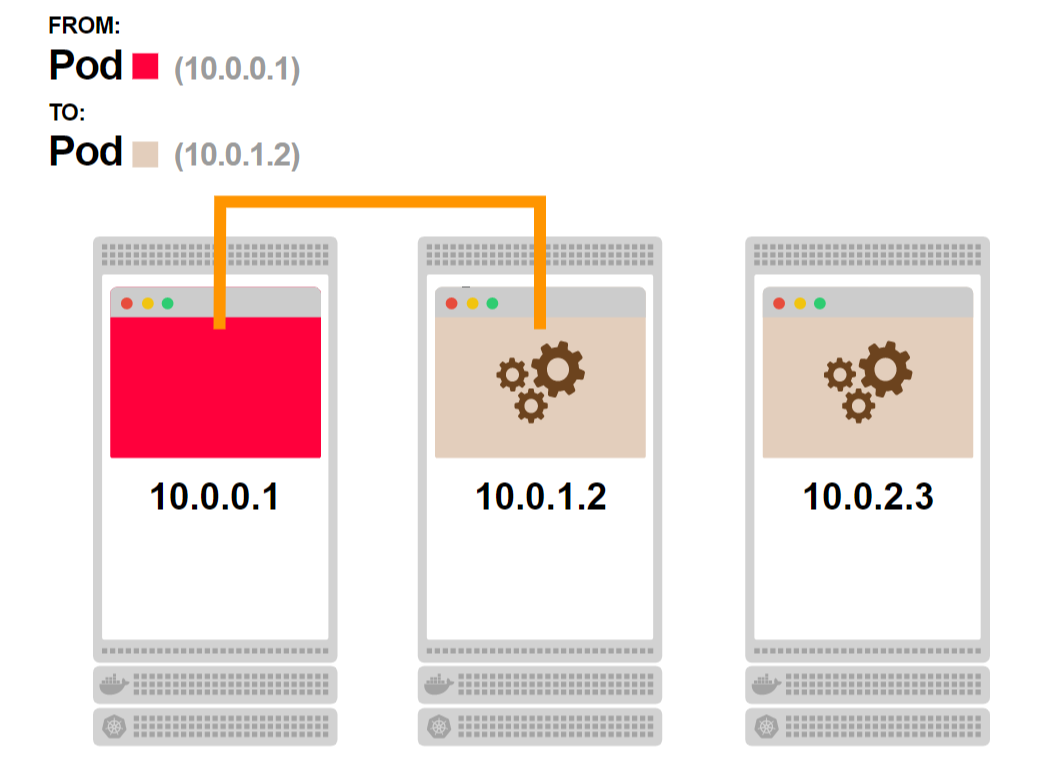
В результате вы получили более быстрый отклик и более высокую пропускную способность, но потеряли возможность масштабирования бэкенда.
Даже если у вас в бэкенде два пода, при постоянном соединении трафик все время будет попадать на один из них.
Можно ли это исправить?
Поскольку Kubernetes не знает, как балансировать постоянные соединения, эта задача возлагается на вас.
Сервисы — это набор IP-адресов и портов, которые называют конечными точками.
Ваше приложение может получить список конечных точек из сервиса и решить, как распределять запросы между ними. Можно открыть по постоянному соединению с каждым подом и балансировать запросы между этими соединениями с помощью round-robin.
Или применить более сложные алгоритмы балансировки.
Код на стороне клиента, который отвечает за балансировку, должен следовать такой логике:
- Получить список конечных точек из сервиса.
- Для каждой конечной точки открыть постоянное соединение.
- Когда необходимо сделать запрос, использовать одно из открытых соединений.
- Регулярно обновлять список конечных точек, создавать новые или закрывать старые постоянные соединения в случае изменения списка.
Вот как это будет выглядеть.
- Вместо того, чтобы первый под отправлял запрос в сервис, вы можете балансировать запросы на стороне клиента:
- Нужно написать код, который спрашивает, какие поды являются частью сервиса:

- Как только получите список, сохраните его на стороне клиента и используйте для соединения с подами:

- Вы сами отвечаете за алгоритм балансировки нагрузки:




Теперь появился вопрос: относится ли эта проблема только к HTTP keep-alive?
Балансировка нагрузки на стороне клиента
HTTP — не единственный протокол, который может использовать постоянные TCP-соединения.
Если ваше приложение использует базу данных, то TCP-соединение не открывается каждый раз, когда вам нужно вылолнить запрос или получить документ из БД.
Вместо этого открывается и используется постоянное TCP-соединение к базе данных.
