
График Гартнера для тех, кто работает в сфере технологий, – всё равно что выставка высокой моды. Взглянув на него, вы можете заранее узнать, какие слова самые хайповые в этом сезоне и что вы услышите на всех ближайших конференциях.
Мы расшифровали, что скрывается за красивыми словами на этом графике, чтобы вы могли тоже говорить на этом языке.
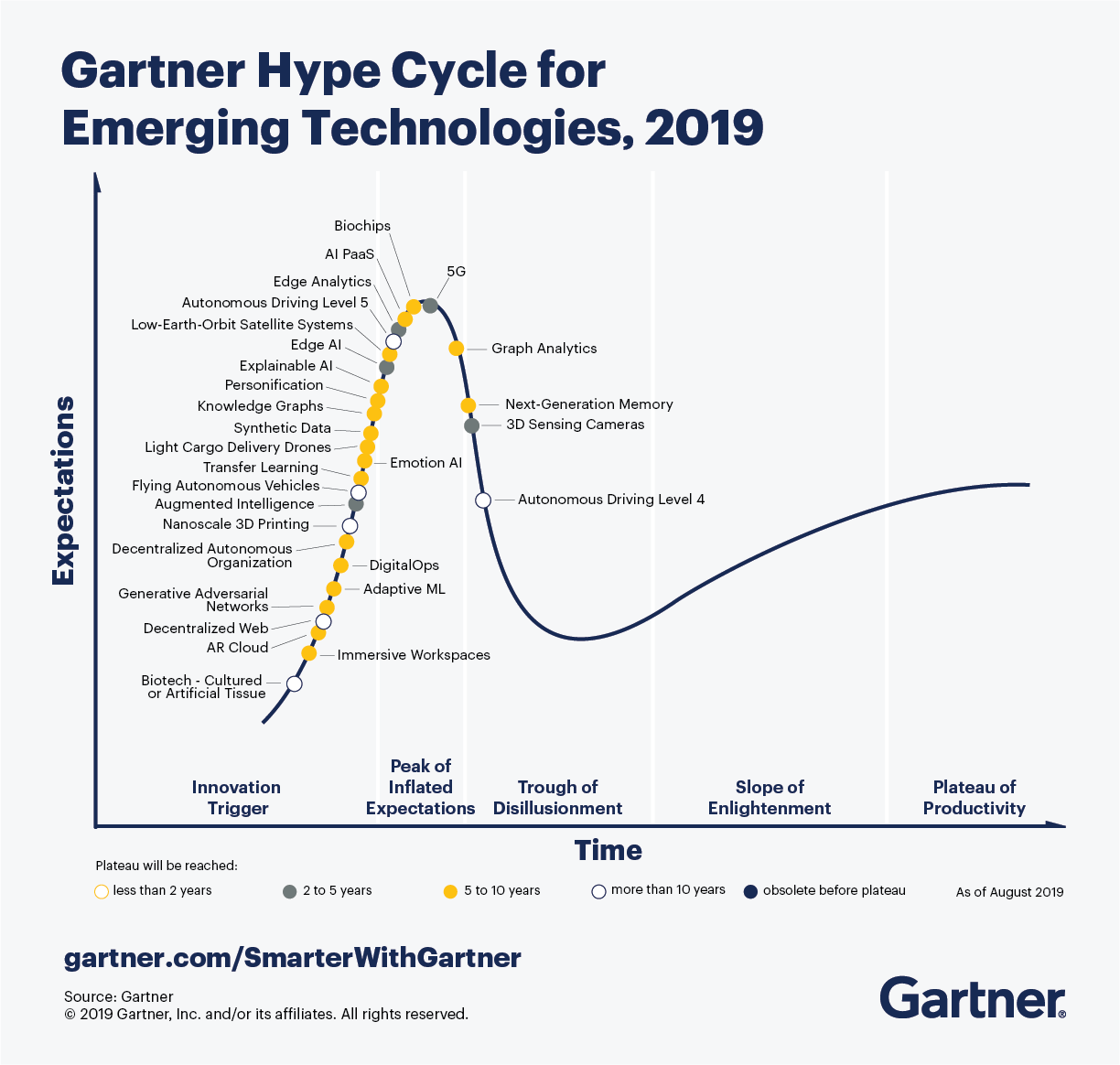
Для начала буквально пару слов, что же это за график. Каждый год в августе консалтинговое агенство Гартнер выпускает отчёт – Gartner Hype Curve. По-русски это «кривая ажиотажа», или, проще говоря – хайпа. 30 лет назад рэперы из группы Public Enemy пели: «Don’t believe the hype». Верить или нет, вопрос личный, но хотя бы знать эти ключевые слова стоит, если вы работаете в сфере технологий и хотите знать мировые тренды.
Это график общественных ожиданий от той или иной технологии. По мнению Гартнера, в идеальном случае технология последовательно проходит 5 стадий: запуск технологии, пик завышенных ожиданий, долина разочарования, склон просвещения, плато продуктивности. Но бывает и так, что она тонет в «долине разочарования» — примеры можете вспомнить сами очень легко, взять те же самые биткоины: изначально попав на пик как «деньги будущего», они быстро скатились вниз, когда стали очевидны недостатки технологии, прежде всего ограничения на количество транзакций и бешеное количество электроэнергии, требуемое на порождение биткоинов (что влечет уже проблемы с экологией). И конечно, нельзя забывать, что график Гартнера – это всего лишь прогноз: тут, например, можно почитать подробную статью, где разбираются самые яркие несбывшиеся предсказания.
Итак, пробежимся по новому графику Гартнера. Технологии разделены на 5 больших тематических групп:
Последние лет 10 мы видим звёздный час глубокого обучения (Deep Learning). Эти сети по-настоящему эффективны для своего круга задач. В 2018 году Ян Лекун, Джеффри Хинтон и Йошуа Бенжио получили за открытия в них премию Тьюринга – самую престижную премию, аналог «Нобелевки» в информатике. Итак, основные тренды в этой области, которые вынесены на график:
Вы не обучаете нейронную сеть с нуля, а берёте уже обученную, и назначаете ей другую цель. Иногда для этого нужно переучить часть сети, но не всю сеть, что гораздо быстрее. Например, взяв готовую нейронную сеть ResNet50, обученную на датасете ImageNet1000, вы получите алгоритм, способный классифицировать по изображению очень много разных объектов на очень глубоком уровне (1000 классов по признакам, выработанным 50 слоями нейронной сети). Но вам не нужно обучать всю эту сеть целиком, что заняло бы месяцы.
В онлайне-курсе Samsung «Нейронные сети и компьютерное зрение», для примера, в финальной Kaggle-задаче с классификацией тарелок на чистые и грязные, демонстрируется подход, который за 5 минут даёт вам в распоряжение глубокую нейронную сеть, способную отличать грязные тарелки от чистых, построенную по вышеописанной архитектуре. Исходная сеть не знала, что такое тарелки вообще, она лишь училась отличать птичек от собачек (см. ImageNet).

Источник: онлайн-курс Samsung «Нейронные сети и компьютерное зрение»
Для Transfer Learning нужно знать, какие подходы работают, какие есть готовые базовые архитектуры. В целом, это очень ускоряет появление практических применений машинного обучения.
Это для тех случаев, когда нам очень сложно сформулировать цель обучения. Чем ближе задача к реальной жизни, тем она понятнее нам («принеси тумбочку»), но тем сложнее её сформулировать как техническое задание. GAN — как раз попытка избавить нас от этой проблемы.
Здесь работают две сети: одна генератор (Generative), другая дискриминатор (Adversarial). Одна сеть учится делать полезную работу (классифицировать картинки, распознавать звуки, рисовать мультики). А другая сеть учится учить ту сеть: у неё есть реальные примеры, и она учится находить заранее неизвестную сложную формулу для сравнения порождений генеративной части сети с объектами реального мира (обучающей выборкой) по действительно важным глубоким признакам: количество глаз, близость к стилю Миядзаки, правильность произношения английского.

Пример результата работы сети для порождения аниме-персонажей. Источник
Но там, конечно же, сложно выстроить архитектуру. Недостаточно просто бросить нейронов, их нужно готовить. И учить приходится неделями. Темой GAN занимаются мои коллеги в Центре искусственного интеллекта Samsung, у них это один из ключевых исследовательских вопросов. Например, вот такая разработка: использование генеративных сетей для синтеза реалистичных фотографий людей с изменяемой позой — например, чтобы создать виртуальную примерочную, или для синтеза лица, что может позволить снизить количество информации, которое нужно хранить или передавать для обеспечения качественной видеосвязи, вещания или защиты персональных данных.

Источник
В некоторых редких задачах прогресс в глубоких архитектурах внезапно приблизил возможности глубоких нейросетей к человеческим. Теперь битва идёт за то, чтобы круг таких задач увеличить. Например, робот-пылесос мог бы легко отличить кошку от собаки при лобовой встрече. Но в большинстве жизненных ситуаций он будет неспособен найти кошку, спящую среди белья или мебели (впрочем, как и мы, в большинстве случаев...).
В чем причина успехов глубоких нейронных сетей? Они вырабатывают представление задачи, основанное не на «видимой невооружённым глазом» информации (пикселях фотографии, скачках громкости звука...), а на признаках, полученных после предобработки этой информации несколькими сотнями слоёв нейронной сети. К сожалению, эти взаимосвязи могут также быть бессмысленными, противоречивыми или нести следы несовершенства исходного набора данных. Например, о том, к чему может привести бездумное применение AI в рекрутинге, есть небольшая компьютерная игра Survival Of The Best Fit.

Система для разметки изображений назвала человека, который готовит, женщиной, хотя на картинке на самом деле мужчина (Источник). Это заметили в Институте Виргинии.
Чтобы анализировать сложные и глубокие взаимосвязи, которые мы часто не можем сами сформулировать, и нужны методы Explainable AI. Они организуют признаки глубоких нейросетей так, чтобы после обучения мы могли анализировать выученное сетью внутреннее представление, а не просто полагаться на её решение.
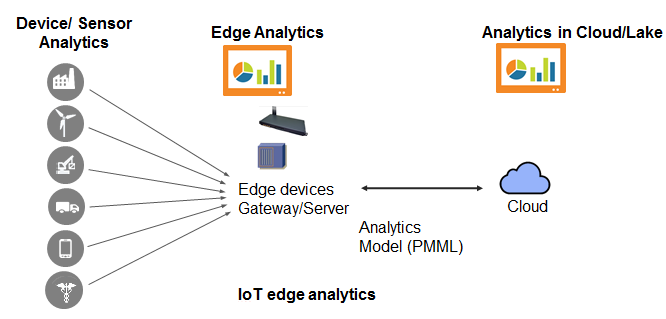
Всё, где есть слово Edge, означает буквально следующее: перенос части алгоритмов из облака/сервера на уровень конечного устройства/шлюза. Такой алгоритм будет срабатывать быстрее и не будет нуждаться в подключении к центральному серверу для своей работы. Если вам знакома абстракция «тонкого клиента», то здесь мы этого клиента немного утолщаем.
Это может быть важно для Интернета вещей. К примеру, если станок перегрелся и нуждается в охлаждении, имеет смысл подать сигнал об этом сразу же, на уровне завода, не дожидаясь, пока данные попадут в облако и оттуда уже мастеру смены. Или другой пример: автомобили-беспилотники могут разобраться с дорожной обстановкой самостоятельно, без обращения к центральному серверу.
Источник
Или другой пример, почему это важно с точки зрения безопасности: когда вы на своем телефоне набираете тексты, он запоминает типичные для вас слова, чтобы дальше вам клавиатура телефона их удобно подсказывала – это называется предиктивный ввод текста. Отправлять куда-то в дата-центр все, что вы вводите на клавиатуре, было бы нарушением вашей приватности и попросту небезопасно. Поэтому обучение клавиатуры происходит только в рамках самого вашего устройства.
PaaS – Платформа-как-услуга – это бизнес-модель, при которой мы получаем доступ к интегрированной платформе, включая её облачное хранилище данных и готовые процедуры. Таким образом, мы можем освободить себя от инфраструктурных задач, и полностью сконцентрироваться на производстве чего-то полезного. Пример платформ PaaS для задач ИИ: IBM Cloud, Microsoft Azure, Amazon Machine Learning, Google AI Platform.
Что, если мы позволим искусственному интеллекту адаптироваться… Вы спросите – то есть как?.. Разве он и так не адаптируется к задаче? Проблема вот в чём: каждую такую задачу мы кропотливо оформляем, прежде чем построить для ее решения алгоритм искусственного интеллекта. Вам ответят – оказывается, можно и эту цепочку упростить.
Обычное машинное обучение работает по принципу открытой системы (open-loop): вы готовите данные, придумываете нейронную сеть (или что угодно), обучаете, потом смотрите на несколько показателей, и если вам всё нравится, можно отправить нейросеть в смартфоны – решать задачи пользователей. Но в применениях, где данных очень много и их характер постепенно меняется, нужны другие методы. Такие системы, которые адаптируются и обучают сами себя, организуют в закрытые, самообучающиеся контуры (closed-loop), и они должны работать бесперебойно.
Применения — это может быть потоковая аналитика (Stream Analytics), на основании которой множество бизнесменов принимают решения, или адаптивное управление производством. В масштабе современных применений и с учётом лучше понимаемых рисков для людей, методы, которые составляют решение этой проблемы, все эти методы собираются под общим названием Adaptive AI.
Источник
Глядя на эту картинку, сложно отделаться от ощущения, что футурологов хлебом не корми – дай научить робота дышать…
Это настолько интересная тема, что сразу отсылаем к нашей статье. Ну а здесь краткая выжимка. 5G за счет повышения частоты передачи данных сделает скорость Интернета нереально быстрой. Коротким волнам сложнее проходить через препятствия, поэтому устройство сетей будет совершенно другим: базовых станций нужно в 500 раз больше.
Вместе со скоростью мы получим новые явления: реалтайм-игры с дополненной реальностью, выполнение сложных задач (таких, как хирургия) через телеприсутствие, предотвращение аварий и сложных ситуаций на дорогах через коммуникацию между машинами. Из более прозаичного: наконец-то перестанет падать мобильный Интернет во время массовых мероприятий, таких как матч на стадионе.

