Мы продолжаем цикл статей о SAP HANA Data Management Suite – гибриде локальных и облачных технологий, который включает в себя четыре компонента-продукта: SAP Data Hub, SAP HANA, SAP Enterprise Architecture Designer и SAP Cloud Platform Big Data Services.
Сочетание этих решений позволяет создать целостную структуру управления данными с следующими функциями:
Но сегодня мы поговорим про «ядро» этой системы – платформу SAP HANA.
SAP проводил и продолжает проводить исследования, инвестирует большие ресурсы и средства в развитие направления по обработке данных. В результате появилась платформа SAP HANA – High-Performance Analytic Appliance. У нашей компании уже был накоплен многолетний и по-своему уникальный опыт по разработке технологий и сервисов для бизнеса – и в SAP применили его при создании платформы для бизнеса для realtime обработки данных. В результате появилась SAP HANA, которая стала основой и ядром для разработки и построения интеллектуальных предприятий нового типа (intelligent enterprise). Платформу используют для разработки приложений как внутри SAP, так и наши клиенты и партнёры.

SAP HANA – это многоцелевое решение для хранения и обработки информации. Одна из особенностей SAP HANA – это встроенный механизм вычислений, который позволяет переносить выполнение операций по планированию с уровня приложений на уровень базы данных SAP HANA. С помощью современной архитектуры аппаратной платформы вычисления проходят эффективнее – вся «лавина» обрабатываемых данных разбивается на строго определённое количество потоков, число которых равно общему количеству ядер платформы. Такой подход позволяет максимально эффективно использовать вычислительную мощность каждого ядра каждого процессора.
SAP HANA также предоставляет технологии для хранения и обработки данных in-memory. SAP HANA как база данных позволяет хранить данные в построчном и в поколоночном виде. Технология хранения и обработки данных in-memory обеспечивает быструю обработку транзакций, а вместе технологией анализа данных Calculation View гарантирует высокое быстродействие при выполнении аналитических запросов.
Аналитики Forrester начали использовать новое понятие – «транслитическая база данных». По их определению, такая платформа «поддерживает многие типы использования, включая информацию в режиме реального времени, машинное обучение, поточную аналитику и экстремальную транзакционную обработку».
В недавнем отчёте Forrester говорится следующее: «SAP HANA – это shared-nothing (без общего использования ресурсов), in-memory платформа. Это основа платформы SAP для транзакций и аналитики по данным, она поддерживает множество сценариев применения: приложения для обработки данный в режиме реального времени, аналитика, транслитические приложения, системы глубокой и продвинутой аналитики. Предприятия используют платформу для организации in-memory витрин данных, для работы с realtime-хранилищем данных SAP Business Warehouse, а также при работе с SAP S/4HANA и SAP Business Suite».
Транслитические платформы подходят для поддержки realtime-приложений и сервисов: для торговли акциями, обнаружения мошенничества, борьбы с терроризмом, мониторинга здоровья пациентов, анализа данных от различных сенсоров, мониторинга землетрясений и много другого. С помощью транслитической платформы приложения могут обмениваться данными в реальном времени, обеспечивают согласованность и точность информации, хранимой на предприятии.
Ещё одна сфера применения SAP HANA – это поддержка машинного обучения, что позволяет применять к данным сложные аналитические модели для более точного прогнозирования операций, бизнес-процессов, поведения клиентов и т.д.
Как SAP HANA поддерживает данную функциональность?
Начнём с сервиса баз данных. Если рассматривать HANA с точки зрения архитектуры и технологий, то здесь применяются два способа хранения данных – построчный и поколоночный.
Построчное хранение данных в таблице позволяет обеспечивать высокую скорость записи данных. Если вы хотите добавить новую строку в таблицу, то вам достаточно найти свободное место в памяти для этой строки и записать туда новые данные. Однако при построчном хранении возникает проблема с анализом данных: необходимо использовать индексирование или материализованное представление данных в форме, которая будет удобна для анализа. При этом индексирование приводит к задержкам из-за того, что необходимо дополнительное время на перестроение индекса, материализацию данных в ином формате в процессе вставки строки.
