У нас в True Engineering на одном проекте назрела необходимость в смене версии PostgreSQL с 9.6 на 11.1.
Зачем? База данных на проекте уже объемом 1,5 Tb и растет. Перформанс – одно из основных требований к системе. А сама структура данных эволюционирует: добавляются новые колонки, меняются существующие. Новая версия Postgres научилась эффективно работать с добавлением новых колонок с дефолтным значением, так что не нужно городить кастомных костылей на уровне приложения. Ещё в новой версии добавили несколько новых способов партиционирования таблиц, что тоже крайне полезно в условиях большого объема данных.
Итак, решено, мигрируем. Конечно, можно поднять параллельно со старой новую версию сервера PostgreSQL, остановить приложение, через dump/restore (или pg_upgrade) переместить базу и снова запустить приложение. Нам это решение не подошло из-за большого размера базы, к тому же, приложение работает в боевом режиме, и на даунтайм есть считанные минуты.
Поэтому мы решили попробовать миграцию с помощью логической репликации в PostgreSQL с использованием стороннего плагина под названием pglogical.
В процессе «проб» мы столкнулись с весьма обрывочной документацией по этому процессу (а на русском языке её вообще нет), а также некоторыми подводными камнями и неочевидными нюансами. В этой статье мы хотим изложить свой опыт в виде Tutorial.

TL;DR
Как мы уже сказали, самый простой выход: поднять параллельно со старой новую версию сервера PostgreSQL, остановить приложение, через dump/restore (или pg_upgrade) переместить базу и снова запустить приложение. Для баз небольшого объёма, в принципе, это вполне подходящий вариант (или, в общем случае — объём неважен, когда у вас есть возможность даунтайма приложения на время «переливания» БД со старого сервера на новый, каким бы долгим это время ни было). Но в нашем случае база занимает порядка 1,5 Tb на диске, и её перемещение — это вопрос не минут, а нескольких часов. Приложение же, в свою очередь, работает в боевом режиме, и даунтайма дольше пары минут очень хотелось избежать.
Также против этого варианта играл ещё и тот факт, что мы используем Master-Slave репликацию и не можем безболезненно выключить Slave-сервер из рабочего процесса. А значит, для переключения приложения со старой версии PostgreSQL на новую после миграции Master-сервера требовалось бы готовить и новый Slave-сервер до запуска приложения. А это ещё несколько часов простоя, пока создастся Slave (хотя и значительно меньше, чем миграция Master).
Поэтому решили попробовать миграцию с помощью логической репликации в PostgreSQL с помощью стороннего плагина под названием pglogical.
pglogical — это система логической репликации, использующая нативный Logical Decoding в PostgreSQL и реализованная в виде PostgreSQL extension. Позволяет настраивать выборочную репликацию с помощью модели подписок/публикаций. Не требует создания триггеров в базе или использования каких-либо внешних утилит для репликации.
Расширение работает на любой версии PostgreSQL, начиная с 9.4 (поскольку Logical Decoding впервые появился в 9.4), и позволяет осуществлять миграцию между любыми поддерживаемыми версиями PostgreSQL в любом направлении.
Настройка репликации с помощью pglogical вручную не очень тривиальна, хотя в принципе и вполне возможна. К счастью, существует сторонняя утилита pgrepup для автоматизации процесса настройки, которой мы и воспользуемся.
Поскольку мы планируем поднимать новую версию PostgreSQL на тех же серверах параллельно со старой, требования к диску под БД на серверах Master и Slave удваиваются. Казалось бы, это очевидно, но… Просто позаботьтесь о достаточном количестве свободного места перед запуском репликации, чтобы не жалеть о бесцельно прожитых годах.
В нашем случае потребовались модификации базы, плюс формат хранения при миграции между 9.6 и 11 «пухнет» не в пользу свежей версии, поэтому место на диске пришлось в итоге увеличивать не в 2, а примерно в 2.2 раза. Хвала LVM, это можно сделать в процессе миграции на лету.
В общем, take care of it.
Старый datadir расположен в /var/lib/pgsql/9.6/data, новый, соответственно, ложится в /var/lib/pgsql/11/data
Копируем настройки доступа (pg_hba.conf) и настройки сервера (postgresql.conf) из 9.6 в 11.
