Недавно новый сотрудник спросил меня за обедом: «Какой у нас техдолг?»
Услышав вопрос, я не мог не улыбнуться. Спрашивать инженеров-программистов о техническом долге компании – это то же самое, что спрашивать о кредитном рейтинге. Так программисты хотят узнать о сомнительном прошлом компании и о том, с каким багажом из прошлого придётся столкнуться. К техническому багажу нам не привыкать.
Как поставщик облачных услуг, который управляет собственными серверами и оборудованием, мы столкнулись с проблемами, с которыми многие другие стартапы в новую эру облачных вычислений не сталкивались. Эти сложные ситуации в конце концов привели к компромиссу, на который нам пришлось пойти, когда компания только начала работать. И, как известно любой быстрорастущей компании, технические решения, которые вы принимаете на раннем этапе, обычно догоняют вас.
Глядя на нового сотрудника, я глубоко вздохнул и начал: «Давай я расскажу о том, как у нас было 15 000 прямых подключений к БД…»
История, которую я рассказал нашему новому сотруднику, – это история крупной технической перестройки DigitalOcean. Работала вся компания, эта работа продолжалась несколько лет и преподала нам много уроков.


С самого начала DigitalOcean была одержима простотой. Стремление к простым и элегантным решениям – одна из наших основных ценностей. Это касается не только продуктов, но и технических решений. Более всего этот подход выделялся в первоначальной архитектуре системы.
Как и GitHub, Shopify и Airbnb, DigitalOcean начиналась как приложение Rails в 2011 году. Внутри компании приложение называли Cloud, оно управляло всеми взаимодействиями с пользователем как в интерфейсе пользователя, так и в общедоступном API. Сервису Rails помогали два сервиса Perl: Scheduler и DOBE (DigitalOcean BackEnd). Планировщик планировал и назначал дроплеты гипервизорам, а DOBE отвечал за создание реальных виртуальных машин дроплетов. В то время как Cloud и Scheduler работали как автономные службы, DOBE работал на каждом сервере парка машин.
Cloud, Scheduler, DOBE общались друг с другом не напрямую, а через базу данных MySQL, которая выполняла две роли: хранила данные и была посредником при обмене данными. Все три службы использовали одну таблицу базы данных в качестве очереди сообщений, чтобы передавать информацию.
Каждый раз, когда пользователь создавал новый дроплет, Cloud вставлял новую запись о событии в очередь. Scheduler непрерывно, каждую секунду опрашивал БД на предмет новых событий Droplet и планировал их создание на доступном гипервизоре. Наконец, каждый экземпляр DOBE ждал создания новых запланированных дроплетов и выполнял задачу. Чтобы серверы могли обнаружить любые новые изменения, каждому нужно было опросить базу данных на предмет новых записей в таблице.

Хотя бесконечные циклы и прямое подключение каждого сервера к базе данных могли быть рудиментарными, с точки зрения проектирования системы, это было просто и работало – особенно для небольшой технической команды, которая сталкивалась с жёсткими сроками, а пользователей становилось всё больше.
Четыре года очередь сообщений базы данных составляла основу технологического стека DigitalOcean. В это время мы приняли архитектуру микросервисов, для внутреннего трафика заменили HTTPS на gRPC, вместо Perl внутренние сервисы стали писать на Golang. Однако все дороги по-прежнему вели к той самой базе данных MySQL.
Важно отметить, что если код – легаси, это не означает, что он не работает и его нужно переписать. У Bloomberg и IBM есть устаревшие сервисы, написанные на Fortran и COBOL, которые приносят доход больше, чем целые компании. С другой стороны, у каждой системы есть предел масштабирования. Мы собирались ударить по нашему.
С 2012 по 2016 год пользовательский трафик DigitalOcean вырос более чем на 10 000 %. Мы добавили больше продуктов в наш каталог и больше сервисов в нашу инфраструктуру. Событий в очереди базы данных стало больше. Повышенный спрос на дроплеты означал, что Scheduler, чтобы назначить их все серверам, работал с превышением штатной нагрузки. И, к сожалению для Scheduler, количество доступных серверов не было постоянным.

Чтобы не отставать от растущего спроса на дроплеты, мы добавляли всё больше и больше серверов для обработки трафика. Каждый новый гипервизор означал еще одно постоянное соединение с базой данных. К началу 2016 года у базы было более 15 000 прямых подключений, и каждое запрашивало новые события через одну-пять секунд. Если и этого было недостаточно, то SQL-запрос, который каждый гипервизор использовал для получения новых событий дроплет, также стал сложнее. Он превратился в колосс из более чем 150 строк и JOIN в 18 таблиц. Этот код впечатлял настолько же, сколько рискованно и трудно было его поддерживать.