Если же данные хранятся поколоночно, то для добавления новой строки необходимо потратить время на разнесение значений строки по колонкам, затем – подождать, пока данные будут разнесены в разные места в памяти. Всё это приводит к снижению производительности во время записи данных.
База данных с поколоночным хранением позволяет значительно быстрее обрабатывать запросы, потому что в этом случае данные из запрошенных колонок расположены в памяти компактно и сжато. Т.е. при запросе нет необходимости сканировать всю таблицу – достаточно просмотреть только колонки, используемые в запросе. Такая база данных оптимизирована для чтения, а поколоночное хранение информации позволяет организовывать данные в оперативной памяти определенным образом, с использованием группировки. При этом подходе можно с большей эффективностью использовать различные техники компрессии, что приводит к многократному сжатию исходной информации.
Для решения этой проблемы был разработан подход Unified Tables, который обеспечивает высокую скорость чтения и записи данных в таблицу поколоночного хранения. Такой механизм позволяет быстро осуществлять транзакции (то есть запись новых строк), анализировать данные с высокой скоростью за счёт поколоночного хранения в сжатом виде, параллельной обработки данных, а также хранить все данные в оперативной памяти (in-memory).
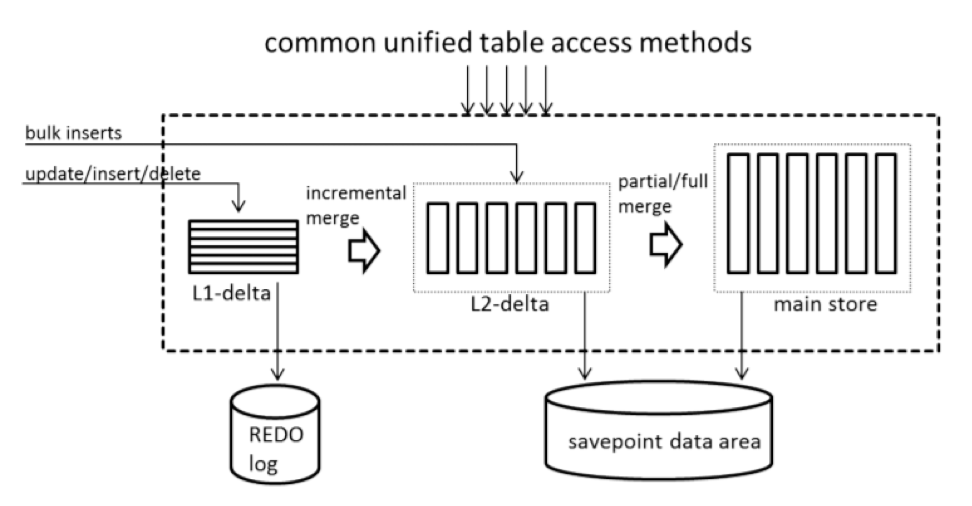
При проведении записи изменения не сразу вносятся в основное место хранения таблиц. Вместо этого все правки заносятся в отдельную структуру данных – дельта-хранилище (на картинке L1-delta). Здесь данные хранятся в оптимизированном для записи формате. Когда необходимо перенести изменения из дельта-хранилища, то запускается специальный процесс Delta merge – слияние дельты. Сначала данные из L1-delta преобразуются в поколоночный формат в L2-delta, а затем объединяются с основным хранением данных (main store). А для механизма чтения данных все три области хранения информации (L1-delta, L2-delta и main store) предоставляют данные в целостном виде. Благодаря этому процессу получается обеспечить высокую скорость записи и анализа данных.
Одно из существенных преимуществ SAP HANA – все расчеты агрегированных данных производятся непосредственно при формировании аналитического запроса и выводятся сразу в виде результата. Возможности по хранению детальных или исходных данных в оперативной памяти (а не агрегированных значений) позволяют отказаться от предварительного расчета и хранения агрегатных таблиц, которые являются неотъемлемой частью классических аналитических систем.
