
Цепочка поставок в пищевой промышленности и ритейле — это сложная, медленная и ненадёжная система. В этой статье мы рассмотрим развёртывание Apache Kafka для обработки данных в реальном времени в таких сферах, как производство, логистика, розничная торговля, доставка, рестораны и другие части бизнеса. Это будут примеры из настоящих компаний: Walmart, Albertsons, Instacart, Domino’s Pizza, Migros и т. д.
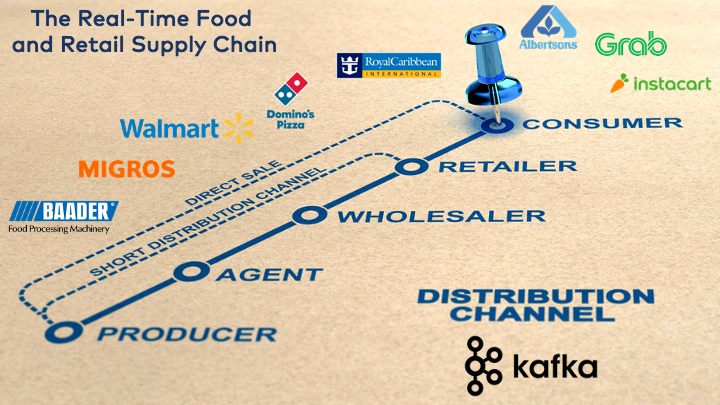
Цепочка поставок в пищепроме и ритейле
Пищевая промышленность — это сложная глобальная сеть из различных компаний, которая кормит большую часть населения Земли. Ничего общего с этой картинкой:

Компании в этой отрасли занимаются производством, распределением, обработкой, переработкой, приготовлением, консервированием, транспортировкой, сертификацией и упаковкой разной еды.
Современная пищевая промышленность очень многообразна. Это и небольшие семейные компании, где многое делается вручную, и корпорации с автоматизированными и механизированными процессами производства.
В этой статье мы рассмотрим примеры, в которых удалось улучшить цепочку поставок и бизнес-процессы с помощью возможностей обработки в реальном времени.
Почти все компании из примеров используют Kafka для различных задач. Иногда их сферы деятельности пересекаются. В следующих разделах приводятся настоящие примеры из настоящих компаний. Вместе они составляют полную цепочку поставок на основе сервисов в реальном времени в пищевой промышленности и ритейле.
Зачем в пищепроме и ритейле нужна потоковая обработка данных в реальном времени с помощью Apache Kafka?
Почему я вообще стал собирать примеры и решил написать эту статью?
В феврале 2022 года я полетел во Флориду, чтобы встретиться с заказчиками. Я много путешествую и часто сталкиваюсь с разными неудобствами. Так совпало, что все беды, описанные ниже, случились со мной в одни выходные.
Как ручные процессы и пакетная обработка испортили мне путешествие
Проблема первая — в отеле. Я отменил бронь за неделю до этого, но всё равно получал по почте сообщения с предложением купить апгрейд. Их присылала система пакетной обработки в движке бронирования. Что характерно, я не получал таких предложений для новой брони в этой же сети.
Проблема вторая — в магазине одежды. Кассовый терминал не работал из-за перебоев с электричеством и интернетом. Обрабатывать платежи было невозможно, люди уходили без покупок. Мне очень нужна была одежда, потому что в моем отеле из-за нехватки персонала не работала прачечная.
Проблема третья — в ресторане. Я пытался поужинать в стейк-хаусе, но из-за тех же перебоев с электричеством терминал не работал. Официант не мог принять заказ. В отдельную программу на кухне нельзя было вбить заказы от официанта вручную.
Проблема четвертая — в ресторане. Через полчаса у меня наконец приняли заказ, но выбранного десерта не было в наличии. Оказалось, поставщик его не завозил, а бумажное меню и PDF онлайн никто не удосужился обновить.
Проблема пятая — в магазине одежды. После ужина я вернулся в магазин одежды. Касса работала, но у меня спросили имейл, чтобы дать скидку 15%. Я удивился, что у них не было моих данных из программы лояльности. Их можно было получить, например, на основе местоположения. Или я мог бы войти и заплатить через мобильное приложение.
