
Docker Swarm, Kubernetes и Mesos являются наиболее популярными фреймворками для оркестровки контейнеров. В своем выступлении Арун Гупта сравнивает следующие аспекты работы Docker, Swarm, и Kubernetes:
В результате вы получите четкое представление о том, что может предложить каждый инструмент оркестровки, и изучите методы эффективного использования этих платформ.
Арун Гупта — главный технолог open-source продуктов Amazon Web Services, который уже более 10 лет развивает сообщества разработчиков Sun, Oracle, Red Hat и Couchbase. Имеет большой опыт работы в ведущих кросс-функциональных командах, занимающихся разработкой и реализацией стратегии маркетинговых кампаний и программ. Руководил группами инженеров Sun, является одним из основателей команды Java EE и создателем американского отделения Devoxx4Kids. Арун Гупта является автором более 2 тысяч постов в IT-блогах и выступил с докладами более чем в 40 странах.
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 1
Концепт масштабирования Scale означает возможность управлять количеством реплик, увеличивая или уменьшая число экземпляров приложения.

Для примера: если хотите масштабировать систему до 6 реплик, используйте команду docker service scale web=6.
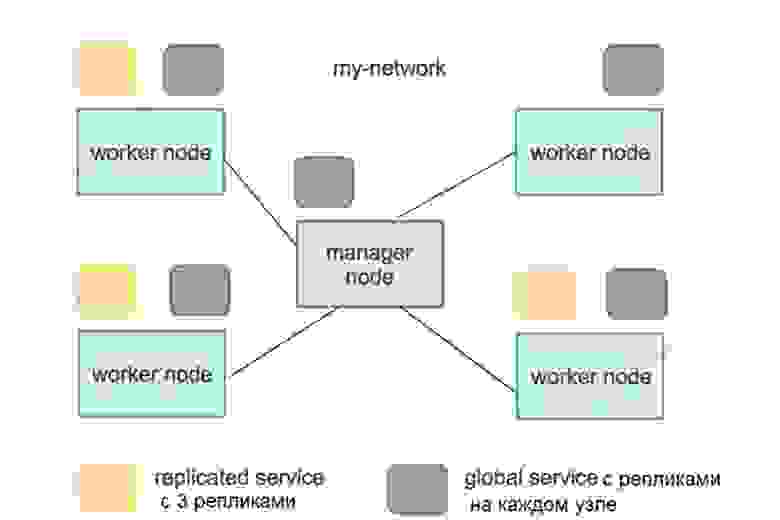
Наряду с концептом Replicated Service в Docker существует концепт общих сервисов Global Service. Скажем, я хочу запустить экземпляр одного и того же контейнера на каждом узле кластера, в данном случае это контейнер приложения веб-мониторинга Prometheus. Это приложение используется, когда требуется собрать метрики о работе хостов. В этом случае вы используете подкоманду — - mode=global — - name=prom prom/Prometheus.

В результате приложение Prometheus будет запущено на всех узлах кластера без исключения, и если в кластер будут добавлены новые ноды, то оно автоматически запустится в контейнере и в этих нодах. Надеюсь, вы поняли разницу между Replicated Service и Global Service. Обычно Replicated Service это то, с чего вы начинаете.
Итак, мы рассмотрели основные понятия, или основные сущности Docker, а теперь рассмотрим сущности Kubernetes. Kubernetes – это тоже своего рода планировщик, платформа для оркестровки контейнеров. Нужно помнить, что основной концепт планировщика — это знание того, как запланировать работу контейнеров на разных хостах. Если же перейти на более высокий уровень, можно сказать, что оркестровка означает расширение ваших возможностей до управления кластерами, получения сертификатов и т.д. В этом смысле и Docker, и Kubernetes являются платформами оркестровки, причем оба имеют встроенный планировщик.
Оркестровка представляет собой автоматизированное управление связанными сущностями — кластерами виртуальных машин или контейнеров. Kubernetes — это совокупность сервисов, реализующих контейнерный кластер и его оркестровку. Он не заменяет Docker, но серьёзно расширяет его возможности, упрощая управление развертыванием, сетевой маршрутизацией, расходом ресурсов, балансировкой нагрузки и отказоустойчивостью запускаемых приложений.
По сравнению с Kubernetes, Docker ориентирован именно на работу с контейнерами, создавая их образы с помощью docker-файла. Если сравнить объекты Docker и Kubernetes, можно сказать, что Docker управляет контейнерами, в то время как Kubernetes управляет самим Docker.
Кто из вас имел дело с контейнерами Rocket? А кто-нибудь использует Rocket в продакшене? В зале поднял руку всего один человек, это типичная картина. Это альтернатива Docker, которая до сих пор не прижилась в сообществе разработчиков.
Итак, основной сущностью Kubernetes является Pod. Он представляет собой связанную группу контейнеров, которые используют общее пространство имен, общее хранилище и общий IP-адрес. Все контейнеры в поде общаются друг с другом через локальный хост. Это означает, что вы не сможете разместить приложение и базу данных в одном и том же поде. Они должны размещаться в разных подах, поскольку имеют разные требования масштабирования.
