
Как вообще понять состояние чего-либо?
Можно положиться на свое мнение, сформированное из разных источников информации, например, публикаций на сайтах или опыта. Можно спросить у коллег, знакомых. Еще вариант — посмотреть на темы конференций: программный комитет — это активные представители индустрии, поэтому мы им доверяем в выборе актуальных тем. Отдельное направление — это исследования и отчеты. Но есть проблема. Исследования состояния DevOps ежегодно проводятся в мире, отчеты публикуются зарубежными компаниями и о российском DevOps информации там почти нет.
Но настал тот день, когда такое исследование провели, и мы сегодня расскажем про полученные результаты. Состояние DevOps в России исследовали совместно компании «Экспресс 42» и «Онтико». Компания «Экспресс 42» помогает технологическим компаниям внедрять и развивать DevOps практики и инструменты и одна из первых начала рассказывать про DevOps в России. Авторы исследования — Игорь Курочкин и Виталий Хабаров занимаются в компании «Экспресс 42» анализом и консалтингом, имея при этом технический бэкграунд из эксплуатации и опыт работы в разных компаниях. За 8 лет коллеги посмотрели десятки компаний и проектов — от стартапа до энтерпрайза — с разными проблемами, а также разной культурной и инженерной зрелостью.
В своем докладе Игорь и Виталий рассказали, какие проблемы были в процессе исследования, как они их решили, а также о том, как в принципе проводятся исследования DevOps и почему «Экспресс 42» решили провести свое. Их отчет можно посмотреть здесь.

Разговор начал Игорь Курочкин.
Мы регулярно задаем вопрос аудитории на DevOps конференциях: «Читали ли вы отчет состояния DevOps за этот год?» Поднимают руки единицы, а наше исследование показало, что только треть изучают их. Если вы никогда не видели такие отчеты, скажем сразу, что все они очень похожи. Чаще всего там встречаются фразы типа: «По сравнению с прошлым годом …»
Тут у нас возникла первая проблема, а за ней ещё две:
Давайте посмотрим, как вообще проводились анализы состояний DevOps в мире.
Исследования DevOps проводятся с 2011 года. Первой их провела компания Puppet — разработчик систем управления конфигурацией. На тот момент это был один из основных инструментов для описания инфраструктуры в виде кода. До 2013 года эти исследования были просто в виде опросов в закрытом формате и без публичных отчетов.
В 2013 году появилась компания IT Revolution, издатель всех основных книг по DevOps. Они вместе с Puppet подготовили первую публикацию «State of DevOps», там впервые появились 4 ключевые метрики. В следующем году подключилась консалтинговая компания ThoughtWorks, известная своими регулярными технологическими радарами по практикам и инструментам в индустрии. А в 2015 году добавился раздел с методологией, и стало понятно, как они выполняют анализ.
В 2016 году авторы исследования, создав свою компанию DORA (DevOps Research and Assessment), опубликовали ежегодный отчет. В следующем году DORA и Puppet последний раз выпустили совместный отчет.
А дальше началось интересное:

В 2018 году компании разделились и вышло два независимых отчета: один — от компании Puppet, второй — от компании DORA совместно с Google. DORA продолжила использовать свою методологию с ключевыми метриками, профилями производительности и инженерными практиками, которые влияют на ключевые метрики и производительность всей компании. А Puppet предложил свой подход с описанием процесса и эволюцией DevOps. Но история не прижилась, в 2019 году Puppet от этой методологии отказался и выпустил новую версию отчетов, в которой перечислил ключевые практики и как они влияют на DevOps с их точки зрения. Тогда же произошло еще одно событие: Google купила DORA, и вместе они выпустили еще один отчет. Возможно, вы его видели.
В этом году всё стало сложно. Известно, что Puppet запустил свой опрос. Они это сделали на неделю раньше, чем мы, и он уже завершился. Мы приняли в нем участие и посмотрели, какие темы их интересуют. Сейчас Puppet выполняет свой анализ и готовит публикацию отчета.
А вот анонса от DORA и Google до сих пор нет. В мае, когда обычно начинался опрос, пришла информация, что Николь Форсгрен, одна из основателей компании DORA, перешла в другую компанию. Поэтому мы предположили, что в этом году исследований и отчета от DORA не будет.
У нас исследований по DevOps не проводилось. Мы выступали на конференциях, пересказывая чужие выводы и Райффайзенбанк перевел «State of DevOps» за 2019 год (вы можете найти их анонс на Хабре), большое им спасибо. И это всё.
Поэтому мы провели собственное исследование в России, используя методологии и выводы DORA. Мы использовали отчет коллег из Райффайзенбанка для своего исследования, в том числе и для синхронизации терминологии и перевода. А актуальные для индустрии вопросы взяли из отчетов DORA и опросника Puppet этого года.
Отчет – это только финальная часть. Весь процесс исследования состоит из четырех больших этапов:
На этапе подготовки мы опросили экспертов из индустрии и подготовили список гипотез. На их основе составили вопросы и запустили опрос на весь август. Потом мы проанализировали и подготовили сам отчет. У DORA этот процесс занимает 6 месяцев. Мы уложились в 3 месяца, и сейчас понимаем, что времени нам едва хватило: только выполняя анализ ты понимаешь, какие вопросы нужно задавать.
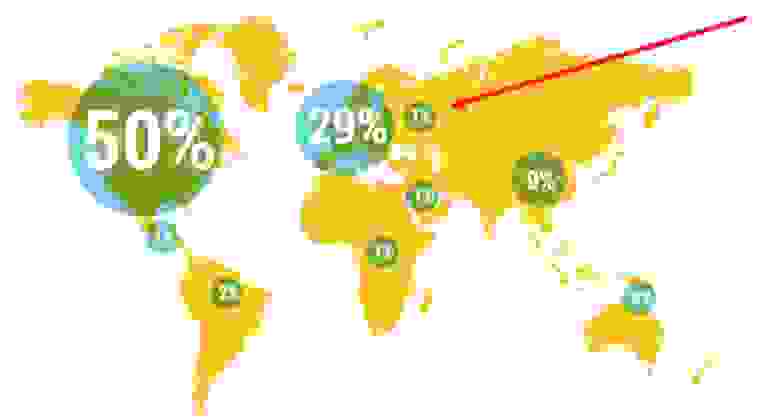
Все зарубежные отчеты начинаются с портрета участников, и большинство из них — не из России. Процент российских респондентов плавает от 5 до 1% из года в год, и это не позволяет сделать какие-либо выводы.
Карта из отчета Accelerate State of DevOps 2019:
В нашем исследовании у нас получилось опросить 889 человек — это достаточно много (DORA в своих отчетах ежегодно опрашивает около тысячи человек) и здесь мы достигли цели:
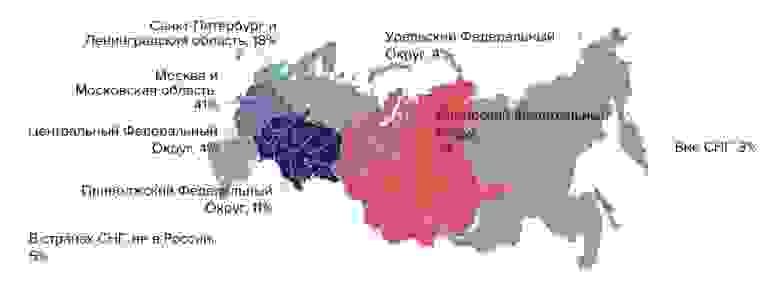
Правда, не все наши участники дошли до конца: процент заполнения получился чуть меньше половины. Но и этого хватило для получения репрезентативной выборки и проведения анализа. DORA в своих отчетах не раскрывает процента заполнения, поэтому здесь сравнить не получится.
Наши респонденты представляют десяток отраслей. Половина работает в сфере информационных технологий. Далее следуют финансовые услуги, торговля, телекоммуникации и другие. Среди должностей это специалисты (разработчик, тестировщик, инженер эксплуатации) и управляющий состав (руководители команд, групп, направлений, директора):
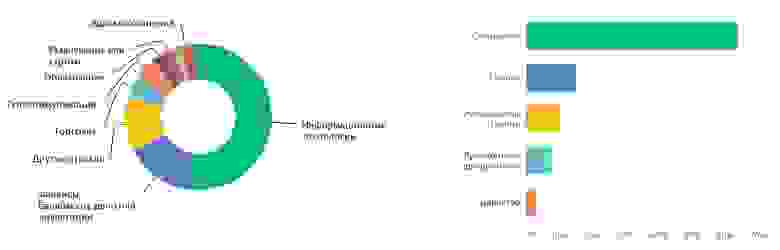
Каждый второй работает в компании среднего размера. В крупных компаниях работает каждый третий. Большинство работают в командах до 9 человек. Отдельно мы спрашивали про основные активности, и большинство так или иначе связано с эксплуатацией, а разработкой занимается около 40%:
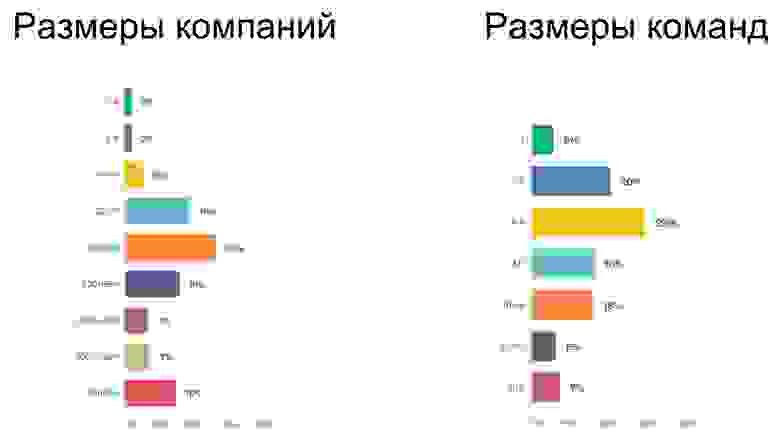
Так мы собрали информацию для сравнения и анализа представителей разных отраслей, компаний, команд. Про анализ расскажет мой коллега Виталий Хабаров.
Виталий Хабаров: Большое спасибо всем участникам, которые прошли наш опрос, заполнили анкеты и дали нам данные для дальнейшего анализа и проверки наших гипотез. А благодаря нашим клиентам и заказчикам у нас есть богатый опыт, который помог определить волнующие индустрию вопросы и сформулировать гипотезы, которые мы проверили в нашем исследовании.
К сожалению, нельзя просто взять список вопросов с одной стороны и данные — с другой, как-то их сопоставить, сказать: «Да, все так и работает, мы были правы» и разойтись. Нет, нужна методология и статистические методы, чтобы быть уверенным, что мы не ошиблись и наши выводы достоверны. Тогда мы можем на основе этих данных строить нашу дальнейшую работу:

За основу мы взяли методологию DORA, которую они подробно описали в книге «Accelerate State of DevOps». Мы проверили, а подходят ли ключевые метрики для российского рынка, можно ли их использовать так же, как использует DORA, чтобы ответить на вопрос: «Насколько индустрия в России соответствует зарубежной индустрии?»
Ключевые метрики:
DORA в своих исследованиях нашла связь между этими метриками и организационной эффективностью. Мы ее тоже проверяем в нашем исследовании.
Но чтобы убедиться, что четыре ключевые метрики могут на что-то влиять, нужно понять — а между собой они как-то связаны? DORA ответила утвердительно с одной оговоркой: связь между неуспешными изменениями (Change Failure Rate) и тремя другими метриками чуть слабее. У нас получилась примерно такая же картина. Если срок поставки, частота развертывания и время восстановления между собой коррелируют (мы установили эту корреляцию через корреляцию Пирсона и через шкалу Чеддока), то с неуспешными изменениями такой сильной корреляции нет.
В принципе, большая часть респондентов склонна отвечать, что у них довольно-таки малое количество инцидентов происходит на продакшене. Хотя в дальнейшем мы увидим, что между группами респондентов все равно есть значимая разница по показателю неуспешных изменений, для этого разделения мы пока не можем использовать эту метрику.
Мы это связываем с тем, что (как выяснилось в процессе анализа и общения с некоторыми нашими заказчиками) есть небольшая разница в восприятии, что считать инцидентом. Если мы успели восстановить работоспособность нашего сервиса во время технического окна — можно ли считать это инцидентом? Наверное, нет, потому что мы все исправили, мы — молодцы. Можно ли считать инцидентом, если нам пришлось в нормальном, привычном для нас режиме 10 раз перевыкатить наше приложение? Кажется, нет. Поэтому вопрос взаимосвязи неуспешных изменений с другими метриками остается открытым. Мы будем уточнять его в дальнейшем.
Здесь важно, что мы нашли значимую корреляцию между сроками поставки, временем восстановления и частотой развертывания. Поэтому эти три метрики мы взяли для дальнейшего разделение респондентов на группы по производительности.
Мы использовали иерархический кластерный анализ:
Так мы группируем всех наших респондентов в нужное нам количество кластеров. С помощью дендрограммы (дерево связей между кластерами) мы видим расстояние между двумя соседними кластерами. Всё, что нам остается — установить некий лимит расстояния между этими кластерами и сказать: «Эти две группы между собой достаточно различимы потому, что расстояние между ними гигантское».
Но здесь есть скрытая проблема: у нас нет ограничений на количество кластеров — можем получить 2, 3, 4, 10 кластеров. И первой идеей было — почему бы не делить всех наших респондентов на 4 группы, как это делает DORA. Но выяснили, что различия между этими группами становятся незначительными, и мы не можем быть уверены, что респондент действительно принадлежит своей группе, а не соседней. Российский рынок мы пока не можем разделить на четыре группы. Поэтому мы остановились именно на трех профилях, между которыми есть статистически значимое различие:

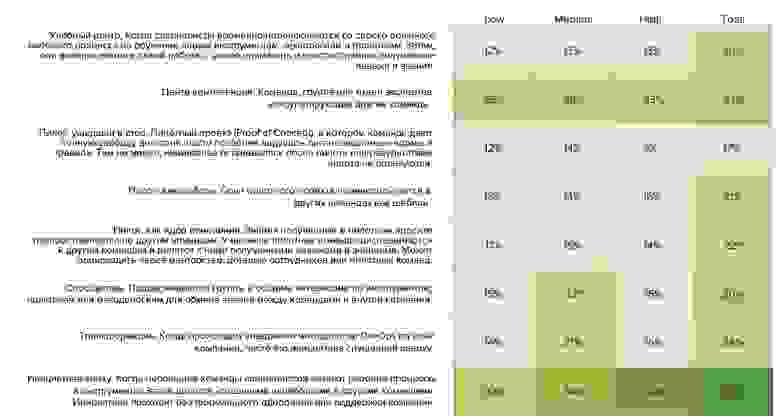
Дальше мы по кластерам определили профиль: мы взяли медианы для каждой метрики по каждой группе и составили табличку профилей эффективности. Фактически получились профили эффективности среднего участника каждой группы. Мы выделили три профиля эффективности: Low, Medium, High:

Здесь мы подтвердили нашу гипотезу о том, что 4 ключевые метрики подходят для определения профиля эффективности, и они работают как на западном, так и на российском рынке. Разница между группами есть, и она статистически значима. Подчеркну, что между профилями эффективности по метрике неуспешных изменений есть значимая разница по среднему, даже несмотря на то, что мы изначально не делили респондентов по этому параметру.
Дальше возникает вопрос: как всем этим пользоваться?
Если взять любую команду, 4 ключевые метрики и применить к таблице, то в 85% случаев мы не получим полного совпадения — это всего лишь средний участник, а не то, что есть в реальности. Мы все (и каждая команда) чуть-чуть отличаемся.
Мы проверили: взяли наших респондентов и профиль эффективности DORA, и посмотрели, сколько респондентов соответствуют тому или иному профилю. Мы получили, что всего лишь 16% респондентов точно попали в один из профилей. Все остальные разбросаны где-то посередине между ними:
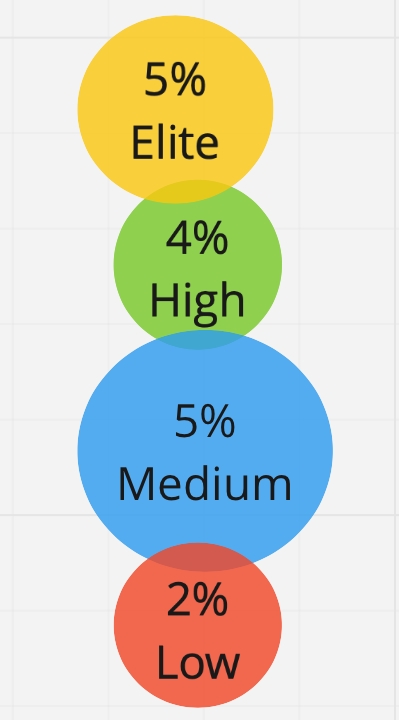
Это значит, что у профиля эффективности есть ограниченная область применения. Для понимания, где вы находитесь в первом приближении, можно использовать эту таблицу: «О, кажется, мы ближе к Medium или High!» Если вы понимаете, куда вам двигаться дальше, этого может хватить. Но если ваша цель — постоянное, непрерывное улучшение, и вы хотите более точно знать, куда развиваться и что делать, то нужны дополнительные средства. Мы их назвали калькуляторы:
Зачем они нужны? Чтобы понять:
Еще вы с их помощью можете собрать статистику внутри компании:
И тогда вы можете выяснить, что внутри нашей компании есть необходимые экспертиза и инструменты для тех команд, которые пока еще не дотягивают.
Или, если вы понимаете, что внутри компании вы чувствуете себя замечательно, вы лучше многих, — то можно взглянуть чуть шире. Это как раз российская индустрия: можем ли мы получить необходимую экспертизу в российской индустрии, чтобы ускориться самим? Здесь поможет калькулятор Экспресс 42 (он в процессе разработки). Если вы переросли российский рынок, то смотрите на калькулятор DORA и на мировой рынок.
Хорошо. А если вы находитесь в группе Elit по калькулятору DORA, то что делать? Хорошего решения тут нет. Скорее всего вы находитесь на передовой индустрии, и дальнейшее ускорение и повышение надежности возможны за счет внутреннего R&D и трат больших ресурсов.
Перейдем к самому сладкому — сравнению.
Мы изначально хотели сравнить российскую индустрию с западной индустрией. Если сравнивать напрямую, то видим, что у нас меньше профилей, и они чуть больше перемешаны между собой, границы чуть более размыты:
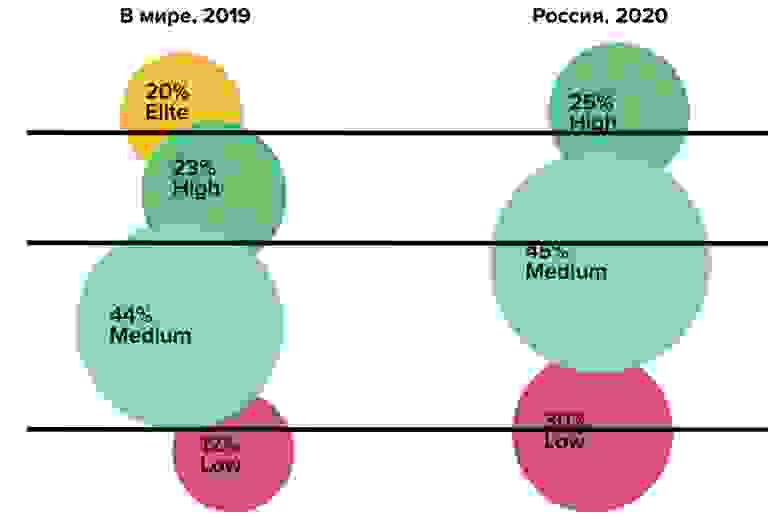
Наши Elite-перформеры скрыты среди High-перформеров, но они есть — это элита, единороги, которые достигли значимых высот. В России разница между профилем Elite и профилем High пока недостаточно значима. Мы думаем, что в будущем это разделение произойдёт в связи с повышением инженерной культуры, качества внедрения инженерных практик и экспертизы внутри компаний.
Если переходить к прямому сравнению внутри российской индустрии, то мы видим, что команды профиля High лучше по всем показателям. Также мы подтвердили нашу гипотезу о том, что есть связь между этими метриками и организационной эффективностью: команды профиля High значительно чаще не только достигают целей, но и превосходят их.
Давайте становиться командами профиля High и не останавливаться на достигнутом:
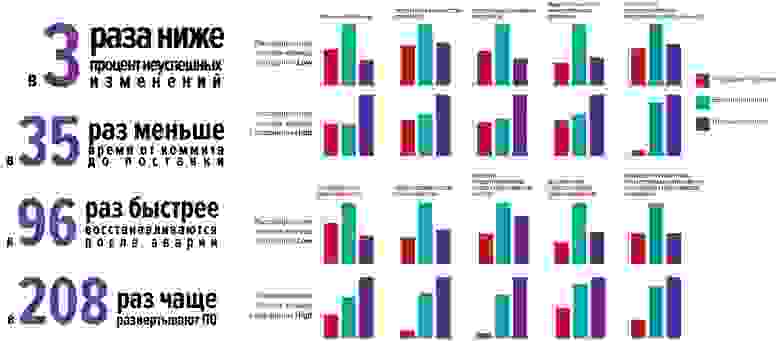
Но этот год особенный, и мы решили еще проверить, как компании живут в условиях пандемии: команды профиля High значительно лучше справляются и чувствуют себя лучше, чем в среднем по индустрии:
То есть те компетенции, которые у них уже были, помогли им развиваться быстрее, выводить новые продукты, модифицировать уже существующие продукты, тем самым завоевывая новые рынки и новых пользователей:
Что еще помогло нашим командам?

