
Привет! Меня зовут Юра Дорофеев, я работаю над Android-версией мессенджера ТамТам. Представьте, что вы договариваетесь о встрече с другом, и он отправляет вам адрес. Но не отдельным сообщением, а посреди другого текста:

Как этот адрес быстро вставить в навигатор или карту? Приходится копировать всё сообщение, потом вырезать лишнее. А если вы за рулем, то проще переписать адрес с нуля или вообще озвучить его голосом. Ну и моё самое любимое — поздравления с днем рождения. В текущих реалиях это номер банковской карты среди текста сообщения:

И тоже сидишь, копируешь, вырезаешь или просишь автора скинуть отдельным сообщением, чтобы весь чат не мучился так же, как и ты.
Проблема была известна, висела в беклоге, но до нее не доходили руки. В это же время Google разрабатывал решение для поиска сущностей в тексте и приглашал партнеров к его тестированию. У компании есть набор библиотек ML Kit, которые позволяют решать какие-то точечные задачи при помощи нейронных сетей. Например, нахождение лица на фотографии или считывание штрих-кода.
Все библиотеки из пакета ML Kit работают с уже обученными моделями. Никакие данные не уходят на серверы Google, вся обработка происходит офлайн и локально на устройстве. А самое главное, это бесплатно! Google готовился к запуску новой библиотеки Entity Extraction, которая умеет находить сущности в тексте и классифицировать их. Вот пример:
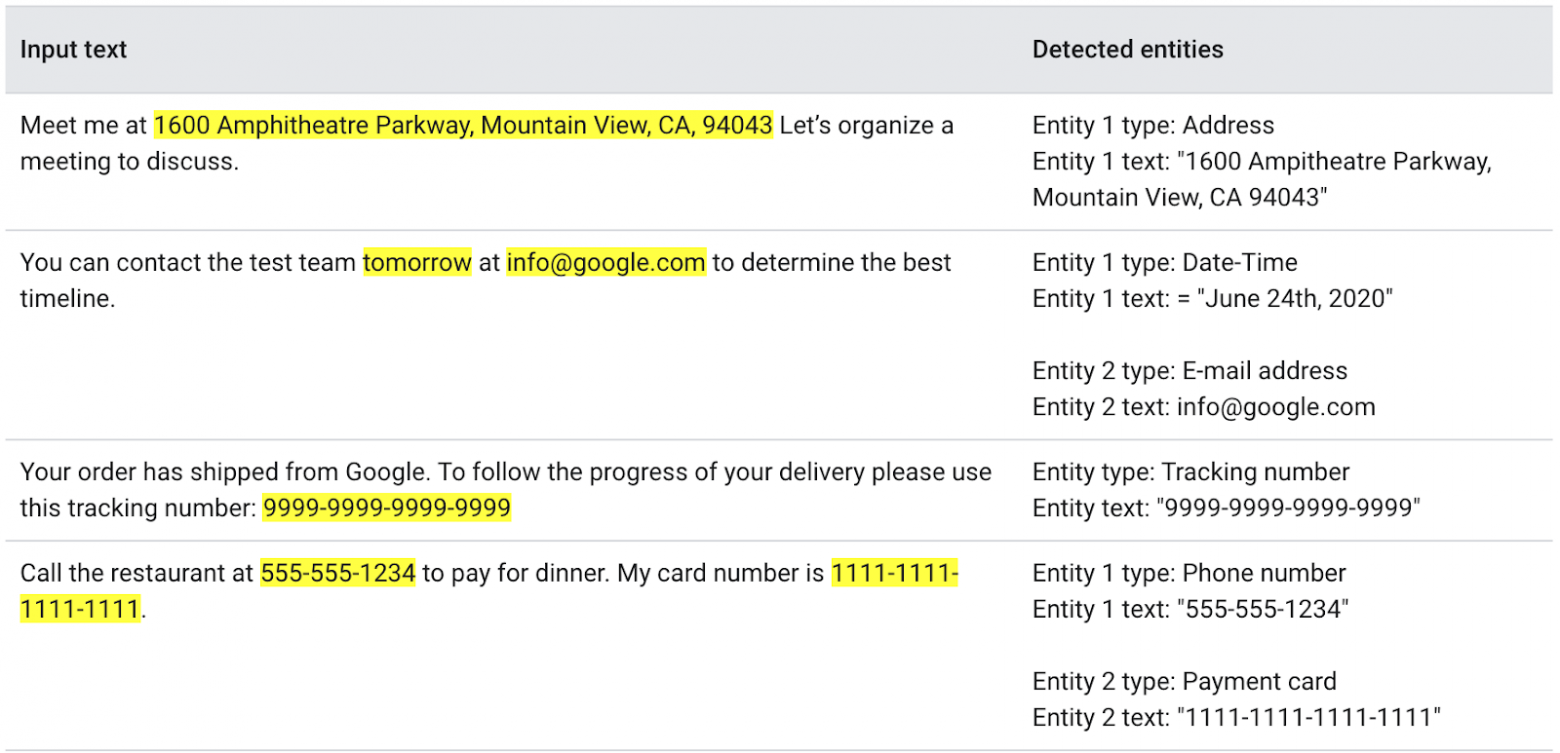
Всего библиотека умеет находить 11 типов сущностей на 15 языках:

Нахождение сущностей устроено следующим образом: вначале текст разбивается на слова. Дальше все слова объединятся во всевозможные последовательности с максимальной длиной 15 слов. И для каждой из этих последовательностей производится оценка, насколько этот набор слов похож на какую-либо сущность. Чем больше похож, тем ближе оценка к единице.
