
Scrub — это процесс фоновой проверки консистентности данных в Ceph. Он позволяет выявить и устранить несоответствия в копиях, а также найти рассыпающиеся диски, чтобы вовремя их заменить. При этом сам Scrub может создавать высокую нагрузку на кластер и мешать другим процессам. Сегодня расскажем о настройках, которые помогут оптимизировать его работу и сделать нагрузку практически незаметной.
Статья подготовлена на основе лекции Александра Руденко, ведущего инженера в группе разработки «Облака КРОК». Лекция доступна в рамках курса по Ceph в «Слёрме».
Предыдущие материалы цикла по Ceph:
Флаги для управления состояниями OSD,
Флаги для управления восстановлением и перемещением данных.
Как работает Scrub
Scrub или scrubbing — это специальный фоновый процесс, который проверяет консистентность данных в placement group. Например, есть пул с тройной репликацией, то есть одна placement group в нём имеет три копии. Данные в этих копиях должны быть полностью идентичны, что и проверяет Scrub.
Если Scrub обнаруживает расхождения (например, в какой-то placement group объект имеет контрольную сумму не такую, как на двух других, либо вообще отсутствует), то возникает ошибка, администратор о ней узнаёт и может исправить.
В Erasure coded pool нет копий, но принцип тот же: Scrub выявляет расхождения в данных, неконсистентность, возникшую по тем или иным причинам. Одна из основных причин — «тихие» повреждения магнитных дисков. Вчера вы записали данные, а сегодня некоторые секторы на диске посыпались и данные оказались повреждены.
Scrub бывает двух типов: обычный и глубокий.
В примере на скриншоте четыре placement groups находятся в состоянии scrubbing, и они же находятся в состоянии scrubbing+deep. «Deep» — это значит глубокий Scrub.

Сначала всегда выполняется обычный Scrub, и только если он завершился успешно, запускается глубокий.
Обычный Scrub проверяет атрибуты и размер объектов. Он проходит быстро и незаметно с точки зрения нагрузки.
Глубокий Scrub читает практически каждый байтик объектов и сверяет их на всех OSD в рамках проверки одной placement group. То есть все данные читаются, проверяются их контрольные суммы и контрольные суммы сверяются. Это достаточно затратный по ресурсам процесс. Он может затрагивать несколько placement group сразу. В примере выше параллельно проверяются данные четырёх placement groups.
Максимальная частота проверки одной placement group — раз в сутки, чаще Scrub не запускается. При этом у процесса есть дедлайн: одна placement group должна быть проверена в течение недели. То есть Scrub может проходить раз в сутки, но не реже раза в семь дней. Если placement group не проверялась больше семи дней, то возникает сообщение об ошибке.
Пример такого сообщения на скриншоте. Здесь показано, сколько placement group не успело пройти проверку в отведённые 7 дней.

Когда Scrub находит различие в данных в одной placement group, возникает такая ошибка:
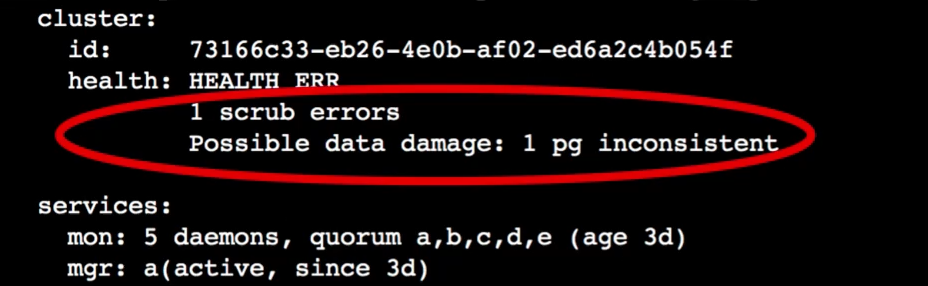
Первая строчка показывает, что есть ошибки scrub error, и сколько их. Вторая строчка говорит, в скольки placement group обнаружена неконсистентность данных. Такие алерты может выдавать только Scrub. По-другому вы не узнаете, что placement group в неконсистентном состоянии.
Фактически алерт говорит: по какой-то причине данные некорректно записались на одну OSD и нужно запустить процесс repair — восстановление консистентности.