Источник картинки — Reuters, Niantic
Здесь речь идёт о пятом поколении оперативной памяти – DDR5. Samsung анонсировала, что до конца 2019 года появятся продукты на базе DDR5. Ожидается, что новая память будет в два раза быстрее и в два раза более ёмкая с сохранением форм-фактора, то есть мы сможем получить для своего компьютера плашки памяти с ёмкостью до 32Гб. В будущем это будет особенно актуально для смартфонов (новая память будет в версии с низким энергопотреблением) и для ноутбуков (где количество DIMM-слотов ограничено). А ещё машинное обучение требует больших объёмов оперативной памяти.
Идея замены тяжелых, дорогих, мощных спутников на рой маленьких и дешевых далеко не нова и появилась ещё в 90-е. Про то, что «Илон Маск скоро будет раздавать всем Интернет со спутника» сейчас не слышал уже только ленивый. Здесь самая известная компания – это Iridium, которая обанкротилась в конце 90-х, но была спасена за счёт Минобороны США (не путать с iRidium – российской системой умного дома). Проект Илона Маска (Starlink) далеко не единственный – в спутниковой гонке участвуют Ричард Брэнсон (OneWeb – 1440 предполагаемых спутников), Boeing (3000 спутников), Samsung (4600 спутников), и другие.
Как обстоит дело в этой области, как там выглядит экономика – читайте в обзоре. А мы ждём первых тестов этих систем первыми пользователями, которые должны состояться уже в следующем году.
3D печать, хоть и не вошла в жизнь каждого человека (в форме, обещанной индивидуальной домашней пластиковой фабрики), тем не менее давно вышла из ниши технологий для гиков. Судить можно по тому, что о существовании хотя бы 3D-скульптурных ручек известно любому школьнику, и многие мечтают приобрести себе коробку с полозьями и экструдером для… «просто так» (или уже приобрели).
Стереолитография (лазерные 3D принтеры) позволяют печатать отдельными фотонами: исследуются новые полимеры, для затвердевания которых достаточно двух фотонов. Это позволит в не-лабораторных условиях создавать совершенно новые фильтры, крепления, пружины, капилляры, линзы и… ваши варианты в комментариях! И здесь недалеко до фотополимеризации – только эта технология позволяет «печатать» процессоры и вычислительные схемы. Помимо этого, не первый год существует технология печати графеновых 500-нм трёхмерных структур, но без радикального развития.

Источник
Чтобы не запутаться в терминологии, стоит разобраться в том, какие уровни автономности различают (взято из подробной статьи, к которой мы отсылаем всех заинтересовавшихся):
Уровень 1: Круиз-контроль: помощь водителю в очень ограниченных ситуациях (например – удержание автомобиля на заданной скорости после того, как водитель снял ногу с педали)
Уровень 2: Ограниченная помощь с рулением и торможением. Водитель должен быть готов взять управление на себя практически мгновенно. Его руки находятся на руле, взгляд направлен на дорогу. Это то, что уже есть в Tesla и General Motors.
Уровень 3: Водитель больше не должен постоянно следить за дорогой. Но должен оставаться начеку и быть готов взять управление на себя. Это то, чего пока нет у имеющихся в продаже автомобилей. Все существующие на настоящий момент – на уровне 1-2.
Уровень 4: Настоящий автопилот, но с ограничениями: только поездки в известной области, которая тщательно картографирована и в целом известна системе, и при определенных условиях: например, в отсутствие снега. Такие прототипы есть у Waymo и General Motors, и они планируют запускать их в нескольких городах и тестировать в реальной обстановке. У «Яндекса» есть тестовые зоны беспилотного такси в Сколково и Иннополисе: поездка происходит под присмотром инженера, сидящего на месте пассажира; к концу года компания планирует расширить парк до 100 беспилотных машин.
Уровень 5: Полное автоматическое вождение, полная замена живого водителя. Таких систем не существует, и вряд ли они появятся в ближайшие годы.
Насколько реалистично всё это увидеть в обозримое время? Здесь хотелось бы переадресовать читателя к статье «Почему запустить роботакси к 2020 году, как обещает Tesla, невозможно». Это отчасти связано с отсутствием связи 5G: имеющихся скоростей 4G недостаточно. Отчасти с очень высокой стоимостью автономных машин: они пока нерентабельны, непонятна бизнес-модель. Словом, здесь «всё сложно», и неслучайно Гартнер пишет, что прогноз массового внедрения Уровня 4 и 5 – не раньше, чем через 10 лет.
Восемь лет назад игровой контроллер Microsoft Kinect наделал шуму, предложив доступное и сравнительно недорогое решение для 3D-зрения. С тех пор физкультурно-танцевальные игры с Кинектом пережили свой недолгий взлёт и упадок, зато 3D-камеры стали использоваться в промышленных роботах, беспилотных автомобилях, мобильных телефонах для идентификации по лицу. Технология стала дешевле, компактнее и доступнее.

В телефоне Samsung S10 стоит времяпролетная (Time-of-Flight) камера, которая измеряет расстояние до объекта – для упрощения фокусировки. Источник
Если вас заинтересовала эта тема, то переадресуем к очень хорошему подробному обзору камер глубины: часть 1, часть 2.
В этом году Amazon наделала шуму, когда показала на выставке новый летающий дрон, способный перевозить небольшие грузы до 2 кг весом. Для города, с его пробками, это кажется идеальным решением. Посмотрим, как эти дроны проявят себя уже в самом ближайшем будущем. Пожалуй, здесь стоит включить осторожный скепсис: есть множество проблем, начиная с возможности легкой кражи дрона, и заканчивая законодательными ограничениями на БПЛА. Amazon Prime Air существует уже шесть лет, но по-прежнему находится на этапе тестирования.

Новый дрон Amazon, показанный этой весной. Что-то есть в нем от «Звездных войн». Источник
Помимо Amazon, есть и другие игроки на этом рынке (есть подробный обзор), но ни одного готового продукта: всё – на стадии тестирования и маркетинговых акций. Отдельно стоит отметить достаточно интересные узкоспециализированные медицинские проекты в Африке: доставка донорской крови в Гане (14 000 доставок, компания Zipline) и Руанде (компания Matternet).
Здесь сложно сказать что-то определённое. По мнению Гартнера, это появится не ранее, чем через 10 лет. В общем-то, здесь все те же самые проблемы, что и в беспилотных автомобилях, только они приобретают новое измерение — вертикальное. О своих амбициях построить летающее такси заявляют Porsche, Boeing, Uber.
Постоянная цифровая копия реального мира, позволяющая создать новый слой реальности, общий для всех пользователей. Если говорить более техническим языком, то речь о том, чтобы сделать открытую облачную платформу, в которую разработчики могли бы интегрировать свои AR-приложения. Модель монетизации понятна, это некий аналог Steam. Идея настолько укоренилась, что теперь уже некоторые считают, что AR без облака попросту бесполезно.
Как это может выглядеть в будущем, нарисовано в небольшом ролике. Выглядит как очередная серия «Чёрного зеркала»:
Ещё можно почитать в статье-обзоре.
Как измерить, симулировать и среагировать на человеческие эмоции? Одни из клиентов здесь – компании, производящие голосовых ассистентов наподобие Amazon Alexa. По-настоящему вжиться в дома они смогут, если научатся распознавать настроение: понять причину недовольства пользователя, попробовать исправить ситуацию. Вообще в контексте гораздо больше информации, чем в самом сообщении. А контекст – это и выражение лица, и интонация, и невербальное поведение.
Из других практических применений: анализ эмоций во время собеседования на работе (по видеоинтервью), оценивание реакции на рекламные ролики или иной видеоконтент (улыбки, смех), помощь при обучении (например, для самостоятельных практик в искусстве публичных выступлений).
На эту тему сложно высказаться лучше, чем автор 6-минутной короткометражки Stealing Ur Feeling. В остроумно и стильно сделанном ролике показано, как можно измерять наши эмоции в маркетинговых целях, и из сиюминутных реакций вашего лица узнать: любите ли вы пиццу, собак, Канье Уэста, и даже каков ваш уровень дохода и примерный IQ. Перейдя на сайт фильма по ссылке выше, вы становитесь участником интерактивного видео с использованием встроенной камеры вашего ноутбука. Фильм уже был показан на нескольких кинофестивалях.

Источник
Есть даже такое интересное исследование: как распознавать сарказм в тексте. Взяли твиты с хэштегом #сарказм и сделали обучающую выборку из 25 000 твитов с сарказмом и 100 000 обычных твитов обо всем на свете. Применили библиотеку TensorFlow, обучили систему, вот результат:

Источник
Поэтому теперь, если вы не уверены насчет вашего коллеги или приятеля – сказал он вам что-то всерьез или с сарказмом, — вы можете воспользоваться уже обученной нейросетью!
Автоматизация интеллектуального труда при помощи методов машинного обучения. Казалось бы, ничего нового? Но здесь важна сама формулировка, тем более, что она совпадает по аббревиатуре с Artificial Intelligence. Это отсылает нас к полемике о «сильном» и «слабом» ИИ.
Сильный ИИ – это тот самый искусственный интеллект из фантастических фильмов, который полностью эквивалентен человеческому разуму и осознает себя как личность. Такого ещё не существует и непонятно, будет ли существовать вообще.
Слабый ИИ – это не самостоятельная личность, а помощник-ассистент человека. Он не претендует на человекоподобное мышление, а просто умеет решать информационные задачи, например, определять, что изображено на картинке или переводить текст.