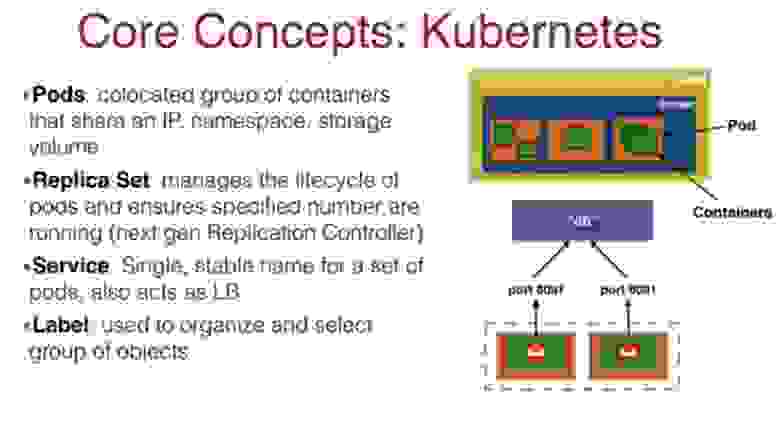
Таким образом, вы можете разместить в одном поде, например, WildFly контейнер, логин-контейнер, прокси-контейнер, или кэш-контейнер, причем вы должны ответственно подходить к составу компонентов контейнера, который собираетесь масштабировать.
Обычно вы «обертываете» свой контейнер в набор реплик Replica Set, поскольку хотите запускать в поде определенное количество экземпляров. Replica Set приказывает запустить столько реплик, сколько требует сервис масштабирования Docker, и указывает, когда и каким образом это проделать.
Поды похожи на контейнеры в том смысле, что если происходит сбой пода на одном хосте, он перезапускается на другом поде с другим IP-адресом. Как Java-разработчик, вы знаете, что когда создаете java-приложение и оно связывается с базой данных, вы не можете полагаться на динамический IP-адрес. В этом случае Kubernetes использует Service – этот компонент публикует приложение как сетевой сервис, создавая статичное постоянное сетевое имя для набора подов, одновременно реализуя балансировку нагрузки между подами. Можно сказать, что это служебное имя базы данных, и java-приложение не полагается на IP-адрес, а взаимодействует только с постоянным именем базы данных.
Это достигается тем, что каждый Pod снабжается определенной меткой Label, которые хранятся в распределенном хранилище etcd, и Service следит за этими метками, обеспечивая связь компонентов. То есть поды и сервисы устойчиво взаимодействуют друг с другом с помощью этих меток.
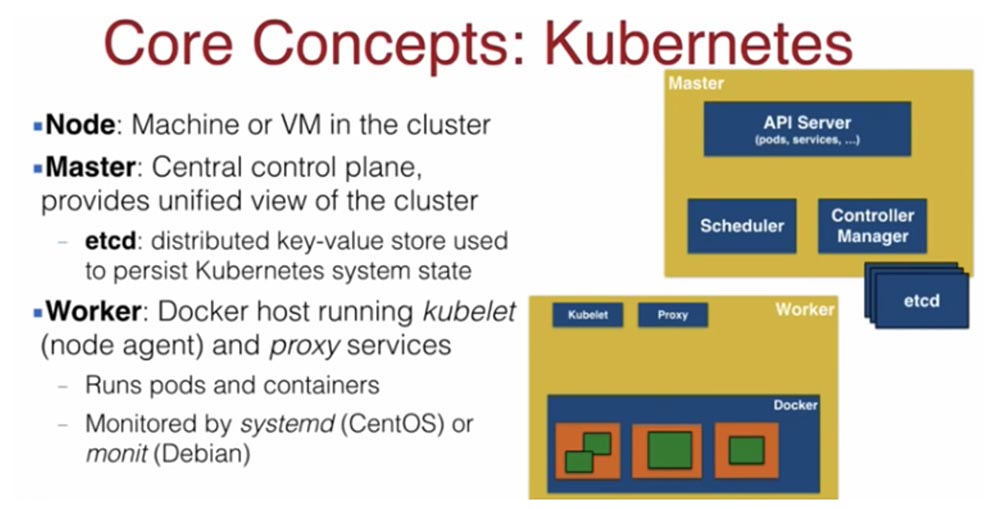
Теперь давайте рассмотрим, как создать кластер Kubernetes. Для этого, как и в Docker, нам нужен мастер-нод и рабочий нод. Нод в кластере обычно представлен физической или виртуальной машиной. Здесь, как и в Docker, мастер представляет собой центральную управляющую структуру, которая позволяет контролировать весь кластер через планировщик и менеджер контроллеров. По умолчанию мастер-нод существует в единственном числе, но есть множество новых инструментов, позволяющих создавать несколько мастер-нодов.
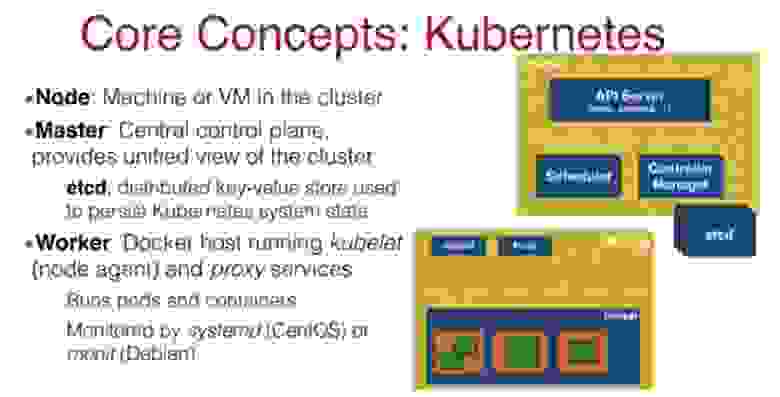
Master-node обеспечивает взаимодействие с пользователем при помощи API-сервера и содержит распределенное хранилище etcd, в котором находится конфигурация кластера, статусы его объектов и метаданные.
