
В наше время существует много популярных, многократно проверенных инструментов для генерации тестовых данных. Их давно и успешно используют для подготовки тестирования систем хранения данных уровня middle. Но что делать, если вы перешли на следующий уровень? Ведь есть системы Enterprise, HS High, такие как, Dell EMC Power Max. И там использовать популярные инструменты уже нельзя.
Меня зовут Анна Рукавицына, я senior quality инженер из Dell Technologies. Люблю автоматизацию тестирования и большие потоки данных. Делаю код качественнее, а мир лучше! Расскажу как мы тестируем СХД и откуда берём качественные входные данные. Почему функциональное тестирование лучше проводить в условиях нагрузки, и почему так важна консистентность данных. Представлю пару кейсов нашей работы: с какими ошибками мы столкнулись и какие выводы из этого сделали.

Общая схема обработки данных
Начнём с общей схемы центра обработки данных. Она выглядит так:
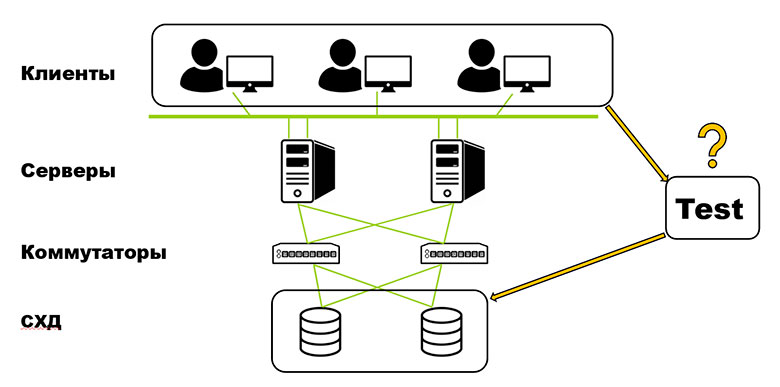
Клиенты посылают запросы ввода/вывода на серверы, которые через коммутаторы адресуют их на систему хранения данных. Чтобы качественно тестировать СХД нужны хорошие входные данные, которые очень похожи на клиентские. Популярные инструменты генерации тестовых данных, такие как Iometer и FioSynth подходят для ряда СХД уровня middle, но для Dell EMC Power Max, с которой я работаю, их уже не применить.
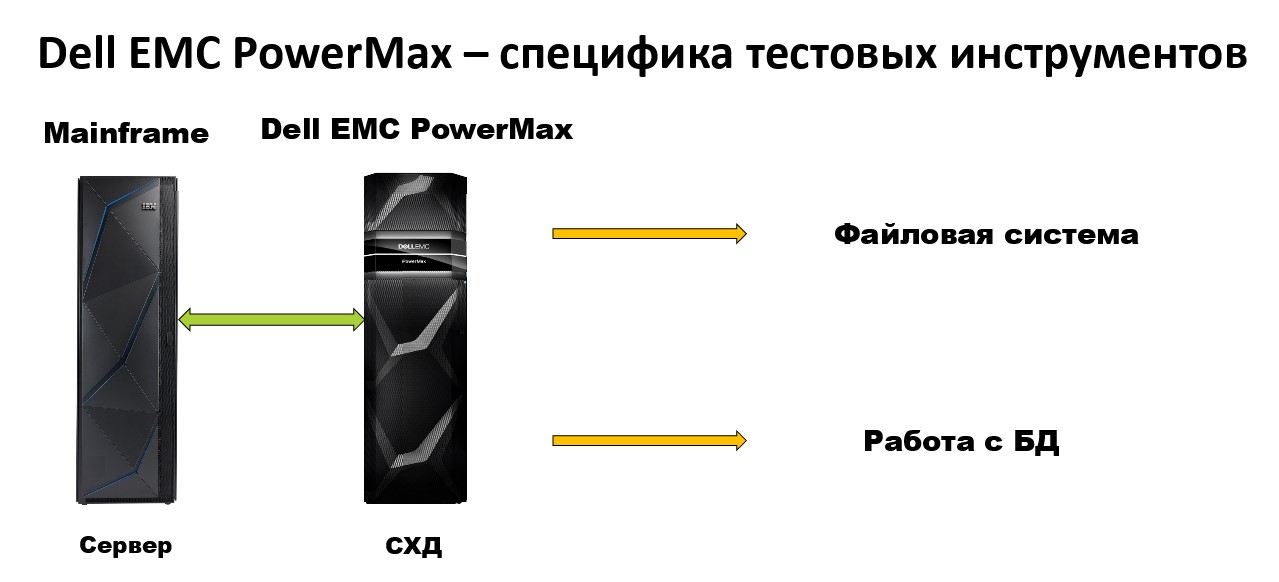
Сложность этой системы состоит в том, что одним из наиболее популярных серверов, который используется для СХД является мейнфрейм.
Многие считают, что мейнфрейм умер. Но нет, он жив и развивается. У него много популярных моделей. Мы активно с ним работаем.
Мейнфрейм — это особенный сервер с операционной системой z/OS, созданной компанией IBM. У него свои способы управления пакетными заданиями, поддерживаются определённые языки программирования. Есть особенности в плане управления и физического соединения с СХД.
Мейнфрейм плюс Power Max используют в двух областях:
Для создания файловой системы для важных, критических предприятий. Такая файловая система отказоустойчивая и высокопроизводительная, с большим количеством пользователей и ресурсами ввода/вывода.
Для управления базами данных.
Генераторы IO
Исходя из данных особенностей системы хранения данных, мы выделили следующие группы разрабатываемых генераторов IO:

Расскажу о первых двух группах, потому что подходы, которые мы использовали для автоматизации данных генераторов, могут быть полезны другим инженерам-тестировщикам, в работе с другими СХД, где требуется автоматизация генераторов тестовых данных.
Симуляторы клиентского IO высокой нагрузки
Когда мы занимались автоматизацией данных симуляторов, то реализовывали три основных функционала. Во-первых, поддерживали IO-процессы различной интенсивности. Во-вторых, хотели уметь работать с дисковым пространством в различных режимах. И, наконец, воспроизводить псевдорандомизацию IO-процессов, чтобы лучше симулировать кастомерские кейсы.

Поддержка IO-процессов различной интенсивности
Самое главное и важное, что требуется от генераторов IO, - это генерация IO высокой нагрузки. Но этим всё не ограничивается. Есть частные кейсы, кастомерские окружения, для которых требуется особая настройка IO-процессов. В связи с этим нами было разработано более 70 различных автоматизированных генераторов данных. Мы их активно используем в тестовой работе каждый день.
Помимо этого, в каждом из генераторов мы ввели широкую параметризацию, чтобы иметь возможность наиболее точно приблизиться к кастомерскому кейсу. Например, в приведенной таблице приведено около 30 параметров лишь для одного из симуляторов. У нас их более 70.
Итак, почему нужна широкая параметризация? Когда мы говорим о воспроизведении кейса в плане IO, важна тонкая настройка IO. У нас был кейс, когда клиент передал нам средние показатели IO-процесса, своё тестовое окружение, настройку конфигурации. Однако, воспроизведение аналогичного процесса с нашей стороны не приводило к появлению клиентской ошибки. Тогда мы начали работать с кастомером подробнее и выяснили следующее. Форма IO-профиля у него была весьма специфичная: средний уровень IOPS, изменялся на достаточно малую величину, изменения происходили через определённый момент времени, то есть профиль был ступенчатый. Но это мы увидели только тогда, когда подробно рассмотрели саму форму IO-профиля. Изменения IOPS на малую величину — это и есть пример тонкой настройки.
Возникает вопрос, что значит «малая» величина . Малая относительно чего? На картинке представлены временные выдержки IO-процесса для процессов чтения и записи.

Изначально операции записи у нас выполнялись примерно на уровне 6 000 IO PS. Это средний показатель. Операции чтения — примерно 4 000 IO PS. После тонкой настройки для такого процесса, когда мы изменили средний уровень IO PS примерно на 2 000 IO PS, мы получили результат, представленный на картинке. Величина, сравнимая с 1 000 IOPS — это тонкая настройка.
Почему мы говорим, что это тонко? Это же много — 1 000. Это не много когда мы говорим о high СХД, high end СХД, о таком уровне СХД, как Dell EMC Power Max — это миллионы IOPS. Потому что современная СХД Dell EMC Power Max рассчитана на пиковые нагрузки до 15 миллионов IOPS. Поэтому 2 000 — это тонкая настройка. Но именно в рамках самой СХД могут включаться различные режимы функционирования, что касается железа, а также ПО со стороны СХД, со стороны мейнфрейма. Это всё может иметь влияние.
Ещё один пример относительно тонкой настройки.

