

В этой статье объясняется, как делать копии списков Python, массивов NumPy и датафреймов Pandas при помощи операций получения срезов, списочного индексирования (fancy indexing) и логического (boolean indexing). Эти операции очень часто используются при анализе данных и должны рассматриваться всерьёз, поскольку ошибочные предположения могут привести к падению быстродействия или неожиданным результатам.
Python кажется простым, но всякий раз, возвращаясь к его азам, ты находишь новые для освоения вещи. Здесь на ум приходит известное изречение Эйнштейна:
«Чем больше я узнаю, тем больше понимаю, как много я ещё не знаю».
Вступление
Я часто задаюсь вопросом, действительно ли я знаю тот или иной предмет в совершенстве. Получив кандидатскую степень и проработав часть жизни исследователем, я могу с уверенностью сказать, что утвердительного ответа на этот вопрос не бывает. Я уже давно работаю с Python и осознаю ценность этого инструмента для анализа данных. С его помощью я создавал множество эффективных решений для реальных задач. И всё же каждый раз, возвращаясь к основам этого языка, я нахожу в нём нечто новое для освоения или вижу иной ракурс для восприятия уже привычных вещей.
Это осознание зачастую возникает во время чтения вводной части книги, которая намеренно содержит простой материал, подготавливая читателя к основной сути. Приведённая фраза Эйнштейна звучит у меня в сознании, когда в очередной раз после использования интерпретатора Python, я задумываюсь, почему столь простые вещи открываются для меня только сейчас?
И текущая статья появилась вслед за одним из таких случаев. В ней я хочу объяснить, как списки Python, массивы NumPy и датафреймы Pandas создают представления или полноценные копии данных при получении срезов, а также множественном и логическом индексировании. В этой теме возникает некоторая путаница, поскольку термины «поверхностная копия» и «глубокая копия» не всегда означают одно и то же, а также неясно, когда дополнительная информация вроде метаданных массива NumPy и индексов Pandas копируется полноценно, а когда поверхностно.
Эта статья может не дать всех исчерпывающих ответов, но она обеспечит основу, которая позволит в случае сомнений дополнить инструкции из документации собственными вычислительными экспериментами.
Все примеры кода были подготовлены с использованием Python v3.8.10, Pandas v1.5.1 и NumPy v1.23.4.
Списки Python
В этом разделе мы проведём ряд экспериментов, чтобы понять принцип создания копий списков Python. Если вы будете проделывать аналогичные действия, то помните, что Python кэширует небольшие целые числа и строки, чтобы иметь возможность обращаться к уже имеющимся объектам, а не создавать каждый раз новые. Это так называемое интернирование является одной из оптимизаций CPython, которая при написании статьи использовалась в стандартном Python. Для избежания путаницы при поиске адресов объектов рекомендуется использовать разные строки и целые числа.
Некоторые читатели могут подумать, что списки в Python являются простой темой. Как бы не так. Давайте создадим такой список, который будет содержать целое число, другой список и вложенный список. Вдобавок к этому мы создадим вспомогательную функцию для вывода адресов различных элементов списка, которая, в целях сокращения, будет показывать только четыре последние цифры адреса.
def show_address(title, a, offset=0):
trim_ad = lambda ad: str(id(ad))[-4:]
print(f"{title.ljust(20, ' ')}: {trim_ad(a)} | {trim_ad(a[offset+0])} | "
f"{trim_ad(a[offset+1])} {trim_ad(a[offset+1][0])} | "
f"{trim_ad(a[offset+2])} {trim_ad(a[offset+2][0])} {trim_ad(a[offset+2][0][0])}")
# original list
a = ['1', ['2','3'], [['4','5'],['6','7']]]
show_address('a', a)Вывод:
a : 4160 | 7728 | 9888 3376 | 3232 0848 2480Очевидно, что при каждом выполнении адреса будут отличаться. В связи с этим мы сделаем так, чтобы массив