Источник
В этом смысле Augmented Intelligence – это в чистом виде «слабый ИИ», и формулировка представляется удачной, поскольку не вносит путаницы и соблазна увидеть здесь тот самый «сильный ИИ», о котором все мечтают (или боятся, если вспомнить многочисленные рассуждения о «восстании машин»). Используя выражение Augmented Intelligence, мы сразу же как бы становимся героями другого фильма: из научной фантастики (наподобие «Я, робот» Азимова) мы попадаем в киберпанк («аугментациями» в этом жанре называют всевозможные имплантанты, расширяющие возможности человека).
Как сказали Эрик Бриньольфссон и Эндрю МакАффи: «За следующие 10 лет произойдет вот что. Не ИИ заменит менеджеров, а те менеджеры, которые используют ИИ, заменят тех, которые еще не успели»
Примеры:
Это любимая тема всех киберпанк-фильмов и книг. Вообще чипирование домашних животных – практика не новая. Но теперь эти чипы стали вживлять ещё и людям.
В данном случае хайп, скорее всего, связан с нашумевшим случаем в американской компании Three Square Market. Там работодатель начал предлагать вживлять под кожу чипы в обмен за вознаграждение. Чип позволяет открывать двери, логиниться в компьютеры, покупать перекусы в автомате – то есть такая универсальная карточка сотрудника. При этом такой чип служит именно как карточка идентификации, в нем нет GPS-модуля, поэтому и отследить никого по нему невозможно. А если человек хочет удалить чип из руки, это занимает 5 минут при помощи доктора.
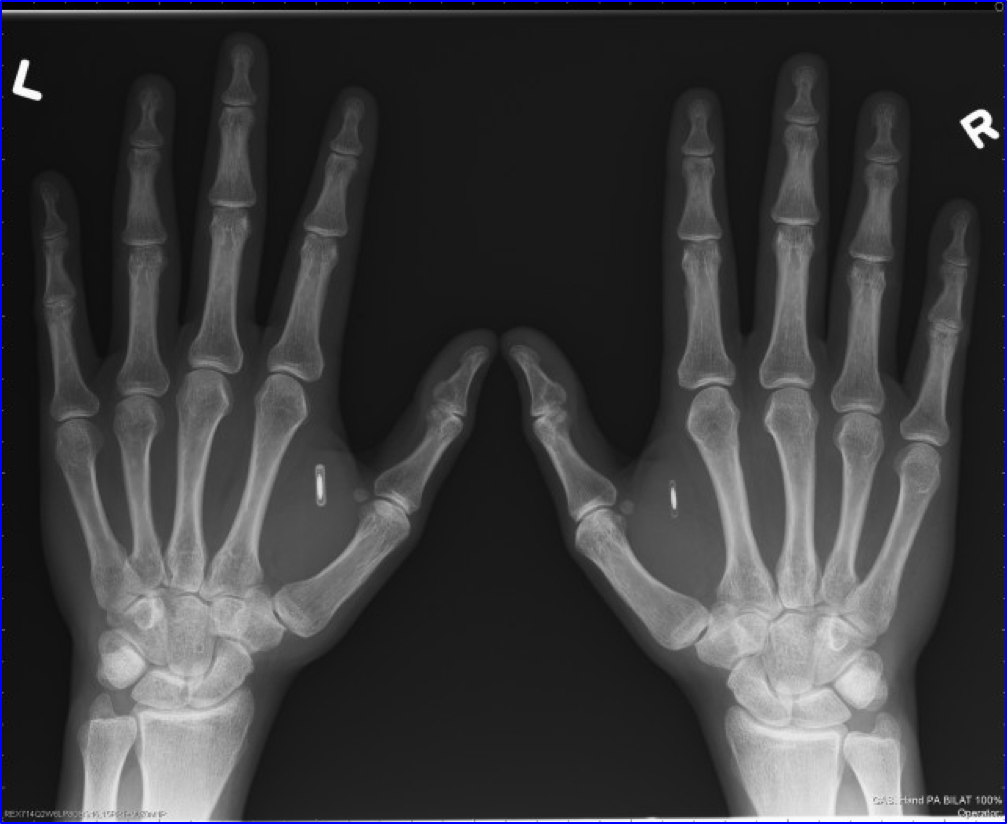
Чипы обычно вживляются между большим и указательным пальцем. Источник
Читайте подробную статью о состоянии дел с чипированием в мире.
«Иммерсивный» — ещё одно новое слово, от которого просто некуда деться. Оно повсюду. Иммерсивный театр, выставка, кино. Что же имеется в виду? Иммерсивность – это создание эффекта погружения, когда теряется граница между автором и зрителем, виртуальным и реальным миром. Применительно к рабочему месту, надо полагать, это означает стирание границы между исполнителем и инициатором и поощрение сотрудников к более активной позиции через переформатирование окружающей его среды.
Раз уж у нас повсюду теперь Agile, гибкость, тесное взаимодействие – то и рабочие места должны быть максимально легко конфигурируемы, должны поощрять групповую работу. Экономика диктует свои условия: становится больше временных сотрудников, стоимость аренды офисных помещений растет, а в условиях конкурентного рынка труда в IT компании стараются повышать удовлетворение сотрудников от работы, создавая рекреационные зоны и прочие преимущества. И всё это отражается на дизайне рабочих мест.
Из отчета Knoll
Все знают, что такое персонализация в рекламе. Это когда вы сегодня обсуждаете с коллегой, что в помещении что-то воздух суховат, и надо бы купить в офис увлажнитель, а назавтра видите у себя в соцсети рекламу – «купите увлажнитель воздуха» (реальный случай, произошедший со мной).

Источник
Персонификация же, по определению Гартнера – это ответ на возрастающее беспокойство пользователей по поводу использования их персональных данных в целях рекламы. Цель – выработать подход, при котором нам будет показываться реклама, соответствующая контексту, в котором мы находимся, а не нам лично. Например, наша локация, тип устройства, время суток, погодные условия – это то, что не нарушает наших персональных данных, и мы не чувствуем неприятное ощущение «слежки».
О разнице между этими двумя понятиями, читайте заметку Эндрю Франка в блоге на сайте Гартнера. Тут настолько тонкое различие и настолько похожие слова, что вы, не зная разницы, рискуете долго спорить с собеседником, не подозревая, что в общем-то, оба правы (и это тоже реальный случай, произошедший с автором).
Это, в первую очередь, идея выращивания искусственного мяса. Одновременно несколько команд по всему миру заняты разработкой лабораторного «Мяса 2.0» – ожидается, что оно станет дешевле обычного, и на него переключатся фастфуды, а затем и супермаркеты. Из инвесторов в эту технологию – Билл Гейтс, Сергей Брин, Ричард Брэнсон и другие.

Источник
Причины, почему всех так интересует искусственное мясо:
Подмена настоящего мяса на соевое – это частичное решение, ведь люди хорошо чувствуют разницу во вкусе и текстуре, и вряд ли откажутся от стейка в пользу сои. Так что необходимо настоящее, именно органически выращенное мясо. Сейчас, к сожалению, искусственное мясо обходится слишком дорого: от 12$ за килограмм. Это связано со сложным техпроцессом выращивания такого мяса. Читайте обо всем этом статью.
Если говорить о других кейсах выращивания тканей – уже в медицине — то интересна тема с искусственными органами: например, «пластырь» для сердечной мышцы, напечатанный специальным 3D-принтером. Известны истории наподобие выращенного искусственно мышиного сердца, но в целом всё пока не выходит за рамки клинических испытаний. Так что Франкенштейна в ближайшие годы мы вряд ли увидим.
Здесь Гартнер очень осторожен в оценках, видимо держа в уме свое провалившееся предсказание 2015 года о том, что в 2019 году 10% населения развитых стран будут иметь 3D-напечатанное медицинское устройство-имплантант. Поэтому и обозначает время выхода на плато продуктивности – не менее 10 лет.
Это понятие тесно связано с именем изобретателя веба, лауреатом премии Тьюринга, сэра Тима Бёрнерса-Ли. Для него всегда были важны вопросы этики в информатике и важна коллективная сущность Интернета: закладывая основы гипертекста, он был убежден, что сеть должна работать как паутина, а не как иерархия. Так и было на раннем этапе развития сети. Однако с ростом Интернета его структура по целому ряду причин стала централизоваться. Оказалось, что доступ к сети для целой страны можно легко перекрыть при помощи всего нескольких провайдеров. А данные пользователей превратились в источник силы и дохода интернет-компаний.
«Интернет уже децентрализован, — говорит Бёрнерс-Ли. — Проблема в том, что доминирует одна поисковая система, одна большая социальная сеть, одна платформа для микроблогинга. У нас нет технологических проблем, но есть социальные».
В своем открытом письме к 30-летию World Wide Web создатель Веба очертил три основные проблемы Интернета:
И у Тима Бернерса-Ли уже есть ответ, на каких принципах мог бы базироваться «Интернет здорового человека», лишенный проблемы номер 2: «Для многих пользователей единственной моделью взаимодействия с вебом остается доход с рекламы. Даже если люди напуганы тем, что происходит с их данными, они согласны пойти на сделку с маркетинговой машиной за возможность получать контент бесплатно. Представьте себе мир, в котором плата за товары услуги легка и приятна для обеих сторон». Из вариантов того, как это может быть устроено: музыканты могут продавать свои записи без посредников в виде iTunes, а новостные сайты — использовать систему микроплатежей за чтение одной статьи, вместо того чтобы зарабатывать на рекламе.
В качестве экспериментального прототипа такого нового Интернета, Тим Бернерс-Ли запустил проект SOLID, суть которого в том, что вы храните свои данные в «поде» — хранилище информации, и можете предоставлять эти данные сторонним приложениям. Но в принципе, вы сами – хозяева своих данных. Всё это тесно связано с понятием пиринговых сетей, то есть ваш компьютер не только запрашивает сервисы, но и предоставляет их, чтобы не полагаться на один сервер в качестве единственного канала.
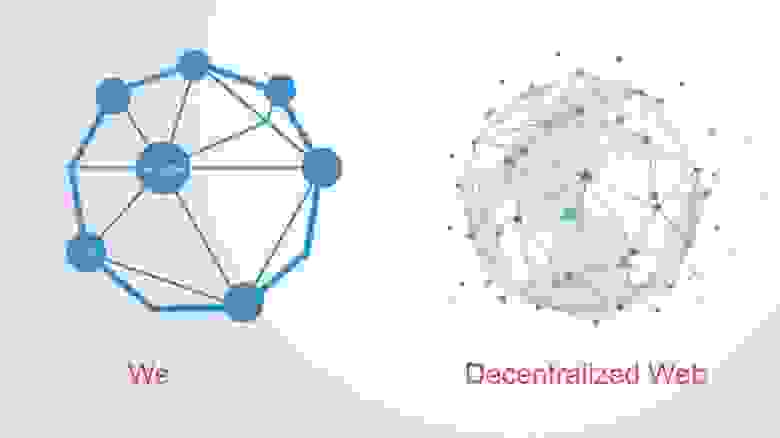
Источник
Это организация, которая управляется правилами, записанными в виде компьютерной программы. Её финансовая деятельность происходит на базе блокчейна. Цель создания таких организаций – устранить государство из роли посредника и создать общую доверенную среду для контрагентов, которой не владеет никто единолично, а владеют все вместе. То есть в теории, это должно, если идея приживется, упразднить нотариусов и другие привычные институты верификации.
Самым известным примером такой организации была ориентированная на венчурный бизнес The DAO, которая в 2016 году собрала 150 миллионов долларов, из которой 50 моментально украли через легальную «дырку» в правилах. Тут же наступила сложная дилемма: или откатить назад и вернуть деньги, или признать, что изъятие денег было легально, ведь оно никоим образом не нарушало правил платформы. В итоге, чтобы вернуть деньги инвесторам, создателям пришлось уничтожить The DAO, переписав блокчейн и нарушив его основной принцип – неизменяемость.

Комикс про Ethereum (слева) и The DAO (справа). Источник
Вся эта история испортила репутацию самой идеи DAO. Тот проект делался на базе криптовалюты Ethereum, в следующем году ожидается версия Эфир 2.0 – возможно, авторы (среди которых известный Виталик Бутерин) учтут ошибки и покажут что-то новое. Наверное, поэтому Gartner и поместил DAO на восходящую линию.
Для обучения нейросетей нужны большие объёмы данных. Размечать данные вручную – огромный труд, который может быть выполнен только человеком. Поэтому можно создавать искусственные наборы данных. Например, те же самые коллекции человеческих лиц на сайте https://generated.photos. Создаются они при помощи GAN – алгоритмов, о которых было уже сказано выше.

