

Все, кто хоть раз в жизни, по работе открывал файл
/etc/services знают, что одни сетевые службы используют транспортный протокол TCP, другие же — UDP. Каждый из них имеет свою область применения. Если надёжность соединения имеет приоритет над скоростью передачи данных, то TCP предпочтительнее. Например, для SMTP, или IMAP больше подходит TCP. Обратное тоже верно там, где важна скорость передачи данных, а потеря дейтаграмм или их порядок не критичны — используют UDP. К их числу относятся SNMP, DNS, VoIP и другие службы.Особенности двух транспортных протоколов:
В целом компромисс между скоростью передачи данных и их надёжностью известен разработчикам приложений и администраторам сети. Важна скорость, используй UDP, необходима надёжность — выбирай TCP. Но может ли быть такое, что протокол TCP обеспечивает также и более высокую производительность по сравнению с UDP? Оказывается, не всё так однозначно.
На первый взгляд, нет никаких оснований полагать, что один и тот же протокол по TCP будет работать быстрее, чем по UDP. В таком случае весь SNMP мониторинг использовал бы более надежный и производительный транспорт вместо UDP. Да и как это можно реализовать, ведь TCP использует многоступенчатую схему установки и обрыва соединений.
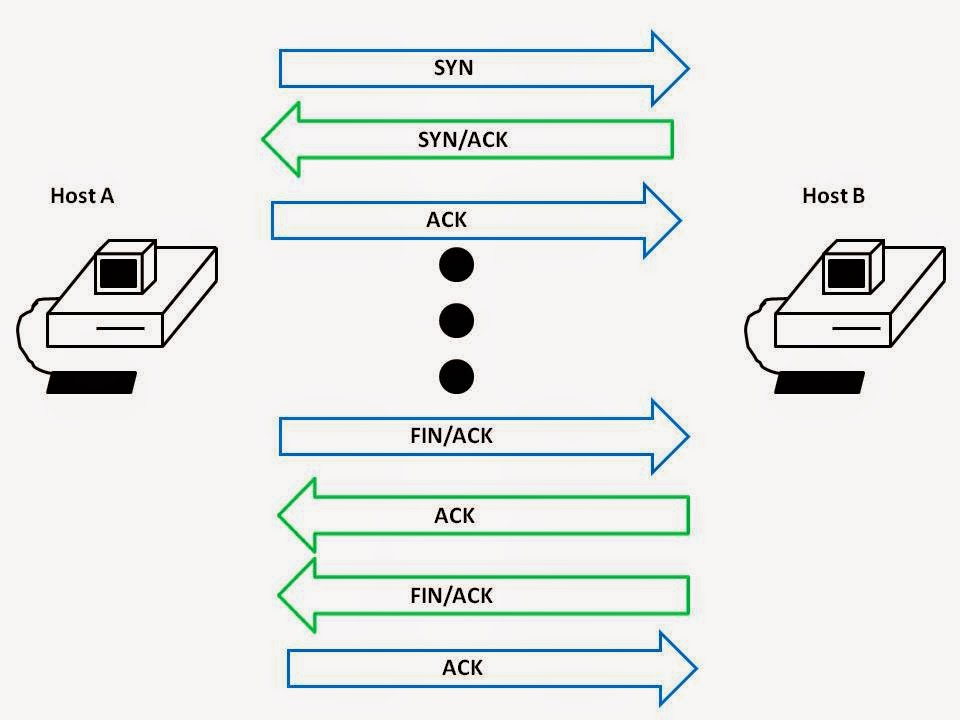
Помимо этого имеется нетривиальный механизм обеспечения надёжной доставки пакетов в исходной последовательности. Так, на каждый пакет принимающая сторона должна прислать подтверждение, выставив контрольный бит
ACK. Утерянный сегмент будет отправлен вновь адресату, пока тот не вернёт ACK. Затем TCP восстановит все фрагменты и передаст приложению сегменты в оригинальном порядке.Но и это не всё, есть еще такая штука, как управление потоком. TCP не сразу отправляет данные по сети на доступной скорости, а постепенно наращивает её до верхней границы возможностей принимающей стороны. Если адресат видит, что буфер входящей очереди близок переполнению, то присылает уведомление, что размер окна необходимо сократить. В результате получается такая диаграмма, похожая на пилу.
