
Перевод A Complete Machine Learning Walk-Through in Python: Part Three
Многим не нравится, что модели машинного обучения представляют собой чёрные ящики: мы кладём в них данные и безо всяких объяснений получаем ответы — часто очень точные ответы. В этой статье мы постараемся разобраться, как созданная нами модель делает прогнозы и что она может рассказать о решаемой нами задаче. И завершим мы обсуждением самой важной части проекта по машинному обучению: задокументируем сделанное и представим результаты.
В первой части мы рассмотрели очистку данных, разведочный анализ, конструирование и выбор признаков. Во второй части изучили заполнение отсутствующих данных, реализацию и сравнение моделей машинного обучения, гиперпараметрическую настройку с помощью случайного поиска с перекрёстной проверкой и, наконец, оценку получившейся модели.
Весь код проекта лежит на GitHub. А третья Jupyter Notebook, относящаяся к этой статье, лежит здесь. Можете её использовать для своих проектов!
Итак, мы работаем над решением задачи с помощью машинного обучения, точнее, с помощью управляемой регрессии (supervised regression). На основе данных об энергопотреблении зданий в Нью-Йорке мы создали модель, прогнозирующую количество баллов Energy Star Score. У нас получилась модель «регрессия на основе градиентного бустинга», способная на основе тестовых данных прогнозировать в пределах 9,1 пунктов (в диапазоне от 1 до 100).
Интерпретация модели
Регрессия на основе градиентного бустинга располагается примерно посередине шкалы интерпретируемости моделей: сама модель сложная, но состоит из сотен довольно простых деревьев решений. Есть три способа разобраться в работе нашей модели:
- Оценить важности признаков.
- Визуализировать одно из деревьев решений.
- Применить метод LIME — Local Interpretable Model-Agnostic Explainations, локальные интерпретируемые моделезависимые объяснения.
Первые два метода характерны для ансамблей деревьев, а третий, как вы могли понять из его названия, можно применять к любой модели машинного обучения. LIME — относительно новый подход, это заметный шаг вперёд в попытке объяснить работу машинного обучения.
Важности признаков