Рабочие узлы Worker-node предназначены исключительно для запуска контейнеров, для этого в них установлены два сервиса Kubernetes — сетевой маршрутизатор proxy service и агент планировщика kubelet. Во время работы этих узлов Docker выполняет их мониторинг с помощью systemd (CentOS) или monit (Debian) в зависимости от того, какой операционной системой вы пользуетесь.
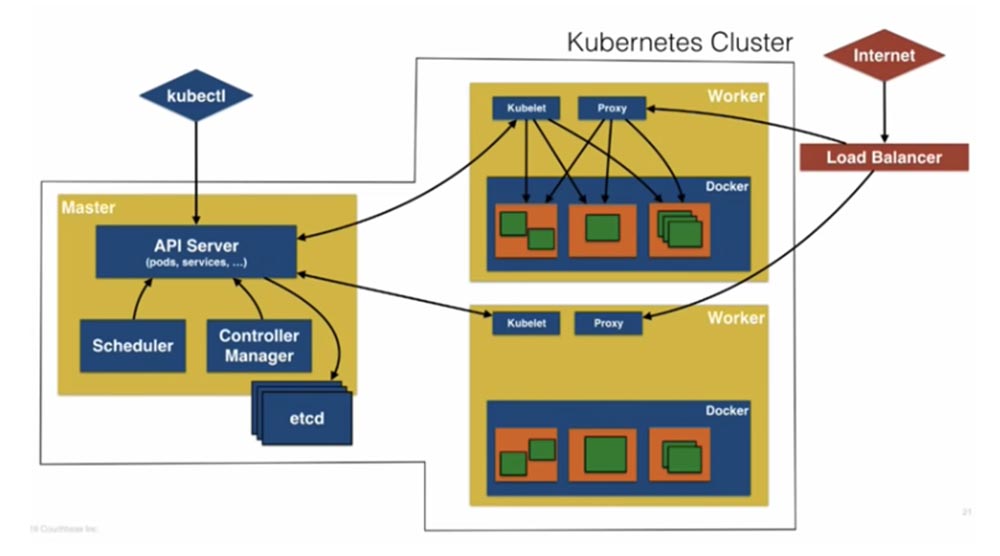
Рассмотрим архитектуру Kubernetes более широко. У нас имеется Master, в составе которого присутствуют API –сервер (поды, сервисы и т.д.), управляемый с помощью CLI kubectl. Kubectl позволяет создавать ресурсы Kubernetes. Он передает API-серверу команды типа «создать под», «создать сервис», «создать набор реплик».
Далее здесь имеется планировщик Scheduler, менеджер контроллеров Controller Manager и хранилище etcd. Менеджер контроллеров, получив указания API-сервера, сопоставляет метки реплик с метками подов, обеспечивая устойчивое взаимодействие компонентов. Планировщик, получив задание создать под, просматривает рабочие ноды и создает его там, где это предусмотрено. Естественно, что он получает эту информацию из etcd.
Далее у нас имеется несколько рабочих нодов, и API-сервер общается с содержащимися в них Kubelet-агентами, сообщая им, как должны создаваться поды. Здесь расположен прокси, который предоставляет вам доступ к приложению, использующему эти поды. Справа на слайде показан мой клиент – это запрос интернета, который поступает в балансировщик нагрузки, тот обращается к прокси, который распределяет запрос по подам и направляет ответ обратно.
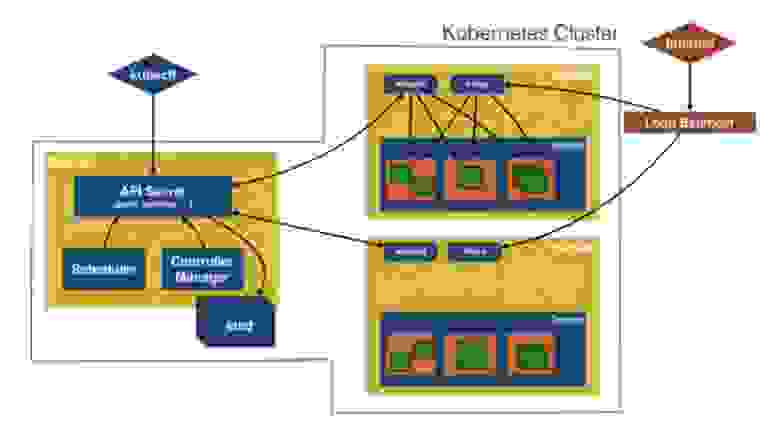
Вы видите итоговый слайд, который изображает кластер Kubernetes и то, как работают все его компоненты.