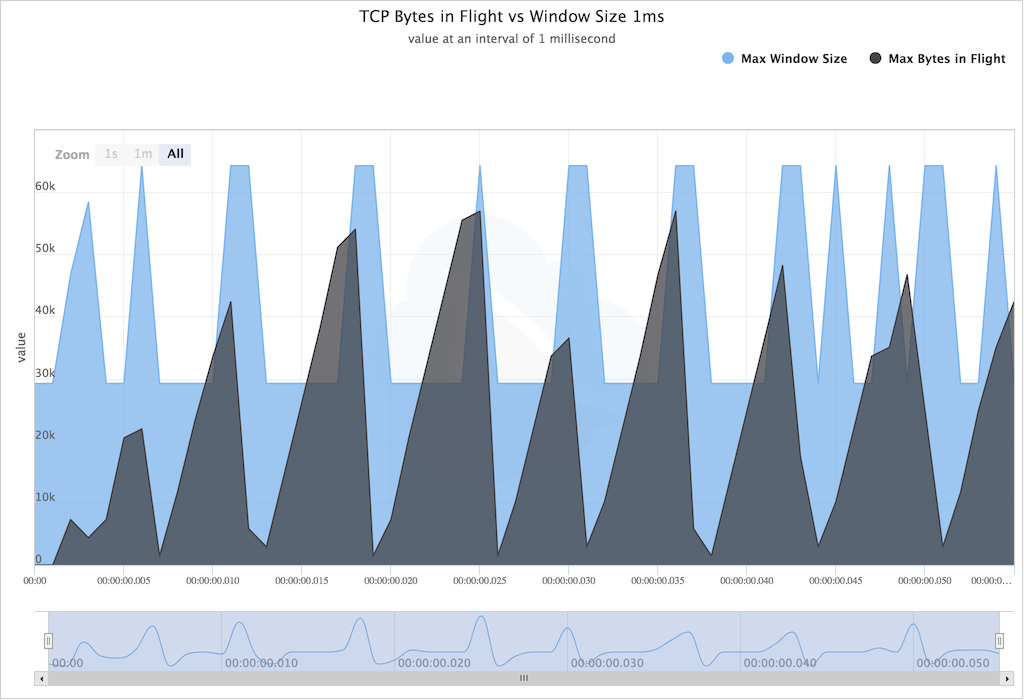
Всех этих тонкостей нет в UDP, берем и отправляем пакеты фиксированной длины на требуемый адрес и порт. Остальное — забота приложения. Так что при прочих равных условиях, UDP должен быть быстрее и это хорошо известно. Однако бывают исключения.
Особенности контейнерной маршрутизации
Типичная конфигурация контейнерной сети довольно сложна. Когда контейнер отправляет пакет, тот пересекает сетевой стек ядра контейнера, достигает устройства виртуального Ethernet (veth) и пересылается на одноранговое устройство veth для достижения виртуальной сети узла. Естественно, что на обратном пути происходит всё то же самое, но в противоположном порядке.
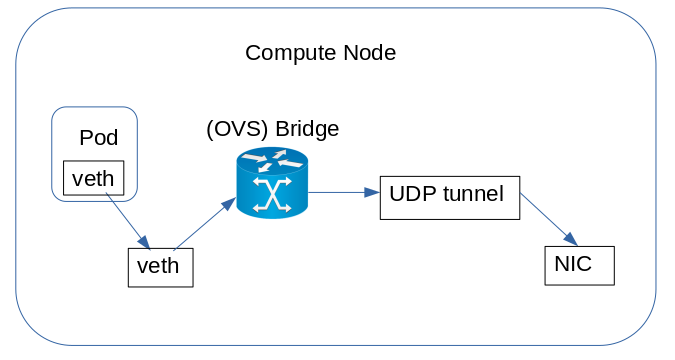
В контейнерной сети пакет проходит сквозь состояния контекста одного аппаратного прерывания, трёх программных прерываний и процесса пользовательского пространства. При увеличении числа потоков аппаратное обеспечение также становится неэффективным из-за низкой эффективности кэширования и высокой пропускной способности памяти. При одинаковой нагрузке, скажем 40 GiB/s при 80 потоках наложенные сети потребляют в 2-3 раза больше ресурсов CPU.
