В фильмах или роликах с YouTube мы наблюдаем происходящее из одной точки, нам не доступны перемещение по сцене или смещение угла зрения. Но, кажется, ситуация меняется. Так, исследователи из Политехнического университета Вирджинии и Facebook разработали новый алгоритм обработки видео. Благодаря ему можно произвольно изменять угол просмотра уже готового видеопотока. Что примечательно — алгоритм использует кадры, которые получены при съемке на одну камеру, совмещение нескольких видеопотоков с разных камер не требуется.
В основе нового алгоритма — нейросеть NeRF (Neural Radiance Fields for Unconstrained). Эта появившаяся в прошлом году сеть умеет превращать фотографии в объемную анимацию. Однако для достижения эффекта перемещения в видео проект пришлось существенно доработать.

NeRF обучают на большом количестве изображений одного и того же объекта с разных ракурсов. Изначально ее научили воссоздавать объемные картинки известных архитектурных достопримечательностей и других объектов. Не все изображения идеально складывались и читались, поэтому требовалось расширить изначальные возможности.

Сама по себе нейросеть умеет создавать 3D-изображение под разными углами из множества снимков. Также она может вычленять 2D-модели. Эти изображения переводят из объемных в плоскостные путем попиксельного переноса. Как именно?
Когда выбран нужный угол зрения, алгоритм начинает пропускать сквозь трехмерную сцену лучи и попиксельно создавать двухмерное изображение, используя данные о плотности и цвете каждого пикселя вдоль всего прохождения луча. Чтобы получить кадр целиком, процесс запускают несколько раз, пока не наберется необходимое количество пикселей из лучей просчитанных с разных направлений. Тем самым становится возможным генерация 2D-изображений с любого ракурса. В целом интересный и оригинальный подход к решению столь нетривиальной задачи.
Для достижения похожего эффекта для видеопотока требуются аналогичные действия. Но есть важный нюанс — в видео есть только один ракурс для каждого отдельного кадра. Чтобы справиться с задачей, исследователи решили обучить две разные модели параллельно. В итоге получились сразу 2 алгоритма: для статической и динамической частей сцены.

Что касается статичной модели, то она устроена по тому же принципу, что и NeRF. Есть только одно отличие — из кадра сразу удалили все движущиеся объекты.

С динамической моделью все намного интереснее. Для ее обработки не хватало кадров. Тогда нейросеть научили предсказывать кадры для объемного потока. Точнее кадры к каждому конкретному моменту времени t. Эти моменты условно назвали t-1 и t+1. Суть 3D-потока сводится к оптическому потоку, только в этом случае его строят для объемных объектов.
Также ученым удалось избавиться от помех и обеспечить согласованность кадров. В итоге новая нейросеть воссоздает достаточно стройный видеоряд с разных ракурсов. На предоставленном разработчиками видео виден эффект, похожий на тот, что многие из нас помнят из «Матрицы». В кинематографе его называют Bullet time, когда зрителя погружают внутрь изображения.
Сами разработчики считают свой проект более удачной версией NeRF, благодаря стройным и плавным переходам.

