Когда вы слышите слово «творчество», какие ассоциации приходят к вам в голову? Скорее всего, не в последнюю очередь вы подумаете о музыке. Зачастую она — прямое выражение глубоких эмоций и переживаний. Как будто из идеального мира Платона к нам проникает свет, который композитор просто записывает в виде нот. Возможно поэтому мы и считаем музыку творчеством в чистом виде, ведь она — проявление глубинных эмоций. Как же ИИ может создавать её, не испытывая эмоций?
В этой статье я расскажу, как наша команда Управления экспериментальных систем машинного обучения SberDevices попыталась формализовать сочинение музыки и научить ему нейронную сеть. Запускайте наш первый генеративный альбом «Thriving Machine» и устраивайтесь поудобнее.

Как всё начиналось
Год назад мы взялись за амбициозную задачу — ни много ни мало, научить компьютер сочинять музыку, используя методы машинного обучения. Мы начали с исследования существующих на тот момент решений. Выяснилось, что есть два основных подхода — генерация непосредственно аудио, где state of art-моделью является JukeBox от OpenAI, и генерация нотной последовательности с сохранением её в формате MIDI и превращением в аудио с помощью виртуальных инструментов.
Генерация аудио напрямую выглядела очень многообещающе, но, к сожалению, скорость работы модели оказалась на порядки медленнее реалтайма, и это при частоте дискретизации 16 кГц. Поэтому мы решили сосредоточиться на символьной генерации и синтезе MIDI. Помимо выигрыша в скорости и возможности применять методы и модели NLP (на уровне нот музыка — это текст со специфическим тезаурусом), этот подход отличается гораздо большей гибкостью и потенциалом к управлению как на этапе синтеза, так при создании конечного аудиофайла.
Из MIDI в музыку
Формат MIDI в первую очередь предназначен для передачи сообщений между инструментами, и только во вторую — для хранения нотной последовательности. Когда музыкант наигрывает мелодию с помощью клавиатуры, подключённой к компьютеру, сообщения о нажатых клавишах и силе нажатия передаются именно в MIDI-формате.
В современном мире всё больше композиций создаются на компьютере, причём нередко отличить «компьютерный» инструмент от сыгранного вживую может только специалист. Зачастую в основе подобных треков лежит всё тот же MIDI. Так как же «мидишки» превращаются в музыку, звучащую в ваших наушниках? Для этого используются профессиональные наборы виртуальных инструментов. Они могут быть записаны в виде сэмплов с настоящих образцов, будь то рояль Стинвей или скрипка Страдивари, или могут быть синтетическими. Однако только выбором качественных инструментов дело не ограничивается — в дело вступает саунд-дизайн.
В широком понимании саунд-дизайн — это весь процесс создания звука в произведении. Это делается в DAW — цифровой звуковой рабочей станции, они бывают программными и «железными». Превратить MIDI в музыку помогают VST-плагины в программных DAW, позволяя сыграть миди-дорожку практически любым инструментом, будь это скрипичный ансамбль (звучание которого, конечно, будет менее крутым, чем у живых инструментов, но всё же достойным), или дисторшированная электро-гитара, как в тяжёлом метале, или великое разнообразие синтезаторных звуков.

Но мало выбрать и настроить виртуальные инструменты, нужно ещё добавить аудиоэффекты, выполнить сведение — всё как в “человеческой” музыке. Без этого наши композиции звучали бы тускло, а инструменты были бы трудно различимы.
Первые шаги
Мы уже выяснили, что с инженерной точки зрения, музыка — это текст из нот. А это значит, что задача генерации нотной последовательности по сути является задачей построения языковой модели. На сегодняшний день лучшие языковые модели получаются на базе архитектуры Transformer. Мы рассмотрели несколько вариантов представления MIDI для использования в трансформере: MuseNet от OpenAI, Music Transformer от Google, и формат REMI, который использовался в модели Pop Music Transformer от команды Yating Music. Последний показался нам наиболее гибким и продуманным. Его мы и решили использовать в нашем проекте.