Чтобы запустить два сервера PostgreSQL на одной машине, в конфиге postgresql.conf 11 версии меняем порт на 15432 (port = 15432).
Здесь нужно плотно подумать, что ещё нужно сделать в новой версии PostgreSQL конкретно в вашем случае, чтобы он запустился с вашим postgresql.conf (и ваше приложение могло в итоге с ним работать). В нашем случае требовалось установить в новую версию используемые нами расширения PostgreSQL. Это выходит за рамки статьи, просто сделайте так, чтобы новый PostgreSQL запустился, работал и полностью вас устраивал :)
Смотрим в /var/lib/pgsql/11/data/pg_log/. Всё хорошо? Продолжаем!
Нюансы:
Получаем на выходе список из множества параметров, которые должны быть настроены требуемым образом.
Пример результатов проверки:


Все ошибки при проверке нужно будет устранить. В настройках обоих серверов должен быть выставлен wal_level=LOGICAL (для работы Logical Decoding), нужные настройки для движка репликации (количество слотов и wal_senders). Подсказки утилиты pgrepup достаточно информативны, по большинству пунктов вопросов возникнуть не должно.
Вносим все необходимые настройки, которые просит pgrepup.
В оба файла pg_hba.conf добавляем права доступа для пользователя, который будет делать репликацию, всё по подсказке pgrepup:
Для работы репликации во всех таблицах должен быть определён Primary Key.
В нашем случае PK был не везде, поэтому на время репликации необходимо его добавить, а по окончании репликации при желании удалить.
Список таблиц без PK, среди прочего, выдаёт
У утилиты pgrepup есть встроенная команда для проведения этой операции (
Инструкции по установке расширения можно почитать тут. Расширение необходимо установить в оба сервера.
Добавляем загрузку библиотеки в postgresql.conf обоих серверов:
Это вспомогательное расширение, которое pgrepup использует для логической репликации DDL.
Добавляем загрузку библиотеки в postgresql.conf обоих серверов:
Теперь с помощью
Если всё хорошо, можно перезапускать старый сервер. Здесь нужно подумать о том, как к перезагрузке сервера БД отнесётся ваше приложение, возможно, следует его предварительно остановить.
Теперь в выводе команды все до единого пункты должны быть отмечены как ОК.
Казалось бы, можно запускать миграцию, но…
В актуальной версии pgrepup есть несколько багов, делающих миграцию невозможной. Pull request’ы отправлены, но увы, остаются без внимания, поэтому придётся сделать исправления вручную.
Идём в папку установки pgrepup (наш случай — /usr/lib/python2.7/site-packages/pgrepup/commands/).
Делай раз. В каждом файле *.py добавляем пропущенные

Коммит тут.
Делай два. В setup.py делаем поиск по «sh -c», два вхождения, все многострочные команды shell нужно сделать однострочными.
Коммит тут.
Этой командой pgrepup подготавливает оба сервера к запуску репликации, создаёт пользователя, настраивает pglogical, переносит схему БД.
Он сказал «Поехали!» и махнул рукой:

Репликация запущена. Текущую ситуацию можно увидеть с помощью команды

Здесь мы видим, что две БД уже переехали и репликация идёт, а одна ещё в процессе переезда. Теперь остаётся только пить кофе и ждать, пока прокачается весь объём исходной БД.
Попутно можно заглянуть глубже фасада pgrepup и посмотреть, что происходит под капотом. Для пытливых умов вот список запросов в качестве отправной точки:
Вдоволь напившись кофе (на тестовом сервере при написании этой статьи миграция ~700Gb данных длилась в районе суток), мы наконец видим такую картину:

И это означает, что пришло время готовить новый Slave.
Здесь всё просто и по учебнику, никаких нюансов.
Копируем настройки доступа (pg_hba.conf) и настройки сервера (postgresql.conf) из 9.6 в 11. В конфиге postgresql.conf 11 версии меняем порт на 15432 (port = 15432)
После всех этих процедур у нас получится вот такая хитрая схема репликаций:
Здесь в качестве последней проверки (ну и, в конце концов, это просто красиво) можно сделать какой-нибудь UPDATE в базу на 9.6 Master и пронаблюдать, как он среплицируется на остальные три сервера.