Мы делаем также тонкую настройку относительно профиля IO-процесса. Не то, что мы генерируем особую форму сигнала, нет. Здесь я расскажу о флуктуациях. У нас есть такой параметр Pace. Он позволяет нам сгладить флуктуации относительно среднего уровня IOPS и определённым образом менять этот параметр. Мы сохраняем среднее число IOPS, получаем более гладкий профиль. Это опять-таки очень сильно влияет на железо с которым мы работаем, на работу СХД в целом. Мы это принимаем во внимание и умеем настраивать IO-процесс, IO-профиль различным образом.
Я также упомянула о том, что мы работаем с дисковым пространством в различных режимах.
Работа с дисковым пространством в различных режимах
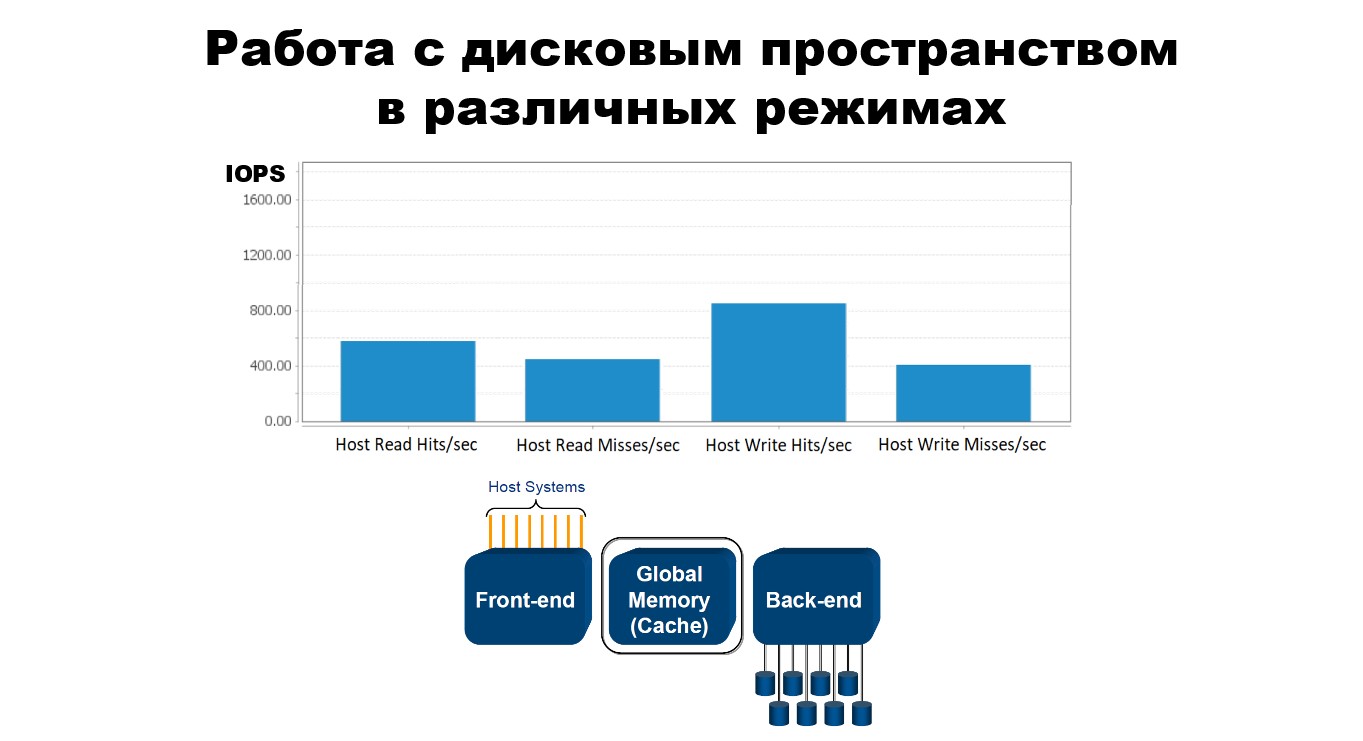
В нижней части картинки показана общая схема СХД нашего Power Max. У нас есть host systems — это хосты, наши сервера. У нас есть фронтэнд часть — железо, те директора, которые обеспечивают связь СХД с мейнфреймом. Далее у нас есть бекэнд часть. Это то железо, те директора, которые работают с дисковыми массивами. Цилиндры под бэкендом — это те дисковые стойки, огромные дисковые массивы , которые есть в СХД. И у нас есть глобальная память (кэш). Это то место, где у нас происходят операции ввода/вывода, операции чтения и записи.
Для СХД у нас существует два варианта операций чтения/записи. Это режим Hit и режим Miss. У них есть отличия. Для Read Hit, запрашиваемая вами информация уже находится в кэше. Вы просто идёте на фронтэнд, достаёте из кэша необходимую вам информацию и идёте с ней на хост. Когда в кэше нет необходимой информации, вам прежде всего необходимо её получить в кэше с дисковых массивов через бэкэнд. Это уже Read Miss операция.
Для операции записи аналогичная ситуация. Операция Write Hit состоит в том, что у нас в кэше достаточное количество свободных слотов для записи. Мы записываем туда необходимую информацию, и потом она в своём режиме реплицируется на дисковые массивы. Операция Write Miss состоит в том, что у нас в кэше недостаточное количество свободных слотов, мы его принудительно освобождаем и потом уже по такой же логике осуществляем операцию записи.
Мы умеем в наших автоматизированных генераторах менять соотношение hit’ов и miss’ов для операции чтения/записи. Ситуация, когда практически сто процентов IO-процесса приходится на операции hit’ов — Read Hit и Write Hit, может возникнуть только у плохого тестировщика, потому что диски не будут задействованы. В таком случае он работает только с фронтенд и с кэш-частью, а вот с самим сердцем СХД не работает. Намного более сбалансированным и реалистичным вариантом будет соотношение, представленное на схеме, когда максимально задействуются обе эти операции.
Мы умеем это настраивать для различных кастомерских кейсов и активно используем.
Еще у нас есть операции последовательного и рандомного доступа. Я думаю, все знают, чем они отличаются. В любом случае операции рандомного доступа требуют больше ресурсов СХД, время ЦПУ и так далее.