В основе нового алгоритма — нейросеть NeRF (Neural Radiance Fields for Unconstrained). Эта появившаяся в прошлом году сеть умеет превращать фотографии в объемную анимацию. Однако для достижения эффекта перемещения в видео проект пришлось существенно доработать.
Что именно умеет NeRF?
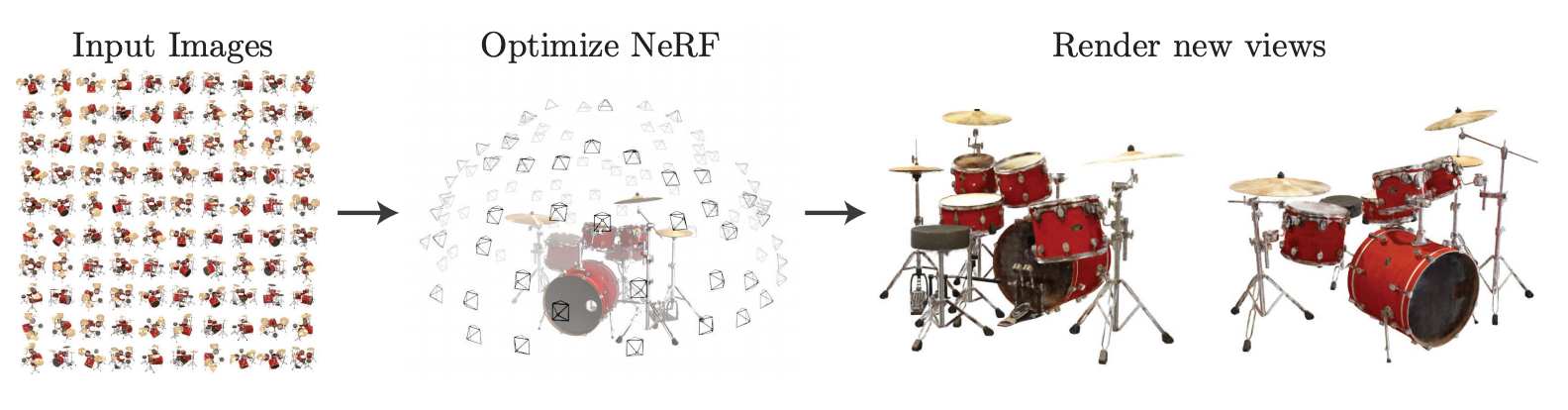
NeRF обучают на большом количестве изображений одного и того же объекта с разных ракурсов. Изначально ее научили воссоздавать объемные картинки известных архитектурных достопримечательностей и других объектов. Не все изображения идеально складывались и читались, поэтому требовалось расширить изначальные возможности.
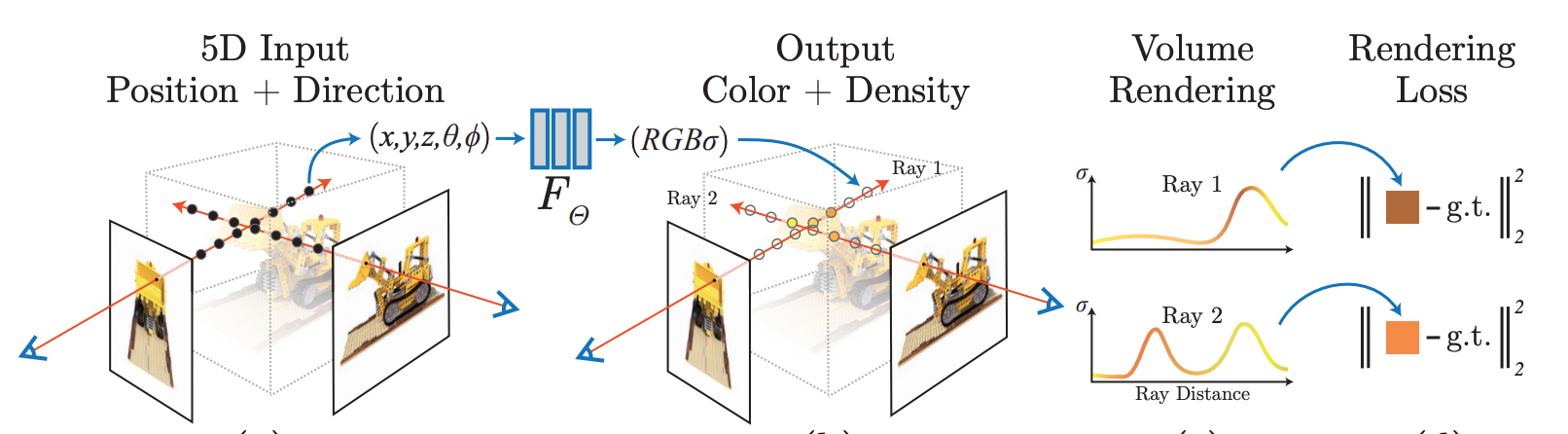
Сама по себе нейросеть умеет создавать 3D-изображение под разными углами из множества снимков. Также она может вычленять 2D-модели. Эти изображения переводят из объемных в плоскостные путем попиксельного переноса. Как именно?
Когда выбран нужный угол зрения, алгоритм начинает пропускать сквозь трехмерную сцену лучи и попиксельно создавать двухмерное изображение, используя данные о плотности и цвете каждого пикселя вдоль всего прохождения луча. Чтобы получить кадр целиком, процесс запускают несколько раз, пока не наберется необходимое количество пикселей из лучей просчитанных с разных направлений. Тем самым становится возможным генерация 2D-изображений с любого ракурса. В целом интересный и оригинальный подход к решению столь нетривиальной задачи.