Проблема шестая — отель. На выезде из отеля я заметил, что они не добавили мой бонус лояльного клиента (скидку на питание в ресторане), потому что система поддерживает только пакетную интеграцию с другими приложениями. В чеке не отображалась информация из программы лояльности и правильная сумма. Мне пришлось с этим смириться, хотя по немецкому налоговому законодательству это вообще незаконно.
Моя печальная история показывает, как важна цифровая трансформация в пищепроме, ритейле и туристической отрасли. Я уже писал о потоковой обработке данных с Apache Kafka в авиации и туризме. Здесь мы поговорим о пищевой промышленности и ритейле, но, в целом, всё это применимо и в других отраслях.
В следующих разделах вы увидите, что с правильными технологиями не так уж и сложно оптимизировать бизнес-процессы, автоматизировать задачи и улучшать клиентский опыт.
Цифровая трансформация с автоматизированными бизнес-процессами и сервисами в реальном времени в цепочке поставок
После всего, что со мной случилось в те выходные, я решил собрать реальные примеры из цепочки поставок в пищепроме и ритейле. Некоторые компании уже вовсю внедряют инновации — оцифровывают бизнес-процессы и создают новые сервисы с обработкой данных в реальном времени.
Аналитика IoT для оборудования от Baader
BAADER — это крупный производитель инновационного оборудования для пищевой промышленности. У них есть цепочка создания ценности на базе IoT и данных в Confluent Cloud.
Инфраструктура на основе Kafka предоставляет единый источник истины для всех заводов во всех регионах по всей цепочке создания ценности. Критические операции доступны круглосуточно для отслеживания, расчётов, оповещений и т. д.
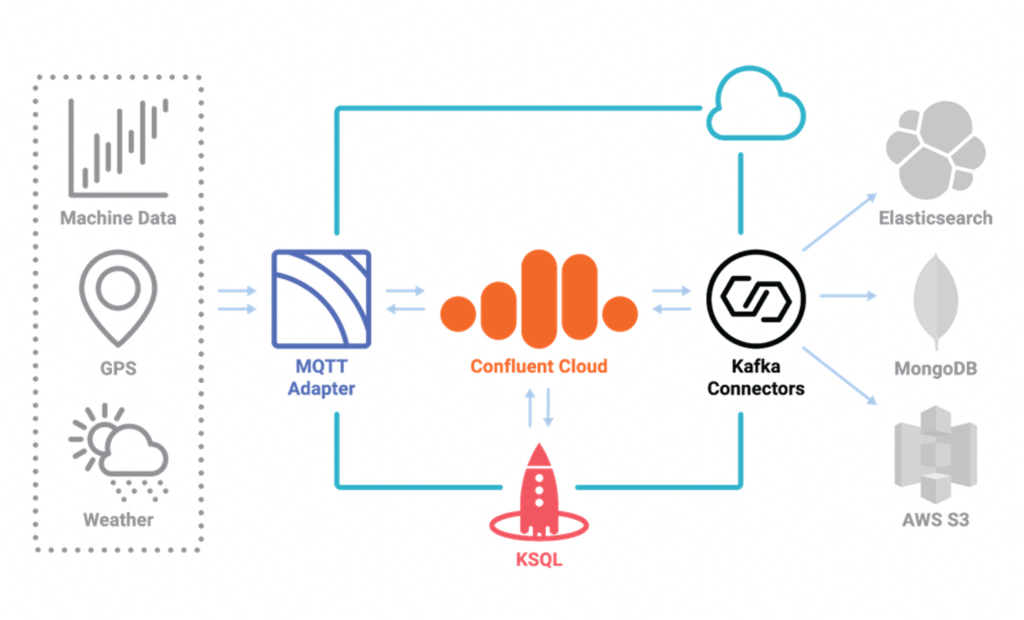
Платформа потоковой обработки событий работает на Confluent Cloud, поэтому у Baader есть всё необходимое для создания инновационных бизнес-приложений. Бессерверная инфраструктура Kafka обеспечивает критичные SLA с оплатой за потребление всех нужных возможностей: обмен сообщениями, хранение, интеграция данных и обработка данных.