Можно подумать, что для любого тестирования СХД большая часть IO-процесса должна находиться в операциях рандомного чтения и записи. И также можно предположить, что все кастомеры так делают, но на самом деле это не так. Мы умеем настраивать, балансировать операции рандомного и последовательного доступа, потому что некоторые наши кастомеры работают только или преимущественно с последовательным доступом.
Псевдорандомизация IO-процессов
Перечислю параметры, относительно которых наших генераторах можно настраивать псевдорандомизацию.

Во-первых, относительно дискового устройства. Когда у нас существуют различные диски, дисковой массив, мы можем рандомно выбирать, с каким диском работать. Далее на конкретном диске можно выбирать рандомное дисковое пространство.
Идём глубже: работаем рандомно с областью памяти в конкретном дисковом пространстве. Это значит, что мы выбираем дисковое пространство, можем поработать в его начале, а потом перепрыгнуть куда-нибудь в середину и так далее. Это будет рандомный режим работы с областью памяти.
Помимо этого, мы проводим псевдорандомизацию относительно генерируемых данных. Когда мы генерируем IO, мы генерируем определённые фреймы данных. Они могут состоять из различных символов, содержать какие-то пустые места, пробелы. Это всё очень сильно влияет на способность данных к сжатию. Любой кастомер, клиент СХД в своей жизни подходит к моменту, когда у него встаёт вопрос: откуда получить ещё место? И он пытается сжать свои данные, освободив ещё немного местечка.Так вот, различные фреймы влияют на степень данных к сжатию, и мы тестируем различные кейсы.
Помимо этого, мы проводим псевдорандомизацию относительно времени IO-операции, чтобы лучше симулировать кастомерскую нагрузку. Вот общие метрики для симуляции клиентского IO.