Видеопоток с эффектом
Для достижения похожего эффекта для видеопотока требуются аналогичные действия. Но есть важный нюанс — в видео есть только один ракурс для каждого отдельного кадра. Чтобы справиться с задачей, исследователи решили обучить две разные модели параллельно. В итоге получились сразу 2 алгоритма: для статической и динамической частей сцены.
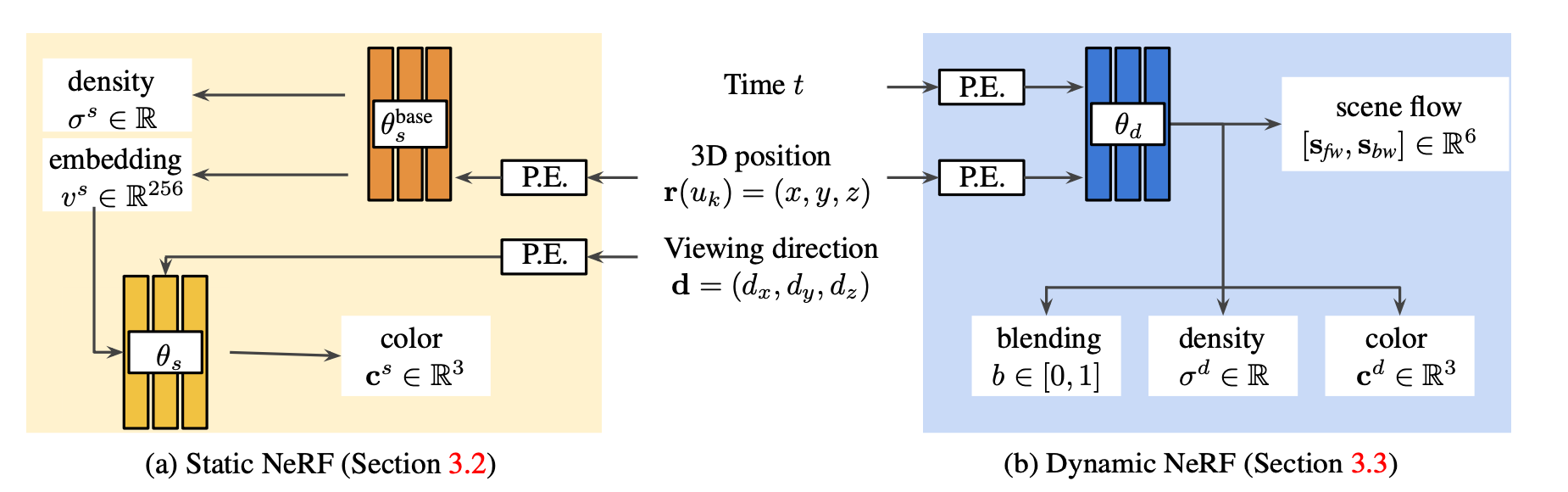
Что касается статичной модели, то она устроена по тому же принципу, что и NeRF. Есть только одно отличие — из кадра сразу удалили все движущиеся объекты.

С динамической моделью все намного интереснее. Для ее обработки не хватало кадров. Тогда нейросеть научили предсказывать кадры для объемного потока. Точнее кадры к каждому конкретному моменту времени t. Эти моменты условно назвали t-1 и t+1. Суть 3D-потока сводится к оптическому потоку, только в этом случае его строят для объемных объектов.
Также ученым удалось избавиться от помех и обеспечить согласованность кадров. В итоге новая нейросеть воссоздает достаточно стройный видеоряд с разных ракурсов. На предоставленном разработчиками видео виден эффект, похожий на тот, что многие из нас помнят из «Матрицы». В кинематографе его называют Bullet time, когда зрителя погружают внутрь изображения.
Сами разработчики считают свой проект более удачной версией NeRF, благодаря стройным и плавным переходам.