a далее не изменялся. Ниже мы попробуем реплицировать этот массив разными способами, а именно с помощью простого присваивания другой переменной и глубокого копирования:from copy import copy, deepcopy
attempts = {'new binding': a,
'shallow copy I': a[:],
'shallow copy II': list(a),
'shallow copy III': a.copy(),
'shallow copy IV': copy(a),
'deep copy': deepcopy(a)
}
for title, b in attempts.items():
show_address(title, b)Вывод:
new binding : 4160 | 7728 | 9888 3376 | 3232 0848 2480
shallow copy I : 7072 | 7728 | 9888 3376 | 3232 0848 2480
shallow copy II : 9312 | 7728 | 9888 3376 | 3232 0848 2480
shallow copy III : 1488 | 7728 | 9888 3376 | 3232 0848 2480
shallow copy IV : 8128 | 7728 | 9888 3376 | 3232 0848 2480
deep copy : 0528 | 7728 | 6848 3376 | 0816 2960 2480Первым делом нужно обратить внимание, что адрес списка (первый численный столбец) изменяется при каждой попытке, за исключением первой операции изменения привязки. Это говорит о том, что в ходе неё была сделана копия. Данный код реализует четыре разных способа создания поверхностной копии, подразумевающей изменение списка, при котором его элементы остаются прежними объектами. Если попробовать изменить немутабельный элемент такой неполной копии списка, исходный список останется нетронутым. При изменении же мутабельного элемента оригинальный список также меняется. Например:
a_demo = ['d1', ['d2', 'd3']]
print('a_demo (before) ->', a_demo)
a_demo_shallow_copy = a_demo[:]
a_demo_shallow_copy[0] = 'D1'
a_demo_shallow_copy[1][0] = 'D2'
print('a_demo (after) ->', a_demo)
print('a_demo_shallow_copy ->', a_demo_shallow_copy)Вывод:
a_demo (before) -> ['d1', ['d2', 'd3']]
a_demo (after) -> ['d1', ['D2', 'd3']]
a_demo_shallow_copy -> ['D1', ['D2', 'd3']]Это означает, что поверхностные копии могут привести к появлению побочных эффектов при наличии вложенных списков, а также при использовании других мутабельных элементов. В случае же глубокого копирования риск побочных проявлений отсутствует, что демонстрируется следующим кодом:
a_demo = ['d1', ['d2', 'd3']]
print('a_demo (before) ->', a_demo)
a_demo_deep_copy = deepcopy(a_demo)
a_demo_deep_copy[0] = 'D1'
a_demo_deep_copy[1][0] = 'D2'
print('a_demo (after) ->', a_demo)
print('a_demo_deep_copy ->', a_demo_deep_copy)Вывод:
a_demo (before) -> ['d1', ['d2', 'd3']]
a_demo (after) -> ['d1', ['d2', 'd3']]
a_demo_deep_copy -> ['D1', ['D2', 'd3']]Показанный пример несложно обобщить. Любой способ получения среза списка в Python, например,
a[:], a[1:4], a[:5] или a[::-1], приводит к созданию поверхностной копии извлекаемой части списка. А что происходит при конкатенировании или умножении списков? Сможете спрогнозировать исход операций ниже?b = a + a
show_address('a', a)
show_address('b (first part)', b, 0)
show_address('b (second part)', b, 3)
b = a*3
show_address('\na', a)
show_address('b (first part)', b, 0)
show_address('b (second part)', b, 3)
show_address('b (third part)', b, 6)Вывод:
a : 4160 | 7728 | 9888 3376 | 3232 0848 2480
b (first part) : 5712 | 7728 | 9888 3376 | 3232 0848 2480
b (second part) : 5712 | 7728 | 9888 3376 | 3232 0848 2480
a : 4160 | 7728 | 9888 3376 | 3232 0848 2480
b (first part) : 5648 | 7728 | 9888 3376 | 3232 0848 2480
b (second part) : 5648 | 7728 | 9888 3376 | 3232 0848 2480
b (third part) : 5648 | 7728 | 9888 3376 | 3232 0848 2480Здесь видно, что мы создаём дополнительные ссылки (привязки) элементов списка, то есть это подобно поверхностному копированию. Такой подход может вести к неожиданным побочным эффектам. Вот пример:
a_demo = ['d1', ['d2', 'd3']]
print('a_demo (before) ->', a_demo)
b = a_demo + a_demo
b[0] = 'D1'
b[1][0] = 'D2'
print('b ->', b)
print('a_demo (after) ->', a_demo)Вывод:
a_demo (before) -> ['d1', ['d2', 'd3']]
b -> ['D1', ['D2', 'd3'], 'd1', ['D2', 'd3']]
a_demo (after) -> ['d1', ['D2', 'd3']]Ещё раз призываю вас самостоятельно поэкспериментировать с подобными примерами. Простота синтаксиса и его лаконичность делают Python отличным языком для экспериментов.