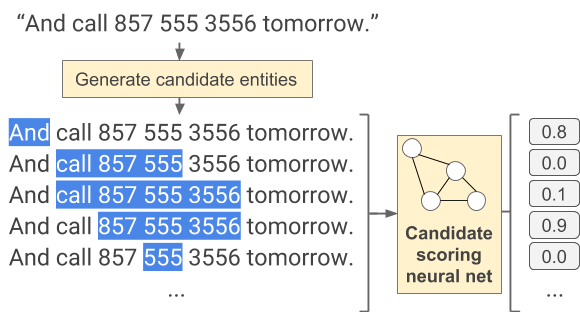
После этого из последовательностей, которые пересекаются, берутся те, у которых оценка больше. Последним этапом определяется, что именно за сущность скрыта в данной последовательности.
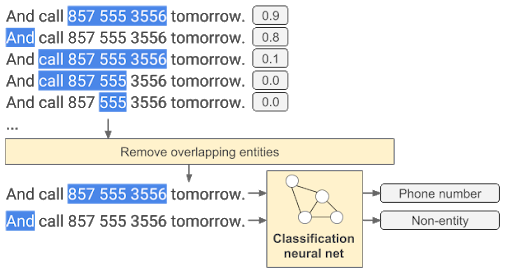
Интересно, что не для всех типов сущностей используются нейронные сети. Например, для распознавания времени, даты, номеров авиарейсов используются регулярные выражения.
Звучит очень круто, а самое главное — должно помочь нам с решением проблемы копирования номера банковской карты из текста сообщения. Мы согласились поучаствовать в программе раннего доступа. Google выслал нам библиотеку с документацией. Было опасение, что библиотека окажется монструозная и использовать её будет очень сложно. Давайте проверим.
Чтобы начать работу, нам нужно инициализировать EntityExtractor. Это та самая штука, которая будет находить сущности в тексте. Инициализируется она очень просто: нужно передать опции с минимальным количеством аргументов — язык, на котором написан исходный текст, и Executor. По умолчанию библиотека использует свой Executor, но можно перевести выполнение на любой другой.
Под каждый язык обучена своя модель, и библиотеке нужно знать, какую модель использовать. Казалось бы, можно же автоматически определить язык? Да, для этого есть отдельная библиотека из набора ML Kit и можно её подключить. Она тоже довольно легкая и имеет простой интерфейс.
Всё просто. Вначале собираем параметры для работы экстрактора. Устанавливаем preferredLocale. Это не язык, на котором будет вестись распознавание, а языковой стандарт для форматирования различных сущностей. Например: 1.10.2021 в русском языке — первое октября, а в английском — десятое января, здесь разный порядок месяца и даты.