MQTT используется для подключения к оборудованию и GPS-данных с автомобилей на границе сети. Коннекторы Kafka Connect интегрируют MQTT и другие ИТ-системы, например Elasticsearch, MongoDB и AWS S3. ksqlDB непрерывно обрабатывает данные при передаче.
У меня была статья про Kafka и MQTT для прочих применений IoT с примерами.
Логистика и отслеживание по всей цепочке поставок в Migros
Migros — крупнейшая розничная компания, крупнейшая сеть супермаркетов и крупнейший работодатель в Швейцарии. Они используют MQTT и Kafka, чтобы в реальном времени визуализировать и обрабатывать данные по логистике и перевозкам.
Как рассказали сами ребята из Migros на митапе по Kafka в Швейцарии, они оптимизировали цепочку поставок, создав единый конвейер потоковой обработки данных, причём не только для ситуаций, когда данные требуются в реальном времени, но и для обработки прошедших событий.
Цель — создать одну глобальную систему вместо четырёх локальных. В логистике, например, они используют эту архитектуру, чтобы прогнозировать время прибытия грузовиков и корректировать график.
Оптимизация управления запасами и пополнения запасов в Walmart
Walmart использует Kafka по всей цепочке поставок во всём своём огромном масштабе. Как сказал вице-президент Walmart Cloud: «Walmart зарабатывает 500 млрд долларов в год, у нас каждая секунда стоит миллионы. Сотрудничество с Confluent для нас бесценно. Kafka и Confluent поддерживают нашу цифровую трансформацию по всем каналам и помогают Walmart закрепить успех».
В цепочку поставок в реальном времени входит система управления запасами Walmart. В этой же инфраструктуре они создали систему пополнения запасов в реальном времени:

Вот что они в двух словах рассказали об этой системе на Kafka Summit.
Обслуживает миллионы покупателей онлайн и в магазинах.
Поддерживает оптимальный уровень запасов и своевременную доставку онлайн-заказов.
Каждый день за 3 часа обрабатывает более 4 млрд сообщений, чтобы составить точный план заказов для всей сети магазинов Walmart.
Apache Kafka используется как хаб данных и для обработки в реальном времени.
Apache Spark используется для микропакетов.
С точки зрения затрат и эффективности операций, ценность такой системы очевидна: быстрая обработка, высокая точность, упрощение, эластичность, масштабируемость, повышенная отказоустойчивость, экономия расходов.
Кстати, это одно из многих применений Kafka в Walmart. Посмотрите или почитайте другие выступления на Kafka Summit про разные варианты использования.
Омниканальное управление заказами в ресторанах Domino’s Pizza
Domino’s Pizza — это международная сеть, куда входит около 17 тысяч пиццерий. Из традиционной компании по продаже пиццы они превратились в организацию на основе данных, занимающуюся электронной коммерцией. Принимая решения, они руководствуются данными и интересами клиентов.
Покупатели франшизы Domino’s Pizza могут в реальном времени просматривать информацию о работе ресторанов, в том числе такие KPI, как объем заказов по каналу и метрики эффективности пиццерии по разным каналам заказов.
Созданный в Domino’s Pizza хаб данных в реальном времени помогает оптимизировать цепочку поставок благодаря следующим возможностям и преимуществам:
Улучшенная аналитика работы пиццерий в реальном времени.
Модернизация традиционных ИТ-систем в поддержку глобального расширения бизнеса.
Персонализация маркетинговых кампаний.
Единая панель мониторинга в реальном времени.
Сервисы на основе местоположения и апселлинг в точках продаж в Royal Caribbean
Royal Caribbean — это круизная компания, которой принадлежат четыре крупнейших пассажирских лайнера в мире. На январь 2021 года у компании было 24 лайнера, ожидалось ещё 6.