SAP HANA также поддерживает различные внутренние языки программирования: R – для создания прогнозных моделей, SQL Script – для написания логики вычислений. На уровне сервера приложений XSA, встроенного в SAP HANA 2.0, можно выполнять разработку на многих других языках благодаря поддержки концепции Bring Your Own Language (и за счёт использования Cloud Foundry). С помощью этих языков можно производить необходимые вычисления и прогнозы непосредственно на уровне хранения данных. Это позволяет избавиться от лишних этапов передачи больших объёмов данных и выдавать готовый результат расчетов на уровень приложения.
Теперь рассмотрим платформенные сервисы SAP HANA.
Сервисы SAP HANA Platform
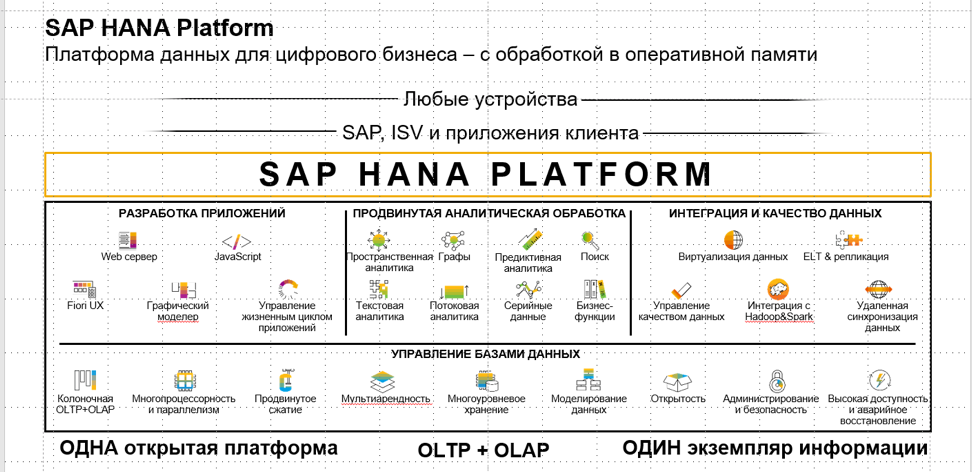
В SAP HANA есть не только база данных, но и целый набор сервисов для разработки приложений, средства интеграции и очистки данных, библиотеки для аналитической обработки данных, включая Machine Learning, а также возможности для хранения и обработки специальных типов данных. SAP HANA позволяет без дополнительных инструментов загружать данные из различных источников, разрабатывать различные формы для ввода, редактирования и анализа данных. Также доступны инструменты для сложной интеллектуальной обработки данных: преобразование, трансформация, поиск закономерностей, исследования. И, конечно, платформа открыта для визуального анализа данных через различные инструменты.
Чтобы рассказать о всех возможностях SAP HANA, потребуется написать несколько дополнительных статей. Многие из них уже описаны в нашем блоге.