Мы считаем процесс Scrub очень важным ещё и потому, что он позволяет выявлять повреждения дисков.
Во время проверки данные placement group читаются целиком. То есть в течение 7 дней 100% данных кластера оказываются прочитаны и сверены на разных OSD. В результате мы получаем проверку состояния дисков: способны ли они отдавать данные, работает ли чтение с них.
Scrub читает данные, которые пользователь, возможно, не читал несколько месяцев и не будет читать ещё год. Если при чтении на диске возникает проблема (например, сектор магнитного диска отказал), то это провоцирует ошибку.
В логе ядра Linux мы видим ошибку типа input/output error. Ceph сообщает, что возникла ошибка при проверке. В мониторинге появляется алерт, в котором фигурирует идентификатор диска. Мы понимаем, что на нём возникли input/output-ошибки, внимательно его смотрим и практически всегда меняем.
Управление проверкой
Если Scrub заканчивается с ошибкой, нужно выяснить детали: какая именно placement group в неконсистентном состоянии и на каких OSD она сейчас находится. Сделать это можно следующей командой:
$ ceph health detailВывод будет примерно такой:

После этого можно пойти в логи ядра конкретной OSD и проверить. Скорее всего там обнаружится ошибка ввода/вывода и станет понятно, что диск нужно менять.
Чтобы узнать, какую именно ошибку выдал Scrub, используйте команду:
$ rados list-inconsistent-obj {PG} | jqВ длинном выводе будет примерно такая секция, как на скриншоте ниже. В ней показаны OSD и состояния проблемного объекта на них.
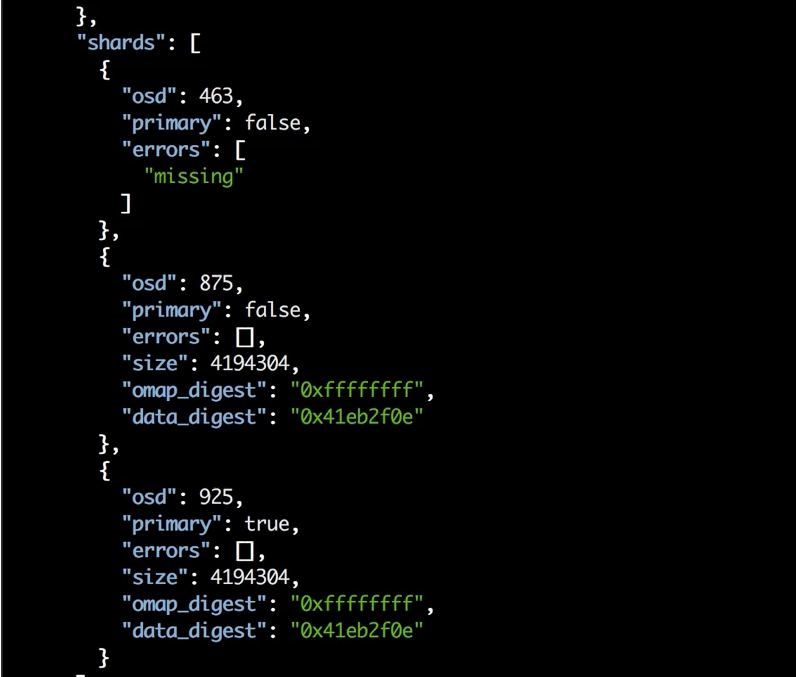
На скриншоте видно, что на двух OSD (875 и 925), в том числе и на primary, объект есть, у него есть есть контрольная сумма, а вот на третьей (463) его просто нет.
Когда есть primary-копия, и она корректная, можно запустить восстановление командой:
$ ceph pg repair {PG}Процесс repair может идти несколько часов. После этого в логе Ceph можно будет найти эту placement group по id и увидеть результат восстановления. Там будет написано, сколько ошибок исправлено, а сколько нет. Но когда большинство данных в порядке и повреждена только одна копия, процесс repair без проблем восстанавливает объект, беря его из primary OSD.