Royal Caribbean реалиузует самый известный вариант применения Kafka на границе сети. У каждого круизного лайнера есть локальный кластер Kafka, который используется для обработки платежей, информации из программы лояльности, рекомендаций для пассажиров и т. д.:
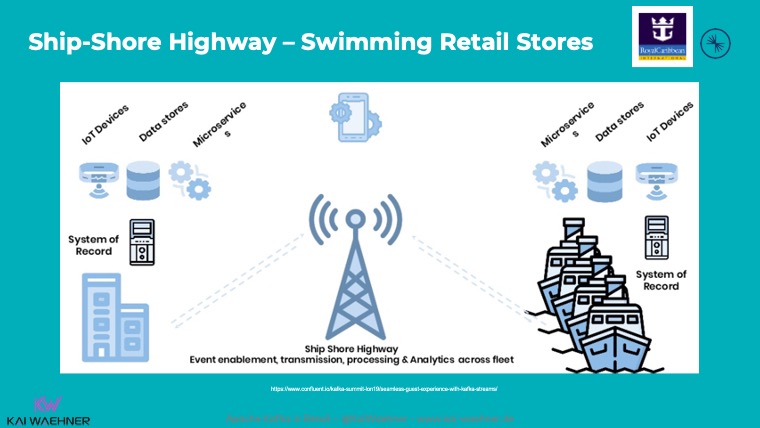
Пограничные вычисления на лайнерах необходимы Royal Caribbean, чтобы поддерживать эффективную цепочку поставок и превосходный клиентский опыт:
На лайнерах плохое и дорогое подключение к интернету.
Пограничные вычисления в реальном времени улучшают опыт клиентов и повышают доход.
Все данные о круизах собираются в облаке для аналитики и отчётности, чтобы улучшать клиентский опыт, использовать возможности для апселлинга и поддержать многие другие бизнес-процессы.
Кластер Kafka на каждом корабле отвечает за локальную обработку и надёжность критичных рабочих нагрузок. Хранилище Kafka гарантирует сохранность данных и упорядоченность событий, даже если обрабатываться они будут потом. Напрямую в облако отправляются только самые важные данные (если удаётся поймать интернет). Остальная информация реплицируется в центральный кластер Kafka в облаке, когда лайнер на несколько часов заходит в порт, где есть хорошее подключение к интернету.
Читайте больше о вариантах применения и архитектуре для Kafka на границе сети.
Рекомендации и скидки на платформе лояльности в Albertsons
Albertsons — вторая по величине продуктовая компания в Америке, более 2200 магазинов и 290 тысяч сотрудников.
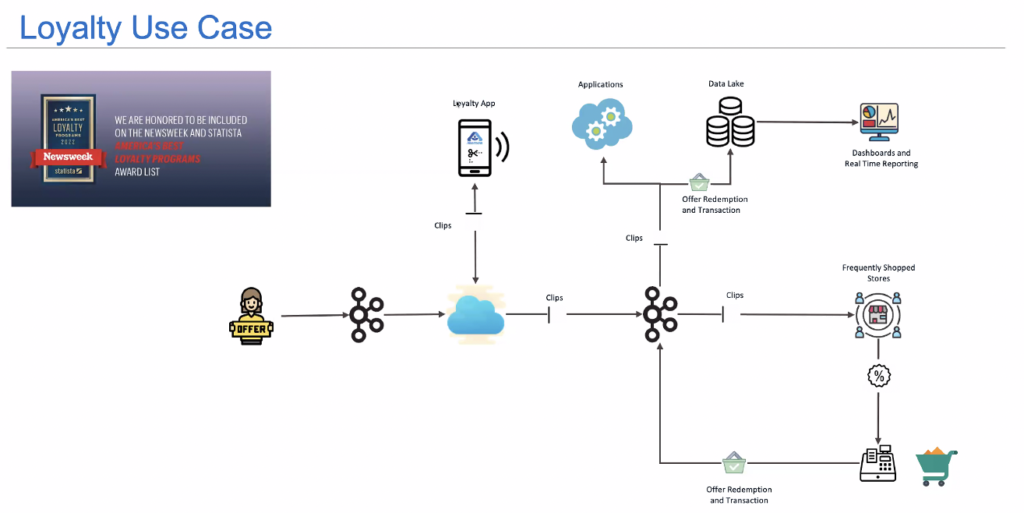
Albertsons использует Kafka с Confluent как хаб данных в реальном времени, чтобы:
Обновлять информацию о запасах из 2200 магазинов в облачных сервисах почти в реальном времени, чтобы отслеживать запасы и предлагать замену онлайн-покупателям.
