Сейчас о мониторинге не пишет только мёртвый тот, у кого его нет. У нас в Тензоре мониторинг есть – это наша собственная система сбора метрик (хотя это далеко не единственное её назначение), тесно интегрированная с Zabbix.
Если вам интересно, как устроен мониторинг 5K серверов в нашей компании, с какими проблемами нам приходилось сталкиваться на пути к 1.5M метрик, 65K значений в секунду и текущему решению и как мы вообще докатились до жизни такой, добро пожаловать под кат.

Давно-давно, еще в 90-х, Тензор разрабатывал не нынешние web-сервисы с миллионами пользователей, а обычное десктоп-приложение – систему для ведения складского и бухгалтерского учета. Это было обычное, максимум с сетевой БД, приложение, которое работало на «железе» клиента. Бухгалтеры готовили в нем отчетность, печатали и носили «ножками» в налоговую.
Из всех «серверных» мощностей у нас самих тогда было всего ничего – пара серверов у программистов для сборки релиза да сервер с корпоративной БД учетной системы. За ними «вполглаза» приглядывали пара «админов», чьим основным занятием был хелпдеск пользователей.
Потом мы смогли избавить своих клиентов-бухгалтеров от походов в госорганы – наше десктопное приложение все так же помогало им готовить отчеты, но посылало их в налоговую уже само – через наш сервер по почтовому протоколу.
Если кто-то считает, что «обмен почтой с налоговой» – это просто пара почтовых серверов, то это сильно не так. Сюда добавляется «горка» проприетарных софтовых и хардварных решений для обеспечения защищенных каналов, своих для каждого госоргана – ФНС, ПФ, Росстат, … много их. И у каждого такого решения свои «заморочки»: требования к ОС, «железу», регламенту обслуживания…
Понятно, что такой принцип работы потребовал роста серверных мощностей на нашей стороне, и «пары админов» перестало хватать на все задачи. В этот момент у нас наметилась специализация «админов», которая сохранилась и по сей день, хоть их и стало уже больше 70 человек:
В этот момент мы поняли, что без какой-то разумной автоматизации мониторинга за всем этим «зоопарком» быстро погрязнем под ворохом проблем.

Собственно, весь мониторинг нужен только для одной задачи – обнаружения аномалий/проблем в наблюдаемой системе. Причем чем раньше – тем лучше, в идеале – еще до того, как проблема случится. А если уж случилась, мы должны иметь возможность проанализировать всю снятую информацию и понять, что же к ней привело.
Фактически, весь цикл разработки мониторинга выглядит так:
Ну, например, бывает, что на сервере кончается память. Технически причины могут быть разными («не отпустил вовремя», «течет приложение», «не сработал GC», …), но симптоматика почти всегда одинаковая – постепенно объем занятой памяти становится все больше и больше.
Многие любят мониторить «свободную память», но это не совсем правильно, – поскольку при активно использующемся pagecache ее может практически не быть даже в нормальных условиях.

Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Соответственно, если мы проанализируем динамику роста и текущее состояние, то вовремя поймем, в какой момент уже пора переставать надеяться на «само рассосется», и пора поднимать тревогу.
На разных этапах в качестве ядра системы мониторинга мы успели попробовать Nagios, Graphite и остановились на Zabbix, который вполне успешно используем и по сей день для наблюдения за несколькими тысячами серверов. За несколько лет мы накопили немалый опыт его эксплуатации, администрирования и тюнинга. И всё это время он довольно неплохо справлялся со своими задачами.
Тем не менее мы наступили, наверное, на все возможные и невозможные грабли. А это –самый полезный опыт.
Итак, основные проблемы, с которыми мы столкнулись (внимание! далее по тексту присутствует много боли и страданий):
Служба эксплуатации поздно узнавала о проблемах инфраструктуры, а разработчики не имели инструмента для анализа эффективности своих решений. В конечном счёте, всё это, так или иначе сказывалось на эффективности наших решений.
 После осознания того факта, что наш мониторинг – это собрание неправильных архитектурных решений (не знаю, можно ли считать отсутствие архитектуры архитектурным решением), мы решили что так больше жить нельзя. И начали думать, как исправить все описанные недостатки, но без радикальных решений, вроде замены Zabbix на что-то другое. Всё-таки, отказываться от накопленного опыта и пытаться искоренить многолетние привычки – наверное, не лучшая затея. Zabbix – это отличный инструмент, если правильно им пользоваться.