Расскажу про значимые находки по каждой практике, которые мы проверили. Возможно, что-то еще помогло командам, но мы говорим про DevOps. И в рамках DevOps мы видим различие среди команд разных профилей.
Мы не обнаружили значимой связи между возрастом платформы и профилем команды: Платформы появились примерно в одно и то же время и у Low-команд, и у High-команд. Но у последних платформа предоставляет в среднем больше сервисов и больше программных интерфейсов для управления через программный код. А платформенные команды чаще помогают своим разработчикам и командам пользоваться платформой, чаще решают их проблемы и инциденты, связанные с платформой, и обучают другие команды.
Здесь все довольно стандартно. Мы нашли взаимосвязь между автоматизацией работы инфраструктурного кода и тем, сколько информации хранится внутри инфраструктурного репозитория. Команды профиля High хранят в репозиториях больше информации: это и конфигурация инфраструктуры, CI/CD пайплайна, настройки окружений и параметры сборки. Они чаще хранят эту информацию, лучше работают с инфраструктурным кодом и автоматизировали больше процессов и задач по работе с инфраструктурным кодом.
Интересно, что мы не увидели значимой разницы по инфраструктурным тестам. Я связываю это с тем, что у команд профиля High в целом больше автоматизации тестирования. Возможно, им не стоит отвлекаться отдельно на инфраструктурные тесты, а достаточно тех тестов, которыми они проверяют приложения, и благодаря им уж видят, что и где у них сломалось.
Самый скучный раздел, потому что мы подтвердили: чем больше у вас автоматизации, чем лучше вы работаете с кодом, тем вероятнее получаете лучшие показатели.
Мы хотели посмотреть, насколько микросервисы влияют на производительность. Если по правде — не влияют, так как применение микросервисов не связано с повышением показателей эффективности. Микросервисы применяются как у команд профиля High, так и у команд профиля Low.
Но значимо то, что для High-команд переход на микросервисную архитектуру позволяет им независимо разрабатывать свои сервисы и выкатываться. Если архитектура позволяет разработчикам действовать автономно, не ждать кого-то внешнего по отношению к команде, то это является ключевой компетенцией для повышения скорости. В этом случае микросервисы помогают. А просто их внедрение большой роли не играет.
У нас был амбициозный план полностью воспроизвести методологию DORA, но не хватило ресурсов. Если DORA использует большую спонсорскую поддержку и исследование у них занимает полгода, свое исследование мы провели в сжатые сроки. Мы хотели построить модель DevOps, как это делает DORA, и мы сделаем это в будущем. Пока мы ограничились тепловыми картами:

Мы посмотрели, какое распределение инженерных практик у команд каждого профиля, и обнаружили, что команды профиля High в среднем чаще применяют инженерные практики. Обо всем этом можно подробнее прочитать в нашем отчете.
Для разнообразия переключимся со сложной статистики на простую.
Мы наблюдаем, что больше всего команд использует ОС семейства Linux. Но Windows всё еще в тренде — не менее четверти наших респондентов отметили использование той или иной его версии. Кажется, что у рынка есть эта потребность. Поэтому вы можете развивать данные компетенции и выступать с докладами на конференциях.
Среди оркестраторов, ни для кого не секрет, лидирует Kubernetes (52%). Следующий по очереди оркестратор — Docker Swarm (около 12%). Наиболее популярные CI-системы — Jenkins и GitLab. Наиболее популярная система управления конфигурацией — Ansible, а за ним — наш с вами любимый Shell.
Среди облачных хостингов пока лидирующее положение занимает Amazon. Доля российских облаков постепенно наращивается. В следующем году будет интересно посмотреть, как российские облачные провайдеры будут себя чувствовать, повысится ли их доля рынка. Они есть, ими можно пользоваться, и это хорошо:
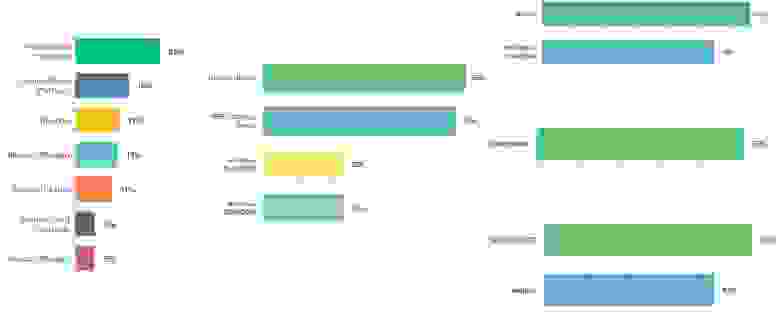
Передаю слово Игорю, который даст еще немного статистики.
Игорь Курочкин: Отдельно мы просили респондентов указать, как рассмотренные инженерные практики распространяются в компании. В большинстве компаний наблюдается смешанный подход, состоящий из разного набора паттернов, а пилотные проекты пользуются большой популярностью. Также мы увидели небольшую разницу между профилями. Представители профиля High чаще используют паттерн «Инициатива снизу», когда небольшие команды специалистов меняют рабочие процессы, инструменты, делятся успешными наработками с другими командами. В Medium это — инициатива сверху, затрагивающая всю компанию созданием сообществ и центров компетенций:
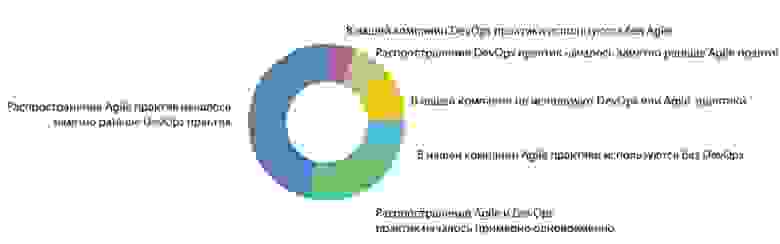
Вопрос о связи Agile и DevOps часто обсуждается в индустрии. Этот вопрос поднимается и в отчете State of Agile Report за 2019/2020 год, поэтому мы решили сравнить как связаны Agile и DevOps активности в компаниях. Мы выяснили, что DevOps без Agile встречается редко. У половины респондентов распространение Agile началось заметно раньше, а одновременное начало наблюдали около 20%, а одним из признаков Low-профиля будет отсутствие Agile и DevOps практик:
В конце прошлого года вышла книга «Team topologies», в которой предложен фреймворк для описания командных топологий. Нам стало интересно, а применим ли он к российским компаниям. И мы задали вопрос: «Какие паттерны встречаются у вас?».
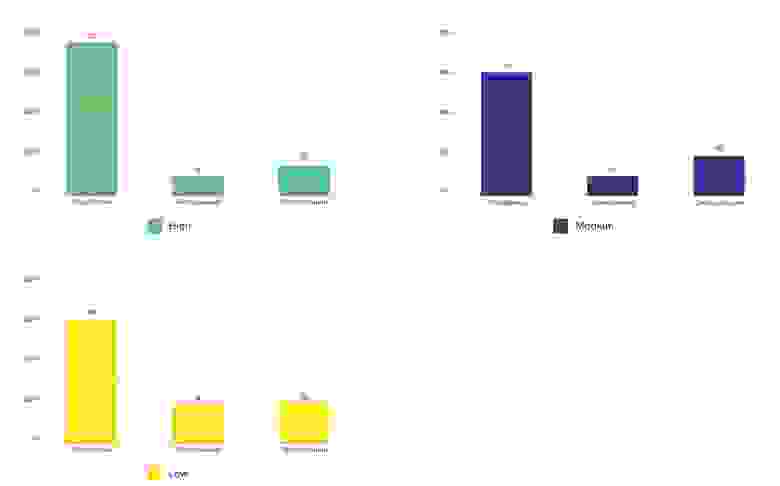
Инфраструктурные команды наблюдаются у половины респондентов, также, как и отдельные команды разработки, тестирования и эксплуатации. Отдельные DevOps команды отметили 45%, среди которых представители High встречаются чаще. Следом идут кроссфункциональные команды, которые также чаще встречаются у High. Отдельные команды SRE появляются в профилях High, Medium и редко встречаются у профиля Low:

Этот вопрос мы увидели в FaceBook у тимлида платформенной команды Skyeng — его интересовало соотношение разработчиков, тестировщиков и администраторов в компаниях. Мы задали его и посмотрели на ответы с учетом профилей: у представителей профиля High на каждого разработчика приходится меньшее число инженеров тестирования и эксплуатации:
В планах на следующий год респонденты отметили следующие активности:
Здесь видно пересечение с конференцией DevOps Live 2020. Мы внимательно ознакомились с программой:
Но времени нашего выступления не хватит, чтобы рассмотреть все темы. За кадром осталось:
Отчет у нас получился объемным, на 50 страниц, и вы можете посмотреть его более подробно.
Мы надеемся, что наше исследование и отчет вдохновят вас на эксперименты с использованием новых подходов к разработке, тестированию и эксплуатации, а также помогут вам сориентироваться, сравнить себя с другими участниками исследования и определить области, в которых вы можете улучшить собственные подходы.
Результаты первого исследования состояния DevOps в России:
Будем рады услышать ваши отзывы, истории, обратную связь. Благодарим всех, кто участвовал в исследовании, и надеемся на ваше участие в следующем году.
Можно положиться на свое мнение, сформированное из разных источников информации, например, публикаций на сайтах или опыта. Можно спросить у коллег, знакомых. Еще вариант — посмотреть на темы конференций: программный комитет — это активные представители индустрии, поэтому мы им доверяем в выборе актуальных тем. Отдельное направление — это исследования и отчеты. Но есть проблема. Исследования состояния DevOps ежегодно проводятся в мире, отчеты публикуются зарубежными компаниями и о российском DevOps информации там почти нет.
Но настал тот день, когда такое исследование провели, и мы сегодня расскажем про полученные результаты. Состояние DevOps в России исследовали совместно компании «Экспресс 42» и «Онтико». Компания «Экспресс 42» помогает технологическим компаниям внедрять и развивать DevOps практики и инструменты и одна из первых начала рассказывать про DevOps в России. Авторы исследования — Игорь Курочкин и Виталий Хабаров занимаются в компании «Экспресс 42» анализом и консалтингом, имея при этом технический бэкграунд из эксплуатации и опыт работы в разных компаниях. За 8 лет коллеги посмотрели десятки компаний и проектов — от стартапа до энтерпрайза — с разными проблемами, а также разной культурной и инженерной зрелостью.
В своем докладе Игорь и Виталий рассказали, какие проблемы были в процессе исследования, как они их решили, а также о том, как в принципе проводятся исследования DevOps и почему «Экспресс 42» решили провести свое. Их отчет можно посмотреть здесь.

Исследования DevOps
Разговор начал Игорь Курочкин.
Мы регулярно задаем вопрос аудитории на DevOps конференциях: «Читали ли вы отчет состояния DevOps за этот год?» Поднимают руки единицы, а наше исследование показало, что только треть изучают их. Если вы никогда не видели такие отчеты, скажем сразу, что все они очень похожи. Чаще всего там встречаются фразы типа: «По сравнению с прошлым годом …»
Тут у нас возникла первая проблема, а за ней ещё две:
- У нас нет данных за прошлый год. Состояние DevOps в России никому не интересно;
- Методология. Непонятно, как проверять гипотезы, как строить вопросы, как проводить анализ, сравнивать результаты, находить связи;
- Терминология. Все отчеты на английском языке, требуется перевод, общего фреймворка по DevOps еще не изобрели и каждый придумывает свое.
Давайте посмотрим, как вообще проводились анализы состояний DevOps в мире.
Историческая справка
Исследования DevOps проводятся с 2011 года. Первой их провела компания Puppet — разработчик систем управления конфигурацией. На тот момент это был один из основных инструментов для описания инфраструктуры в виде кода. До 2013 года эти исследования были просто в виде опросов в закрытом формате и без публичных отчетов.
В 2013 году появилась компания IT Revolution, издатель всех основных книг по DevOps. Они вместе с Puppet подготовили первую публикацию «State of DevOps», там впервые появились 4 ключевые метрики. В следующем году подключилась консалтинговая компания ThoughtWorks, известная своими регулярными технологическими радарами по практикам и инструментам в индустрии. А в 2015 году добавился раздел с методологией, и стало понятно, как они выполняют анализ.
В 2016 году авторы исследования, создав свою компанию DORA (DevOps Research and Assessment), опубликовали ежегодный отчет. В следующем году DORA и Puppet последний раз выпустили совместный отчет.
А дальше началось интересное:

В 2018 году компании разделились и вышло два независимых отчета: один — от компании Puppet, второй — от компании DORA совместно с Google. DORA продолжила использовать свою методологию с ключевыми метриками, профилями производительности и инженерными практиками, которые влияют на ключевые метрики и производительность всей компании. А Puppet предложил свой подход с описанием процесса и эволюцией DevOps. Но история не прижилась, в 2019 году Puppet от этой методологии отказался и выпустил новую версию отчетов, в которой перечислил ключевые практики и как они влияют на DevOps с их точки зрения. Тогда же произошло еще одно событие: Google купила DORA, и вместе они выпустили еще один отчет. Возможно, вы его видели.
В этом году всё стало сложно. Известно, что Puppet запустил свой опрос. Они это сделали на неделю раньше, чем мы, и он уже завершился. Мы приняли в нем участие и посмотрели, какие темы их интересуют. Сейчас Puppet выполняет свой анализ и готовит публикацию отчета.
А вот анонса от DORA и Google до сих пор нет. В мае, когда обычно начинался опрос, пришла информация, что Николь Форсгрен, одна из основателей компании DORA, перешла в другую компанию. Поэтому мы предположили, что в этом году исследований и отчета от DORA не будет.
Как обстоят дела в России?
У нас исследований по DevOps не проводилось. Мы выступали на конференциях, пересказывая чужие выводы и Райффайзенбанк перевел «State of DevOps» за 2019 год (вы можете найти их анонс на Хабре), большое им спасибо. И это всё.
Поэтому мы провели собственное исследование в России, используя методологии и выводы DORA. Мы использовали отчет коллег из Райффайзенбанка для своего исследования, в том числе и для синхронизации терминологии и перевода. А актуальные для индустрии вопросы взяли из отчетов DORA и опросника Puppet этого года.
Процесс исследования
Отчет – это только финальная часть. Весь процесс исследования состоит из четырех больших этапов:
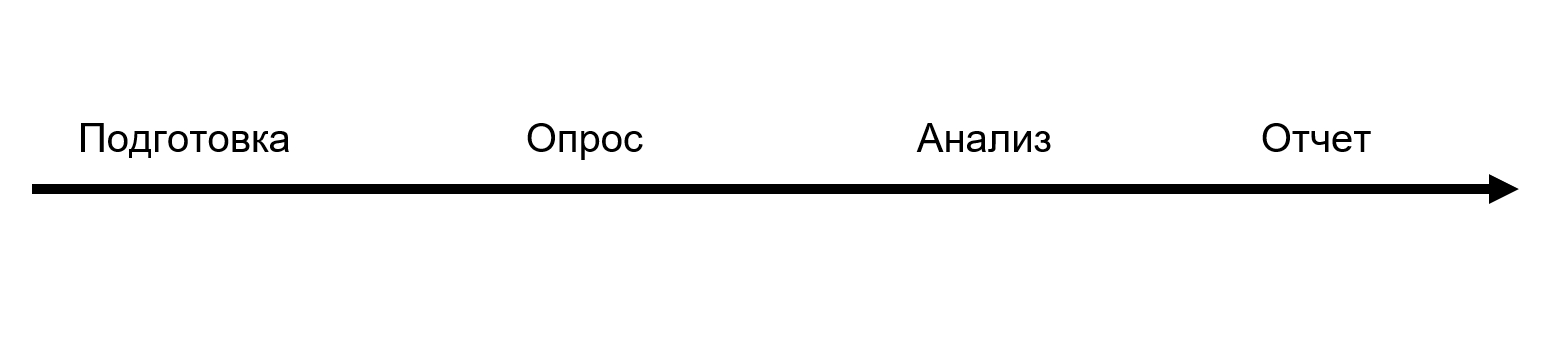
На этапе подготовки мы опросили экспертов из индустрии и подготовили список гипотез. На их основе составили вопросы и запустили опрос на весь август. Потом мы проанализировали и подготовили сам отчет. У DORA этот процесс занимает 6 месяцев. Мы уложились в 3 месяца, и сейчас понимаем, что времени нам едва хватило: только выполняя анализ ты понимаешь, какие вопросы нужно задавать.
Участники
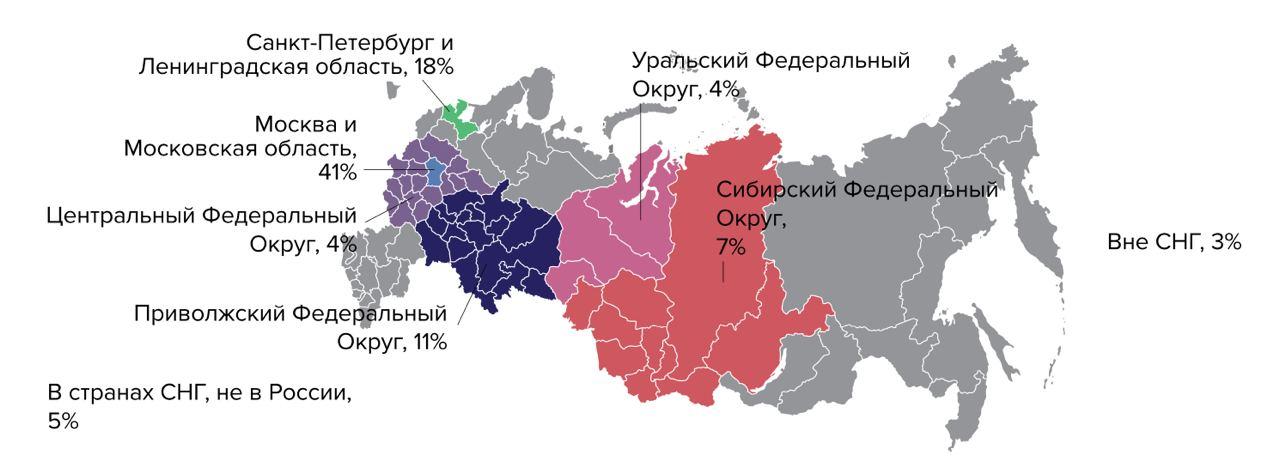
Все зарубежные отчеты начинаются с портрета участников, и большинство из них — не из России. Процент российских респондентов плавает от 5 до 1% из года в год, и это не позволяет сделать какие-либо выводы.
Карта из отчета Accelerate State of DevOps 2019:

В нашем исследовании у нас получилось опросить 889 человек — это достаточно много (DORA в своих отчетах ежегодно опрашивает около тысячи человек) и здесь мы достигли цели:
Правда, не все наши участники дошли до конца: процент заполнения получился чуть меньше половины. Но и этого хватило для получения репрезентативной выборки и проведения анализа. DORA в своих отчетах не раскрывает процента заполнения, поэтому здесь сравнить не получится.
Отрасли и должности
Наши респонденты представляют десяток отраслей. Половина работает в сфере информационных технологий. Далее следуют финансовые услуги, торговля, телекоммуникации и другие. Среди должностей это специалисты (разработчик, тестировщик, инженер эксплуатации) и управляющий состав (руководители команд, групп, направлений, директора):

Каждый второй работает в компании среднего размера. В крупных компаниях работает каждый третий. Большинство работают в командах до 9 человек. Отдельно мы спрашивали про основные активности, и большинство так или иначе связано с эксплуатацией, а разработкой занимается около 40%:

Так мы собрали информацию для сравнения и анализа представителей разных отраслей, компаний, команд. Про анализ расскажет мой коллега Виталий Хабаров.
Анализ и сравнение
Виталий Хабаров: Большое спасибо всем участникам, которые прошли наш опрос, заполнили анкеты и дали нам данные для дальнейшего анализа и проверки наших гипотез. А благодаря нашим клиентам и заказчикам у нас есть богатый опыт, который помог определить волнующие индустрию вопросы и сформулировать гипотезы, которые мы проверили в нашем исследовании.
К сожалению, нельзя просто взять список вопросов с одной стороны и данные — с другой, как-то их сопоставить, сказать: «Да, все так и работает, мы были правы» и разойтись. Нет, нужна методология и статистические методы, чтобы быть уверенным, что мы не ошиблись и наши выводы достоверны. Тогда мы можем на основе этих данных строить нашу дальнейшую работу:

Ключевые метрики
За основу мы взяли методологию DORA, которую они подробно описали в книге «Accelerate State of DevOps». Мы проверили, а подходят ли ключевые метрики для российского рынка, можно ли их использовать так же, как использует DORA, чтобы ответить на вопрос: «Насколько индустрия в России соответствует зарубежной индустрии?»
Ключевые метрики:
- Частота развертываний. Как часто происходит развертывание новой версии приложения на продуктовое окружение (плановых изменений, исключая хотфиксы и реакцию на инциденты)?
- Срок поставки. Сколько в среднем времени проходит между коммитом изменения (написанием функциональности в виде кода) и развертыванием изменения на продуктовом окружении?
- Время восстановления. Сколько в среднем времени занимает восстановление приложения на продуктовом окружении после инцидента, деградации сервиса или обнаружения ошибки, влияющей на пользователей приложения?
- Неуспешные изменения. Какой процент развертываний на продуктовом окружении приводит к деградации приложения или инцидентам и требует устранения последствий (откат изменений, разработку хотфикса или патча)?
DORA в своих исследованиях нашла связь между этими метриками и организационной эффективностью. Мы ее тоже проверяем в нашем исследовании.
Но чтобы убедиться, что четыре ключевые метрики могут на что-то влиять, нужно понять — а между собой они как-то связаны? DORA ответила утвердительно с одной оговоркой: связь между неуспешными изменениями (Change Failure Rate) и тремя другими метриками чуть слабее. У нас получилась примерно такая же картина. Если срок поставки, частота развертывания и время восстановления между собой коррелируют (мы установили эту корреляцию через корреляцию Пирсона и через шкалу Чеддока), то с неуспешными изменениями такой сильной корреляции нет.
В принципе, большая часть респондентов склонна отвечать, что у них довольно-таки малое количество инцидентов происходит на продакшене. Хотя в дальнейшем мы увидим, что между группами респондентов все равно есть значимая разница по показателю неуспешных изменений, для этого разделения мы пока не можем использовать эту метрику.
Мы это связываем с тем, что (как выяснилось в процессе анализа и общения с некоторыми нашими заказчиками) есть небольшая разница в восприятии, что считать инцидентом. Если мы успели восстановить работоспособность нашего сервиса во время технического окна — можно ли считать это инцидентом? Наверное, нет, потому что мы все исправили, мы — молодцы. Можно ли считать инцидентом, если нам пришлось в нормальном, привычном для нас режиме 10 раз перевыкатить наше приложение? Кажется, нет. Поэтому вопрос взаимосвязи неуспешных изменений с другими метриками остается открытым. Мы будем уточнять его в дальнейшем.
Здесь важно, что мы нашли значимую корреляцию между сроками поставки, временем восстановления и частотой развертывания. Поэтому эти три метрики мы взяли для дальнейшего разделение респондентов на группы по производительности.
Сколько вешать в граммах?
Мы использовали иерархический кластерный анализ:
- Распределяем респондентов по n-мерному пространству, где координата каждого респондента — их ответы на вопросы.
- Каждого респондента объявляем маленьким кластером.
- Объединяем два наиболее приближенных друг к другу кластера в один кластер побольше.
- Находим следующую пару кластеров и объединяем их в кластер побольше.
Так мы группируем всех наших респондентов в нужное нам количество кластеров. С помощью дендрограммы (дерево связей между кластерами) мы видим расстояние между двумя соседними кластерами. Всё, что нам остается — установить некий лимит расстояния между этими кластерами и сказать: «Эти две группы между собой достаточно различимы потому, что расстояние между ними гигантское».
Но здесь есть скрытая проблема: у нас нет ограничений на количество кластеров — можем получить 2, 3, 4, 10 кластеров. И первой идеей было — почему бы не делить всех наших респондентов на 4 группы, как это делает DORA. Но выяснили, что различия между этими группами становятся незначительными, и мы не можем быть уверены, что респондент действительно принадлежит своей группе, а не соседней. Российский рынок мы пока не можем разделить на четыре группы. Поэтому мы остановились именно на трех профилях, между которыми есть статистически значимое различие:

Дальше мы по кластерам определили профиль: мы взяли медианы для каждой метрики по каждой группе и составили табличку профилей эффективности. Фактически получились профили эффективности среднего участника каждой группы. Мы выделили три профиля эффективности: Low, Medium, High:

Здесь мы подтвердили нашу гипотезу о том, что 4 ключевые метрики подходят для определения профиля эффективности, и они работают как на западном, так и на российском рынке. Разница между группами есть, и она статистически значима. Подчеркну, что между профилями эффективности по метрике неуспешных изменений есть значимая разница по среднему, даже несмотря на то, что мы изначально не делили респондентов по этому параметру.
Дальше возникает вопрос: как всем этим пользоваться?
Как пользоваться
Если взять любую команду, 4 ключевые метрики и применить к таблице, то в 85% случаев мы не получим полного совпадения — это всего лишь средний участник, а не то, что есть в реальности. Мы все (и каждая команда) чуть-чуть отличаемся.
Мы проверили: взяли наших респондентов и профиль эффективности DORA, и посмотрели, сколько респондентов соответствуют тому или иному профилю. Мы получили, что всего лишь 16% респондентов точно попали в один из профилей. Все остальные разбросаны где-то посередине между ними:
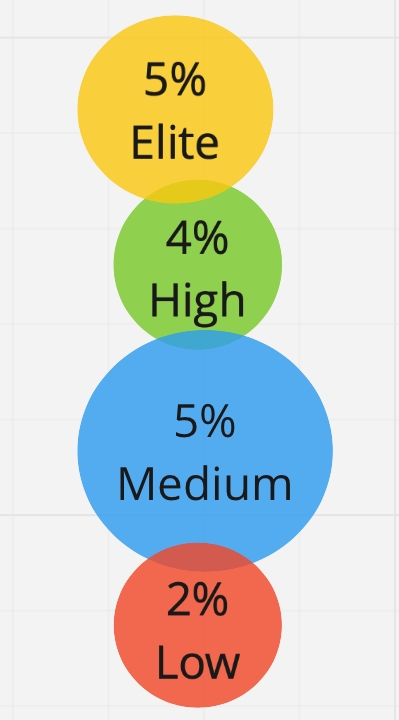
Это значит, что у профиля эффективности есть ограниченная область применения. Для понимания, где вы находитесь в первом приближении, можно использовать эту таблицу: «О, кажется, мы ближе к Medium или High!» Если вы понимаете, куда вам двигаться дальше, этого может хватить. Но если ваша цель — постоянное, непрерывное улучшение, и вы хотите более точно знать, куда развиваться и что делать, то нужны дополнительные средства. Мы их назвали калькуляторы:
- Калькулятор DORA
- Калькулятор Экспресс 42* (в разработке)
- Своя разработка (можно составить свой внутренний калькулятор).
Зачем они нужны? Чтобы понять:
- Команда внутри нашей организации соответствует нашим стандартам?
- Если нет, то можем ли мы ей помочь — ускорить ее в рамках той экспертизы, которая есть в нашей компании?
- Если да, то можем ли сделать еще лучше?
Еще вы с их помощью можете собрать статистику внутри компании:
- Какие у нас команды есть;
- Поделить команды на профили;
- Увидеть: О, эти команды у нас underperforming (немножко не вытягивают), а эти — классные: они деплоят каждый день, без ошибок, lead time у них меньше часа.
И тогда вы можете выяснить, что внутри нашей компании есть необходимые экспертиза и инструменты для тех команд, которые пока еще не дотягивают.
Или, если вы понимаете, что внутри компании вы чувствуете себя замечательно, вы лучше многих, — то можно взглянуть чуть шире. Это как раз российская индустрия: можем ли мы получить необходимую экспертизу в российской индустрии, чтобы ускориться самим? Здесь поможет калькулятор Экспресс 42 (он в процессе разработки). Если вы переросли российский рынок, то смотрите на калькулятор DORA и на мировой рынок.
Хорошо. А если вы находитесь в группе Elit по калькулятору DORA, то что делать? Хорошего решения тут нет. Скорее всего вы находитесь на передовой индустрии, и дальнейшее ускорение и повышение надежности возможны за счет внутреннего R&D и трат больших ресурсов.
Перейдем к самому сладкому — сравнению.
Сравнение
Мы изначально хотели сравнить российскую индустрию с западной индустрией. Если сравнивать напрямую, то видим, что у нас меньше профилей, и они чуть больше перемешаны между собой, границы чуть более размыты:

Наши Elite-перформеры скрыты среди High-перформеров, но они есть — это элита, единороги, которые достигли значимых высот. В России разница между профилем Elite и профилем High пока недостаточно значима. Мы думаем, что в будущем это разделение произойдёт в связи с повышением инженерной культуры, качества внедрения инженерных практик и экспертизы внутри компаний.
Если переходить к прямому сравнению внутри российской индустрии, то мы видим, что команды профиля High лучше по всем показателям. Также мы подтвердили нашу гипотезу о том, что есть связь между этими метриками и организационной эффективностью: команды профиля High значительно чаще не только достигают целей, но и превосходят их.
Давайте становиться командами профиля High и не останавливаться на достигнутом:
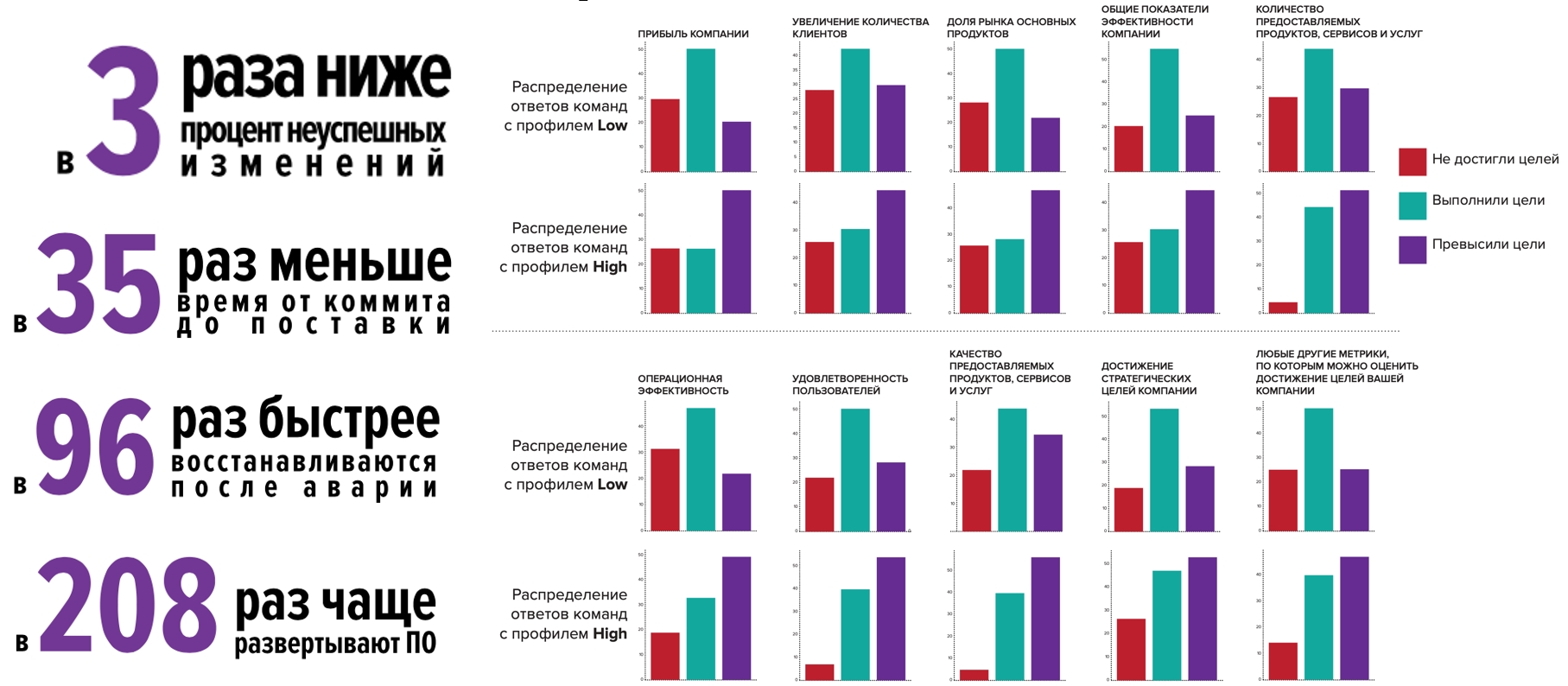
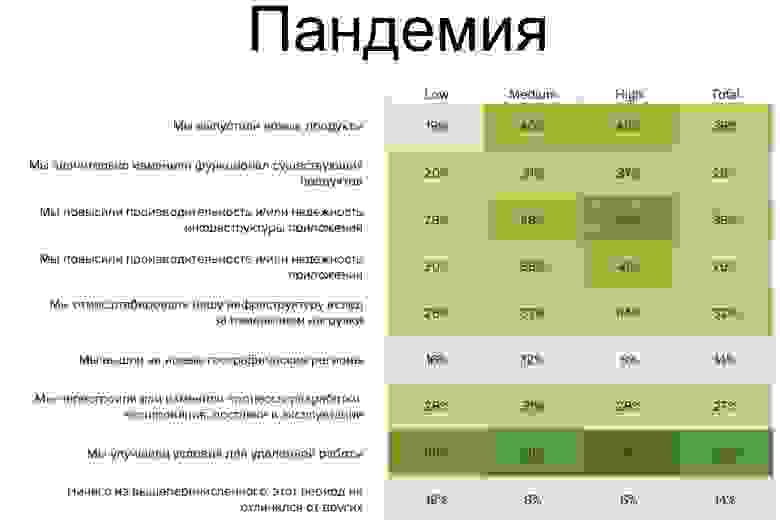
Но этот год особенный, и мы решили еще проверить, как компании живут в условиях пандемии: команды профиля High значительно лучше справляются и чувствуют себя лучше, чем в среднем по индустрии:
- В 1,5-2 раза чаще выпускали новые продукты,
- В 2 раза чаще повышали надежность и/или производительность инфраструктуры приложений.
То есть те компетенции, которые у них уже были, помогли им развиваться быстрее, выводить новые продукты, модифицировать уже существующие продукты, тем самым завоевывая новые рынки и новых пользователей:

Что еще помогло нашим командам?
Инженерные практики

Расскажу про значимые находки по каждой практике, которые мы проверили. Возможно, что-то еще помогло командам, но мы говорим про DevOps. И в рамках DevOps мы видим различие среди команд разных профилей.
Платформа как сервис
Мы не обнаружили значимой связи между возрастом платформы и профилем команды: Платформы появились примерно в одно и то же время и у Low-команд, и у High-команд. Но у последних платформа предоставляет в среднем больше сервисов и больше программных интерфейсов для управления через программный код. А платформенные команды чаще помогают своим разработчикам и командам пользоваться платформой, чаще решают их проблемы и инциденты, связанные с платформой, и обучают другие команды.

