Всем доброго! Вот мы и добрались до тематики С++ на наших курсах и по нашей старой доброй традиции делимся тем, что мы нашли достаточно интересным при подготовке программы и то, что будем затрагивать во время обучения.
Инфографика:
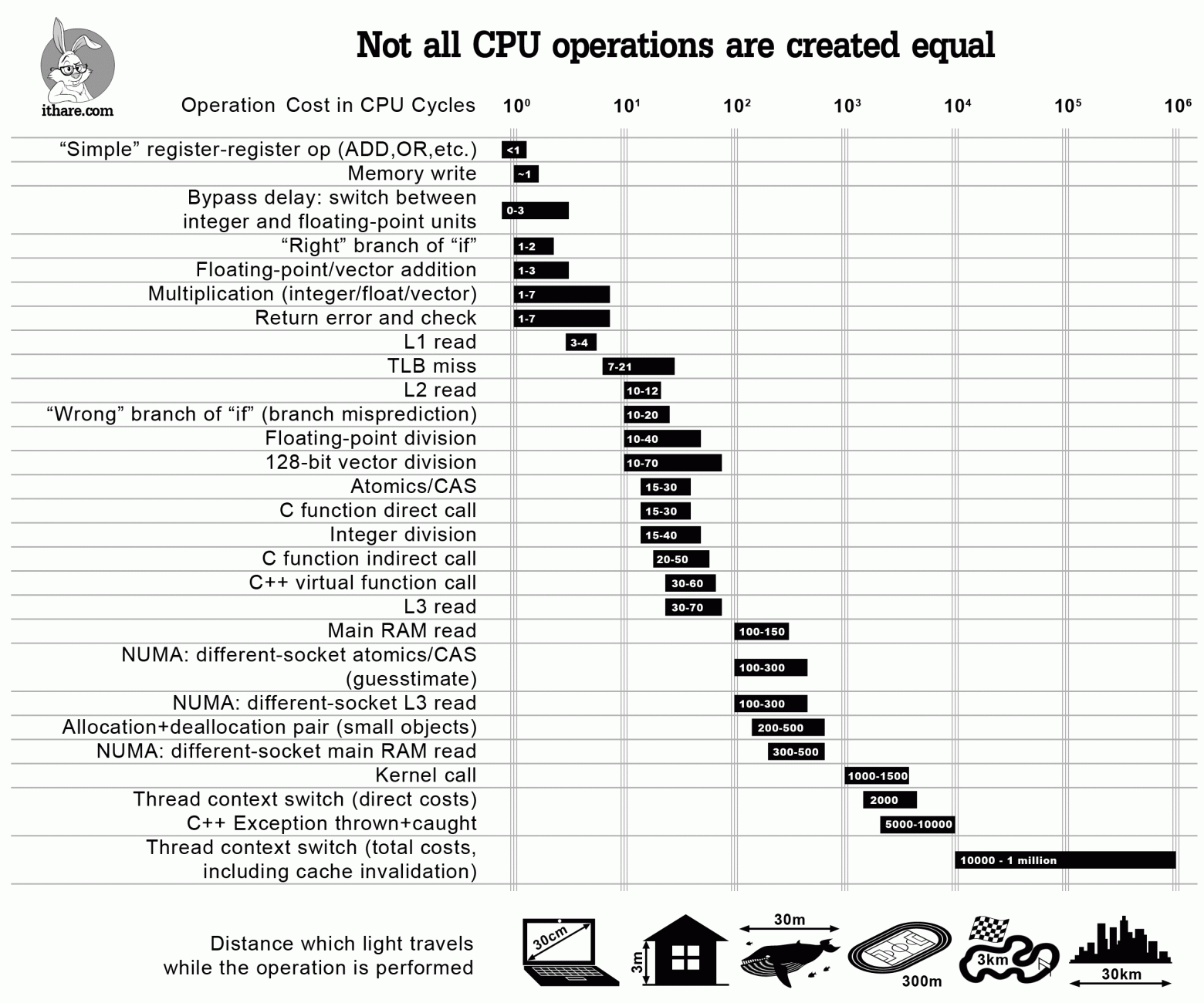
Когда нам нужно оптимизировать код, мы должны отпрофилировать его и упростить. Однако, иногда имеет смысл просто узнать приблизительную стоимость некоторых популярных операций, чтобы не делать с самого начала неэффективных вещей (и, надеюсь, не профилировать программу позже).
Итак, вот она — инфографика, которая должна помочь оценить стоимость конкретных операций в тактах ЦП — и ответить на такие вопросы, как “эй, сколько обычно стоит операция чтения L2?”. Хотя ответы на все эти вопросы более или менее известны, я не знаю ни одного места, где все они перечислены и представлены в перспективе. Также отметим, что, хотя перечисленные стоимости, строго говоря, применяются только к современным процессорам x86/x64, ожидается, что аналогичное отношение стоимостей будут наблюдаться на других современных процессорах с большими многоуровневыми кэшами (такими как ARM Cortex A или SPARC); с другой стороны, MCU (включая ARM Cortex M) достаточно отличны, чтобы некоторые из закономерностей могли быть к ним не применимы.
И последнее, но не менее важное, предостережение: все оценки здесь лишь указывают на порядок; однако, учитывая масштаб различий между различными операциями, эти показания могут по-прежнему использоваться (по крайней мере, следует помнить, что нужно избегать «преждевременной пессимизации»).
С другой стороны, я все еще уверен, что такая диаграмма полезна, чтобы не говорить «эй, вызовы виртуальных функций ничего не стоят» — что может быть или не быть истинным в зависимости от того, как часто вы их вызываете. Вместо этого, используя инфографику выше, вы сможете увидеть, что если вы вызовете свою виртуальную функцию 100K раз в секунду на процессоре с частотой 3 ГГц — это, вероятно, не будет стоить вам более 0,2% от общего объема вашего процессора; однако, если вы вызываете одну и ту же виртуальную функцию 10M раз в секунду, это легко может означать, что виртуализация поглощает двузначные проценты ядра вашего процессора.
Другой способ приблизиться к тому же вопросу — сказать «эй, я вызываю виртуальную функцию один раз за кусок кода, который составляет 10000 тактов, поэтому виртуализация не будет потреблять более 1% от времени программы», — но вам все равно нужен какой-то способ увидеть порядок величины связанных затрат — и приведенная выше диаграмма по-прежнему будет полезна.
Теперь давайте более подробно рассмотрим пункты в нашей инфографике выше.
Операции ALU и FPU
Для наших целей, говоря об операциях ALU, мы будем рассматривать только операции типа регистр-регистр. Если задействована память, затраты могут быть ОЧЕНЬ разными — это будет зависеть от того, “насколько велик был промах кэша” при доступе к памяти, как описано ниже.
“Простые” операции
В наши дни (и на современных процессорах), «простые» операции, такие как ADD/MOV/OR/..., могут легко выполняться быстрее одного такта ЦП. Это не означает, что операция будет выполняться буквально в течение половины такта. Напротив — в то время, как все операции все еще выполняются за целое число тактов, некоторые из них могут выполняться параллельно.
