
Совсем недавно вышла версия 10.5.0 платформы Node.js. Одной из её главных возможностей стала впервые добавленная в Node.js поддержка работы с потоками, пока носящая статус экспериментальной. Этот факт особенно интересен в свете того, что данная возможность теперь есть у платформы, адепты которой всегда гордились тем, что потоки ей, благодаря фантастической асинхронной подсистеме ввода-вывода, не нужны. Однако, поддержка потоков в Node.js всё же появилась. С чего бы это? Кому и зачем они могут пригодиться?

Если в двух словах, то нужно это для того, чтобы платформа Node.js могла бы достигнуть новых высот в тех областях, в которых раньше она показывала не самые замечательные результаты. Речь идёт о выполнении вычислений, интенсивно использующих ресурсы процессора. Это, в основном, является причиной того, что Node.js не отличается сильными позициями в таких сферах, как искусственный интеллект, машинное обучение, обработка больших объёмов данных. На то, чтобы позволить Node.js хорошо показать себя в решении подобных задач, направлено немало усилий, но тут эта платформа пока выглядит куда скромнее, чем, например, в деле разработки микросервисов.
Автор материала, перевод которого мы сегодня публикуем, говорит, что решил свести техническую документацию, которую можно найти в исходном пулл-запросе и в официальных источниках, к набору простых практических примеров. Он надеется, что, любой, кто разберёт эти примеры, узнает достаточно для того, чтобы приступить к работе с потоками в Node.js.
Поддержка многопоточности в Node.js реализована в виде модуля
Учтите, что работать с
Обратите внимание на то, что флаг включает в себя слово «worker» (воркер), а не «thread» (поток). Именно так то, о чём мы говорим, упоминается в документации, в которой используются термины «worker thread» (поток воркера) или просто «worker» (воркер). В дальнейшем и мы будем придерживаться такого же подхода.
Если вы уже писали многопоточный код, то, исследуя новые возможности Node.js, вы увидите много такого, с чем уже знакомы. Если же раньше вы ни с чем таким не работали — просто продолжайте читать дальше, так как здесь будут даны соответствующие пояснения, рассчитанные на новичков.
Потоки воркеров предназначены, как уже было сказано, для решения задач, интенсивно использующих возможности процессора. Надо отметить, что применение их для решения задач ввода-вывода — это пустая трата ресурсов, так как, в соответствии с официальной документацией, внутренние механизмы Node.js, направленные на организацию асинхронного ввода-вывода, сами по себе гораздо эффективнее, чем использование для решения той же задачи потоков воркеров. Поэтому сразу решим, что вводом-выводом данных с помощью воркеров мы заниматься не будем.
Начнём с простого примера, демонстрирующего порядок создания и использования воркеров.
Вывод этого кода будет выглядеть как набор строк, демонстрирующих счётчики, значения которых увеличиваются с разной скоростью.

Результаты работы первого примера
Разберёмся с тем, что тут происходит:
Тут показан очень простой пример использования модуля
Рассмотрим пример, в котором, во-первых, будем выполнять некие «тяжёлые» вычисления, а во-вторых, делать нечто асинхронное в главном потоке.
Для того чтобы запустить у себя этот пример, обратите внимание на то, что этому коду нужен модуль
В этот раз мы параллельно решаем две задачи. Во-первых — загружаем домашнюю страницу google.com, во-вторых — сортируем случайно сгенерированный массив из миллиона чисел. Это может занять несколько секунд, что даёт нам прекрасную возможность увидеть новые механизмы Node.js в деле. Кроме того, тут мы измеряем время, которое требуется потоку воркера для сортировки чисел, после чего отправляем результат измерения (вместе с первым элементом отсортированного массива) главному потоку, который выводит результаты в консоль.

Результат работы второго примера
В этом примере самое главное — это демонстрация механизма обмена данными между потоками.
Воркеры могут получать сообщения из главного потока благодаря методу
Теперь рассмотрим ещё один пример, очень похожий на то, что мы уже видели, но на этот раз уделим особое внимание структуре проекта.