Эти лица не принадлежат людям. Источник
Большой плюс таких данных – в том, что не возникает юридических затруднений в их использовании: согласие на обработку персональных данных выдавать некому.
Суффикс «Ops» стал невероятно модным с тех пор, как в нашей речи прижилось DevOps. Теперь о том, что такое DigitalOps – это просто обобщение DevOps, DesignOps, MarketingOps… Вы ещё не заскучали? Короче говоря, это перенос подхода, принятого в DevOps, из сферы программного обеспечения на все остальные стороны бизнеса – маркетинг, дизайн и т.д.
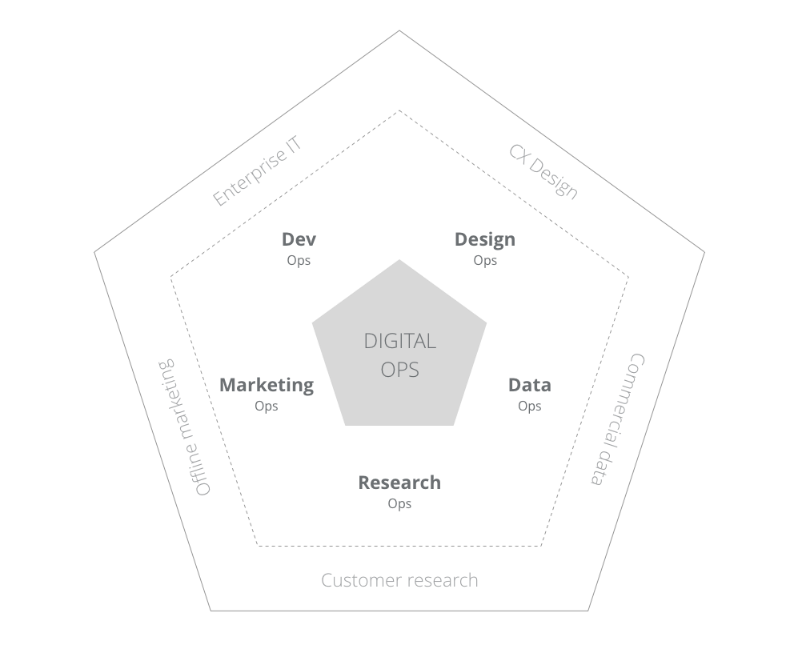
Источник
Идеей DevOps было убрать барьеры между собственно Development (разработкой) и Operations (бизнес-процессами), через создание общих команд, где и программисты, и тестировщики, и безопасники, и администраторы; внедрение определенных практик: непрерывная интеграция, инфраструктура как код, сокращение и усиление цепочек обратной связи. Цель была – ускорить вывод продукта на рынок. Если вы подумали, что это похоже на Agile, вы правильно подумали. Теперь мысленно перенесите этот подход из сферы разработки ПО к разработке вообще – и вы поняли, что такое DigitalOps.
Программный способ моделировать область знаний, в том числе — при помощи алгоритмов машинного обучения. Граф знаний строится поверх существующих баз данных, чтобы связать воедино всю информацию: как структурированную (список событий или персон), так и неструктурированную (текст статьи).
Самый простой пример – это та карточка, которую вы можете увидеть в поисковой выдаче Google. Если вы ищете какую-то персону или учреждение, то вы увидите справа карточку:
Обратите внимание, что «Предстоящие мероприятия» — это не копия информации с Google-карт, а интеграция расписания с Яндекс.Афиши: вы легко увидите это, если кликнете по событиям. То есть это объединение нескольких источников данных воедино.
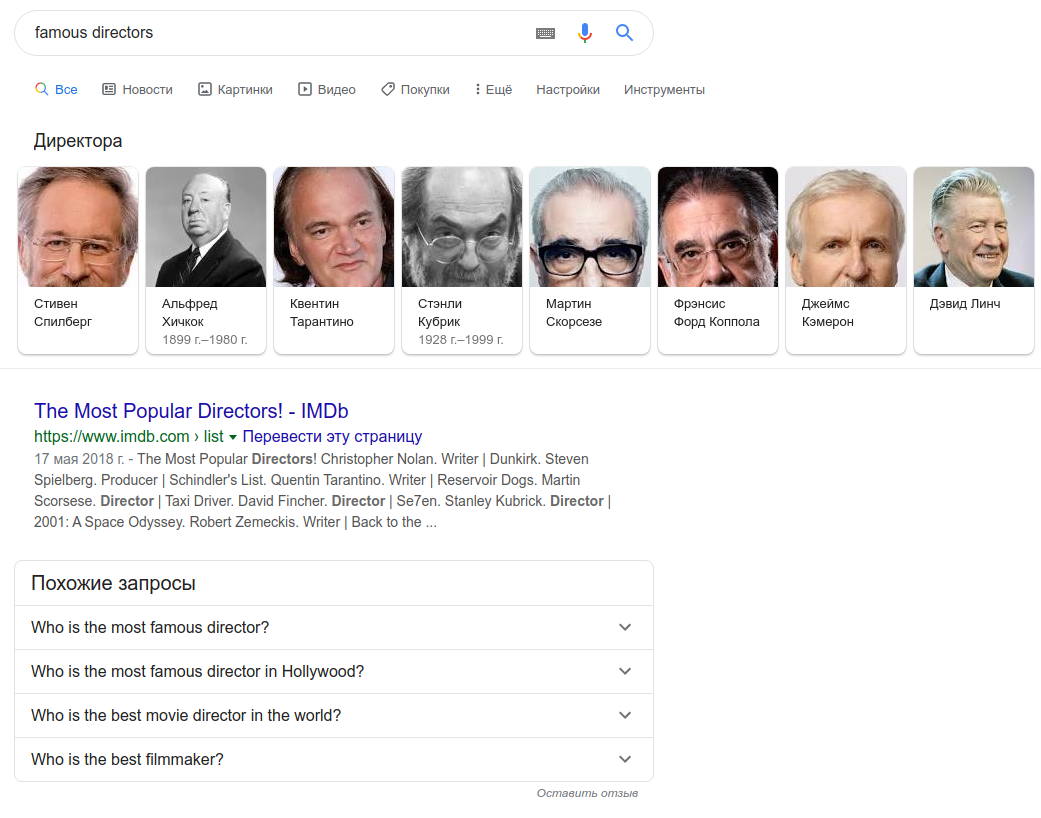
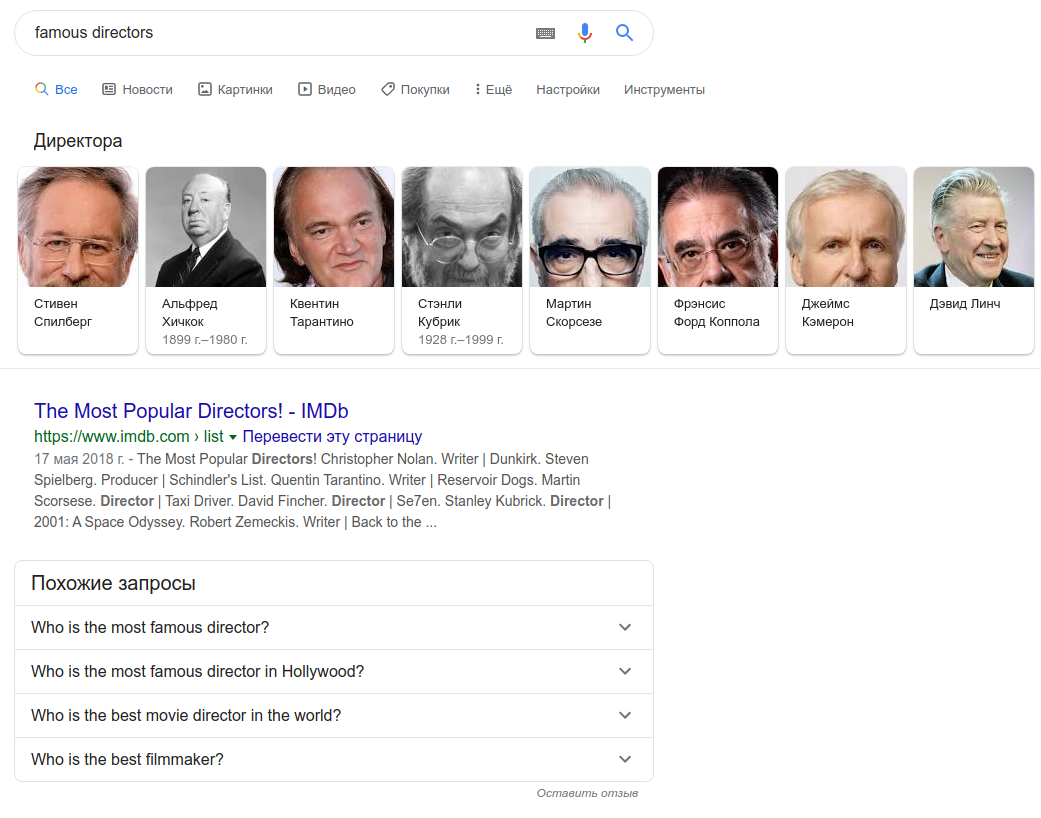
Если вы запросите список – например, «известные режиссеры» — вам покажут «карусель»:
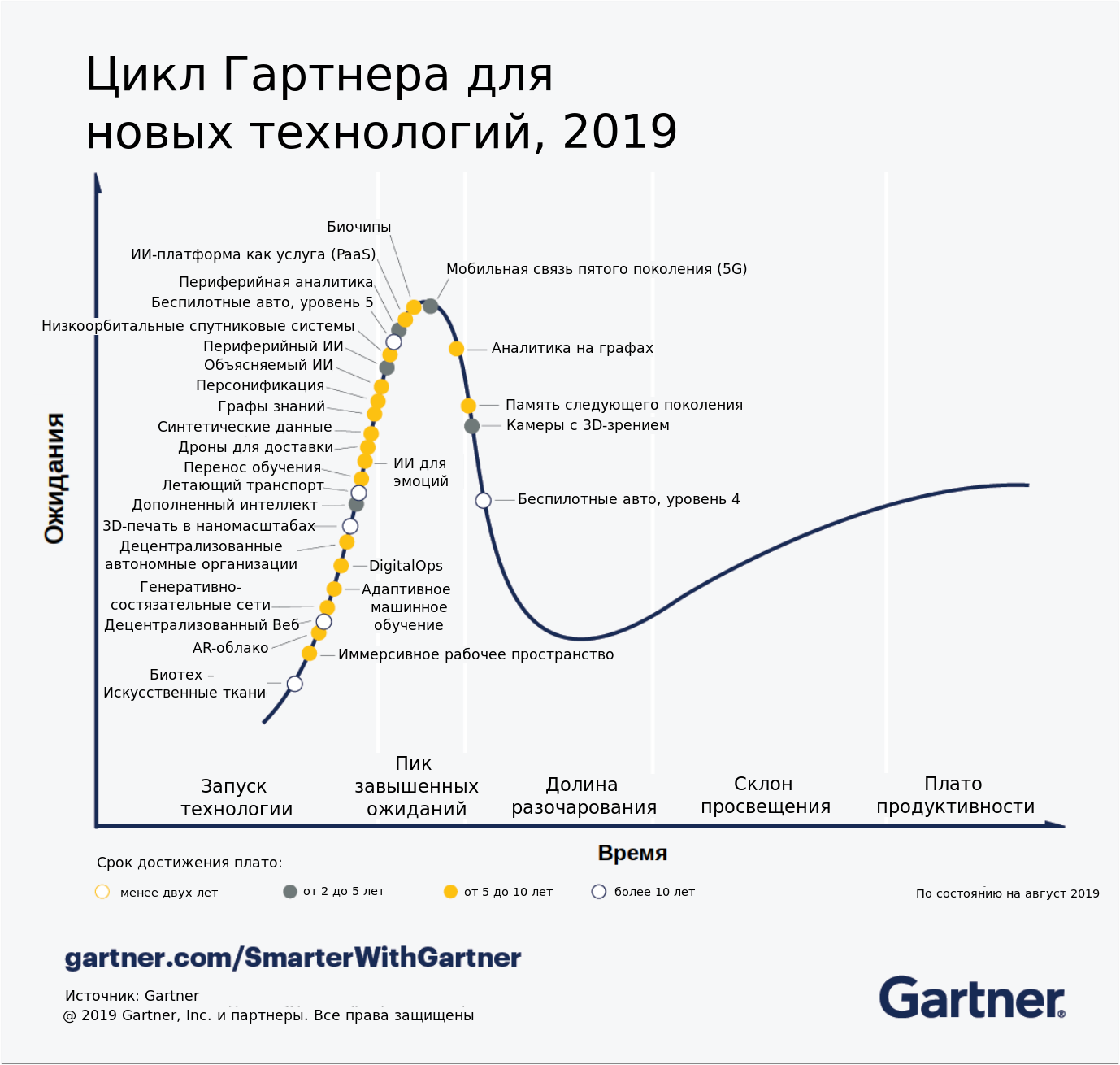
И вот теперь, когда мы прояснили для себя значение каждого из пунктов, можем посмотреть на ту же картинку, но уже на русском языке:
Свободно делитесь ей в соцсетях!

Татьяна Волкова — Автор учебной программы трека по Интернету вещей IT Академии Samsung, специалист по программам корпоративной социальной ответственности Исследовательского центра Samsung
Мы расшифровали, что скрывается за красивыми словами на этом графике, чтобы вы могли тоже говорить на этом языке.

Для начала буквально пару слов, что же это за график. Каждый год в августе консалтинговое агенство Гартнер выпускает отчёт – Gartner Hype Curve. По-русски это «кривая ажиотажа», или, проще говоря – хайпа. 30 лет назад рэперы из группы Public Enemy пели: «Don’t believe the hype». Верить или нет, вопрос личный, но хотя бы знать эти ключевые слова стоит, если вы работаете в сфере технологий и хотите знать мировые тренды.
Это график общественных ожиданий от той или иной технологии. По мнению Гартнера, в идеальном случае технология последовательно проходит 5 стадий: запуск технологии, пик завышенных ожиданий, долина разочарования, склон просвещения, плато продуктивности. Но бывает и так, что она тонет в «долине разочарования» — примеры можете вспомнить сами очень легко, взять те же самые биткоины: изначально попав на пик как «деньги будущего», они быстро скатились вниз, когда стали очевидны недостатки технологии, прежде всего ограничения на количество транзакций и бешеное количество электроэнергии, требуемое на порождение биткоинов (что влечет уже проблемы с экологией). И конечно, нельзя забывать, что график Гартнера – это всего лишь прогноз: тут, например, можно почитать подробную статью, где разбираются самые яркие несбывшиеся предсказания.
Итак, пробежимся по новому графику Гартнера. Технологии разделены на 5 больших тематических групп:
- Продвинутый ИИ и аналитика (Advanced AI and Analytics)
- Постклассические вычисления и коммуникации (Postclassical Compute and Comms)
- Сенсорика и мобильность (Sensing and Mobility)
- «Дополненный» человек (Augmented Human)
- Цифровые экосистемы (Digital Ecosystems)
1. Продвинутый ИИ и аналитика (Advanced AI and Analytics)
Последние лет 10 мы видим звёздный час глубокого обучения (Deep Learning). Эти сети по-настоящему эффективны для своего круга задач. В 2018 году Ян Лекун, Джеффри Хинтон и Йошуа Бенжио получили за открытия в них премию Тьюринга – самую престижную премию, аналог «Нобелевки» в информатике. Итак, основные тренды в этой области, которые вынесены на график:
1.1. Перенос обучения (Transfer Learning)
Вы не обучаете нейронную сеть с нуля, а берёте уже обученную, и назначаете ей другую цель. Иногда для этого нужно переучить часть сети, но не всю сеть, что гораздо быстрее. Например, взяв готовую нейронную сеть ResNet50, обученную на датасете ImageNet1000, вы получите алгоритм, способный классифицировать по изображению очень много разных объектов на очень глубоком уровне (1000 классов по признакам, выработанным 50 слоями нейронной сети). Но вам не нужно обучать всю эту сеть целиком, что заняло бы месяцы.
В онлайне-курсе Samsung «Нейронные сети и компьютерное зрение», для примера, в финальной Kaggle-задаче с классификацией тарелок на чистые и грязные, демонстрируется подход, который за 5 минут даёт вам в распоряжение глубокую нейронную сеть, способную отличать грязные тарелки от чистых, построенную по вышеописанной архитектуре. Исходная сеть не знала, что такое тарелки вообще, она лишь училась отличать птичек от собачек (см. ImageNet).