В [Agner4] (который, кстати, ИМХО является лучшим справочным руководством по оценке операций процессора) эта особенность отражается в наличии двух величин характеризующих каждую операцию: одна — это задержка (которая всегда представлена целым числом тактов), а другая — производительность. Следует отметить, однако, что в реальном мире, когда выходят за рамки оценок порядка, точное время будет сильно зависеть от характера вашей программы и от порядка, в котором компилятор поставил, казалось бы, несвязанные инструкции; вкратце — если вам нужно что-то лучше, чем порядок ожидания, вам нужно профилировать свою конкретную программу, скомпилированную вашим конкретным компилятором (и в идеале — на конкретном целевом процессоре тоже).
Дальнейшее обсуждение таких методов (известных как «внеочередное исполнение»), будучи Действительно Интересным, будет слишком аппаратно-ориентированным (как насчет «именования регистра», которое происходит под капотом процессора, чтобы уменьшить количество зависимостей, которые снижают эффективность работы внеочередного порядка?), и явно не входит в область нашего внимания в настоящий момент.
Целочисленное умножение/деление
Целочисленное умножение/деление достаточно дорогое по сравнению с «простыми» операциями выше. [Agner4] оценивает стоимость 32/64-битного умножения (MUL/IMUL в мире x86/x64) в 1-7 тактов (на практике я наблюдал более узкий диапазон значений, например 3-6 тактов), и стоимость 32/64-разрядного деления (известного как DIV/IDIV на x86/64) — около 12-44 тактов.
Операции с плавающей запятой
Стоимость операций с плавающей запятой взята из [Agner4] и варьируется от 1-3 тактов ЦП для сложения (FADD/FSUB) и 2-5 тактов для умножения (FMUL) до 37-39 тактов для деления (FDIV).
Если использовать скалярные SSE-операции (которыми, по-видимому, пользуется “каждая собака” в наши дни), показатели уменьшаться до 0,5-5 тактов для умножения (MULSS/MULSD) и до 1-40 тактов для деления (DIVSS/DIVSD); на практике, однако, вы должны ожидать скорее 10-40 тактов для деления (1 такт — это «взаимная пропускная способность», что на практике редко реализуется).
128-битные векторные операции
В течении уже нескольких лет ЦП поддерживают «векторные» операции (точнее — операции множественных данных Single Instruction Multiple Data или SIMD); в мире Intel они известны как SSE и AVX и в мире ARM — как ARM Neon. Забавно, что они работают с «векторами» данных, причем данные имеют одинаковый размер (128 бит для SSE2-SSE4, 256 бит для AVX и AVX2 и 512 бит для предстоящего AVX-512), но интерпретировать их можно по-разному. Например, 128-битный регистр SSE2 может быть интерпретирован как (a) два double, (b) четыре float, © два 64-битных integer, (d) четыре 32-битных integer, (e) восемь 16-битных integer, (f) шестнадцать 8-битных integer.
[Agner4] оценивает целочисленное сложение над 128-битным вектором в < 1 такт, если вектор интерпретируется как 4 × 32-битных целых числа и в 4 такта, если это 2 × 64-битных целых числа; умножение (4 × 32 бита) оценивается в 1-5 тактов — и в последний раз, когда я проверял, не было операций целочисленного векторного деления в наборе команд x86/x64. Операций с плавающей запятой над 128-битными векторами оцениваются от 1-3 тактов ЦП для сложения и 1-7 тактов ЦП для умножения, для деления до 17-69 тактов.
Задержки перехода
Не такая очевидная вещь, связанная с затратами на вычисления, заключается в том, что переключение между целыми и плавающими инструкциями не бесплатно. [Agner3] оценивает эту стоимость (известную как «задержка перехода») в 0-3 такта в зависимости от процессора. На самом деле проблема более общая, и (в зависимости от ЦП) также могут быть штрафы за переключение между векторными (SSE) целочисленными инструкциями и обычными (скалярными) целочисленными инструкциями.
Совет по оптимизации: в коде, для которого критична производительность, избегайте комбинирования вычислений с плавающей запятой и целыми числами.
Ветвление
Следующее, что мы будем обсуждать, — это ветвление кода. Переход (if внутри вашей программы), по сути, является сравнением и изменением в счетчике команд. В то время как обе эти вещи просты, ветвление может быть достаточно затратным. Обсуждение, почему это так, опять получится слишком аппаратно-ориентированным (в частности, это затрагивает конвейерную обработку и спекулятивное исполнение), но с точки зрения разработчика программного обеспечения это выглядит так:
Продолжительность этой задержки оценивается в 10-20 тактов процессора, для последних процессоров Intel — около 15-20 тактов [Agner3].
Отметим, что в то время как макрос GCC __builtin_expect(), как полагают, влияет на предсказание ветвления — и он работал таким образом всего 15 лет назад, он больше не актуален, по крайней мере, для процессоров Intel (начиная с Core 2 или около того).
Как описано в [Agner3], на современных Intel-процессорах предсказание перехода всегда динамично (или, по крайней мере, доминируют динамические решения); это, в свою очередь, подразумевает, что ожидаемые отклонения от кода __builtin_expect() не будут влиять на предсказание переходов (на современных процессорах Intel). Однако __builtin_expect() все еще влияет на способ генерации кода, как описано в разделе «Доступ к памяти» ниже.
Доступ к памяти
В 80-е годы скорость процессора была сопоставима с задержкой памяти (например, процессор Z80, работающий на частоте 4 МГц, тратил 4 такта на команду типа регистр-регистр и 6 тактов на команду типа регистр-память). В то время можно было вычислить скорость программы, просто посмотрев на сборку.
С тех пор скорости процессоров выросли на 3 порядка, а задержки памяти улучшились только в 10-30 раз или около того. Чтобы справиться с оставшимся более чем тридцати кратным несоответствием, были введены все эти виды кэшей. Современный процессор обычно имеет 3 уровня кэшей. В результате скорость доступа к памяти очень сильно зависит от ответа на вопрос «где хранятся данные, которые мы пытаемся прочитать?». Чем ниже уровень кэша, где был найден ваш запрос, тем быстрее вы можете его получить.
Время доступа к кэшу L1 и L2 можно найти в официальных документациях, таких как [Intel.Skylake]; он оценивает время доступа к L1 / L2 / L3 в 4/12/44 такта процессора соответственно (обратите внимание: эти цифры немного варьируются от одной модели процессора к другой). Вообще, как упоминается в [Levinthal], время доступа к L3 может достигать 75 тактов, если кэш совместно используется с другим ядром.
Однако, что сложнее найти, так это информацию о времени доступа к основной ОЗУ. [Levinthal] оценивает его в 60нс (~ 180 тактов, если процессор работает на частоте 3ГГц).
Совет по оптимизации: улучшайте локальность данных. Подробнее об этом см., например, [NoBugs].
Помимо чтения из памяти, есть также запись. В то время как запись интуитивно воспринимается как более дорогая, чем чтение, чаще всего это не так; причина для этого проста: процессору не нужно ждать завершения записи перед тем, как идти вперед (вместо этого он только начинает писать — и сразу переходит к другим делам). Это означает, что большую часть времени процессор может выполнять запись в 1 такт; это согласуется с моим опытом и, по-видимому, достаточно хорошо коррелирует с [Agner4]. С другой стороны, если ваша система завязана на пропускной способности памяти, цифры могут получиться ЧРЕЗВЫЧАЙНО высокие; все же, из того, что я видел, перегрузка шины операциями записи является очень редким явлением, поэтому я не отразил его на диаграмме.
Еще помимо данных, есть и код.
