
На каких принципах строится идеальное Хранилище Данных?
Фокус на бизнес-ценности и аналитике при отсутствии boilerplate code. Управление DWH как кодовой базой: версионирование, ревью, автоматическое тестирование и CI. Модульность, расширяемость, открытый исходный код и сообщество. Дружественная пользовательская документация и визуализация зависимостей (Data Lineage).
Обо всём этом подробнее и о роли DBT в экосистеме Big Data & Analytics — добро пожаловать под кат.
Всем привет
На связи Артемий Козырь. Уже более 5 лет я работаю с хранилищами данных, занимаюсь построением ETL/ELT, а также аналитикой данных и визуализацией. В настоящее время я работаю в Wheely, преподаю в OTUS на курсе Data Engineer, и сегодня хочу поделиться с вами статьей, которую я написал в преддверии старта нового набора на курс.
Краткий обзор
Фреймворк DBT — это всё о букве T в акрониме ELT (Extract — Transform — Load).
С появлением таких производительных и масштабируемых аналитических баз данных как BigQuery, Redshift, Snowflake, исчез какой-либо смысл делать трансформации вне Хранилища Данных.
DBT не выгружает данные из источников, но предоставляет огромные возможности по работе с теми данными, которые уже загружены в Хранилище (в Internal или External Storage).

Основное назначение DBT — взять код, скомпилировать его в SQL, выполнить команды в правильной последовательности в Хранилище.
Структура проекта DBT
Проект состоит изиз директорий и файлов всего 2-х типов:
- Модель (.sql) — единица трансформации, выраженная SELECT-запросом
- Файл конфигурации (.yml) — параметры, настройки, тесты, документация
На базовом уровне работа строится следующим образом:
- Пользователь готовит код моделей в любой удобной IDE
- С помощью CLI вызывается запуск моделей, DBT компилирует код моделей в SQL
- Скомпилированный SQL-код исполняется в Хранилище в заданной последовательности (граф)
Вот как может выглядеть запуск из CLI:
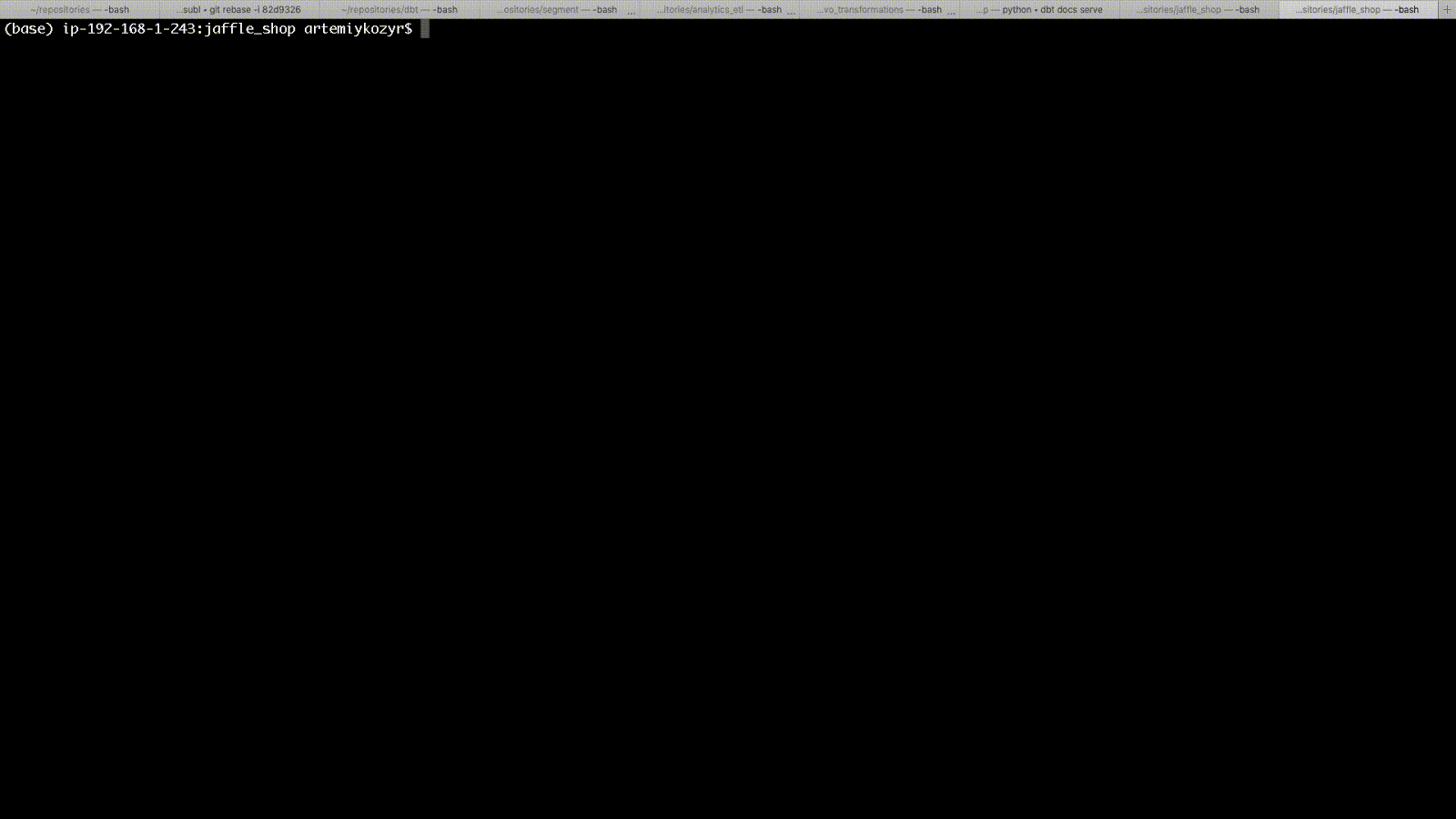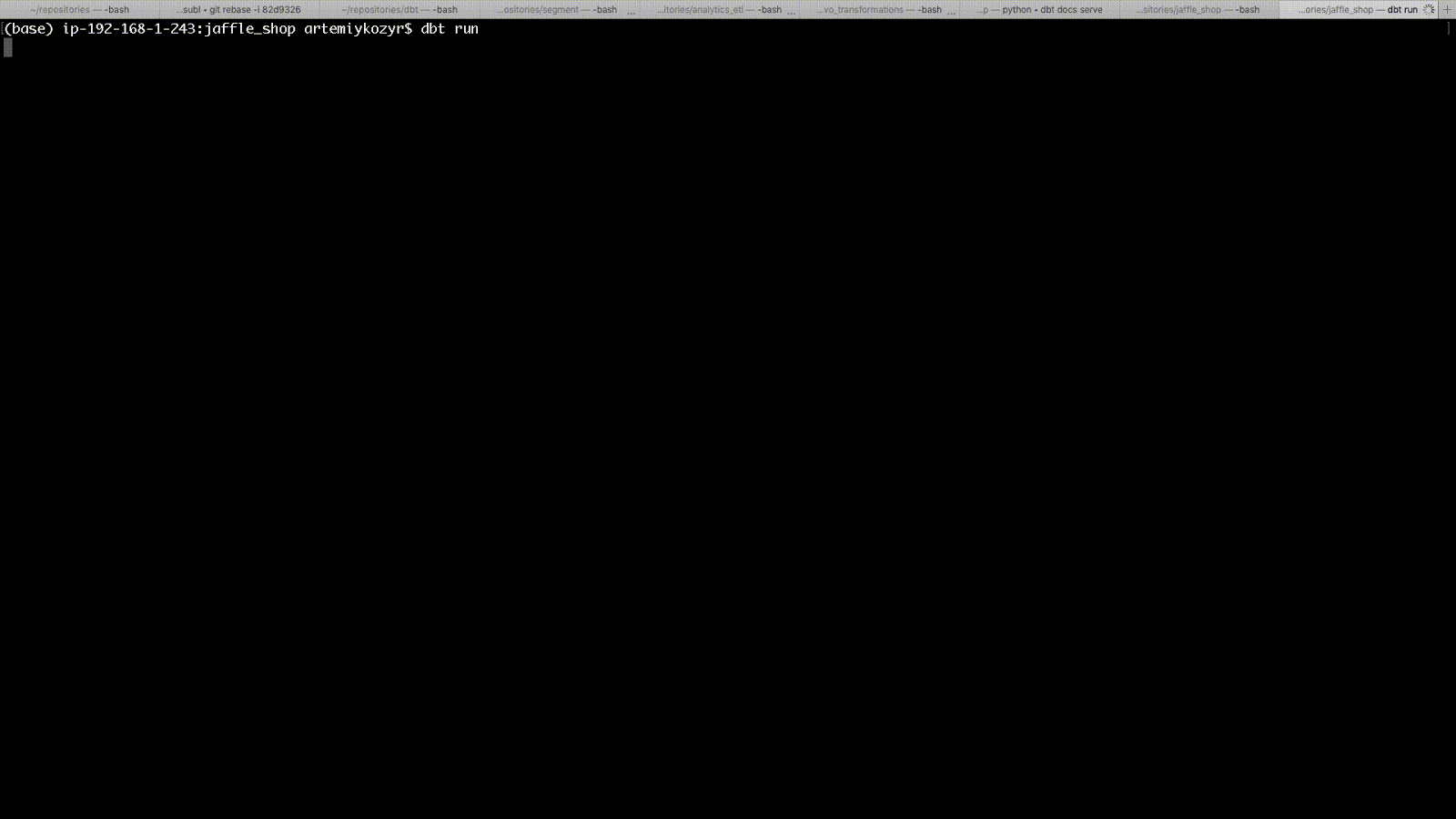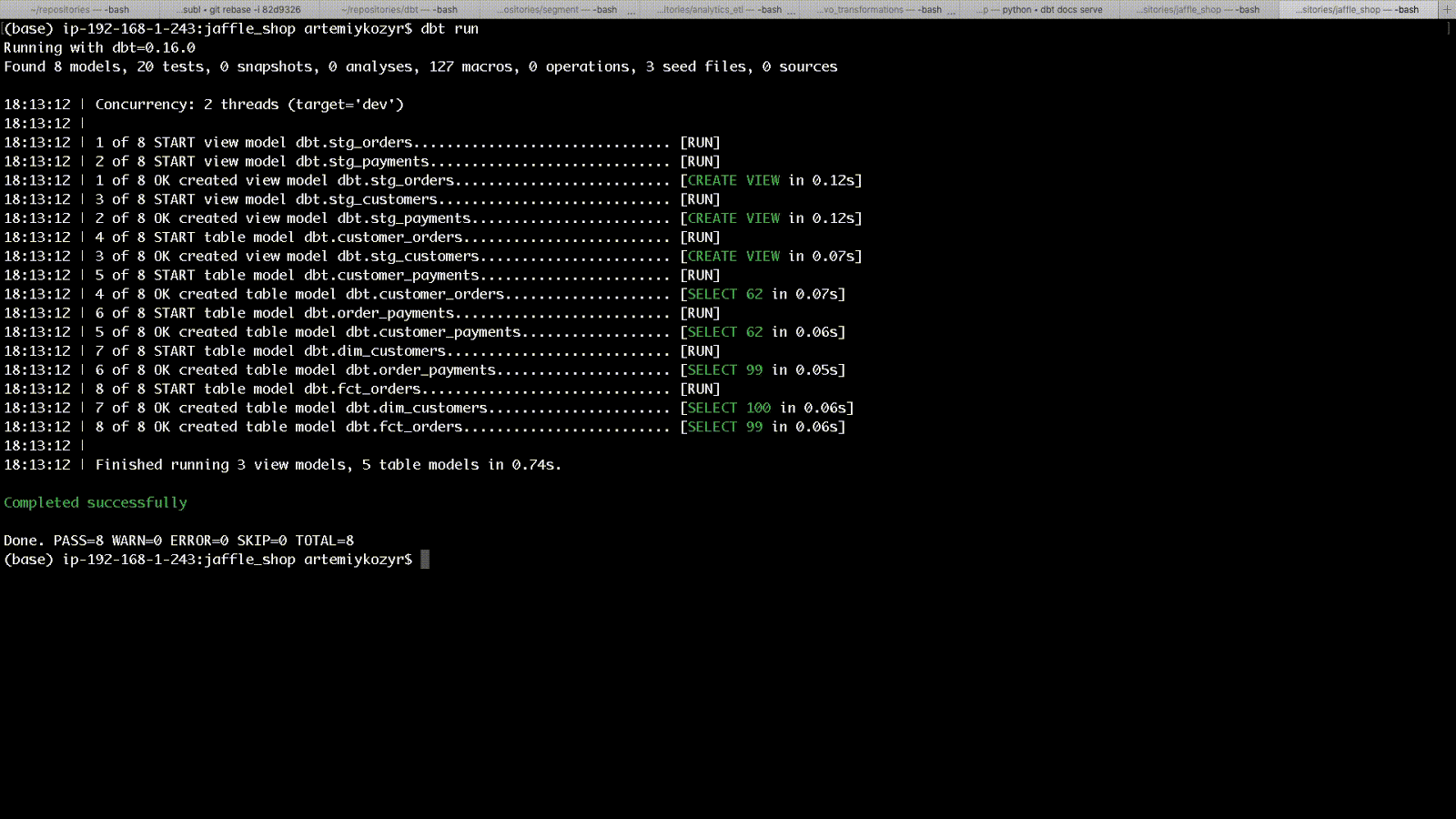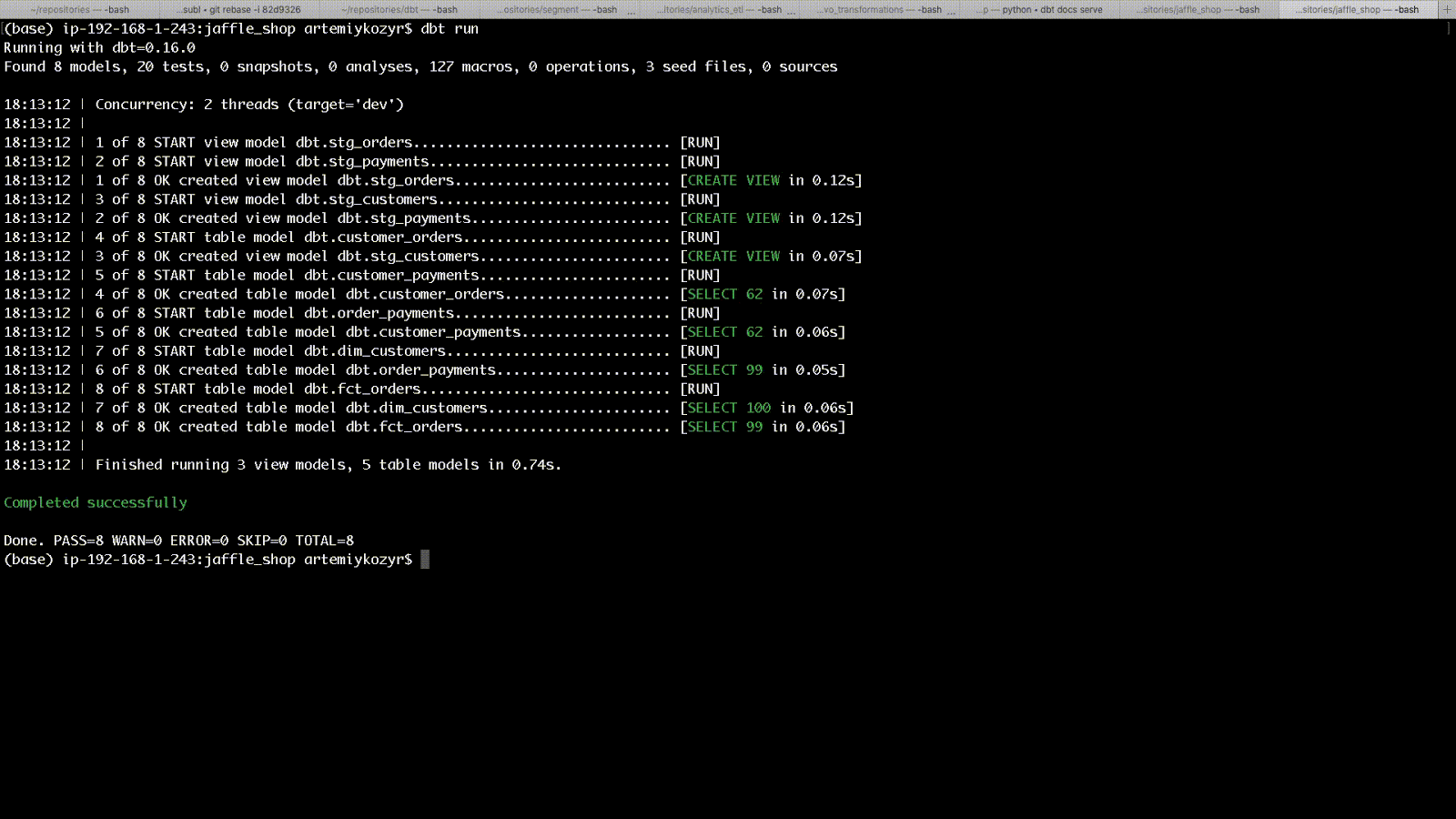
Всё есть SELECT
Это киллер-фича фреймворка Data Build Tool. Другими словами, DBT абстрагирует весь код, связанный с материализацией ваших запросов в Хранилище (вариации из команд CREATE, INSERT, UPDATE, DELETE ALTER, GRANT, ...).
Любая модель подразумевает написание одного SELECT-запроса, который определяет результирующий набор данных.
При этом логика преобразований может быть многоуровневой и консолидировать данные из нескольких других моделей. Пример модели, которая построит витрину заказов (f_orders):
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Что интересного мы можем здесь увидеть?
Во-первых: Использованы CTE (Common Table Expressions) — для организации и понимания кода, который содержит много преобразований и бизнес-логики
Во-вторых: Код модели — это смесь SQL и языка Jinja (templating language).
В примере использован цикл for для формирования суммы по каждому методу платежа, указанному в выражении set. Также используется функция ref — возможность ссылаться внутри кода на другие модели:
- Во время компиляции ref будет преобразован в целевой указатель на таблицу или представление в Хранилище
- ref позволяет построить граф зависимостей моделей
Именно Jinja добавляет в DBT почти неограниченные возможности. Наиболее часто используемые из них:
- If / else statements — операторы ветвления
- For loops — циклы
- Variables — переменные
- Macro — создание макросов
Материализация: Table, View, Incremental
Стратегия Материализации — подход, согласно которому результирующий набор данных модели будет сохранен в Хранилище.
В базовом рассмотрении это:
- Table — физическая таблица в Хранилище
- View — представление, виртуальная таблица в Хранилище
Есть и более сложные стратегии материализации:
- Incremental — инкрементальная загрузка (больших таблиц фактов); новые строки добавляются, измененные — обновляются, удаленные — вычищаются
- Ephemeral — модель не материализуется напрямую, но участвует как CTE в других моделях
- Любые другие стратегии, которые вы можете добавить самостоятельно
Вдобавок к стратегиям материализации открываются возможности для оптимизации под конкретные Хранилища, например:
- Snowflake: Transient tables, Merge behavior, Table clustering, Copying grants, Secure views
- Redshift: Distkey, Sortkey (interleaved, compound), Late Binding Views
- BigQuery: Table partitioning & clustering, Merge behavior, KMS Encryption, Labels & Tags
- Spark: File format (parquet, csv, json, orc, delta), partition_by, clustered_by, buckets, incremental_strategy
На текущий момент поддерживаются следующие Хранилища:
- Postgres
- Redshift
- BigQuery
- Snowflake
- Presto (частично)
- Spark (частично)
- Microsoft SQL Server (коммьюнити адаптер)
Давайте усовершенствуем нашу модель:
- Сделаем ее наполнение инкрементальным (Incremental)
- Добавим ключи сегментации и сортировки для Redshift
-- Конфигурация модели:
-- Инкрементальное наполнение, уникальный ключ для обновления записей (unique_key)
-- Ключ сегментации (dist), ключ сортировки (sort)
{{
config(
materialized='incremental',
unique_key='order_id',
dist="customer_id",
sort="order_date"
)
}}
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
where 1=1
{% if is_incremental() -%}
-- Этот фильтр будет применен только для инкрементального запуска
and order_date >= (select max(order_date) from {{ this }})
{%- endif %}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Граф зависимостей моделей
Он же дерево зависимостей. Он же DAG (Directed Acyclic Graph — Направленный Ациклический Граф).
DBT строит граф на основе конфигурации всех моделей проекта, а точнее ссылок ref() внутри моделей на другие модели. Наличие графа позволяет делать следующие вещи:
- Запуск моделей в корректной последовательности
- Параллелизация формирования витрин
- Запуск произвольного подграфа
Пример визуализации графа:

Каждый узел графа — это модель, ребра графа задаются выражением ref.
Качество данных и Документация
Кроме формирования самих моделей, DBT позволяет протестировать ряд предположений (assertions) о результирующем наборе данных, таких как:
- Not Null
- Unique
- Reference Integrity — ссылочная целостность (например, customer_id в таблице orders соответствует id в таблице customers)
- Соответствие списку допустимых значений
Возможно добавление своих тестов (custom data tests), таких как, например, % отклонения выручки с показателями день, неделю, месяц назад. Любое предположение, сформулированное в виде SQL-запроса, может стать тестом.
Таким образом можно отлавливать в витринах Хранилища нежелательные отклонения и ошибки в данных.
Что касается документирования, DBT предоставляет механизмы для добавления, версионирования и распространения метаданных и комментариев на уровне моделей и даже атрибутов.
Вот как выглядит добавление тестов и документации на уровне конфигурационного файла:
- name: fct_orders
description: This table has basic information about orders, as well as some derived facts based on payments
columns:
- name: order_id
tests:
- unique # проверка на уникальность значений
- not_null # проверка на наличие null
description: This is a unique identifier for an order
- name: customer_id
description: Foreign key to the customers table
tests:
- not_null
- relationships: # проверка ссылочной целостности
to: ref('dim_customers')
field: customer_id
- name: order_date
description: Date (UTC) that the order was placed
- name: status
description: '{{ doc("orders_status") }}'
tests:
- accepted_values: # проверка на допустимые значения
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
А вот как эта документация выглядит уже на сгенерированном веб-сайте:
Макросы и Модули
Назначение DBT заключается не столько в том, чтобы стать набором SQL-скриптов, но предоставить пользователям мощные и богатые возможностями средства для построения собственных трансформаций и распространения этих модулей.
Макросы — это наборы конструкций и выражений, которые могут быть вызваны как функции внутри моделей. Макросы позволяют переиспользовать SQL между моделями и проектами в соответствии с инженерным принципом DRY (Don't Repeat Yourself).
Пример макроса:
{% macro rename_category(column_name) %}
case
when {{ column_name }} ilike '%osx%' then 'osx'
when {{ column_name }} ilike '%android%' then 'android'
when {{ column_name }} ilike '%ios%' then 'ios'
else 'other'
end as renamed_product
{% endmacro %}
И его использования:
{% set column_name = 'product' %}
select
product,
{{ rename_category(column_name) }} -- вызов макроса
from my_table
DBT поставляется с менеджером пакетов (packages), который позволяет пользователям публиковать и переиспользовать отдельные модули и макросы.
Это означает возможность загрузить и использовать такие библиотеки как:
- dbt_utils: работа с Date/Time,Surrogate Keys, Schema tests, Pivot/Unpivot и другие
- Готовые шаблоны витрин для таких сервисов как Snowplow и Stripe
- Библиотеки для определенных Хранилищ Данных, например Redshift
- Logging — Модуль для логирования работы DBT
С полным списком пакетов можно ознакомиться на dbt hub.
Еще больше возможностей
Здесь я опишу несколько других интересных особенностей и реализаций, которые я и команда используем для построения Хранилища Данных в Wheely.
Разделение сред исполнения DEV — TEST — PROD
Даже внутри одного кластера DWH (в рамках разных схем). Например, с помощью следующего выражения:
with source as (
select * from {{ source('salesforce', 'users') }}
where 1=1
{%- if target.name in ['dev', 'test', 'ci'] -%}
where timestamp >= dateadd(day, -3, current_date)
{%- endif -%}
)
Этот код буквально говорит: для сред dev, test, ci возьми данные только за последние 3 дня и не более. То есть прогон в этих средах будет гораздо быстрее и потребует меньше ресурсов. При запуске на среде prod условие фильтра будет проигнорировано.
Материализация с альтернативным кодированием столбцов
Redshift — колоночная СУБД, позволяющая задавать алгоритмы компрессии данных для каждой отдельной колонки. Выбор оптимальных алгоритмов может сократить занимаемый объем на диске на 20-50%.
Макрос redshift.compress_table выполнит команду ANALYZE COMPRESSION, создаст новую таблицу с рекомендуемыми алгоритмами кодирования столбцов, указанными ключами сегментации (dist_key) и сортировки (sort_key), перенесет в нее данные, и при необходимости удалит старую копию.
Сигнатура макроса:
{{ compress_table(schema, table,
drop_backup=False,
comprows=none|Integer,
sort_style=none|compound|interleaved,
sort_keys=none|List<String>,
dist_style=none|all|even,
dist_key=none|String) }}
Логирование запусков моделей
На каждое выполнение модели можно повесить хуки (hooks), которые будут выполняться до запуска или сразу после окончания создания модели:
pre-hook: "{{ logging.log_model_start_event() }}"
post-hook: "{{ logging.log_model_end_event() }}"
Модуль логирования позволит записывать все необходимые метаданные в отдельную таблицу, по которой впоследствии можно проводить аудит и анализ проблемных мест (bottlenecks).
Вот как выглядит дашборд на данных логирования в Looker:

Автоматизация обслуживания Хранилища
Если вы используете какие-то расширения функционала используемого Хранилища, такие как UDF (User Defined Functions), то версионирование этих функций, управление доступами, и автоматизированную выкатку новых релизов очень удобно осуществлять в DBT.
Мы используем UDF на Python, для расчета хэш-значений, доменов почтовых адресов, декодирования битовых масок (bitmask).
Пример макроса, который создает UDF на любой среде исполнения (dev, test, prod):
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_sha256(mes "varchar")
RETURNS varchar
LANGUAGE plpythonu
STABLE
AS $$
import hashlib
return hashlib.sha256(mes).hexdigest()
$$
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}
В Wheely мы используем Amazon Redshift, который основан на PostgreSQL. Для Redshift важно регулярно собирать статистики по таблицам и высвобождать место на диске — команды ANALYZE и VACUUM, соответственно.
Для этого каждую ночь выполняются команды из макроса redshift_maintenance:
{% macro redshift_maintenance() %}
{% set vacuumable_tables=run_query(vacuumable_tables_sql) %}
{% for row in vacuumable_tables %}
{% set message_prefix=loop.index ~ " of " ~ loop.length %}
{%- set relation_to_vacuum = adapter.get_relation(
database=row['table_database'],
schema=row['table_schema'],
identifier=row['table_name']
) -%}
{% do run_query("commit") %}
{% if relation_to_vacuum %}
{% set start=modules.datetime.datetime.now() %}
{{ dbt_utils.log_info(message_prefix ~ " Vacuuming " ~ relation_to_vacuum) }}
{% do run_query("VACUUM " ~ relation_to_vacuum ~ " BOOST") %}
{{ dbt_utils.log_info(message_prefix ~ " Analyzing " ~ relation_to_vacuum) }}
{% do run_query("ANALYZE " ~ relation_to_vacuum) %}
{% set end=modules.datetime.datetime.now() %}
{% set total_seconds = (end - start).total_seconds() | round(2) %}
{{ dbt_utils.log_info(message_prefix ~ " Finished " ~ relation_to_vacuum ~ " in " ~ total_seconds ~ "s") }}
{% else %}
{{ dbt_utils.log_info(message_prefix ~ ' Skipping relation "' ~ row.values() | join ('"."') ~ '" as it does not exist') }}
{% endif %}
{% endfor %}
{% endmacro %}
DBT Cloud
Есть возможность пользоваться DBT как сервисом (Managed Service). В комплекте:
- Web IDE для разработки проектов и моделей
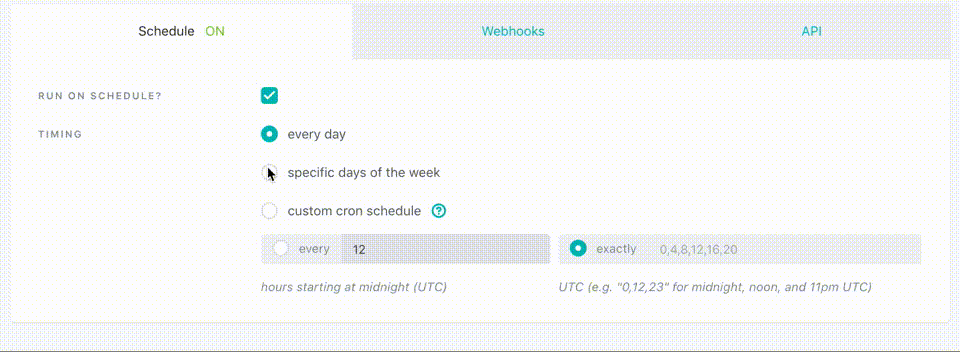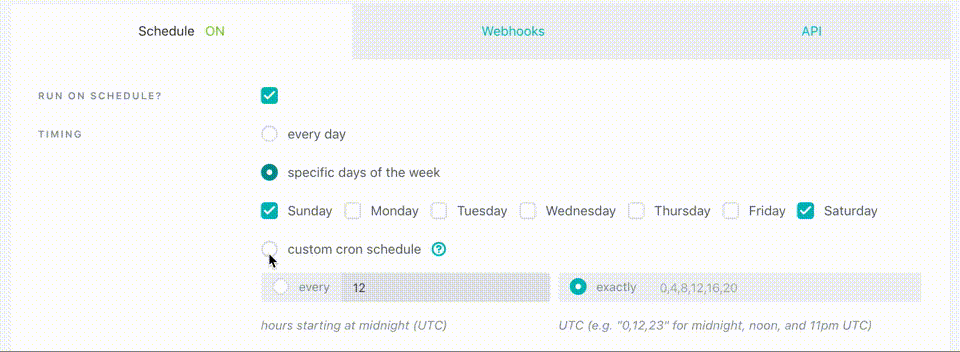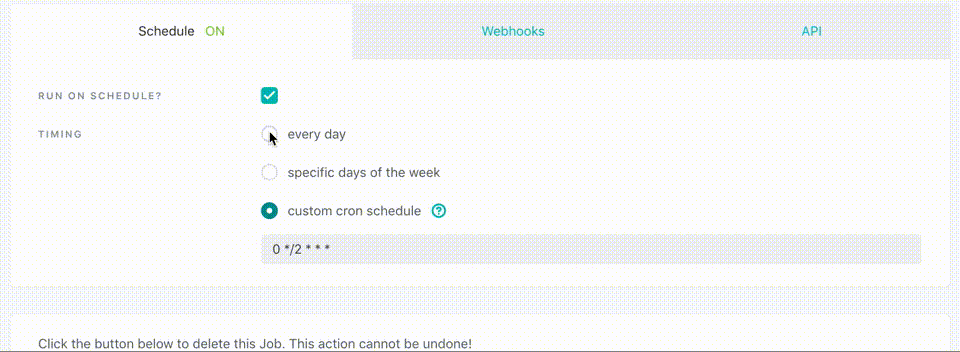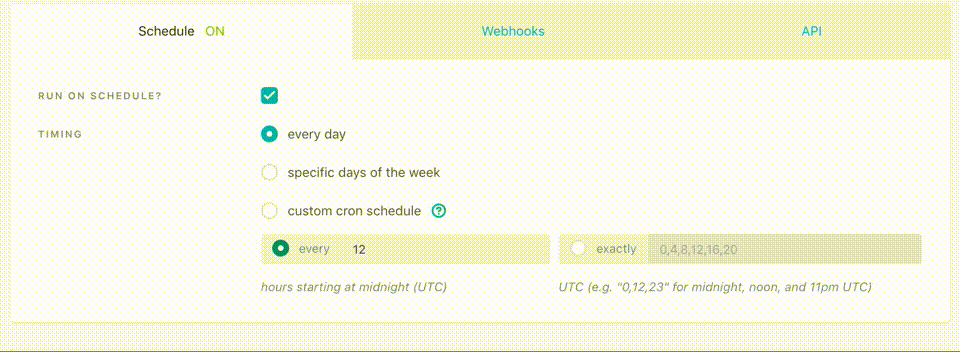
- Конфигурация джобов и установка на расписание
- Простой и удобный доступ к логам
- Веб Сайт с документацией вашего проекта
- Подключение CI (Continuous Integration)
Заключение
Готовить и употреблять DWH становится так же приятно и благотворно, как и пить смузи. DBT состоит из Jinja, пользовательских расширений (модулей), компилятора, движка (executor) и менеджера пакетов. Собрав эти элементы воедино вы получаете полноценное рабочее окружение для вашего Хранилища Данных. Едва ли сегодня есть лучший способ управления трансформациями внутри DWH.

Убеждения, которым следовали разработчики DBT формулируются так:
- Код, а не GUI, является лучшей абстракцией для выражения сложной аналитической логики
- Работа с данными должна адаптировать лучшие практики разработки ПО (Software Engineering)
- Важнейшая инфраструктура по работе с данными должна контролироваться сообществом пользователей как программное обеспечение с открытым исходным кодом
- Не только инструменты аналитики, но и код все чаще будет становиться достоянием сообщества Open Source
Эти основные убеждения породили продукт, который сегодня используется в более чем 850 компаниях, и они составляют основу многих интересных расширений, которые будут созданы в будущем.
Для тех, кто заинтересовался, есть видеозапись открытого урока, который я провел несколько месяцев назад в рамках открытого урока в OTUS — Data Build Tool для хранилища Amazon Redshift.
Помимо DBT и Хранилищ Данных, в рамках курса Data Engineer на платформе OTUS, я и мои коллеги ведем занятия по ряду других актуальных и современных тем:
- Архитектурные концепции приложений Больших Данных
- Практика со Spark и Spark Streaming
- Изучение способов и инструментов загрузки источников данных
- Построение аналитических витрин в DWH
- Концепции NoSQL: HBase, Cassandra, ElasticSearch
- Принципы организации мониторинга и оркестрации
- Финальный Проект: собираем все скиллы воедино под менторской поддержкой
Ссылки:
- DBT documentation — Introduction — Официальная документация
- What, exactly, is dbt? — Обзорная статья одного из авторов DBT
- Data Build Tool для хранилища Amazon Redshift — YouTube, Запись открытого урока OTUS
- Знакомство с Greenplum — Ближайший открытый урок 15 мая 2020
- Курс по Data Engineering — OTUS
- Building a Mature Analytics Workflow — Взгляд на будущее работы с данными и аналитику
- It’s time for open source analytics — Эволюция аналитики и влияние Open Source
- Continuous Integration and Automated Build Testing with dbtCloud — Принципы построение CI с использованием DBT
- Getting started with DBT tutorial — Практика, Пошаговые инструкции для самостоятельной работы
- Jaffle shop — Github DBT Tutorial — Github, код учебного проекта
Подробнее о курсе.