Давайте подробнее поговорим о Service Discovery и балансировщике нагрузки Docker. Когда вы запускаете свое Java-приложение, обычно это происходит в нескольких контейнерах на нескольких хостах. Существует компонент Docker Compose, который позволяет с легкостью запускать мультиконтейнерные приложения. Он описывает мультиконтейнерные приложения и запускает их при помощи одного или нескольких yaml-файлов конфигурации.

По умолчанию это файлы docker-compose.yaml и docker-compose.override.yaml, при этом множества файлов указываются с помощью – f. В первой файле вы прописываете сервис, образы, реплики, метки и т.д. Второй файл используется для перезаписи конфигурации. После создания docker-compose.yaml он развертывается в мультихостовом кластере, который ранее создал Docker Swarm. Вы можете создать один базовый файл конфигурации docker-compose.yaml, в который будете добавлять файлы специфических конфигураций для разных задач с указанием определенных портов, образов и т.д., позже мы поговорим об этом.
На этом слайде вы видите простой пример файла Service Discovery. В первой строке указывается версия, а строка 2 показывает, что он касается сервисов db и web.

Я добиваюсь того, чтобы после «поднятия» мой web-сервис мог общаться с db-сервисом. Это простые java-приложения, развертываемые в контейнерах WildFly. В 11 строке я прописываю среду couchbase_URI=db. Это означает, что мой db-сервис использует эту базу данных. В строке 4 указан образ couchbase, а в строках 5-9 и 15-16 соответственно порты, необходимые для обеспечения работы моих сервисов.
Ключом к пониманию процесса обнаружения сервисов служит то, что вы создаете некоторого рода зависимости. Вы указываете, что web-контейнер должен запуститься раньше db-контейнера, но это только на уровне контейнеров. Как реагирует ваше приложение, как оно стартует – это совершенно другие вещи. Например, обычно контейнер «поднимается» за 3-4 секунды, однако запуск контейнера базы данных занимает гораздо больше времени. Так что логика запуска вашего приложения должна быть «запечена» в вашем java-приложении. То есть приложение должно пинговать базу данных, чтобы убедиться в ее готовности. Поскольку база данных couchbase – это REST API, вы должны вызвать этот API и спросить: «Эй, ты готов? Если да, то я готов присылать тебе запросы»!
Таким образом, зависимости на уровне контейнеров определяются с помощью сервиса docker-compose, но на уровне приложений зависимости и жизнеспособность определяются на основе опросов responsibility. Затем вы берете файл docker-compose.yaml и развертываете в мультихостовом Docker с помощью команды docker stack deploy и подкоманды — - compose-file= docker-compose.yaml webapp. Итак, у вас есть большой стек, в котором расположено несколько сервисов, решающих несколько задач. В основном это задачи запуска контейнеров.

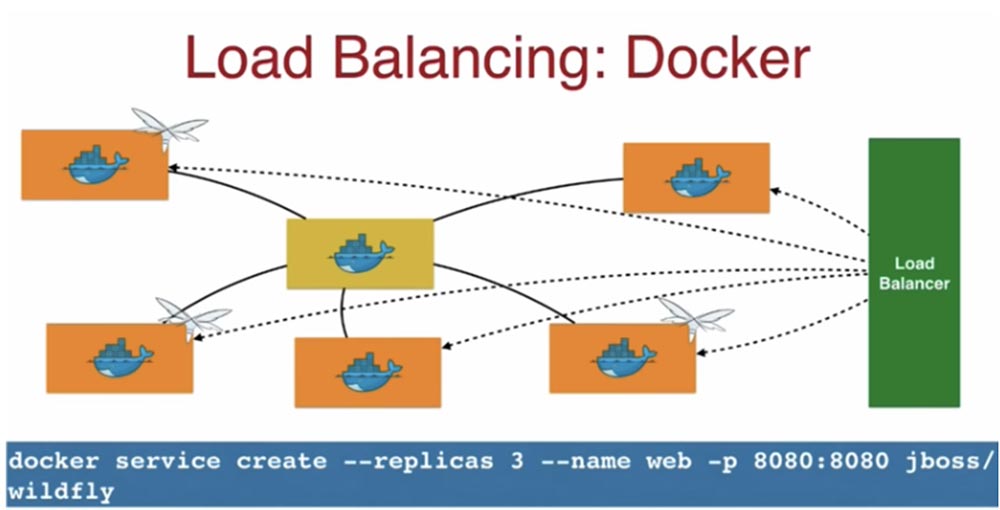
Рассмотрим, как работает балансировщик нагрузки Load balancer. В приведенном примере я с помощью команды docker service create создал сервис – WildFly контейнер, указав номер порта в виде 8080:8080. Это означает, что порт 8080 на хосте – локальной машине — будет увязан с портом 8080 внутри контейнера, так что вы сможете получить доступ к приложению через localhost:8080. Это будет порт доступа ко всем рабочим узлам.

Помните, что балансировщик нагрузки ориентирован на хост, а не на контейнеры. Он использует порты 8080 каждого хоста, независимо от того, запущены ли на хосте контейнеры или нет, потому что сейчас контейнер работает на одном хосте, а после выполнения задачи может быть перенесен на другой хост.
Итак, запросы клиента поступают балансировщику нагрузки, он перенаправляет их на любой из хостов, и если, используя таблицу IP-адресов, попадает на хост с незапущенным контейнером, то автоматически перенаправляет запрос хосту, на котором запущен контейнер.