Распространять предложения и купоны по магазинам почти в реальном времени и улучшать покупательский опыт при оплате покупок.
В реальном времени отправлять данные в аналитические движки, чтобы прогнозировать заказы в цепочке поставок, управлять заказами на складе, доставлять заказы, прогнозировать потребности в персонале, управлять персоналом, планировать спрос и управлять запасами.
Почти в реальном времени отправлять данные о транзакциях в озеро данных для пакетной обработки, чтобы затем создавать дашборды для продавцов и руководства, обучать модели данных и персонализировать покупательский опыт.
Вот так, например, выглядит в Albertsons архитектура потоковой обработки данных для платформы лояльности в реальном времени:
Обработка платежей и выявление мошенничества в Grab
Grab — это что-то вроде азиатского Uber. Все подобные сервисы активно используют экосистему Kafka. Как и FREE NOW, Grab использует управляемый облачный сервис Confluent Cloud, чтобы заниматься бизнес-логикой, а не обслуживанием архитектуры.
У Grab есть свой сервис GrabDefence для обработки платежей и обнаружения мошенничества. Платформа использует Kafka Streams и машинное обучение для stateful потоковой обработки и обнаружения мошенничества в реальном времени и в большом масштабе.

Grab сталкивается с миллионами сомнительных транзакций в день. Компания теряет 1,6% доходов на мошенничестве в Юго-Восточной Азии. Инженеры и специалисты по data science из Grab создали платформу для поиска аномальных и подозрительных транзакций, а также пользователей с высоким риском.
Вот пример мошенничества: пользователь зарегистрирован как водитель и как пассажир и сам себе переводит оплату, чтобы получить скидку.
Доставка и самовывоз в Instacart
Instacart — это сервис по доставке и самовывозу продуктов в США и Канаде. Продукты заказываются в розничных магазинах, а заказы собирают сотрудники.
Instacart нужна была платформа, которая поддерживает эластичное масштабирование и быстрое внедрение обработки данных в реальном времени. Они выбрали Confluent Cloud, чтобы сосредоточиться на бизнес-логике и быстрее выкатывать новые функции приложения. Во время пандемии им пришлось уложить десять лет постепенного роста в полтора месяца. Это возможно только с нативными облачными и бессерверными технологиями передачи данных.
Узнайте больше из разговора между основателем Confluent Джуном Рао и представителем Instacart на Kafka Summit.
С Kafka можно улучшить каждый этап цепочки поставок
В этой статье мы рассмотрели практические примеры того, как обработка данных в реальном времени повышает операционную эффективность, сокращает расходы и улучшает клиентский опыт.
Экосистема Apache Kafka помогает создавать инновации в любом масштабе в сфере производства, логистики, розничной торговли, доставки и обслуживания клиентов. А в облаке бессерверное решение Kafka позволяет компаниям сосредоточиться на создании решений и ценности для бизнеса..
А как вы оптимизируете цепочку поставок? Вы используете потоковую обработку данных? Вы используете Apache Kafka для обработки данных в реальном времени? Или вы предпочитаете другой инструмент?
От редакции
Если хотите больше узнать про Kafka и прокачаться в ней, у Слёрма есть 2 курса:
— Курс «Apache Kafka База»: познакомимся с технологией, научимся настраивать распределённый отказоустойчивый кластер, отслеживать метрики, равномерно распределять нагрузку.
— Видеокурс «Apache Kafka для разработчиков». Это углублённый интенсив с практикой на Java или Golang и платформой Spring+Docker+Postgres. Интенсив даёт понимание, как организовать работу микросервисов и повысить общую надежность системы.
Купить комплектом 2 курса выгоднее на 30%: https://slurm.club/3y3tWCr
