 Привет, Хаброжители!
Привет, Хаброжители!Джунам и вчерашним выпускникам вузов катастрофически не хватает «уличного» опыта. Чтобы стать отличным разработчиком, понадобятся вполне конкретные навыки, позволяющие превратить теорию в практику, а также понимание того, в какие моменты можно нарушать казавшиеся незыблемыми правила. Эта книга — справочник по выживанию для начинающего разработчика.
«Кодер с улицы» научит вас справляться с реальными задачами. Седат Капаноглу честно делится советами, основанными на личном опыте, а не на абстрактной теории. Вы узнаете, как адаптировать знания, полученные из книг и курсов, к повседневным рабочим задачам.
Пора узнать, как использовать антипаттерны и «плохие» методы программирования. Эта книга построена на конкретных задачах, с которыми вы столкнетесь на работе, — от чисто технических аспектов, таких как создание функции поиска, до законов выживания в проблемной команде с менеджером-параноиком.
Все это превратит вас в настоящего уличного бойца, готового в любой момент приступить к созданию эффективного программного обеспечения.
Для кого эта книга
Эта книга предназначена для разработчиков начального и среднего уровня, изучавших программирование и вышедших за пределы обычной учебной программы, но которым все еще не хватает широкого взгляда на парадигмы и лучшие практики разработки. Примеры написаны на C# и .NET, поэтому знакомство с этими языками поможет при чтении. Однако автор стремился, чтобы книга была, насколько это возможно, независима от конкретного языка и его структуры.
4.6. НЕ ПИШИТЕ ТЕСТЫ
Да, тестирование полезно, но не писать тесты — еще лучше. Как обойтись без тестов и при этом сохранить надежность кода?
4.6.1. Не пишите код
Если кода не существует, его не нужно тестировать. Удаленный код не содержит ошибок. Помните об этом. Стоит ли писать тесты, если вам вообще не нужен этот код? Может, лучше использовать существующий пакет, а не создавать его аналог с нуля? Может, использовать существующий класс, который делает то же самое, что вы пытаетесь реализовать? Например, у вас может возникнуть соблазн написать собственные регулярные выражения для проверки URL-адресов, но все, что требуется сделать, это использовать класс System.Uri.
Конечно, сторонний код не всегда идеален или подходит для ваших целей. Вы можете понять это не сразу, но обычно все-таки стоит рискнуть. В кодовой базе может быть код вашего коллеги, выполняющий те же функции, что вам нужны. Поищите в ней.
Если альтернатив нет, готовьтесь писать собственный код. Не бойтесь изобретать велосипед. Это может быть полезно, о чем я уже говорил в главе 3.
4.6.2. Ограничьтесь выборочными тестами
Знаменитый принцип Парето гласит, что 80% следствий вызываются 20% причин. По крайней мере, так говорят 80% определений. Чаще этот принцип называют принципом 80/20. Он применим и к тестированию. Вы можете получить 80% надежности при 20-процентном покрытии тестами, если будете выбирать тесты с умом.
Ошибки проявляются неоднородно. Вероятность их возникновения для разных строк кода различна. Вероятность обнаружить ошибку выше в часто используемом коде. Области кода, в которых вероятность возникновения проблем высока, называют критическими, или горячими путями (hot paths).
Свой сайт я не тестировал даже после того, как он стал одним из самых популярных турецких сайтов. Но тесты пришлось добавить из-за большого количества ошибок парсера текстовой разметки. Разметка была нестандартной и мало напоминала Markdown. Поскольку логика парсинга была сложна и подвержена ошибкам, стало экономически невыгодно исправлять каждую проблему после развертывания в рабочей среде. Я разработал для нее набор тестов. Тестовых фреймворков в то время еще не существовало. По мере появления новых ошибок число тестов росло. Со временем мы разработали широкий набор тестов, который спас нас от тысяч провальных развертываний на продакшен. Тесты работают.