Одиночный хоп обходится не дорого, но он полностью «бесшовный» в отношении масштабирования ваших сервисов в сторону увеличения или уменьшения. Благодаря этому вы можете быть уверены, что ваш запрос попадет именно тому хосту, где запущен контейнер.
Теперь давайте рассмотрим, как работает Service Discovery в Kubernetes. Как я говорил, сервис – это абстракция в виде набора подов с одинаковым IP-адресом и номером порта и простым TCP/UDP балансировщиком нагрузки. На следующем слайде показан файл конфигурации Service Discovery.

Создание таких ресурсов, как поды, сервисы, реплики и т.д. происходит на основе файла конфигурации. Вы видите, что он разбит на 3 части с помощью строк 17 и 37, которые состоят только из — - -.
Посмотрим сначала на строку 39 – в ней значится kind: ReplicaSet, то есть то, что мы создаем. В строках 40-43 расположены метаданные, с 44 строки указывается спецификация для нашего набора реплик. В строке 45 указано, что у меня имеется 1 реплика, ниже указаны ее метки Labels, в данном случае это имя wildfly. Еще ниже, начиная с 50 строки, указывается, в каких контейнерах должна запускаться данная реплика – это wildfly-rs-pod, а строки 53-58 содержат спецификацию этого контейнера.
23:05 мин
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 3
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
- Локальный девелопмент.
- Функции развертывания.
- Мультиконтейнерные приложения.
- Обнаружение служб service discovery.
- Масштабирование сервиса.
- Run-once задания.
- Интеграция с Maven.
- «Скользящее» обновление.
- Создание кластера БД Couchbase.
В результате вы получите четкое представление о том, что может предложить каждый инструмент оркестровки, и изучите методы эффективного использования этих платформ.
Арун Гупта — главный технолог open-source продуктов Amazon Web Services, который уже более 10 лет развивает сообщества разработчиков Sun, Oracle, Red Hat и Couchbase. Имеет большой опыт работы в ведущих кросс-функциональных командах, занимающихся разработкой и реализацией стратегии маркетинговых кампаний и программ. Руководил группами инженеров Sun, является одним из основателей команды Java EE и создателем американского отделения Devoxx4Kids. Арун Гупта является автором более 2 тысяч постов в IT-блогах и выступил с докладами более чем в 40 странах.
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 1
Концепт масштабирования Scale означает возможность управлять количеством реплик, увеличивая или уменьшая число экземпляров приложения.
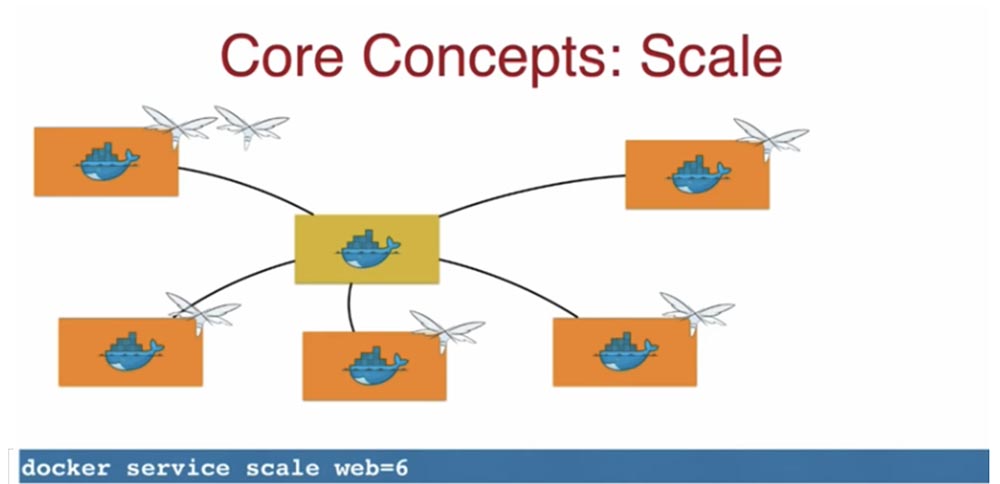
Для примера: если хотите масштабировать систему до 6 реплик, используйте команду docker service scale web=6.
Наряду с концептом Replicated Service в Docker существует концепт общих сервисов Global Service. Скажем, я хочу запустить экземпляр одного и того же контейнера на каждом узле кластера, в данном случае это контейнер приложения веб-мониторинга Prometheus. Это приложение используется, когда требуется собрать метрики о работе хостов. В этом случае вы используете подкоманду — - mode=global — - name=prom prom/Prometheus.