Массивы NumPy
По аналогии со списками Python массивы NumPy также можно копировать или раскрывать через их представление. Чтобы продемонстрировать эту функциональность, мы создадим массив из случайных целых чисел в диапазоне от 0 до 9 включительно.
import numpy as np
import sys
def show_details(a_np):
print('array is\n', a_np)
print(f'\ndatatype is {a_np.dtype}')
print(f'number of bytes is {a_np.nbytes} bytes ({a_np.size} x 8 bytes)')
print(f'size is {sys.getsizeof(a_np)} bytes')
print(f'owndata is {a_np.flags.owndata}')
print(f'base is {a_np.base}')
a_np = np.random.randint(0, 10, (5,5), dtype='int64')
show_details(a_np)При этом мы попутно определили вспомогательную функцию для отображения элементов массива, общего количества занятых ими байтов, общего размера массива в памяти, а также логического значения, которое указывает, владеет ли массив используемой памятью, или же он её одалживает у базового объекта, который в этом случае тоже выводится.
Вывод кода выше:
[[8 2 8 8 1]
[7 4 2 8 8]
[3 3 2 3 3]
[0 0 7 6 8]
[2 7 3 4 6]]
datatype is int64
number of bytes is 200 bytes (25 x 8 bytes)
size is 328 bytes
owndata is True
base is NoneТип данных этого массива явно установлен как
int64, значит, каждый его элемент потребляет 8 байт. Все 25 элементов массива занимают 200 байт, но общий его размер в памяти составляет 328 байт ввиду присутствия метаданных, отражающих тип данных, размер шагов (stride) и прочую важную информацию, помогающую с этим массивом работать. Мы видим, что наш массив содержит собственные данные (owndata is True), в связи с чем его base установлена как None.Посмотрим, что произойдёт при создании представления:
a_np_view = a_np.view()
show_details(a_np_view)Вывод:
[[8 2 8 8 1]
[7 4 2 8 8]
[3 3 2 3 3]
[0 0 7 6 8]
[2 7 3 4 6]]
datatype is int64
number of bytes is 200 bytes (25 x 8 bytes)
size is 128 bytes
owndata is False
base is [[8 2 8 8 1]
[7 4 2 8 8]
[3 3 2 3 3]
[0 0 7 6 8]
[2 7 3 4 6]]Содержимое массива осталось неизменным. Не изменился и тип данных, а также количество байт, занимаемых его элементами. Остальные же атрибуты теперь иные. Размер массива сократился до 128 байт (то есть 328 – 200), поскольку его представление потребляет память для хранения атрибутов. Элементы массива не копировались, на них были созданы ссылки. Об этом говорит изменившееся значение атрибута
base. На языке NumPy представление содержит тот же буфер данных (фактические данные), но при этом имеет собственные метаданные. Изменение элемента представления приведёт к изменению исходного массива.Посмотрим, что произойдёт при создании копии:
a_np_copy = a_np.copy()
show_details(a_np_copy)Вывод:
[[8 2 8 8 1]
[7 4 2 8 8]
[3 3 2 3 3]
[0 0 7 6 8]
[2 7 3 4 6]]
datatype is int64
number of bytes is 200 bytes (25 x 8 bytes)
size is 328 bytes
owndata is True
base is NoneВывод выглядит идентично выводу исходного массива. Изменение элемента копии не ведёт к изменению оригинала.
Можно поэкспериментировать с изменением формы, получением срезов и индексированием, чтобы понять, когда создаётся копия, а когда представление.
attempts = {'reshape': a_np.reshape(1, 25),
'transpose/reshape': a_np.T.reshape(1, 25),
'ravel': a_np.ravel(),
'transpose/ravel': a_np.T.ravel(),
'transpose/ravel (F-order)': a_np.T.ravel(order='F'),
'flatten': a_np.flatten(),
'transpose/flatten': a_np.T.flatten(),
'slicing': a_np[1:2:5],
'advanced indexing': a_np[[1, 3, 4]],
'combined indexing and slicing': a_np[[0, 2, 4], 1:3],
'Boolean indexing': a_np[[True, False, True, False, False]]
}
for title, b in attempts.items():
if b.base is None:
print(f'{title} produces a copy')
else:
print(f'{title} produces a view')Вывод:
reshape produces a view
transpose/reshape produces a view
ravel produces a view
transpose/ravel produces a copy
transpose/ravel (F-order) produces a view
flatten produces a copy
transpose/flatten produces a copy
slicing produces a view
advanced indexing produces a copy
combined indexing and slicing produces a copy
Boolean indexing produces a copyПоведение некоторых функций не всегда одинаково. К примеру,
numpy.ravel возвращает непрерывный уплощённый массив в качестве копии только при необходимости. И напротив, numpy.ndarray.flatten всегда возвращает копию массива, свёрнутую до одного измерения. Поведение numpy.reshape несколько запутанней, так что лучше почитать о ней в официальной документации.Основной смысл здесь в том, что NumPy создаёт представления, в которых элементы адресуются по смещениям и шагам в исходном массиве, например, при базовом индексировании и получении среза. Такое поведение отличается от поведения списков Python. С другой стороны, при продвинутом индексировании всегда создаются копии. Операции изменения формы более сложны, и возвращение копии либо представления определяется контекстом.