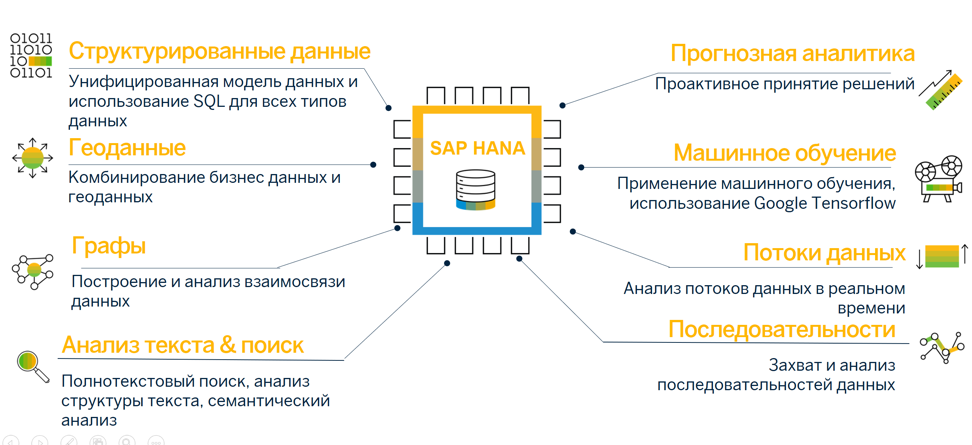
Давайте рассмотрим некоторые доступные сервисы:
SAP HANA включает в себя движок для хранения и обработки геоданных – данных, которые описывают положение, форму и ориентацию объектов в пространстве. SAP HANA поддерживает пространственные типы данных и методы их обработки. Существует специальный метод для обработки такой структуры – граф. SAP HANA в этом случае предоставляет возможности для обработки гиперсвязанных данных и их отношений. Движок для обработки данных имеет встроенные алгоритмы поиска окрестностей, кратчайших путей, сильно связанных компонент, сопоставления образцов и многое другое.
В SAP HANA также есть сотня предварительно упакованных алгоритмов машинного обучения и прогнозирования с такими возможностями, как объединение, кластеризация, классификация, регрессия, распределение вероятности, временные ряды и многое другое. Кроме этого, вы можете использовать библиотеку TensorFlow и язык R.
SAP HANA имеет встроенные возможности для обработки и анализа текстовых файлов, включая различные функции по интеллектуальному анализу текстов – например, нечеткая логика, поиск синонимов, семантический разбор и т.д.
SAP HANA Streaming Analytics может фиксировать, фильтровать, анализировать и воздействовать на миллионы событий в секунду в режиме реального времени, сохраняя данные или результаты в базу данных SAP HANA и направляя менее критические данные в более дешевые решения для хранения — такие, как Hadoop. SAP HANA Streaming Analytics также интегрирована с системой сообщений Apache Kafka.
Полезные материалы и ресурсы для начала работы с SAP HANA:
Бесплатная ознакомительная версия SAP HANA, express edition доступна для скачивания на нашем официальном сайте. Также в начале работы вы можете изучить набор туториалов перед началом работы с SAP HANA:
— виртуальная машина и версия Server + XSA Applications для SAP HANA и видеоинструкция по её установке
— в наборе туториалов есть широкий выбор. Например, для работы с пространственными данными: первый и второй
Сочетание этих решений позволяет создать целостную структуру управления данными с следующими функциями:
- отслеживание происхождения данных
- отслеживание изменений в данных и их структуре
- комплексное понимание метаданных
- поддержка необходимого уровня безопасности
- централизованный мониторинг
Но сегодня мы поговорим про «ядро» этой системы – платформу SAP HANA.
SAP проводил и продолжает проводить исследования, инвестирует большие ресурсы и средства в развитие направления по обработке данных. В результате появилась платформа SAP HANA – High-Performance Analytic Appliance. У нашей компании уже был накоплен многолетний и по-своему уникальный опыт по разработке технологий и сервисов для бизнеса – и в SAP применили его при создании платформы для бизнеса для realtime обработки данных. В результате появилась SAP HANA, которая стала основой и ядром для разработки и построения интеллектуальных предприятий нового типа (intelligent enterprise). Платформу используют для разработки приложений как внутри SAP, так и наши клиенты и партнёры.

SAP HANA – это многоцелевое решение для хранения и обработки информации. Одна из особенностей SAP HANA – это встроенный механизм вычислений, который позволяет переносить выполнение операций по планированию с уровня приложений на уровень базы данных SAP HANA. С помощью современной архитектуры аппаратной платформы вычисления проходят эффективнее – вся «лавина» обрабатываемых данных разбивается на строго определённое количество потоков, число которых равно общему количеству ядер платформы. Такой подход позволяет максимально эффективно использовать вычислительную мощность каждого ядра каждого процессора.