Если ваша база данных развернута в Kubernetes и доступ предоставляется в виде cервиса, то вы столкнетесь с теми же проблемами, что описаны в предыдущем разделе.
Одна реплика базы данных будет нагружена больше, чем остальные. Kube-proxy и Kubernetes не помогут балансировать соединения. Вы должны позаботиться о балансировке запросов к вашей базе данных.
В зависимости от того, какую библиотеку вы используете для подключения к БД, у вас могут быть различные варианты решения этой проблемы.
Ниже приведен пример доступа к кластеру БД MySQL из Node.js:
var mysql = require('mysql');
var poolCluster = mysql.createPoolCluster();
var endpoints = /* retrieve endpoints from the Service */
for (var [index, endpoint] of endpoints) {
poolCluster.add(`mysql-replica-${index}`, endpoint);
}
// Make queries to the clustered MySQL databaseСуществует масса других протоколов, использующих постоянные TCP-соединения:
- WebSockets and secured WebSockets
- HTTP/2
- gRPC
- RSockets
- AMQP
Вы должны быть уже знакомы с большинством этих протоколов.
Но если эти протоколы так популярны, почему нет стандартизованного решения для балансировки? Почему требуется изменение логики клиента? Существует ли нативное решение Kubernetes?
Kube-proxy и iptables созданы, чтобы закрыть большинство стандартных сценариев использования при развертывании в Kubernetes. Это сделано для удобства.
Если вы используете веб-сервис, который предоставляет REST API, вам повезло — в этом случае постоянные TCP-соединения не используются, вы можете использовать любой сервис Kubernetes.
Но как только вы начнете использовать постоянные TCP-соединения, придется разбираться, как равномерно распределить нагрузку на бэкенды. Kubernetes не содержит готовых решений на этот случай.
Однако, конечно же, существуют варианты, которые могут помочь.
Балансировка долгоживущих соединений в Kubernetes
В Kubernetes существует четыре типа сервисов:
- ClusterIP
- NodePort
- LoadBalancer
- Headless
Первые три сервиса работают на базе виртуального IP-адреса, который используется kube-proxy для построения правил iptables. Но фундаментальная основа всех сервисов — это сервис типа headless.
С сервисом headless не связан никакой IP-адрес и он только предоставляет механизм получения списка IP-адресов и портов связанных с ним подов (конечные точки).
Все сервисы базируются на сервисе headless.
Сервис ClusterIP — это headless сервис с некоторыми дополнениями:
- Слой управления назначает ему IP-адрес.
- Kube-proxy формирует необходимые правила iptables.
Таким образом, вы можете игнорировать kube-proxy и напрямую использовать список конечных точек, полученных из сервиса headless для балансировки нагрузки в вашем приложении.
Но как добавить подобную логику ко всем приложениям, развернутым в кластере?
Если ваше приложение уже развернуто, то такая задача может показаться невыполнимой. Однако есть альтернативный вариант.
Service Mesh вам поможет
Вы, наверное, уже заметили, что стратегия балансировки нагрузки на стороне клиента вполне стандартна.
Когда приложение стартует, оно:
- Получает список IP-адресов из сервиса.
- Открывает и поддерживает пул соединений.
- Периодически обновляет пул, добавляя или убирая конечные точки.
Как только приложение хочет сделать запрос, оно:
- Выбирает доступное соединение, используя какую-либо логику (например, round-robin).
- Выполняет запрос.
Эти шаги работают и для соединений WebSockets, и для gRPC, и для AMQP.
Вы можете выделить эту логику в отдельную библиотеку и использовать ее в ваших приложениях.
Однако вместо этого можно использовать сервисные сетки, например, Istio или Linkerd.
Service Mesh дополняет ваше приложение процессом, который:
- Автоматически ищет IP-адреса сервисов.
- Проверяет соединения, такие как WebSockets и gRPC.
- Балансирует запросы, используя правильный протокол.
Service Mesh помогает управлять трафиком внутри кластера, но он довольно ресурсоемок. Другие варианты — это использование сторонних библиотек, например Netflix Ribbon, или программируемых прокси, например Envoy.
Что произойдет, если игнорировать вопросы балансировки?
Вы можете не использовать балансировку нагрузки и при этом не заметить никаких изменений. Давайте посмотрим на несколько сценариев работы.
Если у вас больше клиентов, чем серверов, это не такая большая проблема.