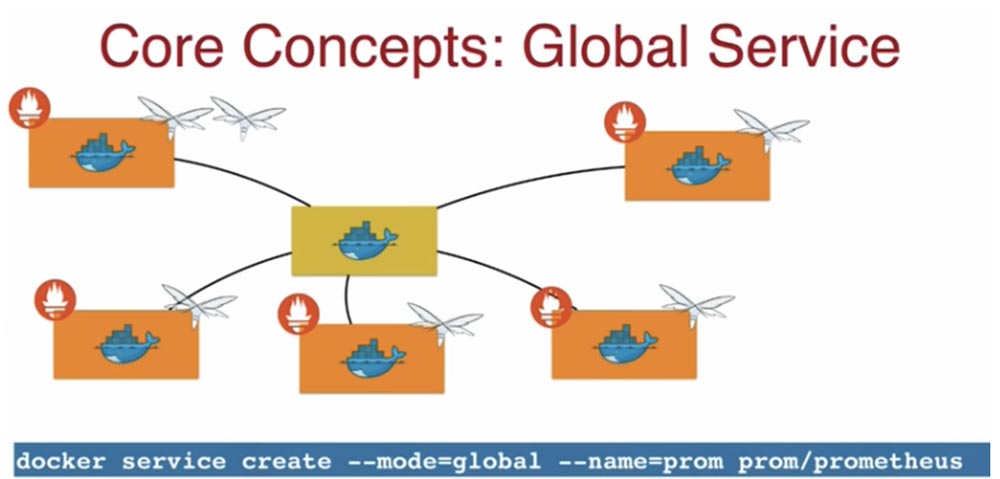
В результате приложение Prometheus будет запущено на всех узлах кластера без исключения, и если в кластер будут добавлены новые ноды, то оно автоматически запустится в контейнере и в этих нодах. Надеюсь, вы поняли разницу между Replicated Service и Global Service. Обычно Replicated Service это то, с чего вы начинаете.
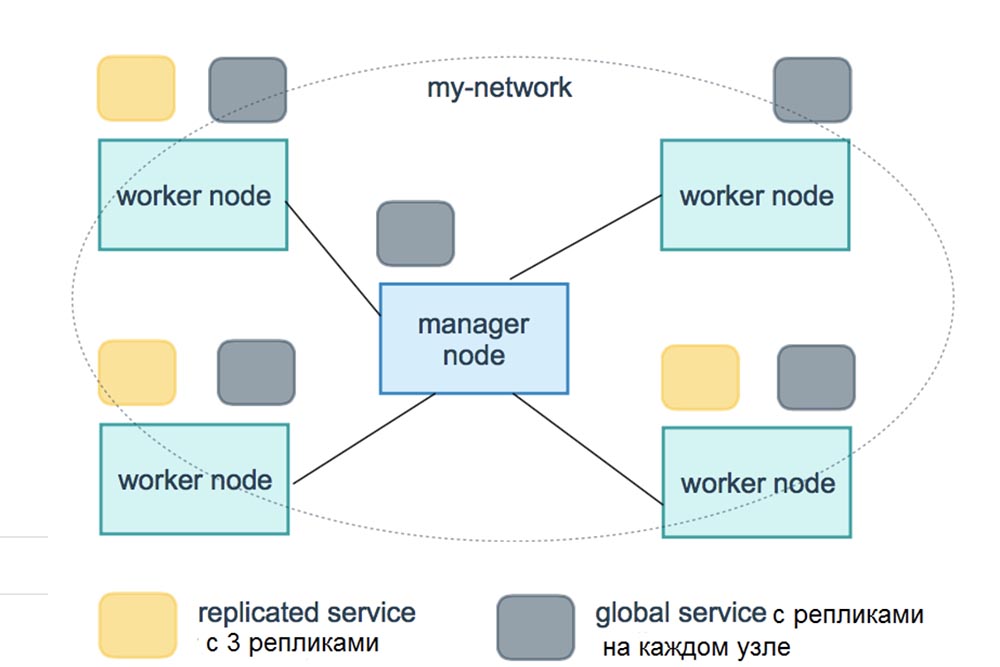
Итак, мы рассмотрели основные понятия, или основные сущности Docker, а теперь рассмотрим сущности Kubernetes. Kubernetes – это тоже своего рода планировщик, платформа для оркестровки контейнеров. Нужно помнить, что основной концепт планировщика — это знание того, как запланировать работу контейнеров на разных хостах. Если же перейти на более высокий уровень, можно сказать, что оркестровка означает расширение ваших возможностей до управления кластерами, получения сертификатов и т.д. В этом смысле и Docker, и Kubernetes являются платформами оркестровки, причем оба имеют встроенный планировщик.
Оркестровка представляет собой автоматизированное управление связанными сущностями — кластерами виртуальных машин или контейнеров. Kubernetes — это совокупность сервисов, реализующих контейнерный кластер и его оркестровку. Он не заменяет Docker, но серьёзно расширяет его возможности, упрощая управление развертыванием, сетевой маршрутизацией, расходом ресурсов, балансировкой нагрузки и отказоустойчивостью запускаемых приложений.
По сравнению с Kubernetes, Docker ориентирован именно на работу с контейнерами, создавая их образы с помощью docker-файла. Если сравнить объекты Docker и Kubernetes, можно сказать, что Docker управляет контейнерами, в то время как Kubernetes управляет самим Docker.
Кто из вас имел дело с контейнерами Rocket? А кто-нибудь использует Rocket в продакшене? В зале поднял руку всего один человек, это типичная картина. Это альтернатива Docker, которая до сих пор не прижилась в сообществе разработчиков.
Итак, основной сущностью Kubernetes является Pod. Он представляет собой связанную группу контейнеров, которые используют общее пространство имен, общее хранилище и общий IP-адрес. Все контейнеры в поде общаются друг с другом через локальный хост. Это означает, что вы не сможете разместить приложение и базу данных в одном и том же поде. Они должны размещаться в разных подах, поскольку имеют разные требования масштабирования.