До сих пор наше приложение ничего не подозревало о новой версии PostgreSQL, пришло время это исправить. Варианты действий здесь принципиально зависят только от двух вещей:
будете ли вы перевешивать новые сервисы на те же порты, на которых работали старые,
и требуется ли вашему приложению перезапуск при перезапуске сервера БД.
Для интереса ответим на оба вопроса «да» и приступим.
Останавливаем приложение.

Возвращаем стандартный порт в конфиге postgresql.conf новой версии на Master и Slave.
На новом Slave также меняем порт на стандартный в recovery.conf.
Попутно есть предложение от греха подальше поменять порт на становящейся неактивной старой версии:
Выставляем нестандартный порт в postgresql.conf старой версии на Master и Slave.
На старом Slave также меняем порт на нестандартный в recovery.conf.
Проверяем логи.
Проверяем статус репликации на Master.
Запускаем приложение. Радуемся полчаса.
А напоследок полезная литература по теме:
Успехов!
Зачем? База данных на проекте уже объемом 1,5 Tb и растет. Перформанс – одно из основных требований к системе. А сама структура данных эволюционирует: добавляются новые колонки, меняются существующие. Новая версия Postgres научилась эффективно работать с добавлением новых колонок с дефолтным значением, так что не нужно городить кастомных костылей на уровне приложения. Ещё в новой версии добавили несколько новых способов партиционирования таблиц, что тоже крайне полезно в условиях большого объема данных.
Итак, решено, мигрируем. Конечно, можно поднять параллельно со старой новую версию сервера PostgreSQL, остановить приложение, через dump/restore (или pg_upgrade) переместить базу и снова запустить приложение. Нам это решение не подошло из-за большого размера базы, к тому же, приложение работает в боевом режиме, и на даунтайм есть считанные минуты.
Поэтому мы решили попробовать миграцию с помощью логической репликации в PostgreSQL с использованием стороннего плагина под названием pglogical.
В процессе «проб» мы столкнулись с весьма обрывочной документацией по этому процессу (а на русском языке её вообще нет), а также некоторыми подводными камнями и неочевидными нюансами. В этой статье мы хотим изложить свой опыт в виде Tutorial.

TL;DR
- Всё получилось (не без костылей, о них и статья).
- Мигрировать можно в рамках PostgreSQL версии от 9.4 до 11.x, с любой версии на любую, вниз или вверх.
- Даунтайм равен времени, которое требуется вашему приложению, чтобы переподключиться к новому серверу БД (в нашем случае это был перезапуск всего приложения, но в дикой природе, очевидно, «возможны варианты»).
Почему нам не подошло решение «в лоб»
Как мы уже сказали, самый простой выход: поднять параллельно со старой новую версию сервера PostgreSQL, остановить приложение, через dump/restore (или pg_upgrade) переместить базу и снова запустить приложение. Для баз небольшого объёма, в принципе, это вполне подходящий вариант (или, в общем случае — объём неважен, когда у вас есть возможность даунтайма приложения на время «переливания» БД со старого сервера на новый, каким бы долгим это время ни было). Но в нашем случае база занимает порядка 1,5 Tb на диске, и её перемещение — это вопрос не минут, а нескольких часов. Приложение же, в свою очередь, работает в боевом режиме, и даунтайма дольше пары минут очень хотелось избежать.
Также против этого варианта играл ещё и тот факт, что мы используем Master-Slave репликацию и не можем безболезненно выключить Slave-сервер из рабочего процесса. А значит, для переключения приложения со старой версии PostgreSQL на новую после миграции Master-сервера требовалось бы готовить и новый Slave-сервер до запуска приложения. А это ещё несколько часов простоя, пока создастся Slave (хотя и значительно меньше, чем миграция Master).
Поэтому решили попробовать миграцию с помощью логической репликации в PostgreSQL с помощью стороннего плагина под названием pglogical.
Общая информация
pglogical — это система логической репликации, использующая нативный Logical Decoding в PostgreSQL и реализованная в виде PostgreSQL extension. Позволяет настраивать выборочную репликацию с помощью модели подписок/публикаций. Не требует создания триггеров в базе или использования каких-либо внешних утилит для репликации.