После осознания того факта, что наш мониторинг – это собрание неправильных архитектурных решений (не знаю, можно ли считать отсутствие архитектуры архитектурным решением), мы решили что так больше жить нельзя. И начали думать, как исправить все описанные недостатки, но без радикальных решений, вроде замены Zabbix на что-то другое. Всё-таки, отказываться от накопленного опыта и пытаться искоренить многолетние привычки – наверное, не лучшая затея. Zabbix – это отличный инструмент, если правильно им пользоваться.
Для начала мы определили для себя следующие критерии, что хочется получить:
Поскольку Zabbix оперирует в качестве объекта мониторинга «хостом», а нам нужен был «сервис» (например, конкретный из нескольких развернутых на одной машине экземпляров СУБД), мы зафиксировали определённые правила именования хостов, сервисов, метрик и комплексных экранов так, чтобы они не «ломали» ни логику Zabbix, ни «человекопонятность»:
К примеру: some-db.pgsql.5433:db.postgres. Если порт дефолтный, то он не указывается для облегчения восприятия.

Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Мы так и не дали этой системе имя, но внутри компании закрепилось рабочее название “sbis3mon”, а кое-кто с лёгкой руки назвал его “красивый мониторинг”. Почему красивый? Мы постарались сделать его не просто функциональным, но и наглядным.


Изображение кликабельно, открывается в текущей вкладке веб-браузера.
На данный момент мы уже разработали десятки модулей для мониторинга различного оборудования и сервисов, используемых в Тензоре:
В ближайших планах также стоит мониторинг MySQL, сетевого оборудования и сервисов телефонии (Asterisk).
В качестве платформы мы выбрали Node.js – из-за развитой экосистемы, асинхронности, простоты работы с сетью, легкости масштабирования (модуль cluster) и скорости разработки.
Также мы приняли на вооружение подход Continuous Delivery и стали приделывать крылья самолёту на лету. Благодаря частым релизам, мы быстро получали фидбэк и могли корректировать направление разработки. Система строилась на глазах у основных наших пользователей – сотрудников службы эксплуатации, при этом они продолжали использовать привычную оболочку мониторинга. Постепенно мы заменяли старые методы мониторинга на новые, пока не изжили их совсем.