Оптимизация проверки
При всей полезности у скраббинга есть недостаток — он создаёт большую нагрузку. Когда идёт глубокий Scrub, данные из placement group читаются, чтение этих данных никак не отражается в системах мониторинга (это внутреннее io) и этот идущий Scrub может создавать нагрузку сам по себе. Раньше это была колоссальная нагрузка.
Кластеры на более ранних версиях сильно страдали от проверки. Scrub был невероятной проблемой. Можно было встретить много статей, как его лимитировать, чтобы он шёл медленнее и не создавал такую нагрузку.
Сейчас Scrub в Ceph стал более интеллектуальным, к нему прикрутили много параметров, которые позволяют его оптимизировать и практически в любом кластере сделать так, чтобы нагрузка от него не была сильно заметна.
Рассмотрим некоторые из этих параметров. Посмотрим на osd параметры, в которых есть слово “scrub”, так увидим все связанные с ним настройки.
ceph daemon osd.0 config show | grep osd | grep scrub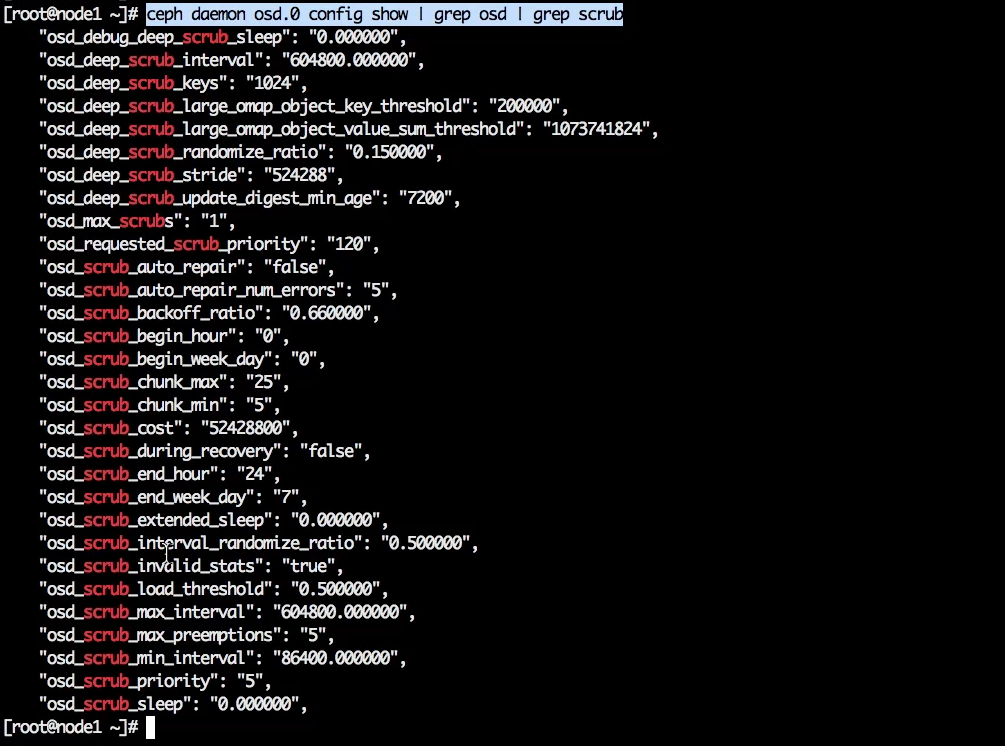
“osd_max_scrubs” — определяет, сколько placement group может параллельно «скрабить» одна OSD. По умолчанию стоит значение “1”, то есть Scrub максимально зажат.
Есть параметры, которые полезно настроить с самого начала:
“osd_scrub_begin_hour” и “osd_scrub_end_hour”. В нашем примере в первом параметре стоит значение “0”, во втором “24”, то есть процессу разрешено идти в любое время.
Поменяем значения: поставим время начала “02”, время окончания “08”:
ceph config set osd osd_scrub_begin_hour 02
ceph config set osd osd_scrub_end_hour 08Таким образом мы задаём желательный интервал времени для проверки.
Но есть важный момент: это будет работать хорошо только поначалу. Как только какие-то placement group не смогут из-за этого интервала успевать «скрабиться» в течение недели, Scrub будет запускаться сразу по истечении недельного срока, независимо от ограничений по времени. Дедлайн для Scrub критичнее, чем эти интервалы.
