
Осенью 2019 года в iOS команде Облака Mail.ru произошло долгожданное событие. Основной базой данных для персистентного хранения состояния приложения стала весьма экзотическая для мобильного мира Lightning Memory-Mapped Database (LMDB). Под катом вашему вниманию предлагается её подробный обзор в четырех частях. Сначала поговорим о причинах столь нетривиального и трудного выбора. Затем перейдем к рассмотрению трёх китов в основе архитектуры LMDB: отображённые в память файлы, B+-дерево, copy-on-write подход для реализации транзакционности и мультиверсионности. Наконец, на сладкое — практическая часть. В ней рассмотрим, как поверх низкоуровневого key-value API спроектировать и реализовать схему базы с несколькими таблицами, включая индексную.
Содержание
- Мотивация внедрения
- Позиционирование LMDB
- Три кита LMDB
3.1. Кит №1. Memory-mapped files
3.2. Кит №2. B+-дерево
3.3. Кит №3. Copy-on-write - Проектирование схемы данных поверх key-value API
4.1. Базовые абстракции
4.2. Моделирование таблиц
4.3. Моделирование связей между таблицами
1. Мотивация внедрения
Однажды году так в 2015 мы озаботились снятием метрики, как часто интерфейс нашего приложения лагает. Занялись мы этим не просто так. У нас участились жалобы на то, что иногда приложение перестаёт реагировать на действия пользователя: кнопки не нажимаются, списки не скролятся и т.п. О механике измерений я рассказывал на AvitoTech, поэтому здесь привожу лишь порядок цифр.
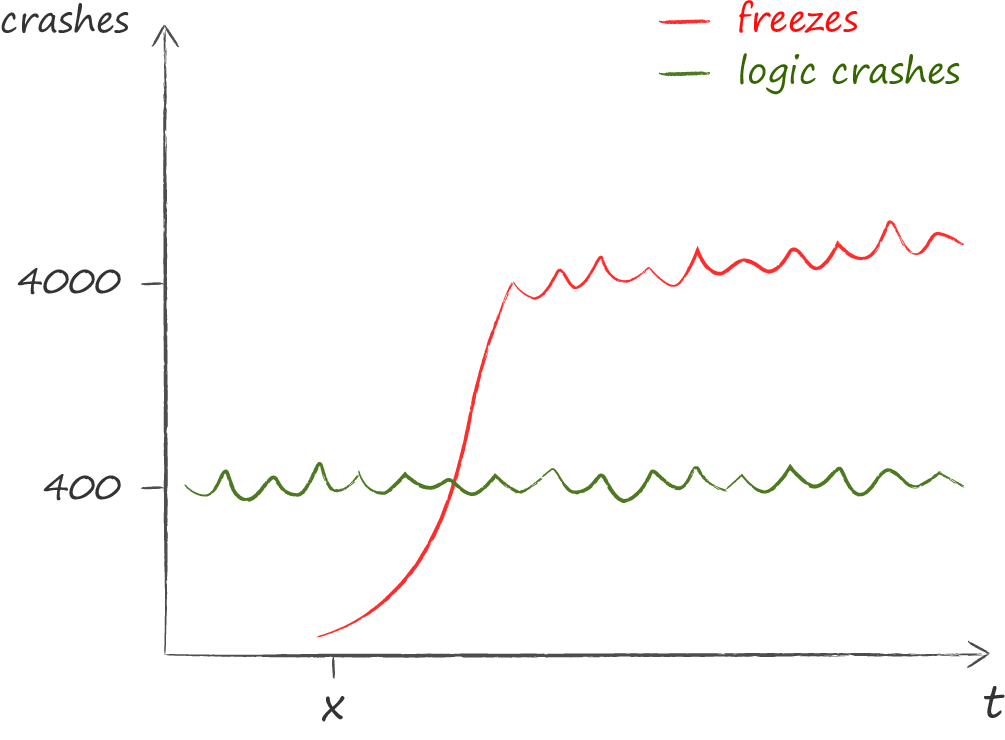
Результаты измерений стали для нас холодным душем. Оказалось, что проблем, вызванных зависаниями, гораздо больше, чем каких-либо других. Если до осознания этого факта главным техническим показателем качества был crash free, то после фокус сместился на freeze free.
Построив дашборд с зависаниями и проведя количественный и качественный анализ их причин, стал понятен главный враг — тяжёлая бизнес-логика, исполняющаяся в главном потоке приложения. Естественной реакцией на это безобразие стало жгучее желание распихать её по рабочим потокам. Для системного решения этой задачи мы прибегли к многопоточной архитектуре на основе легковесных акторов. Её адаптации для мира iOS я посвятил два тредика в коллективном твиттере и статью на Хабре. В рамках же текущего повествования хочу подчеркнуть те аспекты решения, которые повлияли на выбор базы данных.
Акторная модель организации системы предполагает, что многопоточность становится её второй сутью. Объекты модели в ней любят пересекать границы потоков. И делают они это не иногда и кое-где, а практически постоянно и везде.

База данных является одним из краеугольных компонентов на представленной схеме. Её основной задачей является реализация макропаттерна Shared Database. Если в энтерпрайзном мире с его помощью организовывают синхронизацию данных между сервисами, то в случае акторной архитектуры — данные между потоками. Таким образом, нам понадобилась такая база данных, работа с которой в многопоточной среде не вызывает даже минимальных сложностей. В частности, это означает, что полученные из неё объекты должны быть как минимум потокобезопасными, а в идеале и вовсе немутабельными. Как известно, последние можно использовать одновременно из нескольких потоков, не прибегая к каким бы то ни было блокировкам, что благостно сказывается на производительности.
 Вторым значимым фактором, повлиявшим на выбор базы данных, стало наше облачное API. Оно было вдохновлено подходом к синхронизации, принятой на вооружение в git. Как и он мы целились в offline-first API, которое для облачных клиентов выглядит более чем уместно. Предполагалось, что они будут лишь однажды выкачивать полное состояние облака, а затем синхронизация в подавляющем числе случаев будет происходить через накатывание изменений. Увы, эта возможность всё ещё находится лишь в теоретической зоне, а на практике работать с патчами клиенты так и не научились. Тому есть ряд объективных причин, которые, дабы не затягивать введение, оставим за скобками. Сейчас же гораздо больший интерес представляют поучительные итоги урока о том, что происходит когда API сказало «А», а его потребитель не сказал «Б».
Вторым значимым фактором, повлиявшим на выбор базы данных, стало наше облачное API. Оно было вдохновлено подходом к синхронизации, принятой на вооружение в git. Как и он мы целились в offline-first API, которое для облачных клиентов выглядит более чем уместно. Предполагалось, что они будут лишь однажды выкачивать полное состояние облака, а затем синхронизация в подавляющем числе случаев будет происходить через накатывание изменений. Увы, эта возможность всё ещё находится лишь в теоретической зоне, а на практике работать с патчами клиенты так и не научились. Тому есть ряд объективных причин, которые, дабы не затягивать введение, оставим за скобками. Сейчас же гораздо больший интерес представляют поучительные итоги урока о том, что происходит когда API сказало «А», а его потребитель не сказал «Б».
Так вот, если вы представите себе git, который при выполнении команды pull вместо применения патчей к локальному снапшоту сравнивает его полное состояние с полным же серверным, то у вас будет достаточно точное представление, как происходит синхронизация в облачных клиентах. Несложно догадаться, что для её осуществления необходимо аллоцировать в памяти два DOM-дерева с метаинформацией обо всех серверных и локальных файлах. Получается, что если пользователь хранит в облаке 500 тысяч файлов, то для его синхронизации необходимо воссоздать и уничтожить два дерева с 1 миллионом узлов. А ведь каждый узел — это агрегат, содержащий в себе граф подобъектов. В этом свете итоги профилирования оказались ожидаемы. Обнаружилось, что даже без учёта алгоритмики слияния в копеечку влетает уже сама процедура создания и последующего разрушения огромного количества мелких объектов. Положение усугубляется тем, что базовая операция синхронизации включена в большое количество пользовательских сценариев. Как итог фиксируем второй важный критерий в выборе базы данных — возможность реализации операций CRUD без динамической аллокации объектов.
Другие требования более традиционны и их список целиком выглядит следующим образом.
- Потокобезопасность.
- Мультипроцессность. Продиктована желанием использовать один и тот же инстанс базы данных для синхронизации состояния не только между потоками, но и между основным приложением и экстеншенами iOS.
- Возможность представлять хранимые сущности в виде немутабельных объектов.
- Отсутствие динамических аллокаций в рамках операций CRUD.
- Поддержка транзакциями базовых свойств ACID: атомарность, консистентность, изолированность и надёжность.
- Скорость на наиболее популярных кейсах.
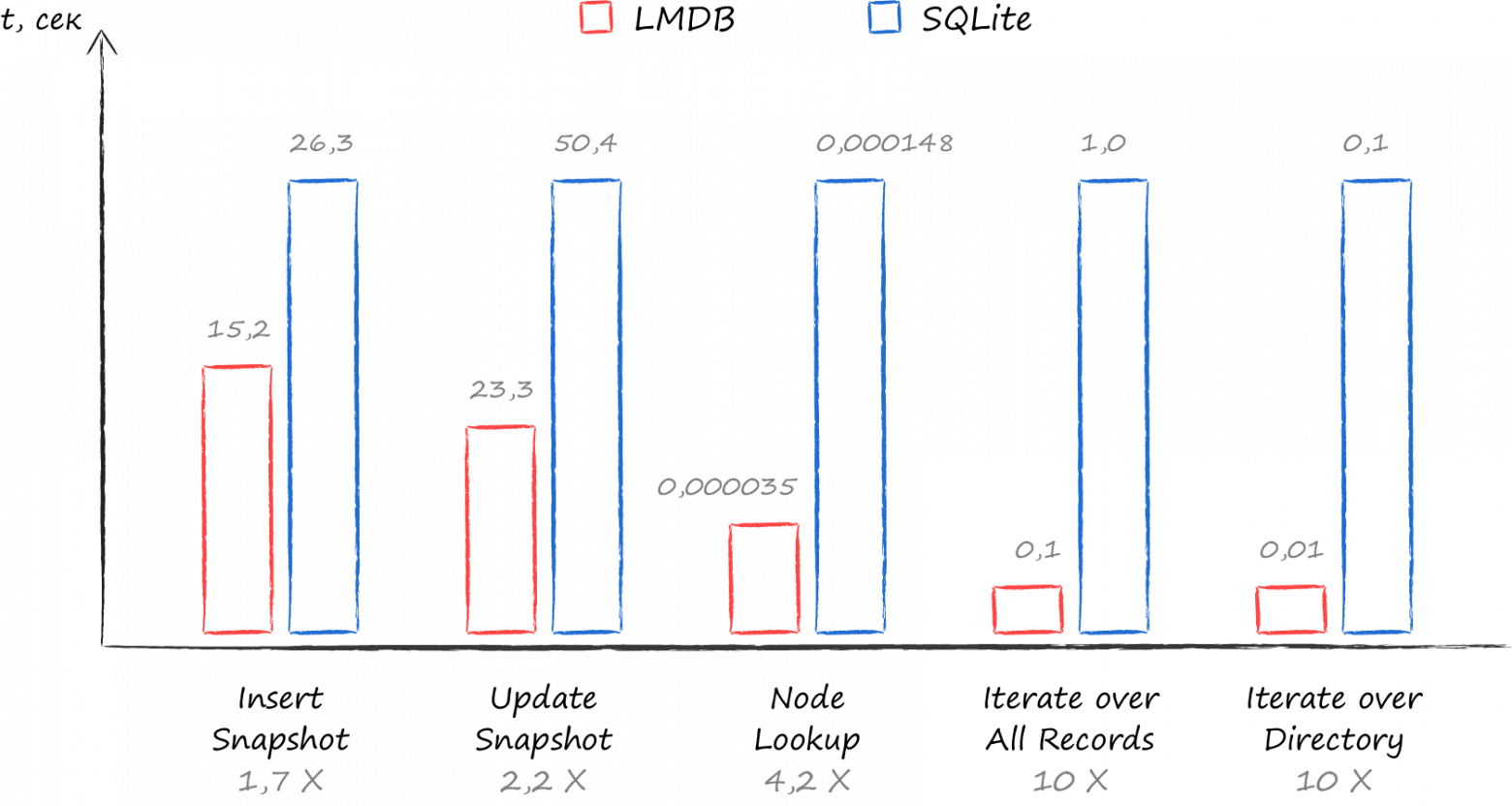
Хорошим выбором с таким набором требований был и остаётся SQLite. Однако в рамках изучения альтернатив, мне под руку попалась книжка «Getting Started with LevelDB». Под её руководством был написан бенчмарк, сравнивающий скорость работы с разными базами данных в рамках реальных облачных сценариев. Результат превзошёл самые смелые ожидания. На самых популярных кейсах — получение курсора на сортированный список всех файлов и сортированный список всех файлов для заданной директории — LMDB оказалась быстрее SQLite в 10 раз. Выбор стал очевиден.
2. Позиционирование LMDB
LMDB — это библиотечка, очень небольшая (всего 10К строк), реализующая самый нижний основополагающий слой баз данных — хранилище.