Далее устанавливаем список сущностей, которые мы готовы обработать. Настраиваем загрузку моделей. В простейшем случае выставляем downloadModelIfNeeded, что означает, что необходимая модель будет скачана, если будет такая необходимость. Если нужна более сложная логика, то есть механизм, позволяющий качать модели по желанию:
В начале статьи я сказал, что библиотека работает полностью офлайн, а парой строчек выше я говорю, что нужно качать какие-то модели. Нестыковка. В самой библиотеке нет моделей, они скачиваются под каждый язык. Но это единственное, что вам нужно будет скачать, далее библиотека будет работать офлайн. Сами модели небольшие, примерно 600-700 Кб. Модель скачивается в папку files в директории приложения. Странно, конечно, что нельзя задать свой путь. Поэтому, если у вас в приложении есть какая-то очистка кэша, не забудьте настроить исключение на эту папку:

P.S. Уже во время использования выяснилось, что библиотека может падать на вызове downloadModelIfNeeded, не забудьте завернуть в try-catch.
Окей, мы скачали модели, задействовали EntityExtractor, что дальше? А дальше просто выставляйте Span в ваш текст, настраивайте цвет отображения, действия по клику и всё, что вашей душе угодно:
Всё просто и понятно. Так? Нет, не так. Скорость обработки одного сообщения колеблется от 8 до 100 мс. Это не так уж и быстро. Сообщения в чатах у нас грузятся чанками по 40 сообщений. В худшем случае обработка займет 4000 мс или 4 с. То есть потенциально можно задержать открытие чата на 4 с.

Пришлось сделать небольшой хак: изначально мы показываем сообщение как есть, и если в фоне оно обработано, и там была найдена сущность, мы анимированно покажем найденный объект.
Выглядит неплохо, и не пришлось задерживать открытие чата:

Сейчас в Google Play опубликована версия мессенджера ТамТам, которая включает все решения, описанные выше. Мы умеем находить в тексте:
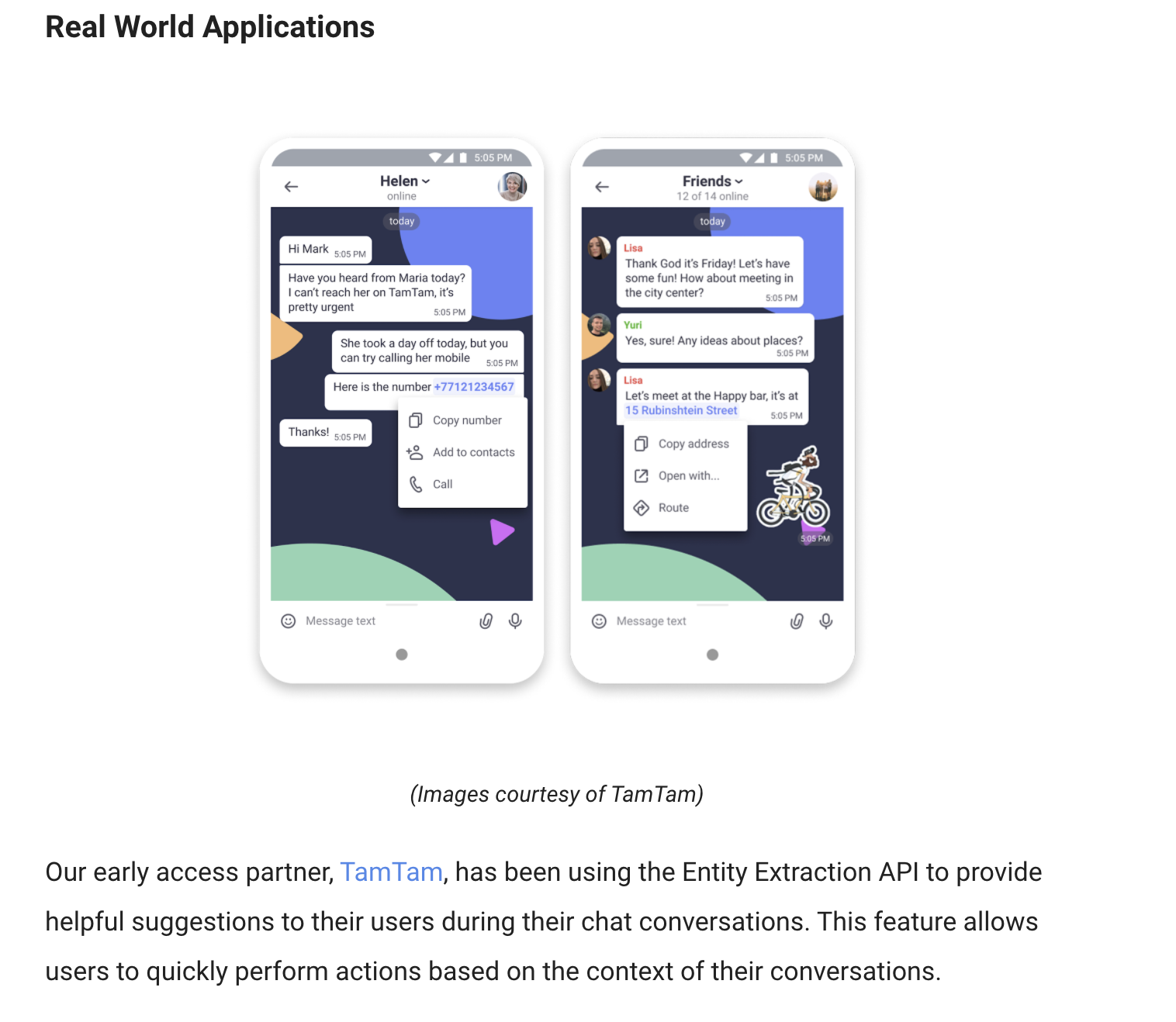
Кроме того, поскольку мы одними из первых приложений в мире успешно внедрили библиотеку, о ТамТам написал Google в своем девелоперском блоге:
Как этот адрес быстро вставить в навигатор или карту? Приходится копировать всё сообщение, потом вырезать лишнее. А если вы за рулем, то проще переписать адрес с нуля или вообще озвучить его голосом. Ну и моё самое любимое — поздравления с днем рождения. В текущих реалиях это номер банковской карты среди текста сообщения:
И тоже сидишь, копируешь, вырезаешь или просишь автора скинуть отдельным сообщением, чтобы весь чат не мучился так же, как и ты.
Выбор Google