Расширение работает на любой версии PostgreSQL, начиная с 9.4 (поскольку Logical Decoding впервые появился в 9.4), и позволяет осуществлять миграцию между любыми поддерживаемыми версиями PostgreSQL в любом направлении.
Настройка репликации с помощью pglogical вручную не очень тривиальна, хотя в принципе и вполне возможна. К счастью, существует сторонняя утилита pgrepup для автоматизации процесса настройки, которой мы и воспользуемся.
Памятка о свободном месте на диске
Поскольку мы планируем поднимать новую версию PostgreSQL на тех же серверах параллельно со старой, требования к диску под БД на серверах Master и Slave удваиваются. Казалось бы, это очевидно, но… Просто позаботьтесь о достаточном количестве свободного места перед запуском репликации, чтобы не жалеть о бесцельно прожитых годах.
В нашем случае потребовались модификации базы, плюс формат хранения при миграции между 9.6 и 11 «пухнет» не в пользу свежей версии, поэтому место на диске пришлось в итоге увеличивать не в 2, а примерно в 2.2 раза. Хвала LVM, это можно сделать в процессе миграции на лету.
В общем, take care of it.
Устанавливаем PostgreSQL 11 на Master
Note: Мы используем Oracle Linux, и всё нижеследующее будет заточено под этот дистрибутив. Не исключено, что другие дистрибутивы Linux потребуют небольшой доработки напильником, но вряд ли она будет существенной.
# добавляем репозиторий
yum install https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-oraclelinux11-11-2.noarch.rpm
# устанавливаем пакеты postgresql11
yum install postgresql11 postgresql11-devel postgresql11-server postgresql11-contrib
# инициализируем базу
/usr/pgsql-11/bin/postgresql-11-setup initdbСтарый datadir расположен в /var/lib/pgsql/9.6/data, новый, соответственно, ложится в /var/lib/pgsql/11/data
Копируем настройки доступа (pg_hba.conf) и настройки сервера (postgresql.conf) из 9.6 в 11.
Чтобы запустить два сервера PostgreSQL на одной машине, в конфиге postgresql.conf 11 версии меняем порт на 15432 (port = 15432).
Здесь нужно плотно подумать, что ещё нужно сделать в новой версии PostgreSQL конкретно в вашем случае, чтобы он запустился с вашим postgresql.conf (и ваше приложение могло в итоге с ним работать). В нашем случае требовалось установить в новую версию используемые нами расширения PostgreSQL. Это выходит за рамки статьи, просто сделайте так, чтобы новый PostgreSQL запустился, работал и полностью вас устраивал :)
# ставим расширения, тюним конфиги, добавляем shared libraries, whatever...
# ....
# запускаемся
systemctl enable postgresql-11
systemctl start postgresql-11Смотрим в /var/lib/pgsql/11/data/pg_log/. Всё хорошо? Продолжаем!
Устанавливаем и настраиваем pgrepup
# ставим python
yum install python
yum install python2-pip
# ставим pgrepup
pip install pgrepup
# создаём конфигурацию
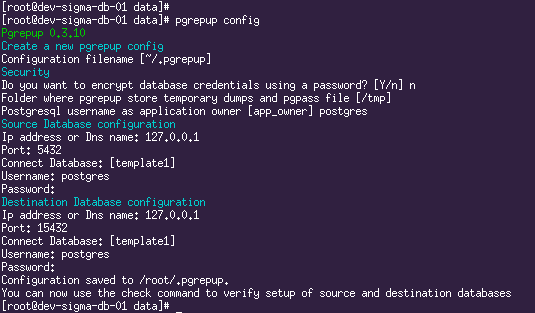
pgrepup config
Нюансы:
- В качестве app_owner указываем пользователя, под которым запущены серверы PostgreSQL.
- В качестве Database указываем template1.
- Username и Password — данные для доступа суперюзера. В нашем случае в pg_hba.conf для локальных подключений пользователя postgres был прописан метод trust, поэтому пароль можно указать произвольный.