Каждая нота в формате REMI задаётся последовательностью токенов: смещение относительно начала такта, сила нажатия клавиши инструмента (громкость), высота тона, длительность.

Помимо токенов нот, в формате предусмотрены различные служебные токены: начало такта, текущий аккорд, изменение темпа и тому подобное.
Основной проблемой оригинального формата была моноинструментальность. При таком представлении мелодии модель могла синтезировать лишь одну партию, пусть и очень сложную. Необходимо было изменить формат таким образом, чтобы модель могла синтезировать партии различных инструментов одновременно. Для этого мы стали добавлять к последовательности токенов еще и токен инструмента.
Но возможных инструментов было слишком много, и часть из них встречалась достаточно редко. Формат MIDI поддерживает до 128 инструментов, и нам нужно было уменьшить это количество. Мы решили объединить похожие инструменты в большие группы, подобно тому, как это сделано в проекте MuseNet. В результате мы выделили группы клавишных, струнных, барабаны и т. д.
Теперь одна сыгранная нота на языке нашей модели стала выглядеть так:

Кроме того, изначальная модель могла работать лишь с музыкой в размере 4/4. Чтобы синтезировать музыку с другими размерами, мы заменили в словаре единый токен начала такта на подмножество токенов, каждый из которых соответствует количеству 32-х долей в такте, например, характерный для вальса размер 3/4 равен 24/32. В результате перед каждым следующим тактом вставляется токен, соответствующий его размеру.
С чем мы столкнулись
Мы увеличили количество партий в мелодии, а это означало, что мы кратно увеличили количество токенов, которые модели нужно было синтезировать для проигрывания мелодии той же самой длительности. Скажем, для того чтобы синтезировать мелодию длительностью полторы минуты, требовалось 8000 токенов.
Transformer XL, который лежал в основе проекта Pop Music Transformer, перестал справляться с последовательностями такой длины, и мелодии на выходе достаточно быстро деградировали. После поисков и экспериментов мы заменили Transformer XL на Performer от Google.
Нас поджидала ещё одна сложность: модель периодически сбивалась с последовательности токенов, которая была нужна для синтеза ноты, и могла, например, пропустить токен высоты ноты, или начать «забывать» вставить токен следующего отсчета. В результате на выходе вместо музыкального фрагмента получался какой-то нечеловеческий аккорд.
Чтобы заставить модель придерживаться нужной нам последовательности, мы стали применять подход, который назвали “структурированным синтезом”. Он заключается в том, чтобы перед сэмплированием выходного токена занулить вероятности выбора тех токенов, которых сейчас быть не должно. Например, если предыдущим токеном был выбор инструмента и теперь мы ждем высоту ноты, то мы зануляем вероятность выбора всех токенов, которые не относятся к типу «высота ноты».
Аугментация и транспонирование
Также как ноты, звучащие в данный момент, должны сочетаться с аккордами, так и вероятность появления самих аккордов и последовательности нот во многом определяется тональностью всего произведения. Одно и то же произведение может быть сыграно в разных тональностях. Перенос из одной тональности в другую называется транспонированием и по сути задаётся смещением высоты каждой ноты на одну и ту же величину. Транспонирование является хорошим способом аугментации, позволяя кратно увеличить датасет и помогая модели уловить гармоническую структуру произведения. Однако наши эксперименты показали, что лучшие результаты даёт не транспонирование, а приведение всех треков в датасете к одной тональности. Таким образом, модель выучивает не абсолютную высоту нот, а относительную — условную ступень внутри тональности.
Управление синтезом
Наш синтез стал лучше, но оказалось, что мы не знаем, как задать стиль произведения, которое хотим получить на выходе. Более того, этого не знала и сама модель — на длинной дистанции она «теряла мысль» и начинала импровизировать достаточно далеко от начального фрагмента, вплоть до смены жанра произведения.