В качестве последнего примера предлагаем рассмотреть реализацию того же функционала, что и в предыдущем примере, но на этот раз улучшим структуру кода, сделаем его чище, приведём его к виду, который повышает удобство поддержки программного проекта.
Вот код основной программы.
А вот код, описывающий поведение потока воркера (в вышеприведённой программе путь к файлу с этим кодом формируется с помощью конструкции
Вот особенности этого примера:
В этом материале мы, на практических примерах, рассмотрели особенности использования новых возможностей по работе с потоками в Node.js. Если вы освоили то, о чём здесь шла речь, это значит, что вы готовы к тому, чтобы, посмотрев документацию, приступить к собственным экспериментам с модулем
Уважаемые читатели! Что вы думаете о поддержке многопоточности в Node.js? Планируете ли вы использовать эту возможность в своих проектах?


Если в двух словах, то нужно это для того, чтобы платформа Node.js могла бы достигнуть новых высот в тех областях, в которых раньше она показывала не самые замечательные результаты. Речь идёт о выполнении вычислений, интенсивно использующих ресурсы процессора. Это, в основном, является причиной того, что Node.js не отличается сильными позициями в таких сферах, как искусственный интеллект, машинное обучение, обработка больших объёмов данных. На то, чтобы позволить Node.js хорошо показать себя в решении подобных задач, направлено немало усилий, но тут эта платформа пока выглядит куда скромнее, чем, например, в деле разработки микросервисов.
Автор материала, перевод которого мы сегодня публикуем, говорит, что решил свести техническую документацию, которую можно найти в исходном пулл-запросе и в официальных источниках, к набору простых практических примеров. Он надеется, что, любой, кто разберёт эти примеры, узнает достаточно для того, чтобы приступить к работе с потоками в Node.js.
О модуле worker_threads и флаге --experimental-worker
Поддержка многопоточности в Node.js реализована в виде модуля
worker_threads. Поэтому для того, чтобы воспользоваться новой возможностью, этот модуль надо подключить с помощью команды require.Учтите, что работать с
worker_threads можно только используя флаг --experimental-worker при запуске скрипта, иначе система этот модуль не найдёт.Обратите внимание на то, что флаг включает в себя слово «worker» (воркер), а не «thread» (поток). Именно так то, о чём мы говорим, упоминается в документации, в которой используются термины «worker thread» (поток воркера) или просто «worker» (воркер). В дальнейшем и мы будем придерживаться такого же подхода.
Если вы уже писали многопоточный код, то, исследуя новые возможности Node.js, вы увидите много такого, с чем уже знакомы. Если же раньше вы ни с чем таким не работали — просто продолжайте читать дальше, так как здесь будут даны соответствующие пояснения, рассчитанные на новичков.
О задачах, которые можно решать с помощью воркеров в Node.js
Потоки воркеров предназначены, как уже было сказано, для решения задач, интенсивно использующих возможности процессора. Надо отметить, что применение их для решения задач ввода-вывода — это пустая трата ресурсов, так как, в соответствии с официальной документацией, внутренние механизмы Node.js, направленные на организацию асинхронного ввода-вывода, сами по себе гораздо эффективнее, чем использование для решения той же задачи потоков воркеров. Поэтому сразу решим, что вводом-выводом данных с помощью воркеров мы заниматься не будем.
Начнём с простого примера, демонстрирующего порядок создания и использования воркеров.
Пример №1
const { Worker, isMainThread, workerData } = require('worker_threads');
let currentVal = 0;
let intervals = [100,1000, 500]
function counter(id, i){
console.log("[", id, "]", i)
return i;
}
if(isMainThread) {
console.log("this is the main thread")
for(let i = 0; i < 2; i++) {
let w = new Worker(__filename, {workerData: i});
}
setInterval((a) => currentVal = counter(a,currentVal + 1), intervals[2], "MainThread");
} else {
console.log("this isn't")
setInterval((a) => currentVal = counter(a,currentVal + 1), intervals[workerData], workerData);
}Вывод этого кода будет выглядеть как набор строк, демонстрирующих счётчики, значения которых увеличиваются с разной скоростью.