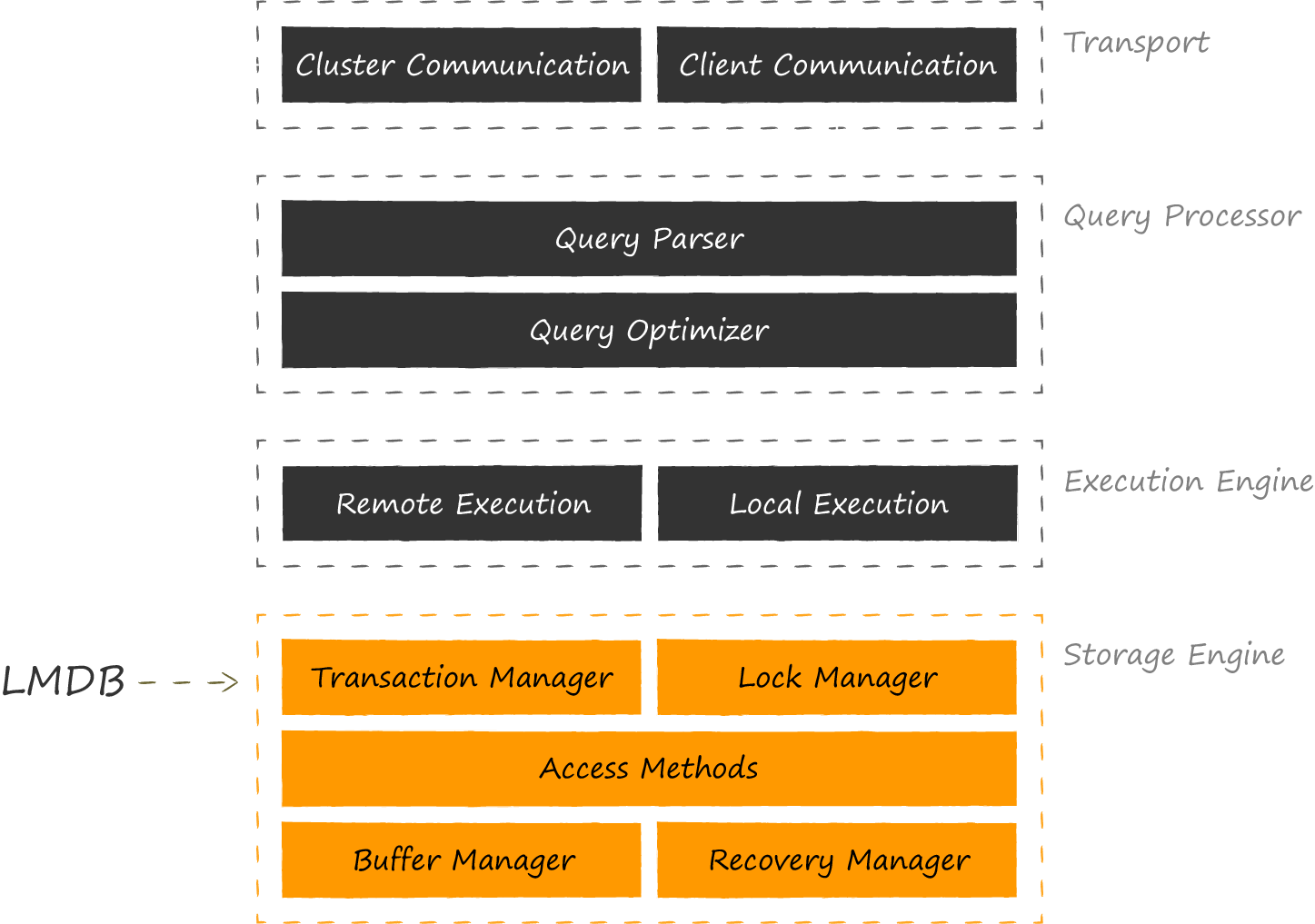
Приведенная схема показывает, что сравнивать LMDB с SQLite, который реализует ещё и более высокие уровни, в общем-то не корректнее, чем SQLite с Core Data. В качестве равноправных конкурентов будет более справедливым приводить такие же движки-хранилища — BerkeleyDB, LevelDB, Sophia, RocksDB и др. Есть даже разработки, где LMDB выступает в качестве компонента storage engine для SQLite. Первым такой эксперимент в 2012 году провел автор LMDB Howard Chu. Результаты оказались настолько интригующими, что его начинание было подхвачено энтузиастами OSS, и нашло своё продолжение в лице LumoSQL. В январе 2020 автор этого проекта Den Shearer презентовал его на LinuxConfAu.
Главное применение LMDB находит в качестве движка для прикладных баз данных. Своим появлением библиотека обязана разработчикам OpenLDAP, которые были сильно не удовлетворены BerkeleyDB в качестве основы своего проекта. Оттолкнувшись от скромной библиотечки btree, Howard Chu смог создать одну из самых популярных в наше время альтернатив. Этой истории а также внутреннему устройству LMDB он посвятил свой очень крутой доклад «The Lightning Memory-mapped Database». Хорошим примером покорения хранилища поделился Леонид Юрьев (aka yleo) из Positive Technologies в своём докладе на Highload 2015 «Движок LMDB — особенный чемпион». В нём он рассказывает об LMDB в контексте похожей задачи реализации ReOpenLDAP, а сравнительной критике подверглась уже LevelDB. По итогам внедрения у Positive Technologies даже появился активно развивающийся форк MDBX с очень вкусными фичами, оптимизациями и багфиксами.
LMDB нередко используется и в качестве хранилища as is. Например, браузер Mozilla Firefox выбрал его для целого ряда нужд, а, начиная с 9 версии, Xcode предпочёл его SQLite для хранения индексов.
Движок засветился и в мире мобильной разработки. Следы его использования можно найти в iOS клиенте для Telegram. LinkedIn пошёл ещё дальше и выбрал LMDB хранилищем по умолчанию для доморощенного фреймворка кеширования данных Rocket Data, о чём поведал в своей статье в 2016 году.
LMDB успешно борется за место под солнцем в нише, оставленной BerkeleyDB после перехода под контроль Oracle. Библиотеку любят за скорость и надёжность даже в сравнении с себе подобными. Как известно, бесплатных обедов не бывает, и хочется подчеркнуть trade-off, с которым придётся столкнуться при выборе между LMDB и SQLite. Схема выше наглядно демонстрирует, за счёт чего достигается повышенная скорость. Во-первых, мы не платим за дополнительные слои абстракции поверх дискового хранилища. Понятное дело, в хорошей архитектуре без них всё равно не обойтись, и они неизбежно появятся в коде приложения, однако они будут гораздо тоньше. В них не будет фич, которые не востребованы конкретным приложением, например, поддержки запросов на языке SQL. Во-вторых, появляется возможность оптимально реализовать маппинг прикладных операций на запросы к дисковому хранилищу. Если SQLite в своей работе исходит из среднестатистических потребностей среднестатистического приложения, то вы как прикладной разработчик прекрасно осведомлены об основных сценариях нагрузки. За более производительное решение придётся заплатить возросшим ценником как на разработку первоначального решения, так и на его последующую поддержку.
3. Три кита LMDB
Посмотрев на LMDB с высоты птичьего полёта, пришла пора спускаться глубже. Следующие три раздела будут посвящены разбору основных китов, на которых покоится архитектура хранилища:
- Отображённые в память файлы в качестве механизма работы с диском и синхронизации внутренних структур данных.
- B+-дерево в качестве организации структуры хранимых данных.
- Copy-on-write в качестве подхода для обеспечения ACID-свойств транзакций и мультиверсионности.
3.1. Кит №1. Memory-mapped files
Отображённые в память файлы — настолько важный архитектурный элемент, что они даже фигурируют в названии хранилища. Вопросы кеширования и синхронизации доступа к хранимой информации целиком и полностью отданы на откуп операционной системе. LMDB не содержит внутри себя каких бы то ни было кешей. Это осознанное решение автора, поскольку чтение данных напрямую из отображённых файлов позволяет срезать множество углов в реализации движка. Ниже привожу далеко не полный список некоторых из них.
- Поддержание консистентности данных в хранилище при работе с ним из нескольких процессов становится обязанностью операционной системы. В следующем разделе данная механика рассмотрена в подробностях и с картинками.
- Отсутствие кешей полностью избавляет LMDB от накладных расходов, связанных с динамическими аллокациями. Чтение данных на практике представляет собой установку указателя на правильный адрес в виртуальной памяти и не более. Звучит как фантастика, но в исходниках хранилища все вызовы сalloc сосредоточены в функции конфигурирования хранилища.
- Отсутствие кешей означает и отсутствие блокировок, связанных с синхронизацией к их доступу. Читатели, которых одновременно может существовать произвольное количество, не встречают на своём пути к данным ни единого мьютекса. За счёт этого скорость чтения имеет идеальную линейную масштабируемость по количеству CPU. В LMDB синхронизации подвергаются лишь модифицирующие операции. Писатель в каждый момент времени может быть только один.
- Минимум логики кеширования и синхронизации избавляет код от крайне сложного вида ошибок, связанных с работой в многопоточной среде. На конференции Usenix OSDI 2014 было два интересных исследования баз данных: «All File Systems Are Not Created Equal: On the Complexity of Crafting Crash-Consistent Applications» и «Torturing Databases for Fun and Profit». Из них можно почерпнуть информацию как о беспрецедентной надёжности LMDB, так и о практически безупречной реализации ACID-свойств транзакций, превосходящей оную в том же SQLite.
- Минималистичность LMDB позволяет машинному представлению её кода полностью размещаться в L1-кэше процессора с вытекающими отсюда скоростными характеристиками.
К сожалению, в iOS с отображёнными в память файлами всё не так безоблачно, как хотелось бы. Чтобы поговорить о связанных с ними недостатках более осознанно, необходимо вспомнить общие принципы реализации этого механизма в операционных системах.
Общие сведения об отображённых в память файлах
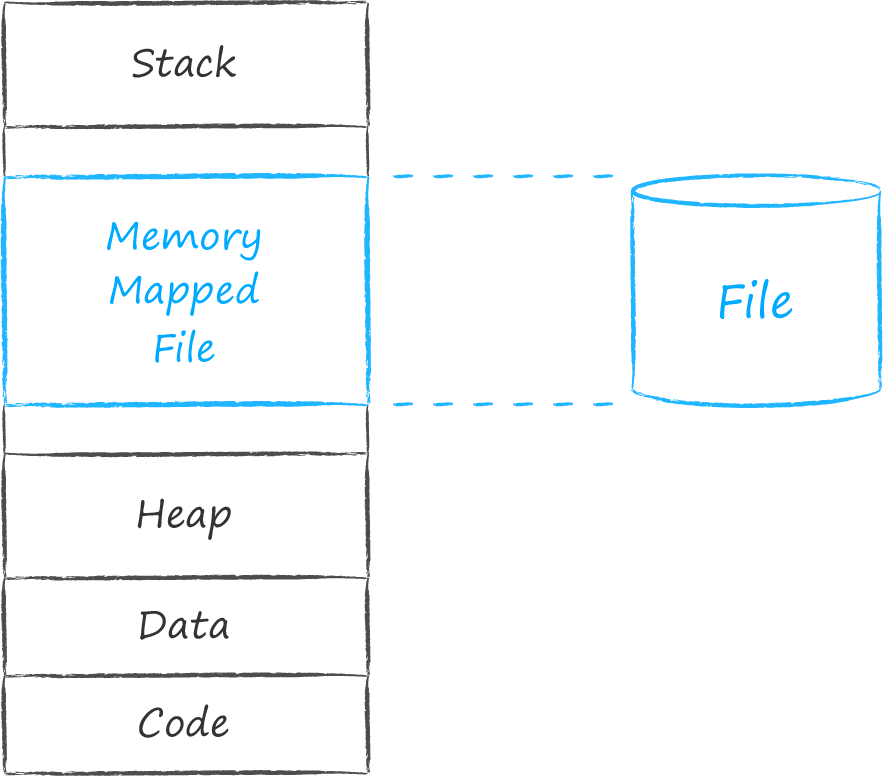 С каждым исполняемым приложением операционная система ассоциирует сущность под названием процесс. Каждому процессу выделяется непрерывный интервал адресов, в котором он размещает всё необходимое ему для работы. В самых нижних адресах располагаются секции с кодом и захардкоженными данными и ресурсами. Далее идет растущий вверх блок динамического адресного пространства, хорошо известный нам под именем heap. В нём содержаться адреса сущностей, которые появляются в процессе работы программы. Вверху располагается область памяти, используемая стеком приложения. Он то растет, то сжимается, другими словами его размер также имеет динамическую природу. Чтобы стек и heap не толкались и не мешали друг другу, они разведены по разным концам адресного пространства. Между двумя динамическими секциями вверху и внизу есть дырка. Адреса в этом срединном участке операционная система использует для ассоциации с процессом самых разных сущностей. В частности, она может поставить в соответствие некому непрерывному набору адресов — файл на диске. Такой файл называется отображённым в память.