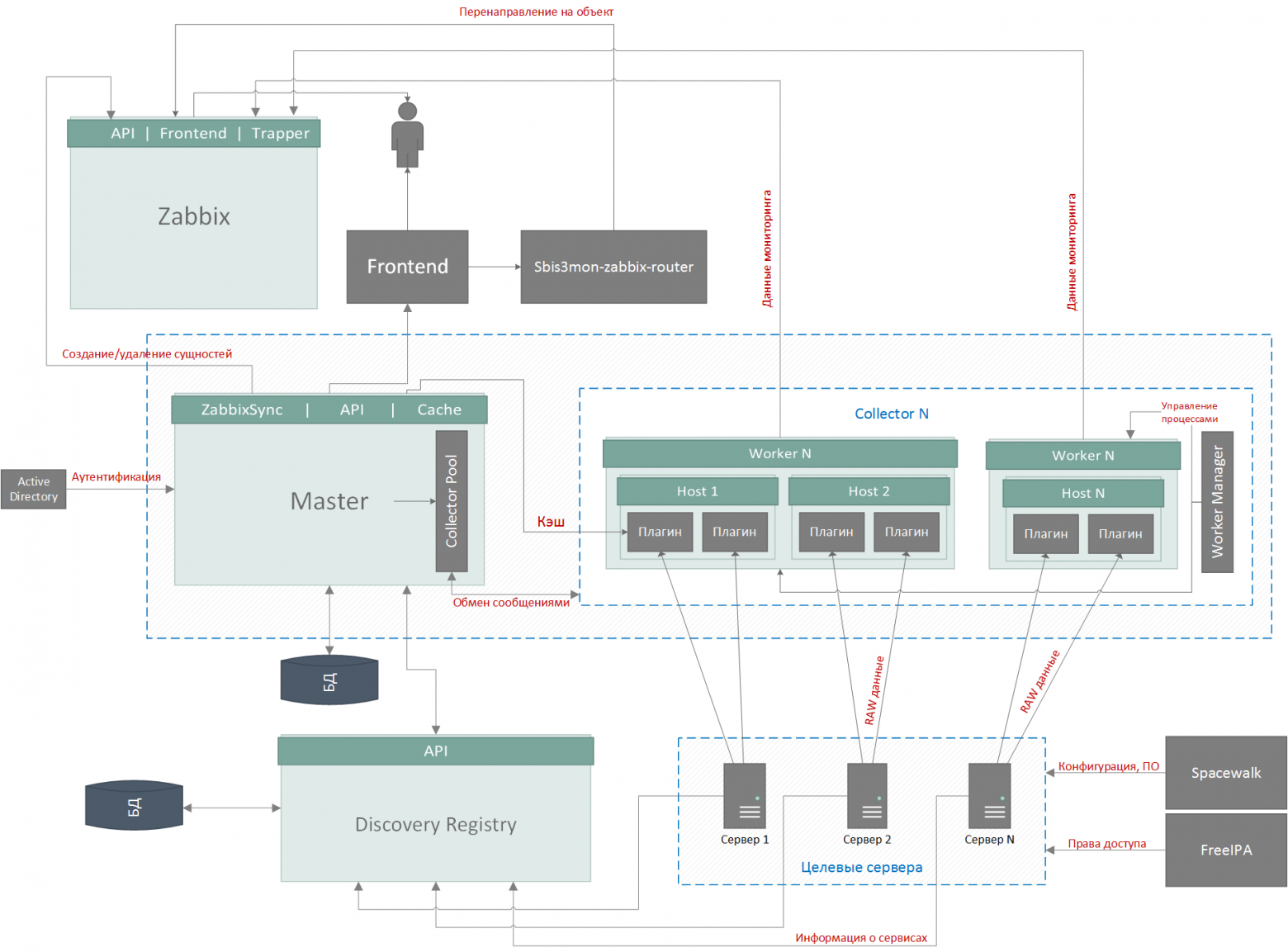
Система строится на микросервисной архитектуре и состоит из 5 основных частей:
В качестве СУБД мы используем PostgreSQL. Но база тут вторична и не очень интересна – там хранятся настройки хостов и сервисов, обнаруженные сущности, ссылки на ресурсы Zabbix и записи аудитлога, и никакого highload.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Самое интересное – сервисы. Они могут работать как на одном сервере, так и на разных.
Мастер и коллекторы имеют общую кодовую базу – ядро. В зависимости от параметров запуска процесс становится либо мастером, либо коллектором.
Функции мастер-процесса:
Функции коллекторов:
Сейчас наши несколько тысяч хостов и десятки тысяч сервисов на них обслуживаются коллекторами, живущими всего на двух серверах, на 40 и 64 ядра, со средней нагрузкой порядка 20-25% – то есть мы легко выдержим и дальнейший рост нашего серверного парка еще в 3-4 раза.
В следующей части мы расскажем более детально о тех решениях, которые позволили нашему мониторингу выдерживать рост нагрузки и требований пользователей, пока Тензор превращался из оператора по сдаче отчетности в настоящего мультисервисного провайдера услуг с миллионами пользователей онлайн.
Авторы: vadim_ipatov (Вадим Ипатов) и kilor (Кирилл Боровиков)
Если вам интересно, как устроен мониторинг 5K серверов в нашей компании, с какими проблемами нам приходилось сталкиваться на пути к 1.5M метрик, 65K значений в секунду и текущему решению и как мы вообще докатились до жизни такой, добро пожаловать под кат.

Когда деревья были большими
Давно-давно, еще в 90-х, Тензор разрабатывал не нынешние web-сервисы с миллионами пользователей, а обычное десктоп-приложение – систему для ведения складского и бухгалтерского учета. Это было обычное, максимум с сетевой БД, приложение, которое работало на «железе» клиента. Бухгалтеры готовили в нем отчетность, печатали и носили «ножками» в налоговую.
Из всех «серверных» мощностей у нас самих тогда было всего ничего – пара серверов у программистов для сборки релиза да сервер с корпоративной БД учетной системы. За ними «вполглаза» приглядывали пара «админов», чьим основным занятием был хелпдеск пользователей.