Источник: онлайн-курс Samsung «Нейронные сети и компьютерное зрение»
Для Transfer Learning нужно знать, какие подходы работают, какие есть готовые базовые архитектуры. В целом, это очень ускоряет появление практических применений машинного обучения.
1.2. Генеративно-состязательные сети (Generative Adversarial Networks, GAN)
Это для тех случаев, когда нам очень сложно сформулировать цель обучения. Чем ближе задача к реальной жизни, тем она понятнее нам («принеси тумбочку»), но тем сложнее её сформулировать как техническое задание. GAN — как раз попытка избавить нас от этой проблемы.
Здесь работают две сети: одна генератор (Generative), другая дискриминатор (Adversarial). Одна сеть учится делать полезную работу (классифицировать картинки, распознавать звуки, рисовать мультики). А другая сеть учится учить ту сеть: у неё есть реальные примеры, и она учится находить заранее неизвестную сложную формулу для сравнения порождений генеративной части сети с объектами реального мира (обучающей выборкой) по действительно важным глубоким признакам: количество глаз, близость к стилю Миядзаки, правильность произношения английского.

Пример результата работы сети для порождения аниме-персонажей. Источник
Но там, конечно же, сложно выстроить архитектуру. Недостаточно просто бросить нейронов, их нужно готовить. И учить приходится неделями. Темой GAN занимаются мои коллеги в Центре искусственного интеллекта Samsung, у них это один из ключевых исследовательских вопросов. Например, вот такая разработка: использование генеративных сетей для синтеза реалистичных фотографий людей с изменяемой позой — например, чтобы создать виртуальную примерочную, или для синтеза лица, что может позволить снизить количество информации, которое нужно хранить или передавать для обеспечения качественной видеосвязи, вещания или защиты персональных данных.
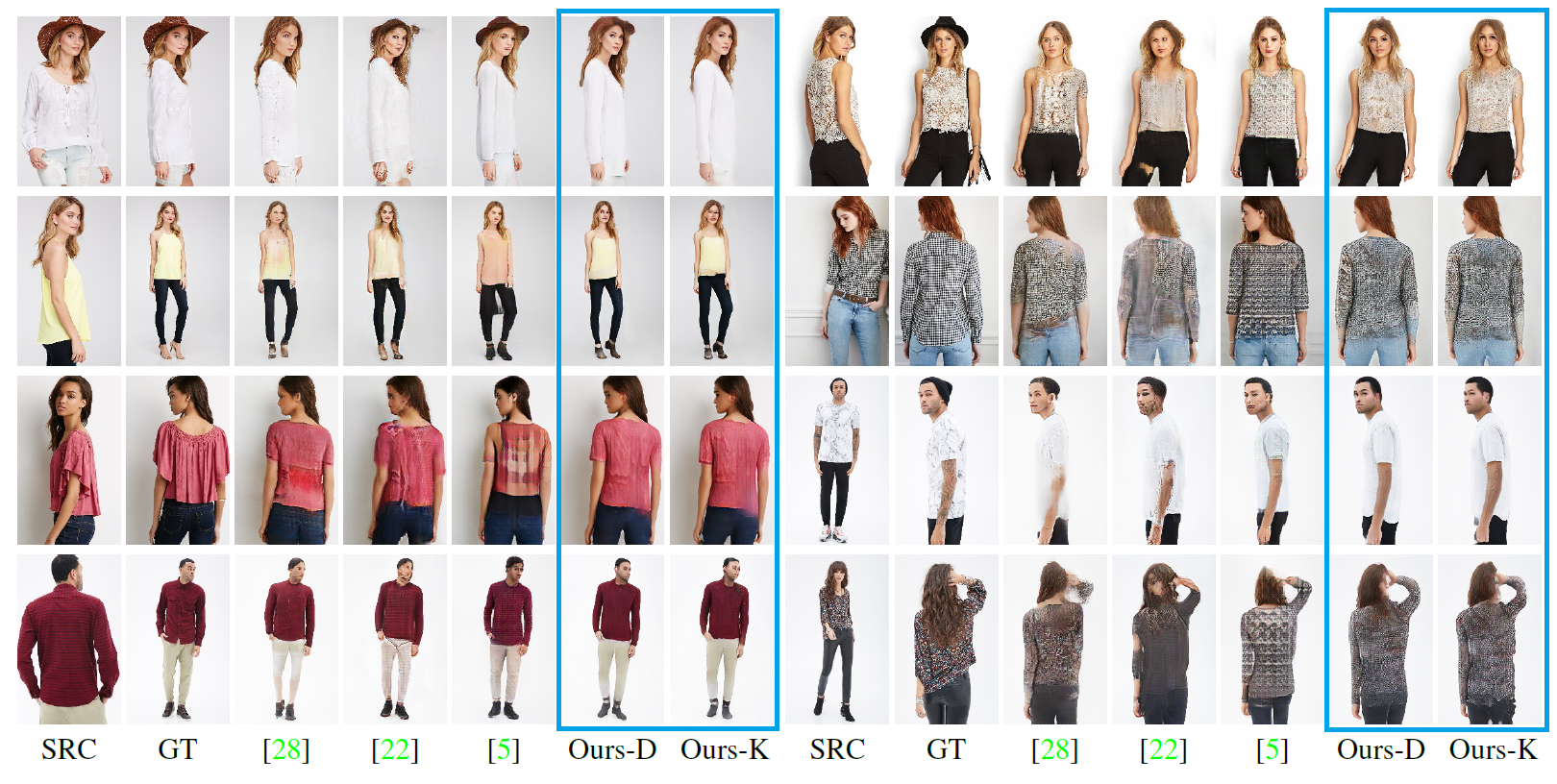
Источник
1.3. Объясняемый ИИ (Explainable AI)
В некоторых редких задачах прогресс в глубоких архитектурах внезапно приблизил возможности глубоких нейросетей к человеческим. Теперь битва идёт за то, чтобы круг таких задач увеличить. Например, робот-пылесос мог бы легко отличить кошку от собаки при лобовой встрече. Но в большинстве жизненных ситуаций он будет неспособен найти кошку, спящую среди белья или мебели (впрочем, как и мы, в большинстве случаев...).
В чем причина успехов глубоких нейронных сетей? Они вырабатывают представление задачи, основанное не на «видимой невооружённым глазом» информации (пикселях фотографии, скачках громкости звука...), а на признаках, полученных после предобработки этой информации несколькими сотнями слоёв нейронной сети. К сожалению, эти взаимосвязи могут также быть бессмысленными, противоречивыми или нести следы несовершенства исходного набора данных. Например, о том, к чему может привести бездумное применение AI в рекрутинге, есть небольшая компьютерная игра Survival Of The Best Fit.

Система для разметки изображений назвала человека, который готовит, женщиной, хотя на картинке на самом деле мужчина (Источник). Это заметили в Институте Виргинии.
Чтобы анализировать сложные и глубокие взаимосвязи, которые мы часто не можем сами сформулировать, и нужны методы Explainable AI. Они организуют признаки глубоких нейросетей так, чтобы после обучения мы могли анализировать выученное сетью внутреннее представление, а не просто полагаться на её решение.
1.4. Периферийная аналитика / AI (Edge Analytics / AI)
Всё, где есть слово Edge, означает буквально следующее: перенос части алгоритмов из облака/сервера на уровень конечного устройства/шлюза. Такой алгоритм будет срабатывать быстрее и не будет нуждаться в подключении к центральному серверу для своей работы. Если вам знакома абстракция «тонкого клиента», то здесь мы этого клиента немного утолщаем.
Это может быть важно для Интернета вещей. К примеру, если станок перегрелся и нуждается в охлаждении, имеет смысл подать сигнал об этом сразу же, на уровне завода, не дожидаясь, пока данные попадут в облако и оттуда уже мастеру смены. Или другой пример: автомобили-беспилотники могут разобраться с дорожной обстановкой самостоятельно, без обращения к центральному серверу.

Источник
Или другой пример, почему это важно с точки зрения безопасности: когда вы на своем телефоне набираете тексты, он запоминает типичные для вас слова, чтобы дальше вам клавиатура телефона их удобно подсказывала – это называется предиктивный ввод текста. Отправлять куда-то в дата-центр все, что вы вводите на клавиатуре, было бы нарушением вашей приватности и попросту небезопасно. Поэтому обучение клавиатуры происходит только в рамках самого вашего устройства.
1.5. ИИ-платформа как услуга (AI PaaS)
PaaS – Платформа-как-услуга – это бизнес-модель, при которой мы получаем доступ к интегрированной платформе, включая её облачное хранилище данных и готовые процедуры. Таким образом, мы можем освободить себя от инфраструктурных задач, и полностью сконцентрироваться на производстве чего-то полезного. Пример платформ PaaS для задач ИИ: IBM Cloud, Microsoft Azure, Amazon Machine Learning, Google AI Platform.
1.6. Адаптивное машинное обучение (Adaptive ML)
Что, если мы позволим искусственному интеллекту адаптироваться… Вы спросите – то есть как?.. Разве он и так не адаптируется к задаче? Проблема вот в чём: каждую такую задачу мы кропотливо оформляем, прежде чем построить для ее решения алгоритм искусственного интеллекта. Вам ответят – оказывается, можно и эту цепочку упростить.
Обычное машинное обучение работает по принципу открытой системы (open-loop): вы готовите данные, придумываете нейронную сеть (или что угодно), обучаете, потом смотрите на несколько показателей, и если вам всё нравится, можно отправить нейросеть в смартфоны – решать задачи пользователей. Но в применениях, где данных очень много и их характер постепенно меняется, нужны другие методы. Такие системы, которые адаптируются и обучают сами себя, организуют в закрытые, самообучающиеся контуры (closed-loop), и они должны работать бесперебойно.
Применения — это может быть потоковая аналитика (Stream Analytics), на основании которой множество бизнесменов принимают решения, или адаптивное управление производством. В масштабе современных применений и с учётом лучше понимаемых рисков для людей, методы, которые составляют решение этой проблемы, все эти методы собираются под общим названием Adaptive AI.
Источник
Глядя на эту картинку, сложно отделаться от ощущения, что футурологов хлебом не корми – дай научить робота дышать…
Постклассические вычисления и коммуникации (Postclassical Compute and Comms)
2.1. Мобильная связь пятого поколения (5G)
Это настолько интересная тема, что сразу отсылаем к нашей статье. Ну а здесь краткая выжимка. 5G за счет повышения частоты передачи данных сделает скорость Интернета нереально быстрой. Коротким волнам сложнее проходить через препятствия, поэтому устройство сетей будет совершенно другим: базовых станций нужно в 500 раз больше.
Вместе со скоростью мы получим новые явления: реалтайм-игры с дополненной реальностью, выполнение сложных задач (таких, как хирургия) через телеприсутствие, предотвращение аварий и сложных ситуаций на дорогах через коммуникацию между машинами. Из более прозаичного: наконец-то перестанет падать мобильный Интернет во время массовых мероприятий, таких как матч на стадионе.

Источник картинки — Reuters, Niantic
2.2. Память следующего поколения (Next-Generation Memory)
Здесь речь идёт о пятом поколении оперативной памяти – DDR5. Samsung анонсировала, что до конца 2019 года появятся продукты на базе DDR5. Ожидается, что новая память будет в два раза быстрее и в два раза более ёмкая с сохранением форм-фактора, то есть мы сможем получить для своего компьютера плашки памяти с ёмкостью до 32Гб. В будущем это будет особенно актуально для смартфонов (новая память будет в версии с низким энергопотреблением) и для ноутбуков (где количество DIMM-слотов ограничено). А ещё машинное обучение требует больших объёмов оперативной памяти.
2.3. Низкоорбитальные спутниковые системы (Low-Earth-Orbit Satellite Systems)
Идея замены тяжелых, дорогих, мощных спутников на рой маленьких и дешевых далеко не нова и появилась ещё в 90-е. Про то, что «Илон Маск скоро будет раздавать всем Интернет со спутника» сейчас не слышал уже только ленивый. Здесь самая известная компания – это Iridium, которая обанкротилась в конце 90-х, но была спасена за счёт Минобороны США (не путать с iRidium – российской системой умного дома). Проект Илона Маска (Starlink) далеко не единственный – в спутниковой гонке участвуют Ричард Брэнсон (OneWeb – 1440 предполагаемых спутников), Boeing (3000 спутников), Samsung (4600 спутников), и другие.
Как обстоит дело в этой области, как там выглядит экономика – читайте в обзоре. А мы ждём первых тестов этих систем первыми пользователями, которые должны состояться уже в следующем году.
2.4. 3D-печать в наномасштабах (Nanoscale 3D Printing)
3D печать, хоть и не вошла в жизнь каждого человека (в форме, обещанной индивидуальной домашней пластиковой фабрики), тем не менее давно вышла из ниши технологий для гиков. Судить можно по тому, что о существовании хотя бы 3D-скульптурных ручек известно любому школьнику, и многие мечтают приобрести себе коробку с полозьями и экструдером для… «просто так» (или уже приобрели).
Стереолитография (лазерные 3D принтеры) позволяют печатать отдельными фотонами: исследуются новые полимеры, для затвердевания которых достаточно двух фотонов. Это позволит в не-лабораторных условиях создавать совершенно новые фильтры, крепления, пружины, капилляры, линзы и… ваши варианты в комментариях! И здесь недалеко до фотополимеризации – только эта технология позволяет «печатать» процессоры и вычислительные схемы. Помимо этого, не первый год существует технология печати графеновых 500-нм трёхмерных структур, но без радикального развития.