Мы их получаем от наших клиентов, когда в самом начале приступаем к воспроизведению кастомерского кейса. Здесь как раз все те характеристики, которые я демонстрировала. Конечно, этого может быть недостаточно. Если у нас не получается воспроизвести что-то, если нам требуется более детальная информация от кастомера, то мы работаем с ним подробнее, узнаем какие-то более узкие параметры.
Кейс: Обрыв удалённой репликации при высокой нагрузке IO
В этом кейсе мы используем наши симуляторы, которые работают как наш клиент, и находим с их помощью баги. СХД уровня middle и high поддерживают удаленную репликацию. Для системы хранения типа Power Max существует два основных режима удаленной репликации. Это синхронная репликация и асинхронная репликация.
Синхронная репликация состоит в том, что у нас есть локальный массив дисков R1 — локальная система хранения данных. У нас есть удалённая система хранения данных — R2. Между ними осуществляется непрерывная репликация в синхронном режиме с R1 на R2 массив. Расстояние ограничено 200 километрами. Связано это с ограничениями передачи светового сигнала по оптоволокну. При этом в любой момент времени у нас R2 массив дисков, является точным зеркалом R1 массива дисков.

Но 200 километров — это мало. Чтобы защитить критически важные данные, нам нужно разнести наши СХД на более далекое расстояние. Поэтому мы сделали асинхронную репликацию. Её отличие состоит в том, что здесь уже возможно безграничное расстояние между локальной и удалённой СХД. Однако сам процесс репликации включает в себя несколько этапов.
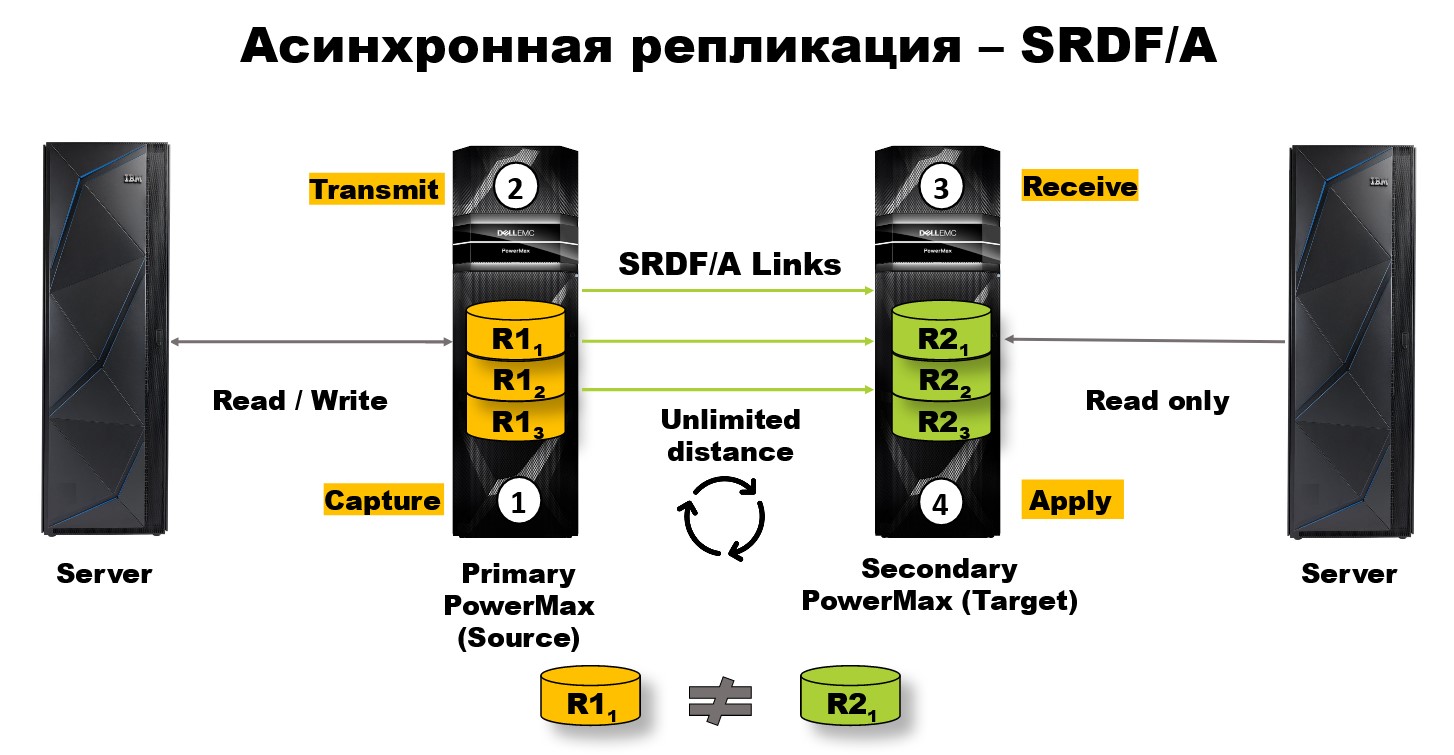
На первом этапе происходит операция capture на локальной стороне. То есть мы захватываем те данные, которые нужно передать, реплицировать.
На втором этапе мы эти данные передаём на удалённый СХД.
На третьем этапе получаем их на удалённый СХД.
И на четвёртом этапе применяем операцию чтения/записи к удалённому массиву дисков.
Это всё повторяется циклично и, естественно, требует определённого времени на выполнение. В связи с этим у нас в любой момент времени R2 массив дисков не является точным зеркалом R1 массива дисков. И отличаются они на некоторую задержку данных дельта, обычно не превышающих несколько миллисекунд.
Всем 4 этапам нужно где-то выполняться. Мы выделили эту память в кэше, про который я говорила. Причём выделили не весь кэш, а ограниченную область памяти для каждой сессии асинхронной репликации.