С каждым исполняемым приложением операционная система ассоциирует сущность под названием процесс. Каждому процессу выделяется непрерывный интервал адресов, в котором он размещает всё необходимое ему для работы. В самых нижних адресах располагаются секции с кодом и захардкоженными данными и ресурсами. Далее идет растущий вверх блок динамического адресного пространства, хорошо известный нам под именем heap. В нём содержаться адреса сущностей, которые появляются в процессе работы программы. Вверху располагается область памяти, используемая стеком приложения. Он то растет, то сжимается, другими словами его размер также имеет динамическую природу. Чтобы стек и heap не толкались и не мешали друг другу, они разведены по разным концам адресного пространства. Между двумя динамическими секциями вверху и внизу есть дырка. Адреса в этом срединном участке операционная система использует для ассоциации с процессом самых разных сущностей. В частности, она может поставить в соответствие некому непрерывному набору адресов — файл на диске. Такой файл называется отображённым в память.
Выделенное процессу адресное пространство огромно. Теоретически количество адресов ограничено лишь размером указателя, определяющегося битностью системы. Если бы ему 1-в-1 была сопоставлена физическая память, то первый же процесс сожрал бы всю оперативу, и ни о какой многозадачности не могло бы идти и речи.
Однако из своего опыта мы знаем, что современные операционные системы могут одновременно исполнять сколь угодно много процессов. Это возможно благодаря тому, что они только лишь на бумаге выделяют процессам кучу памяти, а на деле загружают в основную физическую память только лишь ту часть, которая востребована здесь и сейчас. Поэтому проассоциированная с процессом память называется виртуальной.
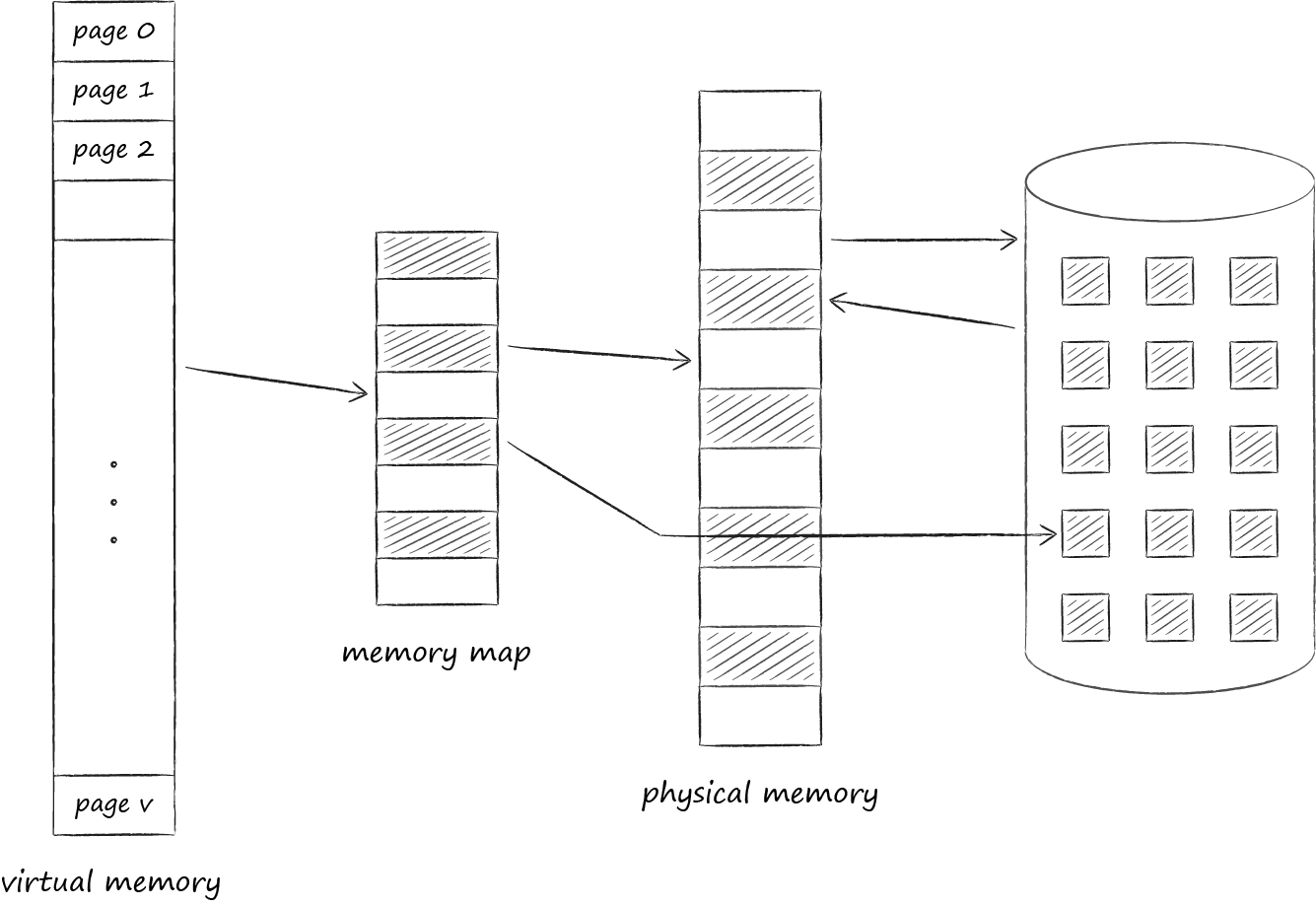
Операционная система организует виртуальную и физическую память в виде страниц определенного размера. Как только некая страница виртуальной памяти оказалась востребована, операционная система загружает её в физическую память и проставляет между ними соответствие в специальной таблице. Если свободные слоты отсутствуют, то одна из ранее загруженных страниц копируется на диск, а востребованная встаёт на её место. Эта процедура, к которой мы вскоре вернёмся, называется свопингом (swapping). Рисунок ниже иллюстрирует описанный процесс. На нём страница А с адресом 0 была загружена и размещена на странице основной памяти с адресом 4. Сей факт нашёл свое отражение в таблице соответствий в ячейке номер 0.

С отображёнными в память файлами история ровно такая же. Логически они якобы непрерывно и целиком размещаются в виртуальном адресном пространстве. Однако в физическую память они попадают постранично и лишь по требованию. Модификация таких страниц синхронизируется с файлом на диске. Таким образом можно выполнять файловый ввод/вывод, просто работая с байтами в памяти, — все изменения будут автоматически перенесены ядром операционки к исходному файлу.
Изображение ниже демонстрирует, как LMDB синхронизирует своё состояние при работе с базой данных из разных процессов. Замапливая виртуальную память разных процессов на один и тот же файл, де-факто мы обязуем операционную систему транзитивно синхронизировать между собой определенные блоки их адресных пространств, куда и смотрит LMDB.
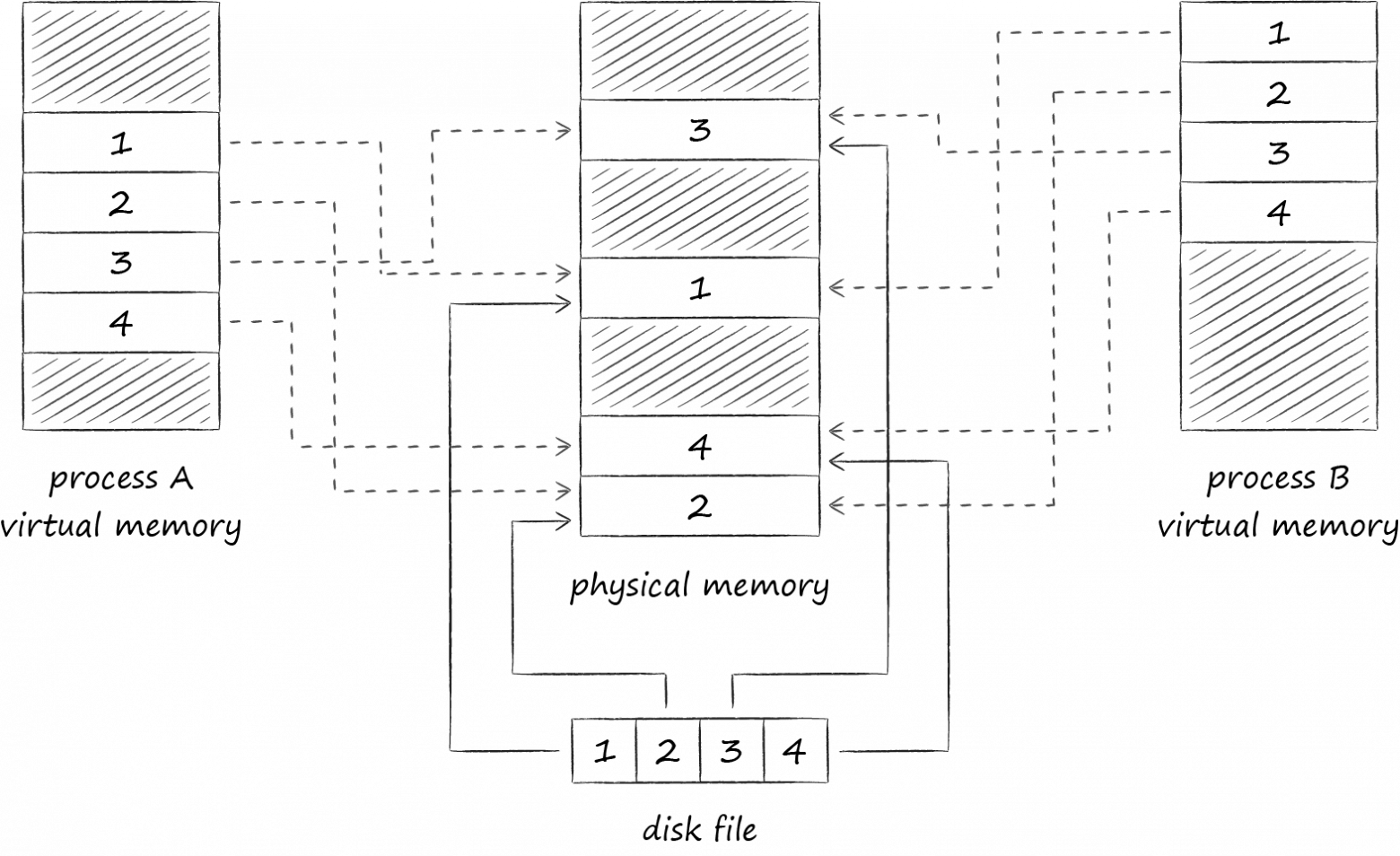
Важный нюанс состоит в том, что LMDB по умолчанию модифицирует файл с данными через механизм системного вызова write, а сам файл отображает в режиме read-only. У такого подхода есть два важных следствия.
Первое следствие — общее для всех операционных систем. Его суть в добавлении защиты от непреднамеренного повреждения базы данных некорректным кодом. Как известно, исполняемые инструкции процесса вольны обращаться к данным из любого места его адресного пространства. В то же время, как мы только что вспомнили, отображение файла в режиме read-write означает, что любая инструкция может его вдобавок ещё и модифицировать. Если она сделает это по ошибке, пытаясь, например, на самом деле перезаписать элемент массива по несуществующему индексу, то таким образом она может случайно изменить замапленный на этот адрес файл, что приведёт к порче базы данных. Если же файл отображён в режиме read-only, то попытка изменить соответствующее ему адресное пространство приведёт к аварийному завершению программы с сигналом SIGSEGV, и файл останется в целостности.
Второе следствие уже специфично для iOS. Ни автор, ни какие бы то ни было другие источники о нём явно не упоминают, но без него LMDB была бы непригодна для работы в этой мобильной операционной системе. Его рассмотрению посвящён следующий раздел.
Специфика отображённых в память файлов в iOS
В 2018 году на WWDC был замечательный доклад «iOS Memory Deep Dive». В нём рассказывается, что в iOS все страницы, расположенные в физической памяти, относятся к одному из 3 типов: dirty, compressed и clean.