Источник
3. Сенсорика и мобильность (Sensing and Mobility)
3.1. Беспилотные автомобили, уровень 4 и 5 (Autonomous Driving Level 4 & 5)
Чтобы не запутаться в терминологии, стоит разобраться в том, какие уровни автономности различают (взято из подробной статьи, к которой мы отсылаем всех заинтересовавшихся):
Уровень 1: Круиз-контроль: помощь водителю в очень ограниченных ситуациях (например – удержание автомобиля на заданной скорости после того, как водитель снял ногу с педали)
Уровень 2: Ограниченная помощь с рулением и торможением. Водитель должен быть готов взять управление на себя практически мгновенно. Его руки находятся на руле, взгляд направлен на дорогу. Это то, что уже есть в Tesla и General Motors.
Уровень 3: Водитель больше не должен постоянно следить за дорогой. Но должен оставаться начеку и быть готов взять управление на себя. Это то, чего пока нет у имеющихся в продаже автомобилей. Все существующие на настоящий момент – на уровне 1-2.
Уровень 4: Настоящий автопилот, но с ограничениями: только поездки в известной области, которая тщательно картографирована и в целом известна системе, и при определенных условиях: например, в отсутствие снега. Такие прототипы есть у Waymo и General Motors, и они планируют запускать их в нескольких городах и тестировать в реальной обстановке. У «Яндекса» есть тестовые зоны беспилотного такси в Сколково и Иннополисе: поездка происходит под присмотром инженера, сидящего на месте пассажира; к концу года компания планирует расширить парк до 100 беспилотных машин.
Уровень 5: Полное автоматическое вождение, полная замена живого водителя. Таких систем не существует, и вряд ли они появятся в ближайшие годы.
Насколько реалистично всё это увидеть в обозримое время? Здесь хотелось бы переадресовать читателя к статье «Почему запустить роботакси к 2020 году, как обещает Tesla, невозможно». Это отчасти связано с отсутствием связи 5G: имеющихся скоростей 4G недостаточно. Отчасти с очень высокой стоимостью автономных машин: они пока нерентабельны, непонятна бизнес-модель. Словом, здесь «всё сложно», и неслучайно Гартнер пишет, что прогноз массового внедрения Уровня 4 и 5 – не раньше, чем через 10 лет.
3.2. Камеры с 3D-зрением (3D Sensing Cameras)
Восемь лет назад игровой контроллер Microsoft Kinect наделал шуму, предложив доступное и сравнительно недорогое решение для 3D-зрения. С тех пор физкультурно-танцевальные игры с Кинектом пережили свой недолгий взлёт и упадок, зато 3D-камеры стали использоваться в промышленных роботах, беспилотных автомобилях, мобильных телефонах для идентификации по лицу. Технология стала дешевле, компактнее и доступнее.

В телефоне Samsung S10 стоит времяпролетная (Time-of-Flight) камера, которая измеряет расстояние до объекта – для упрощения фокусировки. Источник
Если вас заинтересовала эта тема, то переадресуем к очень хорошему подробному обзору камер глубины: часть 1, часть 2.
3.3. Дроны для доставки небольших грузов (Light Cargo Delivery Drones)
В этом году Amazon наделала шуму, когда показала на выставке новый летающий дрон, способный перевозить небольшие грузы до 2 кг весом. Для города, с его пробками, это кажется идеальным решением. Посмотрим, как эти дроны проявят себя уже в самом ближайшем будущем. Пожалуй, здесь стоит включить осторожный скепсис: есть множество проблем, начиная с возможности легкой кражи дрона, и заканчивая законодательными ограничениями на БПЛА. Amazon Prime Air существует уже шесть лет, но по-прежнему находится на этапе тестирования.

Новый дрон Amazon, показанный этой весной. Что-то есть в нем от «Звездных войн». Источник
Помимо Amazon, есть и другие игроки на этом рынке (есть подробный обзор), но ни одного готового продукта: всё – на стадии тестирования и маркетинговых акций. Отдельно стоит отметить достаточно интересные узкоспециализированные медицинские проекты в Африке: доставка донорской крови в Гане (14 000 доставок, компания Zipline) и Руанде (компания Matternet).
3.4. Летающий автономный транспорт (Flying Autonomous Vehicles)
Здесь сложно сказать что-то определённое. По мнению Гартнера, это появится не ранее, чем через 10 лет. В общем-то, здесь все те же самые проблемы, что и в беспилотных автомобилях, только они приобретают новое измерение — вертикальное. О своих амбициях построить летающее такси заявляют Porsche, Boeing, Uber.
3.5. Облако дополненной реальности (AR Cloud)
Постоянная цифровая копия реального мира, позволяющая создать новый слой реальности, общий для всех пользователей. Если говорить более техническим языком, то речь о том, чтобы сделать открытую облачную платформу, в которую разработчики могли бы интегрировать свои AR-приложения. Модель монетизации понятна, это некий аналог Steam. Идея настолько укоренилась, что теперь уже некоторые считают, что AR без облака попросту бесполезно.
Как это может выглядеть в будущем, нарисовано в небольшом ролике. Выглядит как очередная серия «Чёрного зеркала»:
Ещё можно почитать в статье-обзоре.
4. «Дополненный» человек (Augmented Human)
4.1. ИИ для эмоций (Emotion AI)
Как измерить, симулировать и среагировать на человеческие эмоции? Одни из клиентов здесь – компании, производящие голосовых ассистентов наподобие Amazon Alexa. По-настоящему вжиться в дома они смогут, если научатся распознавать настроение: понять причину недовольства пользователя, попробовать исправить ситуацию. Вообще в контексте гораздо больше информации, чем в самом сообщении. А контекст – это и выражение лица, и интонация, и невербальное поведение.
Из других практических применений: анализ эмоций во время собеседования на работе (по видеоинтервью), оценивание реакции на рекламные ролики или иной видеоконтент (улыбки, смех), помощь при обучении (например, для самостоятельных практик в искусстве публичных выступлений).
На эту тему сложно высказаться лучше, чем автор 6-минутной короткометражки Stealing Ur Feeling. В остроумно и стильно сделанном ролике показано, как можно измерять наши эмоции в маркетинговых целях, и из сиюминутных реакций вашего лица узнать: любите ли вы пиццу, собак, Канье Уэста, и даже каков ваш уровень дохода и примерный IQ. Перейдя на сайт фильма по ссылке выше, вы становитесь участником интерактивного видео с использованием встроенной камеры вашего ноутбука. Фильм уже был показан на нескольких кинофестивалях.
Источник
Есть даже такое интересное исследование: как распознавать сарказм в тексте. Взяли твиты с хэштегом #сарказм и сделали обучающую выборку из 25 000 твитов с сарказмом и 100 000 обычных твитов обо всем на свете. Применили библиотеку TensorFlow, обучили систему, вот результат:

Источник
Поэтому теперь, если вы не уверены насчет вашего коллеги или приятеля – сказал он вам что-то всерьез или с сарказмом, — вы можете воспользоваться уже обученной нейросетью!
4.2. Дополненный интеллект (Augmented Intelligence)
Автоматизация интеллектуального труда при помощи методов машинного обучения. Казалось бы, ничего нового? Но здесь важна сама формулировка, тем более, что она совпадает по аббревиатуре с Artificial Intelligence. Это отсылает нас к полемике о «сильном» и «слабом» ИИ.
Сильный ИИ – это тот самый искусственный интеллект из фантастических фильмов, который полностью эквивалентен человеческому разуму и осознает себя как личность. Такого ещё не существует и непонятно, будет ли существовать вообще.
Слабый ИИ – это не самостоятельная личность, а помощник-ассистент человека. Он не претендует на человекоподобное мышление, а просто умеет решать информационные задачи, например, определять, что изображено на картинке или переводить текст.

Источник
В этом смысле Augmented Intelligence – это в чистом виде «слабый ИИ», и формулировка представляется удачной, поскольку не вносит путаницы и соблазна увидеть здесь тот самый «сильный ИИ», о котором все мечтают (или боятся, если вспомнить многочисленные рассуждения о «восстании машин»). Используя выражение Augmented Intelligence, мы сразу же как бы становимся героями другого фильма: из научной фантастики (наподобие «Я, робот» Азимова) мы попадаем в киберпанк («аугментациями» в этом жанре называют всевозможные имплантанты, расширяющие возможности человека).
Как сказали Эрик Бриньольфссон и Эндрю МакАффи: «За следующие 10 лет произойдет вот что. Не ИИ заменит менеджеров, а те менеджеры, которые используют ИИ, заменят тех, которые еще не успели»
Примеры:
- Медицина: Стэнфордский университет разработал алгоритм, который справляется с задачей распознавания патологий на рентгене грудной клетки в среднем настолько же успешно, как и большинство врачей
- Образование: помощь ученику и учителю, анализ отклика учеников на материалы, построение индивидуальной траектории обучения.
- Бизнес-аналитика: предобработка данных, по статистике, занимает 80% времени исследователя, и только 20% — сам эксперимент
4.3. Биочипы (Biochips)
Это любимая тема всех киберпанк-фильмов и книг. Вообще чипирование домашних животных – практика не новая. Но теперь эти чипы стали вживлять ещё и людям.
В данном случае хайп, скорее всего, связан с нашумевшим случаем в американской компании Three Square Market. Там работодатель начал предлагать вживлять под кожу чипы в обмен за вознаграждение. Чип позволяет открывать двери, логиниться в компьютеры, покупать перекусы в автомате – то есть такая универсальная карточка сотрудника. При этом такой чип служит именно как карточка идентификации, в нем нет GPS-модуля, поэтому и отследить никого по нему невозможно. А если человек хочет удалить чип из руки, это занимает 5 минут при помощи доктора.
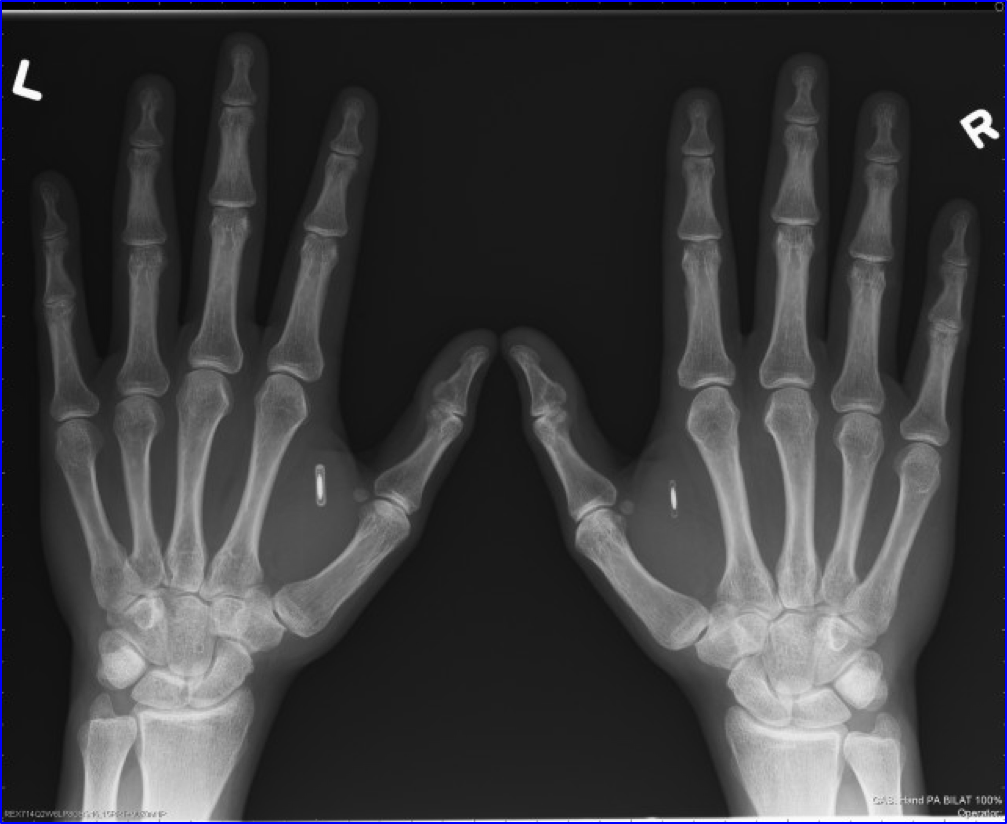
Чипы обычно вживляются между большим и указательным пальцем. Источник
Читайте подробную статью о состоянии дел с чипированием в мире.
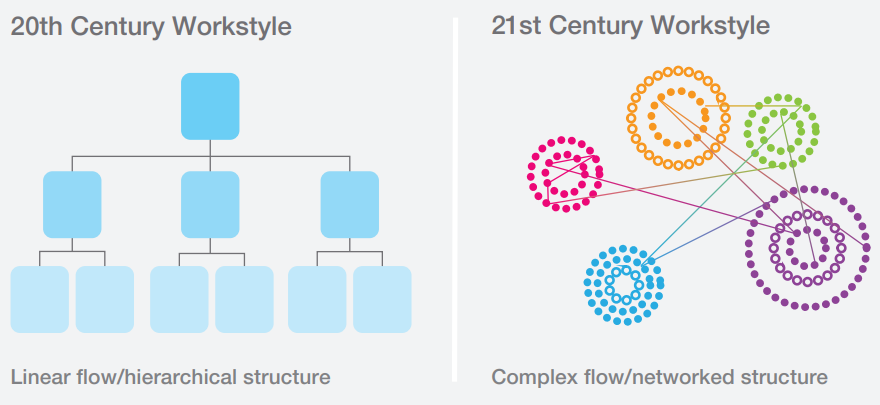
4.4. Иммерсивное рабочее пространство (Immersive Workspace)
«Иммерсивный» — ещё одно новое слово, от которого просто некуда деться. Оно повсюду. Иммерсивный театр, выставка, кино. Что же имеется в виду? Иммерсивность – это создание эффекта погружения, когда теряется граница между автором и зрителем, виртуальным и реальным миром. Применительно к рабочему месту, надо полагать, это означает стирание границы между исполнителем и инициатором и поощрение сотрудников к более активной позиции через переформатирование окружающей его среды.
Раз уж у нас повсюду теперь Agile, гибкость, тесное взаимодействие – то и рабочие места должны быть максимально легко конфигурируемы, должны поощрять групповую работу. Экономика диктует свои условия: становится больше временных сотрудников, стоимость аренды офисных помещений растет, а в условиях конкурентного рынка труда в IT компании стараются повышать удовлетворение сотрудников от работы, создавая рекреационные зоны и прочие преимущества. И всё это отражается на дизайне рабочих мест.
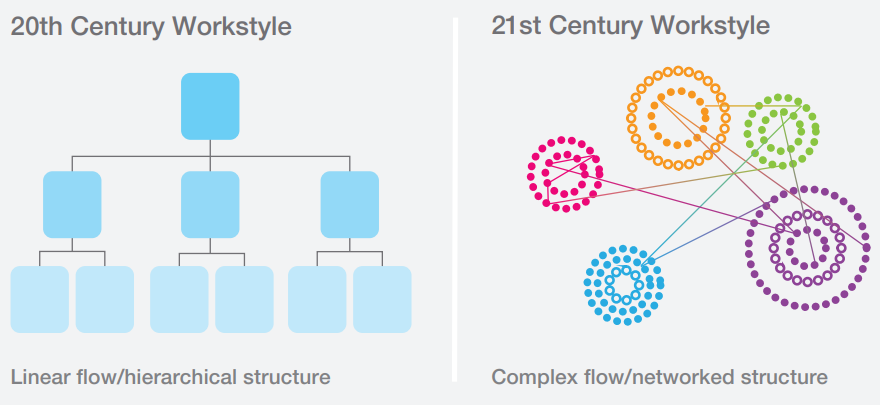
Из отчета Knoll
4.5. Персонификация (Personification)
Все знают, что такое персонализация в рекламе. Это когда вы сегодня обсуждаете с коллегой, что в помещении что-то воздух суховат, и надо бы купить в офис увлажнитель, а назавтра видите у себя в соцсети рекламу – «купите увлажнитель воздуха» (реальный случай, произошедший со мной).