Еще один совет по оптимизации: постарайтесь улучшить также и локальность кода. Это менее очевидно (и, как правило, оказывает меньшее влияние на производительность, чем плохая локализация данных). Обсуждение способов улучшения локальности кода можно найти в [Drepper]; эти способы включают такие вещи, как inlining, и __builtin_expect().
Следует отметить, что хотя __builtin_expect(), как упоминалось выше, больше не влияет на предсказание переходов на процессорах Intel, она все равно влияет на разметку кода, что, в свою очередь, влияет на пространственную локальность кода. В результате __builtin_expect() не имеет эффектов, которые слишком выражены на современных процессорах Intel (на ARM — понятия не имею, если быть честным), но все равно может повлиять на производительность в той или иной степени. Также сообщалось, что под MSVC замена if и else переходов условного оператора имеет эффекты, сходные с __builtin_expect() (если предполагаемый переход является if-переходом условного оператора с двумя переходами), но к этому следует относится с сомнением.
NUMA (Архитектура с неравномерной памятью)
Еще одна вещь, связанная с доступом к памяти и производительностью, редко наблюдается на настольных компьютерах (так как для этого требуются многопроцессорные машины — не следует путать с многоядерными). Таким образом, это, в основном, серверная парафия; однако это существенно влияет на время доступа к памяти.
Когда задействованы несколько сокетов, современные процессоры имеют тенденцию реализовывать так называемую архитектуру NUMA, причем каждый процессор (где «процессор» = «эта штука, вставленная в сокет») имеет свою собственную ОЗУ (в отличие от архитектуры FSB более раннего возраста с общей FSB aka Front-Side Bus и общая оперативная память). Несмотря на то, что каждый процессор имеет собственную ОЗУ, ЦП совместно используют адресное пространство ОЗУ — и всякий раз, когда требуется доступ к ОЗУ, физически находящемуся в другом, это делается путем отправки запроса на другой сокет через сверхбыстрый протокол, такой как QPI или Hypertransport.
Удивительно, но это не так долго, как вы могли бы ожидать — [Levinthal] дает 100-300 тактов ЦП, если данные были в кэше L3 удаленного процессора и 100нс (~ = 300 тактов), если данные были не там, и удаленный процессор должен был перейти в свою основную ОЗУ для этих данных.
CAS (сравнение с обменом)
Иногда (в частности, в неблокирующих алгоритмах и при реализации мьютексов) мы хотим использовать так называемые атомарные операции. Академически обычно рассматривается только одна атомарная операция, известная как CAS (Compare-And-Swap — сравнение с обменом) (на том основании, что все остальное может быть реализовано через CAS); в реальном мире их обычно больше (см., например, std::atomic в C++ 11, Interlocked*() в Windows или __sync _*_ и _*() в GCC/Linux). Эти операции — довольно странные звери: в частности, им нужна специальная поддержка ЦП для правильной работы. В x86 / x64 соответствующие инструкции ASM характеризуются наличием префикса LOCK, поэтому CAS на x86 / x64 обычно записывается как LOCK CMPXCHG.
С нашей нынешней точки зрения важно то, что эти операции, подобные CAS, будут выполняться значительно дольше обычного доступа к памяти (чтобы гарантировать атомарность, процессор должен синхронизировать процессы, по крайней мере, между разными ядрами, или в случае мультисокетных конфигураций, также между различными сокетами).
[AlBahra] оценивает стоимость операций CAS примерно в 15-30 тактов (с небольшой разницей между семействами x86 и IBM Power). Стоит отметить, что это число обоснованно только при выполнении двух допущений: (а) мы работаем с одноядерной конфигурацией и (б), что сравниваемая память уже находится в L1.
Касательно затрат CAS в мультисокетных NUMA-конфигурациях, я не смог найти данные о CAS, поэтому мне пока не обойтись без спекуляций. С одной стороны, ИМХО будет почти невозможным иметь задержки работы CAS на «удаленной» памяти меньше, чем кругооборот HyperTransport между сокетами, что в свою очередь сопоставимо со стоимостью чтения NUMA кэша L3.
С другой стороны, я действительно не вижу причин, чтобы превысить эти показатели :-). В результате я оцениваю стоимость NUMA раздельных CAS (и CAS-подобных) операций в 100-300 тактов ЦП.
TLB (Буфер ассоциативной трансляции)
Всякий раз, когда мы работаем с современными процессорами и современными ОС, на уровне приложений мы обычно имеем дело с «виртуальным» адресным пространством; другими словами, если мы запускаем 10 процессов, каждый из этих процессов может (и, вероятно, будет) иметь свой собственный адрес 0x00000000. Для поддержки такой изоляции процессоры реализуют так называемую «виртуальную память». В мире x86 она была впервые реализована через «защищенный режим», введенный еще в 1982 году на 80286.
Обычно «виртуальная память» работает постранично (для x86 каждая страница имеет размер либо 4K, либо 2M или, по крайней мере, теоретически, даже 1G (!)), когда ЦП знает какой процесс выполняется (!), и переразмечает виртуальные адреса на физические адреса при каждом доступе к памяти. Обратите внимание, что эта повторная разметка происходит полностью за кулисами, в том смысле, что все регистры процессора (кроме тех, которые имеют дело с разметкой) содержат все указатели в формате «виртуальной памяти».
И раз уж мы заговорили о «разметке» — ну, информация об этой разметке должна быть где-то сохранена. Более того, поскольку эта разметка (из виртуальных адресов в физические) происходит при каждом доступе к памяти, это должно быть Чертовски Быстро. Для этого обычно используется специальный вид кэша, называемый Буфер ассоциативной трансляции (TLB).
Так же как и для любого типа кэша, существует стоимость промаха TLB; для x64 она колеблется между 7-21 тактами ЦП [7cpu]. В целом, на TLB довольно сложно повлиять; однако здесь еще можно дать несколько рекомендаций:
Примитивы программного обеспечения
Теперь мы закончили с теми вещами, которые напрямую связаны с “железом”, и будем говорить о некоторых вещах, связанных с программным обеспечением; они действительно все еще повсюду встречаются, поэтому давайте посмотрим, сколько мы тратим каждый раз, когда используем их.
Вызовы функций в С/С++
Сначала давайте рассмотрим стоимость вызова функций в C/C++. На самом деле, то, что вызывает функции в C/C++ делает чертовски много дел перед вызовом, и вызываемое тоже не сидит сложа руки.
[Efficient C++] оценивает затраты ЦП для вызова функции в 25-250 тактов в зависимости от количества параметров; однако, это довольно старая книга, а у меня нет лучшей ссылки того же калибра. С другой стороны, по моему опыту, для функции с достаточно небольшим числом параметров это скорее будет 15-30 тактов; это также, по-видимому, относится к процессорам, отличным от Intel, как выяснил [eruskin].
Совет по оптимизации: используйте inline-функции, где это применимо. Однако имейте в виду, что в наши дни компиляторы чаще всего игнорируют встраиваемые спецификации. Поэтому для действительно критически важных фрагментов кода вы можете использовать __attribute __ ((always_inline)) для GCC и __forceinline для MSVC, чтобы заставить их делать то, что вам нужно. Тем не менее, НЕ используйте эти принудительные inline для не очень критических фрагментов кода, это может сделать намного хуже.
Кстати, во многих случаях выигрыш от встраивания может превышать стоимость простого удаления вызова. Это происходит из-за того, что встраивание обеспечивает довольно много дополнительных оптимизаций (в том числе связанных с переупорядочением для обеспечения правильного использования аппаратного конвейера). Также давайте не будем забывать, что встраивание улучшает пространственную локальность для кода, что также немного помогает (см., например, [Drepper]).