Даже простой просмотр домашней страницы сайта обеспечивает проверку значительной части кода, поскольку задействуются многие пути, общие с другими страницами. На уличном сленге это называют дымовым тестированием. Метод — ровесник первых прототипов компьютера, которые пытались включить, чтобы посмотреть, не идет ли из них дым. Отсутствие дыма было хорошим знаком. Точно так же фокусировка тестирования на критических общих компонентах важнее, чем полнота покрытия кода. Не тратьте время на то, чтобы обеспечить проверку дополнительной строки, если это не имеет большого значения. Вы уже знаете, что покрытие кода — далеко не все.
4.7. ПУСТЬ ТЕСТИРОВАНИЕМ ЗАЙМЕТСЯ КОМПИЛЯТОР
В строго типизированном языке правильное применение системы типов может уменьшить количество необходимых тестовых сценариев. Я уже говорил, как ссылки, допускающие значение null, помогают избежать проверки значений null в коде, что также уменьшает потребность в тестах для сценариев с null. Рассмотрим простой пример. В предыдущем разделе мы убедились, что пользователю, желающему зарегистрироваться, исполнилось 18 лет. Теперь нужно проверить, допустимо ли выбранное им имя, поэтому нам требуется соответствующая функция.
4.7.1. Как исключить проверки на null
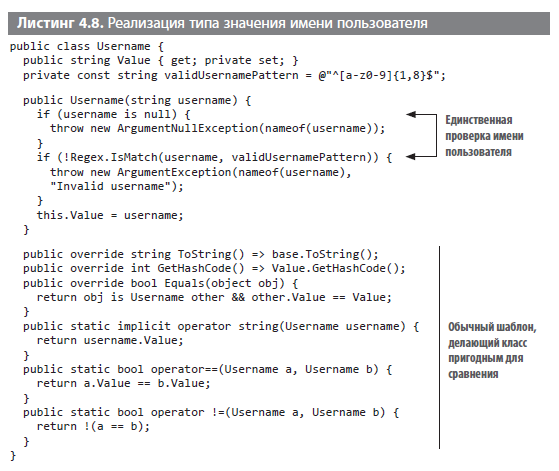
Допустим, что по правилу имя пользователя должно состоять из не менее чем восьми строчных буквенно-цифровых символов. Шаблон регулярного выражения для такого имени пользователя будет "^[a-z0-9]{1,8}$". Можно написать класс имени пользователя, как в листинге 4.8. Зададим класс Username для представления всех имен пользователей в коде. Нам не придется думать о том, где проверять ввод, передав функцию проверки любому коду, который требует имя пользователя.
Чтобы убедиться, что имя пользователя не принимает недействительное значение, мы проверяем параметр в конструкторе и выдаем исключение, если имя имеет неправильный формат. Остальной код вне конструктора остается шаблонным, чтобы он мог работать в сценариях сравнения. Помните, что всегда можно использовать создание базового класса StringValue, написав минимум кода для каждого класса значений на основе строк.
Я повторяю некоторые блоки кода в разных листингах для лучшего их понимания. Обратите внимание на использование оператора nameof вместо жестко закодированных строк для ссылок на параметры. Это позволяет синхронизировать имена после переименования. Кроме того, этот оператор можно использовать для полей и свойств, и он особенно полезен для сценариев, когда данные хранятся в отдельном поле и необходимо ссылаться на это поле по его имени.
МИФЫ О РЕГУЛЯРНЫХ ВЫРАЖЕНИЯХ
Регулярные выражения — одно из самых блестящих изобретений в computer science. Мы обязаны ими достопочтенному Стивену Коулу Клини (Stephen Cole Kleene). Они позволяют создать анализатор текста из пары символов. Шаблон light соответствует только строке light, а [ln]ight соответствует и light, и night. Точно так же li(gh){1,2}t соответствует только словам light и lighght, и это не опечатка, а стихотворение Арама Сарояна (Aram Saroyan), состоящее из одного слова.