SAP HANA также предоставляет технологии для хранения и обработки данных in-memory. SAP HANA как база данных позволяет хранить данные в построчном и в поколоночном виде. Технология хранения и обработки данных in-memory обеспечивает быструю обработку транзакций, а вместе технологией анализа данных Calculation View гарантирует высокое быстродействие при выполнении аналитических запросов.
Аналитики Forrester начали использовать новое понятие – «транслитическая база данных». По их определению, такая платформа «поддерживает многие типы использования, включая информацию в режиме реального времени, машинное обучение, поточную аналитику и экстремальную транзакционную обработку».
В недавнем отчёте Forrester говорится следующее: «SAP HANA – это shared-nothing (без общего использования ресурсов), in-memory платформа. Это основа платформы SAP для транзакций и аналитики по данным, она поддерживает множество сценариев применения: приложения для обработки данный в режиме реального времени, аналитика, транслитические приложения, системы глубокой и продвинутой аналитики. Предприятия используют платформу для организации in-memory витрин данных, для работы с realtime-хранилищем данных SAP Business Warehouse, а также при работе с SAP S/4HANA и SAP Business Suite».
Транслитические платформы подходят для поддержки realtime-приложений и сервисов: для торговли акциями, обнаружения мошенничества, борьбы с терроризмом, мониторинга здоровья пациентов, анализа данных от различных сенсоров, мониторинга землетрясений и много другого. С помощью транслитической платформы приложения могут обмениваться данными в реальном времени, обеспечивают согласованность и точность информации, хранимой на предприятии.
Ещё одна сфера применения SAP HANA – это поддержка машинного обучения, что позволяет применять к данным сложные аналитические модели для более точного прогнозирования операций, бизнес-процессов, поведения клиентов и т.д.
Как SAP HANA поддерживает данную функциональность?
Начнём с сервиса баз данных. Если рассматривать HANA с точки зрения архитектуры и технологий, то здесь применяются два способа хранения данных – построчный и поколоночный.
Построчное хранение данных в таблице позволяет обеспечивать высокую скорость записи данных. Если вы хотите добавить новую строку в таблицу, то вам достаточно найти свободное место в памяти для этой строки и записать туда новые данные. Однако при построчном хранении возникает проблема с анализом данных: необходимо использовать индексирование или материализованное представление данных в форме, которая будет удобна для анализа. При этом индексирование приводит к задержкам из-за того, что необходимо дополнительное время на перестроение индекса, материализацию данных в ином формате в процессе вставки строки.
Если же данные хранятся поколоночно, то для добавления новой строки необходимо потратить время на разнесение значений строки по колонкам, затем – подождать, пока данные будут разнесены в разные места в памяти. Всё это приводит к снижению производительности во время записи данных.
База данных с поколоночным хранением позволяет значительно быстрее обрабатывать запросы, потому что в этом случае данные из запрошенных колонок расположены в памяти компактно и сжато. Т.е. при запросе нет необходимости сканировать всю таблицу – достаточно просмотреть только колонки, используемые в запросе. Такая база данных оптимизирована для чтения, а поколоночное хранение информации позволяет организовывать данные в оперативной памяти определенным образом, с использованием группировки. При этом подходе можно с большей эффективностью использовать различные техники компрессии, что приводит к многократному сжатию исходной информации.
Для решения этой проблемы был разработан подход Unified Tables, который обеспечивает высокую скорость чтения и записи данных в таблицу поколоночного хранения. Такой механизм позволяет быстро осуществлять транзакции (то есть запись новых строк), анализировать данные с высокой скоростью за счёт поколоночного хранения в сжатом виде, параллельной обработки данных, а также хранить все данные в оперативной памяти (in-memory).
При проведении записи изменения не сразу вносятся в основное место хранения таблиц. Вместо этого все правки заносятся в отдельную структуру данных – дельта-хранилище (на картинке L1-delta). Здесь данные хранятся в оптимизированном для записи формате. Когда необходимо перенести изменения из дельта-хранилища, то запускается специальный процесс Delta merge – слияние дельты. Сначала данные из L1-delta преобразуются в поколоночный формат в L2-delta, а затем объединяются с основным хранением данных (main store). А для механизма чтения данных все три области хранения информации (L1-delta, L2-delta и main store) предоставляют данные в целостном виде. Благодаря этому процессу получается обеспечить высокую скорость записи и анализа данных.