Не удивительно, что именно тогда система треснула. Единая точка отказа с тысячами зависимостей, которые боролись за общие ресурсы, время от времени неизбежно обращалась в хаос. Таблицы блокировались и запросы не выполнялись, и это приводило к сбоям, падала производительность.
Из-за тесной связи в системе не было чёткого или простого решения проблемы. Cloud, Schedule и DOBE оказались узкими местами. Патчи только одного или двух компонентов сместили бы нагрузку на оставшиеся узкие места. Поэтому после долгих раздумий инженеры разработали план исправления из трёх пунктов:
Чтобы справиться с зависимостями базы данных, инженеры DigitalOcean создали Event Router. Маршрутизатор событий служил региональным прокси-сервером, который опрашивал базу данных от имени каждого экземпляра DOBE в каждом центре обработки данных. Вместо тысяч серверов, каждый из которых запрашивает базу данных, осталась только горстка выполняющих запрос прокси. Каждый прокси-сервер маршрутизатора событий будет извлекать все активные события в определённом регионе и делегировать каждое событие соответствующему гипервизору. Event Router также разбил гигантский опрашивающий запрос на запросы, которые проще поддерживать.
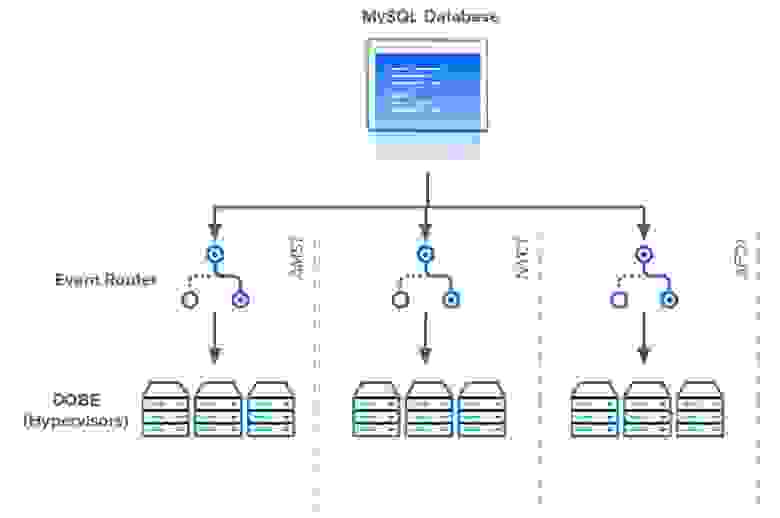
Когда Event Router был запущен, он сократил количество подключений к базе данных с более чем 15 000 до менее 100.
Затем инженеры нацелились на планировщика. Как упоминалось ранее, Scheduler был сценарием Perl и определял, в каком гипервизоре разместить дроплет. Делалось это с помощью серии запросов, чтобы сортировать и ранжировать серверы. Всякий раз, когда пользователь создаёт дроплет, планировщик обновляет строку таблицы на лучшую машину.
Хотя это звучит достаточно просто, Scheduler имел несколько недостатков. Его логика была сложной, работать с ней было непросто. Он был однопоточным, и его производительность снижалась во время пиковой нагрузки. Наконец, был только один экземпляр Scheduler – и он должен был обслуживать весь парк. Это узкое место было неизбежным. Чтобы решить эти проблемы, команда инженеров разработала Scheduler V2.
В обновлённом планировщике переработали всю систему ранжирования. Вместо того чтобы запрашивать у базы данных показатели сервера, планировщик агрегировал их из гипервизоров и хранил в собственной базе данных. Кроме того, команда Scheduler применила параллелизм и репликацию, чтобы их новый сервис под нагрузкой оставался производительным.
Event Router и Scheduler v2 были большими достижениями, они устраняли многие недостатки архитектуры. Но даже с ними имела место большая препона [прим. перев. – это несколько удивительно, но слово препона женского рода]. К началу 2017 года централизованная очередь сообщений MySQL всё ещё использовалась. Она обрабатывала до 400 000 новых записей в день и обновлялась 20 раз в секунду.