Джейми Завински (Jamie Zawinski) однажды сказал: «Некоторые люди, сталкиваясь с проблемой, думают так: “О, знаю, я использую регулярные выражения”. И у них появляются две проблемы». Регулярные выражения работают с определенными задачами парсинга. Регулярные выражения не зависят от контекста, поэтому невозможно с помощью одного регулярного выражения найти самый внутренний тег в документе HTML и несовпадающие закрывающие теги. Это означает, что такие выражения не подходят для сложных задач парсинга. Тем не менее их можно использовать для анализа текста с невложенной структурой.
Регулярные выражения удивительно эффективны в ситуациях, когда их можно применять. Если вам нужна еще более высокая производительность, вы можете предварительно скомпилировать их в C#, создав объект Regex с параметром RegexOptions.Compiled. При этом пользовательский код, который анализирует строку на основе шаблона, будет создаваться по требованию. Шаблон преобразуется в C# и, в конечном итоге, в машинный код. Последовательные вызовы одного и того же объекта Regex будут повторно использовать скомпилированный код, повышая производительность для нескольких итераций.
Несмотря на эффективность, не используйте регулярные выражения, если существует простая альтернатива. Если вам нужно проверить, имеет ли строка определенную длину, простой «str.Lengthv== 5» будет намного быстрее и проще, чем «Regex.IsMatch (@»^.{5}$", str)". Точно так же класс string содержит множество эффективных методов для обычных операций проверки строк, например StartsWith, EndsWith, IndexOf, Last-IndexOf, IsNullOrEmpty и IsNullOrWhiteSpace. Всегда выбирайте готовые методы вместо регулярных выражений для конкретных случаев использования.
Тем не менее важно знать хотя бы базовый синтаксис регулярных выражений, потому что они могут пригодиться в среде разработки. В целях экономии времени изменять код можно довольно сложными способами. Все популярные текстовые редакторы поддерживают регулярные выражения для операций поиска и замены. Я говорю о таких операциях, как «Переместить сотни символов квадратных скобок на следующую строку, но только если они располагаются в конце строки кода». На выбор подходящего шаблона регулярного выражения достаточно пары минут, и не надо будет заниматься целый час этим перемещением вручную.
Тестирование конструктора Username потребует создания трех тестовых методов, как показано в листинге 4.9: для проверки допустимости значений null, так как вызывается другой тип исключения; для не-null, но недопустимых входных данных; наконец, для действительных входных данных, поскольку необходимо убедиться, что конструктор распознает их именно как действительные.
Листинг 4.9. Тесты для класса Username
class UsernameTest {
[Test]
public void ctor_nullUsername_ThrowsArgumentNullException() {
Assert.Throws<ArgumentNullException>(
() => new Username(null));
}
[TestCase("")]
[TestCase("Upper")]
[TestCase("toolongusername")]
[TestCase("root!!")]
[TestCase("a b")]
public void ctor_invalidUsername_ThrowsArgumentException(string username) {
Assert.Throws<ArgumentException>(
() => new Username(username));
}
[TestCase("a")]
[TestCase("1")]
[TestCase("hunter2")]
[TestCase("12345678")]
[TestCase("abcdefgh")]
public void ctor_validUsername_DoesNotThrow(string username) {
Assert.DoesNotThrow(() => new Username(username));
}
}Если бы мы разрешили для класса Username ссылки, допускающие значение null, то для сценария с null писать тесты не пришлось бы. Единственное исключение — создание общедоступного API, который может не работать с кодом, поддерживающим ссылки, допускающие значение null. В этом случае пришлось бы проводить проверки на наличие null.
Точно так же объявление Username структурой, когда это уместно, сделало бы его типом значения, избавив от необходимости проверки на null. Использование правильных типов и структур помогает сократить количество тестов. А компилятор обеспечит правильность кода.
Использование специфических типов для соответствующих целей снижает потребность в тестах. Когда функция регистрации получает Username вместо строки, не нужно тестировать, проверяет ли она свои аргументы. Точно так же когда функция получает аргумент URL-адреса в виде класса Uri, не нужно проверять, правильно ли она обрабатывает URL-адрес.