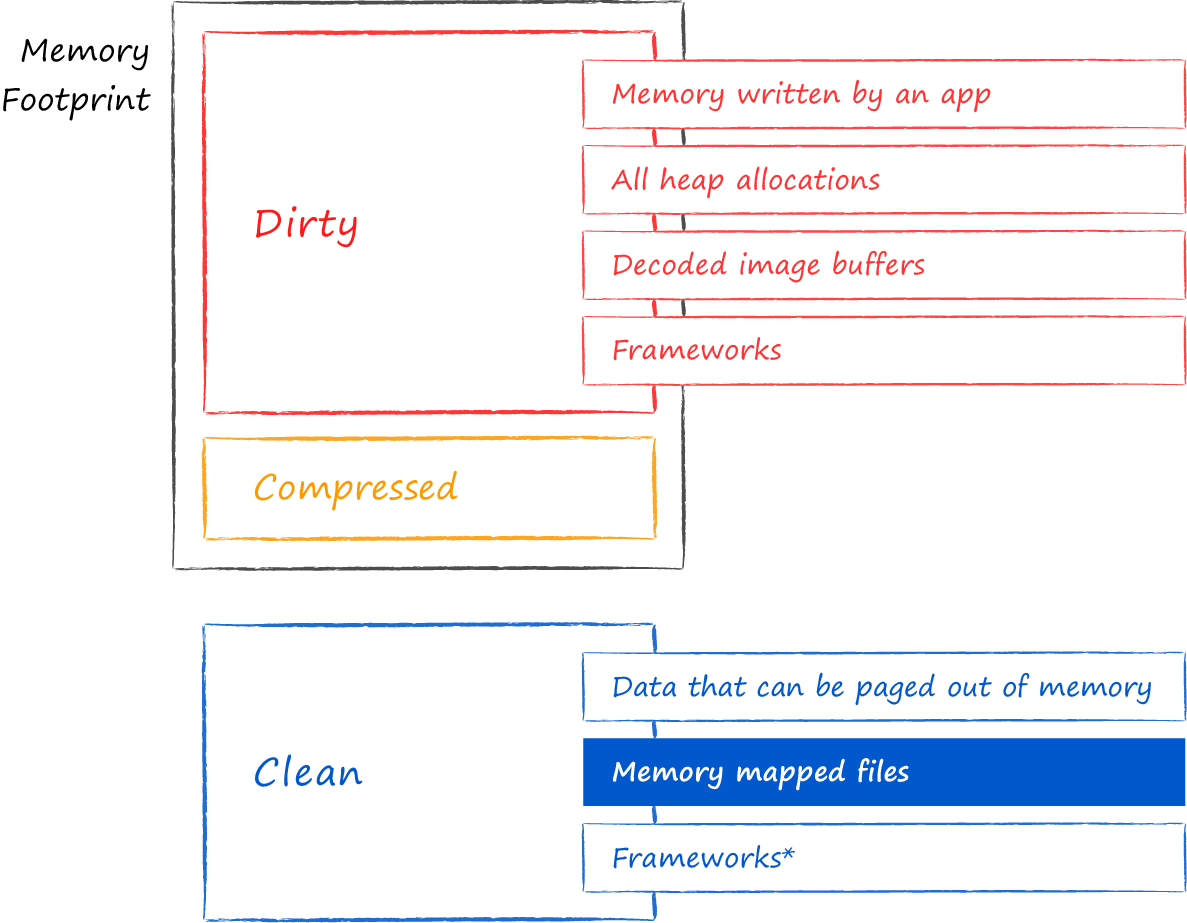
Clean memory — это совокупность страниц, которые могут быть безболезненно выгружены из физической памяти. Находящиеся в них данные можно по мере необходимости загрузить заново из их первоначальных источников. Read-only memory-mapped файлы попадают именно в эту категорию. iOS не боится в любой момент выгружать отображённые на файл страницы из памяти, поскольку они гарантированно синхронизированы с файлом на диске.
В dirty memory попадают все модифицированные страницы, где бы они изначально не располагались. В частности, так будут классифицированы и memory-mapped файлы, изменённые через запись в проассоциированную с ними виртуальную память. Открыв LMDB с флагом MDB_WRITEMAP, после внесения в неё изменений в этом можно убедится лично.
Как только приложение начинает занимать слишком много физической памяти, iOS подвергает его dirty станицы компрессии. Совокупность памяти, занимаемая dirty и compressed страницами, составляет так называемый memory footprint приложения. По достижении им некого порогового значения, за процессом приходит системный демон OOM killer и принудительно его завершает. В этом состоит особенность iOS по сравнению с десктопными операционными системами. В отличие от них понижение memory footprint посредством свопинга страниц из физической памяти на диск в iOS не предусмотрено. О причинах можно лишь гадать. Возможно процедура интенсивного перемещения страниц на диск и обратно слишком энергозатратна для мобильных устройств или iOS экономит ресурс перезаписи ячеек на SSD дисках, а может быть проектировщиков не удовлетворяла общая производительность системы, где всё постоянно свопится. Как бы то ни было, факт остаётся фактом.
Хорошая новость, уже упомянутая ранее, состоит в том, что LMDB по умолчанию не использует механизм mmap для обновления файлов. Из этого следует, что отображённые данные классифицируются iOS как clean memory и не вносят вклада в memory footprint. В этом можно убедиться с помощью инструмента Xcode под названием VM Tracker. На скриншоте ниже отображено состояние виртуальной памяти iOS приложения Облака во время работы. На старте в нём было инициализировано 2 инстанса LMDB. Первому было разрешено отобразить свой файл на 1GiB виртуальной памяти, второму — 512МiB. Несмотря на то, что оба хранилища занимают определенный объем резидентной памяти, ни один из них не контрибутит в dirty size.

А теперь время плохих новостей. Благодаря механизму свопинга в 64-битных настольных операционных системах каждый процесс может занять столько виртуального адресного пространства, сколько позволяет свободное место на жестком диске под его потенциальный своп. Замена свопинга на компрессию в iOS радикально снижает теоретический максимум. Теперь все живущие процессы должны влезть в основную (читай оперативную) память, а все не поместившиеся подлежат принудительному завершению. Об этом говорится как в упомянутом выше докладе, так и в официальной документации. Как следствие, iOS жёстко ограничивает размер памяти, доступной для выделения через mmap. Вот тут можно посмотреть на эмпирические пределы объёмов памяти, которые удалось аллоцировать на разных устройствах с помощью этого системного вызова. На самых современных моделях смартфонов iOS расщедрилась на 2 гигабайта, а на топовых версиях iPad — на 4. На практике, конечно же, приходится ориентироваться на самые младшие поддерживаемые модели устройств, где все очень грустно. Хуже того, посмотрев на состояние памяти приложения в VM Tracker, можно обнаружить, что LMDB далеко не единственная, кто претендует на memory-mapped память. Хорошие куски отъедают системные аллокаторы, файлы с ресурсами, фреймворки для работы с изображениями и другие хищники помельче.
По итогам экспериментов в Облаке мы пришли к следующим компромиссным значениям выделяемой LMDB памяти: 384 мегабайт для 32-битных устройств и 768 — для 64-битных. После израсходования этого объёма любые модифицирующие операции начинают завершаться с кодом MDB_MAP_FULL. Такие ошибки мы наблюдаем в нашем мониторинге, но их достаточно мало, чтобы на данном этапе ими можно было пренебречь.
Неочевидной причиной чрезмерного потребления памяти хранилищем могут стать долгоживущие транзакции. Для понимания, как связаны эти два явления, нам поможет рассмотрение оставшихся двух китов LMDB.
3.2. Кит №2. B+-дерево
Для эмулирования таблиц поверх key-value хранилища необходимо, чтобы в его API присутствовали следующие операции:
- Вставка нового элемента.
- Поиск элемента с заданным ключом.
- Удаление элемента.
- Итерирование по интервалам ключей в порядке их сортировки.
 Самой простой структурой данных, с помощью которой можно легко реализовать все четыре операции, является бинарное дерево поиска. Каждый его узел представляет собой ключ, делящий всё подмножество дочерних ключей на два поддерева. В левом собраны те, которые меньше родительского, а в правом — которые больше. Получение упорядоченного набора ключей достигается за счёт одного из классических обходов дерева.
Самой простой структурой данных, с помощью которой можно легко реализовать все четыре операции, является бинарное дерево поиска. Каждый его узел представляет собой ключ, делящий всё подмножество дочерних ключей на два поддерева. В левом собраны те, которые меньше родительского, а в правом — которые больше. Получение упорядоченного набора ключей достигается за счёт одного из классических обходов дерева.
У бинарных деревьев есть два фундаментальных недостатка, которые не позволяют им быть эффективными в качестве дисковой структуры данных. Во-первых, степень их сбалансированности непредсказуема. Есть немалый риск получить деревья, в которых высота разных веток может сильно отличаться, что значительно ухудшает алгоритмическую сложность поиска по сравнению с ожидаемой. Во-вторых, обилие кросс-ссылок между узлами лишает бинарные деревья локальности в памяти. Близкие узлы (с точки зрения связей между ними) могут находиться на совершенно разных страницах в виртуальной памяти. Как следствие, даже для простого обхода нескольких соседних узлов в дереве может потребоваться посетить сопоставимое количество страниц. Это является проблемой даже когда мы рассуждаем об эффективности бинарных деревьев в качестве in-memory структуры данных, так как постоянная ротация страниц в кеше процессора — недешёвое удовольствие. Когда же речь заходит о частом поднятии связанных с узлами страниц с диска, то положение дел становится совсем уж плачевным.
 B-деревья, будучи эволюцией бинарных деревьев, решают обозначенные в предыдущем абзаце проблемы. Во-первых, они самобалансирующиеся. Во-вторых, каждый их узел разбивает множество дочерних ключей не на 2, а на M упорядоченных подмножеств, причем число M может быть довольно большим, порядка нескольких сотен, а то и тысяч.
B-деревья, будучи эволюцией бинарных деревьев, решают обозначенные в предыдущем абзаце проблемы. Во-первых, они самобалансирующиеся. Во-вторых, каждый их узел разбивает множество дочерних ключей не на 2, а на M упорядоченных подмножеств, причем число M может быть довольно большим, порядка нескольких сотен, а то и тысяч.
За счёт этого:
- В каждом узле находится большое количество уже упорядоченных ключей и деревья получаются очень низкими.
- Дерево приобретает свойство локальности размещения в памяти, поскольку близкие по значению ключи естественным образом располагаются рядом друг с другом на одном или соседних узлах.
- Уменьшается количество транзитных узлов при спуске по дереву во время операции поиска.
- Уменьшается количество считываемых целевых узлов при range-запросах, поскольку в каждом из них уже содержится большое количество упорядоченных ключей.
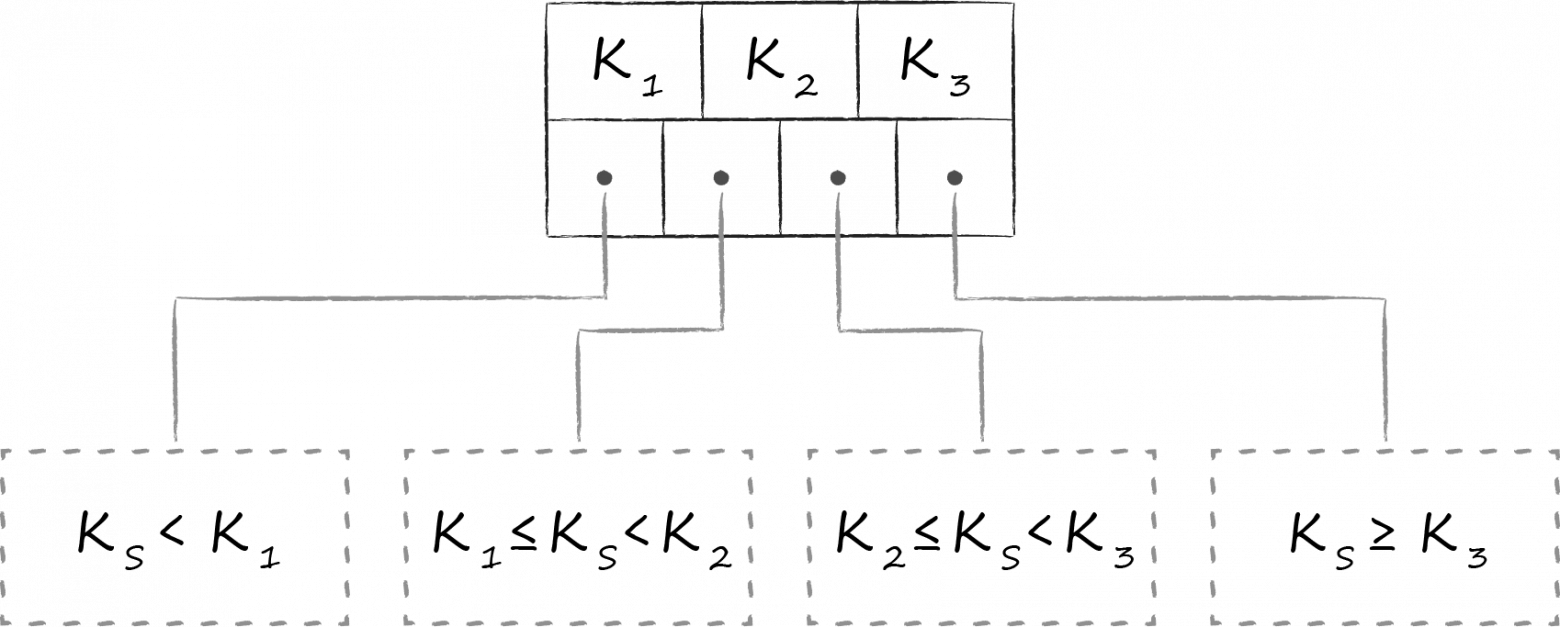
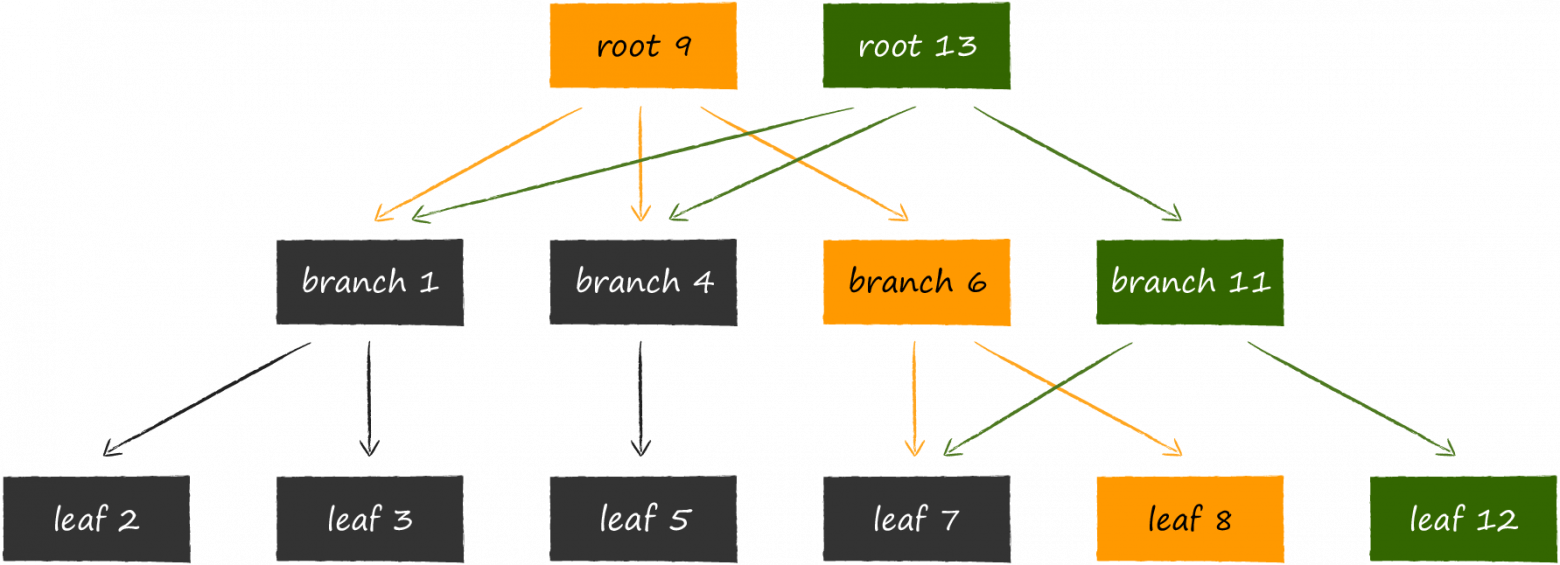
В LMDB для хранения данных используется одна из вариаций B-дерева под названием B+-дерево. На схеме выше изображены три типа узлов, которые в нём бывают:
- В вершине расположен корень (root). Он материализует собой ни что иное, как концепцию базы данных внутри хранилища. Внутри одного инстанса LMDB можно создавать несколько баз данных, разделяющих между собой замапленное виртуальное адресное пространство. Каждая из них начинается со своего собственного корня.