К сожалению, удалить очередь сообщений из базы данных было нелегко. Сначала инженеры запретили сервисам прямой доступ к базе. База нуждалась в дополнительном уровне абстракции. Слою также требовался API, чтобы агрегировать и выполнять запросы от его имени. Если какой-либо сервис захочет создать новое событие, ему нужно будет сделать это через API. Так родился Harpoon.

Однако создать интерфейс очереди сообщений было легко. Труднее оказалось достичь согласия с другими командами. Интеграция с Harpoon означала, что командам пришлось бы отказываться от доступа к базе данных, переписывать куски своего кода и, в конечном счёте, изменить свои привычки. Это было нелегко.
Команда за командой и сервис за сервисом инженеры Harpoon смогли перенести всю кодовую базу на свою новую платформу. На это ушёл почти год, но к концу 2017 года Harpoon стал единственным издателем очереди сообщений базы данных.
Началась настоящая работа. Полный контроль над системой событий означал, что с Harpoon мы получили свободу переосмыслить рабочий процесс дроплета.
Первой задачей Harpoon было взять на себя обязанности по очереди сообщений из базы данных. Для этого Harpoon создал собственную внутреннюю очередь сообщений, состоящую из RabbitMQ и асинхронных воркеров. Пока Harpoon отправлял новые события в очередь с одной стороны, воркеры забирали их с другой стороны. А поскольку RabbitMQ заменил очередь базы данных, воркеры могли напрямую общаться с планировщиком и маршрутизатором событий. Таким образом, вместо того чтобы Scheduler V2 и Event Router опрашивали базу данных на предмет изменений, Harpoon отправлял обновления к ним напрямую. На момент написания этой статьи, в 2019 году, архитектура событий дроплет всё ещё работает.

За последние семь лет мы выросли из группы в гараже до признанного провайдера облачных сервисов, которым являемся сегодня. Как и другие технологические компании, которые занимались переходной экономикой, мы постоянно работаем с устаревшим кодом и техническим долгом. Будь то дробление монолитов, создание мультирегиональных сервисов или устранение единых точек отказа, мы, инженеры, всегда работаем, чтобы создать простые и элегантные решения. Я надеюсь, что эта история окажется полезной для других разработчиков, которые ломают голову над техническим долгом.

Услышав вопрос, я не мог не улыбнуться. Спрашивать инженеров-программистов о техническом долге компании – это то же самое, что спрашивать о кредитном рейтинге. Так программисты хотят узнать о сомнительном прошлом компании и о том, с каким багажом из прошлого придётся столкнуться. К техническому багажу нам не привыкать.
Как поставщик облачных услуг, который управляет собственными серверами и оборудованием, мы столкнулись с проблемами, с которыми многие другие стартапы в новую эру облачных вычислений не сталкивались. Эти сложные ситуации в конце концов привели к компромиссу, на который нам пришлось пойти, когда компания только начала работать. И, как известно любой быстрорастущей компании, технические решения, которые вы принимаете на раннем этапе, обычно догоняют вас.
Глядя на нового сотрудника, я глубоко вздохнул и начал: «Давай я расскажу о том, как у нас было 15 000 прямых подключений к БД…»
История, которую я рассказал нашему новому сотруднику, – это история крупной технической перестройки DigitalOcean. Работала вся компания, эта работа продолжалась несколько лет и преподала нам много уроков.


Как всё начиналось
С самого начала DigitalOcean была одержима простотой. Стремление к простым и элегантным решениям – одна из наших основных ценностей. Это касается не только продуктов, но и технических решений. Более всего этот подход выделялся в первоначальной архитектуре системы.
Как и GitHub, Shopify и Airbnb, DigitalOcean начиналась как приложение Rails в 2011 году. Внутри компании приложение называли Cloud, оно управляло всеми взаимодействиями с пользователем как в интерфейсе пользователя, так и в общедоступном API. Сервису Rails помогали два сервиса Perl: Scheduler и DOBE (DigitalOcean BackEnd). Планировщик планировал и назначал дроплеты гипервизорам, а DOBE отвечал за создание реальных виртуальных машин дроплетов. В то время как Cloud и Scheduler работали как автономные службы, DOBE работал на каждом сервере парка машин.
Cloud, Scheduler, DOBE общались друг с другом не напрямую, а через базу данных MySQL, которая выполняла две роли: хранила данные и была посредником при обмене данными. Все три службы использовали одну таблицу базы данных в качестве очереди сообщений, чтобы передавать информацию.