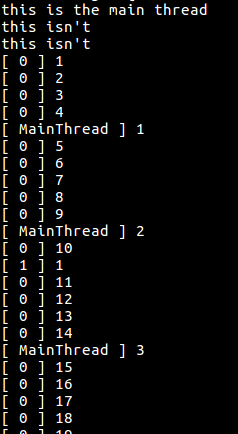
Результаты работы первого примера
Разберёмся с тем, что тут происходит:
- Инструкции внутри выражения
ifсоздают 2 потока, код для которых, благодаря параметру__filename, берётся из того же скрипта, который передавался Node.js при запуске примера. Сейчас воркеры нуждаются в полном пути к файлу с кодом, они не поддерживают относительные пути, именно поэтому здесь и используется данное значение.
- Данные этим двум воркерам отправляют в виде глобального параметра, в форме атрибута
workerData, который используется во втором аргументе. После этого доступ к данному значению можно получить через константу с таким же именем (обратите внимание на то, как создаётся соответствующая константа в первой строке файла, и на то, как, в последней строке, она используется).
Тут показан очень простой пример использования модуля
worker_threads, ничего интересного здесь пока не происходит. Поэтому рассмотрим ещё один пример.Пример №2
Рассмотрим пример, в котором, во-первых, будем выполнять некие «тяжёлые» вычисления, а во-вторых, делать нечто асинхронное в главном потоке.
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
const request = require("request");
if(isMainThread) {
console.log("This is the main thread")
let w = new Worker(__filename, {workerData: null});
w.on('message', (msg) => { //Сообщение от воркера!
console.log("First value is: ", msg.val);
console.log("Took: ", (msg.timeDiff / 1000), " seconds");
})
w.on('error', console.error);
w.on('exit', (code) => {
if(code != 0)
console.error(new Error(`Worker stopped with exit code ${code}`))
});
request.get('http://www.google.com', (err, resp) => {
if(err) {
return console.error(err);
}
console.log("Total bytes received: ", resp.body.length);
})
} else { //код воркера
function random(min, max) {
return Math.random() * (max - min) + min
}
const sorter = require("./list-sorter");
const start = Date.now()
let bigList = Array(1000000).fill().map( (_) => random(1,10000))
sorter.sort(bigList);
parentPort.postMessage({ val: sorter.firstValue, timeDiff: Date.now() - start});
}Для того чтобы запустить у себя этот пример, обратите внимание на то, что этому коду нужен модуль
request (его можно установить с помощью npm, например, воспользовавшись, в пустой директории с файлом, содержащим вышеприведённый код, командами npm init --yes и npm install request --save), и на то, что он использует вспомогательный модуль, подключаемый командой const sorter = require("./list-sorter");. Файл этого модуля (list-sorter.js) должен находиться там же, где и вышеописанный файл, его код выглядит так:module.exports = {
firstValue: null,
sort: function(list) {
let sorted = list.sort();
this.firstValue = sorted[0]
}
}В этот раз мы параллельно решаем две задачи. Во-первых — загружаем домашнюю страницу google.com, во-вторых — сортируем случайно сгенерированный массив из миллиона чисел. Это может занять несколько секунд, что даёт нам прекрасную возможность увидеть новые механизмы Node.js в деле. Кроме того, тут мы измеряем время, которое требуется потоку воркера для сортировки чисел, после чего отправляем результат измерения (вместе с первым элементом отсортированного массива) главному потоку, который выводит результаты в консоль.
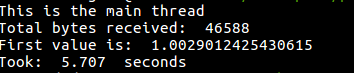
Результат работы второго примера
В этом примере самое главное — это демонстрация механизма обмена данными между потоками.