- На самом нижнем уровне находятся листья (leaf). Именно они и только они содержат хранящиеся в базе данных пары ключ-значение. К слову, в этом и заключается особенность B+-деревьев. Если обычное B-дерево хранит value-части в узлах всех уровней, то B+-вариация только на самом нижнем. Зафиксировав этот факт, далее будем называть подтип используемого в LMDB дерева просто B-деревом.
- Между корнем и листьями размещается 0 и более технических уровней c навигационными (branch) узлами. Их задача — поделить сортированное множество ключей между листьями.
Физически узлы — это блоки памяти заранее определенной длины. Их размер кратен размеру страниц памяти в операционной системе, о которых мы говорили выше. Ниже отображена структура узла. В хедере находится метаинформация, самая очевидная из которых для примера — это контрольная сумма. Далее идет информация об офсетах, по которым располагаются ячейки с данными. В роли данных могут выступать либо ключи, если мы говорим о навигационных узлах, либо целиком пары ключ-значение в случае листьев. Более подробно о структуре страниц можно почитать в работе «Evaluation of High Performance Key-Value Stores».

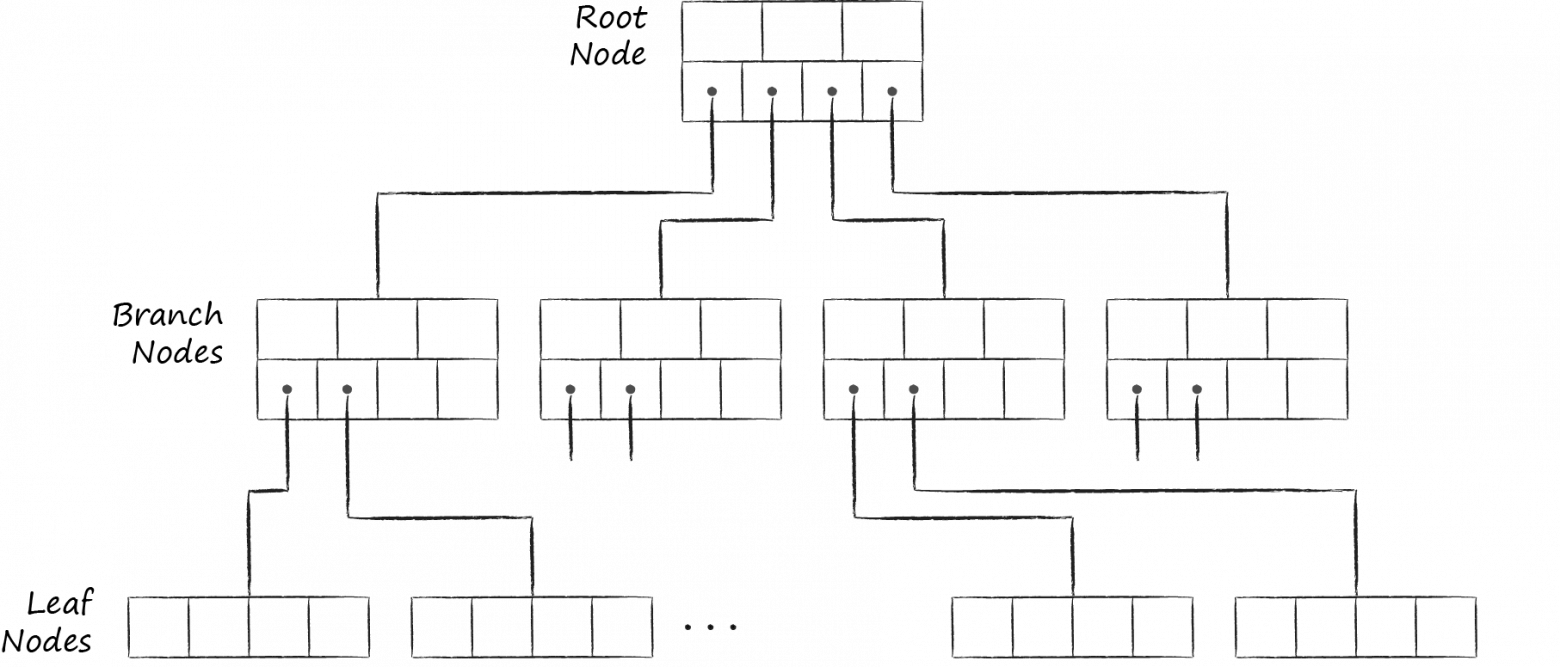
Разобравшись с внутренним наполнением узлов-страниц, далее B-дерево LMDB будем представлять упрощенно в следующем виде.

Страницы с узлами последовательно располагаются на диске. Так называемая мета-страница (meta page) содержит информацию о смещениях, по которым можно найти корни всех деревьев. При открытии файла LMDB постранично сканирует файл в поисках валидной мета-страницы и уже через неё находит существующие базы данных.
Теперь, обладая представлением о логической и физической структуре организации данных, можно переходить к рассмотрению третьего кита LMDB. Именно с его помощью все модификации хранилища происходят транзакционно и изолированно друг от друга, придавая базе данных в целом ещё и свойство мультиверсионности.
3.3. Кит №3. Copy-on-write
Некоторые операции с B-деревом предполагают внесение целой серии изменений в его узлах. Одним из примеров является добавление нового ключа в узел, в котором уже достигнута максимальная вместимость. В таком случае необходимо, во-первых, разделить узел на два, а во-вторых, добавить ссылку на новый отпочковавшийся дочерний узел в его родителе. Данная процедура потенциально очень опасна. Если по каким-то причинам (краш, отключение питания, и т.п.) случится только часть изменений из серии, то дерево останется в неконсистентном состоянии.
Одним из традиционных решений для обеспечения базы данных устойчивостью к сбоям является добавление рядом с B-деревом дополнительной дисковой структуры данных — лога транзакций, известного также под именем write-ahead log (WAL). Он представляет собой файл, в конец которого строго до модификации самого B-дерева записывается предполагаемая операция. Таким образом, если во время самодиагностики обнаруживается порча данных, база данных консультируется с логом для приведения себя в порядок.
LMDB в качестве механизма обеспечения устойчивости к сбоям выбрала другой способ, который называется copy-on-write. Его суть в том, что вместо обновления данных на существующей странице она сначала целиком её копирует и все модификации производит уже в копии.
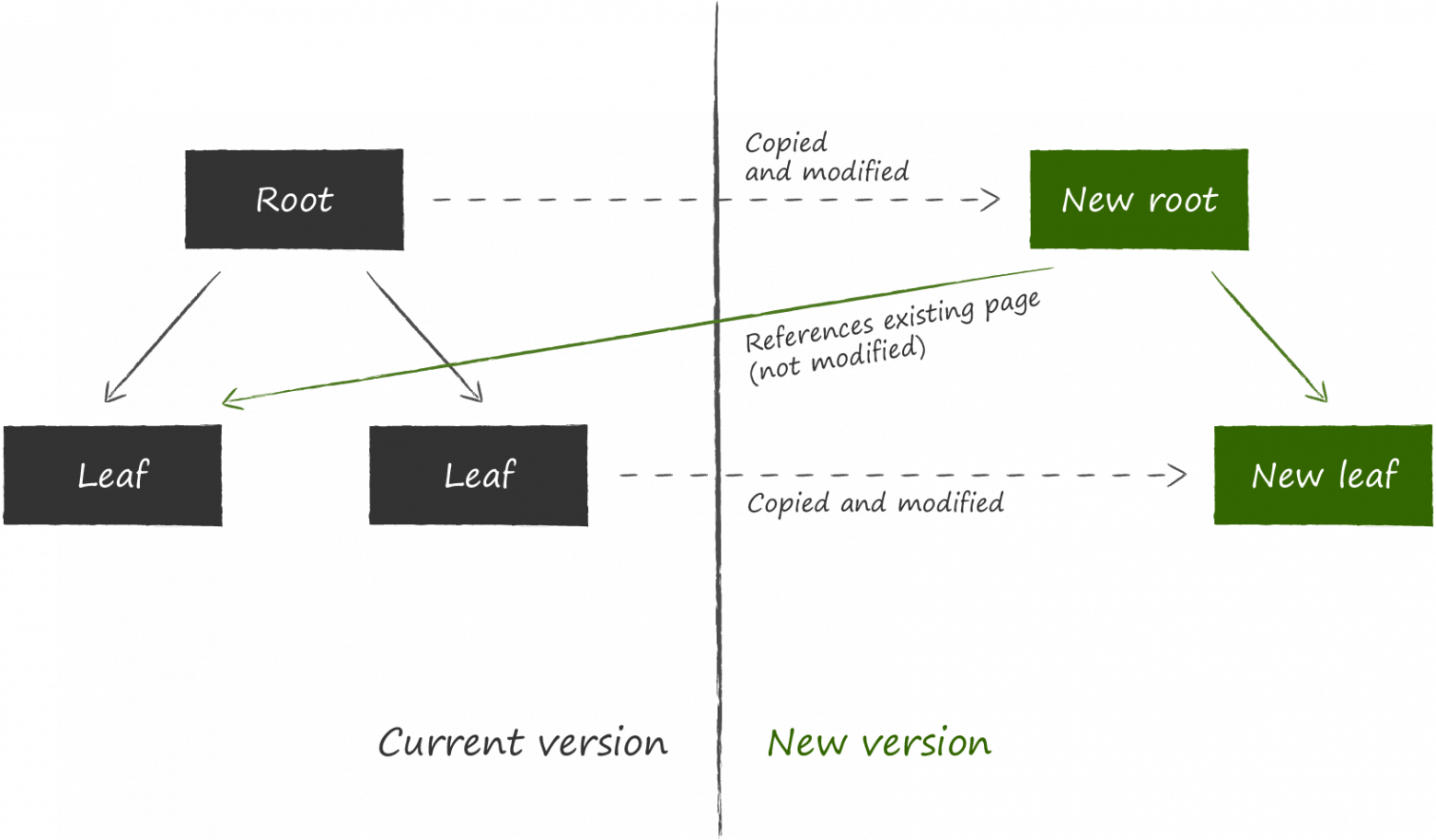
Далее, чтобы обновленные данные были доступны, необходимо изменить ссылку на ставший актуальным узел в родительском по отношению к нему узле. Поскольку для этого его тоже нужно модифицировать, он тоже предварительно копируется. Процесс продолжается рекурсивно до самого корня. Последними меняются данные на мета-странице.
Если вдруг во время процедуры обновления произойдет аварийное завершение процесса, то либо не создастся новая мета-страница, либо она не будет записана на диск до конца, и её контрольная сумма будет некорректной. В любом из этих двух случаев новые страницы будут недостижимы, а старые не пострадают. Это избавляет LMDB от необходимости вести write ahead log для поддержания консистентности данных. Де-факто структура хранения данных на диске, описанная выше, одновременно берёт на себя и его функцию. Отсутствие лога транзакций в явном виде — одна из фишек LMDB, обеспечивающая высокую скорость чтения данных.