Проблема была известна, висела в беклоге, но до нее не доходили руки. В это же время Google разрабатывал решение для поиска сущностей в тексте и приглашал партнеров к его тестированию. У компании есть набор библиотек ML Kit, которые позволяют решать какие-то точечные задачи при помощи нейронных сетей. Например, нахождение лица на фотографии или считывание штрих-кода.
Все библиотеки из пакета ML Kit работают с уже обученными моделями. Никакие данные не уходят на серверы Google, вся обработка происходит офлайн и локально на устройстве. А самое главное, это бесплатно! Google готовился к запуску новой библиотеки Entity Extraction, которая умеет находить сущности в тексте и классифицировать их. Вот пример:
Всего библиотека умеет находить 11 типов сущностей на 15 языках:
Принцип работы
Нахождение сущностей устроено следующим образом: вначале текст разбивается на слова. Дальше все слова объединятся во всевозможные последовательности с максимальной длиной 15 слов. И для каждой из этих последовательностей производится оценка, насколько этот набор слов похож на какую-либо сущность. Чем больше похож, тем ближе оценка к единице.
После этого из последовательностей, которые пересекаются, берутся те, у которых оценка больше. Последним этапом определяется, что именно за сущность скрыта в данной последовательности.
Интересно, что не для всех типов сущностей используются нейронные сети. Например, для распознавания времени, даты, номеров авиарейсов используются регулярные выражения.
Пробуем
Звучит очень круто, а самое главное — должно помочь нам с решением проблемы копирования номера банковской карты из текста сообщения. Мы согласились поучаствовать в программе раннего доступа. Google выслал нам библиотеку с документацией. Было опасение, что библиотека окажется монструозная и использовать её будет очень сложно. Давайте проверим.
Чтобы начать работу, нам нужно инициализировать EntityExtractor. Это та самая штука, которая будет находить сущности в тексте. Инициализируется она очень просто: нужно передать опции с минимальным количеством аргументов — язык, на котором написан исходный текст, и Executor. По умолчанию библиотека использует свой Executor, но можно перевести выполнение на любой другой.
private val entityExtractor: Lazy<EntityExtractor> = lazy {
EntityExtraction.getClient(
EntityExtractorOptions.Builder(buildModelLocale())
.setExecutor(executor)
.build()
)
}
Зачем указывать язык?
Под каждый язык обучена своя модель, и библиотеке нужно знать, какую модель использовать. Казалось бы, можно же автоматически определить язык? Да, для этого есть отдельная библиотека из набора ML Kit и можно её подключить. Она тоже довольно легкая и имеет простой интерфейс.
Как использовать EntityExtractor?