Копии, созданные в результате продвинутого индексирования, как и копии, полученные через
numpy.copy, не подразумевают глубокого копирования мутабельных элементов внутри массивов. Как и поверхностные копии списков Python, копия массива NumPy содержит тот же самый объект, что может привести к неожиданностям, если этот объект допускает изменение (то есть мутабелен):
print('Numpy shallow copy')
a_np_demo = np.array([1, 2, [3, 4]], dtype=object)
print('a_np_demo (before) -> ', a_np_demo)
b = np.copy(a_np_demo)
b[0] = -1
b[2][0] = -3
print('b -> ', b)
print('a_np_demo (after) -> ', a_np_demo)
from copy import deepcopy
print('\nPython deep copy')
a_np_demo = np.array([1, 2, [3, 4]], dtype=object)
print('a_np_demo (before) -> ', a_np_demo)
b2 = deepcopy(a_np_demo)
b2[0] = -1
b2[2][0] = -3
print('b2 -> ', b2)
print('a_np_demo (after) -> ', a_np_demo)Вывод:
Numpy shallow copy
a_np_demo (before) -> [1 2 list([3, 4])]
b -> [-1 2 list([-3, 4])]
a_np_demo (after) -> [1 2 list([-3, 4])]
Python deep copy
a_np_demo (before) -> [1 2 list([3, 4])]
b2 -> [-1 2 list([-3, 4])]
a_np_demo (after) -> [1 2 list([3, 4])]Хотя это больше теоретический аспект, поскольку массивы NumPy обычно для хранения мутабельных объектов не используются. Но всё же будет нелишним знать, что
copy.deepcopy() здесь тоже работает.Датафреймы pandas
По уже налаженной схеме мы определим датафрейм и вспомогательную функцию для вывода его описания.
import pandas as pd
import numpy as np
import sys
def show_details(a_df):
print('dataframe is\n', a_df)
print(f'\ndatatypes are {a_df.dtypes.unique()}')
print(f'number of bytes is {a_df.to_numpy().nbytes} bytes ({a_df.size} x 8 bytes)')
print(f'size is {sys.getsizeof(a_df)} bytes')
print(f"pointer to data area {a_df.to_numpy().__array_interface__['data'][0]}")
a_df = pd.DataFrame(np.random.randint(0, 10, (5,5), dtype='int64'),
index = [f'r{i}' for i in range(5)],
columns = [f'c{i}' for i in range(5)])
show_details(a_df)Структура этих данных совпадает со структурой массива NumPy, то есть в датафрейме присутствует 5х5 элементов
int64, но вдобавок к ним мы определили индексы и имена столбцов. Вспомогательная функция была изменена. Датафреймы Pandas могут содержать в разных столбцах разные типы данных, поэтому мы возвращаем уникальные при помощи a_df.dtypes.unique(). Чтобы увидеть, когда содержащиеся данные копируются, а когда на них лишь даётся ссылка, мы сначала через a_df.to_numpy() получим внутренний массив NumPy, а затем используем интерфейс массива для получения указателя на первый элемент его данных.Вывод:
ddataframe is
c0 c1 c2 c3 c4
r0 5 2 8 6 6
r1 1 9 1 1 1
r2 0 7 6 3 7
r3 7 4 9 5 2
r4 5 8 3 7 1
datatypes are [dtype('int64')]
number of bytes is 200 bytes (25 x 8 bytes)
size is 511 bytes
pointer to data area 2893487649296Теперь у нас есть всё необходимое для экспериментов с копиями и представлениями.