Иными словами, этими параметрами вы задаёте время, когда вы хотели бы, чтобы Ceph делал Scrub, если он может это делать. Если у него настал дедлайн для какой-то placement group, то он проигнорирует интервалы, потому что дедлайн критичен.
“osd_scrub_sleep” — ещё один важный параметр. Для обычного скраба его значение “0.00000”. Можно задать “0.1”, хотя для обычного Scrub это не особо важно.
“osd_debug_deep_scrub_sleep” — задаёт sleep для Deep Scrub. По умолчанию его значение тоже “0”, но мы его у себя ставим “0.2”.
Меняется значение параметра аналогично:
ceph config set osd osd_debug_deep_scrub_sleep 0.2Нужно понимать, что настройки Scrub в каждом кластере индивидуальны. Очень большие кластеры могут даже с дефолтными настройками не испытывать проблем. На кластерах меньшего размера он может быть заметен сильно. А если это кластер небольшого размера и у него ещё очень интенсивное io, то Scrub может быть проблемой.
“osd_scrub_chunk_max” и “osd_scrub_chunk_min” — это самые важные параметры, определяющие интенсивность проверки; то, что сильно зажимает или отпускает Scrub.
Если задать такое значение, то интенсивность идущего скраба упадёт в 5 раз — настолько медленнее будут читаться данные.
ceph config set osd osd_scrub_chunk_min 1
ceph config set osd osd_scrub_chunk_max 4Хотя скорее всего, вы не заметите никакого эффекта, но получите алерты о том, что placement group не успевают пройти Scrub вовремя. Просто потому что слишком мало объектов берётся за одну итерацию, слишком медленное чтение.
Этими параметрами вы можете играть, задавая различные значения, чтобы достигнуть того баланса, когда Scrub успевает проходить за неделю и при этом не создаёт видимой нагрузки. Они меняются на лету, и вы можете ими в любой момент ускорять или зажимать Scrub.
“osd_scrub_auto_repair” — ещё один интересный параметр. В начале статьи вы видели ошибку о том, что placement group в состоянии inconsistent. Если в значении этого параметра поставить “false”, то Ceph запустит repair на эту placement group, но только если количество ошибок до 5. Если ошибок больше, то он не запустит автоматический repair, будет висеть ошибка, и вам надо будет посмотреть, что же произошло. Ceph считает, что повреждённых объектов слишком много, чтобы их автоматически чинить. Нужно разобраться, в чём дело.
“osd_scrub_during_recovery” — это относительно новый параметр. Если он активирован, то Scrub не будет запускаться, когда на OSD запущен backfilling, то есть идёт recovery io. Если у вас будет настроен когда-нибудь мониторинг текущего количества скрабов, то вы сможете увидеть, как во время запущенного rebalance график скрабов начинает стремительно снижаться.
Scrubbing io старается не конфликтовать с recovery io, и это ещё одна причина, по которой Scrub может откладываться. Если вы в течение недели делаете сильный rebalance — увеличиваете число placement group, добавляете сервер — Scrub откладывается, и через неделю вы получите множество сообщений о том, что Scrub не успел пройти за неделю, и вам нужно будет его либо ускорить, либо ждать, пока он «рассосётся».
Общая рекомендация: если вы видите проблему аномальной производительности в кластере и не понимаете, в чём дело, вы всегда можете отключить Scrub с помощью флагов:
Обычный:
ceph osd set noscrubГлубокий:
ceph osd set nodeep-scrubКроме того, скраб можно отключать для конкретного пула. Если у вас несколько пулов, и вы хотите для конкретного пула отключить скраб, то это можно сделать командой:
ceph osd pool set {name} noscrub 1
ceph osd pool set {name} nodeep-scrub 1Флаги отразятся в cluster health:

Эти флаги блокируют новый Scrub, но уже запущенные проверки не отклоняются и будут завершены. Когда текущие проверки закончатся, вы сможете оценить, изменилась ли ситуация с производительностью.
Если проблема исчезла, значит вам нужно немного зажать Scrub. Если сохранилась, то дело не в Scrub, его можно запускать снова и искать другую причину аномальной производительности.