Источник
Персонификация же, по определению Гартнера – это ответ на возрастающее беспокойство пользователей по поводу использования их персональных данных в целях рекламы. Цель – выработать подход, при котором нам будет показываться реклама, соответствующая контексту, в котором мы находимся, а не нам лично. Например, наша локация, тип устройства, время суток, погодные условия – это то, что не нарушает наших персональных данных, и мы не чувствуем неприятное ощущение «слежки».
О разнице между этими двумя понятиями, читайте заметку Эндрю Франка в блоге на сайте Гартнера. Тут настолько тонкое различие и настолько похожие слова, что вы, не зная разницы, рискуете долго спорить с собеседником, не подозревая, что в общем-то, оба правы (и это тоже реальный случай, произошедший с автором).
4.6. Биотех – Искусственные ткани (Biotech – Cultured or Artificial Tissue)
Это, в первую очередь, идея выращивания искусственного мяса. Одновременно несколько команд по всему миру заняты разработкой лабораторного «Мяса 2.0» – ожидается, что оно станет дешевле обычного, и на него переключатся фастфуды, а затем и супермаркеты. Из инвесторов в эту технологию – Билл Гейтс, Сергей Брин, Ричард Брэнсон и другие.

Источник
Причины, почему всех так интересует искусственное мясо:
- Глобальное потепление: выброс метана с ферм. Это 18% от мирового объёма газов, влияющих на климат.
- Рост численности населения. Потребность в мясе растет, и накормить всех натуральным мясом не получится – оно попросту дорогое.
- Нехватка места. 70% лесов Амазонки уже вырублены ради пастбищ.
- Этические соображения. Есть те, для кого это важно. Зоозащитная организация PETA уже предлагала приз в 1 миллион долларов тому ученому, который выпустит на рынок искусственное куриное мясо.
Подмена настоящего мяса на соевое – это частичное решение, ведь люди хорошо чувствуют разницу во вкусе и текстуре, и вряд ли откажутся от стейка в пользу сои. Так что необходимо настоящее, именно органически выращенное мясо. Сейчас, к сожалению, искусственное мясо обходится слишком дорого: от 12$ за килограмм. Это связано со сложным техпроцессом выращивания такого мяса. Читайте обо всем этом статью.
Если говорить о других кейсах выращивания тканей – уже в медицине — то интересна тема с искусственными органами: например, «пластырь» для сердечной мышцы, напечатанный специальным 3D-принтером. Известны истории наподобие выращенного искусственно мышиного сердца, но в целом всё пока не выходит за рамки клинических испытаний. Так что Франкенштейна в ближайшие годы мы вряд ли увидим.
Здесь Гартнер очень осторожен в оценках, видимо держа в уме свое провалившееся предсказание 2015 года о том, что в 2019 году 10% населения развитых стран будут иметь 3D-напечатанное медицинское устройство-имплантант. Поэтому и обозначает время выхода на плато продуктивности – не менее 10 лет.
5. Цифровые экосистемы (Digital Ecosystems)
5.1. Децентрализованный Веб (Decentralized Web)
Это понятие тесно связано с именем изобретателя веба, лауреатом премии Тьюринга, сэра Тима Бёрнерса-Ли. Для него всегда были важны вопросы этики в информатике и важна коллективная сущность Интернета: закладывая основы гипертекста, он был убежден, что сеть должна работать как паутина, а не как иерархия. Так и было на раннем этапе развития сети. Однако с ростом Интернета его структура по целому ряду причин стала централизоваться. Оказалось, что доступ к сети для целой страны можно легко перекрыть при помощи всего нескольких провайдеров. А данные пользователей превратились в источник силы и дохода интернет-компаний.
«Интернет уже децентрализован, — говорит Бёрнерс-Ли. — Проблема в том, что доминирует одна поисковая система, одна большая социальная сеть, одна платформа для микроблогинга. У нас нет технологических проблем, но есть социальные».
В своем открытом письме к 30-летию World Wide Web создатель Веба очертил три основные проблемы Интернета:
- Целенаправленное причинение вреда, такое как спонсируемые государством хакерские атаки, криминал и онлайн-харассмент
- Само устройство системы, которое в ущерб пользователю создает почву для таких механизмов, как: финансовое поощрение кликбейта и вирусное распространение ложной информации
- Непреднамеренные последствия дизайна системы, которые ведут к конфликтам и снижению качества онлайн-дискуссии
И у Тима Бернерса-Ли уже есть ответ, на каких принципах мог бы базироваться «Интернет здорового человека», лишенный проблемы номер 2: «Для многих пользователей единственной моделью взаимодействия с вебом остается доход с рекламы. Даже если люди напуганы тем, что происходит с их данными, они согласны пойти на сделку с маркетинговой машиной за возможность получать контент бесплатно. Представьте себе мир, в котором плата за товары услуги легка и приятна для обеих сторон». Из вариантов того, как это может быть устроено: музыканты могут продавать свои записи без посредников в виде iTunes, а новостные сайты — использовать систему микроплатежей за чтение одной статьи, вместо того чтобы зарабатывать на рекламе.
В качестве экспериментального прототипа такого нового Интернета, Тим Бернерс-Ли запустил проект SOLID, суть которого в том, что вы храните свои данные в «поде» — хранилище информации, и можете предоставлять эти данные сторонним приложениям. Но в принципе, вы сами – хозяева своих данных. Всё это тесно связано с понятием пиринговых сетей, то есть ваш компьютер не только запрашивает сервисы, но и предоставляет их, чтобы не полагаться на один сервер в качестве единственного канала.
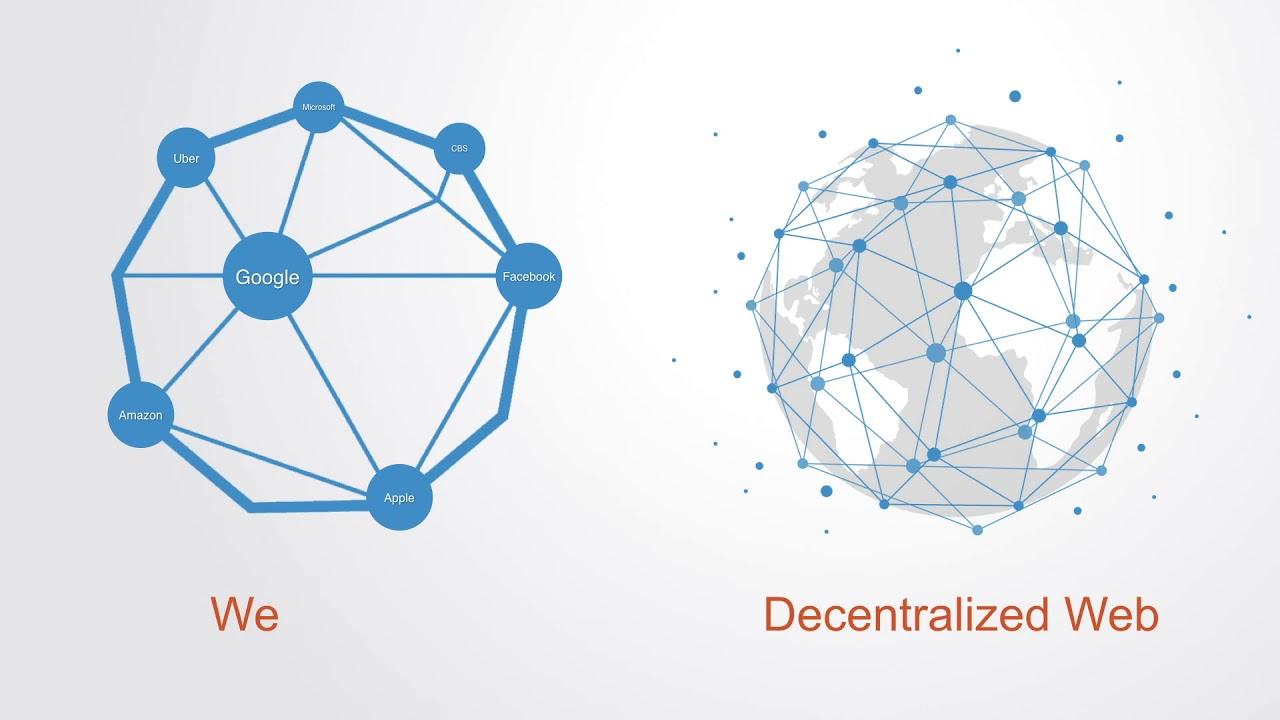
Источник
5.2. Децентрализованные автономные организации (Decentralized Autonomous Organizations)
Это организация, которая управляется правилами, записанными в виде компьютерной программы. Её финансовая деятельность происходит на базе блокчейна. Цель создания таких организаций – устранить государство из роли посредника и создать общую доверенную среду для контрагентов, которой не владеет никто единолично, а владеют все вместе. То есть в теории, это должно, если идея приживется, упразднить нотариусов и другие привычные институты верификации.
Самым известным примером такой организации была ориентированная на венчурный бизнес The DAO, которая в 2016 году собрала 150 миллионов долларов, из которой 50 моментально украли через легальную «дырку» в правилах. Тут же наступила сложная дилемма: или откатить назад и вернуть деньги, или признать, что изъятие денег было легально, ведь оно никоим образом не нарушало правил платформы. В итоге, чтобы вернуть деньги инвесторам, создателям пришлось уничтожить The DAO, переписав блокчейн и нарушив его основной принцип – неизменяемость.