Глядя на интерфейс API, можно найти функцию копирования датафрейма, получающую логический аргумент
deep. Если он True (по умолчанию), создаётся новый объект с копией данных вызывающего объекта и индексами (это не глубокая копия в смысле copy.deepcopy() стандартной библиотеки; см. ниже). Эти данные и индексы можно изменить, не затронув исходный датафрейм. Если же deep = False, новый объект создаётся без копирования данных или индексов вызывающего объекта, то есть генерируются только ссылки на них. В таком случае любые изменения в данных оригинального датафрейма будут отражаться в его копии.Поэкспериментируем с представлением:
a_df_copy = a_df.copy(deep=False)
show_details(a_df_copy)
print(f'Same base: {a_df.to_numpy().base is a_df_copy.to_numpy().base}')
print(f'Same row index: {a_df.index is a_df_copy.index}')
print(f'Same column index: {a_df.columns is a_df_copy.columns}')Вывод:
dataframe is
c0 c1 c2 c3 c4
r0 5 2 8 6 6
r1 1 9 1 1 1
r2 0 7 6 3 7
r3 7 4 9 5 2
r4 5 8 3 7 1
datatypes are [dtype('int64')]
number of bytes is 200 bytes (25 x 8 bytes)
size is 511 bytes
pointer to data area 2893487649296
Same base: True
Same row index: True
Same column index: TrueЗдесь видно, что область данных указывает на тот же адрес памяти, основой массива выступает тот же объект, и два указанных индекса представляют те же объекты.
Теперь создадим копию (
deep=True используется по умолчанию, но я включаю его для большей ясности).a_df_copy = a_df.copy(deep=True)
show_details(a_df_copy)
print(f'Same base: {a_df.to_numpy().base is a_df_copy.to_numpy().base}')
print(f'Same row index: {a_df.index is a_df_copy.index}')
print(f'Same column index: {a_df.columns is a_df_copy.columns}')Вывод:
dataframe is
c0 c1 c2 c3 c4
r0 5 2 8 6 6
r1 1 9 1 1 1
r2 0 7 6 3 7
r3 7 4 9 5 2
r4 5 8 3 7 1
datatypes are [dtype('int64')]
number of bytes is 200 bytes (25 x 8 bytes)
size is 511 bytes
pointer to data area 2893487655536
Same base: False
Same row index: False
Same column index: FalseЗдесь у копии уже используется иная основа, что также отражено в изменённом указателе на область данных. Помимо этого, мы создали новые объекты для двух индексов. Ещё раз напомню, что аналогично массивам NumPy при нахождении в датафрейме мутабельных элементов их изменение в копии приведёт к изменению оригинального датафрейма, как это показано ниже:
import re
a_df_demo = pd.DataFrame({'c1': [1, 2], 'c2': [3, {'key1': 'v', 'key2': 'v'}]})
print('a_df_demo (before) ->', re.sub(r'\s+', ' ', str(a_df_demo)))
# make a copy
b = a_df_demo.copy(deep=True)
# remove one key-value pair from the dicitionary at iloc position (1, 1)
del b.iloc[1,1]['key2']
print('b ->', re.sub(r'\s+', ' ', str(b)))
print('a_df_demo (after) ->', re.sub(r'\s+', ' ', str(b)))Вывод:
a_df_demo (before) -> c1 c2 0 1 3 1 2 {'key1': 'v', 'key2': 'v'}
b -> c1 c2 0 1 3 1 2 {'key1': 'v'}
a_df_demo (after) -> c1 c2 0 1 3 1 2 {'key1': 'v'}Это не очень частый вариант использования датафреймов Pandas, но его всё же стоит иметь в виду. К сожалению, в Pandas невозможно сделать истинную глубокую копию, используя функцию
copy.deepcopy() из стандартной библиотеки, поскольку разработчики этой библиотеки реализовали pd.DataFrame.__deepcopy__() как pd.DataFrame.copy(deep=True). Не уверен, изменится ли это в будущем, но в любом случае данный приём считается антипаттерном. Pandas в этом плане отличается от NumPy.Теперь можно рассмотреть разные способы выбора строк и столбцов с помощью Pandas.
attempts = {'select one column': a_df['c1'],
'select one column using []': a_df[['c1']],
'select one column with loc': a_df.loc[:, 'c1'],
'select columns with loc and slicing': a_df.loc[:, 'c1':'c3'],
'select columns with loc and fancy indexing': a_df.loc[:, ['c1', 'c2', 'c3']],
'select rows using loc and a Boolean mask': a_df.loc[a_df['c1']>5],
'select rows with loc and slicing': a_df.loc['r1': 'r3'],
'chained indexing': a_df.loc['r1': 'r3']['c1'],
}
for title, b in attempts.items():
if a_df.to_numpy().base is not b.to_numpy().base:
print(f'{title} does not use the same base')
else:
print(f'{title} uses the same base')Вывод:
select one column uses the same base
select one column using [] does not use the same base
select one column with loc uses the same base
select columns with loc and slicing uses the same base
select columns with loc and fancy indexing does not use the same base
select rows using loc and a Boolean mask does not use the same base
select rows with loc and slicing uses the same base
chained indexing uses the same baseПри базовом индексировании и получении срезов, например, в случае простого индексирования по столбцам с использованием квадратных скобок или аксессора
.loc[], используется одна основа, но при остальных операциях это не так. В случае сомнений вышеприведённая схема вычислительных экспериментов позволит получить быстрый ответ.К сожалению, проверки неизменности основы не всегда достаточно для прогнозирования последствий использования цепного индексирования (см. ниже), но она даёт некоторое базовое понимание. В последней попытке основа остаётся прежней, но даже если мы используем это цепное индексирование для установки значений, исходный датафрейм останется неизменным. Хотя есть и обратный вариант: если основа изменяется, значит, мы работаем с копией. Здесь бы не помешали ваши комментарии, поскольку в этом вопросе я начинаю плавать.