Каждый раз, когда пользователь создавал новый дроплет, Cloud вставлял новую запись о событии в очередь. Scheduler непрерывно, каждую секунду опрашивал БД на предмет новых событий Droplet и планировал их создание на доступном гипервизоре. Наконец, каждый экземпляр DOBE ждал создания новых запланированных дроплетов и выполнял задачу. Чтобы серверы могли обнаружить любые новые изменения, каждому нужно было опросить базу данных на предмет новых записей в таблице.
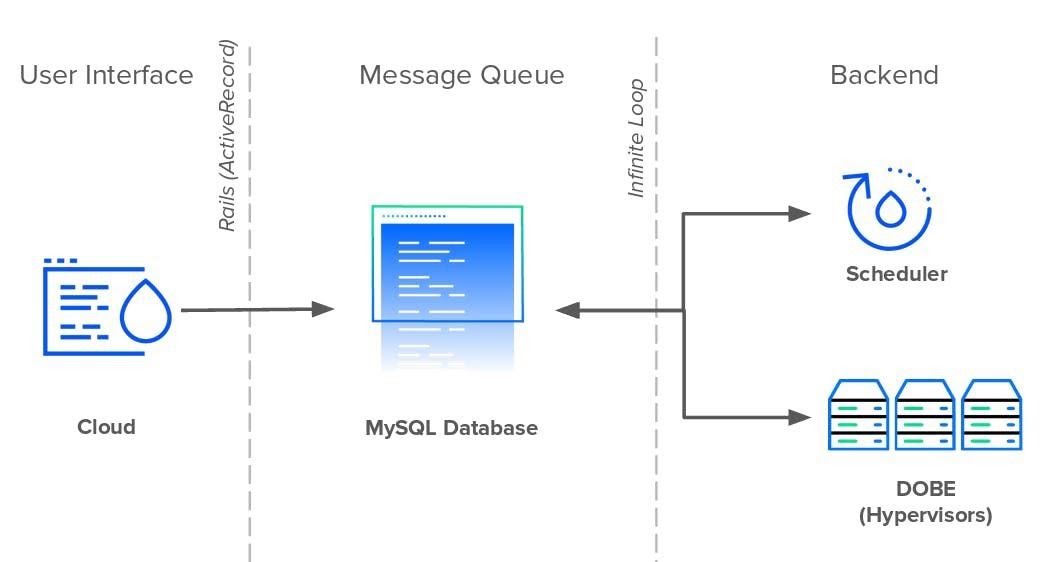
Хотя бесконечные циклы и прямое подключение каждого сервера к базе данных могли быть рудиментарными, с точки зрения проектирования системы, это было просто и работало – особенно для небольшой технической команды, которая сталкивалась с жёсткими сроками, а пользователей становилось всё больше.
Четыре года очередь сообщений базы данных составляла основу технологического стека DigitalOcean. В это время мы приняли архитектуру микросервисов, для внутреннего трафика заменили HTTPS на gRPC, вместо Perl внутренние сервисы стали писать на Golang. Однако все дороги по-прежнему вели к той самой базе данных MySQL.
Важно отметить, что если код – легаси, это не означает, что он не работает и его нужно переписать. У Bloomberg и IBM есть устаревшие сервисы, написанные на Fortran и COBOL, которые приносят доход больше, чем целые компании. С другой стороны, у каждой системы есть предел масштабирования. Мы собирались ударить по нашему.
С 2012 по 2016 год пользовательский трафик DigitalOcean вырос более чем на 10 000 %. Мы добавили больше продуктов в наш каталог и больше сервисов в нашу инфраструктуру. Событий в очереди базы данных стало больше. Повышенный спрос на дроплеты означал, что Scheduler, чтобы назначить их все серверам, работал с превышением штатной нагрузки. И, к сожалению для Scheduler, количество доступных серверов не было постоянным.
