
Совсем недавно два стандарта – OpenTracing и OpenCensus – окончательно объединились в один. Появился новый стандарт распределенного трейсинга и мониторинга – OpenTelemetry. Но несмотря на то, что разработка библиотек идет полным ходом, реального опыта его использования пока не слишком много.
Илья Казначеев color, который занимается разработкой восемь лет и работает backend-разработчиком в МТС, готов поделиться тем, как применять OpenTelemetry в Golang-проектах. На конференции Golang Live 2020 он рассказал о том, как настроить использование нового стандарта для трейсинга и мониторинга и подружить его с уже существующей в проекте инфраструктурой.
OpenTelemetry – стандарт, который появился относительно недавно: в конце прошлого года. При этом он получил широкое распространение и поддержку множества вендоров ПО для трейсинга и мониторинга.
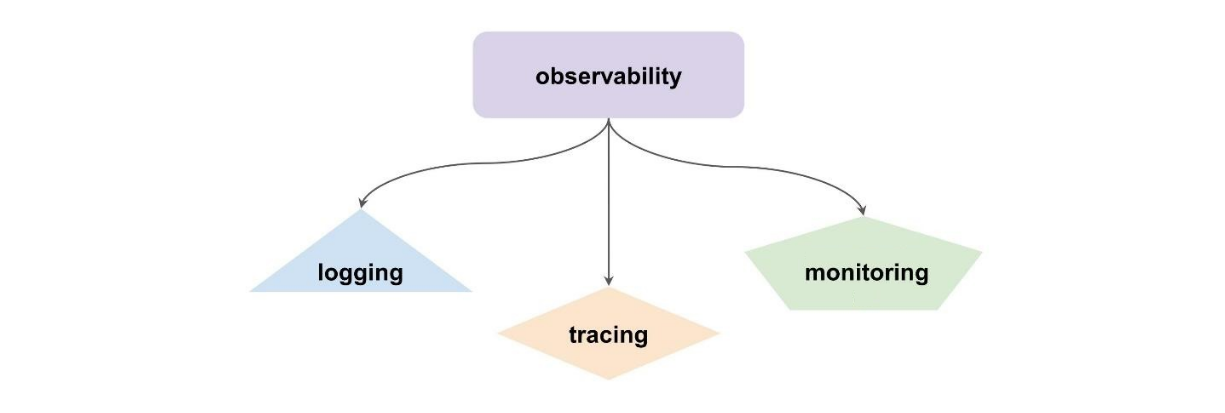
Observability, или наблюдаемость, – термин из теории управления, который определяет, насколько можно судить о внутреннем состоянии системы по ее внешним проявлениям. В системной же архитектуре это обозначает набор подходов к наблюдению за состоянием системы в рантайме. К таким подходам относятся логирование, трейсинг и мониторинг.
Для трейсинга и мониторинга существует множество вендорских решений. До недавнего времени было два открытых стандарта: OpenTracing от CNCF, который появился в 2016, и Open Census от Google, появившийся в 2018.
Это два довольно неплохих стандарта, которые конкурировали между собой некоторое время, пока в 2019 году они не решили объединиться в один новый стандарт, который называется OpenTelemetry.

Этот стандарт включает в себя распределенный трейсинг и мониторинг. Он совместим с первыми двумя. Более того, OpenTracing и Open Census прекращают поддержку в течение двух лет, что неотвратимо приближает нас к переходу на OpenTelemetry.
Сценарии использования
Стандарт предполагает широкие возможности совмещения всего со всем и является по сути активной прослойкой между источниками метрик и трейсов и их потребителями.
Давайте взглянем на основные сценарии.
Для распределенного трейсинга можно напрямую настроить подключение к Jaeger или к тому сервису, который вы используете.
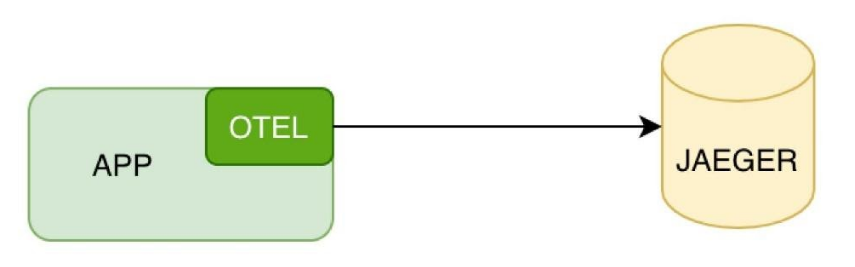
Если трейсинг транслируется напрямую, можно использовать config и просто заменить библиотеку.
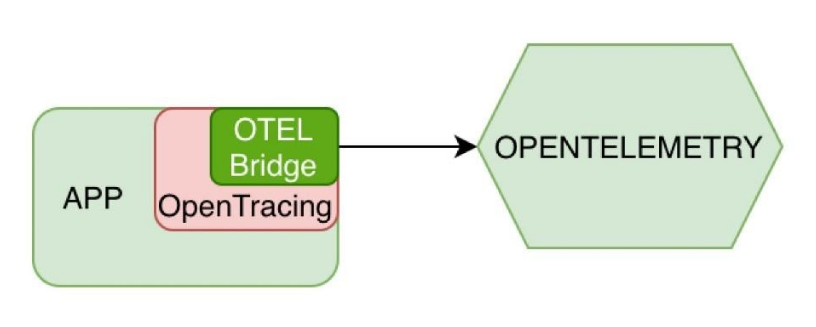
В случае, если ваше приложение уже использует OpenTracing, можно воспользоваться OpenTracing Bridge – оберткой, которая будет конвертировать запросы к OpenTracing API в OpenTelemetry API на верхнем уровне.
Для сбора метрик также можно настроить прямой доступ в Prometheus к порту для сбора метрик вашего приложения.
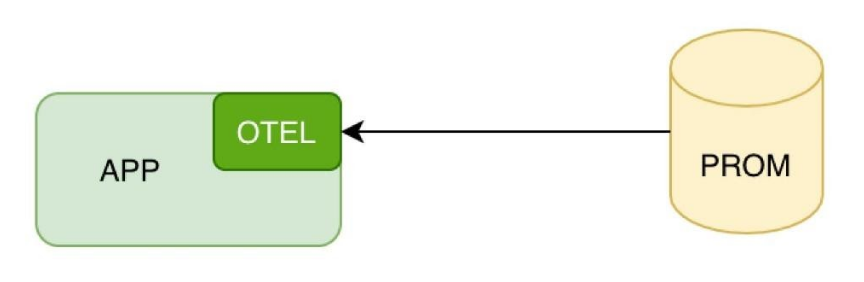
Это пригодится, если у вас простая инфраструктура, и вы собираете метрики напрямую. Но стандарт предоставляет и более гибкие возможности.
Основной сценарий использования стандарта – это сбор метрик и трейсов через коллектор, который также запускается отдельным приложением либо контейнером в вашу инфраструктуру. Кроме того, можно взять готовый контейнер и установить его у себя.
Для этого достаточно настроить в приложении экспортер в формате OTLP. Это grpc-схема для передачи данных в формате OpenTracing. Со стороны коллектора можно настроить формат и параметры экспорта метрик и трейсов конечным потребителям, либо в другие форматы. Например, в OpenCensus.