4.7.2. Как исключить проверки диапазона
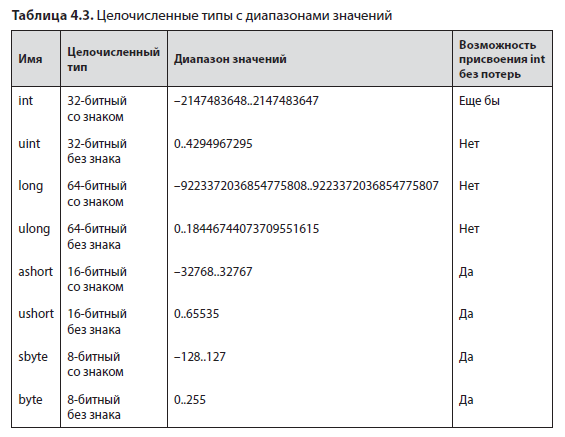
Чтобы уменьшить диапазон возможных недопустимых входящих значений, можно использовать типы целых чисел без знака. В табл. 4.3 представлены беззнаковые версии целочисленных примитивов. В таблице вы можете видеть диапазоны значений для разных типов данных, используемых в коде. Важно помнить, совместим ли выбранный тип напрямую с int, потому что это основной тип для целых чисел в .NET. Вы наверняка знакомы с этими типами, но скорее всего, не думали, что они могут избавить вас от необходимости писать дополнительные тестовые сценарии. Но если функции нужны только положительные значения, то зачем использовать int, проверять отрицательные значения и выдавать исключения? Просто используйте uint.
При использовании беззнакового типа передача отрицательной константы в функцию вызовет ошибку компилирования. Передавать переменные с отрицательными значениями можно только при явном приведении типа, что заставляет задуматься, действительно ли имеющееся значение подходит для функции в месте вызова. Проверка отрицательных аргументов не входит в обязанности функции.
Предположим, что функция должна возвращать популярные теги на сайте микроблогов, но не более определенного их числа. Она получает ряд элементов для извлечения строк сообщений, как в листинге 4.10. Функция GetTrendingTags возвращает элементы с учетом их количества. Обратите внимание, что входящее значение — byte, а не int, поскольку в списке тегов не бывает больше 255 элементов. Это сразу исключает сценарии, когда входящее значение отрицательное или слишком большое. Не нужно даже проверять ввод. Таким образом, тестов становится меньше на один, а диапазон входящих значений значительно уменьшается, что сужает область ошибок.

Отметим две вещи. Во-первых, для нашего варианта использования мы выбираем меньший тип данных. Нам не нужно поддерживать миллиарды строк в поле популярных тегов. Мы сузили пространство ввода. Во-вторых, мы выбираем беззнаковый тип byte, который не может быть отрицательным. Таким образом, мы избавляемся от дополнительного тестового сценария и потенциальной проблемы, которая может вызвать исключение. Функция Take из LINQ не выдает исключение с List, но может это делать, когда преобразуется в запрос для базы данных, такой как Microsoft SQL Server. Изменяя тип, мы избегаем таких сценариев и нам не нужно писать для них тесты.
Обратите внимание, что .NET использует int в качестве стандартного типа для многих операций, таких как индексирование и подсчет. Выбор другого типа может потребовать приведения и преобразования значений в int при взаимодействии со стандартными компонентами .NET.
Убедитесь, что не зарываете себя в яму из-за собственной педантичности. Чувство удовлетворенности и удовольствие от написания кода важнее, чем какой-то единичный случай, которого вы пытаетесь избежать. Например, если в будущем вам понадобится более 255 элементов, вам придется заменить все ссылки на тип byte ссылками на short или int, что может отнять много времени. Так что причина, по которой вы стремитесь избежать тестов, должна быть действительно веской. Возможно, окажется проще написать больше тестов, чем работать с другими типами. В конце концов, важны только ваши комфорт и время, невзирая на очевидное преимущество использования типов для определения диапазонов допустимых значений.
4.7.3. Как исключить проверки допустимых значений
Иногда значения используются для обозначения операции в функции. Типичным примером является функция fopen в языке программирования C. Второй принимаемый этой функцией строковый параметр указывает на режим открытия файла и может означать открытие для чтения, открытие для добавления, открытие для записи и т. д.
Пару десятков лет спустя команда .NET создала усовершенствованное решение — отдельные функции для каждого сценария. Появились отдельные методы File.Create, File.OpenRead и File.OpenWrite, позволившие избежать введения дополнительных параметров и парсинга их значений. Стало невозможно передать неверный параметр. Исчезли ошибки при парсинге параметров в функции, потому что не стало самих параметров.
Обычно значения используются для обозначения типа операции. Но лучше разделить сложные функции на более простые — это поможет передать логику и уменьшит необходимость в тестовом покрытии.
Логические параметры часто используются в C# для изменения логики выполняемой функции. Примером может служить опция сортировки в функции извлечения популярных тегов, как в листинге 4.11. Предположим, что нам нужно вывести эти теги, отсортированные по заголовку, на странице управления тегами. Вопреки законам термодинамики разработчики постоянно теряют энтропию. Они всегда стараются вносить изменения с наименьшей энтропией, не задумываясь о возможных последствиях. Часто первая мысль разработчика — покончить с задачей, добавив лагический параметр.

Проблема в том, что если продолжать в том же духе, функция очень усложнится из-за роста числа комбинаций параметров. Допустим, для другой функции требуются трендовые теги, начиная со вчерашнего дня. Добавим это условие вместе с другими параметрами в следующем листинге. Теперь функция также должна поддерживать комбинации sortByTitle и yesterdaysTags.

Наблюдается тенденция к росту сложности функции с добавлением каждого нового логического параметра. Для трех вариантов использования уже есть четыре разновидности функции. С каждым новым параметром мы создаем версии функции, которые никто не будет использовать, хотя, возможно, когда-нибудь кто-то это все-таки сделает и окажется в тупике. Лучше всего иметь отдельную функцию для каждого клиента, как показано ниже.
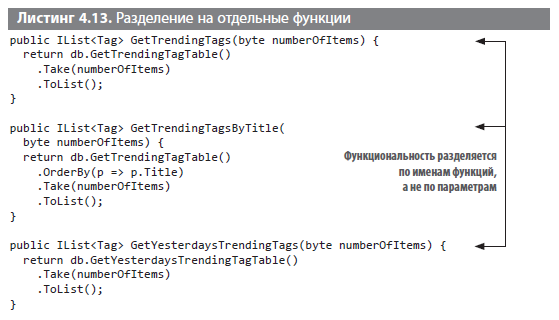
Теперь у нас стало на один тестовый сценарий меньше. В качестве бонусов имеем удобочитаемость и повышенную производительность. Выигрыши, конечно, ничтожны и незаметны для одной функции, но в случае масштабирования кода они могут играть важную роль, даже если вы об этом не подозреваете. Экономия увеличится в геометрической прогрессии, если избегать передачи состояния в параметрах и максимально использовать функции. Раздражающий повторяющийся код легко преобразовать в общие функции, как показано в следующем листинге.
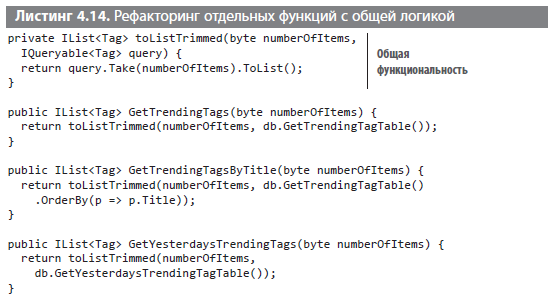
В этом примере экономия незначительна, но в иных случаях подобный рефакторинг может иметь большее значение. Важный вывод: используйте рефакторинг, чтобы избежать повторения кода и комбинаторного ада.
Тот же метод можно использовать с параметрами enum, которые применяются для назначения функции определенной операции. Используйте отдельные функции и даже композицию функций вместо передачи списка параметров.