Получившаяся конструкция естественным образом обеспечивает изоляцию транзакций и мультиверсионность. В LMDB с каждой открытой транзакцией ассоциируется актуальный на данный момент корень дерева. До тех пор, пока транзакция не завершена, страницы связанного с ней дерева никогда не будут изменены или повторно использованы под новые версии данных. Таким образом, можно сколь угодно долго работать ровно с тем набором данных, который был актуален на момент открытия транзакции, даже если хранилище в это время продолжает активно обновляться. В этом и заключается суть мультиверсионности, делающая LMDB идеальным источником данных для всеми нами любимого UICollectionView. Открыв транзакцию, не нужно повышать memory footprint приложения, спешно выкачивая актуальные данные в какую-нибудь in-memory структуру, боясь остаться у разбитого корыта. Данная особенность выгодно отличает LMDB от того же SQLite, который такой тотальной изоляцией похвастаться не может. Открыв в последнем две транзакции и удалив некую запись в рамках одной из них, эту же запись уже не получится получить и в рамках второй оставшейся.
Оборотной стороной медали является потенциально значительно больший расход виртуальной памяти. На слайде изображено, как будет выглядеть структура базы данных, если происходит её модификация одновременно с 3 открытыми транзакциями на чтение, смотрящими на разные версии базы данных. Поскольку LMDB не может повторно использовать узлы, достижимые из корней, связанных с актуальными транзакциями, хранилищу не остаётся ничего иного, кроме как разместить в памяти ещё один четвёртый корень и в очередной раз расклонировать под ним модифицируемые страницы.
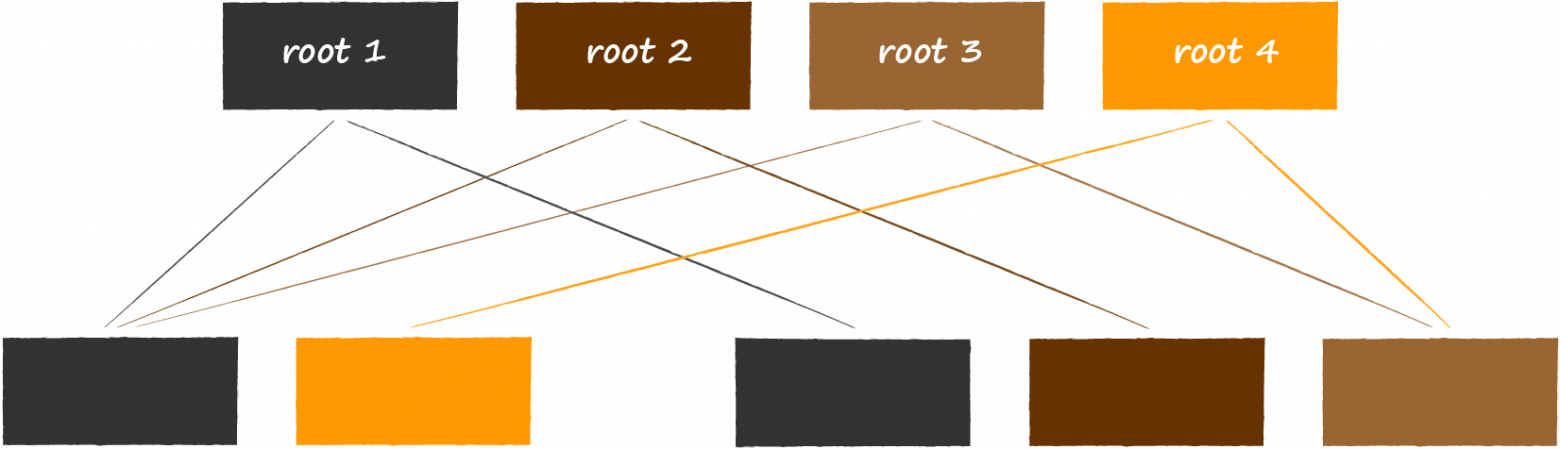
Здесь не лишним будет вспомнить раздел о memory-mapped файлах. Вроде бы дополнительный расход виртуальной памяти не должен нас сильно беспокоить, поскольку она не вносит вклада в memory footprint приложения. Однако в то же время было отмечено, что iOS очень скупа на её выделение, и мы не можем как на сервере или десктопе с барского плеча предоставить LMDB регион в 1 терабайт и не думать об этой особенности вовсе. По возможности нужно стараться делать время жизни транзакций как можно более коротким.
4. Проектирование схемы данных поверх key-value API
Как заметил русский математик и механик Пафнутий Чебышев, теория без практики мертва и бесплодна, а практика без теории бесполезна и пагубна. Поэтому пора перейти к рассмотрению кода, который заземлит все абстрактные конструкции, рассмотренные выше. Если же приводимые далее листинги также покажутся слишком умозрительными, и захочется посмотреть на цельное решение, соединяющее их все вместе в виде работающего приложения, то специально для этого случая на своём GitHub я выложил демо-приложение PodlodkaFiles. Оно реализует игрушечную доменную модель Облака Mail.ru и умеет хранить своё состояние двумя способами, в том числе с помощью LMDB.
Разбор API начнём с рассмотрения базовых абстракций, предоставляемых LMDB: окружение и базы данных, ключи и значения, транзакции и курсоры.
Все функции в публичном API LMDB возвращают результат своей работы в виде кода ошибки, но на всех последующих листингах его проверка опущена в угоду лаконичности. На практике мы и вовсе для взаимодействия с хранилищем использовали свой форк C++ обёртки lmdbxx, в котором ошибки материализуются в виде исключений C++.
В качестве наиболее быстрого способа подключения LMDB к проекту для iOS или macOS предлагаю свой CocoaPod POSLMDB.
4.1. Базовые абстракции
Окружение (environment)
Структура MDB_env является является вместилищем внутреннего состояния LMDB. Семейство функций с префиксом mdb_env позволяет сконфигурировать некоторые его свойства. В простейшем случае инициализация движка выглядит следующим образом.
mdb_env_create(env);
mdb_env_set_map_size(*env, 1024 * 1024 * 512)
mdb_env_open(*env, path.UTF8String, MDB_NOTLS, 0664);В приложении Облака Mail.ru значения по умолчанию мы меняли только у двух параметров.
Первый из них — это размер виртуального адресного пространства, на которое отображается файл хранилища. К сожалению, даже на одном и том же устройстве конкретное значение может существенно отличаться от запуска к запуску. Чтобы учесть эту особенность iOS, максимальный объём хранилища у нас подбирается динамически. Стартуя с некого значения, он последовательно ополовинивается до тех пор, пока функция mdb_env_open не вернет результат отличный от ENOMEM. В теории существует и противоположный путь — сначала выделить движку минимум памяти, а затем, при получении ошибок MDB_MAP_FULL, увеличивать её. Однако он гораздо более тернист. Причина в том, что процедура перевыделения памяти (remap) с помощью функции mdb_env_set_map_size инвалидирует все сущности (курсоры, транзакции, ключи и значения), полученные от движка ранее. Учёт такого поворота событий в коде приведёт к его существенному усложнению. Если, тем не менее, виртуальная память вам очень дорога, то это может быть поводом присмотреться к ушедшему далеко вперед форку MDBX, где среди заявленных фич есть «automatic on-the-fly database size adjustment».
Второй параметр, дефолтное значение которого нам не подошло, регулирует механику обеспечения потокобезопасности. К сожалению, как минимум в iOS 10 есть проблемы с поддержкой thread local storage. По этой причине в примере выше хранилище открывается с флагом MDB_NOTLS. Кроме этого понадобилось ещё и форкать C++ обёртку lmdbxx, чтобы вырезать переменные с этим атрибутом и в ней.
Базы данных
База данных представляет собой отдельный инстанс B-дерева, о которым мы поговорили выше. Её открытие происходит внутри транзакции, что поначалу может показаться немного странным.
MDB_txn *txn;
MDB_dbi dbi;
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
mdb_dbi_open(txn, NULL, MDB_CREATE, &dbi);
mdb_txn_abort(txn);Действительно, транзакция в LMDB — это сущность хранилища, а не конкретной базы данных. Такая концепция позволяет производить атомарные операции над сущностями, находящимися в разных базах данных. В теории это открывает возможность для моделирования таблиц в виде разных баз, но я в своё время пошел другим путём, расписанным в подробностях ниже.
Ключи и значения
Структура MDB_val моделирует концепцию как ключа, так и значения. Хранилище не имеет ни малейшего представления об их семантике. Для неё что то, что другое — это просто массив байт заданного размера. Максимальный размер ключа — 512 байт.
typedef struct MDB_val {
size_t mv_size;
void *mv_data;
} MDB_val;С помощью компаратора хранилище упорядочивает ключи по возрастанию. Если не заменить его собственным, то будет использоваться дефолтный, который сортирует их побайтово в лексикографическом порядке.
Транзакции
Устройство транзакций подробно описано в предыдущей главе, поэтому здесь короткой строкой повторю их основные свойства:
- Поддержка всех базовых свойств ACID: атомарность, консистентность, изолированность и надёжность. Не могу не отметить, что в части durability на macOS и iOS есть баг, исправленный в MDBX. Подробнее можно почитать в их README.
- Подход к многопоточности описывается схемой «single writer / multiple readers». Писатели блокируют друг друга, но не блокируют читателей. Читатели не блокируют ни писателей, ни друг друга.
- Поддержка вложенных транзакций.
- Поддержка мультиверсионности.
Мультиверсионность в LMDB настолько хороша, что хочу продемонстрировать её в действии. Из кода ниже видно, что каждая транзакция работает именно с той версией базы данных, которая была актуальна на момент её открытия, будучи полностью изолированной от всех последующих изменений. Инициализация хранилища и добавление в него тестовой записи ничего интересного не представляют, поэтому данные ритуалы оставлены под спойлером.
MDB_env *env;
MDB_dbi dbi;
MDB_txn *txn;
mdb_env_create(&env);
mdb_env_open(env, "./testdb", MDB_NOTLS, 0664);
mdb_txn_begin(env, NULL, 0, &txn);
mdb_dbi_open(txn, NULL, 0, &dbi);
mdb_txn_abort(txn);
char k = 'k';
MDB_val key;
key.mv_size = sizeof(k);
key.mv_data = (void *)&k;
int v = 997;
MDB_val value;
value.mv_size = sizeof(v);
value.mv_data = (void *)&v;
mdb_txn_begin(env, NULL, 0, &txn);
mdb_put(txn, dbi, &key, &value, MDB_NOOVERWRITE);
mdb_txn_commit(txn);MDB_txn *txn1, *txn2, *txn3;
MDB_val val;
// Открываем 2 транзакции, каждая из которых смотрит
// на версию базы данных с одной записью.
mdb_txn_begin(env, NULL, 0, &txn1); // read-write
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn2); // read-only
// В рамках первой транзакции удаляем из базы данных существующую в ней запись.
mdb_del(txn1, dbi, &key, NULL);
// Фиксируем удаление.
mdb_txn_commit(txn1);
// Открываем третью транзакцию, которая смотрит на
// актуальную версию базы данных, где записи уже нет.
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn3);
// Убеждаемся, что запись по искомому ключу уже не существует.
assert(mdb_get(txn3, dbi, &key, &val) == MDB_NOTFOUND);
// Завершаем транзакцию.
mdb_txn_abort(txn3);
// Убеждаемся, что в рамках второй транзакции, открытой на момент
// существования записи в базе данных, её всё ещё можно найти по ключу.
assert(mdb_get(txn2, dbi, &key, &val) == MDB_SUCCESS);
// Проверяем, что по ключу получен не абы какой мусор, а валидные данные.
assert(*(int *)val.mv_data == 997);
// Завершаем транзакцию, работающей хоть и с устаревшей, но консистентной базой данных.
mdb_txn_abort(txn2);Факультативно рекомендую попробовать провернуть такой же фокус с SQLite и посмотреть, что получится.
Мультиверсионность привносит очень приятные плюшки в жизнь iOS-разработчика. С помощью этого свойства можно легко и непринужденно регулировать скорость обновления источника данных (data source) для экранных форм, исходя из соображений пользовательского опыта. Для примера возьмём такую фичу приложения Облака Mail.ru как автозагрузка контента из системной медиагалереи. При хорошем соединении клиент способен добавлять на сервер несколько фотографий в секунду. Если после каждой загрузки актуализировать UICollectionView с медиаконтентом в облаке пользователя, то можно забыть о 60 fps и плавном скроллинге во время этого процесса. Чтобы предотвратить частые обновления экрана, необходимо как-то ограничить скорость изменения данных в основе UICollectionViewDataSource.
Если база данных не поддерживает мультиверсионность и позволяет работать лишь с текущим актуальным состоянием, то для создания стабильного во времени снапшота данных необходимо произвести его копирование либо в некую in-memory структуру данных, либо во временную таблицу. Любой из этих подходов очень накладен. В случае in-memory хранилища получаем расходы как по памяти, вызванные хранением сконструированных объектов, так и по времени, связанные с избыточными ORM-преобразованиями. Что касается временной таблицы, то это ещё более дорогое удовольствие, имеющее смысл только в нетривиальных кейсах.