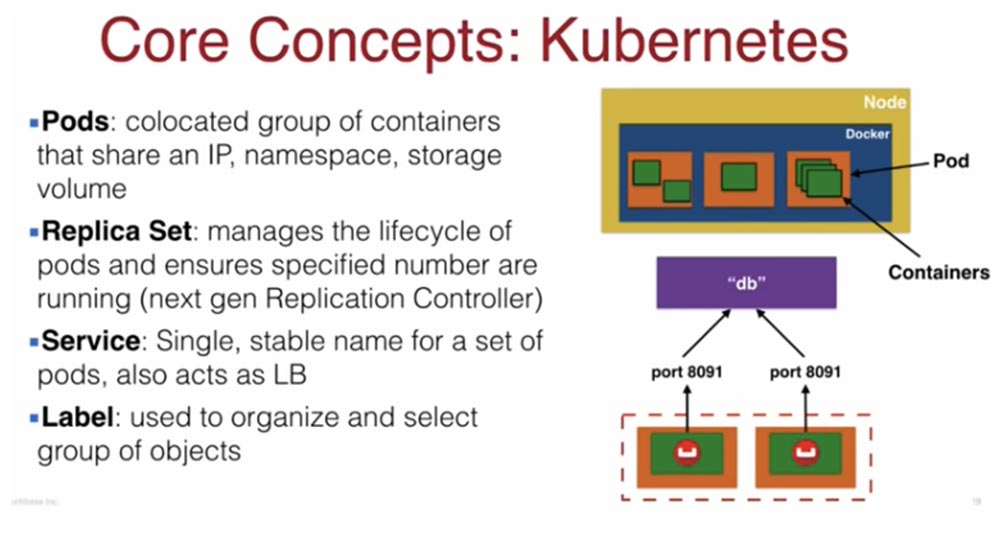
Таким образом, вы можете разместить в одном поде, например, WildFly контейнер, логин-контейнер, прокси-контейнер, или кэш-контейнер, причем вы должны ответственно подходить к составу компонентов контейнера, который собираетесь масштабировать.
Обычно вы «обертываете» свой контейнер в набор реплик Replica Set, поскольку хотите запускать в поде определенное количество экземпляров. Replica Set приказывает запустить столько реплик, сколько требует сервис масштабирования Docker, и указывает, когда и каким образом это проделать.
Поды похожи на контейнеры в том смысле, что если происходит сбой пода на одном хосте, он перезапускается на другом поде с другим IP-адресом. Как Java-разработчик, вы знаете, что когда создаете java-приложение и оно связывается с базой данных, вы не можете полагаться на динамический IP-адрес. В этом случае Kubernetes использует Service – этот компонент публикует приложение как сетевой сервис, создавая статичное постоянное сетевое имя для набора подов, одновременно реализуя балансировку нагрузки между подами. Можно сказать, что это служебное имя базы данных, и java-приложение не полагается на IP-адрес, а взаимодействует только с постоянным именем базы данных.
Это достигается тем, что каждый Pod снабжается определенной меткой Label, которые хранятся в распределенном хранилище etcd, и Service следит за этими метками, обеспечивая связь компонентов. То есть поды и сервисы устойчиво взаимодействуют друг с другом с помощью этих меток.
Теперь давайте рассмотрим, как создать кластер Kubernetes. Для этого, как и в Docker, нам нужен мастер-нод и рабочий нод. Нод в кластере обычно представлен физической или виртуальной машиной. Здесь, как и в Docker, мастер представляет собой центральную управляющую структуру, которая позволяет контролировать весь кластер через планировщик и менеджер контроллеров. По умолчанию мастер-нод существует в единственном числе, но есть множество новых инструментов, позволяющих создавать несколько мастер-нодов.
Master-node обеспечивает взаимодействие с пользователем при помощи API-сервера и содержит распределенное хранилище etcd, в котором находится конфигурация кластера, статусы его объектов и метаданные.
Рабочие узлы Worker-node предназначены исключительно для запуска контейнеров, для этого в них установлены два сервиса Kubernetes — сетевой маршрутизатор proxy service и агент планировщика kubelet. Во время работы этих узлов Docker выполняет их мониторинг с помощью systemd (CentOS) или monit (Debian) в зависимости от того, какой операционной системой вы пользуетесь.
Рассмотрим архитектуру Kubernetes более широко. У нас имеется Master, в составе которого присутствуют API –сервер (поды, сервисы и т.д.), управляемый с помощью CLI kubectl. Kubectl позволяет создавать ресурсы Kubernetes. Он передает API-серверу команды типа «создать под», «создать сервис», «создать набор реплик».
Далее здесь имеется планировщик Scheduler, менеджер контроллеров Controller Manager и хранилище etcd. Менеджер контроллеров, получив указания API-сервера, сопоставляет метки реплик с метками подов, обеспечивая устойчивое взаимодействие компонентов. Планировщик, получив задание создать под, просматривает рабочие ноды и создает его там, где это предусмотрено. Естественно, что он получает эту информацию из etcd.
Далее у нас имеется несколько рабочих нодов, и API-сервер общается с содержащимися в них Kubelet-агентами, сообщая им, как должны создаваться поды. Здесь расположен прокси, который предоставляет вам доступ к приложению, использующему эти поды. Справа на слайде показан мой клиент – это запрос интернета, который поступает в балансировщик нагрузки, тот обращается к прокси, который распределяет запрос по подам и направляет ответ обратно.