Потом мы смогли избавить своих клиентов-бухгалтеров от походов в госорганы – наше десктопное приложение все так же помогало им готовить отчеты, но посылало их в налоговую уже само – через наш сервер по почтовому протоколу.
Если кто-то считает, что «обмен почтой с налоговой» – это просто пара почтовых серверов, то это сильно не так. Сюда добавляется «горка» проприетарных софтовых и хардварных решений для обеспечения защищенных каналов, своих для каждого госоргана – ФНС, ПФ, Росстат, … много их. И у каждого такого решения свои «заморочки»: требования к ОС, «железу», регламенту обслуживания…
Понятно, что такой принцип работы потребовал роста серверных мощностей на нашей стороне, и «пары админов» перестало хватать на все задачи. В этот момент у нас наметилась специализация «админов», которая сохранилась и по сей день, хоть их и стало уже больше 70 человек:
- helpdesk – обслуживают работу локальных пользователей в наших офисах;
- sysop – отвечают за «железо», сети и работу системного ПО;
- devop – занимаются всей работой прикладного ПО (как нашего, так и стороннего) на этом самом «железе».
В этот момент мы поняли, что без какой-то разумной автоматизации мониторинга за всем этим «зоопарком» быстро погрязнем под ворохом проблем.

Back to the Future
Собственно, весь мониторинг нужен только для одной задачи – обнаружения аномалий/проблем в наблюдаемой системе. Причем чем раньше – тем лучше, в идеале – еще до того, как проблема случится. А если уж случилась, мы должны иметь возможность проанализировать всю снятую информацию и понять, что же к ней привело.
Фактически, весь цикл разработки мониторинга выглядит так:
- ищем причины, приводящие к возникновению проблемы;
- понимаем, какие метрики можно использовать для прогнозирования ситуации;
- учимся их снимать, хранить и понятно показывать;
- реализуем «предсказывающие» триггеры, которые уведомляют дежурного.
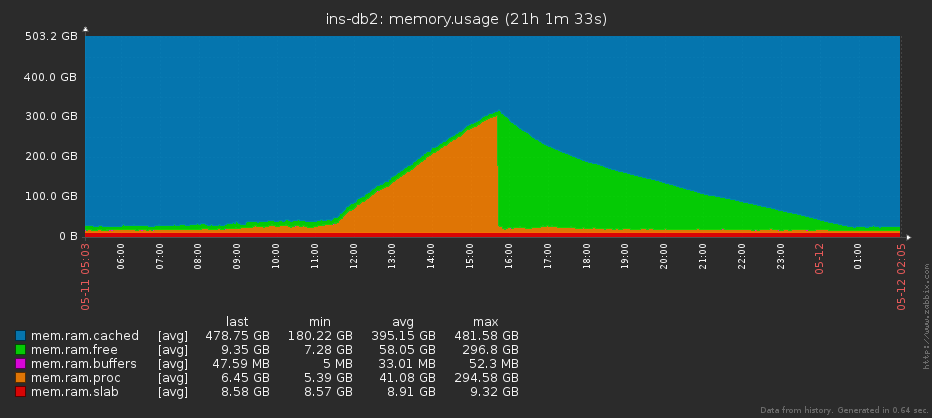
Ну, например, бывает, что на сервере кончается память. Технически причины могут быть разными («не отпустил вовремя», «течет приложение», «не сработал GC», …), но симптоматика почти всегда одинаковая – постепенно объем занятой памяти становится все больше и больше.
Многие любят мониторить «свободную память», но это не совсем правильно, – поскольку при активно использующемся pagecache ее может практически не быть даже в нормальных условиях.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Соответственно, если мы проанализируем динамику роста и текущее состояние, то вовремя поймем, в какой момент уже пора переставать надеяться на «само рассосется», и пора поднимать тревогу.
Мониторинг проблем и проблемы мониторинга
На разных этапах в качестве ядра системы мониторинга мы успели попробовать Nagios, Graphite и остановились на Zabbix, который вполне успешно используем и по сей день для наблюдения за несколькими тысячами серверов. За несколько лет мы накопили немалый опыт его эксплуатации, администрирования и тюнинга. И всё это время он довольно неплохо справлялся со своими задачами.
