¡Hola! мы продолжаем серию публикаций, приуроченных к запуску курса «Web-разработчик на Python» и прямо сейчас делимся с вами переводом еще одной интересной статьи.
В Zendesk мы используем Python для создания продуктов с машинным обучением. В приложениях с использованием машинного обучения одними из самых распространенных проблем, с которыми мы столкнулись, являются утечка памяти и всплески. Код на Python обычно выполняется в контейнерах с помощью фреймворков распределенной обработки, таких как Hadoop, Spark и AWS Batch. Каждому контейнеру выделяется фиксированный объем памяти. Как только выполнение кода превысит заданное ограничение памяти, контейнер прекратит свою работу из-за ошибок, возникающих по причине нехватки памяти.

Быстро исправить проблему можно выделением еще большего количества памяти. Тем не менее, это может привести к растрачиванию ресурсов и повлиять на стабильность работы приложений из-за непредсказуемых всплесков памяти. Причины утечки памяти могут быть следующими:
Полезной практикой считается профилирование использования памяти приложениями для получения лучшего понимания об эффективности использования пространства кода и используемых пакетов.
В этой статье рассматриваются следующие аспекты:
Профилирование памяти с течением времени
Вы можете взглянуть на переменное использование памяти в течение выполнения программы на Python, используя пакет memory-profiler.
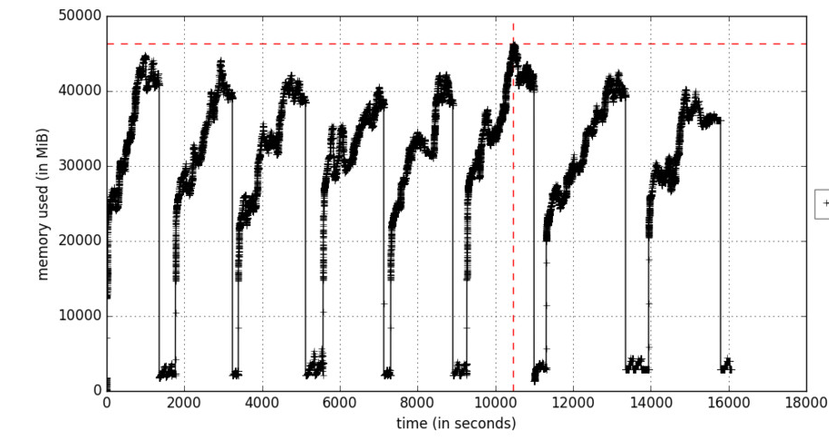
Рисунок А. Профилирование памяти, как функция от времени
Параметр include-children будет включать использование памяти любыми дочерними процессами, порожденными родительскими процессами. Рисунок А отражает итерационный процесс обучения, который вызывает увеличения памяти в циклах в те моменты, когда обрабатываются пакеты обучающих данных. Объекты удаляются во время сборки мусора.
Если использование памяти постоянно возрастает, это считается потенциальной угрозой утечки памяти. Здесь показан пример кода, отражающий это:

Рисунок В. Использование памяти, увеличивающееся со временем
Следует устанавливать точки останова в отладчике, как только использование памяти превышает определенный порог. Для этого можно пользоваться параметром pdb-mmem, который удобен во время устранения неполадок.
Дамп памяти в определенный момент времени
Полезно оценивать заранее ожидаемое количество больших объектов в программе и то, следует ли их дублировать и/или преобразовывать в различные форматы.
Для дальнейшего анализа объектов в памяти можно создавать дамп-кучу в определенных строках программы, используя muppy.
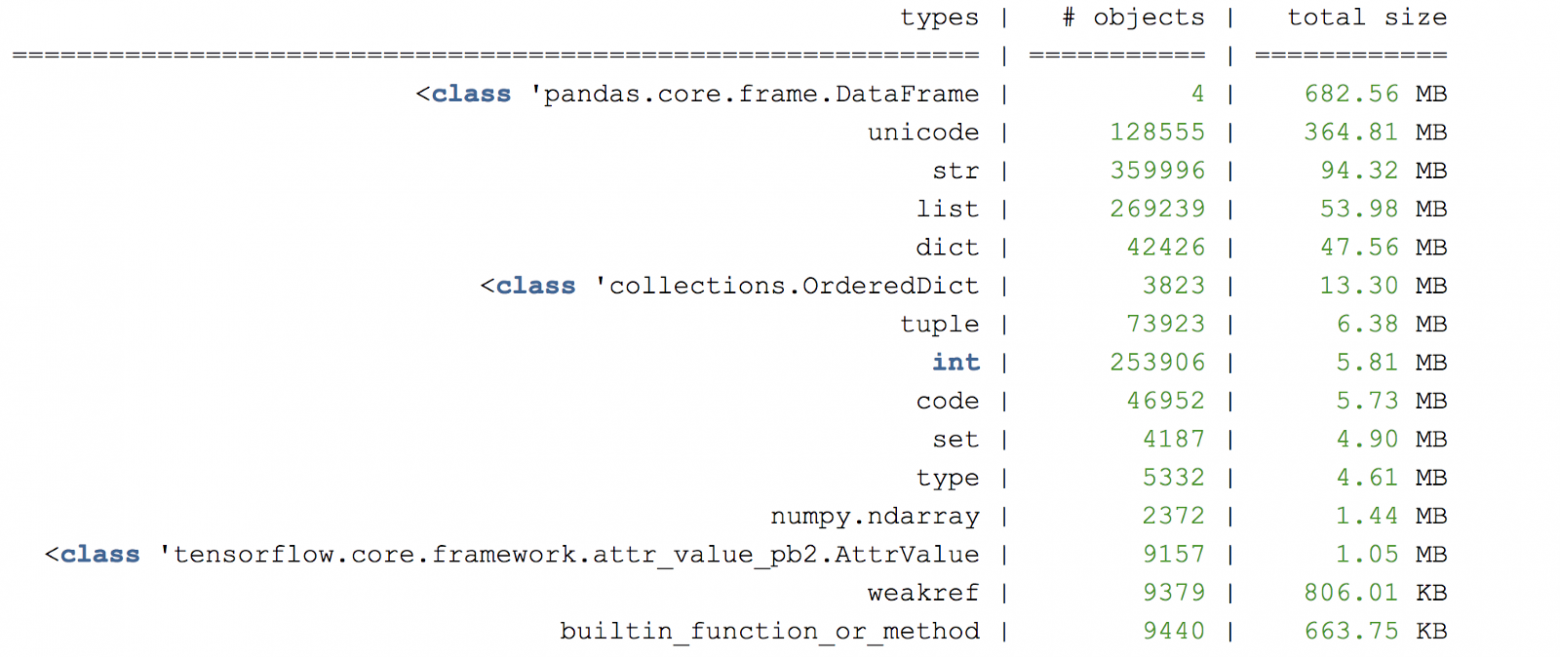
Рисунок С. Пример сводки дампа-кучи памяти
Другая полезная библиотека для профилирования памяти – это objgraph, которая позволяет генерировать графики для проверки происхождения объектов.
Полезные указатели
Полезным подходом является создание небольшого «тестового примера», который запускает соответствующий код, вызывающий утечку памяти. Рассмотрите возможность использования подмножества случайно выбранных данных, если полноценные входные данные будут заведомо долго обрабатываться.
Выполнение задач с большой загрузкой памяти в отдельном процессе
Python не обязательно освобождает память сразу же для операционной системы. Чтобы убедиться в том, что память была освобождена, после выполнения фрагмента кода необходимо запустить отдельный процесс. Больше информации о сборщике мусора в Python вы сможете узнать здесь.
Отладчик может добавлять ссылки на объекты
Если используется такой отладчик точек останова, как pdb, все созданные объекты, на которые вручную ссылается отладчик, будут оставаться в памяти. Это может создать ложное ощущение утечки памяти, поскольку объекты не удаляются своевременно.
Остерегайтесь пакетов, которые могут вызывать утечку памяти
Некоторые библиотеки в Python потенциально могут вызвать утечку, например
Приятной охоты на утечки!
Полезные ссылки:
docs.python.org/3/c-api/memory.html
docs.python.org/3/library/debug.html
Пишите в комментарии была ли эта статья полезной для вас. А тех, кто хочет подробнее узнать о нашем курсе, приглашаем на день открытых дверей, который пройдёт уже 22 апреля.
В Zendesk мы используем Python для создания продуктов с машинным обучением. В приложениях с использованием машинного обучения одними из самых распространенных проблем, с которыми мы столкнулись, являются утечка памяти и всплески. Код на Python обычно выполняется в контейнерах с помощью фреймворков распределенной обработки, таких как Hadoop, Spark и AWS Batch. Каждому контейнеру выделяется фиксированный объем памяти. Как только выполнение кода превысит заданное ограничение памяти, контейнер прекратит свою работу из-за ошибок, возникающих по причине нехватки памяти.

Быстро исправить проблему можно выделением еще большего количества памяти. Тем не менее, это может привести к растрачиванию ресурсов и повлиять на стабильность работы приложений из-за непредсказуемых всплесков памяти. Причины утечки памяти могут быть следующими:
- Затяжное хранение больших объектов, которые не удаляются;
- Циклические ссылки в коде;
- Базовые библиотеки/расширения на С, приводящие к утечке памяти;
Полезной практикой считается профилирование использования памяти приложениями для получения лучшего понимания об эффективности использования пространства кода и используемых пакетов.
В этой статье рассматриваются следующие аспекты:
- Профилирование использования памяти приложений с течением времени;
- Как проверить использование памяти в определенной части программы;
- Советы по отладке ошибок, вызванных проблемами с памятью.
Профилирование памяти с течением времени
Вы можете взглянуть на переменное использование памяти в течение выполнения программы на Python, используя пакет memory-profiler.
# install the required packages
pip install memory_profiler
pip install matplotlib
# run the profiler to record the memory usage
# sample 0.1s by defaut
mprof run --include-children python fantastic_model_building_code.py
# plot the recorded memory usage
mprof plot --output memory-profile.png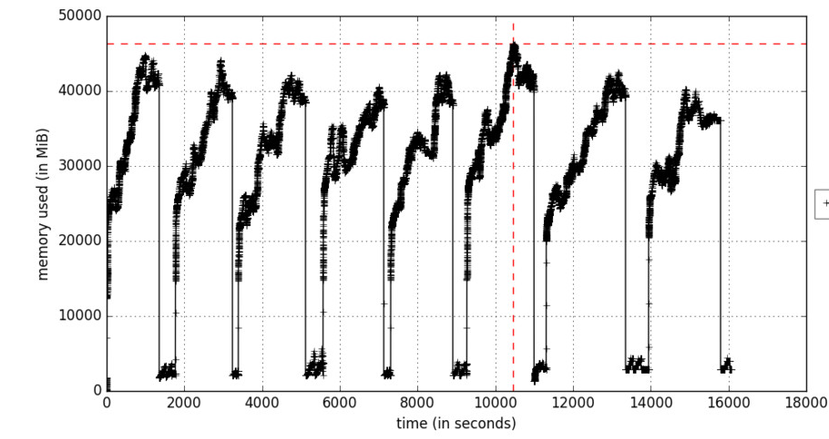
Рисунок А. Профилирование памяти, как функция от времени
Параметр include-children будет включать использование памяти любыми дочерними процессами, порожденными родительскими процессами. Рисунок А отражает итерационный процесс обучения, который вызывает увеличения памяти в циклах в те моменты, когда обрабатываются пакеты обучающих данных. Объекты удаляются во время сборки мусора.
Если использование памяти постоянно возрастает, это считается потенциальной угрозой утечки памяти. Здесь показан пример кода, отражающий это:
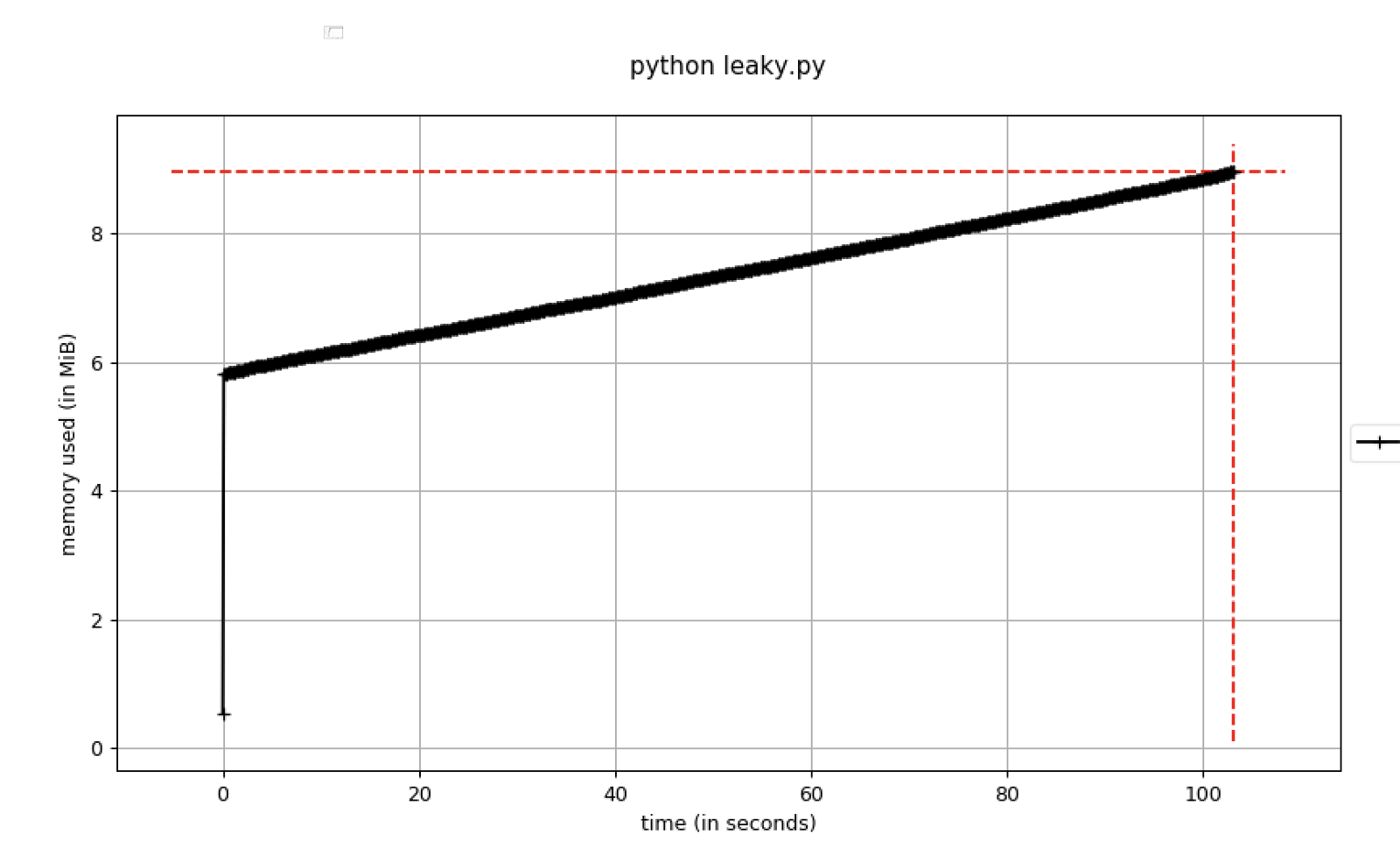
Рисунок В. Использование памяти, увеличивающееся со временем
Следует устанавливать точки останова в отладчике, как только использование памяти превышает определенный порог. Для этого можно пользоваться параметром pdb-mmem, который удобен во время устранения неполадок.
Дамп памяти в определенный момент времени
Полезно оценивать заранее ожидаемое количество больших объектов в программе и то, следует ли их дублировать и/или преобразовывать в различные форматы.
Для дальнейшего анализа объектов в памяти можно создавать дамп-кучу в определенных строках программы, используя muppy.
# install muppy
pip install pympler
# Add to leaky code within python_script_being_profiled.py
from pympler import muppy, summary
all_objects = muppy.get_objects()
sum1 = summary.summarize(all_objects)
# Prints out a summary of the large objects
summary.print_(sum1)
# Get references to certain types of objects such as dataframe
dataframes = [ao for ao in all_objects if isinstance(ao, pd.DataFrame)]
for d in dataframes:
print d.columns.values
print len(d)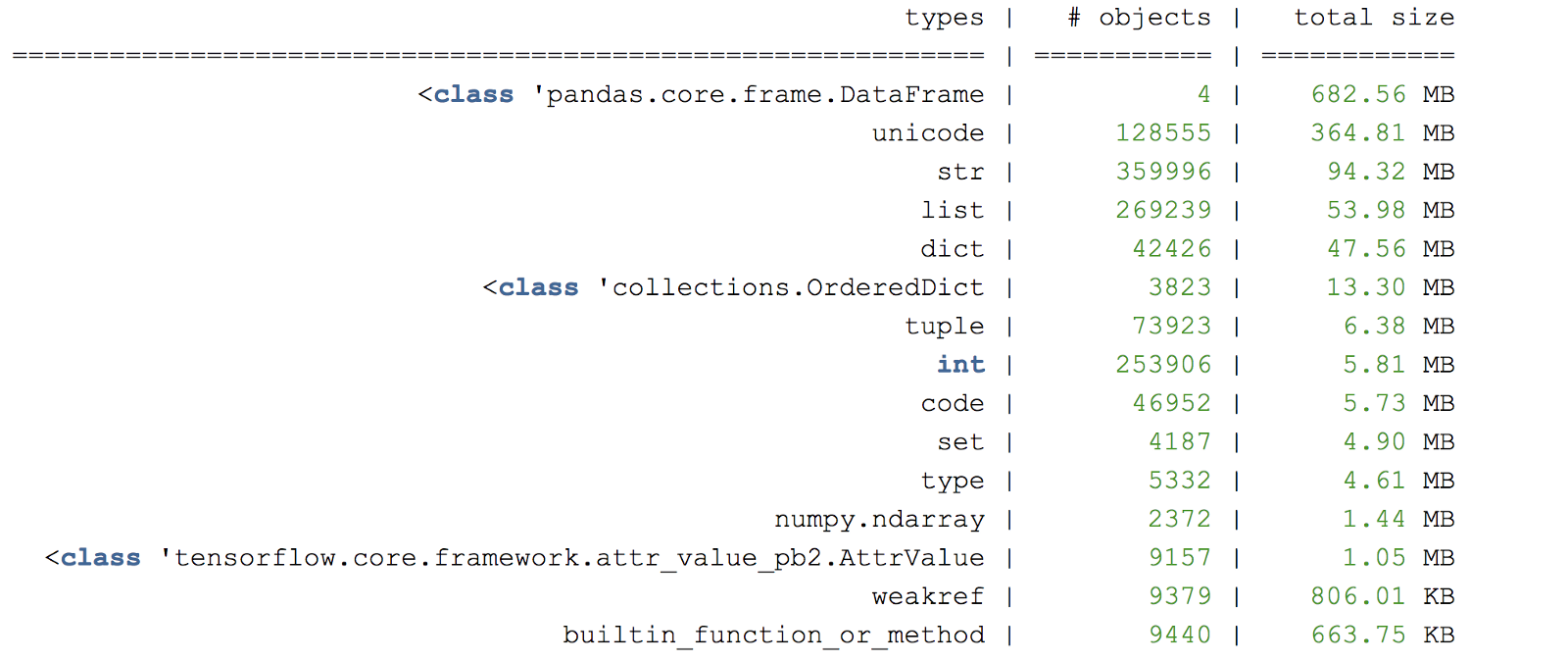
Рисунок С. Пример сводки дампа-кучи памяти
Другая полезная библиотека для профилирования памяти – это objgraph, которая позволяет генерировать графики для проверки происхождения объектов.
Полезные указатели
Полезным подходом является создание небольшого «тестового примера», который запускает соответствующий код, вызывающий утечку памяти. Рассмотрите возможность использования подмножества случайно выбранных данных, если полноценные входные данные будут заведомо долго обрабатываться.
Выполнение задач с большой загрузкой памяти в отдельном процессе
Python не обязательно освобождает память сразу же для операционной системы. Чтобы убедиться в том, что память была освобождена, после выполнения фрагмента кода необходимо запустить отдельный процесс. Больше информации о сборщике мусора в Python вы сможете узнать здесь.
Отладчик может добавлять ссылки на объекты
Если используется такой отладчик точек останова, как pdb, все созданные объекты, на которые вручную ссылается отладчик, будут оставаться в памяти. Это может создать ложное ощущение утечки памяти, поскольку объекты не удаляются своевременно.
Остерегайтесь пакетов, которые могут вызывать утечку памяти
Некоторые библиотеки в Python потенциально могут вызвать утечку, например
pandas имеет несколько известных проблем утечки памяти.Приятной охоты на утечки!
Полезные ссылки:
docs.python.org/3/c-api/memory.html
docs.python.org/3/library/debug.html
Пишите в комментарии была ли эта статья полезной для вас. А тех, кто хочет подробнее узнать о нашем курсе, приглашаем на день открытых дверей, который пройдёт уже 22 апреля.