Вы видите итоговый слайд, который изображает кластер Kubernetes и то, как работают все его компоненты.
Давайте подробнее поговорим о Service Discovery и балансировщике нагрузки Docker. Когда вы запускаете свое Java-приложение, обычно это происходит в нескольких контейнерах на нескольких хостах. Существует компонент Docker Compose, который позволяет с легкостью запускать мультиконтейнерные приложения. Он описывает мультиконтейнерные приложения и запускает их при помощи одного или нескольких yaml-файлов конфигурации.

По умолчанию это файлы docker-compose.yaml и docker-compose.override.yaml, при этом множества файлов указываются с помощью – f. В первой файле вы прописываете сервис, образы, реплики, метки и т.д. Второй файл используется для перезаписи конфигурации. После создания docker-compose.yaml он развертывается в мультихостовом кластере, который ранее создал Docker Swarm. Вы можете создать один базовый файл конфигурации docker-compose.yaml, в который будете добавлять файлы специфических конфигураций для разных задач с указанием определенных портов, образов и т.д., позже мы поговорим об этом.
На этом слайде вы видите простой пример файла Service Discovery. В первой строке указывается версия, а строка 2 показывает, что он касается сервисов db и web.

Я добиваюсь того, чтобы после «поднятия» мой web-сервис мог общаться с db-сервисом. Это простые java-приложения, развертываемые в контейнерах WildFly. В 11 строке я прописываю среду couchbase_URI=db. Это означает, что мой db-сервис использует эту базу данных. В строке 4 указан образ couchbase, а в строках 5-9 и 15-16 соответственно порты, необходимые для обеспечения работы моих сервисов.
Ключом к пониманию процесса обнаружения сервисов служит то, что вы создаете некоторого рода зависимости. Вы указываете, что web-контейнер должен запуститься раньше db-контейнера, но это только на уровне контейнеров. Как реагирует ваше приложение, как оно стартует – это совершенно другие вещи. Например, обычно контейнер «поднимается» за 3-4 секунды, однако запуск контейнера базы данных занимает гораздо больше времени. Так что логика запуска вашего приложения должна быть «запечена» в вашем java-приложении. То есть приложение должно пинговать базу данных, чтобы убедиться в ее готовности. Поскольку база данных couchbase – это REST API, вы должны вызвать этот API и спросить: «Эй, ты готов? Если да, то я готов присылать тебе запросы»!
Таким образом, зависимости на уровне контейнеров определяются с помощью сервиса docker-compose, но на уровне приложений зависимости и жизнеспособность определяются на основе опросов responsibility. Затем вы берете файл docker-compose.yaml и развертываете в мультихостовом Docker с помощью команды docker stack deploy и подкоманды — - compose-file= docker-compose.yaml webapp. Итак, у вас есть большой стек, в котором расположено несколько сервисов, решающих несколько задач. В основном это задачи запуска контейнеров.
Рассмотрим, как работает балансировщик нагрузки Load balancer. В приведенном примере я с помощью команды docker service create создал сервис – WildFly контейнер, указав номер порта в виде 8080:8080. Это означает, что порт 8080 на хосте – локальной машине — будет увязан с портом 8080 внутри контейнера, так что вы сможете получить доступ к приложению через localhost:8080. Это будет порт доступа ко всем рабочим узлам.
Помните, что балансировщик нагрузки ориентирован на хост, а не на контейнеры. Он использует порты 8080 каждого хоста, независимо от того, запущены ли на хосте контейнеры или нет, потому что сейчас контейнер работает на одном хосте, а после выполнения задачи может быть перенесен на другой хост.
Итак, запросы клиента поступают балансировщику нагрузки, он перенаправляет их на любой из хостов, и если, используя таблицу IP-адресов, попадает на хост с незапущенным контейнером, то автоматически перенаправляет запрос хосту, на котором запущен контейнер.
Одиночный хоп обходится не дорого, но он полностью «бесшовный» в отношении масштабирования ваших сервисов в сторону увеличения или уменьшения. Благодаря этому вы можете быть уверены, что ваш запрос попадет именно тому хосту, где запущен контейнер.
Теперь давайте рассмотрим, как работает Service Discovery в Kubernetes. Как я говорил, сервис – это абстракция в виде набора подов с одинаковым IP-адресом и номером порта и простым TCP/UDP балансировщиком нагрузки. На следующем слайде показан файл конфигурации Service Discovery.

Создание таких ресурсов, как поды, сервисы, реплики и т.д. происходит на основе файла конфигурации. Вы видите, что он разбит на 3 части с помощью строк 17 и 37, которые состоят только из — - -.
Посмотрим сначала на строку 39 – в ней значится kind: ReplicaSet, то есть то, что мы создаем. В строках 40-43 расположены метаданные, с 44 строки указывается спецификация для нашего набора реплик. В строке 45 указано, что у меня имеется 1 реплика, ниже указаны ее метки Labels, в данном случае это имя wildfly. Еще ниже, начиная с 50 строки, указывается, в каких контейнерах должна запускаться данная реплика – это wildfly-rs-pod, а строки 53-58 содержат спецификацию этого контейнера.
23:05 мин
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 3
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