Всё просто. Вначале собираем параметры для работы экстрактора. Устанавливаем preferredLocale. Это не язык, на котором будет вестись распознавание, а языковой стандарт для форматирования различных сущностей. Например: 1.10.2021 в русском языке — первое октября, а в английском — десятое января, здесь разный порядок месяца и даты.
Далее устанавливаем список сущностей, которые мы готовы обработать. Настраиваем загрузку моделей. В простейшем случае выставляем downloadModelIfNeeded, что означает, что необходимая модель будет скачана, если будет такая необходимость. Если нужна более сложная логика, то есть механизм, позволяющий качать модели по желанию:
private fun entityAnnotationsSingle(text: String): Single<List<EntityAnnotation>> {
return Single.create { emitter: SingleEmitter<List<EntityAnnotation>> ->
// .........
val params = EntityExtractionParams.Builder(text)
.setPreferredLocale(userLocale)
.setEntityTypesFilter(SUPPORTED_TYPES)
.build()
entityExtractor
.downloadModelIfNeeded()
.onSuccessTask { entityExtractor.annotate(params) }
.addOnFailureListener(executor, onFailureListener)
.addOnSuccessListener(executor, onSuccessListener)
}
}
Скачивание моделей
В начале статьи я сказал, что библиотека работает полностью офлайн, а парой строчек выше я говорю, что нужно качать какие-то модели. Нестыковка. В самой библиотеке нет моделей, они скачиваются под каждый язык. Но это единственное, что вам нужно будет скачать, далее библиотека будет работать офлайн. Сами модели небольшие, примерно 600-700 Кб. Модель скачивается в папку files в директории приложения. Странно, конечно, что нельзя задать свой путь. Поэтому, если у вас в приложении есть какая-то очистка кэша, не забудьте настроить исключение на эту папку:
P.S. Уже во время использования выяснилось, что библиотека может падать на вызове downloadModelIfNeeded, не забудьте завернуть в try-catch.
Используем сущности
Окей, мы скачали модели, задействовали EntityExtractor, что дальше? А дальше просто выставляйте Span в ваш текст, настраивайте цвет отображения, действия по клику и всё, что вашей душе угодно:
fun addMlEntities(text: CharSequence): Maybe<CharSequence> {
return entityAnnotationsSingle(text.toString())
.onErrorReturnItem(emptyList())
.flatMapMaybe { entityAnnotations: List<EntityAnnotation> ->
if (entityAnnotations.isEmpty()) {
return@flatMapMaybe Maybe.empty()
}
val spannable = text.spannable()
for (annotation in entityAnnotations) {
if (annotation.entities.isNotEmpty()) {
val span = MlSpan(annotation.entities[0], annotation.annotatedText, color)
spannable.setSpan(span, annotation.start, annotation.end, SPAN_EXCLUSIVE_EXCLUSIVE)
}
}
return@flatMapMaybe Maybe.just(spannable)
}
}
Всё просто и понятно. Так? Нет, не так. Скорость обработки одного сообщения колеблется от 8 до 100 мс. Это не так уж и быстро. Сообщения в чатах у нас грузятся чанками по 40 сообщений. В худшем случае обработка займет 4000 мс или 4 с. То есть потенциально можно задержать открытие чата на 4 с.
Пришлось сделать небольшой хак: изначально мы показываем сообщение как есть, и если в фоне оно обработано, и там была найдена сущность, мы анимированно покажем найденный объект.
class MlSpan(...) : ClickableSpan() {
// ....
override fun updateDrawState(ds: TextPaint) {
if (!this::colorAnimator.isInitialized) {
colorAnimator = ValueAnimator.ofObject(argbEvaluator, ds.color, color)
colorAnimator.duration = 200
colorAnimator.addUpdateListener {
currentColor = it.animatedValue as Int
animationListener?.onAnimationUpdate()
}
colorAnimator.start()
}
ds.color = currentColor
}
}
Выглядит неплохо, и не пришлось задерживать открытие чата:
Заключение
Сейчас в Google Play опубликована версия мессенджера ТамТам, которая включает все решения, описанные выше. Мы умеем находить в тексте:
- адреса;
- e-mail;
- номера телефонов;
- почтовые номера отслеживания;
- номера банковских карт.
Кроме того, поскольку мы одними из первых приложений в мире успешно внедрили библиотеку, о ТамТам написал Google в своем девелоперском блоге:
