Сегодня мы находимся момент появления у генеративного искусственного интеллекта (ИИ) зачатков будущего технологического стека. Ежегодно сотни новых стартапов устремляются на рынок для разработки моделей обучения, создания приложений на основе ИИ, инструментов для взаимодействия с ним и построения инфраструктуры для поддержки работы всего этого.
Часто новые технологические тенденции становятся «пузырями» задолго до того, как они реально становятся востребованными на рынке. Но бум генеративных ИИ сопровождается реальными достижениями на реальных рынках и реальной подпиткой со стороны реальных компаний. Такие модели, как Stable Diffusion или ChatGPT устанавливают исторические рекорды роста пользователей, а несколько приложений на основе ИИ достигли годового дохода в размере 100 миллионов долларов менее чем через год после запуска. И пора признать, что в некоторых задачах искусственный интеллект уже превосходит людей на несколько порядков. Вопрос один: кто получает основной профит от этого и кто будет владеть всем этим в будущем?
За последний год мы (авторы исходной статьи, прим. переводчика) встретились с десятками основателей и руководителей в стартапах в этой области, а также крупных компаниях, которые имеют дело непосредственно с генеративным ИИ. И мы заметили, что большую часть доходов от этого получают поставщики инфраструктуры. В то же время компании, занимающиеся непосредственно приложениями, очень быстро увеличивают свою выручку, но при этом вынуждены бороться с удержанием пользователей. А вот большинство поставщиков моделей ИИ, хотя и несут ответственность за само существование этого рынка, все еще не достигли больших коммерческих успехов.
Другими словами, компании, создающие наибольшую ценность, то есть обучающие генеративные модели ИИ и применяющие их в новых приложениях, не захватили большую часть рынка, когда речь идет о доходах. И пока еще сложно предсказать, что будет дальше. Давайте попробуем разобрать стек генеративного ИИ и понять, какие его части будут действительно востребованы и подвержены развитию, и кто вероятные бенефициары этого процесса.

Высокоуровневый стек технологий: инфраструктура, модели и приложения
Чтобы понять, как формируется рынок генеративного ИИ, сначала нужно определить, как выглядит стек сегодня. Мы его видим вот так:
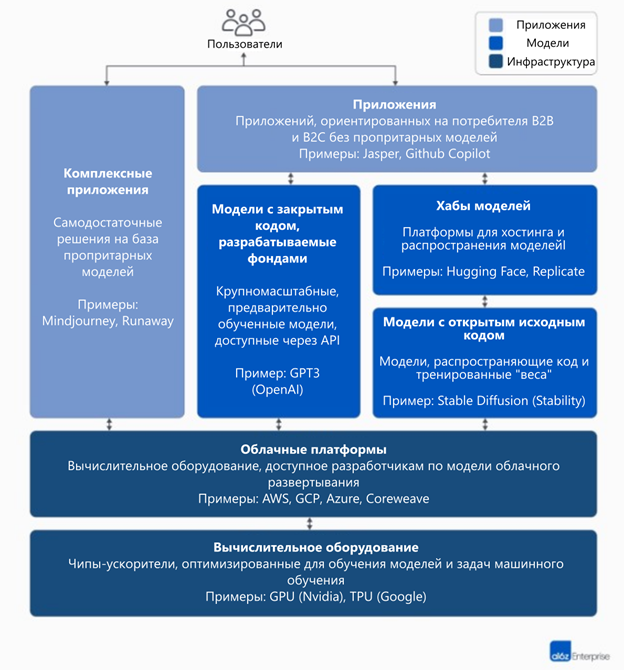
Стек можно разделить на три слоя:
1. Приложения, которые интегрируют генеративные модели ИИ в продукт, ориентированный на пользователя, или запуская свои собственные конвейеры моделей («комплексные приложения») или полагаясь на сторонний API.
2. Модели, которые «питают» продукты ИИ, доступные либо как проприетарные API, либо как «срезы» из решений с открытым исходным кодом (которые, в свою очередь, также требуют хостинга где-либо)
3. Поставщики инфраструктуры (т. е. облачные платформы и производители оборудования), которые предоставляют ресурсы для обучения генеративных моделей ИИ и предоставления результатов работы с ними.
Первая волна приложений на основе генеративных ИИ показывает огромный рост, но борется с удержанием и дифференциацией

Ранее (в предыдущих технологических циклах) считалось, что для создания крупной, независимой компании вы должны «владеть» конечным потребителем. Не важно, будут ли это индивидуальных потребители или покупатели сегмента B2B. Обычным пользователям было бы заманчиво предполагать, что крупнейшие компании в области генеративного ИИ будут вкладываться в основном в приложения для конечных пользователей, а не уйдут на рынок «бизнес-крупняка», но пока этот вопрос неясен.
Да, рост генеративных приложений на основе ИИ был ошеломляющим, чему способствовала явная новизна и множество вариантов использования. Но мы точно можем очертить три категории продуктов, годовые доходы которых уже превысили 100 миллионов долларов — это генерация изображений, копирайтинг и написание кода.
Однако одного роста недостаточно для создания компаний-разработчиков программного обеспечения устойчивых долгое время. Критически важно, чтобы рост был также прибыльным, то есть, когда пользователи и клиенты как генерируют прибыль сразу с момента своей регистрации (высокая валовая прибыль), так и остаются в течение длительного времени (высокое удержание). В отсутствие сильной технической дифференциации, приложения B2B и B2C повышают долгосрочную ценность для клиентов за счет все большего охвата клиентов, хранения промежуточной информации или создания все более сложных рабочих процессов.
Хотя на «входе в маркетинговую воронку» мы сейчас видим давку, но смогут ли текущие стратегии привлечения клиентов стать масштабируемыми? Можно наблюдать, что эффективность платных подписок и цифры удержания клиентов начинают снижаться. Многие приложения находятся в зоне риска, поскольку они часто полагаются на аналогичные базовые модели ИИ и не содержат в себе каких-то особенностей, которые конкурентам трудно было бы продублировать.
Пока что не очевидно, является ли продажа приложений для конечных пользователей единственным или даже лучшим путем к созданию устойчивого бизнеса на основе генеративных ИИ. По идее маржа должна увеличиваться по мере роста конкуренции и эффективности применяемых языковых моделей. Удержание также должно увеличиться, поскольку «туристы ИИ» покидают рынок (речь идет о сравнении с туристами, которые приезжают лишь на короткий период времени и постоянно проживающими жителями, прим. переводчика). Мы думаем, что, вертикально интегрированные приложения имеют преимущество в дифференциации, но все покажет лишь время.
Компании, занимающиеся приложениями на основе генеративных ИИ, сейчас задаются вопросами:
Делать ли вертикальную интеграцию («модель + приложение»). Использование сторонних сервисов моделей ИИ позволяет разработчикам приложений быстро выполнять итерации силами небольшой команды и менять поставщиков моделей по мере развития технологий. С другой стороны, некоторые разработчики утверждают, что их продукт является именно моделью, и что только обучение с нуля и постоянного переобучение на основе проприетарных данных является единственной защитой от создания клонов. Но это требует гораздо большего вложения средств в проект и ограничивает скорость работы команды продукта.
Делать упор на функции против приложений. Продукты на основе генеративных ИИ имеют несколько различных форм: настольные приложения, мобильные приложения, плагины Figma / Photoshop, расширения Chrome и даже боты Discord (привет Mindjourney). Легко интегрировать продукты на основе ИИ туда, с чем уже работают пользователи, так как пользовательский интерфейс часто представляет собой просто текстовое поле. Как вы думаете, какие продукты станут самостоятельными компаниями, а какие будут поглощены действующими компаниями, такими как Microsoft или Google, уже внедряющими ИИ в свои продуктовые линейки?
Управление через цикл хайпа. Пока неясно, присущ ли отток пользователей только определенным версиям продуктов на основе генеративных ИИ или это артефакты формирующегося рынка? Или всплеск интереса к генеративному ИИ затихнет по мере утихания шумихи по ним? Эти вопросы имеют важные последствия для компаний, занимающихся разработкой приложений, в том числе, когда следует «нажать на педаль газа» при сборе средств; насколько агрессивно инвестировать в привлечение клиентов; какие приоритеты следует расставить разным сегментам пользователей и когда декларировать пригодность продукта для рынка.
Поставщики моделей изобрели генеративный ИИ, но не достигли большого успеха в их коммерциализации

То, что мы сейчас называем генеративным ИИ, не существовало бы без блестящей исследовательской и инженерной работы, проделанной Google, OpenAI и Stability. Благодаря новым архитектурам моделей и героическим усилиям по масштабированию потоков обучения мы все извлекаем выгоду из умопомрачительных возможностей современных больших языковых моделей (LLM) и моделей генерации изображений.
Тем не менее, доход самих разработчиков моделей все еще относительно невелики по сравнению с размером их использования и шумихой вокруг них. Stable Diffusion демонстрирует взрывной рост сообщества, поддерживаемый экосистемой пользовательских интерфейсов, онлайнового сервиса и методов тонкой настройки. Но Stability бесплатно отдает «срезы» своих наработок, ставя это основным принципом своего бизнеса. В моделях естественного языка OpenAI доминирует с GPT-3/3.5 и ChatGPT. Но до сих пор существует относительно немного приложений-убийц, построенных на решениях OpenAI, и сама компания уже вынуждена была снижать цены на свои услуги (и начала процесс монетизации того же ChatGPT, прим. переводчика).
Да, это может быть просто временным явлением. Stability — это молодая компания, которая еще не сосредоточилась на монетизации. OpenAI может стать крупным бизнесом, забирая значительную часть доходов во всех категориях обработки естественного языка (NLP) по мере создания большего количества «убийственных» приложений, особенно если будет успешной интеграция их во множество продуктов Microsoft. То есть доходы от моделей будут соизмеримы с уровнем их использования.

Но есть и уравновешивающие силы – это модели, выпущенные с открытым исходным кодом. Они могут быть размещены кем угодно и где угодно, включая сторонние компании, которые не несут расходов, связанных с их крупномасштабным обучением (а это часто десятки, а то и сотни миллионов долларов затрат). Поэтому неясно, смогут ли модели с закрытым исходным кодом сохранять свое преимущество бесконечно. Например, уже сейчас LLM, построенные компаниями Anthropic, Cohere и Character.ai приближаются к уровню производительности аналогичных моделей OpenAI и при этом все они обучаются на аналогичных наборах данных (то есть из Интернет). Пример Stable Diffusion показывает, что если модели с открытым исходным кодом достигают достаточного уровня производительности и поддержки сообщества, то проприетарным альтернативам может быть трудно конкурировать с ними.
Возможно, самым очевидным выводом для поставщиков моделей будет то, что коммерциализировать надо не сами модели, а их хостинг. Спрос на проприетарные API (от того же OpenAI) быстро растет среди производителей приложений. Услуги хостинга для моделей с открытым исходным кодом (например, Hugging Face или Replicate) становятся полезными центрами для легкого обмена и интеграции моделей и даже налаживают «мосты» между производителями моделей и их потребителями.
Но перед поставщиками моделей также стоят ряд больших вопросов:
Из элитного в общедоступный. Существует распространенное мнение, что модели ИИ со временем будут сближаться в производительности. Разговаривая с разработчиками приложений, становится ясно, что это еще не произошло и мы пока еще имеем лидеров как в текстовых, так и в графических моделях. Но их преимущества часто основаны не на уникальных архитектурах моделей, а на доступе к финансированию, проприетарных данных и общем дефиците талантливых специалистов в области ИИ. Но насколько долго продлится эта элитарность?
Риск остаться без работы. Полагаться на поставщиков моделей — это отличный способ для компаний, занимающихся разработкой приложений на начальной стадии и даже для построения бизнеса. Но при этом у этих компаний появляется стимул создавать и/или размещать свои собственные модели, как только они достигнут определенных размеров по клиентам и доходам. Многие поставщики моделей находятся в положении, когда большую часть их дохода составляют лишь несколько приложений. Что произойдет, когда эти клиенты решат, что могут сами разработать свой ИИ?
Так ли важны деньги? Перспективы генеративного ИИ настолько велики, а также потенциально настолько вредны, что многие поставщики моделей вынуждены представляться общественными организациями, закладывая общественное благо как часть своей миссии, чтобы успокоить общественное мнение. Хотя это нисколько не мешает им получать доходы с моделей. Но дискуссии о том, бескорыстны ли действия поставщиков моделей и не хотят ли они захватить таким образом сегменты рынка (особенно людской рабочей силы), не утихают.
Поставщики инфраструктуры успевают везде и пожинают плоды

Почти все в генеративном ИИ в какой-то момент проходит через облачный графический процессор (или тензорный процессор - TPU). Будь то поставщики моделей, исследовательские лаборатории, хостинговые компании ИИ или все вместе - FLOPS являются жизненной силой генеративного ИИ. Впервые за очень долгое время прогресс в области революционных вычислительных технологий в значительной степени связан непосредственно с вычислениями.
В результате большая часть денег на рынке генеративного ИИ в итоге поступает в инфраструктурные компании. По нашим оценкам, компании, занимающиеся приложениями, тратят около 20–40% своего дохода просто на вывод информации и тонкую настройку для каждого клиента. Обычно эта сумма выплачивается либо непосредственно облачным провайдерам за вычислительные инстансы, либо сторонним поставщикам моделей, которые, в свою очередь, тратят около половины своего дохода на облачную инфраструктуру. Таким образом, разумно предположить, что минимум 10–20% от общего дохода в генеративном ИИ сегодня идет облачным провайдерам.
Кроме того, стартапы, обучающие свои собственные модели, привлекли миллиарды долларов венчурного капитала и большая часть которого, как правило, также тратится на облачных провайдеров (иногда до 80–90% в ранних раундах). Многие публичные технологические компании тратят сотни миллионов долларов в год на обучение моделей. При этом они вкладываются либо во внешних облачных провайдеров, либо непосредственно в производителей оборудования.
И это реально «большие деньги», особенно для зарождающегося рынка. Большая часть средств тратится на облака «большой тройки»: Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure. Эти облачные провайдеры в совокупности вложили почти 100 миллиардов долларов в год в капитальные затраты, чтобы обеспечить себе наиболее полные, надежные и конкурентоспособные по стоимости платформы.
При этом такие стартапы, как Coreweave и Lambda Labs смогли вклиниться на этот рынок с решениями, ориентированными специально на крупных разработчиков моделей. Они конкурируют по стоимости, доступности и персонализированной поддержке и предоставляют более детальную абстракцию ресурсов (т. е. контейнеры), в то время как «большие облака» предлагают только инстансы виртуальных машин из-за ограничений виртуализации GPU.

Серым кардиналом и победителем в части оборудования для генеративных ИИ является компания Nvidia. Ее доходы от GPU для центров обработки данных в третьем квартале 2023 финансового года составили 3,8 миллиарда долларов, и значительную часть принесли как раз сценарии использования генеративного ИИ. Компания вырыла надежный «ров» вокруг этого бизнеса благодаря десятилетиям инвестиций в архитектуру GPU, надежную экосистему программного обеспечения и массовое использование в академическом сообществе. Графические процессоры Nvidia цитируются в исследовательских работах в 90 раз чаще, чем лучшие стартапы-производители чипов ИИ вместе взятые.
Существуют и другие варианты аппаратного обеспечения, в том числе тензорные процессоры Google, графические процессоры AMD Instinct, чипы AWS Inferentia и Trainium. Также на рынке представлены акселераторы ИИ от таких стартапов, как Cerebras, Sambanova и Graphcore. Intel, увы опоздавшая к раздаче «слонов ИИ», выходит на рынок со своими высококлассными чипами Habana и графическими процессорами Ponte Vecchio. Но до сих пор немногие из этих новых чипов заняли значительную долю рынка. Двумя исключениями являются Google, чьи TPU завоевали популярность в сообществе Stable Diffusion и у некоторых крупных облачных клиентов и, как не странно, TSMC, который скорее всего и производит все перечисленные здесь чипы, включая графические процессоры Nvidia (Intel использует как свои собственные фабрики, так и мощности TSMC для производства своих чипов).
Другими словами, инфраструктура является прибыльным, долговечным и, казалось бы, наиболее защищенным слоем в стеке генеративных ИИ. Но и тут возникают определенные вопросы:
Рабочие нагрузки, а не сохранение данных. Графические процессоры Nvidia одинаковы везде, где бы вы их не арендовали. Большинство рабочих процессов ИИ не требуют длительного хранения данных в том смысле, что вывод модели не требует прикреплять к нему огромные базы данных (кроме самих весов модели). Это означает, что рабочая нагрузка ИИ может быть легко перенесена из одного облака в другое и что мешает клиенту в этом случае перейти к самому дешевому провайдеру облачных услуг?
Окончание дефицита чипов. Высокие расценки облачных провайдеров и самой Nvidia сейчас поддерживаются скудными поставками наиболее желанных графических процессоров. Но когда это ограничение поставок будет устранено за счет увеличения производства и/или внедрения новых аппаратных платформ, как это повлияет на облачных провайдеров и саму Nvidia?
Могут ли прорваться конкуренты? Мы уверены, что вертикальные облака отнимут долю рынка у Big 3 более специализированными предложениями. И до сих пор конкурент в области инфраструктуры для ИИ добивались успеха только за счет того, что у остальных все было примерено одинаково, так как для той же Nvidia действующие облачные провайдеры являются как крупнейшими клиентами, так и новыми конкурентами. Вопрос заключается в том, будет ли «не быть как все» достаточно, чтобы преодолеть масштабные преимущества Big 3, которые что-то начали подозревать?
Так... и у кого будет вся прибыль?
Мы не знаем это точно, но можем предположить, что сегодня нет никаких способов «вырыть ров» вокруг своего бизнеса в генеративном ИИ для защиты от наступления конкурентов: приложениям не хватает отличительной особенности для их продукта, поскольку они используют похожие модели; модели сталкиваются с неясной долгосрочной дифференциацией, поскольку они обучаются на сходных наборах данных и на похожих архитектурах; облачным провайдерам не хватает глубокой технической дифференциации, поскольку они используют одни и те же графические процессоры; и даже производители чипов производят их на одних и тех же фабриках.
Конечно можно задавить конкурентов масштабом («У меня есть или я могу собрать больше денег, чем вы!»), цепочками поставок («У меня есть графические процессоры, у вас их нет!»), экосистемой («Все уже используют мое программное обеспечение!»), алгоритмами («Мы умнее вас!»), маркетингом («У меня уже есть команда продаж и больше клиентов, чем у вас!») и даже размером выборки данных («Я обработал больше Интернета, чем вы!»). Но ни один из способов защиты не долговечен в долгосрочной перспективе. И еще слишком рано говорить о том имеет ли место на каком-либо уровне стека «эффект толпы» и будет ли единственный победитель на рынке.
Это странно. Но для нас это хорошая новость. Потенциальный размер этого рынка трудно понять. Он лежит где-то между всем программным обеспечением и всеми человеческими усилиями, поэтому мы ожидаем приход еще большего числа игроков и здоровой конкуренции на всех уровнях стека. Мы также ожидаем, что как горизонтальные, так и вертикальные компании добьются успеха, причем лучший подход будет продиктован конечными рынками и конечными пользователями.
Мы в RoboUniver точно уверены в одной вещи: генеративный ИИ меняет всю игру. Игру, в которой мы все изучаем правила в режиме реального времени, где разблокируется всё большего нового контента и возможностей и в результате возможно уже через пару-тройку лет мировой технический ландшафт будет выглядеть намного иначе.