Настраиваем репликацию
# запускаем проверку
pgrepup check
Получаем на выходе список из множества параметров, которые должны быть настроены требуемым образом.
Пример результатов проверки:
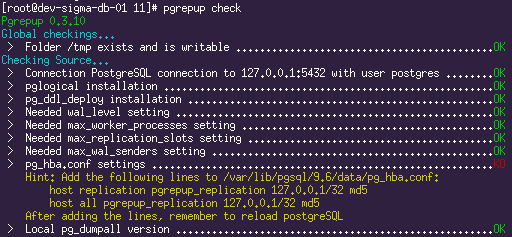

Все ошибки при проверке нужно будет устранить. В настройках обоих серверов должен быть выставлен wal_level=LOGICAL (для работы Logical Decoding), нужные настройки для движка репликации (количество слотов и wal_senders). Подсказки утилиты pgrepup достаточно информативны, по большинству пунктов вопросов возникнуть не должно.
Вносим все необходимые настройки, которые просит pgrepup.
В оба файла pg_hba.conf добавляем права доступа для пользователя, который будет делать репликацию, всё по подсказке pgrepup:
host replication pgrepup_replication 127.0.0.1/32 md5
host all pgrepup_replication 127.0.0.1/32 md5Добавляем Primary Keys
Для работы репликации во всех таблицах должен быть определён Primary Key.
В нашем случае PK был не везде, поэтому на время репликации необходимо его добавить, а по окончании репликации при желании удалить.
Список таблиц без PK, среди прочего, выдаёт
pgrepup check. Для всех таблиц из этого списка нужно добавить primary key любым приемлемым для вас способом. В нашем случае это было нечто вида:ALTER TABLE %s ADD COLUMN temporary_pk BIGSERIAL NOT NULL PRIMARY KEYУ утилиты pgrepup есть встроенная команда для проведения этой операции (
pgrepup fix), и при её использовании даже подразумевается, что при успешной репликации эти временные колонки будут автоматически удалены. Но, к сожалению, этот функционал так неиллюзорно и феерически глючил на больших базах, что мы решили не использовать его, а сделать эту операцию вручную так, как нам удобно.Устанавливаем pglogical extension
Инструкции по установке расширения можно почитать тут. Расширение необходимо установить в оба сервера.
# добавляем репозитории с нужными нам версиями
curl https://access.2ndquadrant.com/api/repository/dl/default/release/9.6/rpm | bash
curl https://access.2ndquadrant.com/api/repository/dl/default/release/11/rpm | bash
# устанавливаем пакеты
yum install postgresql96-pglogical postgresql11-pglogicalДобавляем загрузку библиотеки в postgresql.conf обоих серверов:
shared_preload_libraries = 'pglogical'Устанавливаем pgl_ddl_deploy extension
Это вспомогательное расширение, которое pgrepup использует для логической репликации DDL.
# и его придётся собирать вручную
git clone https://github.com/enova/pgl_ddl_deploy.git
# сборка и установка для старого сервера
PATH=/usr/pgsql-9.6/bin/:$PATH
USE_PGXS=1 make
USE_PGXS=1 make install
make clean
# сборка и установка для нового сервера
PATH=/usr/pgsql-11/bin/:$PATH
make CLANG=true
make installДобавляем загрузку библиотеки в postgresql.conf обоих серверов:
shared_preload_libraries = 'pglogical,pgl_ddl_deploy'Проверяем внесённые изменения
# перезапускаем новый postgresql
systemctl restart postgresql-11Теперь с помощью
pgrepup check необходимо убедиться, что с целевым сервером всё стало ок и все замечания касательно целевого сервера полностью устранены.Если всё хорошо, можно перезапускать старый сервер. Здесь нужно подумать о том, как к перезагрузке сервера БД отнесётся ваше приложение, возможно, следует его предварительно остановить.
# перезапускаем
systemctl restart postgresql-9.6
# проверяем
pgrepup checkТеперь в выводе команды все до единого пункты должны быть отмечены как ОК.
Казалось бы, можно запускать миграцию, но…
Правим баги pgrepup
В актуальной версии pgrepup есть несколько багов, делающих миграцию невозможной. Pull request’ы отправлены, но увы, остаются без внимания, поэтому придётся сделать исправления вручную.