Важности признаков позволяют увидеть связь каждого признака с целью прогнозирования. Технические подробности этого метода сложны (измеряется среднее уменьшение инородности (the mean decrease impurity) или уменьшение ошибки из-за включения признака), но мы можем использовать относительные значения, чтобы понять, какие признаки более релевантны. В Scikit-Learn можно извлечь важности признаков из любого ансамбля «учеников» на основе деревьев.
В приведённом ниже коде
model — наша обученная модель, и с помощью model.feature_importances_ можно определить важности признаков. Затем мы отправим их в кадр данных Pandas и выведем на экран 10 самых важных признаков:import pandas as pd
# model is the trained model
importances = model.feature_importances_
# train_features is the dataframe of training features
feature_list = list(train_features.columns)
# Extract the feature importances into a dataframe
feature_results = pd.DataFrame({'feature': feature_list,'importance': importances})
# Show the top 10 most important
feature_results = feature_results.sort_values('importance',ascending = False).reset_index(drop=True)
feature_results.head(10)
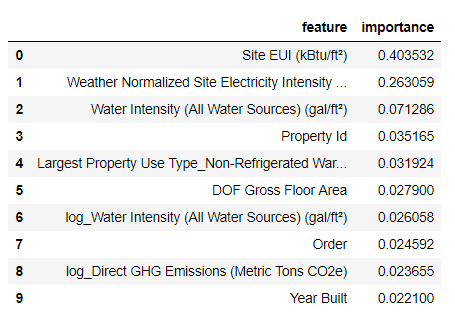
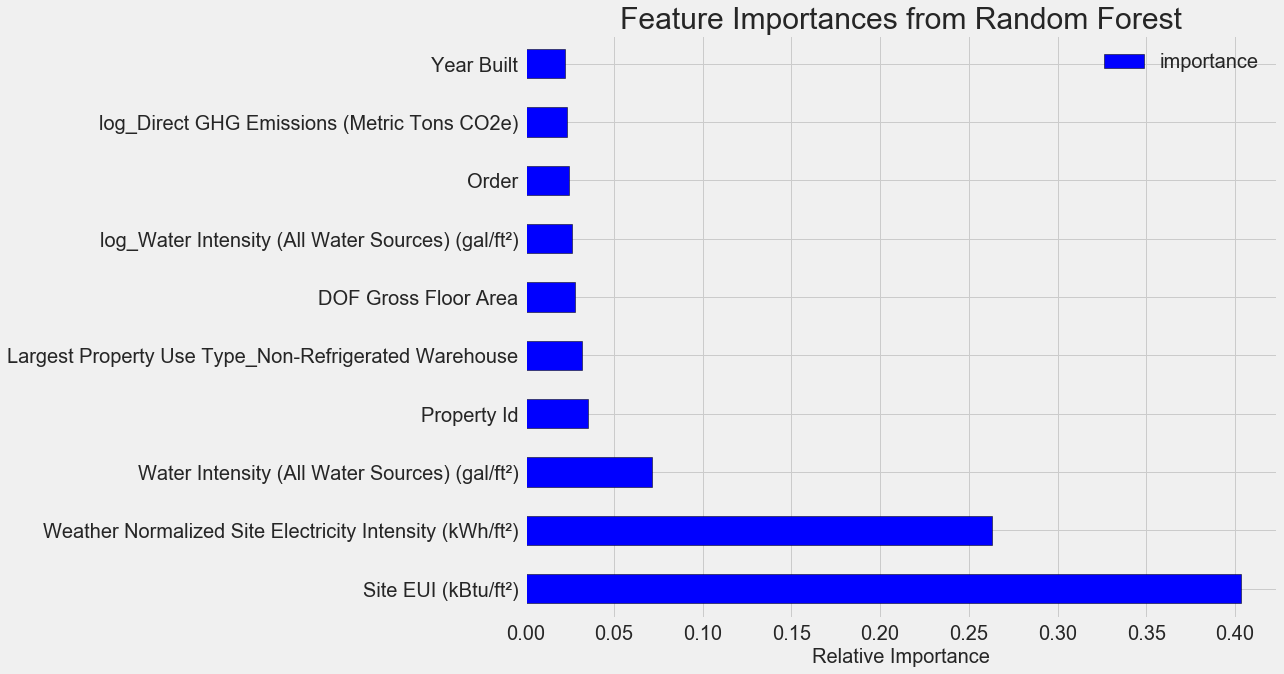
Самые важные признаки —
Site EUI (интенсивность потребления энергии) и Weather Normalized Site Electricity Intensity, на них приходится больше 66 % суммарной важности. Уже у третьего признака важность сильно падает, это может говорить о том, что нам не нужно использовать все 64 признака для достижения высокой точности прогнозирования (в Jupyter notebook эта теория проверяется с использованием только 10 самых важных признаков, и модель оказалась не слишком точной).На основе этих результатов можно наконец-то ответить на один из исходных вопросов: самыми важными индикаторами количества баллов Energy Star Score являются Site EUI и Weather Normalized Site Electricity Intensity. Не будем слишком углубляться в дебри важностей признаков, скажем лишь, что с них можно начать разбираться в механизме прогнозирования моделью.
Визуализация одного дерева решений
Осмыслить всю модель регрессии на основе градиентного бустинга тяжело, чего не скажешь об отдельных деревьях решений. Можно визуализировать любое дерево с помощью
Scikit-Learn-функции export_graphviz. Сначала извлечём дерево из ансамбля, а затем сохраним его в виде dot-файла:from sklearn import tree
# Extract a single tree (number 105)
single_tree = model.estimators_[105][0]