Косвенные и виртуальные вызовы
Дискуссия выше была связана с обычными («прямыми») вызовами функций. Стоимость косвенных и виртуальных вызовов, как известно, выше, и многие согласны с тем, что косвенный вызов вызывает ветвление (однако, как отмечает [Agner1], до тех пор, пока вы вызываете одну и ту же функцию из одной и той же точки кода, механизмы предсказания переходов современных процессоров могут предсказать это довольно хорошо, в противном случае, вы получите штраф за ложное предсказание в 10-30 тактов). Что касается виртуальных вызовов — это одно дополнительное чтение (чтение указателя VMT), поэтому, если в этот момент все кэшируется (как обычно и есть), мы говорим о дополнительных 4 тактах процессора или около того.
С другой стороны, практические измерения [eruskin] показывают, что стоимость виртуальных функций примерно вдвое меньше стоимости прямых вызовов для небольших функций; в пределах нашей погрешности (которая является «порядком») это вполне согласуется с вышеприведенным анализом.
Совет по оптимизации: если ваши виртуальные вызовы стоят дорого, вместо этого в C++ вы можете подумать об использовании шаблонов (реализация так называемого полиморфизма времени компиляции); CRTP — это один (хотя и не единственный) способ сделать это.
Аллокации
В наши дни аллокаторы как таковые могут быть довольно быстрыми; в частности, аллокаторы tcmalloc и ptmalloc2 могут потратить всего 200-500 тактов ЦП для выделения/освобождения небольшого объекта [TCMalloc].
Тем не менее, есть существенное предостережение, связанное с аллокацией, и добавление к косвенным затратам на использование аллокаций: аллокация, как старое доброе правило большого пальца, означает уменьшение локальности памяти, что, в свою очередь, отрицательно влияет на производительность (из-за взаимодействий с незакэшированной памятью, описанных выше). Чтобы проиллюстрировать, насколько это плохо на практике, мы можем взглянуть на 20-строчную программу в [NoBugs]; эта программа при использовании vector<> выполняется от 100 до 780 раз быстрее (в зависимости от компилятора и конкретного поля), чем эквивалентная программа, использующая list<> — все из-за плохой локальности памяти последнего :-(.
Совет по оптимизации: думайте о сокращении количества аллокаций в ваших программах, особенно если есть этап, когда большая часть работы выполняется с данными только для чтения. В некоторых реальных случаях сглаживание ваших структур данных (т.е. замена выделенных объектов упакованными) может ускорить вашу программу до 5 раз.
Реальная история по теме. Когда-то давным-давно была программа, в которой использовались гигабайты оперативной памяти, что считалось слишком большим; окей, я переписал ее в «сплющенную» версию (то есть каждый узел был сначала сконструирован динамически, а затем в памяти был создан эквивалентный «сплющенный» объект только для чтения); идея «сглаживания» заключалась в уменьшении объема памяти. Когда мы запускали программу, мы заметили, что не только объем памяти уменьшился в 2 раза (что и было тем, что мы ожидали), но также, как очень хороший побочный эффект, скорость выполнения увеличилась в 5 раз.
Вызовы ядра ОС
Если наша программа работает под операционной системой (да, есть еще программы, которые работают без нее), то у нас есть целая группа системных API. На практике (по крайней мере, если мы говорим о более или менее обычной ОС) многие из этих системных вызовов приводят к вызовам ядра, которые включают в себя переключения в режим ядра и обратно; это включает в себя переключение между различными «кольцами защиты» (на процессоре Intel обычно между «кольцом 3» и «кольцом 0»). В то время как переключение между уровнями процессора занимает всего около 100 тактов, другие связанные с этим накладные расходы, как правило, делают вызовы ядра намного более дорогими, поэтому обычный вызов ядра занимает не менее 1000-1500 тактов процессора [Wikipedia.ProtectionRing].
Исключения C++
В наши дни про исключения C++ говорят, что они ничего не стоят до тех пор, пока не сработают. Действительно ли ничего — все еще не на 100% ясно (ИМО даже не ясно, может ли вообще задаваться такой вопрос), но он, безусловно, очень близок.
Тем не менее, эти «беззатратные пока не сработавшие» реализации стоят за огромной кучей работы, которая должна выполняться всякий раз, когда возникает исключение. Все согласны с тем, что стоимость брошенного исключения огромна, однако (как обычно) экспериментальных данных мало. Тем не менее, эксперимент [Ongaro] дает нам примерное количество около 5000 тактов процессора (чума!). Более того, в более сложных случаях я бы ожидал, что это число будет еще больше.
Возврат ошибки и проверка
Временная альтернатива исключениям — это возврат кодов ошибок и проверка их на каждом уровне. Хотя у меня нет ссылок на измерения производительности такого рода, мы уже знаем достаточно, чтобы сделать разумный эксперимент. Давайте подробнее рассмотрим его (мы не очень заботимся о производительности в случае возникновения ошибки, поэтому сосредоточимся на оценке, когда все в порядке).
В принципе, стоимость возврата-и-проверки состоит из трех отдельных стоимостей. Первая из них — это стоимость самого условного перехода, и мы можем с уверенностью предположить, что в 99+% случаев он будет предсказан правильно; это означает, что стоимость условного перехода в этом случае составляет около 1-2 тактов. Вторая стоимость — это затраты на копирование кода ошибки, и до тех пор, пока он остается в пределах регистров, это простое MOV, которое при данных обстоятельствах составляет от 0 до 1 такта (0 тактов означает, что MOV не имеет дополнительную стоимость, поскольку она выполняется параллельно с некоторыми другими операциями). Третья стоимость гораздо менее очевидна — это стоимость дополнительного регистра, необходимого для переноса кода ошибки; если мы вышли из регистров — нам понадобится пара PUSH/POP (или разумная факсимиле), которая, в свою очередь запись + чтение L1 или 1 + 4 такта. С другой стороны, давайте иметь в виду, что шансы PUSH/POP быть необходимыми, варьируются от одной платформы к другой; например, на x86 любая реалистическая функция потребует их почти наверняка; однако на x64 (у которого есть двойное число регистров) вероятность того, что PUSH/POP будут необходимы, значительно снизится (и в довольно многих случаях, даже если регистр не является полностью свободным, компилятор сделать его доступным дешевле, чем тривиальный PUSH/POP).
Объединив все три стоимости, я бы оценил затраты на возврат-кода-ошибки-и-проверку (в нормальном случае) в пределах от 1 до 7 тактов ЦП. Это, в свою очередь, означает, что если у нас есть одно исключение на 10000 вызовов функций, нам, вероятно, будет лучше с исключениями; однако, если у нас есть одно исключение на 100 вызовов функций, нам, вероятно, будем лучше с кодами ошибок. Другими словами, мы только что подтвердили очень хорошо известную передовую практику — «используйте исключения только для ненормальных ситуаций».
Переключения контекста потока
Последнее, но, конечно, не менее важное, нам нужно поговорить о стоимости переключения контекста потока. Одна из проблем с их оценкой заключается в том, что их очень сложно понять. Общая мудрость говорит, что они «чертовски дороги» (эй, должна же быть причина, почему nginx превосходит Apache), но насколько это «чертовски дорого»?
Из моих личных наблюдений цена составляла не менее 10000 тактов ЦП; однако есть много источников, которые дают НАМНОГО более низкие цифры. Фактически, однако, речь идет о том, «что именно мы пытаемся измерить». Как отмечено в [LiEtAl], существуют две разные стоимости по отношению к переключениям контекста.
Подытожим
Фух, было сделано довольно много работы, чтобы найти ссылки на все эти более или менее известные наблюдения.
Также учтите, что, хотя я честно пытался собрать все связанные цены в одном месте (проверяя сторонние выводы на моем собственном опыте в процессе), это всего лишь первая попытка, поэтому, если вы найдете достаточно убедительные доказательство того, что что-то неправильно — сообщите мне, я буду рад сделать диаграмму более точной.
THE END
Как всегда ждём тапков, вопросов в комментариях или на Дне открытых дверей
Инфографика:
Когда нам нужно оптимизировать код, мы должны отпрофилировать его и упростить. Однако, иногда имеет смысл просто узнать приблизительную стоимость некоторых популярных операций, чтобы не делать с самого начала неэффективных вещей (и, надеюсь, не профилировать программу позже).
Итак, вот она — инфографика, которая должна помочь оценить стоимость конкретных операций в тактах ЦП — и ответить на такие вопросы, как “эй, сколько обычно стоит операция чтения L2?”. Хотя ответы на все эти вопросы более или менее известны, я не знаю ни одного места, где все они перечислены и представлены в перспективе. Также отметим, что, хотя перечисленные стоимости, строго говоря, применяются только к современным процессорам x86/x64, ожидается, что аналогичное отношение стоимостей будут наблюдаться на других современных процессорах с большими многоуровневыми кэшами (такими как ARM Cortex A или SPARC); с другой стороны, MCU (включая ARM Cortex M) достаточно отличны, чтобы некоторые из закономерностей могли быть к ним не применимы.
И последнее, но не менее важное, предостережение: все оценки здесь лишь указывают на порядок; однако, учитывая масштаб различий между различными операциями, эти показания могут по-прежнему использоваться (по крайней мере, следует помнить, что нужно избегать «преждевременной пессимизации»).
С другой стороны, я все еще уверен, что такая диаграмма полезна, чтобы не говорить «эй, вызовы виртуальных функций ничего не стоят» — что может быть или не быть истинным в зависимости от того, как часто вы их вызываете. Вместо этого, используя инфографику выше, вы сможете увидеть, что если вы вызовете свою виртуальную функцию 100K раз в секунду на процессоре с частотой 3 ГГц — это, вероятно, не будет стоить вам более 0,2% от общего объема вашего процессора; однако, если вы вызываете одну и ту же виртуальную функцию 10M раз в секунду, это легко может означать, что виртуализация поглощает двузначные проценты ядра вашего процессора.
Другой способ приблизиться к тому же вопросу — сказать «эй, я вызываю виртуальную функцию один раз за кусок кода, который составляет 10000 тактов, поэтому виртуализация не будет потреблять более 1% от времени программы», — но вам все равно нужен какой-то способ увидеть порядок величины связанных затрат — и приведенная выше диаграмма по-прежнему будет полезна.
Теперь давайте более подробно рассмотрим пункты в нашей инфографике выше.
Операции ALU и FPU
Для наших целей, говоря об операциях ALU, мы будем рассматривать только операции типа регистр-регистр. Если задействована память, затраты могут быть ОЧЕНЬ разными — это будет зависеть от того, “насколько велик был промах кэша” при доступе к памяти, как описано ниже.
“Простые” операции
В наши дни (и на современных процессорах), «простые» операции, такие как ADD/MOV/OR/..., могут легко выполняться быстрее одного такта ЦП. Это не означает, что операция будет выполняться буквально в течение половины такта. Напротив — в то время, как все операции все еще выполняются за целое число тактов, некоторые из них могут выполняться параллельно.
В [Agner4] (который, кстати, ИМХО является лучшим справочным руководством по оценке операций процессора) эта особенность отражается в наличии двух величин характеризующих каждую операцию: одна — это задержка (которая всегда представлена целым числом тактов), а другая — производительность. Следует отметить, однако, что в реальном мире, когда выходят за рамки оценок порядка, точное время будет сильно зависеть от характера вашей программы и от порядка, в котором компилятор поставил, казалось бы, несвязанные инструкции; вкратце — если вам нужно что-то лучше, чем порядок ожидания, вам нужно профилировать свою конкретную программу, скомпилированную вашим конкретным компилятором (и в идеале — на конкретном целевом процессоре тоже).
Дальнейшее обсуждение таких методов (известных как «внеочередное исполнение»), будучи Действительно Интересным, будет слишком аппаратно-ориентированным (как насчет «именования регистра», которое происходит под капотом процессора, чтобы уменьшить количество зависимостей, которые снижают эффективность работы внеочередного порядка?), и явно не входит в область нашего внимания в настоящий момент.
Целочисленное умножение/деление
Целочисленное умножение/деление достаточно дорогое по сравнению с «простыми» операциями выше. [Agner4] оценивает стоимость 32/64-битного умножения (MUL/IMUL в мире x86/x64) в 1-7 тактов (на практике я наблюдал более узкий диапазон значений, например 3-6 тактов), и стоимость 32/64-разрядного деления (известного как DIV/IDIV на x86/64) — около 12-44 тактов.
Операции с плавающей запятой
Стоимость операций с плавающей запятой взята из [Agner4] и варьируется от 1-3 тактов ЦП для сложения (FADD/FSUB) и 2-5 тактов для умножения (FMUL) до 37-39 тактов для деления (FDIV).
Если использовать скалярные SSE-операции (которыми, по-видимому, пользуется “каждая собака” в наши дни), показатели уменьшаться до 0,5-5 тактов для умножения (MULSS/MULSD) и до 1-40 тактов для деления (DIVSS/DIVSD); на практике, однако, вы должны ожидать скорее 10-40 тактов для деления (1 такт — это «взаимная пропускная способность», что на практике редко реализуется).
128-битные векторные операции
В течении уже нескольких лет ЦП поддерживают «векторные» операции (точнее — операции множественных данных Single Instruction Multiple Data или SIMD); в мире Intel они известны как SSE и AVX и в мире ARM — как ARM Neon. Забавно, что они работают с «векторами» данных, причем данные имеют одинаковый размер (128 бит для SSE2-SSE4, 256 бит для AVX и AVX2 и 512 бит для предстоящего AVX-512), но интерпретировать их можно по-разному. Например, 128-битный регистр SSE2 может быть интерпретирован как (a) два double, (b) четыре float, © два 64-битных integer, (d) четыре 32-битных integer, (e) восемь 16-битных integer, (f) шестнадцать 8-битных integer.
[Agner4] оценивает целочисленное сложение над 128-битным вектором в < 1 такт, если вектор интерпретируется как 4 × 32-битных целых числа и в 4 такта, если это 2 × 64-битных целых числа; умножение (4 × 32 бита) оценивается в 1-5 тактов — и в последний раз, когда я проверял, не было операций целочисленного векторного деления в наборе команд x86/x64. Операций с плавающей запятой над 128-битными векторами оцениваются от 1-3 тактов ЦП для сложения и 1-7 тактов ЦП для умножения, для деления до 17-69 тактов.