Легко догадаться, что процессорное время, необходимое для выполнения всех этапов пересылки и инкапсуляции, намного превышает время обработки транспортного протокола, для каждого из них — будь то UDP, TCP или MPTCP. Согласование контейнеров также добавляет значительные накладные расходы из-за сложного набора правил пересылки, необходимого для одновременной работы с несколькими контейнерами.

И вот тут как раз видны преимущества TCP и MPTCP. При передаче данных исходящий поток собирается в пакеты, превышающие текущий максимальный размер сегмента TCP, a․ k․ a․ MSS. Такие крупные пакеты без изменений проходят через всю виртуальную сеть, пока не попадут на физическую сетевую карту. В самом общем случае сетевая карта разбивает эти пакеты на сегменты размером MSS с помощью механизма Transmit Segmentation Offload (TSO).
На обратном пути пакеты, полученные сетевой картой, укрупняются перед входом в сетевой стек. Этот механизм называется Generic Receive Offload (GRO). Обычно эту операцию выполняет ЦПУ, однако на некоторых сетевых картах имеется возможность аппаратной реализации GRO. В обоих случаях многочисленные переходы по лабиринтам контейнерной сети амортизируются укрупнением и агрегированием сетевых пакетов, однако эта функциональность недоступна на UDP.
▍ Замер производительности в Docker сети
Для тестовой среды были выбраны два сервера с такой конфигурацией железа и программного обеспечения:
- Процессор Xeon E5-2630 v4 CPU (2.2 GHz c 10 физическими ядрами и гипер-тредингом — 20 виртуальных ядер)
- 64 GB ОЗУ.
- Сетевая карта 40 Gb Mellanox ConnectX-3 Infiniband с технологией множественной очереди (16 очередей пакетов).
- Ubuntu Linux 16.04 LTS, ядро 4.4.
- Docker-18.06.
- Нагрузочное тестирование — Iperf3.
- Размера пакета TCP по умолчанию — 128 Kb.
- Размера пакета UDP по умолчанию — 8 Kb.
Цель состояла в оценке степени падения производительности передачи данных в контейнерной сети по сравнению с обычной физической. Сравнение проводилось для трёх типов сетей и двух протоколов транспортного уровня. Тип сети Linux Overlay отличается наличием программного интерфейса VxLAN, прикреплённом к штатному интерфейсу узла.

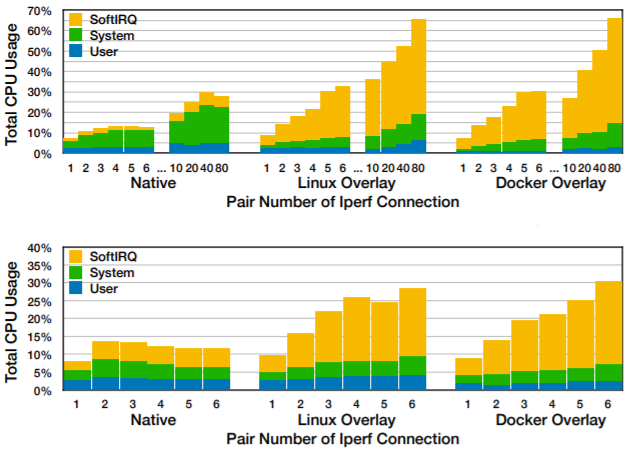
Сначала замер производился для обмена данных по одному потоку. В сети Docker производительность TCP составляет 6.4 GiB/s, а UDP — всего лишь 3.9 GiB/s. Впрочем и в стандартной сети TCP по производительности бьёт UDP — 23 GiB/s против 9.3 GiB/s соответственно. При таком раскладе вся нагрузка падает на одно ядро CPU, а остальные бездействуют. Для контейнерной сети это довольно быстро приводит к насыщению ресурсов CPU и после этого пропускная способность уже не растет.