Тем не менее мы наступили, наверное, на все возможные и невозможные грабли. А это –самый полезный опыт.
Итак, основные проблемы, с которыми мы столкнулись (внимание! далее по тексту присутствует много боли и страданий):
- «У семи нянек…» – отсутствие единых правил мониторинга
Помните, я выше рассказывал про специализацию «админов»? Постепенно они разделились на разные отделы, и у каждого сложились свои правила мониторинга и реакции на одни и те же факторы.
Ну, например, база работает на хосте и «ест» 100% CPU. У «железячников» радость – «железо молодец, не сбоит даже под такой нагрузкой!», а у «прикладников» – паника.
- Не шаблоном единым…
Большинство использующих Zabbix знает про его мощную систему шаблонов, но иногда она натыкается на суровую реальность.
К разным правилам (и шаблонам) мониторинга одних и тех же сущностей в разных отделах начинали добавляться проблемы из-за недостаточной возможности параметризации самого Zabbix.
Например, у нас есть отличный шаблон с красивыми графиками для мониторинга 8-ядерного сервера:
 Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
И… для 16-ядерного он уже не подходит, нужен новый, с новыми графиками, ведь количество метрик – другое. А ведь у нас есть и 64-ядерные хосты…
В результате у нас была целая куча шаблонов на все случаи жизни. Только для мониторинга дисков их было больше десятка. Не существовало строгих правил, какие из них должны подключаться к хосту и в каких случаях.
У шаблонов не было никакой версионности, кроме пометок вроде “old” и “very_old”. Они привязывались и отвязывались так, как админу велело его сердце. В некоторых случаях метрики заводились просто вручную, без шаблонов. В результате получилась ситуация, когда разные хосты мониторились по-разному.
- Developers! Developers!
Хосты добавлялись в мониторинг вручную. Несмотря на то, что настройки Zabbix-агента разливались на сервера при помощи spacewalk, в некоторых случаях для снятия метрик требовалось зайти на сервер по SSH и внести какие-то изменения (положить скрипты, доустановить утилиты, настроить права и т.п.).
Если конфигурация сервера менялась, то нужно было не забыть подцепить правильные шаблоны. А ведь ещё нужно было вбить в конфиг хоста макросы с различными настройками, а потом проверить, что всё это работает.
- Неуправляемый склероз
Эта проблема, отчасти, следует из двух предыдущих: множество хостов просто не были добавлены в мониторинг. А те, что были, могли не иметь нужных настроек в конфиге, метрик, триггеров, графиков, … И даже если все было настроено правильно, это ещё ничего не гарантировало – данные могли не собираться, например, из-за несовпадения версии скрипта и ОС.
И даже если все собирались, то контрольные триггеры могли оказаться просто случайно отключены – ведь доступ на редактирование в Zabbix имело больше десятка человек!
- Overmonitoring
Zabbix отлично умеет собирать конкретные значения определенных метрик, но если их надо снять сразу несколько с одного объекта – возникают проблемы.
На каждый отсчет для каждой из множества метрик генерировался запрос, по которому на целевом сервере отрабатывала портянка из разного рода atop, iostat, grep, cut, awk и т.п., и возвращалось единственное значение, затем соединение закрывалось, и инициировался следующий запрос.
Понятно, что это плохо для производительности и для наблюдаемого сервера, и для Zabbix’а. Но еще хуже – отсутствие синхронности в получаемых данных.
Например, если мы замеряем поочередно нагрузку каждого из ядер CPU, получаем нули и… И ничего не понимаем о нагрузке на CPU в целом, поскольку она в момент каждого отдельного замера могла оказываться на других ядрах.
- Проблемы с производительностью Zabbix
На том этапе у нас было еще не так много метрик, а Zabbix тем не менее регулярно пытался “прилечь” – несмотря на весь тюнинг и хорошее «железо».
Для сбора метрик мы использовали пассивные zabbix-агенты и внешние скрипты. Для запроса данных с агентов со стороны Zabbix’а форкается указанное фиксированное количество воркеров. Пока воркер ждёт ответа от агента, другие запросы он не обслуживает. Таким образом, нередко возникали ситуации, когда zabbix не успевал обслуживать очередь и на графиках возникали “дыры” – интервалы с отсутствующими данными.