Задержки перехода
Не такая очевидная вещь, связанная с затратами на вычисления, заключается в том, что переключение между целыми и плавающими инструкциями не бесплатно. [Agner3] оценивает эту стоимость (известную как «задержка перехода») в 0-3 такта в зависимости от процессора. На самом деле проблема более общая, и (в зависимости от ЦП) также могут быть штрафы за переключение между векторными (SSE) целочисленными инструкциями и обычными (скалярными) целочисленными инструкциями.
Совет по оптимизации: в коде, для которого критична производительность, избегайте комбинирования вычислений с плавающей запятой и целыми числами.
Ветвление
Следующее, что мы будем обсуждать, — это ветвление кода. Переход (if внутри вашей программы), по сути, является сравнением и изменением в счетчике команд. В то время как обе эти вещи просты, ветвление может быть достаточно затратным. Обсуждение, почему это так, опять получится слишком аппаратно-ориентированным (в частности, это затрагивает конвейерную обработку и спекулятивное исполнение), но с точки зрения разработчика программного обеспечения это выглядит так:
- если процессор правильно угадывает, куда будет направлено выполнение (это до фактического вычисления условия if), тогда стоимость перехода составляет около 1-2 тактов ЦП
- однако, если процессор делает неправильное предположение — это приводит к тому, что ЦП «глохнет»
Продолжительность этой задержки оценивается в 10-20 тактов процессора, для последних процессоров Intel — около 15-20 тактов [Agner3].
Отметим, что в то время как макрос GCC __builtin_expect(), как полагают, влияет на предсказание ветвления — и он работал таким образом всего 15 лет назад, он больше не актуален, по крайней мере, для процессоров Intel (начиная с Core 2 или около того).
Как описано в [Agner3], на современных Intel-процессорах предсказание перехода всегда динамично (или, по крайней мере, доминируют динамические решения); это, в свою очередь, подразумевает, что ожидаемые отклонения от кода __builtin_expect() не будут влиять на предсказание переходов (на современных процессорах Intel). Однако __builtin_expect() все еще влияет на способ генерации кода, как описано в разделе «Доступ к памяти» ниже.
Доступ к памяти
В 80-е годы скорость процессора была сопоставима с задержкой памяти (например, процессор Z80, работающий на частоте 4 МГц, тратил 4 такта на команду типа регистр-регистр и 6 тактов на команду типа регистр-память). В то время можно было вычислить скорость программы, просто посмотрев на сборку.
С тех пор скорости процессоров выросли на 3 порядка, а задержки памяти улучшились только в 10-30 раз или около того. Чтобы справиться с оставшимся более чем тридцати кратным несоответствием, были введены все эти виды кэшей. Современный процессор обычно имеет 3 уровня кэшей. В результате скорость доступа к памяти очень сильно зависит от ответа на вопрос «где хранятся данные, которые мы пытаемся прочитать?». Чем ниже уровень кэша, где был найден ваш запрос, тем быстрее вы можете его получить.
Время доступа к кэшу L1 и L2 можно найти в официальных документациях, таких как [Intel.Skylake]; он оценивает время доступа к L1 / L2 / L3 в 4/12/44 такта процессора соответственно (обратите внимание: эти цифры немного варьируются от одной модели процессора к другой). Вообще, как упоминается в [Levinthal], время доступа к L3 может достигать 75 тактов, если кэш совместно используется с другим ядром.
Однако, что сложнее найти, так это информацию о времени доступа к основной ОЗУ. [Levinthal] оценивает его в 60нс (~ 180 тактов, если процессор работает на частоте 3ГГц).
Совет по оптимизации: улучшайте локальность данных. Подробнее об этом см., например, [NoBugs].
Помимо чтения из памяти, есть также запись. В то время как запись интуитивно воспринимается как более дорогая, чем чтение, чаще всего это не так; причина для этого проста: процессору не нужно ждать завершения записи перед тем, как идти вперед (вместо этого он только начинает писать — и сразу переходит к другим делам). Это означает, что большую часть времени процессор может выполнять запись в 1 такт; это согласуется с моим опытом и, по-видимому, достаточно хорошо коррелирует с [Agner4]. С другой стороны, если ваша система завязана на пропускной способности памяти, цифры могут получиться ЧРЕЗВЫЧАЙНО высокие; все же, из того, что я видел, перегрузка шины операциями записи является очень редким явлением, поэтому я не отразил его на диаграмме.
Еще помимо данных, есть и код.
Еще один совет по оптимизации: постарайтесь улучшить также и локальность кода. Это менее очевидно (и, как правило, оказывает меньшее влияние на производительность, чем плохая локализация данных). Обсуждение способов улучшения локальности кода можно найти в [Drepper]; эти способы включают такие вещи, как inlining, и __builtin_expect().
Следует отметить, что хотя __builtin_expect(), как упоминалось выше, больше не влияет на предсказание переходов на процессорах Intel, она все равно влияет на разметку кода, что, в свою очередь, влияет на пространственную локальность кода. В результате __builtin_expect() не имеет эффектов, которые слишком выражены на современных процессорах Intel (на ARM — понятия не имею, если быть честным), но все равно может повлиять на производительность в той или иной степени. Также сообщалось, что под MSVC замена if и else переходов условного оператора имеет эффекты, сходные с __builtin_expect() (если предполагаемый переход является if-переходом условного оператора с двумя переходами), но к этому следует относится с сомнением.
NUMA (Архитектура с неравномерной памятью)
Еще одна вещь, связанная с доступом к памяти и производительностью, редко наблюдается на настольных компьютерах (так как для этого требуются многопроцессорные машины — не следует путать с многоядерными). Таким образом, это, в основном, серверная парафия; однако это существенно влияет на время доступа к памяти.
Когда задействованы несколько сокетов, современные процессоры имеют тенденцию реализовывать так называемую архитектуру NUMA, причем каждый процессор (где «процессор» = «эта штука, вставленная в сокет») имеет свою собственную ОЗУ (в отличие от архитектуры FSB более раннего возраста с общей FSB aka Front-Side Bus и общая оперативная память). Несмотря на то, что каждый процессор имеет собственную ОЗУ, ЦП совместно используют адресное пространство ОЗУ — и всякий раз, когда требуется доступ к ОЗУ, физически находящемуся в другом, это делается путем отправки запроса на другой сокет через сверхбыстрый протокол, такой как QPI или Hypertransport.
Удивительно, но это не так долго, как вы могли бы ожидать — [Levinthal] дает 100-300 тактов ЦП, если данные были в кэше L3 удаленного процессора и 100нс (~ = 300 тактов), если данные были не там, и удаленный процессор должен был перейти в свою основную ОЗУ для этих данных.
CAS (сравнение с обменом)
Иногда (в частности, в неблокирующих алгоритмах и при реализации мьютексов) мы хотим использовать так называемые атомарные операции. Академически обычно рассматривается только одна атомарная операция, известная как CAS (Compare-And-Swap — сравнение с обменом) (на том основании, что все остальное может быть реализовано через CAS); в реальном мире их обычно больше (см., например, std::atomic в C++ 11, Interlocked*() в Windows или __sync _*_ и _*() в GCC/Linux). Эти операции — довольно странные звери: в частности, им нужна специальная поддержка ЦП для правильной работы. В x86 / x64 соответствующие инструкции ASM характеризуются наличием префикса LOCK, поэтому CAS на x86 / x64 обычно записывается как LOCK CMPXCHG.