Коллектор позволяет подключать большое количество видов источников данных и множество приемников данных на выходе.
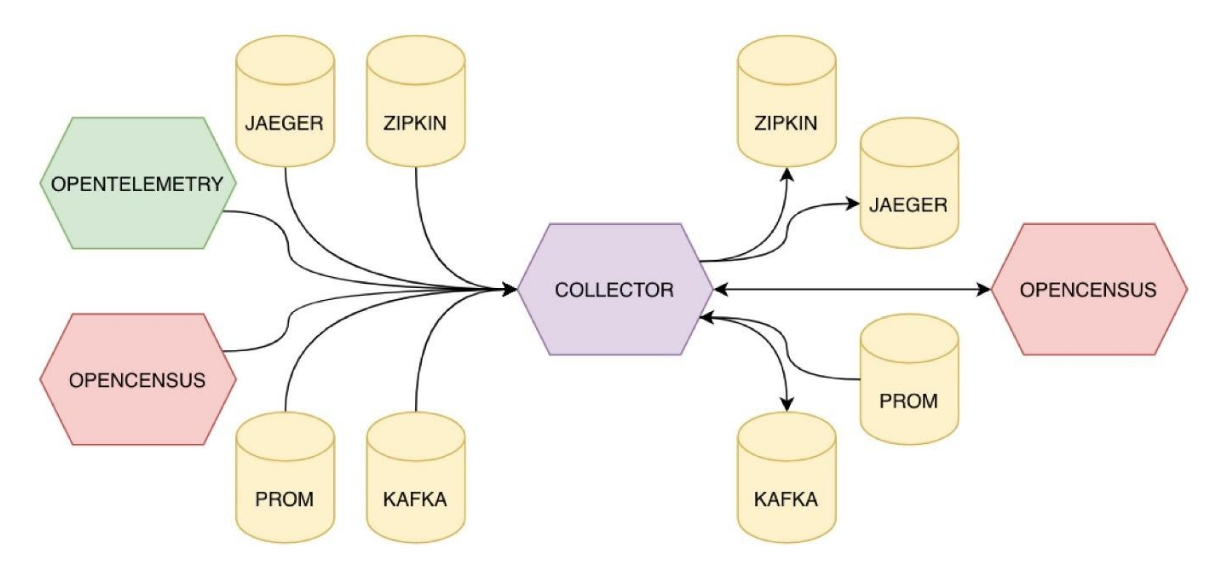
Таким образом, стандарт OpenTelemetry обеспечивает совместимость с многими открытыми и вендорскими стандартами.
Стандартный коллектор расширяем. Поэтому у большинства вендоров уже готовы экспортеры в их собственные решения, если они есть. Вы можете использовать OpenTelemetry, даже если применяете сбор метрик и трейсов от какого-то закрытого вендора. Таким образом решается проблема с vendor lock-in. Даже если что-то еще не появилось непосредственно для OpenTelemetry, это можно пробросить через OpenCensus.
Сам коллектор очень просто конфигурируется через банальный YAML конфиг:

Здесь указываются ресиверы. В вашем приложении может быть какой-то другой источник (Kafka и т.д.):

Экспортеры – получатели данных.
Процессоры – методы обработки данных внутри коллектора:

И pipelines, которые непосредственно определяют, как будет обрабатываться каждый поток данных, который протекает внутри коллектора:

Давайте рассмотрим один показательный пример.