Мониторинг с помощью внешних скриптов тоже ни к чему хорошему не приводил. Большое количество одновременно запущенных различных интерпретаторов быстро приводило к космической загрузке сервера. Мониторинг в это время не работал, мы оставались “без глаз”.
- Ограниченность Zabbix в плане формирования расчётных показателей
Сложно создать даже простейшие вычисляемые метрики, вроде ratio=rx/tx – элементарно, вы не сможете проверить деление на 0. Если это произойдет, то на некоторое время метрика будет отключена.
Служба эксплуатации поздно узнавала о проблемах инфраструктуры, а разработчики не имели инструмента для анализа эффективности своих решений. В конечном счёте, всё это, так или иначе сказывалось на эффективности наших решений.
 После осознания того факта, что наш мониторинг – это собрание неправильных архитектурных решений (не знаю, можно ли считать отсутствие архитектуры архитектурным решением), мы решили что так больше жить нельзя. И начали думать, как исправить все описанные недостатки, но без радикальных решений, вроде замены Zabbix на что-то другое. Всё-таки, отказываться от накопленного опыта и пытаться искоренить многолетние привычки – наверное, не лучшая затея. Zabbix – это отличный инструмент, если правильно им пользоваться.
После осознания того факта, что наш мониторинг – это собрание неправильных архитектурных решений (не знаю, можно ли считать отсутствие архитектуры архитектурным решением), мы решили что так больше жить нельзя. И начали думать, как исправить все описанные недостатки, но без радикальных решений, вроде замены Zabbix на что-то другое. Всё-таки, отказываться от накопленного опыта и пытаться искоренить многолетние привычки – наверное, не лучшая затея. Zabbix – это отличный инструмент, если правильно им пользоваться.Эволюция
Для начала мы определили для себя следующие критерии, что хочется получить:
- Единообразие. Мониторинг должен осуществляться по одинаковым принципам для всех основных систем и сервисов, используемых в компании. То есть если уж мы снимаем какие-то метрики для 4-ядерного сервера с 2 HDD, то для 16-ядерного с 8 HDD они должны сниматься так же без дополнительных доработок.
- Модульность. Общее ядро с минимумом сервисных функций, которое расширяется с помощью подключения «прикладных плагинов», реализующих мониторинг того или иного вида объектов.
В плагин входят:
- реализация обнаружения наблюдаемых объектов (например, баз на сервере СУБД);
- реализация сбора целевых метрик;
- шаблоны генерируемых триггеров;
- шаблоны формируемых графиков и комплексных экранов.
- Автоматизация. Минимум ручной настройки, если что-то можно сделать автоматически – лучше так и сделать.
- Эффективность. Минимум нагрузки на целевой сервер. Если какой-то набор метрик можно получить как результат всего одного обращения – так и должно быть. Если с БД регулярно надо получать какие-то «внутренние» метрики, то не надо умучивать ее переустановкой соединения, а стоит его просто держать.
zabbix-1: cat /proc/meminfo | grep 'MemFree' | awk '{print $2}' zabbix-2: cat /proc/meminfo | grep 'Shmem' | awk '{print $2}' sbis-mon: cat /proc/meminfo # все, дальше парсим на приемнике
- Независимость. По возможности agent-less мониторинг. На сервер, желательно, ничего дополнительно не устанавливать и не настраивать, обходиться штатными средствами. То есть да, ‘cat /proc/meminfo’ – это правильный путь.
- Monitoring as code. Одна из основных концепций, позволяющая описать желаемое конечное состояние мониторинга с помощью кода, что даёт следующие преимущества:
- Мониторинг использует возможности системы контроля версий: все изменения прозрачны, известно кто, что и когда изменил, можно легко откатиться на произвольную версию в любое время. Репозиторий становится общим инструментом разработчиков и службы эксплуатации.
- Мониторинг проходит полноценное тестирование в несколько стадий: dev, QA, prod.
- Непрерывная интеграция.
Поскольку Zabbix оперирует в качестве объекта мониторинга «хостом», а нам нужен был «сервис» (например, конкретный из нескольких развернутых на одной машине экземпляров СУБД), мы зафиксировали определённые правила именования хостов, сервисов, метрик и комплексных экранов так, чтобы они не «ломали» ни логику Zabbix, ни «человекопонятность»:
hostname[.service[.port]][:screen]К примеру: some-db.pgsql.5433:db.postgres. Если порт дефолтный, то он не указывается для облегчения восприятия.

Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Мы так и не дали этой системе имя, но внутри компании закрепилось рабочее название “sbis3mon”, а кое-кто с лёгкой руки назвал его “красивый мониторинг”. Почему красивый? Мы постарались сделать его не просто функциональным, но и наглядным.

Изображение кликабельно, открывается в текущей вкладке веб-браузера.
На данный момент мы уже разработали десятки модулей для мониторинга различного оборудования и сервисов, используемых в Тензоре:
- ОС: Linux и Windows;
- гипервизор ESXI и его виртуальные машины;
- СХД: IBM DS, Storwize, Xiv, XtremIO, Openstack Swift;
- СУБД: PostgreSQL (и pgBouncer к нему), MongoDB, Redis;
- Search Engine: ElasticSearch, Sphinx;
- Messaging: RabbitMQ;
- Web: Nginx и IIS, PHP-FPM, HAProxy;
- DNS: Named (BIND);
- а также модули мониторинга наших собственных сервисов.
В ближайших планах также стоит мониторинг MySQL, сетевого оборудования и сервисов телефонии (Asterisk).
Архитектура сбора метрик
В качестве платформы мы выбрали Node.js – из-за развитой экосистемы, асинхронности, простоты работы с сетью, легкости масштабирования (модуль cluster) и скорости разработки.
Также мы приняли на вооружение подход Continuous Delivery и стали приделывать крылья самолёту на лету. Благодаря частым релизам, мы быстро получали фидбэк и могли корректировать направление разработки. Система строилась на глазах у основных наших пользователей – сотрудников службы эксплуатации, при этом они продолжали использовать привычную оболочку мониторинга. Постепенно мы заменяли старые методы мониторинга на новые, пока не изжили их совсем.
Система строится на микросервисной архитектуре и состоит из 5 основных частей:
- управляющий мастер-процесс
- БД
- коллекторы – сборщики данных
- реестр автообнаружения
- frontend
В качестве СУБД мы используем PostgreSQL. Но база тут вторична и не очень интересна – там хранятся настройки хостов и сервисов, обнаруженные сущности, ссылки на ресурсы Zabbix и записи аудитлога, и никакого highload.
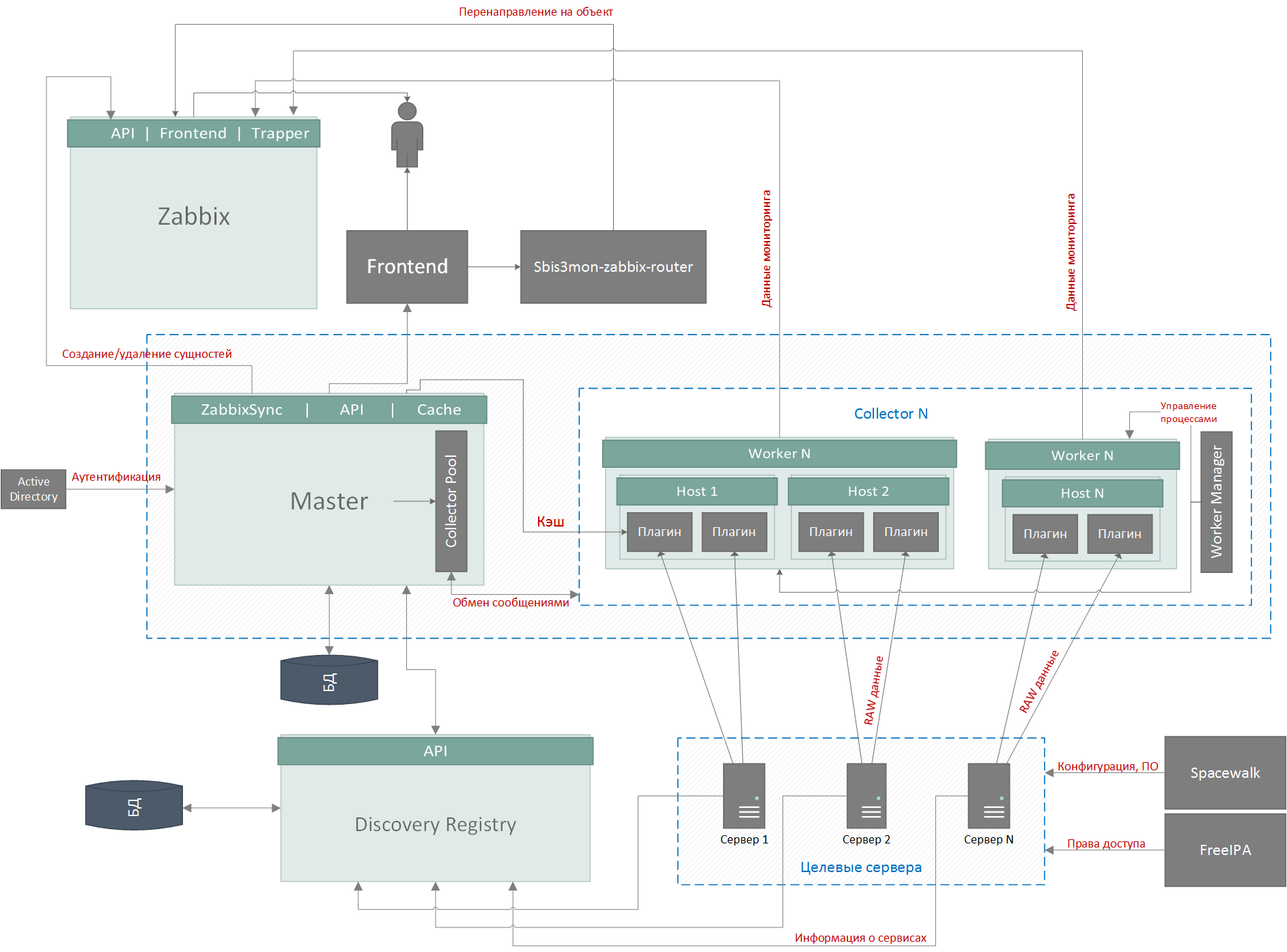