С нашей нынешней точки зрения важно то, что эти операции, подобные CAS, будут выполняться значительно дольше обычного доступа к памяти (чтобы гарантировать атомарность, процессор должен синхронизировать процессы, по крайней мере, между разными ядрами, или в случае мультисокетных конфигураций, также между различными сокетами).
[AlBahra] оценивает стоимость операций CAS примерно в 15-30 тактов (с небольшой разницей между семействами x86 и IBM Power). Стоит отметить, что это число обоснованно только при выполнении двух допущений: (а) мы работаем с одноядерной конфигурацией и (б), что сравниваемая память уже находится в L1.
Касательно затрат CAS в мультисокетных NUMA-конфигурациях, я не смог найти данные о CAS, поэтому мне пока не обойтись без спекуляций. С одной стороны, ИМХО будет почти невозможным иметь задержки работы CAS на «удаленной» памяти меньше, чем кругооборот HyperTransport между сокетами, что в свою очередь сопоставимо со стоимостью чтения NUMA кэша L3.
С другой стороны, я действительно не вижу причин, чтобы превысить эти показатели :-). В результате я оцениваю стоимость NUMA раздельных CAS (и CAS-подобных) операций в 100-300 тактов ЦП.
TLB (Буфер ассоциативной трансляции)
Всякий раз, когда мы работаем с современными процессорами и современными ОС, на уровне приложений мы обычно имеем дело с «виртуальным» адресным пространством; другими словами, если мы запускаем 10 процессов, каждый из этих процессов может (и, вероятно, будет) иметь свой собственный адрес 0x00000000. Для поддержки такой изоляции процессоры реализуют так называемую «виртуальную память». В мире x86 она была впервые реализована через «защищенный режим», введенный еще в 1982 году на 80286.
Обычно «виртуальная память» работает постранично (для x86 каждая страница имеет размер либо 4K, либо 2M или, по крайней мере, теоретически, даже 1G (!)), когда ЦП знает какой процесс выполняется (!), и переразмечает виртуальные адреса на физические адреса при каждом доступе к памяти. Обратите внимание, что эта повторная разметка происходит полностью за кулисами, в том смысле, что все регистры процессора (кроме тех, которые имеют дело с разметкой) содержат все указатели в формате «виртуальной памяти».
И раз уж мы заговорили о «разметке» — ну, информация об этой разметке должна быть где-то сохранена. Более того, поскольку эта разметка (из виртуальных адресов в физические) происходит при каждом доступе к памяти, это должно быть Чертовски Быстро. Для этого обычно используется специальный вид кэша, называемый Буфер ассоциативной трансляции (TLB).
Так же как и для любого типа кэша, существует стоимость промаха TLB; для x64 она колеблется между 7-21 тактами ЦП [7cpu]. В целом, на TLB довольно сложно повлиять; однако здесь еще можно дать несколько рекомендаций:
- еще раз — улучшение общей локальности памяти помогает уменьшить промахи TLB; чем локальнее ваши данные, тем меньше шансов выйти из TLB.
- рассмотрите возможность использования «больших страниц» (те 2 MБ страницы на x64). Чем больше страницы, тем меньше записей в TLB вам понадобится; с другой стороны, использовать «больший страницы» нужно с осторожностью, это палка о двух концах. Это означает, что вам нужно протестировать его для своего конкретного приложения.
- рассмотрите возможность отключения ASLR (=«рандомизация размещения адресного пространства»). Как обсуждалось в [Drepper], в то время как включение ASLR хорошо для безопасности, оно убивает производительность, и в том числе именно из-за промахов TLB .
Примитивы программного обеспечения
Теперь мы закончили с теми вещами, которые напрямую связаны с “железом”, и будем говорить о некоторых вещах, связанных с программным обеспечением; они действительно все еще повсюду встречаются, поэтому давайте посмотрим, сколько мы тратим каждый раз, когда используем их.
Вызовы функций в С/С++
Сначала давайте рассмотрим стоимость вызова функций в C/C++. На самом деле, то, что вызывает функции в C/C++ делает чертовски много дел перед вызовом, и вызываемое тоже не сидит сложа руки.
[Efficient C++] оценивает затраты ЦП для вызова функции в 25-250 тактов в зависимости от количества параметров; однако, это довольно старая книга, а у меня нет лучшей ссылки того же калибра. С другой стороны, по моему опыту, для функции с достаточно небольшим числом параметров это скорее будет 15-30 тактов; это также, по-видимому, относится к процессорам, отличным от Intel, как выяснил [eruskin].
Совет по оптимизации: используйте inline-функции, где это применимо. Однако имейте в виду, что в наши дни компиляторы чаще всего игнорируют встраиваемые спецификации. Поэтому для действительно критически важных фрагментов кода вы можете использовать __attribute __ ((always_inline)) для GCC и __forceinline для MSVC, чтобы заставить их делать то, что вам нужно. Тем не менее, НЕ используйте эти принудительные inline для не очень критических фрагментов кода, это может сделать намного хуже.
Кстати, во многих случаях выигрыш от встраивания может превышать стоимость простого удаления вызова. Это происходит из-за того, что встраивание обеспечивает довольно много дополнительных оптимизаций (в том числе связанных с переупорядочением для обеспечения правильного использования аппаратного конвейера). Также давайте не будем забывать, что встраивание улучшает пространственную локальность для кода, что также немного помогает (см., например, [Drepper]).
Косвенные и виртуальные вызовы
Дискуссия выше была связана с обычными («прямыми») вызовами функций. Стоимость косвенных и виртуальных вызовов, как известно, выше, и многие согласны с тем, что косвенный вызов вызывает ветвление (однако, как отмечает [Agner1], до тех пор, пока вы вызываете одну и ту же функцию из одной и той же точки кода, механизмы предсказания переходов современных процессоров могут предсказать это довольно хорошо, в противном случае, вы получите штраф за ложное предсказание в 10-30 тактов). Что касается виртуальных вызовов — это одно дополнительное чтение (чтение указателя VMT), поэтому, если в этот момент все кэшируется (как обычно и есть), мы говорим о дополнительных 4 тактах процессора или около того.
С другой стороны, практические измерения [eruskin] показывают, что стоимость виртуальных функций примерно вдвое меньше стоимости прямых вызовов для небольших функций; в пределах нашей погрешности (которая является «порядком») это вполне согласуется с вышеприведенным анализом.
Совет по оптимизации: если ваши виртуальные вызовы стоят дорого, вместо этого в C++ вы можете подумать об использовании шаблонов (реализация так называемого полиморфизма времени компиляции); CRTP — это один (хотя и не единственный) способ сделать это.
Аллокации
В наши дни аллокаторы как таковые могут быть довольно быстрыми; в частности, аллокаторы tcmalloc и ptmalloc2 могут потратить всего 200-500 тактов ЦП для выделения/освобождения небольшого объекта [TCMalloc].
Тем не менее, есть существенное предостережение, связанное с аллокацией, и добавление к косвенным затратам на использование аллокаций: аллокация, как старое доброе правило большого пальца, означает уменьшение локальности памяти, что, в свою очередь, отрицательно влияет на производительность (из-за взаимодействий с незакэшированной памятью, описанных выше). Чтобы проиллюстрировать, насколько это плохо на практике, мы можем взглянуть на 20-строчную программу в [NoBugs]; эта программа при использовании vector<> выполняется от 100 до 780 раз быстрее (в зависимости от компилятора и конкретного поля), чем эквивалентная программа, использующая list<> — все из-за плохой локальности памяти последнего :-(.