Инфраструктура как код
Здесь все довольно стандартно. Мы нашли взаимосвязь между автоматизацией работы инфраструктурного кода и тем, сколько информации хранится внутри инфраструктурного репозитория. Команды профиля High хранят в репозиториях больше информации: это и конфигурация инфраструктуры, CI/CD пайплайна, настройки окружений и параметры сборки. Они чаще хранят эту информацию, лучше работают с инфраструктурным кодом и автоматизировали больше процессов и задач по работе с инфраструктурным кодом.
Интересно, что мы не увидели значимой разницы по инфраструктурным тестам. Я связываю это с тем, что у команд профиля High в целом больше автоматизации тестирования. Возможно, им не стоит отвлекаться отдельно на инфраструктурные тесты, а достаточно тех тестов, которыми они проверяют приложения, и благодаря им уж видят, что и где у них сломалось.
Интеграция и поставка
Самый скучный раздел, потому что мы подтвердили: чем больше у вас автоматизации, чем лучше вы работаете с кодом, тем вероятнее получаете лучшие показатели.
Архитектура
Мы хотели посмотреть, насколько микросервисы влияют на производительность. Если по правде — не влияют, так как применение микросервисов не связано с повышением показателей эффективности. Микросервисы применяются как у команд профиля High, так и у команд профиля Low.
Но значимо то, что для High-команд переход на микросервисную архитектуру позволяет им независимо разрабатывать свои сервисы и выкатываться. Если архитектура позволяет разработчикам действовать автономно, не ждать кого-то внешнего по отношению к команде, то это является ключевой компетенцией для повышения скорости. В этом случае микросервисы помогают. А просто их внедрение большой роли не играет.
Как мы все это обнаружили?
У нас был амбициозный план полностью воспроизвести методологию DORA, но не хватило ресурсов. Если DORA использует большую спонсорскую поддержку и исследование у них занимает полгода, свое исследование мы провели в сжатые сроки. Мы хотели построить модель DevOps, как это делает DORA, и мы сделаем это в будущем. Пока мы ограничились тепловыми картами:

Мы посмотрели, какое распределение инженерных практик у команд каждого профиля, и обнаружили, что команды профиля High в среднем чаще применяют инженерные практики. Обо всем этом можно подробнее прочитать в нашем отчете.
Для разнообразия переключимся со сложной статистики на простую.
Что мы обнаружили ещё?
Инструменты
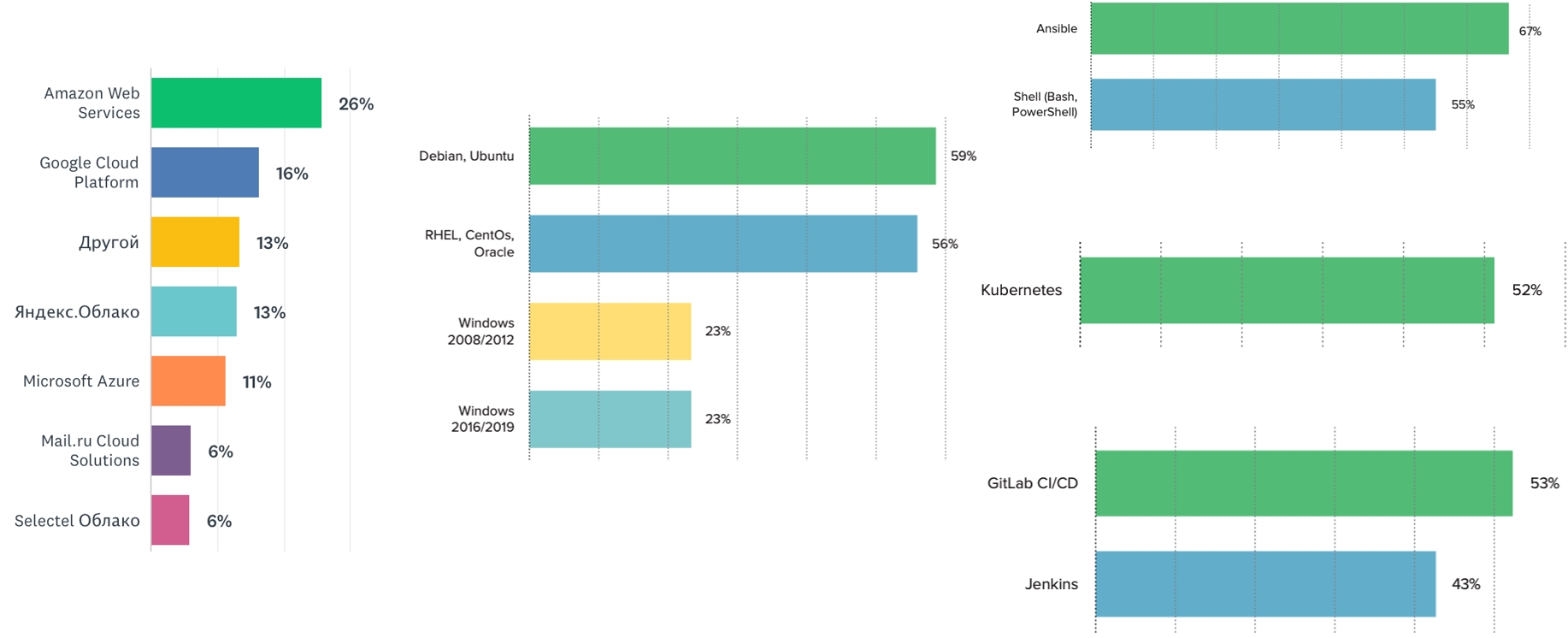
Мы наблюдаем, что больше всего команд использует ОС семейства Linux. Но Windows всё еще в тренде — не менее четверти наших респондентов отметили использование той или иной его версии. Кажется, что у рынка есть эта потребность. Поэтому вы можете развивать данные компетенции и выступать с докладами на конференциях.
Среди оркестраторов, ни для кого не секрет, лидирует Kubernetes (52%). Следующий по очереди оркестратор — Docker Swarm (около 12%). Наиболее популярные CI-системы — Jenkins и GitLab. Наиболее популярная система управления конфигурацией — Ansible, а за ним — наш с вами любимый Shell.
Среди облачных хостингов пока лидирующее положение занимает Amazon. Доля российских облаков постепенно наращивается. В следующем году будет интересно посмотреть, как российские облачные провайдеры будут себя чувствовать, повысится ли их доля рынка. Они есть, ими можно пользоваться, и это хорошо:
Передаю слово Игорю, который даст еще немного статистики.
Распространение практик
Игорь Курочкин: Отдельно мы просили респондентов указать, как рассмотренные инженерные практики распространяются в компании. В большинстве компаний наблюдается смешанный подход, состоящий из разного набора паттернов, а пилотные проекты пользуются большой популярностью. Также мы увидели небольшую разницу между профилями. Представители профиля High чаще используют паттерн «Инициатива снизу», когда небольшие команды специалистов меняют рабочие процессы, инструменты, делятся успешными наработками с другими командами. В Medium это — инициатива сверху, затрагивающая всю компанию созданием сообществ и центров компетенций:

Agile и DevOps
Вопрос о связи Agile и DevOps часто обсуждается в индустрии. Этот вопрос поднимается и в отчете State of Agile Report за 2019/2020 год, поэтому мы решили сравнить как связаны Agile и DevOps активности в компаниях. Мы выяснили, что DevOps без Agile встречается редко. У половины респондентов распространение Agile началось заметно раньше, а одновременное начало наблюдали около 20%, а одним из признаков Low-профиля будет отсутствие Agile и DevOps практик:

Командные топологии
В конце прошлого года вышла книга «Team topologies», в которой предложен фреймворк для описания командных топологий. Нам стало интересно, а применим ли он к российским компаниям. И мы задали вопрос: «Какие паттерны встречаются у вас?».
Инфраструктурные команды наблюдаются у половины респондентов, также, как и отдельные команды разработки, тестирования и эксплуатации. Отдельные DevOps команды отметили 45%, среди которых представители High встречаются чаще. Следом идут кроссфункциональные команды, которые также чаще встречаются у High. Отдельные команды SRE появляются в профилях High, Medium и редко встречаются у профиля Low:
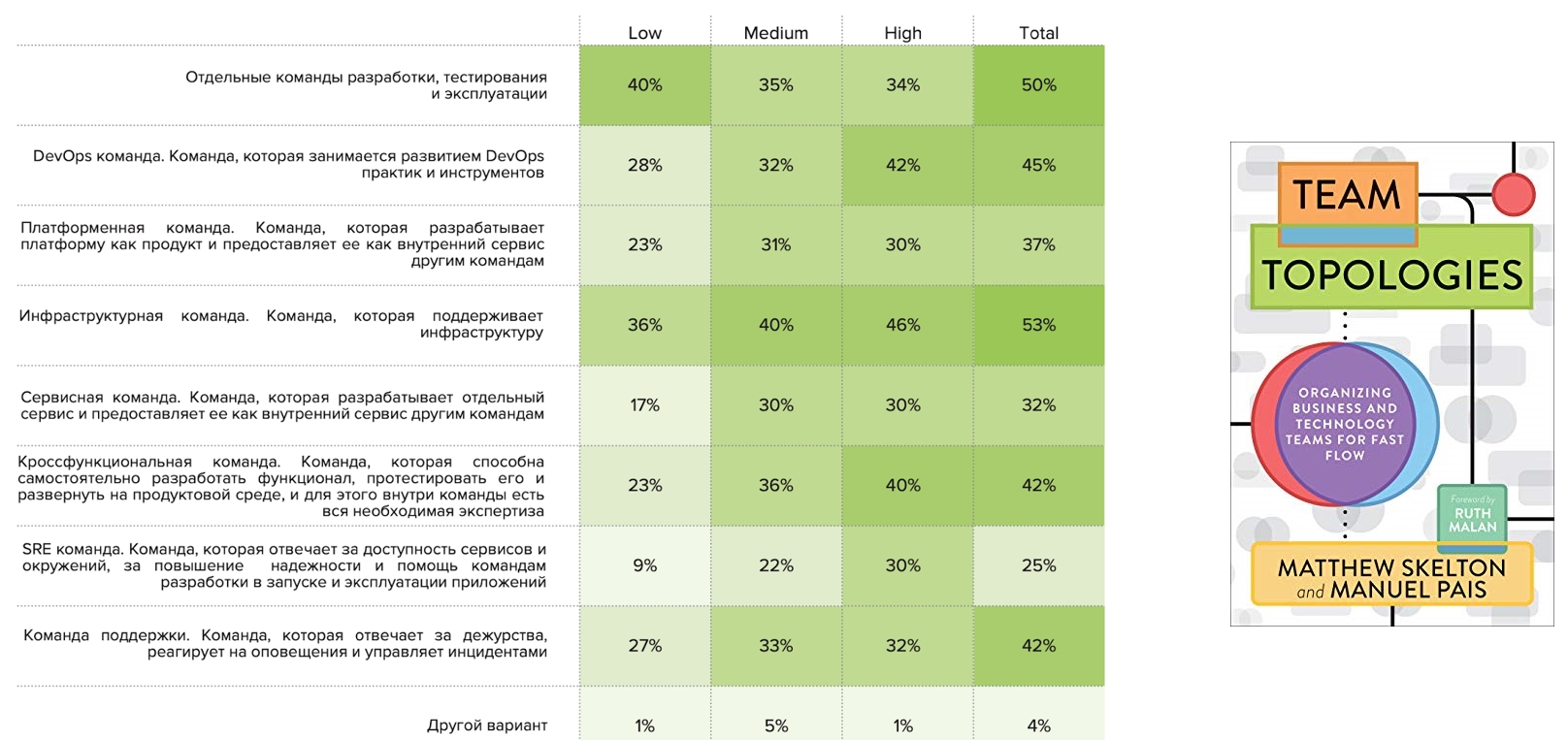
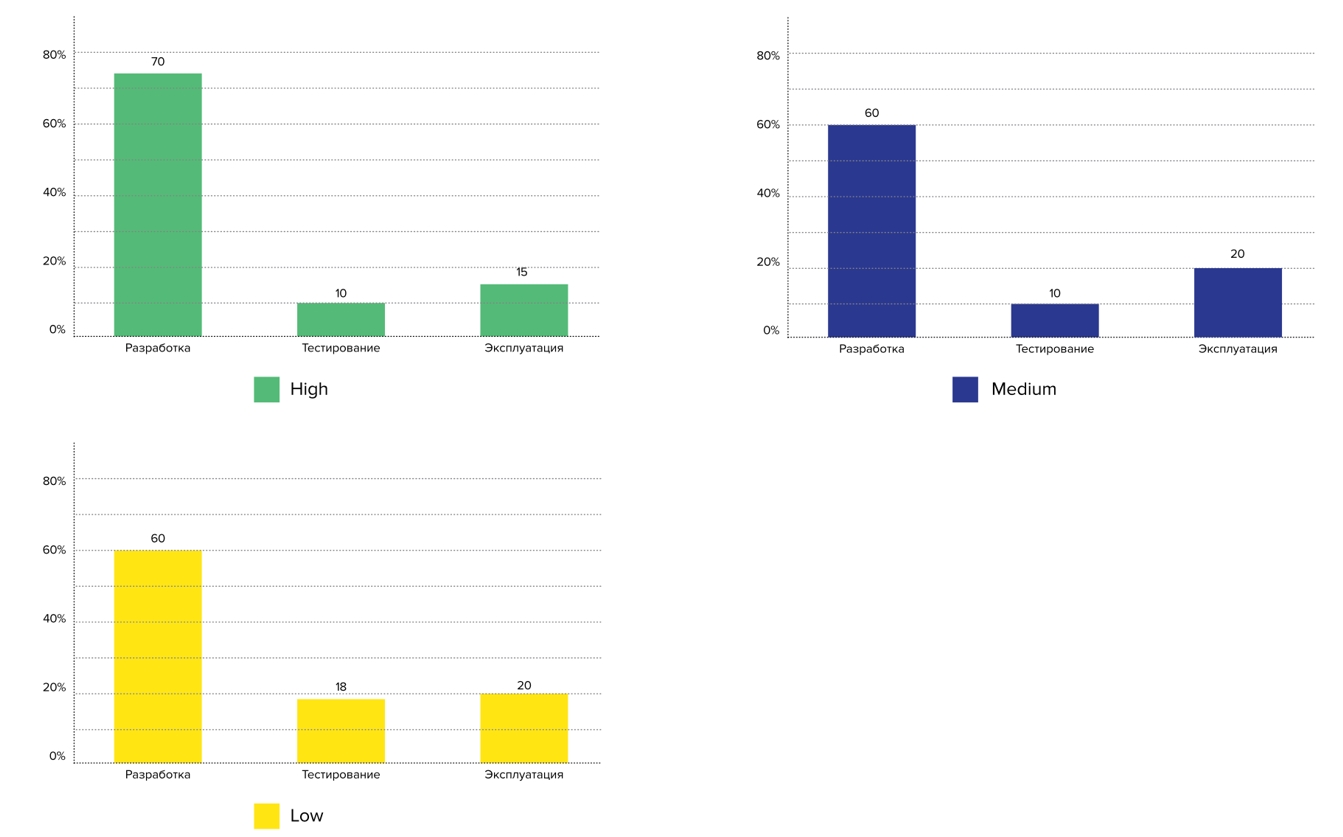
Соотношение DevQaOps
Этот вопрос мы увидели в FaceBook у тимлида платформенной команды Skyeng — его интересовало соотношение разработчиков, тестировщиков и администраторов в компаниях. Мы задали его и посмотрели на ответы с учетом профилей: у представителей профиля High на каждого разработчика приходится меньшее число инженеров тестирования и эксплуатации:
Планы на 2021 год
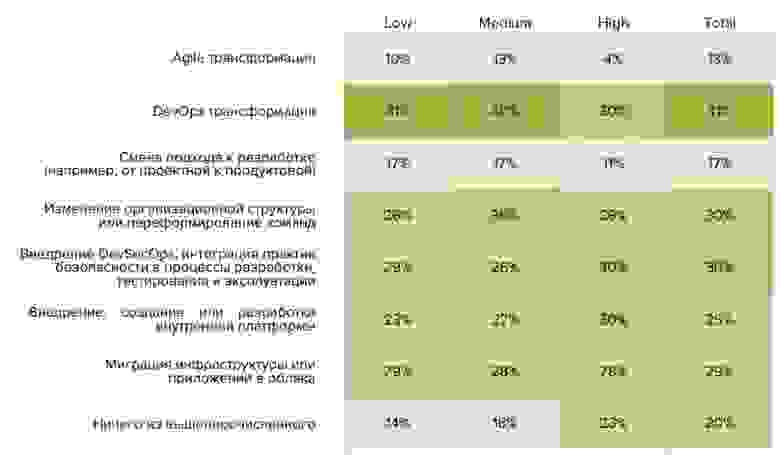
В планах на следующий год респонденты отметили следующие активности:

Здесь видно пересечение с конференцией DevOps Live 2020. Мы внимательно ознакомились с программой:
- Инфраструктура как продукт
- DevOps трансформация
- Распространение DevOps практик
- DevSecOps
- Кейс-клубы и дискуссии
Но времени нашего выступления не хватит, чтобы рассмотреть все темы. За кадром осталось:
- Платформа как сервис и как продукт;
- Инфраструктура как код, окружения и облака;
- Непрерывная интеграция и поставка;
- Архитектура;
- Паттерны DevSecOps;
- Платформенные и кросс-функциональные команды.
Отчет у нас получился объемным, на 50 страниц, и вы можете посмотреть его более подробно.
Подводим итоги
Мы надеемся, что наше исследование и отчет вдохновят вас на эксперименты с использованием новых подходов к разработке, тестированию и эксплуатации, а также помогут вам сориентироваться, сравнить себя с другими участниками исследования и определить области, в которых вы можете улучшить собственные подходы.
Результаты первого исследования состояния DevOps в России:
- Ключевые метрики. Мы выяснили, что ключевые метрики (срок поставки, частота развертывания, время восстановления и неуспешные изменения) подходят для анализа эффективности процессов разработки, тестирования и эксплуатации.
- Профили High, Medium, Low. На основе собранных данных можно выделить статистически различающиеся группы High, Medium, Low с отличительными признаками по метрикам, практикам, процессам и инструментам. Представители профиля High показывают лучшие результаты, чем Low. У них больше шансов достичь и перевыполнить поставленные цели.
- Показатели, пандемия и планы на 2021 год. Особый показатель в этом году, как компании справились с пандемией. Представители High справились лучше, испытали рост активности пользователей, а основными причинами успеха стали эффективные процессы разработки и сильная инженерная культура.
- DevOps практики, инструменты и их развитие. В основные планы компаний на следующий год входят развитие DevOps практик и инструментов, внедрение практик DevSecOps, изменение организационной структуры. А эффективное внедрение и развитие DevOps практик выполняется с помощью пилотных проектов, формированием сообществ и центров компетенций, инициатив на верхнем и нижнем уровнях компании.
Будем рады услышать ваши отзывы, истории, обратную связь. Благодарим всех, кто участвовал в исследовании, и надеемся на ваше участие в следующем году.