Допустим, у вас есть некий микросервис, к которому вы уже прикрутили OpenTelemetry и настроили его. И еще один сервис с аналогичной фрагментацией.
Пока все легко. Но появляются:
Все эти метрики можно объединить одним коллектором.
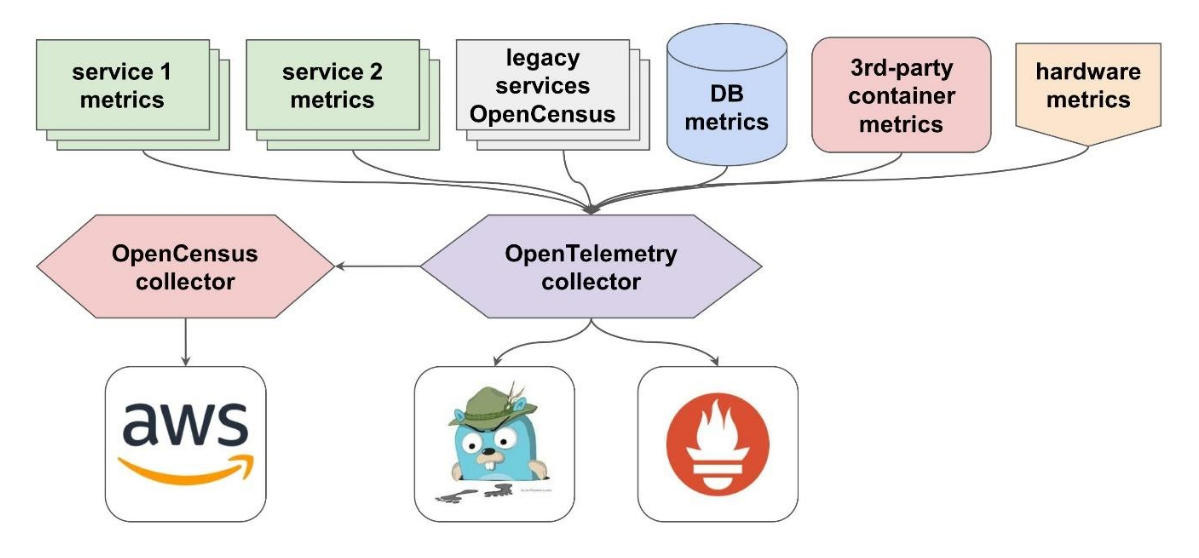
Уже сейчас он поддерживает множество источников метрик и трейсов, которые используются в существующих приложениях. А на случай, если вы используете что-то экзотическое, можно реализовать собственный плагин. Но вряд ли это понадобится на практике. Потому что приложения, которые экспортируют метрики или трейсы, так или иначе используют либо какие-то распространенные стандарты, либо открытые стандарты типа OpenCensus.
Теперь мы хотим использовать эту информацию. В качестве экспортера трейсов можно указать Jaeger, а метрики отправлять в Prometheus, или что-то совместимое. Допустим, всеми любимую VictoriaMetrics.
Но что, если мы вдруг решили переехать в AWS и использовать местный трейсер X‑Ray? Не проблема. Это можно пробросить через OpenCensus, в котором есть экспортер для X‑Ray.
Таким образом, из этих кусков можно собрать всю вашу инфраструктуру для метрик и трейсов.
С теорией покончено. Поговорим о том, как использовать трейсинг на практике.
Инструментация Golang приложения: трейсинг
Сначала нужно создать корневой span, от которого и будет расти дерево вызовов.
Здесь указывается название вашего сервиса или библиотеки. В трейсе таким образом можно определить spans, которые лежат именно в рамках вашего приложения, и те, которые пошли в импортированные библиотеки.
Дальше создается корневой span с указанием названия:
Выбирайте название, которое будет внятно описывать уровень трейса. Например, это может быть либо название метода (или класса и метода), либо слой архитектуры. Например, инфраструктурный уровень, уровень логики, уровень баз данных и т.д.
Данные о span также кладутся в контекст:
Поэтому в контекст нужно передавать методы, которые вы хотите трейсить.
Span представляет собой процесс на определенном уровне дерева вызова. В него можно положить атрибуты, логи и статусы ошибки, в случае ее возникновения. Span обязательно закрывать в конце. При закрытии рассчитывается его длительность.
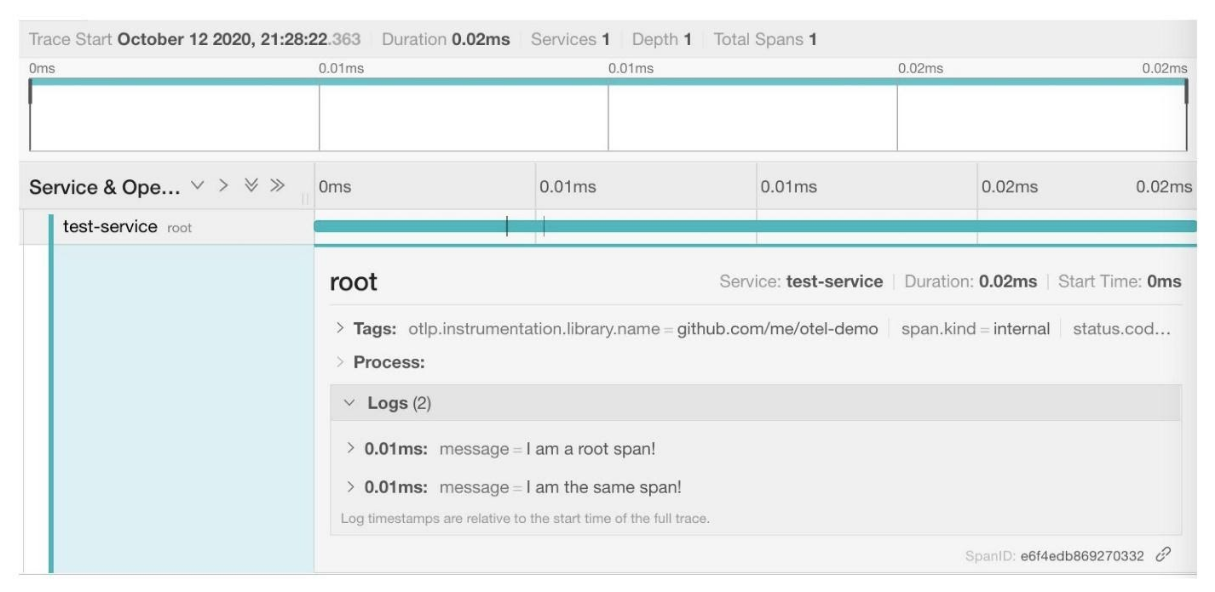
Так наш span выглядит в Jaeger:

Его можно развернуть и посмотреть логи и атрибуты.
Далее можно получить тот же span из контекста, если не хочется задавать новый. Например, вы хотите писать один архитектурный слой в один span, а слой у вас разбросан по нескольким методам и нескольким уровням вызова. Вы его получаете, пишете в него, и потом он закрывается.
Обратите внимание, что закрывать здесь его не нужно, потому что он закроется в том же методе, где был создан. Мы просто берем его из контекста.
Записываем сообщение в корневой span:
Иногда нужно создать новый дочерний span, чтобы он существовал отдельно.
Здесь мы получаем глобальный трейсер по имени библиотеки. Этот вызов можно обернуть в какой-нибудь метод, либо использовать глобальную переменную, потому что во всем вашем сервисе он будет одинаков.
Дальше создается дочерний span из контекста, и ему присваивается имя по аналогии с тем, как мы делали это в начале:
Не забудьте, что span нужно закрыть в конце метода, в котором он был создан.
Пишем в него сообщения, которые попадают в дочерний span.
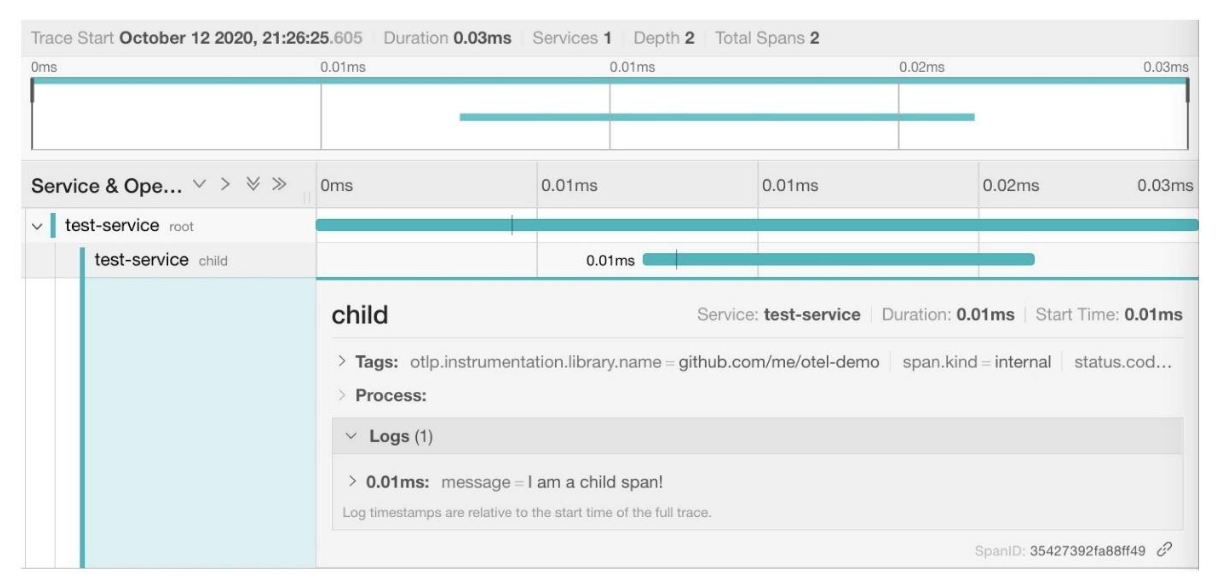
Здесь видно, что сообщения отображаются иерархически, и дочерний span находится под родительским. Он ожидаемо короче, потому что это был синхронный вызов.
В нем показываются атрибуты, которые можно писать в span:
Например, сюда попал наш request. id:

Можно добавлять events:
Кроме того, сюда можно добавлять label. Это работает примерно также, как структурный лог в виде logrus:
Здесь мы видим свое сообщение в логе span. Можно развернуть его и посмотреть labels. В нашем случае сюда добавился label count:
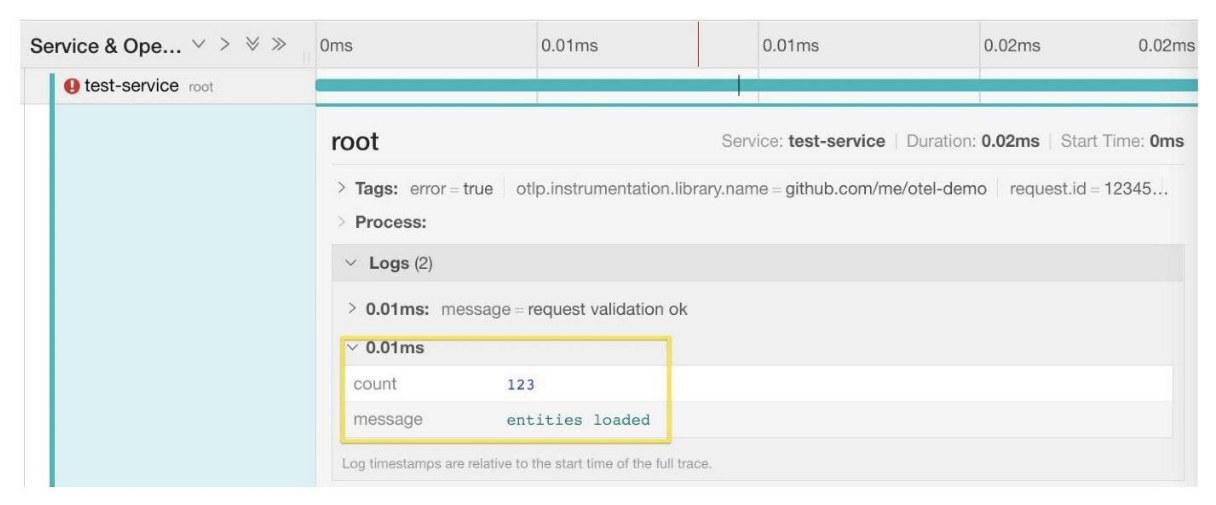
Потом это будет удобно использовать при фильтрации в поиске.
Если возникла ошибка, в span можно дописать статус. В этом случае он будет помечен как ошибочный.
Раньше стандарт использовал коды ошибок из OpenCensus, и они были из grpc. Сейчас оставили только OK, ERROR и UNSET. OK ставится по умолчанию, ERROR в случае ошибки добавляете вы.
Здесь видно, что трейс ошибки помечен красным значком. Есть код ошибки и сообщение о ней:

Нужно не забывать о том, что трейсинг – это не замена логов. Основной смысл в том, чтобы отслеживать протекание информации через распределенную систему, а для этого нужно класть трейсы в сетевые запросы и уметь читать их оттуда.
Трейсинг микросервисов
В OpenTelemetry уже есть множество set party реализаций interceptors и middleware для различных фреймворков и библиотек. Их можно найти в репозитории: github.com/open-telemetry/opentelemetry-go-contrib
Список фреймворков, для которых есть interceptors и middleware:
Как это использовать, посмотрим на примере стандартного http клиента и сервера.
middleware client
В клиенте просто добавляем interceptor в качестве транспорта, после чего наши запросы обогащаются на trace.id и необходимую для продолжения трейса информацию.
middleware server
На сервере добавляется небольшой middleware с названием библиотеки:
Дальше как обычно: получаете span из контекста, работаете с ним, пишите в него что-то, создаете дочерние spans, закрываете их и т.д.
Так выглядит простой запрос, проходящий через три сервиса:

На скриншоте видна иерархия вызовов, разделение на сервисы, их длительность, последовательность. На каждый из них можно кликнуть и посмотреть более подробную информацию.
А так выглядит ошибка:

Легко отследить, где она произошла, когда и сколько времени прошло.
В span можно посмотреть подробную информацию о контексте, в котором произошла ошибка:
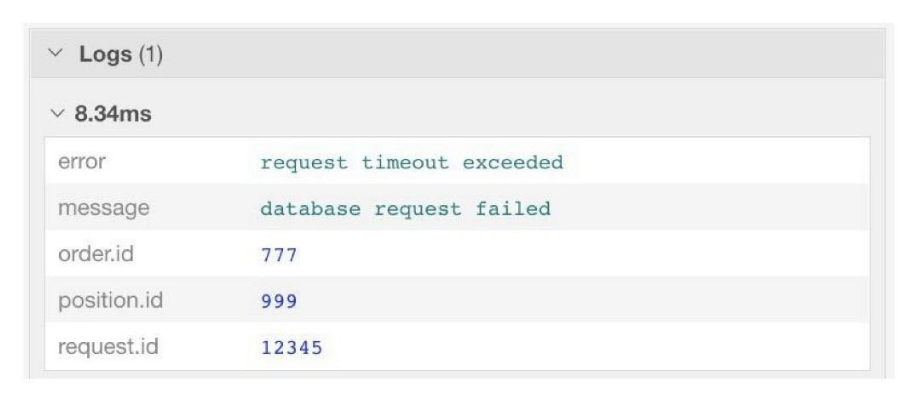
Более того, поля, которые относятся ко всему span (различные id запроса, ключевые поля в таблице в запросе, еще какие-то мета данные, которые вы хотите положить) можно вкладывать в span при его создании. Грубо говоря, не нужно копипастить все эти поля в каждое место, где вы обрабатываете ошибку. Можно записать данные о ней в span.
middleware func
Вот небольшой бонус: как сделать middleware, чтобы можно было использовать его в качестве глобального middleware для таких вещей как Gorilla и Gin:
Инструментация Golang приложения: мониторинг
Пришло время поговорить о мониторинге.
Подключение к системе мониторинга настраивается аналогично тому, что делается для трейсинга.
Измерения делятся на два типа:
1. Синхронные, когда пользователь явно передает значения в момент вызова:
int64, float64
2. Асинхронные, которые SDK считывает в момент коллекта данных из приложения:
int64, float64
Сами метрики бывают:
В начале программы создается глобальный измеритель, которому указывается название библиотеки или сервиса.
Дальше создается метрика:
Ей указывается название:
Описание:
Набор лейблов, по которым вы потом можете фильтровать запросы. Например, при построении дашбордов в Grafana:
В конце программы также нужно вызвать Unbind для каждой метрики, что освободит ресурсы и правильно ее закроет:
Записывать изменения просто:
Это положительные числа для Counter, любые числа для UpDownCounter, которые он будет суммировать, и также любые числа для ValueRecorder. Для всех видов инструментов в Go поддерживаются int64 и float64.
Вот что мы получаем на выходе:
Это наша метрика с комментарием и заданным лейблом. Потом можно ее взять либо напрямую через Prometheus, либо экспортировать через OpenTelemetry коллектор, и дальше использовать там, где нам нужно.
Инструментация Golang приложения: библиотеки
Последнее, о чем хочется сказать – это возможность, которую стандарт дает для инструментирования библиотек.
Раньше, когда использовались OpenCensus и OpenTracing, вы не могли инструментировать ваши отдельные библиотеки, особенно опенсорсные. Потому что в этом случае у вас получался vendor lock-in. Тот, кто плотно работал с трейсингом, наверняка обращал внимание на то, что большие клиентские библиотеки, или крупные API к облачным сервисам, время от времени падают с трудно объяснимыми ошибками.
Тут бы очень пригодился трейсинг. Особенно в продуктиве, когда у вас происходит какая-то неясная ситуация, и очень хотелось бы знать, почему она произошла. Но все, что у вас есть – это сообщение об ошибке из вашей импортированной библиотеки.
OpenTelemetry решает эту проблему.

Так как в стандарте SDK и API разделены, API трейсинга метрик можно использовать независимо от SDK и конкретных настроек экспорта данных. Более того, вы можете сначала инструментировать свои методы, а только потом настроить экспорт этих данных вовне.
Таким образом можно инструментировать импортируемую библиотеку, не заботясь о том, как и куда будут экспортированы эти данные. Это подойдет и для внутренних, и для открытых опенсорсных библиотек.
Не нужно заботиться о vendor lock-in, не нужно переживать по поводу того, как будет использована эта информация и будет ли использована вообще. Библиотеки и приложения инструментируются заранее, а конфигурация экспорта данных указывается при инициализации приложения.
Таким образом видно, что настройки конфигурации задаются в SDK приложении. Дальше нужно заняться экспортерами трейсинга и метрик. Это может быть один экспортер через OTLP, если вы экспортируете в OpenTelemetry коллектор. Потом все необходимые трейсы и метрики попадают в контекст, а он пропагируется по дереву вызова другим методом вниз.
Приложение наследует от корневого span остальные spans, просто используя OpenTelemetry API и данные, которые лежат в контексте. При этом импортируемые библиотеки получают на вход методы контекст, пытаются считать из этого метода информацию о корневом span. Если его нет, создают свой, и дальше инструментируют логику. Таким образом, вы можете сначала инструментировать свою библиотеку.
Более того, вы можете инструментировать все, но не настраивать экспортеры данных, и просто задеплоить это.
У вас это может работать в проде, и пока инфраструктура не устоялась, у вас не будет настроен трейсинг и мониторинг. Потом вы настроите их, развернете там коллектор, какие-то приложения для сбора этих данных, и у вас все заработает. Вам не нужно ничего менять непосредственно в самих методах.
Таким образом, если у вас какая-то опенсорсная библиотека, вы можете инструментировать ее при помощи OpenTelemetry. Потом люди, которые ее используют, настроят у себя OpenTelemetry и будут использовать эти данные.
В заключении хочу сказать, что стандарт OpenTelemetry многообещающий. Возможно, наконец это тот самый универсальный стандарт, который мы все хотели увидеть.
У нас в компании активно применяется стандарт OpenCensus для трейсинга и мониторинга микросервисного ландшафта компании. Планируется внедрение OpenTelemetry после его релиза.
Илья Казначеев color, который занимается разработкой восемь лет и работает backend-разработчиком в МТС, готов поделиться тем, как применять OpenTelemetry в Golang-проектах. На конференции Golang Live 2020 он рассказал о том, как настроить использование нового стандарта для трейсинга и мониторинга и подружить его с уже существующей в проекте инфраструктурой.

OpenTelemetry – стандарт, который появился относительно недавно: в конце прошлого года. При этом он получил широкое распространение и поддержку множества вендоров ПО для трейсинга и мониторинга.
Observability, или наблюдаемость, – термин из теории управления, который определяет, насколько можно судить о внутреннем состоянии системы по ее внешним проявлениям. В системной же архитектуре это обозначает набор подходов к наблюдению за состоянием системы в рантайме. К таким подходам относятся логирование, трейсинг и мониторинг.

Для трейсинга и мониторинга существует множество вендорских решений. До недавнего времени было два открытых стандарта: OpenTracing от CNCF, который появился в 2016, и Open Census от Google, появившийся в 2018.
Это два довольно неплохих стандарта, которые конкурировали между собой некоторое время, пока в 2019 году они не решили объединиться в один новый стандарт, который называется OpenTelemetry.

Этот стандарт включает в себя распределенный трейсинг и мониторинг. Он совместим с первыми двумя. Более того, OpenTracing и Open Census прекращают поддержку в течение двух лет, что неотвратимо приближает нас к переходу на OpenTelemetry.
Сценарии использования
Стандарт предполагает широкие возможности совмещения всего со всем и является по сути активной прослойкой между источниками метрик и трейсов и их потребителями.
Давайте взглянем на основные сценарии.
Для распределенного трейсинга можно напрямую настроить подключение к Jaeger или к тому сервису, который вы используете.

Если трейсинг транслируется напрямую, можно использовать config и просто заменить библиотеку.
В случае, если ваше приложение уже использует OpenTracing, можно воспользоваться OpenTracing Bridge – оберткой, которая будет конвертировать запросы к OpenTracing API в OpenTelemetry API на верхнем уровне.

Для сбора метрик также можно настроить прямой доступ в Prometheus к порту для сбора метрик вашего приложения.

Это пригодится, если у вас простая инфраструктура, и вы собираете метрики напрямую. Но стандарт предоставляет и более гибкие возможности.
Основной сценарий использования стандарта – это сбор метрик и трейсов через коллектор, который также запускается отдельным приложением либо контейнером в вашу инфраструктуру. Кроме того, можно взять готовый контейнер и установить его у себя.
Для этого достаточно настроить в приложении экспортер в формате OTLP. Это grpc-схема для передачи данных в формате OpenTracing. Со стороны коллектора можно настроить формат и параметры экспорта метрик и трейсов конечным потребителям, либо в другие форматы. Например, в OpenCensus.

Коллектор позволяет подключать большое количество видов источников данных и множество приемников данных на выходе.

Таким образом, стандарт OpenTelemetry обеспечивает совместимость с многими открытыми и вендорскими стандартами.
Стандартный коллектор расширяем. Поэтому у большинства вендоров уже готовы экспортеры в их собственные решения, если они есть. Вы можете использовать OpenTelemetry, даже если применяете сбор метрик и трейсов от какого-то закрытого вендора. Таким образом решается проблема с vendor lock-in. Даже если что-то еще не появилось непосредственно для OpenTelemetry, это можно пробросить через OpenCensus.
Сам коллектор очень просто конфигурируется через банальный YAML конфиг:

Здесь указываются ресиверы. В вашем приложении может быть какой-то другой источник (Kafka и т.д.):

Экспортеры – получатели данных.
Процессоры – методы обработки данных внутри коллектора:

И pipelines, которые непосредственно определяют, как будет обрабатываться каждый поток данных, который протекает внутри коллектора:

Давайте рассмотрим один показательный пример.

Допустим, у вас есть некий микросервис, к которому вы уже прикрутили OpenTelemetry и настроили его. И еще один сервис с аналогичной фрагментацией.
Пока все легко. Но появляются:
- legacy-сервисы, которые работают через OpenCensus;
- база данных, которая отдает данные в своем формате (например, напрямую в Prometheus, как это делает PostgreSQL);
- еще какой-то сервис, работающий в контейнере и отдающий метрики в своем формате. Вам не хочется перебилдить этот контейнер и прикручивать sidecars, чтобы они переформатировали метрики. Вы хотите просто брать и отправлять их.
- железо, с которого вы тоже собираете метрики и хотите как-то использовать их.
Все эти метрики можно объединить одним коллектором.

Уже сейчас он поддерживает множество источников метрик и трейсов, которые используются в существующих приложениях. А на случай, если вы используете что-то экзотическое, можно реализовать собственный плагин. Но вряд ли это понадобится на практике. Потому что приложения, которые экспортируют метрики или трейсы, так или иначе используют либо какие-то распространенные стандарты, либо открытые стандарты типа OpenCensus.
Теперь мы хотим использовать эту информацию. В качестве экспортера трейсов можно указать Jaeger, а метрики отправлять в Prometheus, или что-то совместимое. Допустим, всеми любимую VictoriaMetrics.
Но что, если мы вдруг решили переехать в AWS и использовать местный трейсер X‑Ray? Не проблема. Это можно пробросить через OpenCensus, в котором есть экспортер для X‑Ray.
Таким образом, из этих кусков можно собрать всю вашу инфраструктуру для метрик и трейсов.
С теорией покончено. Поговорим о том, как использовать трейсинг на практике.
Инструментация Golang приложения: трейсинг
Сначала нужно создать корневой span, от которого и будет расти дерево вызовов.
ctx := context.Background()
tr := global.Tracer("github.com/me/otel-demo")
ctx, span := tr.Start(ctx, "root")
span.AddEvent(ctx, "I am a root span!")
doSomeAction(ctx, "12345")
span.End()Здесь указывается название вашего сервиса или библиотеки. В трейсе таким образом можно определить spans, которые лежат именно в рамках вашего приложения, и те, которые пошли в импортированные библиотеки.
Дальше создается корневой span с указанием названия:
ctx, span := tr.Start(ctx, "root")Выбирайте название, которое будет внятно описывать уровень трейса. Например, это может быть либо название метода (или класса и метода), либо слой архитектуры. Например, инфраструктурный уровень, уровень логики, уровень баз данных и т.д.
Данные о span также кладутся в контекст:
ctx, span := tr.Start(ctx, "root")
span.AddEvent(ctx, "I am a root span!")
doSomeAction(ctx, "12345")
Поэтому в контекст нужно передавать методы, которые вы хотите трейсить.
Span представляет собой процесс на определенном уровне дерева вызова. В него можно положить атрибуты, логи и статусы ошибки, в случае ее возникновения. Span обязательно закрывать в конце. При закрытии рассчитывается его длительность.
ctx, span := tr.Start(ctx, "root")
span.AddEvent(ctx, "I am a root span!")
doSomeAction(ctx, "12345")
span.End()Так наш span выглядит в Jaeger:

Его можно развернуть и посмотреть логи и атрибуты.
Далее можно получить тот же span из контекста, если не хочется задавать новый. Например, вы хотите писать один архитектурный слой в один span, а слой у вас разбросан по нескольким методам и нескольким уровням вызова. Вы его получаете, пишете в него, и потом он закрывается.
func doSomeAction(ctx context.Context, requestID string) {
span := trace.SpanFromContext(ctx)
span.AddEvent(ctx, "I am the same span!")
...
}Обратите внимание, что закрывать здесь его не нужно, потому что он закроется в том же методе, где был создан. Мы просто берем его из контекста.
Записываем сообщение в корневой span:

Иногда нужно создать новый дочерний span, чтобы он существовал отдельно.
func doSomeAction(ctx context.Context, requestID string) {
ctx, span := global.Tracer("github.com/me/otel-demo").
Start(ctx, "child")
defer span.End()
span.AddEvent(ctx, "I am a child span!")
...
}Здесь мы получаем глобальный трейсер по имени библиотеки. Этот вызов можно обернуть в какой-нибудь метод, либо использовать глобальную переменную, потому что во всем вашем сервисе он будет одинаков.
Дальше создается дочерний span из контекста, и ему присваивается имя по аналогии с тем, как мы делали это в начале:
Start(ctx, "child")Не забудьте, что span нужно закрыть в конце метода, в котором он был создан.
ctx, span := global.Tracer("github.com/me/otel-demo").
Start(ctx, "child")
defer span.End()Пишем в него сообщения, которые попадают в дочерний span.

Здесь видно, что сообщения отображаются иерархически, и дочерний span находится под родительским. Он ожидаемо короче, потому что это был синхронный вызов.
В нем показываются атрибуты, которые можно писать в span:
func doSomeAction(ctx context.Context, requestID string) {
...
span.SetAttributes(label.String("request.id", requestID))
span.AddEvent(ctx, "request validation ok")
span.AddEvent(ctx, "entities loaded", label.Int64("count", 123))
span.SetStatus(codes.Error, "insertion error")
}Например, сюда попал наш request. id:

Можно добавлять events:
span.AddEvent(ctx, "request validation ok")Кроме того, сюда можно добавлять label. Это работает примерно также, как структурный лог в виде logrus:
span.AddEvent(ctx, "entities loaded", label.Int64("count", 123))Здесь мы видим свое сообщение в логе span. Можно развернуть его и посмотреть labels. В нашем случае сюда добавился label count:

Потом это будет удобно использовать при фильтрации в поиске.
Если возникла ошибка, в span можно дописать статус. В этом случае он будет помечен как ошибочный.
span.SetStatus(codes.Error, "insertion error")Раньше стандарт использовал коды ошибок из OpenCensus, и они были из grpc. Сейчас оставили только OK, ERROR и UNSET. OK ставится по умолчанию, ERROR в случае ошибки добавляете вы.
Здесь видно, что трейс ошибки помечен красным значком. Есть код ошибки и сообщение о ней:

Нужно не забывать о том, что трейсинг – это не замена логов. Основной смысл в том, чтобы отслеживать протекание информации через распределенную систему, а для этого нужно класть трейсы в сетевые запросы и уметь читать их оттуда.
Трейсинг микросервисов
В OpenTelemetry уже есть множество set party реализаций interceptors и middleware для различных фреймворков и библиотек. Их можно найти в репозитории: github.com/open-telemetry/opentelemetry-go-contrib
Список фреймворков, для которых есть interceptors и middleware:
- beego
- go-restful
- gin
- gocql
- mux
- echo
- http
- grpc
- sarama
- memcache
- mongo
- macaron
Как это использовать, посмотрим на примере стандартного http клиента и сервера.
middleware client
В клиенте просто добавляем interceptor в качестве транспорта, после чего наши запросы обогащаются на trace.id и необходимую для продолжения трейса информацию.
client := http.Client{
Transport: otelhttp.NewTransport(http.DefaultTransport),
}
req, _ := http.NewRequestWithContext(ctx, "GET", url, nil)
resp, err := client.Do(req)middleware server
На сервере добавляется небольшой middleware с названием библиотеки:
http.Handle("/", otelhttp.NewHandler(
http.HandlerFunc(get), "root"))
err := http.ListenAndServe(addr, nil)Дальше как обычно: получаете span из контекста, работаете с ним, пишите в него что-то, создаете дочерние spans, закрываете их и т.д.
Так выглядит простой запрос, проходящий через три сервиса:

На скриншоте видна иерархия вызовов, разделение на сервисы, их длительность, последовательность. На каждый из них можно кликнуть и посмотреть более подробную информацию.
А так выглядит ошибка:

Легко отследить, где она произошла, когда и сколько времени прошло.
В span можно посмотреть подробную информацию о контексте, в котором произошла ошибка:

Более того, поля, которые относятся ко всему span (различные id запроса, ключевые поля в таблице в запросе, еще какие-то мета данные, которые вы хотите положить) можно вкладывать в span при его создании. Грубо говоря, не нужно копипастить все эти поля в каждое место, где вы обрабатываете ошибку. Можно записать данные о ней в span.
middleware func
Вот небольшой бонус: как сделать middleware, чтобы можно было использовать его в качестве глобального middleware для таких вещей как Gorilla и Gin:
middleware := func(h http.Handler) http.Handler {
return otelhttp.NewHandler(h, "root")
}Инструментация Golang приложения: мониторинг
Пришло время поговорить о мониторинге.
Подключение к системе мониторинга настраивается аналогично тому, что делается для трейсинга.
Измерения делятся на два типа:
1. Синхронные, когда пользователь явно передает значения в момент вызова:
- Counter
- UpDownCounter
- ValueRecorder
int64, float64
2. Асинхронные, которые SDK считывает в момент коллекта данных из приложения:
- SumObserver
- UpDownSumObserver
- ValueObserver
int64, float64
Сами метрики бывают:
- Аддитивные и монотонные (Counter, SumObserver), которые суммируют положительные числа, и они не уменьшаются.
- Аддитивные, но не монотонные (UpDownCounter, UpDownSumObserver), которые могут суммировать положительные и отрицательные числа.
- Неаддитивные (ValueRecorder, ValueObserver), которые просто записывают последовательность значений. Например, какое-то распределение.
В начале программы создается глобальный измеритель, которому указывается название библиотеки или сервиса.
meter := global.Meter("github.com/ilyakaznacheev/otel-demo")
floatCounter := metric.Must(meter).NewFloat64Counter(
"float_counter",
metric.WithDescription("Cumulative float counter"),
).Bind(label.String("label_a", "some label"))
defer floatCounter.Unbind()Дальше создается метрика:
floatCounter := metric.Must(meter).NewFloat64Counter(
"float_counter",
metric.WithDescription("Cumulative float counter"),
).Bind(label.String("label_a", "some label"))Ей указывается название:
"float_counter",Описание:
…
metric.WithDescription("Cumulative float counter"),
…Набор лейблов, по которым вы потом можете фильтровать запросы. Например, при построении дашбордов в Grafana:
…
).Bind(label.String("label_a", "some label"))
…
В конце программы также нужно вызвать Unbind для каждой метрики, что освободит ресурсы и правильно ее закроет:
…
defer floatCounter.Unbind()
…
Записывать изменения просто:
var (
counter metric.BoundFloat64Counter
udCounter metric.BoundFloat64UpDownCounter
valueRecorder metric.BoundFloat64ValueRecorder
)
...
counter.Add(ctx, 1.5)
udCounter.Add(ctx, -2.5)
valueRecorder.Record(ctx, 3.5)
Это положительные числа для Counter, любые числа для UpDownCounter, которые он будет суммировать, и также любые числа для ValueRecorder. Для всех видов инструментов в Go поддерживаются int64 и float64.
Вот что мы получаем на выходе:
# HELP float_counter Cumulative float counter
# TYPE float_counter counter
float_counter{label_a="some label"} 20Это наша метрика с комментарием и заданным лейблом. Потом можно ее взять либо напрямую через Prometheus, либо экспортировать через OpenTelemetry коллектор, и дальше использовать там, где нам нужно.
Инструментация Golang приложения: библиотеки
Последнее, о чем хочется сказать – это возможность, которую стандарт дает для инструментирования библиотек.
Раньше, когда использовались OpenCensus и OpenTracing, вы не могли инструментировать ваши отдельные библиотеки, особенно опенсорсные. Потому что в этом случае у вас получался vendor lock-in. Тот, кто плотно работал с трейсингом, наверняка обращал внимание на то, что большие клиентские библиотеки, или крупные API к облачным сервисам, время от времени падают с трудно объяснимыми ошибками.
Тут бы очень пригодился трейсинг. Особенно в продуктиве, когда у вас происходит какая-то неясная ситуация, и очень хотелось бы знать, почему она произошла. Но все, что у вас есть – это сообщение об ошибке из вашей импортированной библиотеки.
OpenTelemetry решает эту проблему.

Так как в стандарте SDK и API разделены, API трейсинга метрик можно использовать независимо от SDK и конкретных настроек экспорта данных. Более того, вы можете сначала инструментировать свои методы, а только потом настроить экспорт этих данных вовне.
Таким образом можно инструментировать импортируемую библиотеку, не заботясь о том, как и куда будут экспортированы эти данные. Это подойдет и для внутренних, и для открытых опенсорсных библиотек.
Не нужно заботиться о vendor lock-in, не нужно переживать по поводу того, как будет использована эта информация и будет ли использована вообще. Библиотеки и приложения инструментируются заранее, а конфигурация экспорта данных указывается при инициализации приложения.
Таким образом видно, что настройки конфигурации задаются в SDK приложении. Дальше нужно заняться экспортерами трейсинга и метрик. Это может быть один экспортер через OTLP, если вы экспортируете в OpenTelemetry коллектор. Потом все необходимые трейсы и метрики попадают в контекст, а он пропагируется по дереву вызова другим методом вниз.
Приложение наследует от корневого span остальные spans, просто используя OpenTelemetry API и данные, которые лежат в контексте. При этом импортируемые библиотеки получают на вход методы контекст, пытаются считать из этого метода информацию о корневом span. Если его нет, создают свой, и дальше инструментируют логику. Таким образом, вы можете сначала инструментировать свою библиотеку.
Более того, вы можете инструментировать все, но не настраивать экспортеры данных, и просто задеплоить это.
У вас это может работать в проде, и пока инфраструктура не устоялась, у вас не будет настроен трейсинг и мониторинг. Потом вы настроите их, развернете там коллектор, какие-то приложения для сбора этих данных, и у вас все заработает. Вам не нужно ничего менять непосредственно в самих методах.
Таким образом, если у вас какая-то опенсорсная библиотека, вы можете инструментировать ее при помощи OpenTelemetry. Потом люди, которые ее используют, настроят у себя OpenTelemetry и будут использовать эти данные.
В заключении хочу сказать, что стандарт OpenTelemetry многообещающий. Возможно, наконец это тот самый универсальный стандарт, который мы все хотели увидеть.
У нас в компании активно применяется стандарт OpenCensus для трейсинга и мониторинга микросервисного ландшафта компании. Планируется внедрение OpenTelemetry после его релиза.