Предположим, есть пять клиентов, которые коннектятся к двум серверам. Даже если нет балансировки, оба сервера будут использоваться:
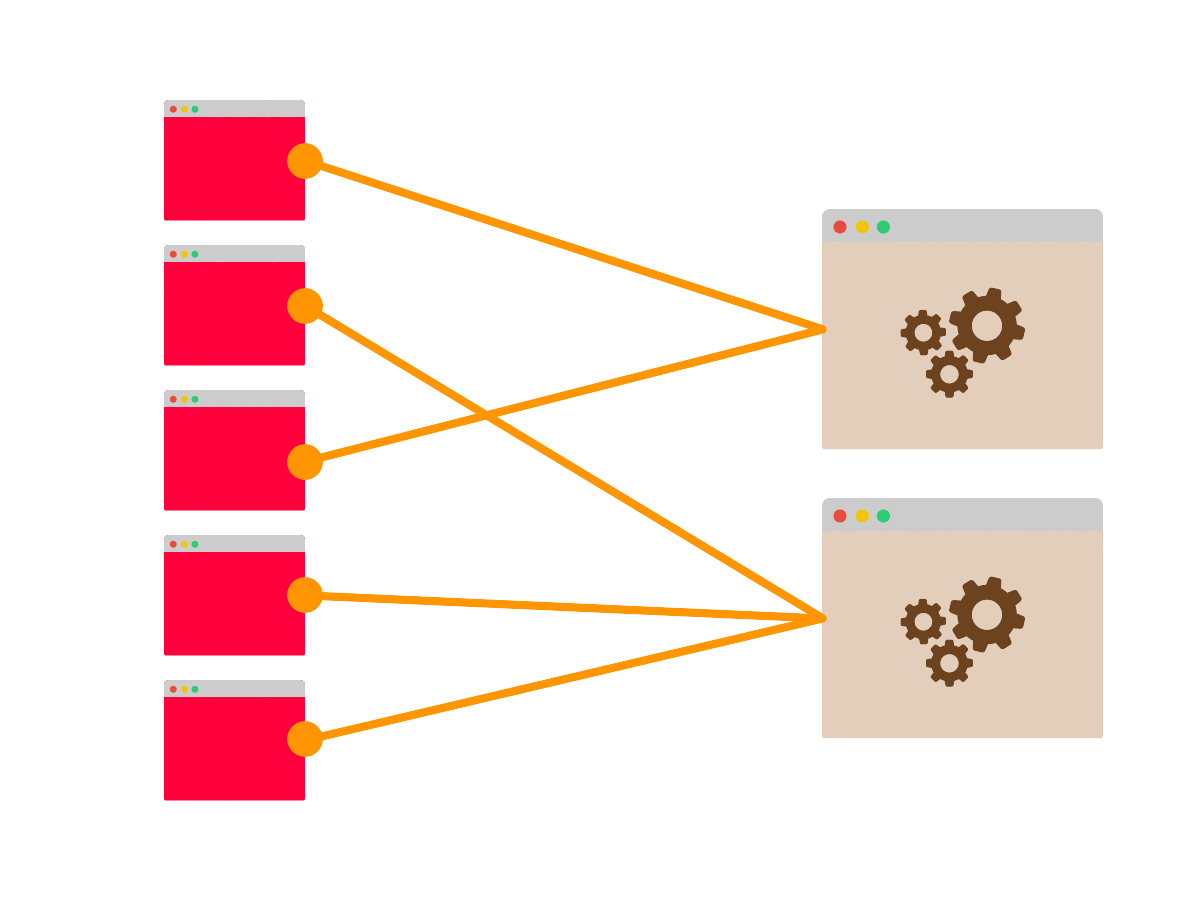
Соединения могут быть распределены неравномерно: возможно, четыре клиента подключились к одному и тому же серверу, но есть хороший шанс, что оба сервера будут использованы.
Что более проблематично, так это противоположный сценарий.
Если у вас меньше клиентов и больше серверов, ваши ресурсы могут недостаточно использоваться, и появится потенциальное узкое место.
Предположим, есть два клиента и пять серверов. В лучшем случае будет два постоянных соединения к двум серверам из пяти.
Остальные серверы будут простаивать:

Если эти два сервера не могут справиться с обработкой запросов клиентов, горизонтальное масштабирование не поможет.
Заключение
Сервисы Kubernetes созданы для работы в большинстве стандартных сценариев веб-приложений.
Однако, как только вы начинаете работать с протоколами приложений, которые используют постоянные соединения TCP, такими как базы данных, gRPC или WebSockets, сервисы уже не подходят. Kubernetes не предоставляет внутренних механизмов для балансировки постоянных TCP-соединений.
Это значит, вы должны писать приложения с учетом возможности балансировки на стороне клиента.
Перевод подготовлен командой Kubernetes aaS от Mail.ru.
Что еще почитать по теме:
