Перевод статьи подготовлен в преддверии старта продвинутого курса «Математика для Data Scienсe».

Алгоритм AdaBoost можно использовать для повышения производительности любого алгоритма машинного обучения. Машинное обучение стало мощным инструментом, позволяющим делать прогнозы на основе больших объемов данных. Оно стало настолько популярно на сегодняшний день, что приложения с машинным обучением находят применение даже в повседневных задачах. Один из самых распространенных примеров – рекомендации товаров на основе прошлых покупок, сделанных клиентом. Машинное обучение, часто называемое прогностическим анализом или прогностическим моделированием, можно определить как способность компьютеров учиться без явного программирования. Машинное обучение использует уже готовые алгоритмы для анализа входных данных, чтобы сделать предсказания по определенным критериям.
В машинном обучении бустинг нужен для преобразования слабых классификаторов в сильные. Слабый обучающий алгоритм или классификатор – это обучающий алгоритм, который работает лучше, чем случайное угадывание, и работать хорошо он будет в случае переобучения, поскольку при большом наборе слабых классификаторов, любой слабый классификатор будет работать лучше, чем случайная выборка. В качестве слабого классификатора часто используется обычный
AdaBoost означает «Adaptive Boosting» или адаптивный бустинг. Он превращает слабые обучающие алгоритмы в сильные для решения проблем классификации.
Окончательное уравнение для классификации может выглядит следующим образом:

Здесь fm – это m-ый слабый классификатор, где m отвечает за соответствующий ему вес.
AdaBoost можно использовать для повышения производительности алгоритмов машинного обучения. Он лучше всего работает со слабыми обучающими алгоритмами, поэтому такие модели могут достигнуть точности гораздо выше случайной при решении задачи классификации. Наиболее распространенными алгоритмами, используемыми с AdaBoost, являются одноуровневые деревья решений. Слабый обучающий алгоритм – это классификатор или алгоритм предсказания, который работает относительно плохо в плане точности. Помимо этого, можно сказать, что слабые классификаторы легко вычисляются, поэтому можно объединять много сущностей алгоритма, чтобы создать более сильный классификатор с помощью бустинга.
Если у нас есть набор данных, в котором n – количество точек и

Где -1 будет отрицательным классом, а 1 – положительным. Тогда вес каждый точки будет инициализирован, как показано ниже:

Каждое m в следующем выражении у нас будет изменяться от 1 до M.
Для начала нужно выбрать слабый классификатор с наименьшей взвешенной ошибкой классификации, применив классификатор к набору данных.

Затем посчитаем вес m-ого слабого классификатора, как показано ниже:

Вес положителен для любого классификатора с точностью выше 50%. Чем больше вес, тем точнее классификатор. Вес становится отрицательным, когда точность падает ниже 50%. Предсказания можно объединять, инвертируя знак. Таким образом классификатор с точность в 40% можно преобразовать в классификатор с точностью в 60%. Так классификатор будет вносить вклад в итоговое предсказание, даже если он работал хуже, чем случайное угадывание. Однако окончательный результат никак не изменится под влиянием классификатора, точность которого равна 50%.
Экспонента в числителе всегда будет больше 1 в случае неверной классификации из классификатора с положительным весом. После итерации вес неверно классифицированных объектов возрастет. Классификаторы с отрицательным весом поведут себя аналогичным образом. Здесь есть разница в инверсии знака: правильная классификация станет неправильной. Окончательный прогноз можно рассчитать путем учета вклада каждого классификатора и вычисления суммы их взвешенных прогнозов.
Вес для каждой точки будет обновляться следующим образом:
Здесь Zm – это нормализующий параметр. Он нужен, чтобы убедиться, что сумма всех весов экземпляра равна 1.
AdaBoost можно использовать для распознавания лиц, поскольку он является стандартным алгоритмом для таких задач. Он использует каскад отбраковки, состоящий из нескольких слоев классификаторов. Когда область распознавания не обнаруживает лица ни на одном слое, она отбраковывается. Первый классификатор в области отбрасывает отрицательную область, чтобы свести стоимость вычислений к минимуму. Несмотря на то, что AdaBoost используется для объединения слабых классификаторов, принципы AdaBoost также используются для поиска лучших признаков для каждого слоя в каскаде.
Одним их многих преимуществ алгоритма AdaBoost является то, что его легко, быстро и просто запрограммировать. Кроме того, он достаточно гибкий, чтобы комбинировать его с любым алгоритмом машинного обучения без настройки параметров, кроме параметра Т. Он расширяем до задач обучения сложнее, чем двоичная классификация, и достаточно универсален, поскольку его можно использовать с числовыми или текстовыми данными.
Также в AdaBoost есть несколько недостатков, как минимум то, что этот алгоритм доказывается эмпирически и очень уязвим к равномерно распределенному шуму. Слабые классификаторы в случае, если они слишком слабые, могут привести к плохим результатам и переобучению.
В качестве примера возьмем приемную кампанию университета, где абитуриент может быть либо принят в университет, либо нет. Здесь можно взять различные количественные и качественные данные. Например, результат приема, который может быть выражен как «да» или «нет», можно определить количественно, тогда как навыки и хобби студентов можно определить качественно. Мы можем легко придумать корректную классификацию обучающих данных. Допустим, если студент хорошо себя показал в определенной дисциплине, то он будет принят с большей вероятностью. Однако предсказание с высокой точностью – это дело сложное и именно тут помогают слабые классификаторы.
AdaBoost помогает выбрать обучающий набор для каждого классификатора, который обучается на основе результатов работы предыдущего классификатора. Что касается объединения результатов, то алгоритм определяет, какой вес нужно придать каждому классификатору в зависимости от полученного ответа. Он объединяет слабые классификаторы для создания сильного и исправления ошибок классификации, а также является крайне успешным алгоритмом бустинга для задач двоичной классификации.
Узнать подробнее о курсе.

Введение
Алгоритм AdaBoost можно использовать для повышения производительности любого алгоритма машинного обучения. Машинное обучение стало мощным инструментом, позволяющим делать прогнозы на основе больших объемов данных. Оно стало настолько популярно на сегодняшний день, что приложения с машинным обучением находят применение даже в повседневных задачах. Один из самых распространенных примеров – рекомендации товаров на основе прошлых покупок, сделанных клиентом. Машинное обучение, часто называемое прогностическим анализом или прогностическим моделированием, можно определить как способность компьютеров учиться без явного программирования. Машинное обучение использует уже готовые алгоритмы для анализа входных данных, чтобы сделать предсказания по определенным критериям.
Что такое алгоритм AdaBoost?
В машинном обучении бустинг нужен для преобразования слабых классификаторов в сильные. Слабый обучающий алгоритм или классификатор – это обучающий алгоритм, который работает лучше, чем случайное угадывание, и работать хорошо он будет в случае переобучения, поскольку при большом наборе слабых классификаторов, любой слабый классификатор будет работать лучше, чем случайная выборка. В качестве слабого классификатора часто используется обычный
threshold по определённому признаку. Если признак лежит выше threshold (порогового значения), чем было спрогнозировано, он относится к положительной области, в противном случае – к отрицательной.AdaBoost означает «Adaptive Boosting» или адаптивный бустинг. Он превращает слабые обучающие алгоритмы в сильные для решения проблем классификации.
Окончательное уравнение для классификации может выглядит следующим образом:
Здесь fm – это m-ый слабый классификатор, где m отвечает за соответствующий ему вес.
Как работает алгоритм AdaBoost?
AdaBoost можно использовать для повышения производительности алгоритмов машинного обучения. Он лучше всего работает со слабыми обучающими алгоритмами, поэтому такие модели могут достигнуть точности гораздо выше случайной при решении задачи классификации. Наиболее распространенными алгоритмами, используемыми с AdaBoost, являются одноуровневые деревья решений. Слабый обучающий алгоритм – это классификатор или алгоритм предсказания, который работает относительно плохо в плане точности. Помимо этого, можно сказать, что слабые классификаторы легко вычисляются, поэтому можно объединять много сущностей алгоритма, чтобы создать более сильный классификатор с помощью бустинга.
Если у нас есть набор данных, в котором n – количество точек и
Где -1 будет отрицательным классом, а 1 – положительным. Тогда вес каждый точки будет инициализирован, как показано ниже:

Каждое m в следующем выражении у нас будет изменяться от 1 до M.
Для начала нужно выбрать слабый классификатор с наименьшей взвешенной ошибкой классификации, применив классификатор к набору данных.

Затем посчитаем вес m-ого слабого классификатора, как показано ниже:
Вес положителен для любого классификатора с точностью выше 50%. Чем больше вес, тем точнее классификатор. Вес становится отрицательным, когда точность падает ниже 50%. Предсказания можно объединять, инвертируя знак. Таким образом классификатор с точность в 40% можно преобразовать в классификатор с точностью в 60%. Так классификатор будет вносить вклад в итоговое предсказание, даже если он работал хуже, чем случайное угадывание. Однако окончательный результат никак не изменится под влиянием классификатора, точность которого равна 50%.
Экспонента в числителе всегда будет больше 1 в случае неверной классификации из классификатора с положительным весом. После итерации вес неверно классифицированных объектов возрастет. Классификаторы с отрицательным весом поведут себя аналогичным образом. Здесь есть разница в инверсии знака: правильная классификация станет неправильной. Окончательный прогноз можно рассчитать путем учета вклада каждого классификатора и вычисления суммы их взвешенных прогнозов.
Вес для каждой точки будет обновляться следующим образом:
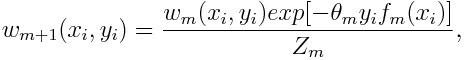
Здесь Zm – это нормализующий параметр. Он нужен, чтобы убедиться, что сумма всех весов экземпляра равна 1.
Где используется алгоритм AdaBoost?
AdaBoost можно использовать для распознавания лиц, поскольку он является стандартным алгоритмом для таких задач. Он использует каскад отбраковки, состоящий из нескольких слоев классификаторов. Когда область распознавания не обнаруживает лица ни на одном слое, она отбраковывается. Первый классификатор в области отбрасывает отрицательную область, чтобы свести стоимость вычислений к минимуму. Несмотря на то, что AdaBoost используется для объединения слабых классификаторов, принципы AdaBoost также используются для поиска лучших признаков для каждого слоя в каскаде.
Преимущества и недостатки алгоритма AdaBoost
Одним их многих преимуществ алгоритма AdaBoost является то, что его легко, быстро и просто запрограммировать. Кроме того, он достаточно гибкий, чтобы комбинировать его с любым алгоритмом машинного обучения без настройки параметров, кроме параметра Т. Он расширяем до задач обучения сложнее, чем двоичная классификация, и достаточно универсален, поскольку его можно использовать с числовыми или текстовыми данными.
Также в AdaBoost есть несколько недостатков, как минимум то, что этот алгоритм доказывается эмпирически и очень уязвим к равномерно распределенному шуму. Слабые классификаторы в случае, если они слишком слабые, могут привести к плохим результатам и переобучению.
Пример алгоритма AdaBoost
В качестве примера возьмем приемную кампанию университета, где абитуриент может быть либо принят в университет, либо нет. Здесь можно взять различные количественные и качественные данные. Например, результат приема, который может быть выражен как «да» или «нет», можно определить количественно, тогда как навыки и хобби студентов можно определить качественно. Мы можем легко придумать корректную классификацию обучающих данных. Допустим, если студент хорошо себя показал в определенной дисциплине, то он будет принят с большей вероятностью. Однако предсказание с высокой точностью – это дело сложное и именно тут помогают слабые классификаторы.
Заключение
AdaBoost помогает выбрать обучающий набор для каждого классификатора, который обучается на основе результатов работы предыдущего классификатора. Что касается объединения результатов, то алгоритм определяет, какой вес нужно придать каждому классификатору в зависимости от полученного ответа. Он объединяет слабые классификаторы для создания сильного и исправления ошибок классификации, а также является крайне успешным алгоритмом бустинга для задач двоичной классификации.
Узнать подробнее о курсе.