Воркеры могут получать сообщения из главного потока благодаря методу
on. В коде можно найти события, которые мы прослушиваем. Событие message вызывается каждый раз, когда мы отправляем сообщение из некоего потока с использованием метода parentPort.postMessage. Кроме того, тот же метод можно использовать для отправки сообщения потоку, обращаясь к экземпляру воркера, и получать их, используя объект parentPort.Теперь рассмотрим ещё один пример, очень похожий на то, что мы уже видели, но на этот раз уделим особое внимание структуре проекта.
Пример №3
В качестве последнего примера предлагаем рассмотреть реализацию того же функционала, что и в предыдущем примере, но на этот раз улучшим структуру кода, сделаем его чище, приведём его к виду, который повышает удобство поддержки программного проекта.
Вот код основной программы.
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
const request = require("request");
function startWorker(path, cb) {
let w = new Worker(path, {workerData: null});
w.on('message', (msg) => {
cb(null, msg)
})
w.on('error', cb);
w.on('exit', (code) => {
if(code != 0)
console.error(new Error(`Worker stopped with exit code ${code}`))
});
return w;
}
console.log("this is the main thread")
let myWorker = startWorker(__dirname + '/workerCode.js', (err, result) => {
if(err) return console.error(err);
console.log("[[Heavy computation function finished]]")
console.log("First value is: ", result.val);
console.log("Took: ", (result.timeDiff / 1000), " seconds");
})
const start = Date.now();
request.get('http://www.google.com', (err, resp) => {
if(err) {
return console.error(err);
}
console.log("Total bytes received: ", resp.body.length);
//myWorker.postMessage({finished: true, timeDiff: Date.now() - start}) //так можно отправлять сообщения воркеру
})А вот код, описывающий поведение потока воркера (в вышеприведённой программе путь к файлу с этим кодом формируется с помощью конструкции
__dirname + '/workerCode.js'):const { parentPort } = require('worker_threads');
function random(min, max) {
return Math.random() * (max - min) + min
}
const sorter = require("./list-sorter");
const start = Date.now()
let bigList = Array(1000000).fill().map( (_) => random(1,10000))
/**
//вот как получить сообщение из главного потока:
parentPort.on('message', (msg) => {
console.log("Main thread finished on: ", (msg.timeDiff / 1000), " seconds...");
})
*/
sorter.sort(bigList);
parentPort.postMessage({ val: sorter.firstValue, timeDiff: Date.now() - start});Вот особенности этого примера:
- Теперь код для главного потока и для потока воркера размещён в разных файлах. Это облегчает поддержку и расширение проекта.
- Функция
startWorkerвозвращает новый экземпляр воркера, что позволяет, при необходимости, отправлять этому воркеру сообщения из главного потока. - Здесь не нужно проверять, выполняется ли код в главном потоке (мы убрали выражение
ifс соответствующей проверкой). - В воркере показан закомментированный фрагмент кода, демонстрирующий механизм получения сообщений от главного потока, что, учитывая уже рассмотренный механизм отправки сообщений, позволяет организовать двусторонний асинхронный обмен данными между главным потоком и потоком воркера.
Итоги
В этом материале мы, на практических примерах, рассмотрели особенности использования новых возможностей по работе с потоками в Node.js. Если вы освоили то, о чём здесь шла речь, это значит, что вы готовы к тому, чтобы, посмотрев документацию, приступить к собственным экспериментам с модулем
worker_threads. Пожалуй, стоит ещё отметить, что эта возможность только появилась в Node.js, пока она является экспериментальной, поэтому со временем что-то в её реализации может измениться. Кроме того, если в ходе собственных экспериментов с worker_threads вы столкнётесь с ошибками, или обнаружите, что этому модулю не помешает какая-то отсутствующая в нём возможность — дайте знать об этом разработчикам и помогите улучшить платформу Node.js.Уважаемые читатели! Что вы думаете о поддержке многопоточности в Node.js? Планируете ли вы использовать эту возможность в своих проектах?