Пример — модель меняет жанр:
Пример — модель зациклилась:
Очевидное решение – добавить управляющий токен в состав затравки (начальной последовательности). Мы попробовали подавать токен автора, токен жанра, проверили ещё несколько экспериментальных вариантов, но управляемость и устойчивость синтеза оставляли желать лучшего.
Так как нам не удалось заставить модель за один раз запомнить всё, что мы от неё хотим, и помнить об этом до конца произведения, мы попробовали напоминать ей об этом постоянно. Для этого в начале каждого такта мелодии мы решили подавать какой-то управляющий вектор, несущий в себе информацию о фрагменте, который нужно сыграть в текущем такте. Информации в таком векторе должно было быть достаточно, чтобы модель могла опереться на него при синтезе, но недостаточно для того, чтобы модель могла опираться только на него без учета предыдущего контекста.
После долгих поисков мы пришли к двухэтапной схеме тренировки. На первом этапе мы стали тренировать связку из двух перформеров и вариационного автоэнкодера между ними. Задачей этой модели было восстановление одного такта мелодии.
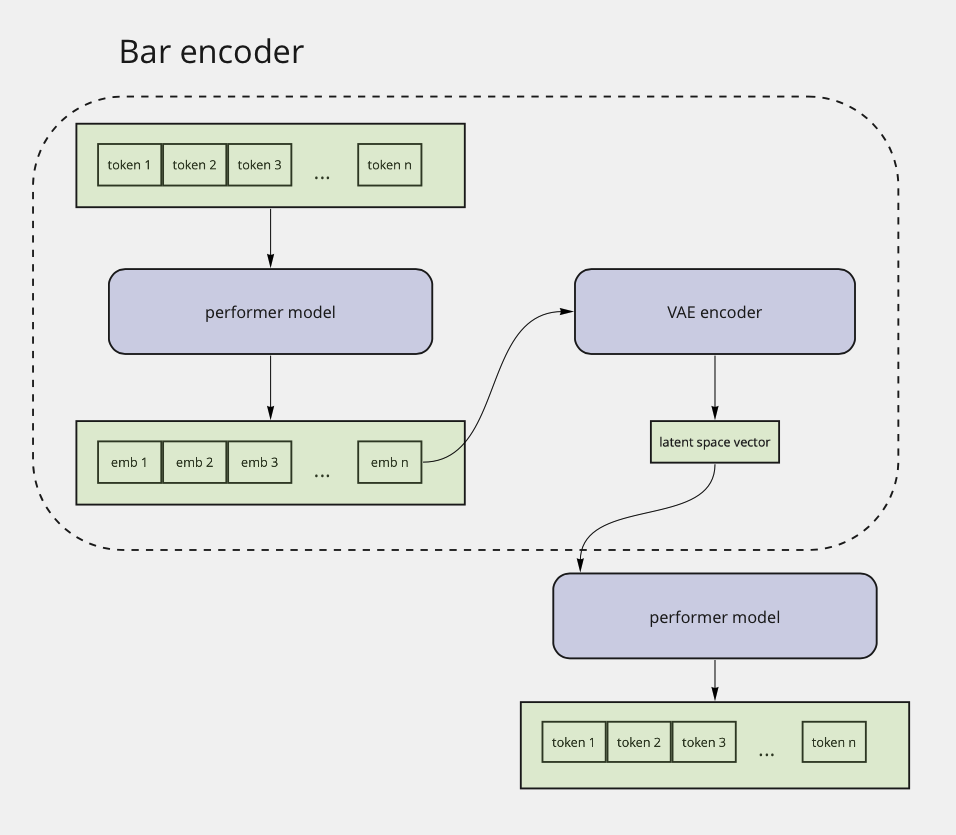
На втором этапе мы стали подавать вектор латентного пространства автоэнкодера в качестве управляющего вектора в основную модель.

В результате при синтезе модель стала «обращать внимание» как на управляющий вектор, так и на предыдущий контекст. Как это звучит, можно услышать в этих двух примерах:
В первом примере мы подавали векторы, извлечённые из композиции Blondie «Call Me». Во втором, начиная с пятого такта, мы стали подавать векторы, извлечённые из композиции Кино «Группа крови».