# Save the tree to a dot file
tree.export_graphviz(single_tree, out_file = 'images/tree.dot', feature_names = feature_list)С помощью визуализатора Graphviz преобразуем dot-файл в png, введя в командной строке:
dot -Tpng images/tree.dot -o images/tree.pngПолучили полное дерево решений:

Немного громоздко! Хотя это дерево глубиной всего в 6 слоёв, отследить все переходы трудно. Давайте изменим вызов функции
export_graphviz и ограничим глубину дерева двумя слоями: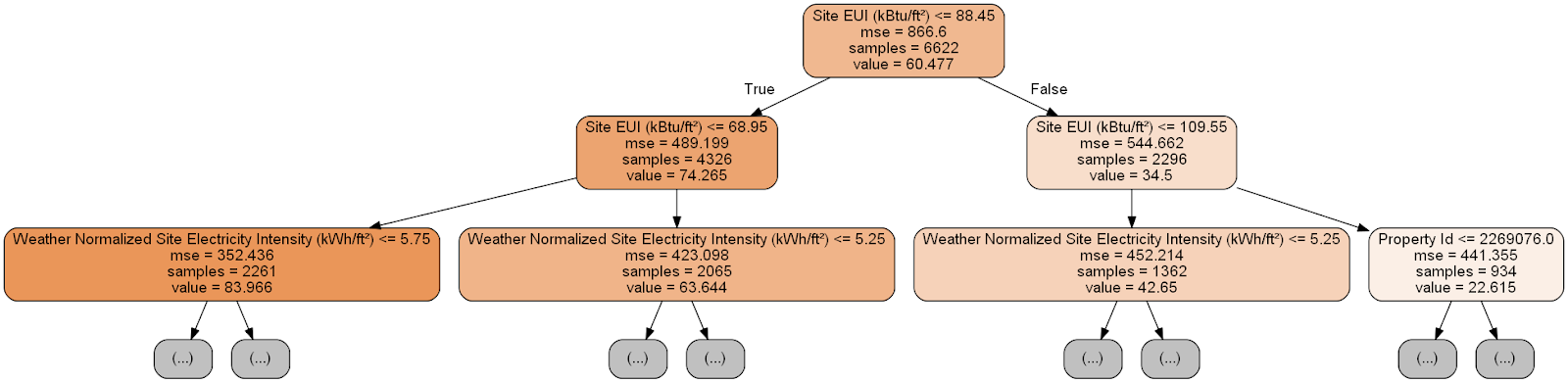
Каждый узел (прямоугольник) дерева содержит четыре строки:
- Задаваемый вопрос о значении одного из признаков конкретного измерения: от него зависит, в какую сторону мы выйдем из этого узла.
Mse— мера ошибки в узле.Samples— количество образцов данных (измерений) в узле.Value— оценка цели для всех образцов данных в узле.
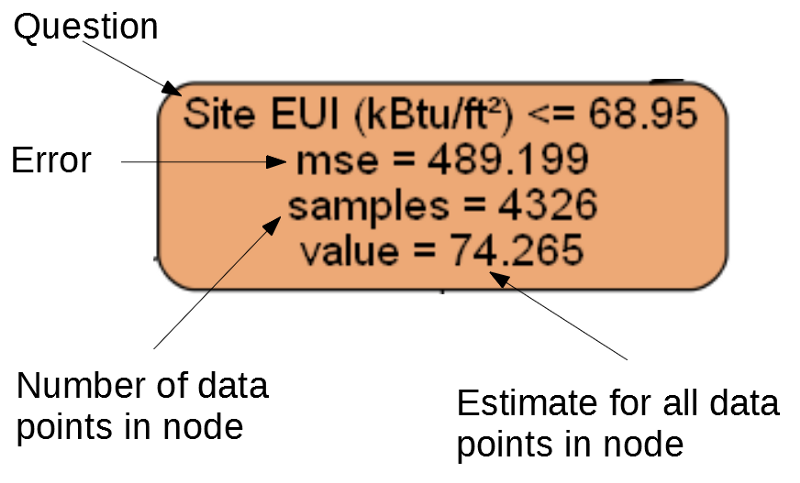
Отдельный узел.
(Листья содержат только 2.–4., потому что они представляют собой финальную оценку и не имеют дочерних узлов).
Формирование прогноза для заданного измерения в дереве решений начинается с верхнего узла — корня, а затем спускается вниз по дереву. В каждом узле нужно ответить на задаваемый вопрос «да» или «нет». Например, на предыдущей иллюстрации спрашивается: «Site EUI здания меньше или равно 68.95?» Если да, алгоритм переходит в правый дочерний узел, если нет, то в левый.
Эта процедура повторяется на каждом слое дерева, пока алгоритм не дойдёт до узла-листа на последнем слое (эти узлы не показаны на иллюстрации с уменьшенным деревом). Прогнозом для любого измерения в листе является
value. Если в лист приходит несколько измерений (samples), то каждое из них получит один и тот же прогноз. По мере увеличения глубины дерева ошибка на обучающих данных будет уменьшаться, поскольку листьев будет больше и образцы будут делиться тщательнее. Однако слишком глубокое дерево приведёт к переобучению на обучающих данных и не сможет обобщить тестовые данные.Во второй статье мы настроили количество гиперпараметров модели, которые управляют каждым деревом, например, максимальную глубину дерева и минимальное количество образцов, необходимых для каждого листа. Два этих параметра сильно влияют на баланс между пере- и недообучением, а визуализация дерева решений позволит нам понять, как работают эти настройки.