Когда мы приступили к тестированию, мы задумались, какие нагрузки присутствуют в системах у наших кастомеров. И обнаружили, что они составляют примерно сотни тысяч IOPS. Решили протестировать их в условиях нагрузки. При малой нагрузке в несколько тысяч IOPS все работало без проблем. Но когда мы подключили несколько серверов, то нагрузка выросла до 200 000 IO PS. И мы получили переполнение кэша и нехватку памяти на локальной и удалённой стороне СХД.

Соответственно, нашим операциям по асинхронной репликации 1, 2, 3, 4, просто негде было выполняться. В связи с этим у нас произошёл обрыв связи асинхронной репликации, и на удалённой стороне мы получили устаревшую информацию.
Эта ситуация крайне критична именно в рамках СХД. Потому что любой бизнес-процесс принимает как правило, что абсолютно любые бизнес-данные критичны. И когда на удалённой стороне R2 в течение продолжительного времени присутствует неактуальная информация, это может привести к приостановлению бизнес-процесса или даже к бизнес-катастрофе.
Мы сделали выводы из этой ситуации. Теперь любое функциональное тестирование мы проводим в условиях кастомерской нагрузки. А что насчёт консистентности? Возникает вопрос, причём здесь вообще консистентность, когда мы говорим про нагрузку и различные симуляторы?
Консистентность данных — почему это важно?
Консистентность для таких СХД важна. Мы привыкли воспринимать её как непротиворечивость, целостность, согласованность данных друг с другом. При этом консистентность обычно ставится рядом с такими словами как «база данных». Но мы поговорим только про СХД.
Как мы обычно работаем с СХД? Сначала мы пишем на неё IO с сервера. После этого, как разумные люди, делаем резервную копию операцией локальной репликации с массива дисков R1 на массив дисков Т.
Мы поработали, ушли домой, легли спать. И за это время с нашей СХД могло произойти что угодно. Например, потерялось питание, вышел из строя массив дисков R1, вышла из строя вся СХД (это возможно, только если будет пожар или землетрясение).