Идём в папку установки pgrepup (наш случай — /usr/lib/python2.7/site-packages/pgrepup/commands/).
Делай раз. В каждом файле *.py добавляем пропущенные
**kwargs в описании функции. Картинка лучше тысячи слов: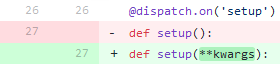
Коммит тут.
Делай два. В setup.py делаем поиск по «sh -c», два вхождения, все многострочные команды shell нужно сделать однострочными.
Коммит тут.
Запускаем миграцию
# подготовка
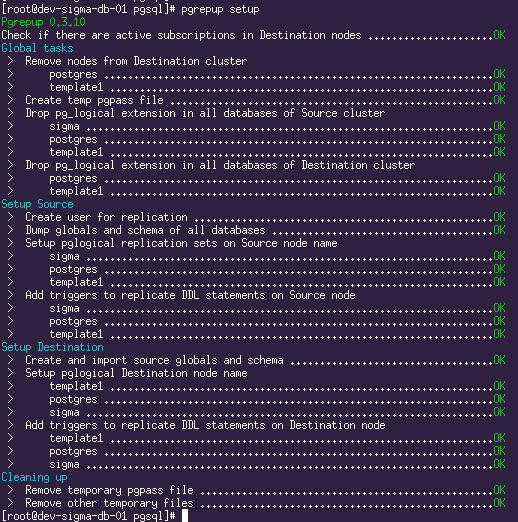
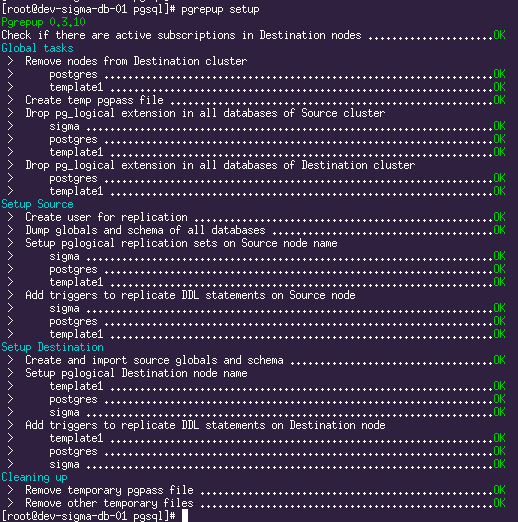
pgrepup setupЭтой командой pgrepup подготавливает оба сервера к запуску репликации, создаёт пользователя, настраивает pglogical, переносит схему БД.
# запускаем репликацию
pgrepup startОн сказал «Поехали!» и махнул рукой:

Репликация запущена. Текущую ситуацию можно увидеть с помощью команды
pgrepup status: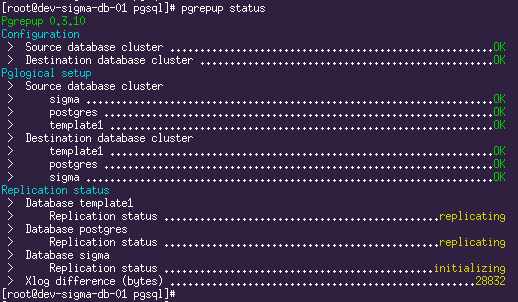
Здесь мы видим, что две БД уже переехали и репликация идёт, а одна ещё в процессе переезда. Теперь остаётся только пить кофе и ждать, пока прокачается весь объём исходной БД.
Попутно можно заглянуть глубже фасада pgrepup и посмотреть, что происходит под капотом. Для пытливых умов вот список запросов в качестве отправной точки:
SELECT * FROM pg_replication_origin_status ORDER BY remote_lsn DESC;
SELECT *,pg_xlog_location_diff(s.sent_location,s.replay_location) byte_lag FROM pg_stat_replication s;
SELECT query FROM pg_stat_activity WHERE application_name='subscription_copy'Вдоволь напившись кофе (на тестовом сервере при написании этой статьи миграция ~700Gb данных длилась в районе суток), мы наконец видим такую картину:
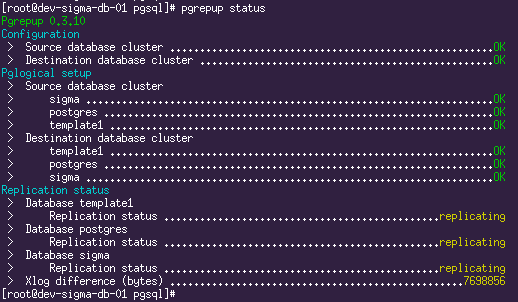
И это означает, что пришло время готовить новый Slave.