При увеличении количества соединений iperf TCP довольно быстро насыщает пропускную способность сети полностью в стандартной сети. В конечном счёте контейнерная сеть тоже достигает уровня 80 GiB/s, но уже при количестве 80 потоков и многократно большем использовании ресурсов CPU. Уже сказано о том, что причиной такой повышенной нагрузки на CPU в Docker сетях являются постоянные переключения между разными состояниями контекста и многочисленные IRQ, softirq в пользовательском пространстве. Но это не объясняет почему так сильно отстаёт именно UDP.
Более подробное изучение данной специфики показало, что в стандартной сети все потоки UDP совместно используют одну и ту же информацию на уровне потока (т․ е․ одни и те же IP-адреса источника и назначения). Как следствие, Receive Side Scaling (RSS) и Receive Packet Steering (RPS) не могут их различать и отправляют всё на одно ядро, которое затем перенасыщается. Такого не случается в наложенных сетях, потоки имеют различные IP адреса и механизмы RSS и RPS равномерно распределяют их по разным ядрам.
Generic Receive Offload для UDP, возможно ли это?
Обмен данных по протоколу TCP происходит в режиме потоков и благодаря этому данные можно разделить на необходимое количество сегментов. Главное, чтобы в конце все части собрать в исходной последовательности и без потерь. В противоположность этому UDP-соединения представляют из себя последовательности пакетов фиксированной длины, которую определяет приложение. Агрегирование и разделение UDP пакетов приведёт к тому, что приложение не сможет их распознать, так как оно полагается на длину пакета для того, чтобы извлечь сообщение прикладного уровня.
В связи с этим понятно, что функциональность GRO/TSO для TCP присутствует в ядре Linux, в течение продолжительного времени, в то время как поддержка TSO для UDP появилась лишь в версии 4.18, благодаря новому транспортному протоколу QUIC. Приложение должно включить сегментацию UDP на каждом сокете, затем передать ядру агрегированные пакеты вместе с их длиной. Так как включение этой опции зависит от приложения, стороны знают о том, что длина сообщения отлична от длины передаваемого UDP пакета.
TSO повышает производительность при отправке UDP пакетов по контейнерной сети, однако никак не влияет на их приём. Тем временем с версии Linux 5.10 появилась поддержка GRO для транспортного протокола UDP. Опция
UDP_GRO также включается отдельно для каждого сокета и после этого начинает агрегировать входящие пакеты так же, как для TCP. Однако так же, как и в случае TSO, приложение должно быть в состоянии воспользоваться этой функциональностью.В последующих версиях кернела появились дополнительные возможности для UDP. В Linux 5.12 поддержка UDP GRO стала возможной не для отдельного сокета, а для всей системы. В следующей стабильной версии стало возможно применять GRO в туннелях UDP-UDP, а также в устройствах veth. До этого приходилось прикручивать программу eBPF с движком eXpress Data Path (XDP) к veth устройствам.
▍ Пример настройки UDP GRO
Для того чтобы настроить UDP GRO в типовой контейнерной сети необходимо выполнить следующие шаги.
- В основном пространстве имён сети включить GRO на veth узле:
VETH=<veth device name> CPUS=`/usr/bin/nproc` ethtool -K $VETH gro on ethtool -L $VETH rx $CPUS tx $CPUS echo 50000 > /sys/class/net/$VETH/gro_flush_timeout - Включить на том же устройстве перенаправление GRO:
ethtool -K $VETH rx-udp-gro-forwarding on - Включить перенаправление GRO на активном сетевом интерфейсе:
DEV=<real NIC name> ethtool -K $DEV rx-udp-gro-forwarding on
Выводы
Низкая производительность транспортного протокола UDP в наложенных, контейнерных сетях уже длительное время занимает умы разработчиков ядра Linux. От версии к версии предлагаются новые решения, позволяющие повысить пропускную способность сетевых соединений в контейнерах. Пионером этих нововведений в настоящее время является компания RedHat. Однако как это обычно происходит в Linux, остальные дистрибутивы довольно скоро подхватывают все изменения, происходящие в стабильной ветке ядра.
▍ Дополнительные материалы:
- Richard Stevens, TCP/IP Illustrated, Volume 1
- Tackling Parallelization Challenges of Kernel Network Stack for Container Overlay Networks
- Improve UDP performance in RHEL 8.5