В любом случае нам нужно восстановить наши данные, и наша система понимает, что данные не были повреждены на резервных дисках во время системного сбоя именно засчёт свойства консистентности.
Консистентность — это то качество, которое позволяет восстановить данные из резервной копии. Данное свойство всегда тестируется в рамках одной СХД. Это либо локальная сторона (R1), либо удалённая сторона(R2). Если мы говорим о тестировании удалённой репликации, конечно, будет логично протестировать данные, которые уже реплицировались на удалённый массив дисков. Так что рассмотрю этот массив дисков R2.
Консистентность данных — логика тестирования
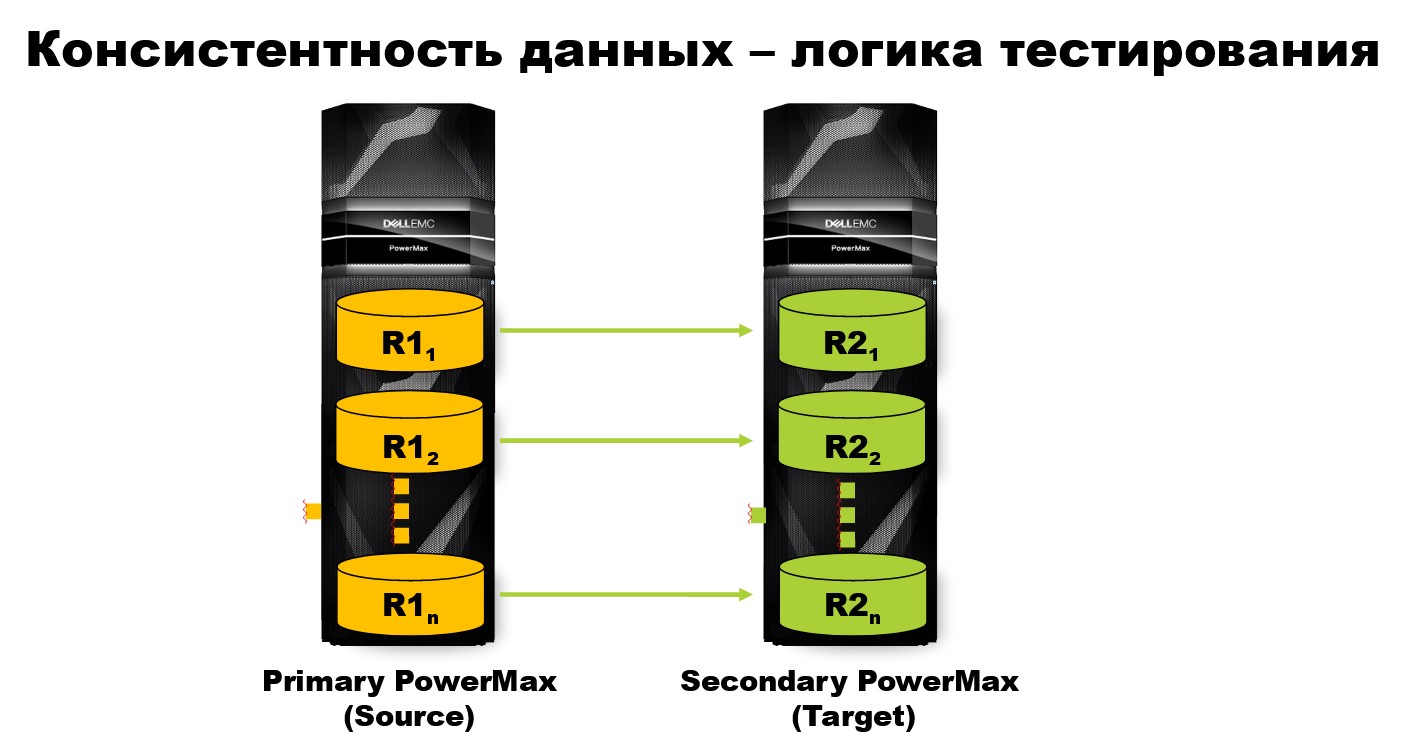
Как проходит классический тест? Исходно состояние системы консистентно, и мы принимаем это как данное. После этого мы запускаем в работу наш специальный генератор (не те, которые были продемонстрированы раньше), который пишет данные консистентно. Он пишет записи, руководствуясь логикой, так называемых зависимых записей (dependent writes).