Устанавливаем PostgreSQL 11 на Slave
Здесь всё просто и по учебнику, никаких нюансов.
# добавляем репозиторий
yum install https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-oraclelinux11-11-2.noarch.rpm
# устанавливаем postgresql 11
yum install postgresql11 postgresql11-devel postgresql11-server postgresql11-contrib
# переливаем данные с нового мастера
su - postgres
pg_basebackup -h db-master.hostname -p 15432 -D /var/lib/pgsql/11/data/ -R -P -U replication -X stream -c fastКопируем настройки доступа (pg_hba.conf) и настройки сервера (postgresql.conf) из 9.6 в 11. В конфиге postgresql.conf 11 версии меняем порт на 15432 (port = 15432)
# запускаем
systemctl enable postgresql-11
systemctl start postgresql-11# проверяем статус репликации на Master
SELECT *,pg_wal_lsn_diff(s.sent_lsn,s.replay_lsn) AS byte_lag FROM pg_stat_replication s;
# проверяем статус репликации на Slave
SELECT now()-pg_last_xact_replay_timestamp();
Промежуточные итоги
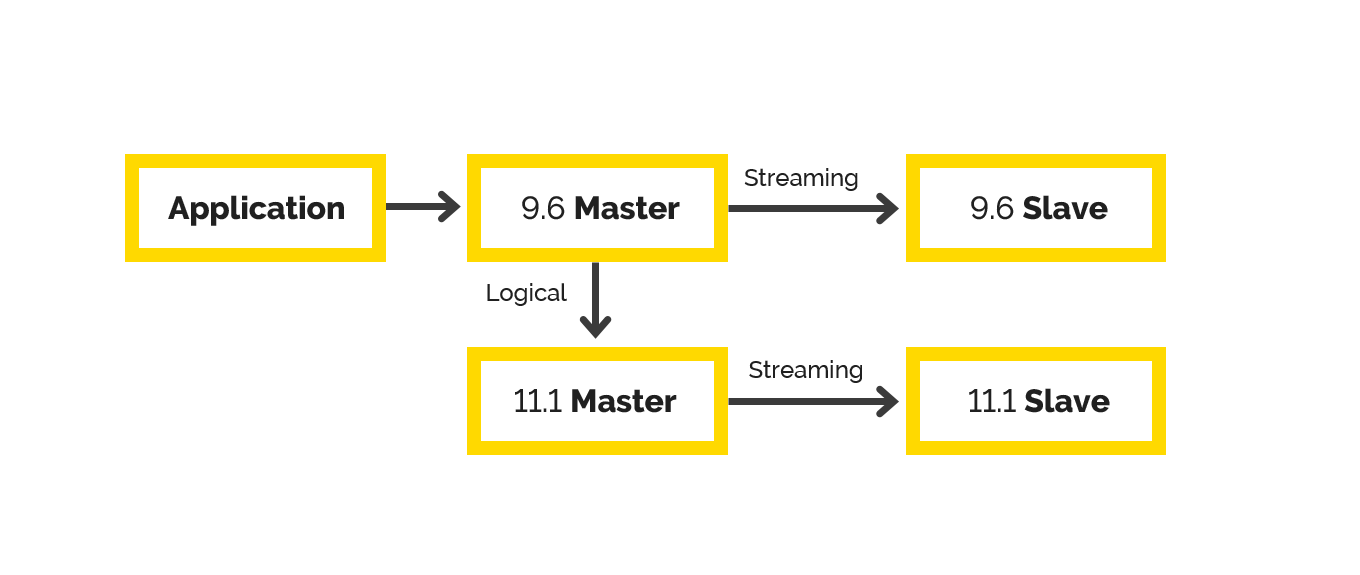
После всех этих процедур у нас получится вот такая хитрая схема репликаций:

Здесь в качестве последней проверки (ну и, в конце концов, это просто красиво) можно сделать какой-нибудь UPDATE в базу на 9.6 Master и пронаблюдать, как он среплицируется на остальные три сервера.