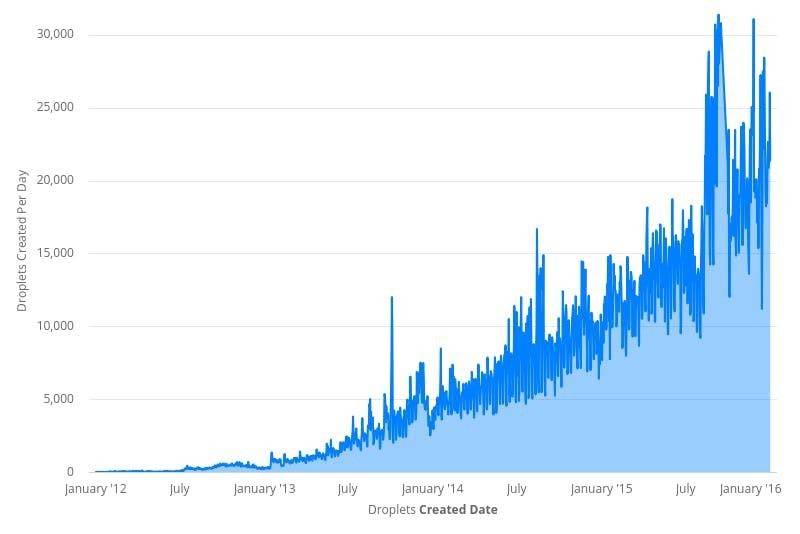
Чтобы не отставать от растущего спроса на дроплеты, мы добавляли всё больше и больше серверов для обработки трафика. Каждый новый гипервизор означал еще одно постоянное соединение с базой данных. К началу 2016 года у базы было более 15 000 прямых подключений, и каждое запрашивало новые события через одну-пять секунд. Если и этого было недостаточно, то SQL-запрос, который каждый гипервизор использовал для получения новых событий дроплет, также стал сложнее. Он превратился в колосс из более чем 150 строк и JOIN в 18 таблиц. Этот код впечатлял настолько же, сколько рискованно и трудно было его поддерживать.
Не удивительно, что именно тогда система треснула. Единая точка отказа с тысячами зависимостей, которые боролись за общие ресурсы, время от времени неизбежно обращалась в хаос. Таблицы блокировались и запросы не выполнялись, и это приводило к сбоям, падала производительность.
Из-за тесной связи в системе не было чёткого или простого решения проблемы. Cloud, Schedule и DOBE оказались узкими местами. Патчи только одного или двух компонентов сместили бы нагрузку на оставшиеся узкие места. Поэтому после долгих раздумий инженеры разработали план исправления из трёх пунктов:
- Уменьшить количество прямых подключений к базе данных.
- Переписать алгоритм ранжирования Scheduler, чтобы повысить доступность этого сервиса.
- Освободить БД от ответственности за очередь сообщений.
Переписываем код: начало
Чтобы справиться с зависимостями базы данных, инженеры DigitalOcean создали Event Router. Маршрутизатор событий служил региональным прокси-сервером, который опрашивал базу данных от имени каждого экземпляра DOBE в каждом центре обработки данных. Вместо тысяч серверов, каждый из которых запрашивает базу данных, осталась только горстка выполняющих запрос прокси. Каждый прокси-сервер маршрутизатора событий будет извлекать все активные события в определённом регионе и делегировать каждое событие соответствующему гипервизору. Event Router также разбил гигантский опрашивающий запрос на запросы, которые проще поддерживать.

Когда Event Router был запущен, он сократил количество подключений к базе данных с более чем 15 000 до менее 100.
Затем инженеры нацелились на планировщика. Как упоминалось ранее, Scheduler был сценарием Perl и определял, в каком гипервизоре разместить дроплет. Делалось это с помощью серии запросов, чтобы сортировать и ранжировать серверы. Всякий раз, когда пользователь создаёт дроплет, планировщик обновляет строку таблицы на лучшую машину.
Хотя это звучит достаточно просто, Scheduler имел несколько недостатков. Его логика была сложной, работать с ней было непросто. Он был однопоточным, и его производительность снижалась во время пиковой нагрузки. Наконец, был только один экземпляр Scheduler – и он должен был обслуживать весь парк. Это узкое место было неизбежным. Чтобы решить эти проблемы, команда инженеров разработала Scheduler V2.
В обновлённом планировщике переработали всю систему ранжирования. Вместо того чтобы запрашивать у базы данных показатели сервера, планировщик агрегировал их из гипервизоров и хранил в собственной базе данных. Кроме того, команда Scheduler применила параллелизм и репликацию, чтобы их новый сервис под нагрузкой оставался производительным.
Event Router и Scheduler v2 были большими достижениями, они устраняли многие недостатки архитектуры. Но даже с ними имела место большая препона [прим. перев. – это несколько удивительно, но слово препона женского рода]. К началу 2017 года централизованная очередь сообщений MySQL всё ещё использовалась. Она обрабатывала до 400 000 новых записей в день и обновлялась 20 раз в секунду.
К сожалению, удалить очередь сообщений из базы данных было нелегко. Сначала инженеры запретили сервисам прямой доступ к базе. База нуждалась в дополнительном уровне абстракции. Слою также требовался API, чтобы агрегировать и выполнять запросы от его имени. Если какой-либо сервис захочет создать новое событие, ему нужно будет сделать это через API. Так родился Harpoon.