Таким образом, глобальная структура произведения стала задаваться последовательностью управляющих векторов, и наша модель перестала «терять мысль».
Модель верхнего уровня
После того как мы смогли задать структуру произведения, нам понадобилась ещё одна модель, которая эту структуру будет синтезировать. В качестве архитектуры мы взяли ту же самую связку Performer + VAE. При тренировке на вход модели подавалась последовательность управляющих векторов. Эта последовательность сжималась в вектор фиксированной длины, который разжимался обратно в исходную последовательность управляющих векторов. Таким образом, мелодия целиком стала задаваться вектором размерностью 64.
Во время первой попытки построения такой модели мы хотели получать управляющие векторы непосредственно в качестве выхода модели. Поэтому мы не использовали токены на входе, но использовали mean squared error в качестве функции потерь. Однако такая модель плохо училась, и конечный результат был далёк от желаемого.
Тогда мы решили вернуться к токенам в качестве как входной информации, так и результата работы модели.
Поскольку латентное пространство вариационных автоэнкодеров является непрерывным, то мы могли квантизировать наши управляющие векторы в некоторое фиксированное множество токенов. В результате экспериментов выяснилось, что минимальный размер кодбука, при котором качество синтеза не страдает, равен 16384 векторам. А это значит, что таким же будет и размер словаря верхнеуровневой модели.
Размер словаря оказался достаточно большим, модель часто ошибалась при выборе токенов, и каждая ошибка «резала ухо» в финальном синтезе. И тут нам снова сыграло на руку свойство непрерывности пространства управляющих векторов. В качестве эмбеддингов токенов верхнеуровневой модели мы стали использовать векторы кодбука, который был использован для квантизации. В результате перплексия модели упала, и когда в результате сэмплирования выбирался «не тот» токен, стилистически он всё равно был похож на оригинал, и финальная мелодия звучала хорошо.
В первом примере для синтеза использовались управляющие векторы, извлеченные из MIDI:
Гитарная партия этого примера выглядит так:

Во втором примере управляющие векторы были синтезированы моделью верхнего уровня:
Гитарная партия:

Ранжирование результатов
Несмотря на все улучшения, модель временами продолжала выдавать не очень качественный результат. Например, длительный участок мелодии мог быть монотонным, или отдельные переходы звучали не очень хорошо. Для того, чтобы решить эту проблему, мы создали ранжировщик результатов.
В качестве исходных данных мы извлекли управляющие векторы из 100 MIDI-файлов, разбитых на фрагменты по 8 отсчётов, и для каждого такого набора провели синтез десять раз с разными значениями температуры сэмплинга. Полученные результаты попарно сравнивались людьми на краудсорсинг-платформе.
Пример — худший сэмпл из пары:
Пример — лучший сэмпл из пары:
Модель-ранжировщик также должна была научиться выбирать лучший из двух музыкальных фрагментов. Для этого мы стали преобразовывать музыкальные фрагменты после синтеза в управляющие векторы уже имевшейся у нас модели «Performer + VAE», а полученные результаты — подавать в сиамскую свёрточную нейронную сеть, которая предсказывала лучший фрагмент из пары.