Далее же мы перейдём к заключительной теме, связанной с Pandas, а именно к пресловутому цепному индексированию и связанным с ним
SettingWithCopyWarning. Используя ранее определённый датафрейм a_df, можно попробовать изменить значения конкретных элементов столбца при помощи логического индекса. Если предположить использование цепного индексирования, то на ум приходят два способа:# создание копии, чтобы не изменять исходный датафрейм
a_df_demo = a_df.copy(deep=True)
# установка логического индекса
msk = a_df['c1']>5
# attempt 1: сначала логическое индексирование (выдаёт SettingWithCopyWarning)
print('attempt 1')
a_df_demo.loc[msk]['c3'] = -1
print(a_df_demo)
# attempt 2, логическое индексирование в конце
print('\nattempt 2')
a_df_demo['c3'].loc[msk] = -1 # <- выдаёт предупреждение
print(a_df_demo)Вывод:
attempt 1
c0 c1 c2 c3 c4
r0 5 2 8 6 6
r1 1 9 1 1 1
r2 0 7 6 3 7
r3 7 4 9 5 2
r4 5 8 3 7 1
attempt 2
c0 c1 c2 c3 c4
r0 5 2 8 6 6
r1 1 9 1 -1 1
r2 0 7 6 -1 7
r3 7 4 9 5 2
r4 5 8 3 -1 1
<ipython-input-789-06440868e65b>:5: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
a_df_demo.loc[msk]['c3'] = -1Здесь имеет значение порядок выполнения операций. Первая попытка приводит к выдаче
SettingWithCopyWarning, что вполне ожидаемо. При использовании аксессора .loc[] с логической маской мы получаем копию. Присваивание элементам копии новых значений не ведёт к изменению исходного датафрейма. Это ожидаемое поведение, но Pandas, в отличие от NumPy, делает дополнительный шаг и даёт пользователю рекомендацию. Хотя даже в случае Pandas не стоит особо полагаться на такие предупреждения, поскольку выводятся они не всегда. К примеру,a_df_demo = a_df.copy(deep=True)
a_df_demo.loc[['r1', 'r2', 'r3']]['c3'] = -1
print(a_df_demo)Не выдаёт предупреждения, хотя датафрейм не изменяется, что видно по выводу:
c0 c1 c2 c3 c4
r0 5 2 8 6 6
r1 1 9 1 1 1
r2 0 7 6 3 7
r3 7 4 9 5 2
r4 5 8 3 7 1Нужно ли всё это помнить? Не обязательно. Не только потому, что практически нереально перечислить все возможности цепного индексирования, но также ввиду отсутствия гарантии неизменности поведения в различных версиях Pandas при использовании
SettingWithCopyWarning. Хуже того, может случиться так, что в одной версии датафрейм будет изменяться, а в другой нет (личных подтверждений этому у меня нет, просто опасения).Использование виртуальной среды и настройка файла requirements.txt не только предотвратят ад зависимостей, но и защитят от подобных опасностей, хотя лучше всего знать, какие присваивания в Pandas представляют риски, чтобы их избегать. Ситуация дополнительно усложняется, когда датафрейм содержит иерархические индексы и разные типы данных. В таком случае пытаться предугадать результат цепного индексирования опасно.
Правильным выходом будет избегать такого вида индексирования и использовать для установки значений один аксессор. Вот пример:
a_df_demo = a_df.copy(deep=True)
a_df_demo.loc['r1':'r2', 'c2'] = -1
print(a_df_demo)Этот код выводит изменённый датафрейм, не выводя предупреждение.
c0 c1 c2 c3 c4
r0 5 2 8 6 6
r1 1 9 -1 1 1
r2 0 7 -1 3 7
r3 7 4 9 5 2
r4 5 8 3 7 1Так весь смысл в использовании одного аксессора?
Использовать один аксессор и избегать цепного индексирования – это определённо надёжный совет, но есть тут и подвохи. Давайте создадим срез датафрейма и посмотрим, что с ним происходит при изменении исходных данных.
Первая попытка подразумевает три подобных эксперимента.
# -- NOT ALWAYS CHANGED --
print('experiment 1')
df = pd.DataFrame({"a": np.arange(4), "b": np.arange(4)})
print('data buffer pointer (before) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (before) ->', df.dtypes.unique().tolist())
my_slice = df.loc[1:3]
print('my_slice (before) ->', my_slice.unstack().to_list())
# Изменяет my_slice
df.loc[1, 'a'] = -10
print('data buffer pointer (after) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (after) ->', df.dtypes.unique().tolist())
print('my_slice (after) ->', my_slice.unstack().to_list())
print('experiment 2')
df = pd.DataFrame({"a": np.arange(4), "b": np.arange(4)})
print('data buffer pointer (before) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (before) ->', df.dtypes.unique().tolist())
my_slice = df.loc[1:3]
print('my_slice (before) ->', my_slice.unstack().to_list())
# Изменяет my_slice
df.loc[0:, 'a'] = -10
print('data buffer pointer (after) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (after) ->', df.dtypes.unique().tolist())
print('my_slice (after) ->', my_slice.unstack().to_list())
print('experiment 3')
df = pd.DataFrame({"a": np.arange(4), "b": np.arange(4)})
print('data buffer pointer (before) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (before) ->', df.dtypes.unique().tolist())
my_slice = df.loc[1:3]
print('my_slice (before) ->', my_slice.unstack().to_list())
# Не изменяет my_slice
df.loc[:, 'a'] = -10
print('data buffer pointer (after) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (after) ->', df.dtypes.unique().tolist())
print('my_slice (after) ->', my_slice.unstack().to_list())Отличаются эти эксперименты только способом изменения исходного датафрейма. Первый изменяет лишь один элемент столбца
a, второй изменяет весь столбец a, а третий также изменяет весь этот столбец, но уже с помощью df.loc[:,'a'].Вот вывод:
experiment 1
data buffer pointer (before) -> 2893435341184
data types (before) -> [dtype('int32')]
my_slice (before) -> [1, 2, 3, 1, 2, 3]
data buffer pointer (after) -> 2893435341184
data types (after) -> [dtype('int32')]
my_slice (after) -> [-10, 2, 3, 1, 2, 3]
experiment 2
data buffer pointer (before) -> 2893490708496
data types (before) -> [dtype('int32')]
my_slice (before) -> [1, 2, 3, 1, 2, 3]
data buffer pointer (after) -> 2893490708496
data types (after) -> [dtype('int32')]
my_slice (after) -> [-10, -10, -10, 1, 2, 3]
experiment 3
data buffer pointer (before) -> 2893435341184
data types (before) -> [dtype('int32')]
my_slice (before) -> [1, 2, 3, 1, 2, 3]
data buffer pointer (after) -> 2893491528672
data types (after) -> [dtype('int64'), dtype('int32')]
my_slice (after) -> [1, 2, 3, 1, 2, 3]В результате успешного изменения датафрейма его срез также изменяется только в первых двух экспериментах. Если посмотреть внимательно, тип одного из столбцов датафрейма изменился на
int64, а его буфер данных переместился в памяти. Я думаю, что причина преобразования типа в изменении значения всего столбца a. В этом можно убедиться, если установить тип данных явно при создании датафрейма.# -- ALWAYS CHANGED --
print('experiment 1')
df = pd.DataFrame({"a": np.arange(4), "b": np.arange(4)}, dtype='int64')
print('data buffer pointer (before) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (before) ->', df.dtypes.unique().tolist())
my_slice = df.loc[1:3]
print('my_slice (before) ->', my_slice.unstack().to_list())
# Изменяет my_slice
df.loc[1, 'a'] = -10
print('data buffer pointer (after) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (after) ->', df.dtypes.unique().tolist())
print('my_slice (after) ->', my_slice.unstack().to_list())
print('experiment 2')
df = pd.DataFrame({"a": np.arange(4), "b": np.arange(4)}, dtype='int64')
print('data buffer pointer (before) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (before) ->', df.dtypes.unique().tolist())
my_slice = df.loc[1:3]
print('my_slice (before) ->', my_slice.unstack().to_list())
# Изменяет my_slice
df.loc[0:, 'a'] = -10
print('data buffer pointer (after) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (after) ->', df.dtypes.unique().tolist())
print('my_slice (after) ->', my_slice.unstack().to_list())
print('experiment 3')
df = pd.DataFrame({"a": np.arange(4), "b": np.arange(4)}, dtype='int64')
print('data buffer pointer (before) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (before) ->', df.dtypes.unique().tolist())
my_slice = df.loc[1:3]
print('my_slice (before) ->', my_slice.unstack().to_list())
# Не изменяет my_slice
df.loc[:, 'a'] = -10
print('data buffer pointer (after) ->', df.to_numpy().__array_interface__['data'][0])
print('data types (after) ->', df.dtypes.unique().tolist())
print('my_slice (after) ->', my_slice.unstack().to_list())Вывод:
experiment 1
data buffer pointer (before) -> 2893491528672
data types (before) -> [dtype('int64')]
my_slice (before) -> [1, 2, 3, 1, 2, 3]
data buffer pointer (after) -> 2893491528672
data types (after) -> [dtype('int64')]
my_slice (after) -> [-10, 2, 3, 1, 2, 3]
experiment 2
data buffer pointer (before) -> 2893486517968
data types (before) -> [dtype('int64')]
my_slice (before) -> [1, 2, 3, 1, 2, 3]
data buffer pointer (after) -> 2893486517968
data types (after) -> [dtype('int64')]
my_slice (after) -> [-10, -10, -10, 1, 2, 3]
experiment 3
data buffer pointer (before) -> 2893491528672
data types (before) -> [dtype('int64')]
my_slice (before) -> [1, 2, 3, 1, 2, 3]
data buffer pointer (after) -> 2893491528672
data types (after) -> [dtype('int64')]
my_slice (after) -> [-10, -10, -10, 1, 2, 3]Думаю, нет особого смысла оставлять уже неактуальный срез, если только он не был явно скопирован с помощью
df.loc[1:3].copy(). В противном случае всегда можно получить свежий срез датафрейма именно в момент необходимости. Хотя это вполне рабочий эксперимент, позволяющий лучше понять тему представлений и копий.Заключение
Чтобы понять, когда Python создаёт копии, а когда представления, необходима практика. Списки Python, массивы NumPy и датафреймы Pandas предлагают функции для создания копий и представлений, как это показано в таблице ниже.
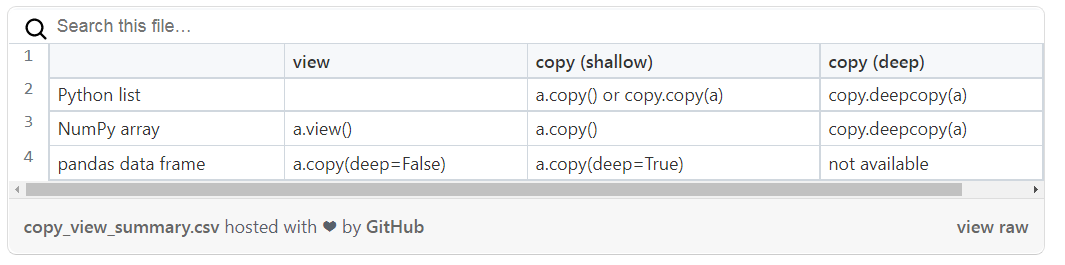
Интерактивная версия доступна в оригинале статьи
Однако самые важные выводы связаны с поведением инструкций присваивания на основе индексов при использовании массивов NumPy и датафреймов Pandas:
- цепное индексирование NumPy обычно вполне ясно: базовое индексирование даёт представления, а продвинутое возвращает копии, которые исключают изменение исходного массива в случае новых присваиваний. Это поведение несколько усложняется при использовании операций изменения формы (
reshape); - цепного индексирования в Pandas желательно избегать, используя вместо него один аксессор для всех присваиваний. Это касается даже тех случаев, когда поведение цепного индексирования, казалось бы, можно спрогнозировать.
Понимать принцип создания представлений и копий очень важно, особенно при работе с крупными массивами и датафреймами. Надеюсь, эта статья послужит основой для дальнейшего изучения темы. Несомненно, некоторые аспекты я упустил, а некоторые — мог неверно понять сам. Буду признателен за ваши справедливые замечания и дополнения в комментариях, которые лишний раз подтвердят истинность изречения Альберта Эйнштейна.
▍ Рекомендуемые материалы:
- Прекрасная статья (англ.) о вездесущем
SettingWithCopyWarningв Pandas; - Документация Python по копиям и представлениям;
- Документация Pandas по копиям и представлениям.