Достичь согласия труднее, чем вы думаете

Однако создать интерфейс очереди сообщений было легко. Труднее оказалось достичь согласия с другими командами. Интеграция с Harpoon означала, что командам пришлось бы отказываться от доступа к базе данных, переписывать куски своего кода и, в конечном счёте, изменить свои привычки. Это было нелегко.
Команда за командой и сервис за сервисом инженеры Harpoon смогли перенести всю кодовую базу на свою новую платформу. На это ушёл почти год, но к концу 2017 года Harpoon стал единственным издателем очереди сообщений базы данных.
Началась настоящая работа. Полный контроль над системой событий означал, что с Harpoon мы получили свободу переосмыслить рабочий процесс дроплета.
Первой задачей Harpoon было взять на себя обязанности по очереди сообщений из базы данных. Для этого Harpoon создал собственную внутреннюю очередь сообщений, состоящую из RabbitMQ и асинхронных воркеров. Пока Harpoon отправлял новые события в очередь с одной стороны, воркеры забирали их с другой стороны. А поскольку RabbitMQ заменил очередь базы данных, воркеры могли напрямую общаться с планировщиком и маршрутизатором событий. Таким образом, вместо того чтобы Scheduler V2 и Event Router опрашивали базу данных на предмет изменений, Harpoon отправлял обновления к ним напрямую. На момент написания этой статьи, в 2019 году, архитектура событий дроплет всё ещё работает.
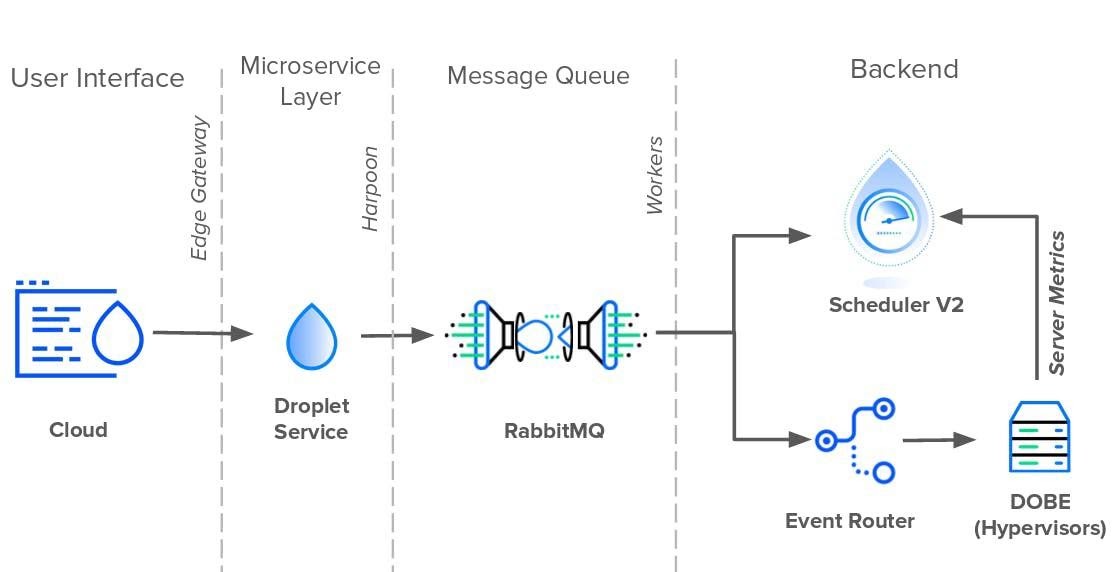
Прогресс DigitalOcean
За последние семь лет мы выросли из группы в гараже до признанного провайдера облачных сервисов, которым являемся сегодня. Как и другие технологические компании, которые занимались переходной экономикой, мы постоянно работаем с устаревшим кодом и техническим долгом. Будь то дробление монолитов, создание мультирегиональных сервисов или устранение единых точек отказа, мы, инженеры, всегда работаем, чтобы создать простые и элегантные решения. Я надеюсь, что эта история окажется полезной для других разработчиков, которые ломают голову над техническим долгом.

Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
- Профессия Data Scientist
- Профессия Data Analyst
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Java-разработчик
- Профессия Разработчик игр на Unity
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
КУРСЫ
- Курс по JavaScript
- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Курс «Алгоритмы и структуры данных»
- Курс «Python для веб-разработки»
- Курс по аналитике данных
- Курс по DevOps