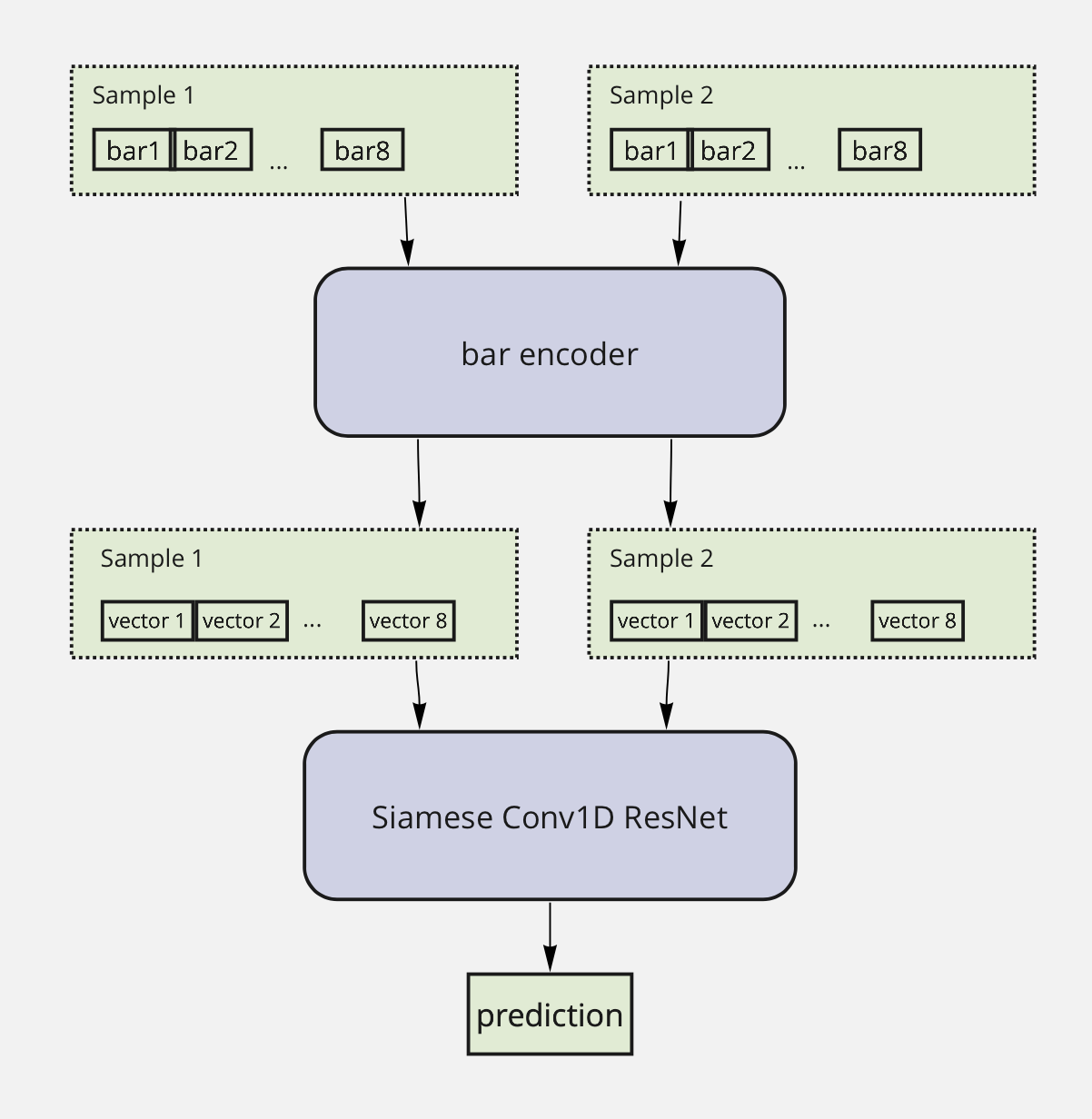
Поскольку мы могли представить в виде управляющих векторов результаты синтеза как модели верхнего, так и модели нижнего уровня, то ранжировщик мы стали применять на обоих этапах синтеза.
Что дальше?
Мы продолжаем работу над нашим проектом, и сейчас перед нами стоит большая задача автоматизации саунд-дизайна.
Хотя мелодии в нашем альбоме были полностью написаны нейронной сетью, саунд-дизайн и сведение делались людьми. В настоящее время у нас есть прототип системы автоматического саунд-дизайна, которая хорошо показала себя для внутреннего применения, например, side-by-side сравнения результатов моделей, но пока не достигает «альбомного» качества. Мы надеемся улучшить её в ближайшее время и, таким образом, собрать end2end-решение, позволяющее на основе пользовательских предпочтений создавать персонализированную музыку. И научим наших ассистентов Салют быть вашими персональными композиторами!