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Самое интересное – сервисы. Они могут работать как на одном сервере, так и на разных.
Мастер и коллекторы имеют общую кодовую базу – ядро. В зависимости от параметров запуска процесс становится либо мастером, либо коллектором.
Функции мастер-процесса:
- Управление пулом коллекторов, распределение задач между ними, автоматическая балансировка нагрузки; сейчас оба сервера коллекторов одинаково нагружены на 25% по CPU и LA=15.
- Синхронизация сущностей с Zabbix и Discovery Registry, удаление «потеряшек»
например, вместо «умершего» HDD подмонтировали новый на другом пути. - public API для работы фронтенда и интеграции с внешними сервисами.
Функции коллекторов:
- Управление рабочими процессами (WorkerManager).
«Что-то у нас тут задач приросло, пора еще один дочерний процесс поднять…» - Управление задачами (плагинами).
«Процесс PID 12345, тебе – собирать метрики linux-плагина с хоста с some-host! Процесс PID 54321, тебе – собирать метрики postgresql-плагина с хоста с some-db!» - Cбор и агрегация данных плагинами.
«Так, от нас ждут 1 отсчет на каждые 5 секунд… За последний интервал мы сняли с CPU следующие показатели нагрузки: [60,50,40,30,20]. Значит, для сохранения корректных значений min/max/avg, отправлять будем [min = 20, avg = 40, max = 60].» - Группировка пакетов из дочерних процессов и отправка данных в Zabbix на уровне cluster.master.
Сейчас наши несколько тысяч хостов и десятки тысяч сервисов на них обслуживаются коллекторами, живущими всего на двух серверах, на 40 и 64 ядра, со средней нагрузкой порядка 20-25% – то есть мы легко выдержим и дальнейший рост нашего серверного парка еще в 3-4 раза.
В следующей части мы расскажем более детально о тех решениях, которые позволили нашему мониторингу выдерживать рост нагрузки и требований пользователей, пока Тензор превращался из оператора по сдаче отчетности в настоящего мультисервисного провайдера услуг с миллионами пользователей онлайн.
Авторы: vadim_ipatov (Вадим Ипатов) и kilor (Кирилл Боровиков)