Одно из существенных преимуществ SAP HANA – все расчеты агрегированных данных производятся непосредственно при формировании аналитического запроса и выводятся сразу в виде результата. Возможности по хранению детальных или исходных данных в оперативной памяти (а не агрегированных значений) позволяют отказаться от предварительного расчета и хранения агрегатных таблиц, которые являются неотъемлемой частью классических аналитических систем.
SAP HANA также поддерживает различные внутренние языки программирования: R – для создания прогнозных моделей, SQL Script – для написания логики вычислений. На уровне сервера приложений XSA, встроенного в SAP HANA 2.0, можно выполнять разработку на многих других языках благодаря поддержки концепции Bring Your Own Language (и за счёт использования Cloud Foundry). С помощью этих языков можно производить необходимые вычисления и прогнозы непосредственно на уровне хранения данных. Это позволяет избавиться от лишних этапов передачи больших объёмов данных и выдавать готовый результат расчетов на уровень приложения.
Теперь рассмотрим платформенные сервисы SAP HANA.
Сервисы SAP HANA Platform

В SAP HANA есть не только база данных, но и целый набор сервисов для разработки приложений, средства интеграции и очистки данных, библиотеки для аналитической обработки данных, включая Machine Learning, а также возможности для хранения и обработки специальных типов данных. SAP HANA позволяет без дополнительных инструментов загружать данные из различных источников, разрабатывать различные формы для ввода, редактирования и анализа данных. Также доступны инструменты для сложной интеллектуальной обработки данных: преобразование, трансформация, поиск закономерностей, исследования. И, конечно, платформа открыта для визуального анализа данных через различные инструменты.
Чтобы рассказать о всех возможностях SAP HANA, потребуется написать несколько дополнительных статей. Многие из них уже описаны в нашем блоге.

Давайте рассмотрим некоторые доступные сервисы:
SAP HANA включает в себя движок для хранения и обработки геоданных – данных, которые описывают положение, форму и ориентацию объектов в пространстве. SAP HANA поддерживает пространственные типы данных и методы их обработки. Существует специальный метод для обработки такой структуры – граф. SAP HANA в этом случае предоставляет возможности для обработки гиперсвязанных данных и их отношений. Движок для обработки данных имеет встроенные алгоритмы поиска окрестностей, кратчайших путей, сильно связанных компонент, сопоставления образцов и многое другое.
В SAP HANA также есть сотня предварительно упакованных алгоритмов машинного обучения и прогнозирования с такими возможностями, как объединение, кластеризация, классификация, регрессия, распределение вероятности, временные ряды и многое другое. Кроме этого, вы можете использовать библиотеку TensorFlow и язык R.
SAP HANA имеет встроенные возможности для обработки и анализа текстовых файлов, включая различные функции по интеллектуальному анализу текстов – например, нечеткая логика, поиск синонимов, семантический разбор и т.д.
SAP HANA Streaming Analytics может фиксировать, фильтровать, анализировать и воздействовать на миллионы событий в секунду в режиме реального времени, сохраняя данные или результаты в базу данных SAP HANA и направляя менее критические данные в более дешевые решения для хранения — такие, как Hadoop. SAP HANA Streaming Analytics также интегрирована с системой сообщений Apache Kafka.
Полезные материалы и ресурсы для начала работы с SAP HANA:
Бесплатная ознакомительная версия SAP HANA, express edition доступна для скачивания на нашем официальном сайте. Также в начале работы вы можете изучить набор туториалов перед началом работы с SAP HANA:
— виртуальная машина и версия Server + XSA Applications для SAP HANA и видеоинструкция по её установке
— в наборе туториалов есть широкий выбор. Например, для работы с пространственными данными: первый и второй