4.8. ИМЕНОВАНИЕ ТЕСТОВ
Имена очень важны. Поэтому важны и грамотные соглашения как для рабочего, так и для тестового кода, хотя эти виды не обязательно должны пересекаться. Тесты с хорошим покрытием могут служить спецификациями, если имеют корректное название. Из названия
- теста должно быть понятно:
- имя тестируемой функции;
- входные данные и начальное состояние;
- ожидаемое поведение;
- кто виноват.
Последнее, конечно, шутка. Помните? После код-ревью вашему коду дан зеленый свет. Кроме себя, винить некого. В лучшем случае вы можете разделить вину с кем-нибудь. Я обычно использую для имен тестов формат A_B_C, и он заметно отличается от обычного стиля именования. В предыдущих примерах мы использовали более простую схему, потому что для описания начального состояния теста служил атрибут TestCase. Я использую дополнительно ReturnsExpectedValues, но можно просто добавить Test к имени функции. Лучше не использовать только имя функции, потому что вас может сбить с толку ее появление в списках автозавершения кода. Точно так же если функция не принимает входные данные или не зависит от начального состояния, можно пропустить эту часть имени. Цель — тратить меньше времени на тесты, а не вводить драконовские законы именования.
Предположим, босс попросил вас написать новое правило проверки формы регистрации, чтобы код возвращал ошибку, если клиент не принял условия обслуживания. Именем такого теста будет Register_LicenseNotAccepted_ShouldReturnFailure, как показано на рис. 4.6.
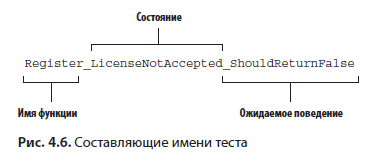
Это не единственное возможное соглашение об именовании. Некоторые разработчики предпочитают создавать внутренние классы для каждой тестируемой функции и вносить в имена только состояние и ожидаемое поведение, но я считаю такие названия слишком громоздкими. Важно выбрать соглашение, которое лучше всего подходит для вас.
ИТОГИ
- С нежеланием писать тесты справиться легко: многие из них можно просто не писать.
- Разработка через тестирование и другие подобные парадигмы могут вызвать еще большее нежелание писать тесты. Старайтесь писать тесты, которые вас радуют.
- Фреймворки, особенно для параметризованных тестов на основе данных, значительно упрощают создание тестов.
- Количество тестовых сценариев можно заметно сократить, тщательно проанализировав граничные значения входных данных функции.
- Правильное использование типов позволит избежать множества ненужных тестов.
- Тесты не просто обеспечивают хорошее качество кода. Они помогают вам улучшить навыки разработки и повысить производительность.
- Тестирование в рабочей среде можно проводить, только если вы уже обновили свое резюме.
Об авторе
СЕДАТ КАПАНОГЛУ — разработчик-самоучка из Эскишехира, Турция. Работал инженером в корпорации Microsoft в Сиэтле (США), в подразделении Windows Core Operating System. Его профессиональная карьера в области разработки ПО насчитывает три десятилетия.
Седат — младший из пятерых детей в боснийской семье, эмигрировавшей из бывшей Югославии в Турцию. Он основал популярную турецкую пользовательскую платформу Ekşi Sözlük (https://eksisozluk.com), что дословно переводится как «кислый словарь». В 1990-х годах активно участвовал в деятельности турецкой демосцены — международного сообщества в сфере цифрового искусства, члены которого занимаются созданием компьютерных графических и музыкальных произведений.
Связаться с ним можно в Twitter (@esesci) или в его авторском блоге, посвященном программированию, на ssg.dev.
Седат — младший из пятерых детей в боснийской семье, эмигрировавшей из бывшей Югославии в Турцию. Он основал популярную турецкую пользовательскую платформу Ekşi Sözlük (https://eksisozluk.com), что дословно переводится как «кислый словарь». В 1990-х годах активно участвовал в деятельности турецкой демосцены — международного сообщества в сфере цифрового искусства, члены которого занимаются созданием компьютерных графических и музыкальных произведений.
Связаться с ним можно в Twitter (@esesci) или в его авторском блоге, посвященном программированию, на ssg.dev.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Кодер