Мультиверсионность LMDB решает задачу поддержания стабильного источника данных очень элегантно. Достаточно просто открыть транзакцию и вуа-ля — пока мы её не завершим набор данных у нас гарантированно зафиксирован. Логика скорости его обновления теперь целиком и полность находится в руках презентационного слоя при полном отсутствии накладных расходов значимых ресурсов.
Курсоры
Курсоры предоставляют механизм для упорядоченного итерирования по парам ключ-значение посредством обхода B-дерева. Без них было бы невозможно эффективно моделировать таблицы в базе данных, к рассмотрению которых мы и переходим.
4.2. Моделирование таблиц
Свойство упорядоченности ключей позволяет конструировать поверх базовых абстракций такую высокоуровневую как таблица. Рассмотрим этот процесс на примере основной таблицы облачного клиента, в которой закеширована информация обо всех файлах и папках пользователя.
Схема таблицы
Одним из частых сценариев, под который должна быть заточена структура таблицы с деревом папок — выборка всех элементов, расположенных внутри заданной директории. Хорошей моделью организации данных для эффективных запросов такого рода является Adjacency List. Для её воплощения поверх key-value хранилища необходимо отсортировать ключи файлов и папок таким образом, чтобы они группировались на основании принадлежности к родительской директории. Кроме того, чтобы отображать содержимое директории в привычном пользователю Windows виде (сначала папки, потом файлы, и те и другие отсортированы по алфавиту), необходимо включить в ключ соответствующие дополнительные поля.
На картинке ниже показано, как, исходя из поставленной задачи, может выглядеть представление ключей в виде массива байт. Вначале размещаются байты с идентификатором родительской директории (красные), потом — с типом (зелёные) и уже в хвосте — с именем (синие). Будучи отсортированными дефолтным компаратором LMDB в лексикографическом порядке, они упорядочиваются требуемым образом. Последовательный обход ключей с одним и тем же красным префиксом даёт нам связанные с ними значения в той последовательности, в которой они должны быть выведены в интерфейсе пользователя (справа), не требуя как-то дополнительной постобработки.

Сериализация ключей и значений
В мире придумано множество методов сериализации объектов. Поскольку у нас никакого иного требования кроме скорости не было, для себя мы выбрали самый быстрый из возможных — дамп памяти, занимаемой инстансом структуры языка C. Так, ключ элемента директории можно смоделировать следующей структурой NodeKey.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;Для сохранения NodeKey в хранилище нужно в объекте MDB_val спозиционировать указатель на данные на адрес начала структуры, а их размер вычислить функцией sizeof.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = sizeof(NodeKey),
.mv_data = (void *)key
};
}В первой главе о критериях выбора базы данных в качестве важного фактора выбора я упоминал минимизацию динамических аллокаций в рамках операций CRUD. Код функции serialize показывает, как в случае LMDB их можно полностью избежать при вставке в базу данных новых записей. Пришедший массив байт с сервера сначала трансформируется в стековые структуры, а затем они тривиальным образом дампятся в хранилище. Учитывая, что внутри LMDB также нет динамических аллокаций, можно получить фантастическую по меркам iOS ситуацию — задействовать для работы с данными на всём их пути от сети до диска только стековую память!
Упорядочивание ключей бинарным компаратором
Отношение порядка ключей задаётся специальной функцией, называемой компаратором. Поскольку движок ничего не знает о семантике содержащихся в них байт, дефолтному компаратору не остаётся ничего иного, кроме как упорядочить ключи в лексикографическом порядке, прибегая к их побайтовому сравнению. Пользоваться им для упорядочивания структур сродни бритью разделочным топором. Тем не менее, в несложных случаях я нахожу этот способ приемлемым. Альтернатива описана чуть ниже, а здесь отмечу парочку разбросанных на этом пути граблей.
Первое, о чём необходимо помнить — это представление в памяти примитивных типов данных. Так, на всех устройствах Apple целочисленные переменные хранятся в формате Little Endian. Это означает, что наименее значимый байт будет находится слева, и отсортировать целые числа, используя их побайтовое сравнение, не получится. Например, попытка сделать это с набором чисел от 0 до 511 приведёт к следующему результату.
// value (hex dump)
000 (0000)
256 (0001)
001 (0100)
257 (0101)
...
254 (fe00)
510 (fe01)
255 (ff00)
511 (ff01)Для решения этой проблемы целые числа должны храниться в ключе в подходящем для побайтового компаратора формате. Осуществить необходимое преобразование помогут функции из семейства hton* (в частности htons для двухбайтовых чисел из примера).
Формат представления строк в программировании — это, как известно, целая история. Если семантика строк а также используемая для их представления в памяти кодировка предполагает, что на символ может приходится больше одного байта, то от идеи использования дефолтного компаратора лучше сразу отказаться.
Второе, что нужно держать в голове — принципы выравнивания компилятором полей структуры. Из-за них в памяти между полями могут образовываться байты с мусорными значениями, что, конечно же, ломает побайтовую сортировку. Для ликвидации мусора нужно либо объявлять поля в строго определённом порядке, держа в голове правила выравнивания, либо использовать в объявлении структуры атрибут packed.
Упорядочивание ключей внешним компаратором
Логика сравнения ключей может отказаться слишком сложной для бинарного компаратора. Одна из множества причин — наличие внутри структур технических полей. Проиллюстрирую их возникновение на примере уже знакомого нам ключа для элемента директории.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;При всей своей простоте в подавляющем большинстве случаев он потребляет слишком много памяти. Буфер под название занимает 256 байт, хотя в среднем имена файлов и папок редко превышают 20-30 символов.
Один из стандартных приёмов оптимизации размера записи состоит в её «подрезании» под фактический размер. Его суть в том, что содержимое всех полей переменной длины хранится в буфере в конце структуры, а их длины — в отдельных переменных. В соответствии с этим подходом ключ NodeKey трансформируется следующим образом.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Далее при сериализации в качестве размера данных указывается не sizeof всей структуры, а размер всех полей фиксированной длины плюс размер реально используемой части буфера.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = offsetof(NodeKey, nameBuffer) + key->nameLength,
.mv_data = (void *)key
};
}В результате произведённого рефакторинга мы получили значительную экономию занимаемого ключами места. Однако из-за технического поля nameLength, дефолтный бинарный компаратор более не годится для сравнения ключей. Если мы его не заменим на свой, то длина имени будет более приоритетным фактором при сортировке, нежели само имя.
LMDB позволяет задать каждой базе данных свою функцию сравнения ключей. Делается это с помощью функции mdb_set_compare строго до открытия. По очевидным причинам, на протяжении всей жизни базы данных менять её нельзя. На вход компаратор получает два ключа в бинарном формате, а на выходе возвращает результат сравнения: меньше (-1), больше (1) или равны (0). Псевдокод для NodeKey выглядит так.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey * const aKey = (NodeKey * const)a->mv_data;
NodeKey * const bKey = (NodeKey * const)b->mv_data;
return // ...
}До тех пор, пока в базе данных все ключи имеют один и тот же тип, безусловное приведение их байтового представления к типу прикладной структуры ключа является законным. Тут есть один нюанс, но он будет рассмотрен чуть ниже в подразделе «Чтение записей».
Сериализация значений
С ключами хранимых записей LMDB работает крайне интенсивно. Их сравнение между собой происходит в рамках любой прикладной операции, и от скорости работы компаратора зависит производительность всего решения. В идеальном мире для сравнения ключей должно хватать дефолтного бинарного компаратора, но если уж пришлось использовать свой собственный, то процедура десериализации ключей в нём должна быть настолько быстрой, насколько это возможно.
Value-частью записи (значением) база данных особо не интересуется. Её преобразование из байтового представления в объект происходит только тогда, когда это уже требуется прикладному коду, например, для его отображения на экране. Поскольку происходит это относительно редко, то требования к скорости этой процедуры не столь критичны, и в её реализации мы в гораздо большей степени вольны ориентироваться на удобство. Например, для сериализации метаданных о ещё не загруженных файлах у нас используется NSKeyedArchiver.
NSData *data = serialize(object);
MDB_val value = {
.mv_size = data.length,
.mv_data = (void *)data.bytes
};Тем не менее бывают случаи, когда производительность всё же имеет значение. Например, для при сохранении метаинформации о файловой структуре пользовательского облака мы пользуемся всё тем же дампом памяти объектов. Изюминкой задачи по формированию их сериализованного представления является тот факт, что элементы директории моделируются иерархией классов.
Для её реализации на языке C специфические поля наследников выносятся в отдельные структуры, а их связь с базовой задаётся через поле типа union. Актуальное содержимое объединения задаётся через технический атрибут type.
typedef struct NodeValue {
EntityId localId;
EntityType type;
union {
FileInfo file;
DirectoryInfo directory;
} info;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeValue;Добавление и обновление записей
Сериализованные ключ и значение можно добавлять хранилище. Для этого используется функция mdb_put.
// key и value имеют тип MDB_val
mdb_put(..., &key, &value, MDB_NOOVERWRITE);На этапе конфигурации хранилищу можно разрешить или запретить хранить несколько записей с одинаковым ключом. Если дублирование ключей запрещено, то при вставке записи можно определить допустимо ли обновление уже существующей записи или нет. Если перетирание может произойти лишь вследствие ошибки в коде, то от неё можно подстраховаться, указав флаг NOOVERWRITE.
Чтение записей
Для чтения записей в LMDB предназначена функция mdb_get. Если пара ключ-значение представлена ранее сдампленными структурами, то выглядит эта процедура следующим образом.
NodeValue * const readNode(..., NodeKey * const key) {
MDB_val rawKey = serialize(key);
MDB_val rawValue;
mdb_get(..., &rawKey, &rawValue);
return (NodeValue * const)rawValue.mv_data;
}Представленный листинг показывает, как сериализация через дамп структур позволяет избавится от динамических аллокаций не только при записи, но при чтении данных. Полученный из функции mdb_get указатель смотрит в аккурат в тот адрес виртуальной памяти, где база данных хранит байтовое представление объекта. По факту у нас получается эдакий ORM, практически бесплатно обеспечивающий очень высокую скорость чтения данных. При всей красоте подхода необходимо помнить о нескольких сопряжённых с ним особенностях.
- Для readonly транзакции указатель на структуру-значение будет гарантированно оставаться валидным лишь до тех пор, пока транзакция не будет закрыта. Как было отмечено ранее, страницы B-дерева, на которых располагается объект, благодаря принципу copy-on-write остаются неизменными пока на них ссылается хотя бы одна транзакция. В то же время, как только последняя связанная с ними транзакция завершается, страницы могут быть повторно использованы для новых данных. Если необходимо, чтобы объекты переживали породившую их транзакцию, то их всё-таки придётся скопировать.
- Для readwrite транзакции указатель на полученную структуру-значение будет валидным лишь до первой модифицирующей процедуры (запись или удаление данных).
- Несмотря на то, что структура
NodeValueне полноценная, а подрезанная (см. подраздел «Упорядочивание ключей внешним компаратором»), через указатель можно спокойно обращаться к её полям. Главное его не разыменовывать! - Ни в коем случае нельзя модифицировать структуру через полученный указатель. Все изменения должны осуществляться только через метод
mdb_put. Впрочем, при всём желании сделать это и не получится, поскольку область памяти, где эта структура располагается, замаплена в режиме readonly. - Remap файла на адресное пространство процесса с целью, например, увеличения максимального размера хранилища с помощью функции
mdb_env_set_map_sizeполностью инвалидирует все транзакции и связанные с ними сущности вообще и указатели на считанные объекты в частности.
Наконец, ещё одна особенность настолько коварна, что раскрытие её сути никак не влезает просто в ещё один пункт. В главе про B-дерево я приводил схему устройства его страниц в памяти. Из неё следует, что адрес начала буфера с сериализованными данными может быть абсолютно произвольным. Из-за этого указатель на них, получаемый в структуре MDB_val и приводимый к указателю на структуру, получается в общем случае не выровненным. В то же время архитектуры некоторых чипов (в случае iOS это armv7) требуют, чтобы адрес любых данных был кратен размеру машинного слова или, иначе говоря, битности системы (для armv7 — это 32 бита). Иными словами операция вроде *(int *foo)0x800002 на них приравнивается к побегу и приводит к расстрелу с вердиктом EXC_ARM_DA_ALIGN. Избежать столь печальной участи можно двумя способами.
Первый сводится к предварительному копированию данных в заведомо выровненную структуру. Например, на кастомном компараторе это отразится следующим образом.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey aKey, bKey;
memcpy(&aKey, a->mv_data, a->mv_size);
memcpy(&bKey, b->mv_data, b->mv_size);
return // ...
}Альтернативный путь — заранее уведомить компилятор, что структуры с ключом и значением могут быть не выровненными с помощью атрибута aligned(1). На ARM такого же эффекта можно добиться и с помощью атрибута packed. Учитывая, что он к тому же ещё и способствует оптимизации занимаемого структурой места, данный способ мне видится предпочтительным, хоть и приводит к удорожанию операций доступа к данным.
typedef struct __attribute__((packed)) NodeKey {
uint8_t parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Range-запросы
Для итерирования по группе записей в LMDB предусмотрена абстракция курсора. О том, как с ним работать, рассмотрим на примере уже знакомой нам таблицы с метаданными облака пользователя.