Логика в том, что записи идут на каждый диск друг за другом через весь массив дисков. Кроме этого, каждый следующий цикл записи начинает выполняться только после завершения предыдущего цикла.
После этого мы или кто-то другой работаем с дисками. Вовлекаем их в различные процессы удалённой и локальной репликации. В любом случае после нашего теста стоит проверить, что данные консистентны.
Мы хитрые — снабдили один и тот же генератор двумя абсолютно разными режимами. Один пишет, другой проверят. Поэтому запускаем тот же самый генератор, только в другом режиме с проверкой на консистентность. Он проверяет поля мета-даты и по ним определяет, присутствуют ли на дисках все необходимые записи, цели ли они, были ли они сделаны последовательно на всех дисках, согласованы ли по времени и соответствуют ли необходимому формату: размеру и формату записи. После этого мы получаем отчёт, консистентны или не консистентны наши данные.
Хочу сделать здесь акцент именно на свойстве консистентности. Очень часто в литературе я вижу приравнивание таких характеристик, как целостность и консистентность. Это абсолютно разные вещи.
Целостность, по крайней мере в мире СХД — качество, которое позволяет программе принять на вход наши данные. То есть они находятся в правильном формате.
Консистентность — это более сложное качество. К примеру, предположим, у нас есть записи в формате целого числа. А дальше временной формат — часы/минуты/секунды, время совершения этой записи. Массив таких записей будет не целостным, если для одной записи у нас вместо целого числа будет стоять буква, программа просто не сможет принять эти данные на вход.
Другой пример не консистентного массива записей представлен на картинке.

Время совершения 4-ой операции стоит позже, чем время совершения пятой, то есть данные не согласованы по времени. Отсюда видно, что консистентные данные заведомо целостные. Обратное неверно. То есть целостность не равна консистентности.
Кейс: Обнаружение неконсистентности на этапе тестирования

У нас есть система хранения данных. Мы запускаем сервер, запускаем на нём генератор IO, который пишет данные консистентно по логике зависимых данных. После этого мы проводим операцию локальной репликации по созданию снэпшотов. В СХД она очень популярная. Простыми словами, это логическое «изображение» диска, его «снимок» в определённый момент времени. По сделанному снэпшоту диска можно узнать, что было на нем в определенный момент времени. После этого, мы можем наши снимки-снэпшоты прилинковать к абсолютно другому массиву дисков R2 специальной командой Link. Линкуя новый массив дисками со снэпшотами, мы можем воспроизвести состояние массива дисков R1 на массиве дисков R2.

Через какое-то время, после определенной работы с данными мы решили восстановить наш массив дисков R1 до изначального состояния. Мы сделали команду Restore. То есть на самом деле мы просто погоняли наши данные туда-сюда через снэпшоты. Логично, что мы ожидали после этого получить консистентные данные на R1 и R2 массиве дисков. Поэтому проверили их. Сравнили диски попарно, и обнаружили, что массивы дисков не равны. Потом мы запустили наш генератор в режиме проверки на консистентность. Проверили сначала R2 массив дисков. Там всё хорошо, всё консистентно. После этого запустили проверку консистентности на R1 массиве дисков, и обнаружили не консистентную запись.
После некоторого разбора полётов мы выяснили, что проблема была в команде restore. Она портила и повреждала наши данные. И именно благодаря тому, что мы использовали генератор консистентного IO, нам удалось эту багу обнаружить быстро и безболезненно. Мы поняли, что именно эта команда нам консистентность всю и попортила. Поэтому на тестирование консистентности мы обращаем особое внимание.
Выводы
Основные выводы получаются такие:
Во-первых, у нас существуют такие СХД, для которых необходима собственная разработка тестовых генераторов данных. Например, наша СХД Dell EMC Power Max.
Во-вторых, функциональное тестирование нужно всегда проводить в условиях нагрузки. По крайней мере, для СХД.
В третьих, для распределённых и геораспределённых СХД очень важно тестировать консистентность данных.
И, наконец, Customer-like тестирование требует от каждого симулятора широкой параметризации, чтобы лучше воспроизвести кастомерский кейс.
У тестирования распределенных систем хранения данных много нюансов. Но инженеры сталкиваются не только с проблемами генерации тестовых данных. Многие процессы требуют автоматизации. Их легче всего рассматривать на основе реальных кейсов. Множество кейсов с реальными ошибками и реальными решениями проблем будут разобраны на DevOps Conf. Вы уже можете посмотреть какие именно. Программа конференции сформирована.