Хотя мы не сможем изучить все деревья в модели, анализ одного из них поможет разобраться в том, как прогнозирует каждый «ученик». Этот основанный на блок-схеме метод очень похож на то, как принимает решение человек. Ансамбли из деревьев решений комбинируют прогнозы многочисленных отдельных деревьев, что позволяет создавать более точные модели с меньшей вариативностью. Такие ансамбли очень точны и просты в объяснении.
Локальные интерпретируемые моделезависимые объяснения (LIME)
Последний инструмент, с помощью которого можно постараться разобраться в том, как «думает» наша модель. LIME позволяет объяснить, как сформирован одиночный прогноз любой модели машинного обучения. Для этого локально, рядом с каким-нибудь измерением на основе простой модели наподобие линейной регрессии создаётся упрощённая модель (подробности описаны в этой работе: https://arxiv.org/pdf/1602.04938.pdf).
Мы воспользуемся методом LIME, чтобы изучить совершенно ошибочный прогноз нашей модели и понять, почему она ошибается.
Сначала найдём этот неверный прогноз. Для этого обучим модель, сгенерируем прогноз и выберем значение с наибольшей ошибкой:
from sklearn.ensemble import GradientBoostingRegressor
# Create the model with the best hyperparamters
model = GradientBoostingRegressor(loss='lad', max_depth=5, max_features=None, min_samples_leaf=6, min_samples_split=6, n_estimators=800, random_state=42)
# Fit and test on the features
model.fit(X, y)
model_pred = model.predict(X_test)
# Find the residuals
residuals = abs(model_pred - y_test)
# Extract the most wrong prediction
wrong = X_test[np.argmax(residuals), :]
print('Prediction: %0.4f' % np.argmax(residuals))
print('Actual Value: %0.4f' % y_test[np.argmax(residuals)])Prediction: 12.8615
Actual Value: 100.0000
Затем создадим объясняющий объект (explainer) и передадим ему обучающие данные, информацию о режиме, метки для обучающих данных и имена признаков. Теперь можно передать explainer’у данные наблюдений и функцию прогнозирования, а потом попросить объяснить причину ошибочности прогноза.
import lime
# Create a lime explainer object
explainer = lime.lime_tabular.LimeTabularExplainer(training_data = X, mode = 'regression', training_labels = y, feature_names = feature_list)
# Explanation for wrong prediction
exp = explainer.explain_instance(data_row = wrong, predict_fn = model.predict)
# Plot the prediction explaination
exp.as_pyplot_figure();Диаграмма объяснения прогноза:
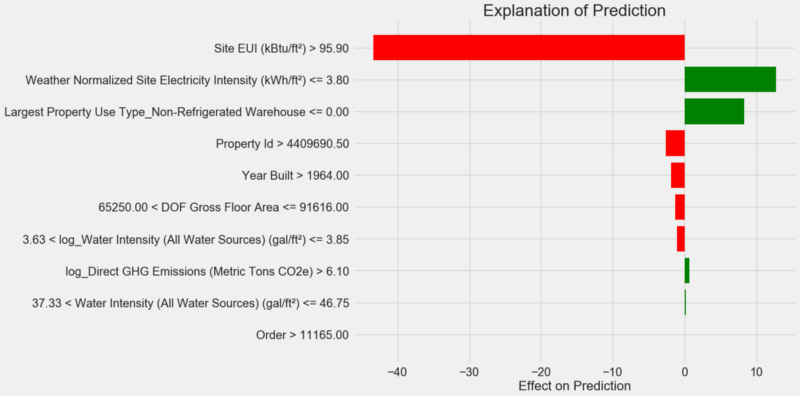
Как интерпретировать диаграмму: каждая запись по оси Y обозначает одно значение переменной, а красные и зелёные полосы отражают влияние этого значения на прогноз. Например, согласно верхней записи влияние
Site EUI больше 95,90, в результате из прогноза вычитается около 40 пунктов. Согласно второй записи влияние Weather Normalized Site Electricity Intensity меньше 3,80, и поэтому к прогнозу прибавляется около 10 пунктов. Итоговый прогноз представляет собой сумму интерсепта и влияний каждого из перечисленных значений.Давайте посмотрим на это с другой стороны и вызовем метод
.show_in_notebook():# Show the explanation in the Jupyter Notebook
exp.show_in_notebook()

Слева показан процесс принятия решения моделью: визуально отображено влияние на прогноз каждой переменной. В таблице справа приведены фактические значения переменных для заданного измерения.
В данном случае модель спрогнозировала около 12 баллов, а на самом деле было 100. Поначалу вы можете недоумевать, почему так произошло, но если проанализировать объяснение, то оказывается, что это не крайне смелое предположение, а результат расчёта на основе конкретных значений. Значение
Site EUI было относительно высоким и можно было ожидать низкого балла Energy Star Score (потому что на него сильно влияет EUI), что наша модель и сделала. Но в данном случае эта логика оказалась ошибочной, потому что по факту здание получило наивысший балл Energy Star Score — 100.Ошибки модели могут вас расстраивать, но подобные объяснения помогут понять, почему модель ошиблась. Более того, благодаря объяснениям можно начать раскапывать, почему здание получило высший балл несмотря на высокое значение Site EUI. Возможно, мы узнаем что-то новое о нашей задаче, что ускользнуло бы от нашего внимания, не начни мы анализировать ошибки модели. Подобные инструменты не идеальны, но они могут сильно облегчить понимание работы модели и принимать более правильные решения.
Документирование работы и представление результатов
Во многих проектах уделяется мало внимания документации и отчётам. Можно сделать лучший анализ в мире, но если не представить результаты должным образом, они не будут иметь значения!
Документируя проект по анализу данных, мы упаковываем все версии данных и код, чтобы проект могли воспроизвести или собрать другие люди. Помните, что код читают чаще, чем пишут, поэтому наша работа должна быть понятна и другим людям, и нам, если мы вернёмся к ней через несколько месяцев. Поэтому вставляйте в код полезные комментарии и объясняйте свои решения. Блокноты Jupyter Notebook — прекрасный инструмент для документирования, они позволяют сначала объяснять решения, а потом показывать код.
Также Jupyter Notebook хорошая платформа для взаимодействия с другими специалистами. С помощью расширений для блокнотов можно скрыть код из финального отчёта, поскольку, как бы вам ни было трудно в это поверить, не все хотят видеть кучу кода в документе!
Возможно, вам захочется не делать выжимку, а показать все подробности. Однако важно понимать свою аудиторию, когда представляешь свой проект, и соответствующим образом составить отчёт. Вот пример краткого изложения сути нашего проекта:
- С помощью данных об энергопотреблении зданий в Нью-Йорке можно построить модель, прогнозирующую количество баллов Energy Star Score с погрешностью в пределах 9,1 пункта.
- Site EUI и Weather Normalized Electricity Intensity — главные факторы, влияющие на прогноз.
Подробное описание и выводы мы написали в Jupyter Notebook, но вместо PDF преобразовали в Latex .tex-файл, который затем отредактировали в texStudio, и получившийся вариант преобразовали в PDF. Дело в том, что результат экспорта по умолчанию из Jupyter в PDF выглядит вполне прилично, но его можно сильно улучшить всего за несколько минут редактирования. К тому же Latex — мощная система подготовки документов, которой полезно владеть.
В конечном счёте, ценность нашей работы определяется решениями, которые она помогает принять, и очень важно уметь «подать товар лицом». Правильно документируя, мы помогаем другим людям воспроизвести наши результаты и дать нам обратную связь, что позволит нам стать опытнее и в дальнейшем опираться на полученные результаты.
Выводы
В нашей серии публикаций мы разобрали от начала до конца учебный проект по машинному обучению. Начали с очистки данных, затем создали модель, и в конце научились её интерпретировать. Напомним общую структуру проекта по машинному обучению:
- Очистка и форматирование данных.
- Разведочный анализ данных.
- Конструирование и выбор признаков.
- Сравнение метрик нескольких моделей машинного обучения.
- Гиперпараметрическая настройка лучшей модели.
- Оценка лучшей модели на тестовом наборе данных.
- Интерпретирование результатов работы модели.
- Выводы и хорошо задокументированный отчёт.
Набор этапов может меняться в зависимости от проекта, и машинное обучение зачастую процесс итеративный, а не линейный, так что это руководство поможет вам в будущем. Надеемся, вы теперь сможете уверенно реализовать свои проекты, но помните: никто не действует в одиночку! Если вам нужна помощь, есть множество очень полезных сообществ, где вам дадут советы.
Эти источники могут помочь вам:
- Hands-On Machine Learning with Scikit-Learn and Tensorflow (Jupyter Notebook для этой книги доступны для скачивания бесплатно)!
- An Introduction to Statistical Learning
- Kaggle: The Home of Data Science and Machine Learning
- Datacamp: хорошие руководства для практики в программировании анализа данных.
- Coursera: бесплатные и платные курсы по многим темам.
- Udacity: платные курсы по программированию и анализу данных.

{kind=link}