В рамках отображения списка файлов в директории необходимо найти все ключи, с которыми проассоциированы её дочерние файлы и папки. В предыдущих подразделах мы отсортировали ключи NodeKey таким образом, чтобы они в первую очередь были упорядочены по идентификатору родительской директории. Таким образом, технически задача получения содержимого папки сводится к установке курсора на верхнюю границу группы ключей с заданным префиксом с последующим итерированием до нижней границы.

Найти верхнюю границу можно "в лоб" последовательным поиском. Для этого курсор устанавливается в начало всего списка ключей в базе данных и далее инкрементируется до тех пор, пока не под ним не окажется ключ с идентификатором родительской директории. У этого подхода есть 2 очевидных недостатка:
- Линейная сложность поиска, хотя, как известно, в деревьях вообще и в B-дереве в частности его можно осуществить за логарифмическое время.
- Напрасно поднимаются из файла в основную память все страницы, предшествующих искомой, что крайне дорого.
К счастью в API LMDB предусмотрен эффективный способ начального позиционирования курсора. Для этого нужно сформировать такой ключ, значение которого будет заведомо меньше либо равно ключу, находящегося на верхней границе интервала. Например, применительно к списку на рисунке выше, мы можем сделать такой ключ, в котором поле parentId будет равно 2, а все остальные заполнены нулями. Такой частично заполненный ключ подается на вход функции mdb_cursor_get с указанием операция MDB_SET_RANGE.
NodeKey upperBoundSearchKey = {
.parentId = 2,
.type = 0,
.nameLength = 0
};
MDB_val value, key = serialize(upperBoundSearchKey);
MDB_cursor *cursor;
mdb_cursor_open(..., &cursor);
mdb_cursor_get(cursor, &key, &value, MDB_SET_RANGE);Если верхняя граница группы ключей найдена, то далее итерируемся по ней пока либо не встретиться либо ключ с другим parentId, либо ключи вовсе не закончатся.
do {
rc = mdb_cursor_get(cursor, &key, &value, MDB_NEXT);
// processing...
} while (MDB_NOTFOUND != rc && // check end of table
IsTargetKey(key)); // check end of keys groupЧто приятно, в рамках итерирования с помощью mdb_cursor_get мы получаем не только ключ, но и значение. Если для выполнения условий выборки нужно проверить в том числе поля из value-части записи, то они вполне себе доступны без дополнительных телодвижений.
4.3. Моделирование связей между таблицами
К текущему моменту нам удалось рассмотреть все аспекты проектирования и работы с однотабличной базой данных. Можно сказать, что таблица — это набор отсортированных записей, состоящих из однотипных пар ключ-значение. Если отобразить ключ в виде прямоугольника, а связанное с ним значение в виде параллелепипеда, то получится визуальная схема базы данных.

Однако в реальной жизни редко удается обойтись столь малой кровью. Зачастую в базе данных требуется, во-первых, иметь несколько таблиц, а во-вторых, осуществлять в них выборки в порядке, отличном от первичного ключа. Вопросам их создания и связывания между собой и посвящен данный последний раздел.
Индексные таблицы
В облачном приложении есть раздел «Галерея». В нём отображается медиаконтент из всего облака, отсортированный по дате. Для оптимальной реализации такой выборки рядом с основной таблицей нужно завести ещё одну с новым типом ключей. В них будет содержаться поле с датой создания файла, которое будет выступать в качестве первичного критерия сортировки. Поскольку новые ключи ссылаются на те же самые данные, что и ключи в основной таблице, они называются индексными. На картинке ниже они выделены оранжевым цветом.
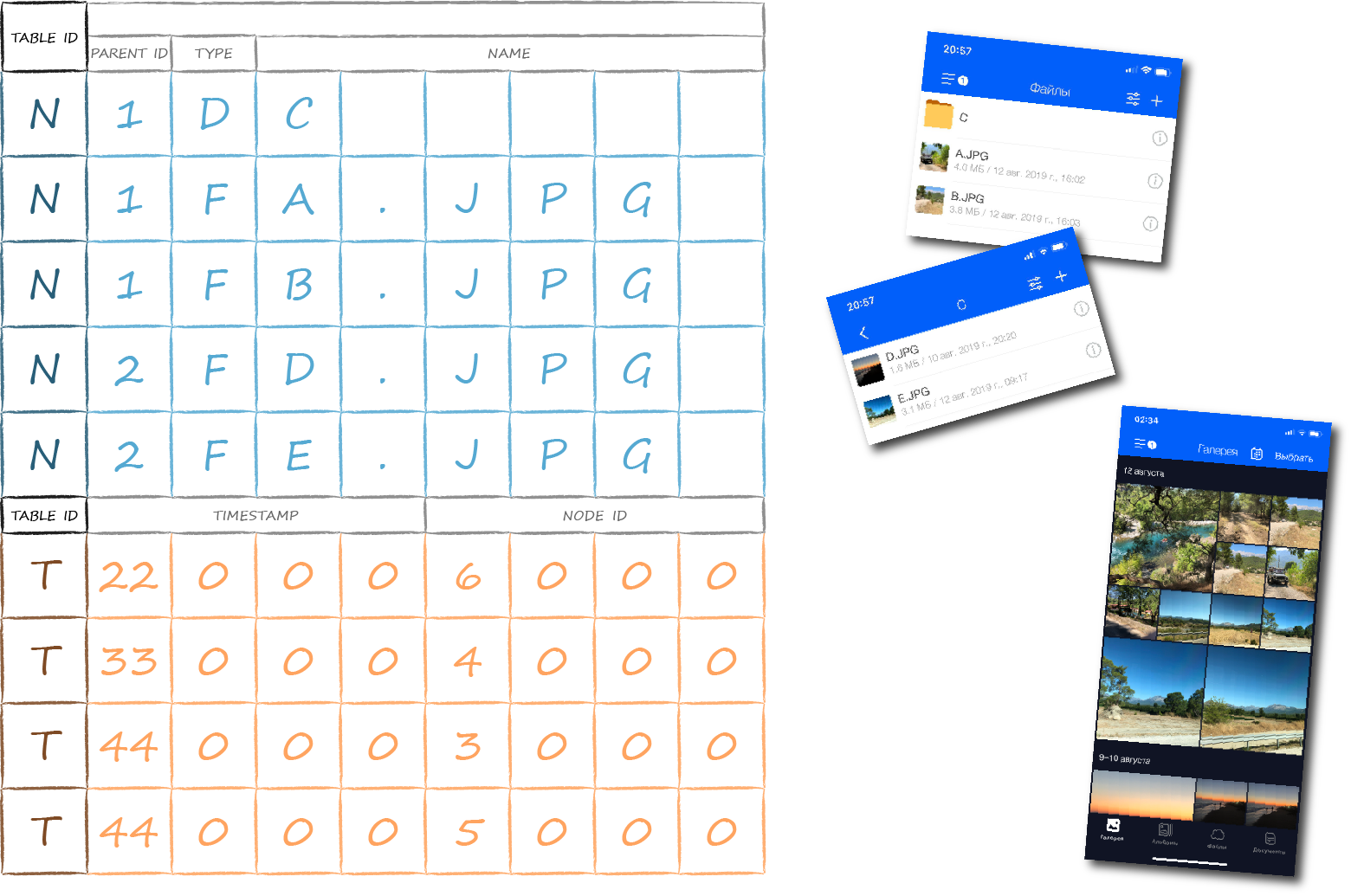
Чтобы внутри одной базы данных отделить друг от друга ключи разных таблиц, им всем добавлено дополнительное техническое поле tableId. Сделав его самым приоритетным для сортировки, мы добьемся группировки ключей сначала по таблицам, а уже внутри таблиц — по своим правилам.
Индексный ключ ссылается те же данные, что и первичный. Прямолинейная реализация этого свойства через ассоциацию с ним копии value-части первичного ключа неоптимально сразу с нескольких точек зрения:
- С точки зрения занимаемого места в виду того, что метаданные могут быть весьма богатыми.
- С точки зрения производительности, так как при обновлении метаданных ноды придется делать перезапись по двум ключам.
- С точки зрения поддержки кода, ведь стоит нам забыть обновить данные по одному из ключей, как мы получим трудноуловимый баг неконсистентности данных в хранилище.
Далее рассмотрим как ликвидировать эти недостатки.
Организация связей между таблицами
Для связи индексной таблицы с основной хорошо подходит паттерн «ключ как значение». Как следует из его названия в качестве value-части индексной записи выступает копия значения первичного ключа. Этот подход нивелирует все перечисленные выше недостатки, связанные с хранением копии value-части первичной записи. Единственная плата — для получения значения по индексному ключу нужно сделать 2 запроса в базу данных вместо одного. Схематично получившаяся схема базы данных выглядит следующим образом.
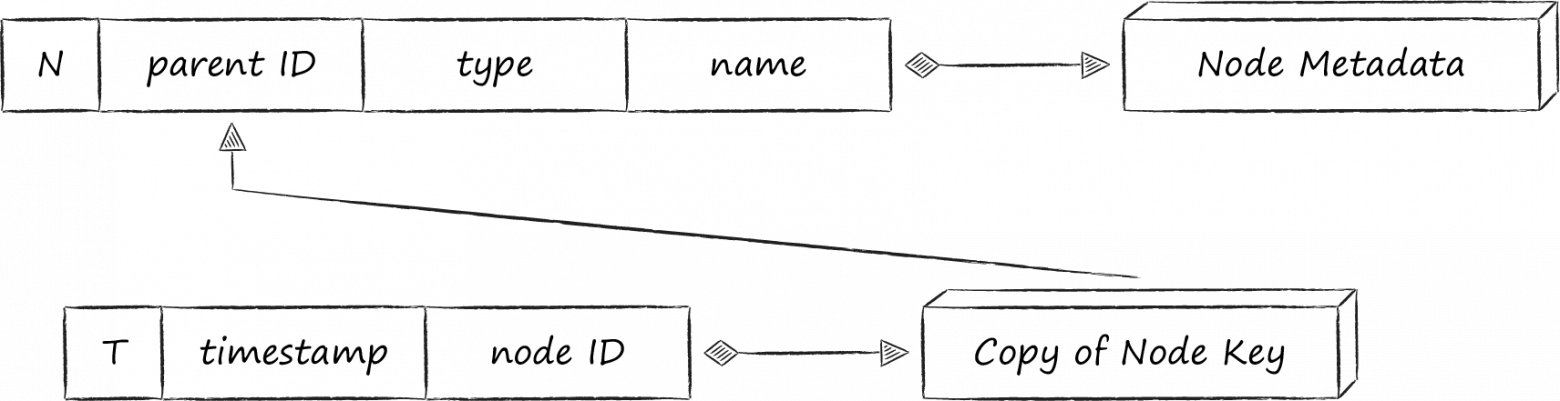
Ещё одним паттерном организации связи между таблицами является «избыточный ключ». Его суть в добавлении в ключ дополнительных атрибутов, которые нужны не для сортировки, а для воссоздания связанного ключа. В приложении Облака Mail.ru есть реальные примеры его использования, однако во избежании глубокого погружения в контекст специфических iOS-фреймворков, приведу вымышленный, но зато более понятный пример.
В облачных мобильных клиентах есть страница, где отображаются все файлы и папки, к которым пользователь предоставил доступ другим людям. Поскольку таких файлов относительно мало, а разного рода связанной с ними специфической информации о публичности много (кому предоставлен доступ, с какими правами и т.п.) будет не рационально утяжелять ей value-часть записи в основной таблице. Однако если захотеть отображать такие файлы в офлайне, то хранить её где-то всё-таки нужно. Естественным вариантом решения является заведение под неё отдельной таблицы. На схеме ниже её ключ имеет префикс «P», а плейсхолдер «propname» может быть заменён на более конкретное значение «public info».

Все уникальные метаданные, ради хранения которых и заводилась новая таблица, выносятся в value-часть записи. В то же время, те данные о файлах и папках, которые уже хранятся в основной таблице, дублировать не хочется. Вместо этого в ключ «P» добавляются избыточные данные в лице полей «node ID» и «timestamp». Благодаря ним можно сконструировать индексный ключ, по которому получить первичный ключ, по которому, наконец, получить метаданные ноды.
Заключение
Итоги внедрения LMDB мы оцениваем позитивно. После него количество зависаний приложения уменьшилось на 30%.

Результаты проделанной работы нашли отклик за пределами команды iOS. На текущий момент один из главных разделов «Файлы» в приложении для Android также перешёл на использование LMDB, а другие части на подходе. Язык C, на котором реализовано key-value хранилище, явился хорошим подспорьем, чтобы изначально сделать прикладную обвязку вокруг него кроссплатформенно на языке С++. Для бесшовного соединения получившейся C++ библиотеки с платформенным кодом на Objective-C и Kotlin был использован кодогенератор Djinni от Dropbox, но это уже совсем другая история.
В самом конце не могу ещё раз не привести ссылку на демо-приложение PodlodkaFiles. Изучение его внутреннего устройства поможет соединить воедино всю рассмотренную тут теорию и практику, и, таким образом, будет хорошим следующим шагом для тех из вас, кто заинтересовался LMDB в контексте мобильной разработки.