Переключение приложения на новую версию PostgreSQL
До сих пор наше приложение ничего не подозревало о новой версии PostgreSQL, пришло время это исправить. Варианты действий здесь принципиально зависят только от двух вещей:
будете ли вы перевешивать новые сервисы на те же порты, на которых работали старые,
и требуется ли вашему приложению перезапуск при перезапуске сервера БД.
Для интереса ответим на оба вопроса «да» и приступим.
Останавливаем приложение.
# проверяем, что нет коннектов, например:
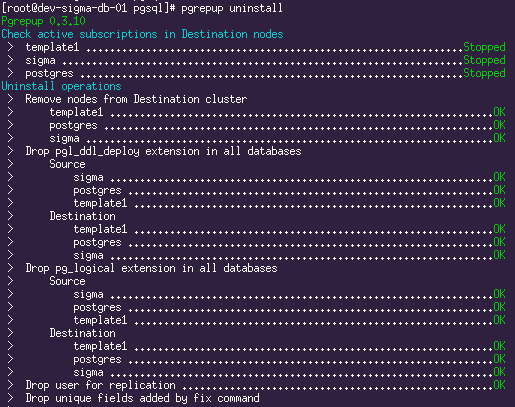
SELECT * FROM pg_stat_activity;# останавливаем логическую репликацию
# при этом также произойдёт финальная синхронизация sequences.
pgrepup stop
# чистим за собой все хвосты
pgrepup uninstall
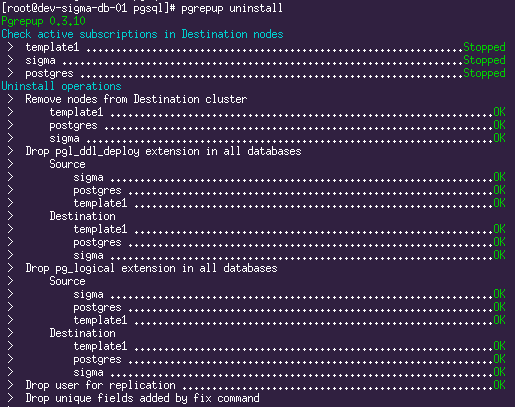
# на master:
# выключаем старый сервис
systemctl disable postgresql-9.6
# останавливаем оба сервиса, сначала старый, затем новый.
systemctl stop postgresql-9.6
systemctl stop postgresql-11
# на slave:
# выключаем старый сервис
systemctl disable postgresql-9.6
# останавливаем оба сервиса, сначала старый, затем новый.
systemctl stop postgresql-9.6
systemctl stop postgresql-11Возвращаем стандартный порт в конфиге postgresql.conf новой версии на Master и Slave.
На новом Slave также меняем порт на стандартный в recovery.conf.
Попутно есть предложение от греха подальше поменять порт на становящейся неактивной старой версии:
Выставляем нестандартный порт в postgresql.conf старой версии на Master и Slave.
На старом Slave также меняем порт на нестандартный в recovery.conf.
# запускаем на master
systemctl enable postgresql-11
systemctl start postgresql-11
# запускаем на slave:
systemctl enable postgresql-11
systemctl start postgresql-11Проверяем логи.
Проверяем статус репликации на Master.
SELECT *,pg_wal_lsn_diff(s.sent_lsn,s.replay_lsn) AS byte_lag FROM pg_stat_replication s;Запускаем приложение. Радуемся полчаса.
А напоследок полезная литература по теме:
- pglogical
- Installation Instructions for pglogical
- pglogical Docs
- Upgrading PostgreSQL from 9.4 to 10.3 with pglogical
- pgrepup – upgrade PostgreSQL using logical replication
- pgrepup – PostgreSQL REPlicate and UPgrade
- Upgrading PostgreSQL from 9.6 to 10 with minimal downtime using pglogical
Успехов!