Комикс про Ethereum (слева) и The DAO (справа). Источник
Вся эта история испортила репутацию самой идеи DAO. Тот проект делался на базе криптовалюты Ethereum, в следующем году ожидается версия Эфир 2.0 – возможно, авторы (среди которых известный Виталик Бутерин) учтут ошибки и покажут что-то новое. Наверное, поэтому Gartner и поместил DAO на восходящую линию.
5.3.Синтетические данные (Synthetics Data)
Для обучения нейросетей нужны большие объёмы данных. Размечать данные вручную – огромный труд, который может быть выполнен только человеком. Поэтому можно создавать искусственные наборы данных. Например, те же самые коллекции человеческих лиц на сайте https://generated.photos. Создаются они при помощи GAN – алгоритмов, о которых было уже сказано выше.

Эти лица не принадлежат людям. Источник
Большой плюс таких данных – в том, что не возникает юридических затруднений в их использовании: согласие на обработку персональных данных выдавать некому.
5.4.Digital Ops
Суффикс «Ops» стал невероятно модным с тех пор, как в нашей речи прижилось DevOps. Теперь о том, что такое DigitalOps – это просто обобщение DevOps, DesignOps, MarketingOps… Вы ещё не заскучали? Короче говоря, это перенос подхода, принятого в DevOps, из сферы программного обеспечения на все остальные стороны бизнеса – маркетинг, дизайн и т.д.

Источник
Идеей DevOps было убрать барьеры между собственно Development (разработкой) и Operations (бизнес-процессами), через создание общих команд, где и программисты, и тестировщики, и безопасники, и администраторы; внедрение определенных практик: непрерывная интеграция, инфраструктура как код, сокращение и усиление цепочек обратной связи. Цель была – ускорить вывод продукта на рынок. Если вы подумали, что это похоже на Agile, вы правильно подумали. Теперь мысленно перенесите этот подход из сферы разработки ПО к разработке вообще – и вы поняли, что такое DigitalOps.
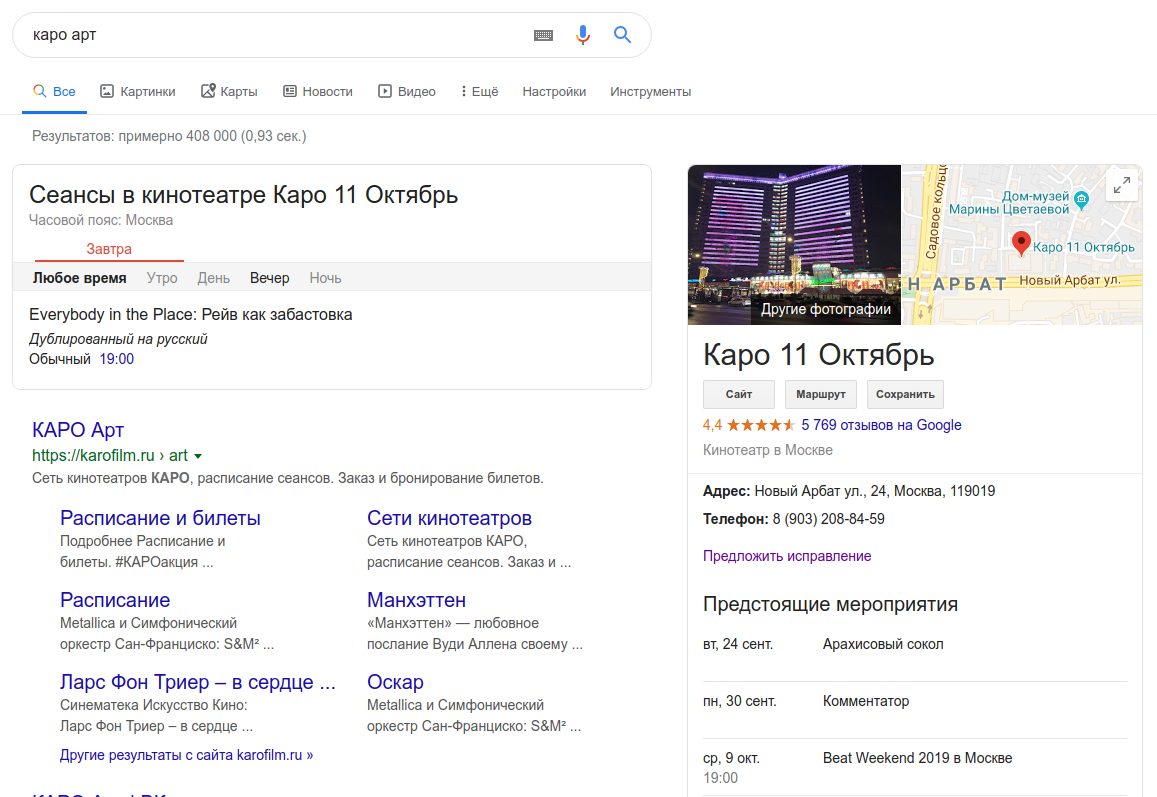
5.5. Графы знаний (Knowledge Graphs)
Программный способ моделировать область знаний, в том числе — при помощи алгоритмов машинного обучения. Граф знаний строится поверх существующих баз данных, чтобы связать воедино всю информацию: как структурированную (список событий или персон), так и неструктурированную (текст статьи).
Самый простой пример – это та карточка, которую вы можете увидеть в поисковой выдаче Google. Если вы ищете какую-то персону или учреждение, то вы увидите справа карточку:
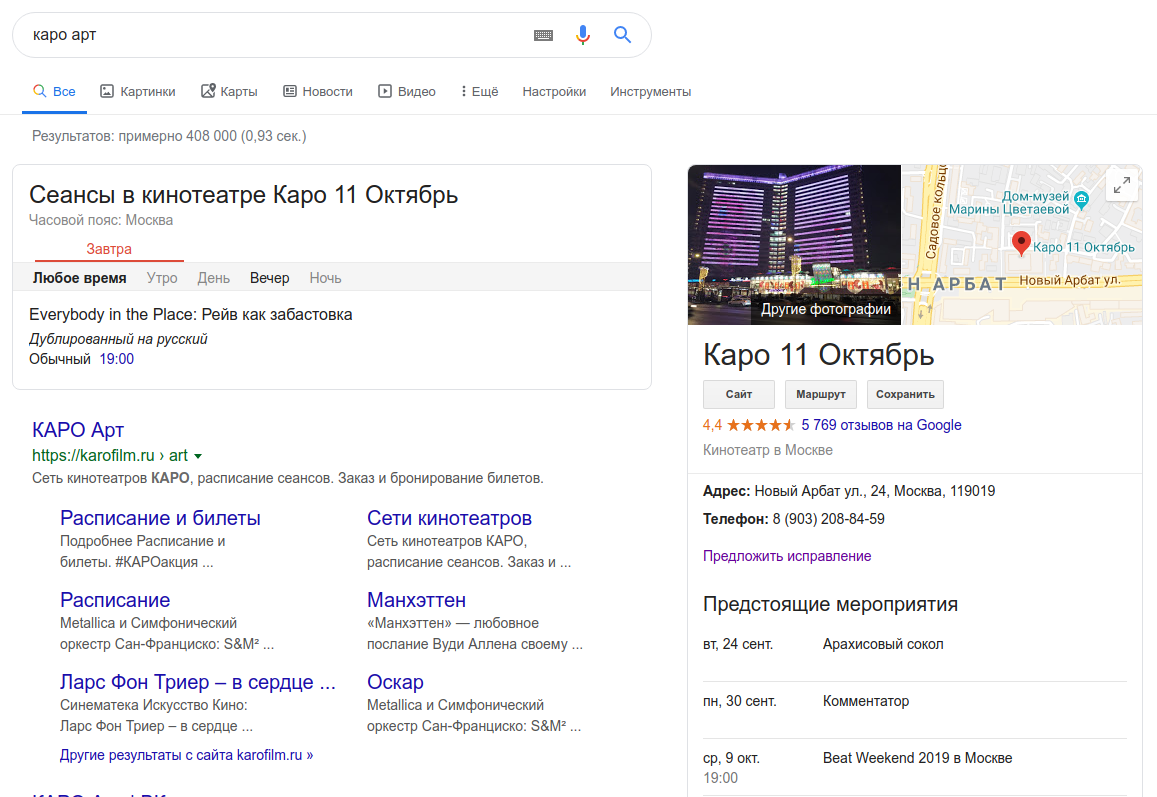
Обратите внимание, что «Предстоящие мероприятия» — это не копия информации с Google-карт, а интеграция расписания с Яндекс.Афиши: вы легко увидите это, если кликнете по событиям. То есть это объединение нескольких источников данных воедино.
Если вы запросите список – например, «известные режиссеры» — вам покажут «карусель»:
Бонус для тех, кто дочитал до конца
И вот теперь, когда мы прояснили для себя значение каждого из пунктов, можем посмотреть на ту же картинку, но уже на русском языке:
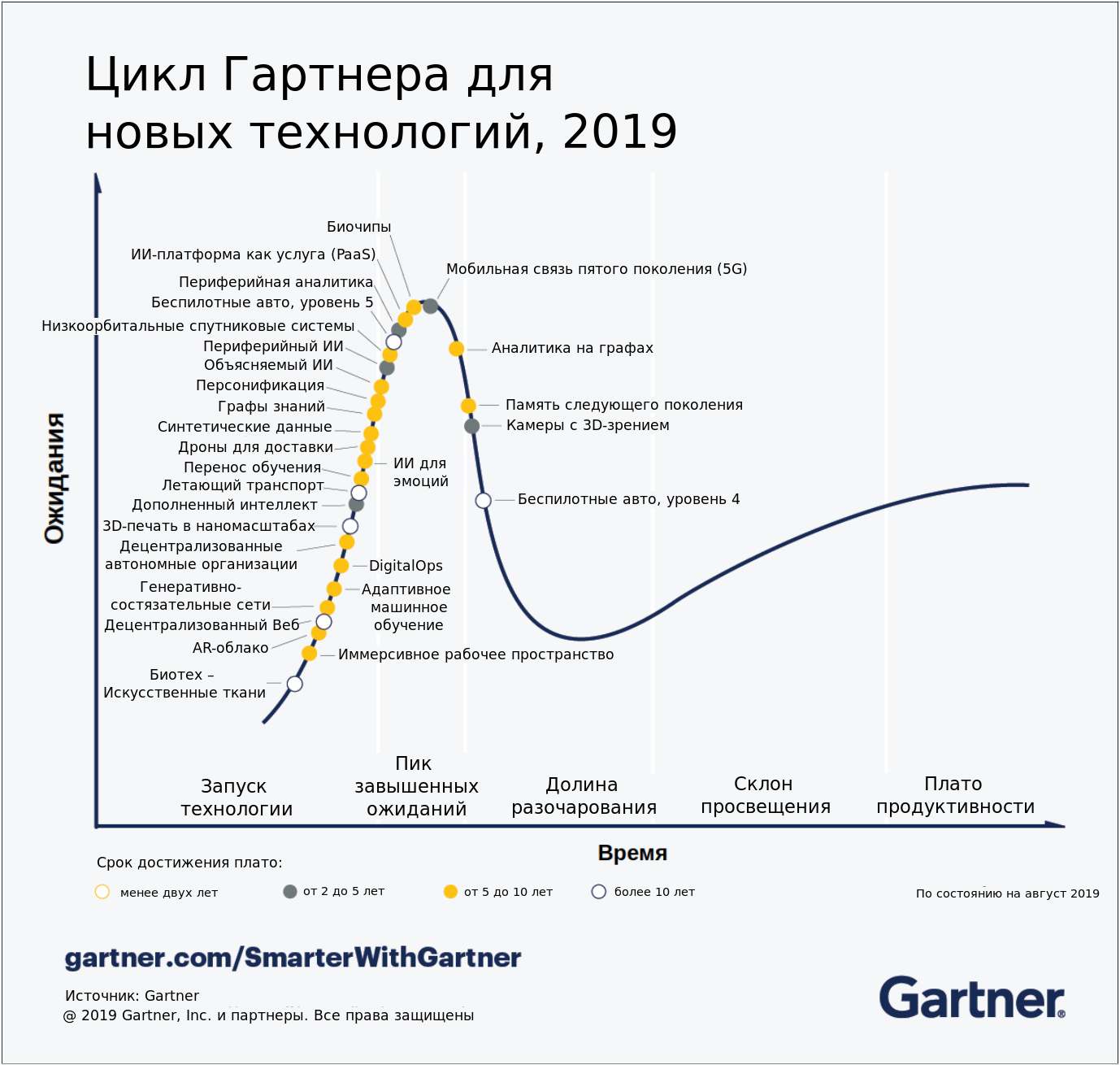
Свободно делитесь ей в соцсетях!

Татьяна Волкова — Автор учебной программы трека по Интернету вещей IT Академии Samsung, специалист по программам корпоративной социальной ответственности Исследовательского центра Samsung