Совет по оптимизации: думайте о сокращении количества аллокаций в ваших программах, особенно если есть этап, когда большая часть работы выполняется с данными только для чтения. В некоторых реальных случаях сглаживание ваших структур данных (т.е. замена выделенных объектов упакованными) может ускорить вашу программу до 5 раз.
Реальная история по теме. Когда-то давным-давно была программа, в которой использовались гигабайты оперативной памяти, что считалось слишком большим; окей, я переписал ее в «сплющенную» версию (то есть каждый узел был сначала сконструирован динамически, а затем в памяти был создан эквивалентный «сплющенный» объект только для чтения); идея «сглаживания» заключалась в уменьшении объема памяти. Когда мы запускали программу, мы заметили, что не только объем памяти уменьшился в 2 раза (что и было тем, что мы ожидали), но также, как очень хороший побочный эффект, скорость выполнения увеличилась в 5 раз.
Вызовы ядра ОС
Если наша программа работает под операционной системой (да, есть еще программы, которые работают без нее), то у нас есть целая группа системных API. На практике (по крайней мере, если мы говорим о более или менее обычной ОС) многие из этих системных вызовов приводят к вызовам ядра, которые включают в себя переключения в режим ядра и обратно; это включает в себя переключение между различными «кольцами защиты» (на процессоре Intel обычно между «кольцом 3» и «кольцом 0»). В то время как переключение между уровнями процессора занимает всего около 100 тактов, другие связанные с этим накладные расходы, как правило, делают вызовы ядра намного более дорогими, поэтому обычный вызов ядра занимает не менее 1000-1500 тактов процессора [Wikipedia.ProtectionRing].
Исключения C++
В наши дни про исключения C++ говорят, что они ничего не стоят до тех пор, пока не сработают. Действительно ли ничего — все еще не на 100% ясно (ИМО даже не ясно, может ли вообще задаваться такой вопрос), но он, безусловно, очень близок.
Тем не менее, эти «беззатратные пока не сработавшие» реализации стоят за огромной кучей работы, которая должна выполняться всякий раз, когда возникает исключение. Все согласны с тем, что стоимость брошенного исключения огромна, однако (как обычно) экспериментальных данных мало. Тем не менее, эксперимент [Ongaro] дает нам примерное количество около 5000 тактов процессора (чума!). Более того, в более сложных случаях я бы ожидал, что это число будет еще больше.
Возврат ошибки и проверка
Временная альтернатива исключениям — это возврат кодов ошибок и проверка их на каждом уровне. Хотя у меня нет ссылок на измерения производительности такого рода, мы уже знаем достаточно, чтобы сделать разумный эксперимент. Давайте подробнее рассмотрим его (мы не очень заботимся о производительности в случае возникновения ошибки, поэтому сосредоточимся на оценке, когда все в порядке).
В принципе, стоимость возврата-и-проверки состоит из трех отдельных стоимостей. Первая из них — это стоимость самого условного перехода, и мы можем с уверенностью предположить, что в 99+% случаев он будет предсказан правильно; это означает, что стоимость условного перехода в этом случае составляет около 1-2 тактов. Вторая стоимость — это затраты на копирование кода ошибки, и до тех пор, пока он остается в пределах регистров, это простое MOV, которое при данных обстоятельствах составляет от 0 до 1 такта (0 тактов означает, что MOV не имеет дополнительную стоимость, поскольку она выполняется параллельно с некоторыми другими операциями). Третья стоимость гораздо менее очевидна — это стоимость дополнительного регистра, необходимого для переноса кода ошибки; если мы вышли из регистров — нам понадобится пара PUSH/POP (или разумная факсимиле), которая, в свою очередь запись + чтение L1 или 1 + 4 такта. С другой стороны, давайте иметь в виду, что шансы PUSH/POP быть необходимыми, варьируются от одной платформы к другой; например, на x86 любая реалистическая функция потребует их почти наверняка; однако на x64 (у которого есть двойное число регистров) вероятность того, что PUSH/POP будут необходимы, значительно снизится (и в довольно многих случаях, даже если регистр не является полностью свободным, компилятор сделать его доступным дешевле, чем тривиальный PUSH/POP).
Объединив все три стоимости, я бы оценил затраты на возврат-кода-ошибки-и-проверку (в нормальном случае) в пределах от 1 до 7 тактов ЦП. Это, в свою очередь, означает, что если у нас есть одно исключение на 10000 вызовов функций, нам, вероятно, будет лучше с исключениями; однако, если у нас есть одно исключение на 100 вызовов функций, нам, вероятно, будем лучше с кодами ошибок. Другими словами, мы только что подтвердили очень хорошо известную передовую практику — «используйте исключения только для ненормальных ситуаций».
Переключения контекста потока
Последнее, но, конечно, не менее важное, нам нужно поговорить о стоимости переключения контекста потока. Одна из проблем с их оценкой заключается в том, что их очень сложно понять. Общая мудрость говорит, что они «чертовски дороги» (эй, должна же быть причина, почему nginx превосходит Apache), но насколько это «чертовски дорого»?
Из моих личных наблюдений цена составляла не менее 10000 тактов ЦП; однако есть много источников, которые дают НАМНОГО более низкие цифры. Фактически, однако, речь идет о том, «что именно мы пытаемся измерить». Как отмечено в [LiEtAl], существуют две разные стоимости по отношению к переключениям контекста.
- Первая стоимость — прямые затраты на переключение контекста потока, и они измеряются примерно в 2000 тактов ЦП (3 то есть, если моя математика правильна при преобразовании из микросекунд в такты)
- Однако вторая стоимость намного выше; это связано с аннулированием кэша потоком; согласно [LiEtAl], он может быть примерно 3M тактов ЦП. Теоретически, с полностью случайным шаблоном доступа, современный процессор с 12M кэша L3 (и с учетом штрафа порядка 50 тактов за доступ) может вызвать задержку в 10M тактов за контекстный переключатель; однако на практике штрафы обычно несколько ниже, поэтому число 1M от [LiEtAl] имеет смысл. Эта «намного более высокая» оценка также согласуется с количеством спинлоков на x64 (по умолчанию это 4000, по крайней мере для Windows/x64): если обычно полезно ждать 4000 итераций (в сумме, по крайней мере, до 15-20 тыс. тактов ЦП и больше, чем 40-50K тактов, из моего опыта), считывая эту переменную-которая-в-настоящее-время-заблокирована в замкнутом цикле — просто в надежде, что переменная откроется до того, как закончится 4000 итераций, все эти проблемы и такты ЦП просто для того, чтобы избежать переключения контекста — это означает, что стоимость переключения контекста обычно намного выше, чем те десятки-тысяч-процессорных-тактов-которые-мы-готовы-потратить-на-замкнутый-цикл-не-делающий-ничего-полезного.
Подытожим
Фух, было сделано довольно много работы, чтобы найти ссылки на все эти более или менее известные наблюдения.
Также учтите, что, хотя я честно пытался собрать все связанные цены в одном месте (проверяя сторонние выводы на моем собственном опыте в процессе), это всего лишь первая попытка, поэтому, если вы найдете достаточно убедительные доказательство того, что что-то неправильно — сообщите мне, я буду рад сделать диаграмму более точной.
THE END
Как всегда ждём тапков, вопросов в комментариях или на Дне открытых дверей
